
Бд oracle что это
Обновлено: 03.07.2024
История выпуска версий для различных операционных платформ
История выпуска для Linux x86
сентябрь 1998 года — 8.0 (8.0.5) 23 февраля 1999 года — 8.0 (8.0.5.1.0) 22 ноября 2000 года — 8i Release 3 (8.1.7.0.1) 25 марта 2003 года — 9i Release 2 (9.2.0.4) 21 декабря 2004 года — 10g Release 1 (10.1.0.3) 2 июля 2005 года — 10g Release 2 (10.2.0.1) 10 августа 2007 года — 11g Release 1 (11.1.0.6) 1 сентября 2009 года — 11g Release 2 (11.2.0.1)
История выпуска для Linux x86-64
16 октября 2007 года — 11g Release 1 (11.1.0.6) 1 сентября 2009 года — 11g Release 2 (11.2.0.1) 26 июня 2013 года — 12c (12.1.0.1)
История выпуска для Solaris x86
14 мая 1999 года — 8i Release 1 (8.1.5) для Intel UNIX (DG/UX Intel, SCO UnixWare, Solaris Intel)
История выпуска для Solaris x86-64
23 марта 2006 года — 10g Release 2 (10.2.0.1) 25 ноября 2009 года — 11g Release 2 (11.2.0.1) 26 июня 2013 года — 12c (12.1.0.1)
История выпуска для Solaris SPARC 64-bit
6 ноября 2009 года — 11g Release 2 (11.2.0.1) 26 июня 2013 года — 12c (12.1.0.1)
История выпуска для Windows x86
март 1997 года — 7 (7.3.3) для Windows NT 3.51/4.0 октябрь 1997 года — 7 (7.3.4) для Windows NT 3.51/4.0 1 июля 1998 года — 8.0 (8.0.5) для Windows NT 10 марта 1999 года — 8i Release 1 (8.1.5) для Windows NT и Windows 95/98 20 сентября 1999 года — 8.0 (8.0.6) для Windows NT январь 2000 года — 8i Release 2 (8.1.6) для Windows NT 16 ноября 2000 года — 8i Release 3 (8.1.7) для Windows NT 13 сентября 2001 года — 9i Release 1 (9.0.1.0) для Windows 32-bit 14 мая 2002 года — 9i Release 2 (9.2.0.1) для Windows 32-bit 26 марта 2004 года — 10g Release 1 (10.1.0.2) для Windows 32-bit 7 сентября 2005 года — 10g Release 2 (10.2.0.1) для Windows 32-bit 15 октября 2007 года — 11g Release 1 (11.1.0.6) для Windows 32-bit 5 апреля 2010 года — 11g Release 2 (11.2.0.1) для Windows 32-bit
История выпуска для Windows x86-64
31 октября 2005 года — 10g Release 2 (10.2.0.1) 7 ноября 2007 года — 11g Release 1 (11.1.0.6) 2 апреля 2010 года — 11g Release 2 (11.2.0.1) 1 августа 2013 года — 12c Release 1 (12.1.0.1) 8 марта 2017 года — 12c Release 2 (12.2.0.1)
Программно-аппаратные платформы
До выпуска Oracle9i корпорация Oracle портировала движок базы данных на многие платформы, но в последнее время Oracle портирует на меньшее количество платформ. К примеру Oracle RDBMS 10g с июня 2005 года поддерживаются следующие программно-аппаратные платформы:
- Linux x86
- Linux x86-64
- Linux на zSeries
- Linux Itanium
- Linux на POWER
- Microsoft Windows (32-бит)
- Windows NT (x64)
- Windows NT (64-бит Itanium)
- Solaris x86
- Solaris AMD64/EM64T
- Solaris SPARC (64-бит)
- AIX5L
- HP-UX PA-RISC
- HP-UX Itanium
- HP Tru64 UNIX
- HP OpenVMS Alpha
- IBM z/OS
- Mac OS X Server
Редакции
СУБД поставляется в шести различных редакциях, ориентированных на различные сценарии разработки и развертывания приложений (а также отличающиеся ценой).
| Название | Ограничения | Операционные платформы |
|---|---|---|
| Enterprise Edition | ||
| Standard Edition | не может устанавливаться на системы, имеющие более 4 процессорных разъёмов | |
| Standard Edition One | не может устанавливаться на системы, имеющие более 2 процессорных разъёмов; не поддерживает кластеризацию (RAC) | |
| Personal Edition | один пользователь | |
| Lite | для мобильных и встраиваемых устройств | |
| Express Edition (XE) | бесплатная редакция; используемая оперативная память — 1 ГБ, а также используется только 1 процессор, максимальный объём базы данных — 11 ГБ (для 10g — 4ГБ), из них от 0,5 до 0,9 ГБ используются словарём данных, внутренними схемами и временным дисковым пространством | Windows x86-64 Linux x86-64 |
Особенности
- MVCC (англ. MultiVersion Concurrency Control) — многоверсионность данных для управления параллельными транзакциями.
- Секционирование.
- Автономные транзакции.
- Automatic Storage Management — автоматическое управление хранением файлов БД.
- Oracle Enterprise Manager — набор инструментов, предназначенных для управления и мониторинга СУБД Oracle и серверов, на которых они установлены.
- Пакеты. [2]
- Поддержка последовательностей.
- Аналитические функции в SQL.
- Profile manager.
- Oracle Label Security.
- Streams.
- Advanced Queuing.
- Flashback Query.
- RAC (англ. Real Application Clusters).
- RAT (Real Application Testing) — позволяет значительно снизить затраты на испытание новой конфигурации программного или аппаратного обеспечения, так как способна точно воспроизвести на ней нагрузку рабочего сервера.
- Data Guard — технология, позволяющая создать резервный сервер, который может работать в паре с основным, снижая нагрузку на него, и который может автоматически заменить основной сервер в случае его отказа или планового отключения (есть вариант с постоянной доступностью резервного сервера для чтения — Active Data Guard).
- Total Recall — даёт возможность разгрузить базу данных от устаревшей, редко используемой информации, сохраняя при этом возможность доступа к ней, так что для пользователя базы данных это изменение остаётся незамеченным.
- Объектные типы (в смысле объектно-ориентированного подхода).
- Automatic Database Diagnostic Monitoring — автоматический мониторинг и диагностика баз для выявления проблем производительности и, возможно, автоматической корректировки (если таковая определена администратором).
- Подсказки для изменения плана выполнения запроса.
Пример работы с БД
Создание представления базы данных в Oracle с помощью SQL
Уровень сложности: Начальный
Требования к данным: Используйте собственные данные
Для отображения таблиц и классов пространственных объектов многопользовательской базы геоданных можно использовать SQL.
Приведенные в настоящей теме примеры показывают, как создать в Oracle простое представление для просмотра с ограничением доступа пользователей к другим столбцам. Этот пример построен на базе таблицы со следующим определением:
Предоставление прав доступа к таблице
Если создающий представление пользователь не является владельцем таблицы или таблиц в этом представлении, владелец таблиц должен предоставить создателю как минимум права доступа Select. Для предоставления прав доступа к представлению для других пользователей владелец представления должен получить соответствующие права доступа от владельца таблицы.
В данном примере таблица, на базе которой построено представление (employees), принадлежит пользователю gdb. Представление создается пользователем rocket. Также пользователь rocket предоставляет права доступа к представлению другим пользователям. Таким образом, пользователь gdb должен передать пользователю rocket права доступа SELECT и WITH GRANT OPTION, чтобы пользователь rocket мог передавать другим пользователям права доступа SELECT.
Создание представления
В этом примере пользователь rocket создает представление таблицы employees и ограничивает доступ к нему только пользователям из отдела 201:
Выдача прав доступа к представлению
Права доступа к представлению можно предоставлять определенным пользователям, не передавая им права доступа к базовой таблице (employees). В данном примере пользователю mgr200 предоставлены права доступа SELECT к представлению view_dept_201:
Тестовые права доступа
Войдите в систему как mgr200 и выберите записи view_dept_201:
Как ожидалось, выводятся только записи для сотрудников отдела 201.
Основные команды
Войдите в систему SQL * Plus
Выполнять команды хоста
Показать системные переменные SQL * Plus или настройки среды
Изменение системных переменных SQL * Plus или настроек среды
Запуск базы данных
Подключение к базе данных
Редактировать содержимое SQL-буфера или файла
Выполнять команды, хранящиеся в буфере SQL
Отключиться от базы данных
Проверить статус листенера
Зайти под администратором
Стартовать БД на standby
Посмотреть список датафайлов в табличном пространстве
Добавить к табличному пространству файл данных размером
Посмотреть список пользователей
Запустить накат архивных логов на standby
Остановить накат архивных логов на standby
Зарегистрировать архивный лог на standby
Установка
Установка Oracle Database 12c на Windows 10 Professional 64 bit: [Источник 2]
Oracle Database — это объектно-реляционная СУБД (система управления базами данных), созданная компанией Oracle. В настоящее время она имеет множество разных версий и типов. Однако в этой статье мы поговорим не о видах баз данных Oracle, а о структуре и основных концепциях, которые относятся к СУБД Oracle Database. Поняв архитектуру СУБД Oracle, вы заложите фундамент, необходимый для понимания прочих средств (а они весьма обширны), предоставляемых базой данных Oracle.
Базы данных Oracle: экземпляры и сущности
СУБД Oracle Database включает в себя физические и логические компоненты. Особого упоминания заслуживает понятие экземпляра. Замечено, что некоторые используют термины «база данных» и «экземпляр» в качестве синонимов. Да, это взаимосвязанные, но всё же разные вещи. База данных в терминологии Oracle — это физическое хранилище информации, а экземпляр — это программное обеспечение, которое работает на сервере и предоставляет доступ к информации, содержащейся в базе данных Oracle. Экземпляр исполняется на конкретном сервере либо компьютере, в то самое время как база данных хранится на дисках, подключённых к этому серверу:
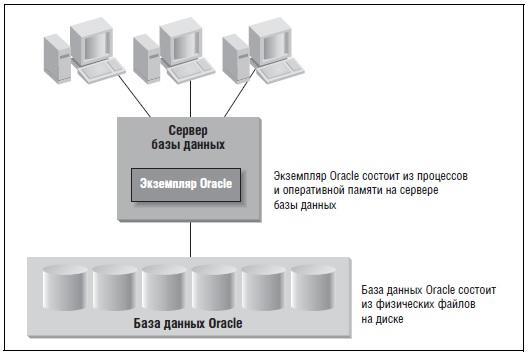
При этом база данных Oracle является физической сущностью, состоящей из файлов, которые хранятся на дисках. В то же самое время, экземпляр – это сущность логическая, состоящая из структур в оперативной памяти и процессов, которые работают на сервере. Экземпляр может являться частью только одной базы данных. При этом с одной базой данных бывает ассоциировано несколько экземпляров. Экземпляр ограничен по времени жизни, тогда как БД, условно говоря, может существовать вечно.
Также стоит заметить, что у пользователей нет прямого доступа к информации, которая хранится в базе данных Oracle — они должны запрашивать эту информацию у экземпляра Oracle.
Если упрощённо, то экземпляр — это мост к базе данных, а сама БД – это остров. Когда экземпляр запущен, мост работает, а данные способны попадать в базу данных Oracle и покидать её. Если мост перекрыт (экземпляр остановлен), пользователи не могут обращаться к базе данных, несмотря на то, что физически она никуда не исчезла.
Структура базы данных Oracle
База данных Oracle включает в себя: — табличные пространства; — управляющие файлы; — журналы; — архивные журналы; — файлы трассировки изменения блоков; — ретроспективные журналы; — файлы резервных копий (RMAN).
Табличные пространства Oracle
Любые данные, которые хранятся в базе данных Oracle, просто обязаны существовать в каком-либо табличном пространстве. Под табличным пространством (tablespace) понимают логическую структуру, то есть вы не сможете попросить ОС показать вам табличное пространство Oracle.
При этом каждое табличное пространство включает в себя физические структуры, называемые файлами данных (data files). Одно табличное пространство Oracle способно содержать один либо несколько файлов данных, в то время как каждый файл данных может принадлежать лишь одному tablespace. Создавая таблицу, мы можем указать, в какое именно табличное пространство мы её поместим — Oracle находит для неё место в каком-нибудь из файлов данных, которые составляют указанное табличное пространство.
На рисунке ниже вы можете посмотреть на соотношение между файлами данных и табличными пространствами в базе данных Oracle.
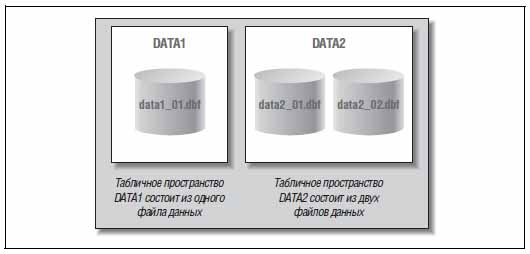
Создавая новую таблицу, мы можем поместить её в табличное пространство DATA1 либо DATA2. Таким образом, физически наша таблица окажется в одном из файлов данных, которые составляют указанное табличное пространство.
Файлы базы данных Oracle
База данных Oracle может включать в себя физические файлы 3-х основных типов: • control files — управляющие файлы; • data files — файлы данных; • redo log files — журнальные файлы либо журналы.
Посмотрим на отношения между ними:
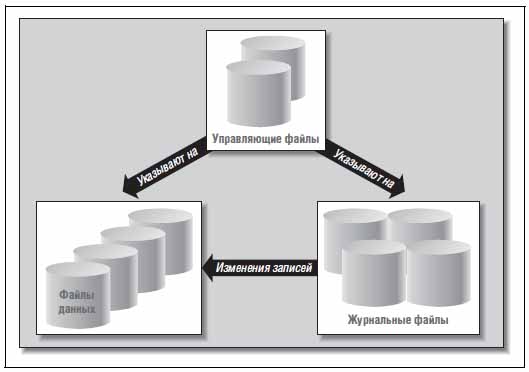
В управляющих файлах содержится информация о местонахождении других физических файлов, которые составляют базу данных Oracle, — речь идёт о файлах данных и журналов. Также там хранится важная информация о содержимом и состоянии БД Oracle. Что это за информация: • имя базы данных Oracle; • время создания БД; • имена и местонахождение журнальных файлов и файлов данных; • информация о табличных пространствах; • информация об архивных журналах; • история журналов, порядковый номер текущего журнала; • информация о файлах данных в автономном режиме; • информация о резервных копиях, контрольных точках, копиях файлов данных.
При этом функция управляющих файлов не ограничивается хранением важной информации, нужной при запуске экземпляра, — полезны они и в процессе удалении БД Oracle. К примеру, уже с версии Oracle Database 10g можно посредством команды DROP DATABASE удалить все файлы, которые перечислены в управляющем файле БД, включая сам управляющий файл.
Инициализация СУБД Oracle
Когда вы запускаете экземпляр Oracle, происходит считывание параметров инициализации. Параметры определяют, каким образом базе данных Oracle следует использовать физическую инфраструктуру и прочую конфигурационную информацию об экземпляре.
Как правило, инициализационные параметры хранятся в файле параметров инициализации экземпляра (обычно это INIT.ORA) либо, начиная с Oracle9i, в репозитории, называемом файлом параметров сервера (SPFILE). С выходом каждой новой версии Oracle число обязательных параметров инициализации уменьшается.
Кстати, в дистрибутиве Oracle можно найти пример файла инициализации, который пригоден для запуска базы данных. Также можно воспользоваться специальной программой Database Configuration Assistant (DCA) — она подскажет обязательные значения.
Более подробную информацию смотрите в официальной документации для СУБД Oracle Database.
Когда вы меняете данные в БД, то ваши изменения сначала идут в кэш, а потом асинхронно в нескольких потоках (число можно сконфигурировать) пишутся на диск. Синхронно же пишется специальных лог (оперативный журнальный файл), чтобы была возможность восстановить данные после сбоя, если они еще не успели с кэша сброситься на диск. Данный подход позволяет выиграть в скорости, так как в этом случае на диск все пишется последовательно в один файл, причем можно настроить так, чтобы писалось параллельно на два или больше дисков, тем самым увеличивая надежность защиты от потери изменений. Описанных файлов должно быть несколько, и они используются по кругу: как только все данные защищенные одним из лог файлов были записаны фоновым процессом в блоки данных на диск, то данный лог файл может быть переиспользован. Таким образом в какой-то мере это позволяет еще и сэкономить, имея ультрабыстрые диски небольшого размера только для небольших журнальных файлов используемых по кругу.
Обычно я рассказываю об этом, когда мне предлагают что-то сохранять просто в файл на диске, так как это будет «быстрее» за счет того, что мы будет писать все данные последовательно и головке жесткого диска не надо будет бегать и искать рэндомные блоки. Я все же настаиваю, что мы тут ничего не выиграем, так как будем писать на медленный диск, который скоро всего активно используется множеством других процессов для записи огромного количества различных логов, а Oracle синхронно тоже пишет у себя на диск только последовательно, как я описал выше.
Механизм восстановления данных
В СУБД Oracle можно включить архивацию вышеописанных оперативных журнальных файлов, и все изменения будут архивироваться. Таким образом при потере любого диска с блоками данных мы можем восстановить их на любой момент времени, включая момент прямо перед падением, накатив на последние архивные журнальные файлы текущий оперативный журнал.
Stand by копия
Вышеупомянутые архивные файлы можно отправлять по сети и на лету применять к копии БД. Таким образом у вас всегда под рукой будет горячая копия с минимальным запаздыванием данных. В некоторых приложениях, где нет необходимости показывать данные с точностью до последнего момента, можно настроить такую БД только на чтение и разгрузить основной экземпляр БД, причем таких экземпляров на чтение может быть несколько.
Подвисание некоторых запросов на запись
При зависании некоторых ваших запросов в произвольный момент времени стоит заглянуть в alert.log на предмет наличия incomplete checkpoint. Это говорит о том, что ваши оперативные журнальные файлы слишком большие или их слишком мало, таким образом, защищаемые ими данные не успевают сбрасываться из кэша на диск, а СУБД заполнила уже все доступные оперативные журнальные файлы и хочет использовать их по кругу повторно, чего делать ни в коем случае нельзя, вот и появляется пауза. Хотя если ваше приложение работает на java, то в первую очередь я бы загляну на наличия Full GC в логах.
Неблокирующее чтение и сегмент отката
Одной из наиболее замечательных особенностей СУБД Oracle является неблокирующее чтение, которое достигается за счет сегмента отката. Запросы к Oracle на чтение никогда не блокируются, так как данные почти всегда могут быть прочитаны из сегмента отката.
Сегмент отката дает еще одну плюшку: из него можно попытаться считать немного устаревшие данные для какой-нибудь таблицы, которые были в ней на определенный момент. Называется данная фича — flashback.
Однако иногда сегмент отката может подложить свинью: если у вас есть большой job для bulk удаления данных (удаление генерирует всех больше данных в сегменте отката), то вы можете получить ORA-01555: snapshot too old. Главное что в этом случае надо помнить — это то, что не надо переписывать ваш job, чтобы он коммитил через каждые N операций, а нужно использовать отдельный специально созданный сегмент отката для таких операций.
Уровни изоляции транзакций
В Oracle вообще нет уровня изоляции READ_UNCOMMITED. Дело в том, что в других базах данных он используется для достижения максимального параллелизма путем удаления блокировок чтения. Но в Oracle чтение и так всегда выполняется без блокировок, таким образом мы уже имеем все преимущества, которые может дать этот уровень, не вводя никаких дополнительных ограничений.
Вообще, в Oracle явно доступно всего два уровня изоляции: по умолчанию используется READ_COMMITTED, но при желании вы можете установить SERIALIZABLE.
Однако на уровне операторов (SELECT, UPDATE и т.д.) у вас по умолчанию уже есть REPEATABLE_READ, т.е. в рамках одного оператора вы всегда получаете согласованное чтение, что достигается конечно же за счет сегмента отката. Мне всегда очень нравился пример приводимый Томом Кайтом для описания того, что это дает. Допустим у вас есть очень большая таблица со счетами и вы выполняете SELECT на получение суммы. В Oracle, в отличие от многих других БД, даже если в середине вашего запроса другая транзакция переведет некоторую суммы с первого счета на последний, вы в итоге все равно получите данные актуальные на начало вашего запроса, так как дойдя до последний строчки ваш SELECT увидит, что строчка была изменена, пойдет в сегмент отката и прочитает данные, которые были в этой ячейке на момент начала выполнения запроса. Во многих других базах данных, вы получите ответ в виде суммы, никогда не существующей в вашей таблице. Однако в Oracle в данном случае есть опасность получить ORA-01555: snapshot too old.
В дополнение к стандартным уровням изоляции в Oracle еще есть так называемые READ_ONLY транзакции, которые дают REPEATABLE_READ в рамках всей транзакции, а не только в рамках одного оператора. Но как следует из названия, в такой транзакции вы можете выполнять только чтение.
Позвольте Oracle кэшировать ваши данные эффективно
В Oracle все данные читаются-пишутся не прямо на диск, а через кэш. По умолчанию кэш основан на LRU алгоритме, так что если вы читаете какую-нибудь очень большую табличку по идентификатору в больших количествах, запрашивая в каждый раз новую строчку, то такие запросы могут вытеснять из кэша небольшую статическую табличку, которой бы самое милое дело постоянно находиться в кэше. Для таких целей при создании таблицы вы можете указать специальный вид кэша, куда будут ходить запросы к вашим таблицам. Так для первой таблицы в вышеописанном примере подойдет кэш RECYCLE, который по сути не хранит никакие данные, а сразу их выбрасывает из кэша. А для второй таблицы подойдет кэш KEEP, который позволить хранить в кэше небольшие статические таблице и запросы ко всем остальным таблицам не будут вытеснять данные статических таблиц из кэша.
Пустые строки
В оракл есть одна очень интересная особенность, от которой они теперь уже никогда не смогут избавиться. Дело в том, что если вы кладете в БД пустую строку, то она сохраниться как NULL. Таким образом при последующем чтении вы никогда не получите пустой строки, а только NULL. Имейте так же в виду, что по этой же причине пустые строки не попадают в индекс, так что если вы будете делать запросы, план выполнения которых, будет использовать индекс, то ваше пустые (вернее NULL) строки вы никогда не получите, но об этом чуть позже.
Индексы
Кроме всем известных индексов в виде B-деревьев в Oracle еще есть так называемые битовые индексы, которые показывают очень высокую производительность на запросах к таблицам в которых есть колонки с очень разреженными значениями. Особенно эффективно в этом случае будут работать запросы (по сравнению с обычными индексами) в которых присутствуют сложные комбинации OR и AND к разряженным столбцам. Данный индекс храниться не в B-дереве, а в битовых картах, что и дает возможность быстрого выполнения описанных запросов. Вопрос в количестве уникальных значений в таблице при которых данный индекс еще будет более предпочтителен весьма сложен: это может быть как 10 уникальных значений, так и 10 000. Здесь надо создавать индекс на конкретной таблице и смотреть что получается. Главное не пытайтесь использовать данный индекс на таблицах с большим количеством вставок и обновлений индексируемой колонки, так как такие операции будут блокировать довольно большие участки в индексируемой таблице и ваша система может встать колом или даже поймаете deadlock.
Одна из вещей, которая меня всегда очень радовала в Oracle — это возможность создания индекса по функции. Т.е. если вам в запросах приходиться использовать какую-нибудь функцию, то вы можете построить по ней индекс и значительно ускорить операции чтения.
Еще одно интересное свойство индексов, о котором необходимо знать, это то, что в индексе не хранятся значения NULL. Таким образом если вы будете делать запросы с условием <, > или <> по индексируемой колонке, то в ответ строчек со значением NULL в индексируемой колонке вы обратно не получите. С другой стороны данное свойство можно очень эффективно использовать дня некоторых специфичных случаев. Например, у вас есть очень большая табличка в которой хранятся ордера, которая никогда не чистится. И существует фоновый процесс, который обязан все ордера отсылать в какую-нибудь backoffice систему. Первое решение, которое напрашивается — это завести еще одну колонку с флагом is_sent, где изначально стоит 0 и при отсылке мы будем проставлять 1. Т.е. фоновый процесс при каждом запуске будет делать запрос к таблице с условием is_sent=0. Битовый индекс вы здесь использовать не можете, так как табличка очень активно пополняется. Обычный индекс на основе В-дерева будет занимать очень много места, так как нужно хранить ссылки на огромное количество строчек. Но если мы слегка поменяем нашу логику и в качестве пометки отсылки, и в колонку is_sent будем класть NULL вместо 1, то индекс у нас будет крошечный, так как в любой момент в нем будут храниться только не NULL значения, а их будет очень мало.
Таблицы бывают разные
Кроме обычных таблиц в oracle как и во многих других БД есть так называемые индекс-таблицы, когда данные таблицы непосредственно лежат в индекс-дереве первичного ключа. Таким образом достигается сразу две вещи: во первых для чтения данных по первичному ключу вы имеете на одно чтение меньше, во вторых данные в таблице получаются упорядоченными по первичному ключу, так что операция ORDER BY PK будет выполняться без дополнительной сортировки. К недостаткам можно отнести тот факт, что отличить логирование в оперативные журнальные файлы данного индекса вы уже не сможете.
Еще один замечательный тип таблиц — это кластерные таблицы, которые позволяют хранить данные из двух или более таблиц кластеризованные по одному значению ключа в одном блоке данных. Это может быть весьма эффективно если вы всегда используете какие-нибудь таблицы совместно.
На основе кластерных таблиц есть еще кластерные хэш-таблицы, в которых для доступа вместо B-дерева используется таблица на основе хеша кластерного ключа. Звучит, конечно, очень интересно, но, честно говоря, на практике никогда не сталкивался.
Связывание переменных
Наверное об этом уже наслышан каждый программист, но я все же упомяну о такой обязательной техники, как связывание переменных. Дело в том, что для каждого уникального запроса строится план разбора и кладется в кэш. Если различных запросов очень много, как, например, весьма распространенный запрос по ID, то на каждый запрос буден генериться свой план, к тому же они будут вытеснять из кэша все другие планы, что может в разы увеличить время отклика вашей базы данных.
Стоит так же заметить, что не стоит этим злоупотреблять и использовать связывание для столбцов с небольшим количеством различных значений, как-то флаг is_deleted, ведь различных запросов в этом случае будет не так много, а, возможно, для более конкретного запроса СУБД удастся построить более эффективный план.
Еще пара заметок для программиста
Если у вас колонка имеет тип VARCHAR2(100), то попытка туда запихнуть строку longString.substring(0, 100) не факт, что увенчается успехом, так как ограничение 100 в определении колонки по умолчанию относится к количеству байтов, а не символов, поэтому при наличии двухбайтовых символов вы можете попасть впросак. На самом деле данное поведение можно немного сконфигурировать, подробнее можно почитать тут. Хорошо если вы еще не пытаетесь выполнить вставку в бесконечном цикле, по принципу делать пока не получиться, ведь это «получиться» в данном случае никогда не наступит.
Ну и общая рекомендация для всех типов БД: никогда не делайте update всех колонок в таблице при изменении одного поля объекта. Кажется весьма очевидным, но как показывает практика, данный антипаттерн часто имеет место быть, поэтому я настоятельно рекомендую проверить, что ваши фреймворки делают UPDATE только действительно измененных полей.

Данная статья - это обзор концепций и структур, относящихся к ядру СУБД Oracle Database. Разобравшись в архитектуре сервера Oracle, вы заложите фундамент для понимания остальных обширных средств, предоставляемых базой данных Oracle. СУБД Oracle Database состоит из физических и логических компонентов.
Базы данных и экземпляры Oracle
Многие пользователи Oracle Database употребляют термины экземпляр и база данных как синонимы. На самом деле это разные (хотя и взаимосвязанные) вещи. Различие существенно, так как проливает свет на архитектуру Oracle.
В Oracle термином база данных описывается физическое хранилище информации, а термином экземпляр – программное обеспечение, работающее на сервере и предоставляющее доступ к информации в базе данных Oracle Database. Экземпляр исполняется на конкретном компьютере или сервере; база данных хранится на дисках, подключенных к этому серверу. Эта взаимосвязь изображена на рисунке 1 ниже:
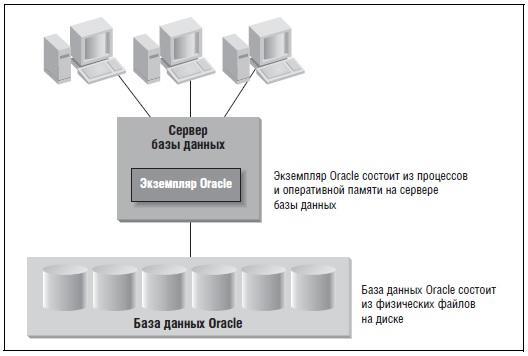
Рис. 1. Экземпляр и база данных
База данных Oracle Database – физическая сущность: она состоит из файлов, хранящихся на дисках. Экземпляр – сущность логическая: он состоит из структур в оперативной памяти и процессов, работающих на сервере.
Например, Oracle использует область разделяемой памяти System Global Area (SGA, системная глобальная область) и области памяти в каждом процессе – Program Global Area (PGA, программная глобальная область). Экземпляр может быть частью одной и только одной базы данных. Напротив, с одной базой данных может быть ассоциировано несколько экземпляров. Время жизни экземпляров ограничено, тогда как база данных при должном обслуживании может существовать вечно.
Пользователи не имеют прямого доступа к информации, хранящейся в базе данных Oracle; они должны запрашивать информацию у экземпляра Oracle.
В реальном мире есть хорошая аналогия экземплярам и базам данных. Можно считать экземпляр мостом к базе данных, а саму ее – островом. Транспорт попадает на остров и уходит с него по мосту. Если мост перекрыт, то остров на месте, но транспорту туда не попасть. В терминологии Oracle, если экземпляр запущен, то данные могут попадать в базу и уходить из нее. Физическое состояние базы данных при этом изменяется. Если же экземпляр остановлен, то пользователи не могут обращаться к базе данных, пусть даже физически она никуда не делась. База данных в этом случае статична, никаких изменений в ней не происходит. Экземпляр снова запущен – и данные тут как тут.
Структура базы данных Oracle Database
База данных состоит из табличных пространств, управляющих файлов, журналов, архивных журналов, файлов трассировки изменения блоков, ретроспективных журналов и файлов резервных копий (RMAN). В этом разделе мы познакомимся со многими из этих структур, а также с другими компонентами, составляющими в совокупности базу данных.
Табличные пространства
Любые данные, хранящиеся в базе Oracle, должны находиться в каком-то табличном пространстве. Табличное пространство (tablespace) – это логическая структура; нельзя попросить операционную систему показать вам табличное пространство. Каждое табличное пространство состоит из физических структур, называемых файлами данных (data files). В одном табличном пространстве может быть один или несколько файлов данных, тогда как каждый файл данных принадлежит ровно одному табличному пространству. При создании таблицы можно указать, в какое табличное пространство ее поместить. Тогда Oracle найдет для нее место в одном из файлов данных, составляющих указанное табличное пространство.
На рисунке 2 показано соотношение между табличными пространствами и файлами данных. Здесь мы видим два табличных пространства в базе данных Oracle.
При создании новой таблицы ее можно поместить в табличное пространство DATA1 или DATA2. Физически таблица окажется в одном из файлов данных, составляющих указанное табличное пространство.
Начиная с версии Oracle Database 10g Release 2 для всех типов таблиц по умолчанию подразумеваются локально управляемые табличные пространства. В таком табличном пространстве можно создавать большие файлы, то есть при работе в 64-разрядных системах задействуется возможность создавать сверхбольшие файлы.
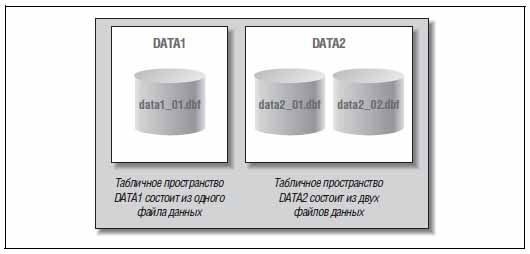
Рис. 2. Табличные пространства и файлы данных Oracle
В Oracle9i появился механизм файлов, управляемых Oracle (Oracle Managed Files, OMF), позволяющий автоматически создавать, именовать и, если понадобится, удалять все файлы, составляющие базу данных. OMF упрощает обслуживание базы данных, поскольку не нужно помнить имена всех составляющих ее файлов. К тому же не возникают проблемы из-за ошибок человека, ответственного за именование файлов. Начиная с версии Oracle Database 10g сочетание OMF и табличных пространств с большими файлами делает работу с файлами данных совершенно прозрачной.
Максимальное количество файлов данных в базе Oracle - 64 000. Поскольку табличное пространство с большими файлами может содержать файл, который в 1024 раза больше файла в табличном пространстве с малыми файлами, а размер блока в табличном пространстве с большими файлами для 64-разрядных операционных систем составляет 32 Кбайт, общий размер базы данных Oracle может достигать 8 экзабайт (1 экзабайт = 1 000 000 терабайт) . Табличные пространства с большими файлами предназначены для использования совместно с подсистемой автоматического управления хранением Automatic Storage Management (ASM), иными менеджерами логических томов, поддерживающими расслоение, и RAID-массивами .
Файлы базы данных Oracle
База данных Oracle состоит из физических файлов трех основных типов:
- управляющие файлы (control files);
- файлы данных (datafiles);
- журнальные файлы, или журналы (redo log files).
На рис. 3 показаны эти три типа файлов и отношения между ними.
В управляющем файле хранится информация о местонахождении других физических файлов, составляющих базу данных, - файлов данных и журналов. Там же хранится важнейшая информация о содержимом и состоянии базы данных:
- имя базы данных;
- время создания базы данных;
- имена и местонахождение файлов данных и журнальных файлов;
- информация о табличных пространствах;
- информация о файлах данных в автономном режиме;
- история журналов и информация о порядковом номере текущего журнала;
- информация об архивных журналах;
- информация о наборах и фрагментах резервных копий, файлах данных и журналах;
- информация о копиях файлов данных;
- информация о контрольных точках.
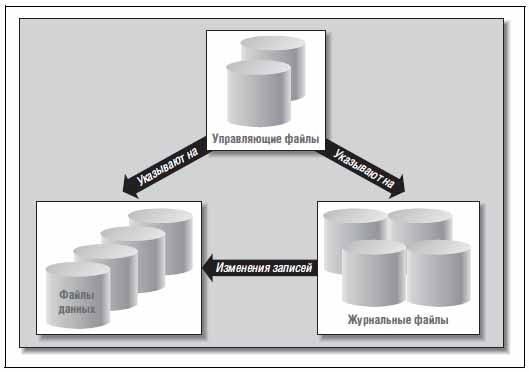
Рис. 3. Файлы, составляющие базу данных
Управляющие файлы не только содержат важную информацию, необходимую при запуске экземпляра, они полезны и при удалении базы данных. Начиная с версии Oracle Database 10g с помощью команды DROP DATABASE можно удалить все файлы, перечисленные в управляющем файле базы данных, а также сам управляющий файл.
Инициализация базы данных
При запуске экземпляра Oracle считываются параметры инициализации. Они определяют, как база данных должна использовать физическую инфраструктуру и иную конфигурационную информацию об экземпляре. Параметры инициализации хранятся в файле параметров инициализации экземпляра, который обычно называют просто INIT.ORA, или, начиная с версии Oracle9i, в репозитории, который называется файлом параметров сервера (или SPFILE). Количество обязательных параметров инициализации уменьшается с выходом каждой новой версии Oracle. В дистрибутиве Oracle есть пример файла инициализации, пригодный для запуска базы данных. Либо можно воспользоваться программой Database Configuration Assistant (DCA), которая подскажет обязательные значения (например, имя базы данных).
Вот обязательные параметры инициализации для версии Oracle Database 11g:
Местонахождение управляющих файлов.
Локальное имя базы данных.
Местонахождение архивного журнала.
Параметр, включающий архивирование журналов.
Местонахождение области быстрого восстановления (flash recovery area) (каталог, файловая система или группа дисков ASM).
Максимальный размер области быстрого восстановления базы данных в байтах.
Размер блока базы данных в байтах (например, для 4 Кбайт указывается значение 4096).
Максимальное число процессов операционной системы, обслуживающих одновременный доступ к базе данных.
Максимальное число сеансов работы с базой данных.
Максимальное число открытых в базе данных курсоров.
Минимальное число разделяемых серверов базы данных.
REM O TE_LI S TENER
Имя удаленного прослушивателя.
Версия базы данных, с которой должна поддерживаться совместимость, в тех случаях, когда то или иное средство затрагивает формат файла (например, 11.1.0, 10.0.0).
Размер области памяти, автоматически выделяемой для SGA и PGA экземпляра.
Для команд языка определения данных (DDL) - время (в секундах) ожидания возможности установить монопольную блокировку, прежде чем сообщить об ошибке.
Язык, определенный в подсистеме поддержки национальных языков (National Language Support, NLS) для базы данных.
Территория, определенная в подсистеме поддержки национальных языков для базы данных.
В качестве признака взятого курса на автоматизацию отметим, что в версии Oracle Database 11g параметр UNDO_MANAGEMENT по умолчанию устанавливается в режим автоматического управления откатом (undo). Механизм отката применяется при откате транзакций, а также для восстановления базы данных, обеспечения согласованности по чтению и реализации ретроспекции. (Однако записи о повторном выполнении располагаются в физических журналах повтора, или наката, redo log; в них хранятся изменения, произведенные в сегментах данных и блоках сегментов отката, там же хранится таблица транзакций для сегментов отката.) Время хранения информации для отката Oracle теперь подбирает автоматически, исходя из того, как сконфигурировано табличное пространство отката.
Изучите поставляемую с вашей версией СУБД документацию в части дополнительных параметров инициализации, поскольку эта информация изменяется от версии к версии.
Читайте также: