
Windows failover cluster что это
Обновлено: 05.07.2024
Несмотря на неоднозначное отношение к Microsoft необходимо отметить, что компания сделала высокие технологии доступными для простых пользователей. Так или иначе, но современное положение сферы информационных технологий не в последнюю очередь определено именно компанией Microsoft.
Далеко не всегда решения и продукты от компании Microsoft сразу занимали позиции на уровне специализированных решений, однако наиболее важные все равно постепенно выбивались в лидеры в соотношении цена/функциональность, а также по простоте внедрения. Одним из таких примеров являются кластеры.
Разработка вычислительных кластеров не является сильной стороной Microsoft. Об этом свидетельствует, в том числе, тот факт, что разработки компании не попали в список Top-500 суперкомпьютеров. Поэтому совершенно логично, что в линейке Windows Server 2012 отсутствует редакция HPC (High-performance computing –высокопроизводительные вычисления).
Кроме того, учитывая особенности высокопроизводительных вычислений, платформа Windows Azure кажется более перспективной. Поэтому компания Microsoft сосредоточила свое внимание на кластерах высокой доступности.
Кластеры в Windows.
Впервые поддержка кластеров была реализована компанией Microsoft еще в операционной системе в Windows NT 4 Server Enterprise Edition в виде технологии Microsoft Cluster Service (MSCS). В операционной системе Windows Server 2008 она превратилась в компонент Failover Clustering. По сути это кластеры с обработкой отказа или высокодоступные кластеры, хотя иногда их не вполне корректно называют отказоустойчивыми.
В общем случае при выходе из строя узла, к которому идет запрос, как раз и будет проявляться отказ в обслуживании, однако при этом произойдет автоматический перезапуск кластеризуемых сервисов на другом узле, и система будет приведена в состояние готовности в кратчайший срок.
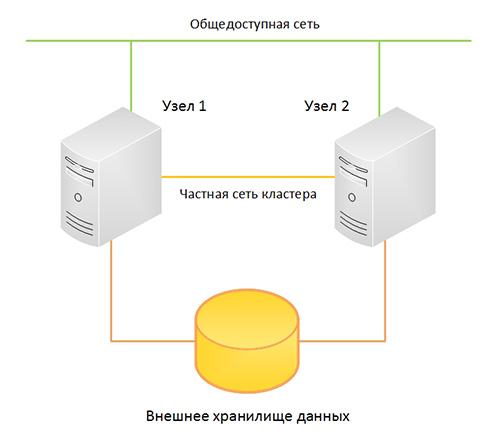
С момента первой реализации, поддержка кластеров в Windows существенно изменилась. Была реализована поддержка файловых и сетевых служб, позже SQL Server (в операционной системе Windows Server 2000), Exchange Server ( в Windows Server 2003), и другие стандартные службы и роли, включая Hyper-V (в операционной системе Windows Server 2008). Была улучшена масштабируемость (до 64 узлов в Windows Server 2012), список кластеризуемых сервисов был расширен.
Поддержка виртуализации, а также позиционирование Windows Server как облачной операционной системы, стали поводом для дальнейшего развития поддержки кластеров, поскольку высокая плотность вычислений предъявляет высокие требования к надежности и доступности инфраструктуры. Поэтому, начиная с операционной системы Windows Server 2008, именно в этой области сосредоточена основная масса усовершенствований.
В операционной системе Windows Server 2008 R2 реализованы общие тома кластера Hyper-V (CSV), позволяющие узлам одновременно обращаться к одной файловой системе NTFS. В результате несколько кластерных виртуальных машин могут использовать один адрес LUN и мигрировать с узла на узел независимо.
В Windows Server 2012 кластерная поддержка Hyper-V была усовершенствована. Была добавлена возможность управления на уровне целого кластера приоритетами виртуальных машин, определяющих порядок перераспределения памяти, восстановления вирутальных машин в случае выхода из строя узлов или запланированной массовой миграции. Были расширены возможности мониторинга – в случае сбоя контролируемой службы появилась возможность перезапуска не только самой службы, но и всей виртуальной машины. Есть возможность осуществления миграции на другой, менее загруженный узел. Реализованы и другие, не менее интересные нововведения, касающиеся кластеризации.
Кластеры в Windows Server 2012.
Сначала остановимся на нововведениях в базовых технологиях, которые используются кластерами или помогаю расширить их возможности.
SMB 3.0
Новая версия протокола SMB 3.0 используется для сетевого обмена данными. Этот протокол востребован при выполнении чтения, записи и других файловых операций на удаленных ресурсах. В новой версии реализовано большое количество усовершенствований, которые позволяют оптимизировать работу SQL Server, Hyper-V и файловых кластеров. Обратим внимание на следующие обновления:
- прозрачная отказоустойчивость. Это новшество обеспечивает непрерывность выполнения операций. При сбое одного из узлов файлового кластера текущие операции автоматически передаются другому узлу. Благодаря этому нововведению стала возможной реализация схемы Active-Active с поддержкой до 8 узлов.
- масштабирование. Благодаря новой реализации общих томов кластера (версия 2.0) существует возможность одновременного доступа к файлам через все узлы кластера, за счет чего достигается агрегация пропускной способности и осуществляется балансировка нагрузки.
- SMB Direct. Реализована поддержка сетевых адаптеров с технологией RDMA. Технология RDMA (удаленный прямой доступ к памяти) позволяет передавать данные непосредственно в память приложения, существенно освобождая центральный процессор.
- SMB Multichannel. Позволяет агрегировать пропускную способность и повышает отказоустойчивость при наличии нескольких сетевых путей между сервером с поддержкой SMB 3.0 и клиентом.
Необходимо сказать, что для использования этих возможностей поддержка SMB 3.0 должна присутствовать на обоих концах соединения. Компания Microsoft рекомендует использование серверов и клиентов одного поколения (в случае с Windows Server 2012 такой клиентской платформой является Windows 8). К сожалению, на сегодня Windows 7 поддерживает только SMB версии 2.1.
Storage Spaces.
Технология Storage Spaces реализована впервые в операционных системах Windows Server 2012 и Windows 8. Реализована поддержка новой файловой системы ReFS, которая обеспечивает функции повышения отказоустойчивости. Есть возможность назначения дисков в пуле для горячей замены (в случае отказа других носителей или для быстрой замены исчерпавшего свой ресурс SSD). Кроме того, расширены возможности тонкой настройки с использованием PowerShell.
По сути, технология Storage Spaces является программной реализацией RAID, расширенной за счет большого числа дополнительных функций. Во-первых, накопители с прямым доступом должны быть объединены в пулы. В принципе накопители могут быть любых типов и мощностей, однако для организации стабильной работы необходимо четкое понимание принципов функционирования технологии.
Далее на пулах можно создавать виртуальные диски следующих типов (не путать с VHD/VHDX):
- простой (является аналогом RAID 0);
- зеркало (двухстороннее зеркало является аналогом RAID1, трехстороннее зеркало представляет собой более сложную схему наподобие RAID 1E)
- с контролем четности (является аналогом RAID 5. Данный вариант обеспечивает минимальный перерасход пространства при минимальной отказоустойчивости).
Технология Storage Spaces не является абсолютным новшеством. Похожие возможности были давно реализованы в Windows Server, например в форме динамических дисков. Технология Storage Spaces позволяет сделать использование всех этих возможностей более удобными и обеспечить новый уровень использования. Среди прочих преимуществ Storage Spaces необходимо отметить тонкую инициализацию (thin provisioning), которая дает возможность назначать виртуальным дискам размеры сверх доступных в реальности из расчета на добавление в соответствующий пул новых накопителей впоследствии.
Один из наиболее непростых вопросов, связанных с технологией Storage Spaces – это производительность. Как правило, программные реализации RAID уступают по производительности аппаратным вариантам. Однако, если речь идет о файловом сервере, то Storage Spaces получает в свое распоряжение большой объем оперативной памяти и мощный процессор, поэтому необходимо тестирование с учетом различных видов нагрузки. С этой точки зрения особую ценность приобретают возможности тонкой настройки с использованием PowerShell.
Технология Storage Spaces предлагает отказ от RAID-контроллеров и дорогих систем хранения, перенеся из логику на уровень операционной системы. Эта идея раскрывает все свои достоинства и оказывается достаточно привлекательной вместе с еще одним новшеством.
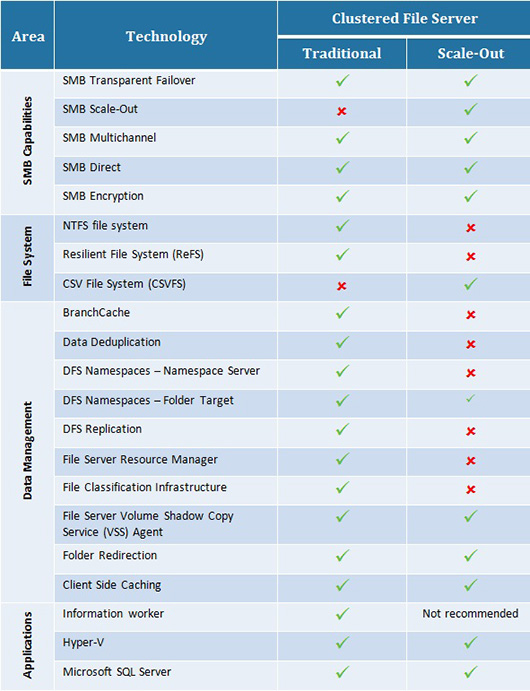
Scale-Out File Server (SOFS).
Еще одним новшеством является режим кластеризуемой роли File Server в Windows Server 2012, который получил название Scale-Out File Server. Теперь реализована поддержка двух типов кластеризации, названия которых полностью звучат как File Sever for General Use и Scale-Out File Server (SOFS) for application data. Каждая из технологий имеет свои сферы применения, а также свои достоинства и недостатки.
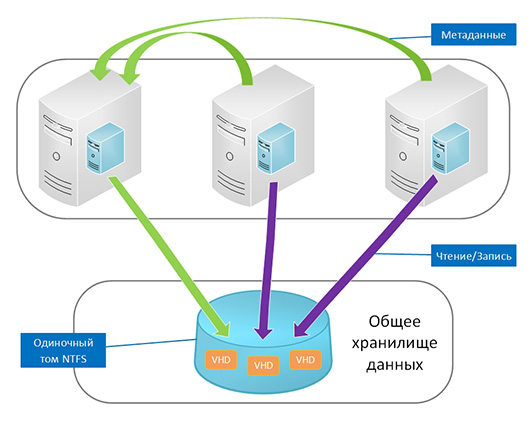
Всецелевой файловый сервер представляет собой хорошо известный тип кластера Active-Passive. В свою очередь SOFS представляет собой кластер Active-Active, являясь действительно отказоустойчивой конфигурацией. Для совместного доступа к соответствующим папкам используется опция Continuously Available.
Помимо отличных характеристик отказоустойчивости это обеспечивает повышение пропускной способности при условии рационального проектирования сетевой архитектуры. Проксирующая файловая система CSV 2.0 (CSVFS) позволяет уменьшить влияние CHKDSK, позволяя утилите выполнять необходимые операции, сохраняя при этом возможность работы с томом активных приложений. Реализовано кэширование чтения с CSV. Использование CSV обеспечивает простоту и удобство развертывания и управления. Пользователю нужно создать обычный кластер, настроить том CSV и активировать роль файлового сервера в режиме Scale-Out File Server for application data.
Благодаря простоте и функциональности предложенного решения сформировался новый класс оборудования «кластер-в-коробке» (Сluster-in-a-Box, CiB). Как правило, это шасси с двумя блейд-серверами и дисковым массивом SAS JBOD с поддержкой Storage Spaces. Здесь важно, чтобы SAS JBOD были двухпортовыми, и имелся SAS HBA для реализации перекрестного подключения.
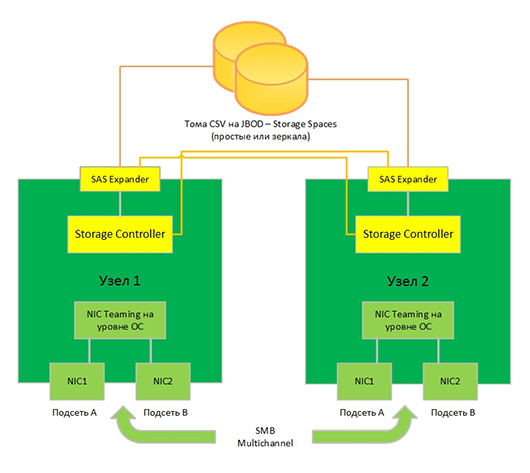
Такая организация системы ориентирована именно на поддержку SOFS. Учитывая, что iSCSI target стандартно интегрирован в Windows Server 2012 и также может быть кластеризована, таким образом может реализовать «самодельную» систему хранения данных на базе всецелевой операционной системы.
Однако следует иметь ввиду, что владельцем CSV по-прежнему является один из узлов, который отвечает за все операции с метаданными. При большом количестве метаданных может наблюдаться снижение производительности, поэтому для SOFS не рекомендуется использовать сценарий Information Worker, тогда как Hyper-V и SQL Server идеально подходят для этого, в том числе благодаря функциям агрегации пропускной способности.
Другие новшества технологий кластеризации Windows.
Выше мы перечислили только самые важные и крупные новшества в области кластеризации в Windows Server 2012. Другие менее крупные нововведения, однако, тоже появились не случайно.
Была расширена поддержка виртуализации за счет существенного упрощения создания гостевых кластеров (из виртуальных машин). В отличие от Windows Server 2008 R2, где для этого нужно было предоставить iSCSI Target в общее пользование виртуальных машин, в операционной системе Windows Server 2012 появилась функция, позволяющая виртуализировать FC-контроллер (по аналогии с сетевыми адаптерами), за счет чего виртуальные машины получают возможность непосредственного доступ к LUN. Реализован и более простой вариант с использованием общей сетевой папки SMB 3.0 для гостевых Windows Server 2012.
Одной из важных, но нетривиальных задач является установка программных обновлений в кластере. При этом может потребоваться перезагрузка узлов, поэтому процедура должна контролироваться. В операционной системе Windows Server 2012 предлагается инструмент Cluster-Aware Updating, который работает следующим образом: один из узлов назначается координатором и следит за наличием обновлений, загружает их на остальные узлы и выполняет поочередное обновление узлов, начиная с тех, которые загружены меньше всего. Благодаря этому доступность кластера сохраняется на максимально возможном уровне в течение всего процесса обновления.
Есть новшества и в управлении кворумом. Например, реализована возможность давать право голоса только некоторым узлам. Это может быть полезно при размещении отдельных узлов на удаленной площадке, но имеет наибольшую ценность при реализации новой модели динамического кворума. Основная идея динамического кворума состоит в том, что узел, прекративший свою работу и недоступный в течение определенного промежутка времени по любой причине, теряет право голоса вплоть до повторного подключения. Таким образом, общее число голосов сокращается и кластер сохраняет доступность максимально долго.
Новшества в Windows Server 2012 R2.
Операционная система Windows Server 2012 R2 не является простым обновлением Windows Server 2012, а представляет собой полноценную новую операционную систему. Новшества, реализованные в Windows Server 2012 R2 переводят некоторые возможности серверной платформы на качественно новый уровень. В первую очередь это касается SOFC и Hyper-V.
Высокодоступные виртуальные машины.
Упрощена процедура создания гостевых кластеров, поскольку теперь появилась возможность использовать в качестве общего хранилища обычные VHDX, которые внутри виртуальной машины будут представлены как Shared SAS-диски. При этом сами VHDX должны быть размещены на CSV или в общих папках SMB 3.0. При этом в виртуальных машинах могут использоваться как Windows Server 2012 R2, так и Windows Server 2012 (с обновленными интеграционными компонентами).
Опция DrainOnShutdown призвана избавить системных администраторов от ошибок и лишней работы. Функция активирована по умолчанию и при плановых перезагрузках или выключениях заранее переводит узел в такой режим обслуживания при котором эвакуируются все кластеризованные роли. При этом происходит миграция активных виртуальных машин на другие узлы кластера Hyper-V.
Также в новой операционной системе Windows Server 2012 R2 Hyper-V производит мониторинг сетевых интерфейсов в виртуальных машинах и в случае возникновения проблемы запускает процесс их миграции на узел, где доступна внешняя сеть.
Кворум.
Кроме динамического кворума в Windows Server 2012 R2 реализован еще и динамический диск-свидетель (witness). При изменении числа узлов его голос может быть автоматически учтен, так, чтобы общее число голосов оставалось нечетным. В случае, если сам диск окажется недоступным, его голос будет просто обнулен. Такая схема позволяет полностью положиться на автоматические механизмы, отказавшись от моделей кворума.
Увеличена надежность работы кластеров, размещенных на двух площадках. Часто при такой реализации на каждой площадке находится ровно половина узлов, поэтому нарушения коммуникации между площадками может возникнуть проблема с формированием кворума. Хотя с большинством подобных ситуаций успешно справляется механизм динамического кворума, в Windows Server 2012 R2 существует возможность назначить одной из площадок низкий приоритет, для того, чтобы в случае сбоя кластер всегда функционировал на основной площадке. В случае, если кластер был запущен с принудительным кворумом, то при восстановлении связи с удаленной площадкой службы кластера будут перезапущены в автоматическом режиме и весь кластер будет вновь объединен.
CSV 2.1
Существенные изменения коснулись и реализации CSV. Теперь роли владельцев томов равномерно распределяются по узлам в автоматическом режиме, в соответствии с изменением их числа. Увеличена отказоустойчивость CSV благодаря тому, что на каждом узле кластера запускается по два экземпляра серверной службы. Один используется для обслуживания клиентского SMB-трафика, другой обеспечивает коммуникацию между узлами. При этом обязательно производится мониторинг службы и в случае сбоя роль владельца CSV мигрирует на другой узел.
Целый ряд новшеств в CSV обеспечивает более эффективное использование SOFC и Storage Spaces. Добавлена поддержка файловой системы ReFS, которая обладает более совершенной, чем NTFS внутренней организацией. Скорее всего постепенно эта файловая система займет ведущее положение в продуктах компании Microsoft. Также в Windows Server 2012 R2 реализован механизм дедупликации, который ранее был прерогативой всецелевого файлового сервера. Активация дедупликации приводит к отключению CSV Block Cache, однако в некоторых случаях она может быть достаточно эффективной. Тома CSV могут создаваться на дисковых пространствах с контролем четности.
В Windows Server 2012 R2 возможность комбинировать накопители различных типов приобрела особый смысл с многоуровневыми пространствами. Появилась возможность формировать два уровня быстрый (на основе SSD) и емкий (на основе жестких дисках) и при создании виртуального диска выделять определенный объем из каждого из них. Далее в соответствии с некоторым расписанием содержимое виртуального диска будет анализироваться и размещаться блоками по 1 МБ на более быстрых или медленных носителях в зависимости от востребованности. Другим применением многоуровневых пространств является реализация кэша с обратной записью на SSD. В моменты пиковых нагрузок запись осуществляется на быстрые твердотельные накопители, а позже холодные данные перемещаются на более медленные жесткие диски.
Новшества, касающиеся CSV и Storage Spaces, являются наиболее существенными в Windows Server 2012 R2. На их основе можно разворачивать не просто надежные файловые серверы, а мощные и гибкие системы хранения данных с прекрасными возможностями масштабирования и отличной отказоустойчивостью, предоставляющие в распоряжение пользователя широкий спектр современных инструментов.
Как известно, кластеры позволяют решать проблемы, связанные с производительностью, балансировкой нагрузки и отказоустойчивостью. Для построения кластеров используются различные решения и технологии, как на программном, так и на аппаратном уровне. В этой статье будут рассмотрены программные решения, предлагаемые компаниями Microsoft и Oracle.
Виды кластеров
Кластер — это группа независимых компьютеров (так называемых узлов или нодов), к которой можно получить доступ как к единой системе. Кластеры могут быть предназначены для решения одной или нескольких задач. Традиционно выделяют три типа кластеров:
- Кластеры высокой готовности или отказоустойчивые кластеры (high-availability clusters или failover clusters) используют избыточные узлы для обеспечения работы в случае отказа одного из узлов.
- Кластеры балансировки нагрузки (load-balancing clusters) служат для распределения запросов от клиентов по нескольким серверам, образующим кластер.
- Вычислительные кластеры (compute clusters), как следует из названия, используются в вычислительных целях, когда задачу можно разделить на несколько подзадач, каждая из которых может выполняться на отдельном узле. Отдельно выделяют высокопроизводительные кластеры (HPC — high performance computing clusters), которые составляют около 82% систем в рейтинге суперкомпьютеров Top500.
Системы распределенных вычислений (gird) иногда относят к отдельному типу кластеров, который может состоять из территориально разнесенных серверов с отличающимися операционными системами и аппаратной конфигурацией. В случае грид-вычислений взаимодействия между узлами происходят значительно реже, чем в вычислительных кластерах. В грид-системах могут быть объединены HPC-кластеры, обычные рабочие станции и другие устройства.

Такую систему можно рассматривать как обобщение понятия «кластер». ластеры могут быть сконфигурированы в режиме работы active/active, в этом случае все узлы обрабатывают запросы пользователей и ни один из них не простаивает в режиме ожидания, как это происходит в варианте active/passive.
Oracle RAC и Network Load Balancing являются примерами active/ active кластера. Failover Cluster в Windows Server служит примером active/passive кластера. Для организации active/active кластера требуются более изощренные механизмы, которые позволяют нескольким узлам обращаться к одному ресурсу и синхронизовать изменения между всеми узлами. Для организации кластера требуется, чтобы узлы были объединены в сеть, для чего наиболее часто используется либо традиционный Ethernet, либо InfiniBand.

Программные решения могут быть довольно чувствительны к задержкам — так, например, для Oracle RAC задержки не должны превышать 15 мс. В качестве технологий хранения могут выступать Fibre Channel, iSCSI или NFS файловые сервера. Однако оставим аппаратные технологии за рамками статьи и перейдем к рассмотрению решений на уровне операционной системы (на примере Windows Server 2008 R2) и технологиям, которые позволяют организовать кластер для конкретной базы данных (OracleDatabase 11g), но на любой поддерживаемой ОС.
Windows Clustering
У Microsoft существуют решения для реализации каждого из трех типов кластеров. В состав Windows Server 2008 R2 входят две технологии: Network Load Balancing (NLB) Cluster и Failover Cluster. Существует отдельная редакция Windows Server 2008 HPC Edition для организации высокопроизводительных вычислительных сред. Эта редакция лицензируется только для запуска HPC-приложений, то есть на таком сервере нельзя запускать базы данных, web- или почтовые сервера.

NLB-кластер используется для фильтрации и распределения TCP/IPтрафика между узлами. Такой тип кластера предназначен для работы с сетевыми приложениями — например, IIS, VPN или межсетевым экраном.
Могут возникать сложности с приложениями, которые полага ются на сессионные данные, при перенаправлении клиента на другой узел, на котором этих данных нет. В NLB-кластер можно включать до тридцати двух узлов на x64-редакциях, и до шестнадцати — на x86.
Failoverclustering — это кластеризации с переходом по отказу, хотя довольно часто термин переводят как «отказоустойчивые кластеры».
Узлы кластера объединены программно и физически с помощью LAN- или WAN-сети, для multi-site кластера в Windows Server 2008 убрано требование к общей задержке 500 мс, и добавлена возможность гибко настраивать heartbeat. В случае сбоя или планового отключения сервера кластеризованные ресурсы переносятся на другой узел. В Enterprise edition в кластер можно объединять до шестнадцати узлов, при этом пятнадцать из них будут простаивать до тех пор, пока не произойдет сбой. Приложения без поддержки кластеров (cluster-unaware) не взаимодействуют со службами кластера и могут быть переключены на другой узел только в случае аппаратного сбоя.
Приложения с поддержкой кластеров (cluster-aware), разработанные с использованием ClusterAPI, могут быть защищены от программных и аппаратных сбоев.
Развертывание failover-кластера
Процедуру установки кластера можно разделить на четыре этапа. На первом этапе необходимо сконфигурировать аппаратную часть, которая должна соответствовать The Microsoft Support Policy for Windows Server 2008 Failover Clusters. Все узлы кластера должны состоять из одинаковых или сходных компонентов. Все узлы кластера должны иметь доступ к хранилищу, созданному с использованием FibreChannel, iSCSI или Serial Attached SCSI. От хранилищ, работающих с Windows Server 2008, требуется поддержка persistent reservations.
На втором этапе на каждый узел требуется добавить компонент Failover Clustering — например, через Server Manager. Эту задачу можно выполнять с использованием учетной записи, обладающей административными правами на каждом узле. Серверы должны принадлежать к одному домену. Желательно, чтобы все узлы кластера были с одинаковой ролью, причем лучше использовать роль member server, так как роль domain controller чревата возможными проблемами с DNS и Exchange.
Третий не обязательный, но желательный этап заключается в проверке конфигурации. Проверка запускается через оснастку Failover Cluster Management. Если для проверки конфигурации указан только один узел, то часть проверок будет пропущена.
На четвертом этапе создается кластер. Для этого из Failover Cluster Management запускается мастер Create Cluster, в котором указываются серверы, включаемые в кластер, имя кластера и дополнительные настройки IP-адреса. Если серверы подключены к сетям, которые не будут использоваться для общения в рамках кластера (например, подключение только для обмена данными с хранилищем), то в свойствах этой сети в Failover Cluster Management необходимо установить параметр «Do not allow the cluster to use this network».
После этого можно приступить к настройке приложения, которое требуется сконфигурировать для обеспечения его высокой доступности.
Для этого необходимо запустить High Availability Wizard, который можно найти в Services and Applications оснастки Failover Cluster Management.
Cluster Shared Volumes
В случае failover-кластера доступ к LUN, хранящему данные, может осуществлять только активный узел, который владеет этим ресурсом. При переключении на другой узел происходит размонтирование LUN и монтирование его для другого узла. В большинстве случаев эта задержка не является критичной, но при виртуализации может требоваться вообще нулевая задержка на переключение виртуальных машин с одного узла на другой.

Еще одна проблема, возникающая из-за того, что LUN является минимальной единицей обхода отказа, заключается в том, что при сбое одного приложения, находящегося на LUN, приходится переключать все приложения, которые хранятся на этом LUN, на другой сервер. Во всех приложениях (включая Hyper-V до второго релиза Server 2008) это удавалось обходить за счет многочисленных LUN, на каждом из которых хранились данные только одного приложения. В Server 2008 R2 появилось решение для этих проблем, но предназначенное для работы только с Hyper-V и CSV (Cluster Shared Volumes).
CSV позволяет размещать на общем хранилище виртуальные машины, запускаемые на разных узлах кластера — тем самым разбивается зависимость между ресурсами приложения (в данном случае виртуальными машинами) и дисковыми ресурсами. В качестве файловой системы CSV использует обычную NTFS. Для включения CSV необходимо в Failover Cluster Manage выполнить команду Enable Cluster Shared Volumes. Отключить поддержку CSV можно только через консоль:
Для использования этой команды должен быть загружен Failover Clusters, модуль PowerShell. Использование CSV совместно с live migration позволяет перемещать виртуальные машины между физическими серверами в считанные миллисекунды, без обрыва сетевых соединений и совершенно прозрачно для пользователей. Стоит отметить, что копировать любые данные (например, готовые виртуальные машины) на общие диски, использующие CSV, следует через узел-координатор.
Несмотря на то, что общий диск доступен со всех узлов кластера, перед записью данных на диск узлы запрашивают разрешение у узлакоординатора. При этом, если запись требует изменений на уровне файловой системы (например, смена атрибутов файла или увеличение его размера), то записью занимается сам узел-координатор.
Oracle RAC
Oracle Real Application Clusters (RAC) — это дополнительная опция Oracle Database, которая впервые появилась в Oracle Database 9i под названием OPS (Oracle Parallel Server). Опция предоставляет возможность нескольким экземплярам совместно обращаться к одной базе данных. Базой данных в Oracle Database называет ся совокупность файлов данных, журнальных файлов, файлов параметров и некоторых других типов файлов. Для того, чтобы пользовательские процессы могли получить доступ к этим данным, должен быть запущен экземпляр. Экземпляр (instance) в свою очередь состоит из структур памяти (SGA) и фоновых процессов. В отсутствии RAC получить доступ к базе данных может строго один экземпляр.

Опция RAC не поставляется с Enterprise Edition и приобретается отдельно. Стоит отметить, что при этом RAC идет в составе Standard Edition, но данная редакция обладает большим количеством ограничений по сравнению с Enterprise Edition, что ставит под сомнение целесообразность ее использования.
Oracle Grid Infrastructure
Для работы Oracle RAC требуется Oracle Clusterware (или стороннее ПО) для объединения серверов в кластер. Для более гибкого управления ресурсами узлы такого кластера могут быть организованы в пулы (с версии 11g R2 поддерживается два варианта управления — на основании политик для пулов или, в случае их отсутствия, администратором).
Во втором релизе 11g Oracle Clusterware был объединен с ASM под общим названием Oracle Grid Infrastructure, хотя оба компонента и продолжают устанавливаться по различным путям.
Automatic Storage Management (ASM) — менеджер томов и файловая система, которые могут работать как в кластере, так и с singleinstance базой данных. ASM разбивает файлы на ASM Allocation Unit.
Размер Allocation Unit определяется параметром AU_SIZE, который задается на уровне дисковой группы и составляет 1, 2, 4, 8, 16, 32 или 64 MB. Далее Allocation Units распределяются по ASM-дискам для балансировки нагрузки или зеркалирования. Избыточность может быть реализована, как средствами ASM, так и аппаратно.
ASM-диски могут быть объединены в Failure Group (то есть группу дисков, которые могут выйти из строя одновременно — например, диски, подсоединенные к одному контролеру), при этом зеркалирование осуществляется на диски, принадлежащие разным Failure Group. При добавлении или удалении дисков ASM автоматически осуществляет разбалансировку, скорость которой задается администратором.

На ASM могут помещаться только файлы, относящиеся к базе данных Oracle, такие как управляющие и журнальные файлы, файлы данных или резервные копии RMAN. Экземпляр базы данных не может взаимодействовать напрямую с файлами, которые размещены на ASM. Для обеспечения доступа к данным дисковая группа должна быть предварительно смонтирована локальным ASM-экземпляром.
Oracle рекомендует использовать ASM в качестве решения для управления хранением данных вместо традиционных менеджеров томов, файловых систем или RAW-устройств.
Развертывание Oracle RAC
Рассмотрим этапы установки различных компонентов, необходимых для функционирования Oracle RAC в режиме active/active кластера с двумя узлами. В качестве дистрибутива будем рассматривать последнюю на момент написания статьи версию Oracle Database 11g Release 2. В качестве операционной системы возьмем Oracle Enterprise Linux 5. Oracle Enterprise Linux — операционная система, базирующаяся на RedHat Enterprise Linux. Ее основные отличия — цена лицензии, техническая поддержка от Oracle и дополнительные пакеты, которые могут использоваться приложениями Oracle.
Подготовка ОС к установке Oracle стандартна и заключается в создании пользователей и групп, задании переменных окружения и параметров ядра. Параметры для конкретной версии ОС и БД можно найти в Installation Guide, который поставляется вместе с дистрибутивом.
На узлах должен быть настроен доступ к внешним общим дискам, на которых будут храниться файлы базы данных и файлы Oracle Clusterware. К последним относятся votingdisk (файл, определяющий участников кластера) и Oracle Cluster Registry (содержит конфигурационную информацию — например, какие экземпляры и сервисы запущены на конкретном узле). Рекомендуется создавать нечетное количество votingdisk. Для создания и настройки ASMдисков желательно использовать ASMLib, которую надо установить на всех узлах:
Кроме интерфейса для взаимодействия с хранилищем на узлах желательно настроить три сети — Interconnect, External и Backup.
Необходимо настроить IP-адресацию (вручную или с использованием Oracl e GNS) и DNS для разрешения всех имен (или только GNS).
Вначале осуществляется установка Grid Infrastructure. Для этого загружаем и распаковываем дистрибутив, затем запускаем установщик. В процессе установки необходимо указать имя кластера; указать узлы, которые будут входить в кластер; указать назначение сетевых интерфейсов; настроить хранилище.
В конце нужно выполнить с правами root скрипты orainstRoot.sh и root.sh. Первым на всех узлах выполняется скрипт orainstRoot.sh, причем запуск на следующем узле осуществляется только после завершения работы скрипта на предыдущем. После выполнения orainstRoot.sh последовательно на каждом узле выполняется root.sh. Проверить успешность установки можно с помощью команды:
/u01/grid/bin/crsctl check cluster –all
Выполнив проверку, можно приступать к установке базы данных. Для этого запускаем Oracle Universal installer, который используется и для обычной установки базы.
Кроме active/active-кластера в версии 11g R2 существуют две возможности для создания active/passive-кластера. Одна из них — Oracle RACOneNode. Другой вариант не требует лицензии для RAC и реализуется средствами Oracle Clusterware. В этом случае вначале создается общее хранилище; затем устанавливается Grid Infrastructure, с использованием ASM_CRS и SCAN; а после этого на узлы устанавливается база данных в варианте Standalone. Далее создаются ресурсы и скрипты, которые позволяют запускать экземпляр на другом узле в случае недоступности первого.
Заключение
Oracle RAC совместно с Oracle Grid Infrastructure позволяют реализовать разнообразные сценарии построения кластеров. Гибкость настройки и широта возможностей компенсируются ценой такого решения.
Решения же Microsoft ограничены не только возможностями самой кластеризации, но и продуктами, которые могут работать в такой среде. Хотя стоит отметить, что набор таких продуктов все равно шире, чем одна база данных.
В статье приводится краткий обзор создания отказоустойчивого кластера Microsoft Windows (WFC) в ОС Windows Server 2019 или 2016. В результате вы получите двухузловой кластер с одним общим диском и кластерный вычислительный ресурс (объект «компьютер» в Active Directory).

Подготовка
Не имеет значения, какие машины вы используете — физические или виртуальные, главное, чтобы технология подходила для создания кластеров Windows. Перед тем, как начать, проверьте соответствие необходимым требованиям:
Две машины Windows 2019 с установленными последними обновлениями. У них должно быть по крайней мере два сетевых интерфейса: один для производственного трафика и один для кластерного трафика. В моем примере у машин три сетевых интерфейса (один дополнительный для трафика iSCSI). Я предпочитаю статические IP-адреса, но также можно использовать DHCP.

Введите оба сервера в домен Microsoft Active Directory и убедитесь, что они видят общий ресурс хранения, доступный в Disk Management. Пока не переводите диск в режим «онлайн».
Далее необходимо добавить функциональность Failover clustering (Server Manager > Аdd roles and features).

Перезапустите сервер, если требуется. В качестве альтернативы можно использовать следующую команду PowerShell:
Install-WindowsFeature -Name Failover-Clustering –IncludeManagementTools

После успешной установки в меню Start, в Windows Administrative Tools появится Failover Cluster Manager .
После установки Failover-Clustering можно перевести общий диск в режим «онлайн» и отформатировать его на одном из серверов. Не меняйте ничего на втором сервере. Там диск остается в режиме offline.
Обновив Disk Management, вы увидите что-то типа такого:
Server 1 Disk Management (disk status online)

Server 2 Disk Management (disk status offline)

Проверка готовности отказоустойчивого кластера
Перед созданием кластера необходимо убедиться, что все настройки правильно сконфигурированы. Запустите Failover Cluster Manager из меню Start, прокрутите до раздела Management и кликните Validate Configuration.

Выберите для валидации оба сервера.

Выполните все тесты. Там же есть описание того, какие решения поддерживает Microsoft.

После успешного прохождения всех нужных тестов, можно создать кластер, установив флажок Create the cluster now using the validated nodes (создать кластер с помощью валидированных узлов), или это можно сделать позже. Если во время тестирования возникали ошибки или предупреждения, можно просмотреть подробный отчет, кликнув на View Report.

Создание отказоустойчивого кластера
Если вы решите создать кластер, кликнув на Create Cluster в Failover Cluster Manager, потребуется снова выбрать узлы кластера. Если вы используете флажок Create the cluster now using the validated nodes в мастере валидации кластера, выбирать узлы не понадобится. Следующим шагом будет создание точки доступа для администрирования кластера — Access Point for Administering the Cluster. Это будет виртуальный объект, с которым позже будут коммуницировать клиенты. Это объект «компьютер» в Active Directory.
В мастере нужно будет задать имя кластера — Cluster Name и сетевую конфигурацию.

На последнем шаге подтвердите выбранные настройки и подождите создания кластера.

По умолчанию мастер автоматически добавит общий диск к кластеру. Если вы его еще не сконфигурировали, будет возможность сделать это позже.
В результате вы увидите новый объект «компьютер» Active Directory под названием WFC2019.


В качестве альтернативы можно создать кластер с помощью PowerShell. Следующая команда автоматически добавит подходящее хранилище:
New-Cluster -Name WFC2019 -Node SRV2019-WFC1 , SRV2019-WFC2 -StaticAddress 172.21.237.32

Результат можно будет увидеть в Failover Cluster Manager, в разделах Nodes и Storage > Disks.


Иллюстрация показывает, что в данный момент диск используется в качестве кворума. Поскольку мы хотим использовать этот диск для данных, нам необходимо сконфигурировать кворум вручную. Из контекстного меню кластера выберите More Actions > Configure Cluster Quorum Settings (конфигурирование настроек кворума).

Мы хотим выбрать диск-свидетель вручную.

В данный момент кластер использует диск, ранее сконфигурированный как диск-свидетель. Альтернативно можно использовать в качестве свидетеля общую папку или учетную запись хранилища Azure. В этом примере мы используем в качестве свидетеля общую папку. На веб-сайте Microsoft представлены пошаговые инструкции по использованию свидетеля в облаке. Я всегда рекомендую конфигурировать свидетель кворума для правильной работы. Так что, последняя опция для производственной среды не актуальна.

Просто укажите путь и завершите мастер установки.

После этого общий диск можно использовать для работы с данными.

Поздравляю, вы сконфигурировали отказоустойчивый кластер Microsoft с одним общим диском.

Следующие шаги и резервное копирование
Одним из следующих шагов будет добавление роли для кластера, но это выходит за рамки данной статьи. Когда кластер будет содержать данные, пора будет подумать о его резервном копировании. Veeam Agent for Microsoft Windows может применяться для резервного копирования отказоустойчивых кластеров Windows с общими дисками. Мы также рекомендуем осуществлять резервное копирование «всей системы» кластера. При этом выполняется резервное копирование операционных систем узлов кластера. Это поможет ускорить восстановление отказавшего узла кластера, так как вам не придется искать драйверы и прочее при восстановлении.
Руководство по созданию отказоустойчивых кластеров для Windows Server 2019
В данной статье речь пойдет о подготовке и конфигурации отказоустойчивого кластера (Failover Cluster) на базе сервера Netberg Demos R420 M2. Программно-аппаратный комплекс Netberg Demos R420 M2 специально сконструирован для построения решений класса «кластер-в-коробке» (Cluster-in-a-box) на основе Microsoft Windows Server 2012.
Аналогичную процедуру можно применять и к кластерам с внешними устройствами хранения. Например для дисковых полок Aeon J424 M3 и Aeon J470 M3, используемых совместно со стандартными серверами.
Настройку разделим на 3 этапа:
- Подготовительные работы, которые будут включать подготовку дисковой подсистемы сервера для работы в кластере и настройку сети между узлами.
- Установка и настройка компоненты Failover Cluster.
- Настройка роли отказоустойчивого файлового сервера в кластере.
Перед началом настройки на все узлы рекомендуется:
- установить все доступные обновления операционной системы (обратите особое внимание на то, что на узлах должен быть установлен абсолютно одинаковый набор обновлений);
- обновить до последней версии драйверы и прошивки устройств, драйверы должны иметь подпись Microsoft;
- узлы кластера должны быть добавлены в домен Active Directory;
- иcпользуйте в одном массиве идентичные SAS-диски вплоть до версии прошивки.
Подготовка к установке кластера
Подготовка дисковой подсистемы
Каждый узел сервера имеет доступ к общему дисковому хранилищу, которое позволяет разместить до 12 дисков. Для установки операционной системы используются внутренние посадочные места для 2.5” SATA/SSD дисков.
Диски в сервере подключены одновреммено к двум узлам системы с использованием дублированной системы ввода/вывода Multipath I/O, таким образом, в диспетчере устройств будет отображаться удвоенное
количество дисков находящихся в хранилище. В нашем случае, мы установили 12 SAS-дисков, в результате чего в диспетчере устройств отображается 24. Для операционной системы установлен SSD диск.

Для настройки Multipath I/O запустите мастер установки ролей и компонентов и установите компоненту Multipath I/O.

На рабочем столе откройте ярлык MPIO. На вкладке Discover Multi-Paths установите галку Add support for SAS devices и нажмите Add. Перезагрузите сервер.

После перезагрузки в диспетчере устройств отображается 12 дисков, принадлежащих дисковому хранилищу.

Данную процедуру необходимо выполнить на двух узлах.
Инициализация дисков

Подготовка сетевых интерфейсов
В настройках интерфейса для подключения к локальной сети рекомендуется задать статические IP-адреса. Информация об IP-адресах и именах узлов кластера обязательно должна содержаться в прямой и обратной зоне DNS сервера. Убедитесь в работоспособности прямого и обратного разрешения имен. Для настройки сети между узлами кластера в Netberg Demos R420 M2 используется внутренний сетевой интерфейс Intel® I350 Gigabit Backplane Connection, в настройках которого вы можете выставить свою конфигурацию протокола TCP/IPv4. Неиспользуемые сетевые адаптеры рекомендуется поставить в состояние Disabled.

Установка и настройка компоненты Failover Cluster
После того, как были проделаны все необходимые подготовительные настройки, на узлы кластера установим компоненту Failover Cluster с помощью мастера установки ролей и компонентов.

Проверка конфигурации узлов кластера
Прежде чем приступить к настройке кластера необходимо выполнить проверку конфигурации узлов кластера. Для этого в Failover Cluster Manager запустим мастер проверки конфигурации (Validate a Configuration Wizard).

Для корректной работы кластера важно успешное прохождение всех тестов.
На шаге Select Servers or a Cluster укажите имена узлов кластера, которые, как было сказано выше, должны являться членами домена Active Directory.

На шаге Testing Options выберем прохождение всех тестов(Run all tests).

По завершении работы Validate a Configuration Wizard откроется окно с результатами проверки. Нажав View Report можно ознакомиться с детальной информацией о пройденных тестах.

Установка кластера
Теперь можно приступить к установке кластера. Для этого в Failover Cluster Manager запустим Create Cluster Wizard.
На шаге Select Servers укажите имена узлов кластера.

На следующем шаге введите имя кластера и его IP- адрес.

На шаге Confirmation снимем галку Add all eligible storage to the cluster. Диски настроим позже с использованием новой компоненты Storage Spaces, которая стала доступна в Windows 2012.

По завершении работы мастера можно ознакомиться с подробным отчетом о результатах.

В результате работы мастера будет создан объект Active Directory с именем CLUSTER1. Объект будет располагаться в том же контейнере, где и узлы кластера, в нашем случае в контейнере Experiment.

Далее необходимо дать разрешение на создание объектов в контейнере Experiment для компьютера CLUSTER1. Это будет необходимо для успешного добавления роли кластера.

Настройка дисков для кластера
Приступим к настройке общего дискового ресурса для узлов кластера с использованием компоненты Storage Spaces. Подробно о настройке Storage Spaces.
Как видно следующем на рисунке, было добавлено 2 виртуальных диска quorum и file-storage.

Диск quorum настроим в качестве диска кворума для кластера, диск file-storage – для хранения данных.
Добавим вновь созданные диски в кластер. Для этого в Failover Cluster Manager в правой панели правой кнопкой мыши выберите Disks и нажмите Add Disk.

Для настройки диска кворума в Failover Cluster Manager нажмите правой кнопкой на имени кластера и выберете меню More Actions – Configure Cluster Quorum Settings.

Далее запуститься мастер настройки диска кворума.
На шаге Select Quorum Configuration Option используем рекомендуемые параметры.

На шаге Confirmation подтверждаем конфигурацию.

На последнем шаге можно ознакомиться с детальным отчетом.

Настройка роли отказоустойчивого файлового сервера в кластере
Добавим роль файлового сервера для кластера. В Failover Cluster Manager нажмите правой кнопкой на имени кластера и выберите пункт Configure Role.
На шаге Select Role выберем File Server.

На следующем шаге предлагается выбрать тип файлового сервера. Выберем File Server for general use.

На шаге Client Access Point необходимо ввести имя и IP-адрес для доступа клиентов к файловому серверу.

Далее выберем диск для данных файлового сервера. В нашем случае доступен Cluster Disk 2.


На последнем шаге можно ознакомиться с детальным отчетом.

В результате работы мастера будет создан объект Active Directory с именем FILESTORAGE. Объект будет располагаться в том же контейнере, где и узлы кластера, а также созданный ранее объект CLUSTER1. Как было описано выше, объект CLUSTER1 должен иметь права на создание объектов в контейнере, иначе объект FILESTORAGE создан не будет.

В консоли Failover Cluster Manager можно убедиться, что роль успешно добавлена и функционирует.
Читайте также: