
Что такое асинхронное чтение файла
Обновлено: 07.07.2024
Для того чтобы воспользоваться возможностями асинхронного ввода-вывода , нужно вызвать функцию CreateFile с установленным флагом FILE_FLAG_OVERLAPPED , входящим в состав параметра dwFlagsAndAttrs , и указать: с какой позиции осуществлять чтение (запись), сколько байтов считать (записать) и какое событие должно сигнализировать о том, что операция завершена. Для этого необходимо проинициализировать поля структуры OVERLAPPED в параметре pOverlapped функций ReadFile или WriteFile .
Структура OVERLAPPED
Параметр Internal используется для хранения кода возможной ошибки, а параметр InternalHigh - для хранения числа переданных байт. Вначале разработчики Windows не планировали делать их общедоступными - отсюда и такие не содержащие мнемоники имена. Offset и OffsetHigh - соответственно младшие и старшие разряды текущей позиции файла. hEvent специфицирует событие, сигнализирующее окончание операции ввода-вывода.
Прогон программы, осуществляющей асинхронное чтение из уже существующего файла
В программе проинициализирована структура OVERLAPPED и передана функции ReadFile в качестве параметра. Чтение начинается с 3-й позиции. Узнать число прочитанных байтов можно из ov.InternalHigh - компонента структуры OVERLAPPED . Обратите внимание, что значение переменной iRead , которая должна содержать количество прочтенных байтов, равно 0, так как функция вернула управление до завершения операции ввода-вывода. Обычно это справедливо для первого запуска программы. При последующих запусках, поскольку данные файла находятся в кэше, запрос может успеть выполниться синхронно и значение iRead уже будет равно числу прочитанных байтов.
В программе выбран простейший вариант синхронизации - сигнализация от объекта, управляющего устройством, в данном случае - открытого файла (функции WaitForSingleObject передан описатель открытого файла в качестве параметра). Существуют и другие, более интересные способы синхронизации, например, использование порта завершения ввода-вывода ( IoCompletitionPort ). Более подробно возможности асинхронного ввода-вывода описаны в [ Рихтер ] , [ Рихтер, Кларк ] и [ Харт ] .
Результат работы данной программы практически ничем не отличается от обычного синхронного чтения и в таком виде большого смысла не имеет. Однако если между операциями чтения и синхронизации заставить программу выполнять какую-либо полезную работу, то ресурсы компьютера будут использоваться более эффективно, т.к. процессор и устройство ввода будут работать параллельно.
Операция позиционирования в случае синхронного доступа к файлу
Итак, в случае асинхронного доступа позиция, начиная с которой будет осуществляться операция чтения-записи, содержится в запросе на операцию ( параметр структуры OVERLAPPED ). Рассмотрим теперь особенности позиционирования при обычном синхронном вводе-выводе . В этом случае реализуется схема с "сохранением состояния", 64-разрядный указатель текущей для чтения-записи позиции хранится в составе атрибутов объекта "открытый файл " (его не нужно путать с атрибутами файла), описатель которого возвращает функция CreateFile .
Текущая позиция смещается на конец считанной или записанной последовательности байтов в результате операций чтения или записи. Кроме того, можно установить текущую позицию при помощи Win32-функции SetFilePointer . Например, операция
устанавливает указатель текущей позиции на 17-й байт с начала файла.
Тот факт, что указатель текущей позиции является атрибутом объекта "открытый файл ", а не самого файла, означает, что тот же самый файл можно открыть повторно с другим описателем. При этом для одного и того же файла будут существовать два разных объекта с двумя разными указателями текущих позиций. Очевидно, что смена текущей позиции при работе с файлом через разные объекты будет происходить независимо.
С другой стороны, получив описатель открытого файла, можно его продублировать при помощи Win32- функции DuplicateHandle . В этом случае два разных описателя будут ссылаться на один и тот же объект с одним и тем же указателем текущей позиции .
Написание, компиляция и прогон программы, осуществляющей перемещение указателя текущей позиции внутри открытого файла
В качестве самостоятельного упражнения рекомендуется написать программу, которая проиллюстрировала бы перемещение указателя текущей позиции в результате операций чтения, записи и позиционирования. Необходимо также продемонстрировать в программе независимое позиционирование для двух описателей одного и того же файла и зависимое позиционирование для дубликата уже существующего описателя.
Директории. Логическая структура файлового архива
Файловая система на диске представляет собой иерархическую структуру, которая организована за счет наличия специальных файлов - каталогов (директорий). Каталоги имеют один и тот же внутренний табличный формат ( рис. 11.1) и обеспечивают многоуровневое наименование файлов.

Запись в каталоге о файле содержит имя файла , некоторые атрибуты ( длина имени, временная метка ) и ссылку на запись в главной файловой таблице, необходимую для нахождения блоков файла.
В итоге, файловая система на диске образует хорошо известную древовидную структуру ( рис. 11.2), где нет циклов (если отсутствуют ссылки и точки монтирования) и путь от корня к файлу однозначно определяет файл .

Рис. 11.2. Иерархическая древовидная структура файловой системы
Поскольку имена файлов, находящихся в разных каталогах, могут совпадать, уникальность имени файла на диске обеспечивается добавлением к собственному имени файла списка вложенных каталогов , содержащих данный файл . Так образуется хорошо известное абсолютное или полное имя ( pathname ), например, \Games\Heroes\heroes.exe . Таким образом, использование древовидных каталогов минимизирует сложность назначения уникальных имен.
Чтобы иметь возможность работать с собственными именами файлов, используют концепцию рабочей или текущей директории, которая обычно входит в состав атрибутов процесса, работающего с данным файлом. Тогда на файлы в такой директории можно ссылаться только по имени. Кроме того ОС поддерживает обозначения '.' - для текущей директории и '..' - для родительской.
В системе поддерживается большое количество Win32-функций для манипуляции с каталогами, их полный перечень имеется в MSDN . В частности, для создания каталогов можно использовать функцию CreateDirectory . Вновь созданная директория включает записи с именами '.' и '..', однако считается пустой. Для работы с текущим каталогом можно использовать функции GetCurrentDirectory и SetCurrentDirectory . Работа с этими функциями проста и не нуждается в специальных разъяснениях.
Прогон программы, задача которой создать каталог на диске и сделать его текущим
Приведенная программа выводит на экран название текущего каталога, создает каталог "tmp1" на диске "F:" , делает его текущим и выводит на экран его название в качестве текущего каталога.
Самостоятельное упражнение
На основании предыдущей программы рекомендуется написать программу, которая создает каталог в родительской директории и копирует в него какой-либо файл с помощью функции CopyFile .
Довольно часто встречаются задачи, связанные с записью файлов на основе информации, полученной из информационной базы. Для примера возьмем запись содержимого элемента справочника в файл, выбранный пользователем.
В те благословенные времена, когда о тонком клиенте и управляемых формах и не слышали В толстом клиенте на обычных формах эта задача решается довольно просто:
Здесь Ссылка - ссылка на элемент справочника, данные которого записываем в файл. СериализаторXDTO - специальный объект платформы, с помощью которого объект ИБ трансформируется в файл формата XML.
Все изменилось с появлением тонкого клиента и управляемых форм. Во-первых, на клиенте стала недоступна работа с объектами ИБ, а сервер, в свою очередь, ничего не знает о действиях пользователя, а во-вторых, использование веб-клиента породило необходимость отказаться от модальности и использовать асинхронные вызовы многих методов. Таким образом, решение приведенной выше задачи стало достаточно непростым.
Общая схема решения:
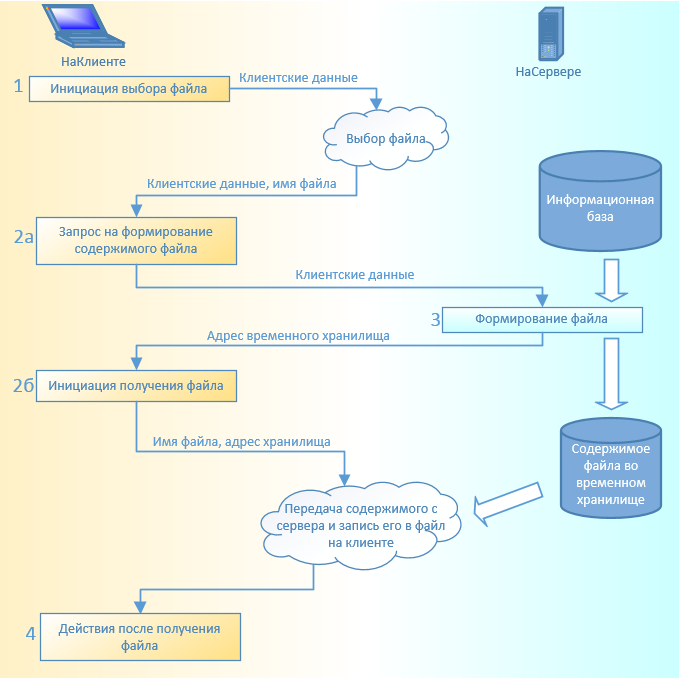
Рассмотрим каждый шаг более подробно.
1 шаг. Пользователь выбирает данные для файла (в данном случае - ссылку справочника) и хочет выбрать файл для записи. Использовать синхронные методы вроде Диалог.Выбрать() теперь стало нельзя. Вместо синхронных методов появились их асинхронные аналоги, в данном случае Диалог.Показать(Оповещение).
Ключевой особенностью асинхронных методов является то, что результат их работы мы можем получить не сразу после вызова метода в том же участке кода, а с помощью отдельного метода (callback, метод обратного вызова), который будет вызван платформой после завершения асинхронного метода. В данном случае методом обратного вызова является ОповещениеПослеВыбораФайлаДляЗаписи, описание которого указывается в параметрах открытия диалога. Он будет вызван автоматически после закрытия диалога выбора файла вне зависимости от результата выбора.
После закрытия диалога выбора файла, и проверки, что пользователь действительно не отказался от выбора (в первом параметре метода будет находится массив выбранных файлов), мы можем продолжить процесс. И здесь программиста подстерегает возможность совершить трудноуловимую ошибку. Дело в том, что в веб-клиенте во время показа пользователю диалога выбора файла выполнение кода не останавливается! Существует вероятность, что за время между первым и вторым шагом изменятся данные, которые пользователь выбрал на первом шаге (в нашем примере - Ссылка). Чтобы этого избежать, данные надо где-то сохранить, а еще лучше - передать в качестве параметра при открытии диалога, так, чтобы этот параметр попал на второй шаг без изменений. В нашем примере это реализовано указанием ссылки в качестве третьего параметра при создании оповещения на первом шаге. Эта же ссылка будет получена вторым параметром метода ОповещениеПослеВыбораФайлаДляЗаписи. Итак мы имеем все необходимые данные (имя файла и ссылку) для записи. Напомню: пока все то, что происходит, происходит на стороне клиента. Но на стороне клиента недоступны данные ИБ, поэтому нам необходимо передать управление на сервер, вызвав серверный метод и передав в него ссылку.
На этом шаге нам необходимо сформировать содержимое файла и подготовить его для передачи на сторону клиента, поместив в специальную область - временное хранилище. Временное хранилище располагается на сервере, доступ к нему осуществляется с помощью специального адреса. Временное хранилище "живет" непродолжительное время, в нашем случае - пока живет форма, для этого при создании хранилища указывается идентификатор формы. В хранилище будем помещать ДвоичныеДанные - содержимое нашего будущего файла. Как правило, использование двоичных данных связано с формированием промежуточного временного файла, но в нашем случае мы можем обойтись без этого. В последних версиях платформы появились новые объекты - Поток, ПотокВПамяти, которые позволят нам обойтись без дополнительных файлов.
В конечном итоге на этом шаге мы получим адрес хранилища, в котором находится содержимое нашего файла.
Вызов серверной функции на втором шаге был обычным, не асинхронным, поэтому после выполнения этого метода мы продолжаем выполнение второго шага. Итак, имеем: имя выбранного пользователем файла и адрес временного хранилища на сервере, где хранится его содержимое. Необходимо вызвать метод, который получит содержимое с сервера и запишет в файл на клиенте. Этот метод - НачатьПолучениеФайлов. Не буду останавливаться на подробном описании его параметров, скажу лишь, что в него передается имя файла и адрес временного хранилища. Метод НачатьПолучениеФайлов является асинхронным, окончание его работы запустит метод обратного вызова ОповещениеПослеПолученияФайла, в котором мы узнаем результат. Разумеется, описание метода ОповещениеПослеПолученияФайла мы должны указать при вызове НачатьПолучениеФайлов.
Этот шаг - завершающий. На этом шаге мы можем проанализировать результат получения файла.
Аналогичным образом можно решить обратную задачу: загрузить данные из файла в информационную базу
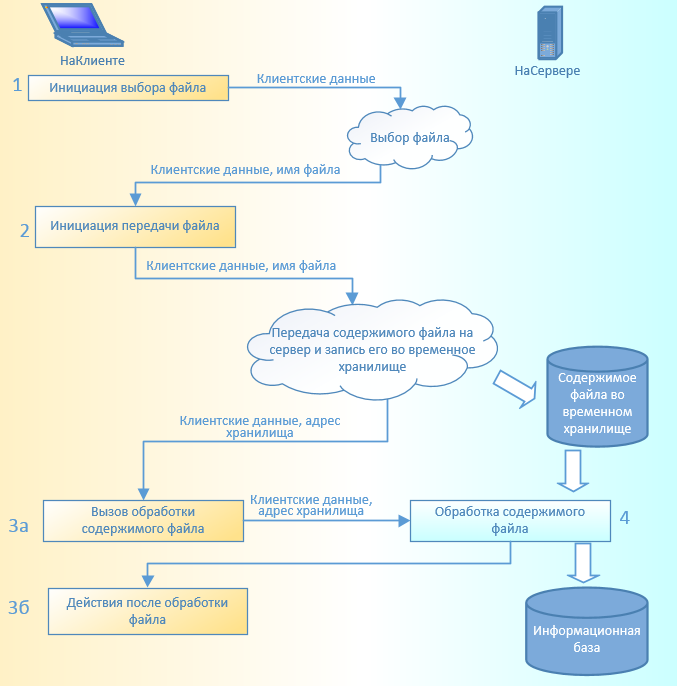
1 шаг. Открываем асинхронный диалог выбора файла, передав в него все необходимые клиентские данные (в нашем случае - Ссылка)
2 шаг. Если пользователь выбрал файл, то инициируем асинхронную передачу файла на сервер с помощью НачатьПомещениеФайлов. Платформа автоматически создаст на сервере временное хранилище и поместит в него содержимое файла.
3а шаг. После завершения операции помещения файла платформа вызовет клиентскую процедуру, в которую будут переданы данные о помещенных на сервер файлах. Нас будет интересовать адрес хранилища ПомещенныеФайлы[0].Хранение, в которое записано содержимое файла. Для обработки этого содержимого вызовем серверную функцию, передав в нее этот адрес и данные, выбранные клиентом на первом шаге. Еще раз подчеркну, что эти клиентские данные (в нашем случае - Ссылка) передаются по цепочке оповещений, что гарантирует их неизменность во время асинхронного выполнения нескольких методов.
4 шаг. Получив на сервере адрес временного хранилища, прочитаем его содержимое в ДвоичныеДанные. Так же, как и в предыдущем примере, чтобы не создавать дополнительных временных файлов, воспользуемся потоками. С помощью СериализаторXDTO преобразуем данные (они представляют собой XML текст) в объект для дальнейшей обработки.
3б шаг. После завершения серверной функции, управление передается обратно в клиентский метод (вызов был не асинхронный), где мы можем выполнить все оставшиеся действия (в нашем случае - обновить интерфейс после загрузки данных)
Как видим, работа с файлами в тонком клиенте существенно сложнее, чем в толстом. К сожалению, это - та плата, которую вынужден платить разработчик при разработке современной системы.
Давайте теперь рассмотрим асинхронную работу с файловой системой. Как правило, в NodeJS все методы модуля fs существуют в двух вариантах: в синхронном и асинхронном.
Например, для синхронного чтения файла используется метод readFileSync , а для асинхронного - readFile . Аналогично для записи файла существует пара writeFileSync и writeFile .
Асинхронное чтение файла
Метод readFile первым параметром принимает имя или путь к файлу, вторым параметром - кодировку, а третьим - коллбэк, который выполнится после чтения файла.
В коллбэк следует передавать два параметра. В первый параметр попадет объект с ошибкой, если она произойдет, а во второй - текст прочитанного файла.
Давайте для примера прочитаем текст какого-нибудь файла:
Дан файл с числом. Прочитайте этот файл и выведите в консоль квадрат этого числа.
Проверка асинхронности
Можно убедится в том, что чтение файла происходит асинхронно. Для этого выведем что-нибудь в консоль после работы с методом readFile :
fs.readFile('readme.txt', 'utf8', function(err, data) < console.log(data); >); console.log('. ');Как вы уже знаете, коллбэк выполнится, когда файл будет прочитан. А пока файл читается, код скрипта будет выполнятся дальше. Это значит, что в консоли сначала появится результат второго console.log , а потом первого.
Проверьте, что код после метода readFile будет выполнен раньше, чем будет прочитан файл.
Обработка исключительных ситуаций
Так как наш код асинхронный, то исключительные ситуации нельзя поймать через try-catch . Для обработки исключений в коллбэке предназначен первый параметр. Этот параметр будет содержать null , если исключения не случилось, или объект с ошибкой, если исключение произошло.
Давайте допишем код коллбэка так, чтобы он обрабатывал исключительные ситуации:
Попробуйте прочитать несуществующий файл. Убедитесь, что при этом произойдет исключительная ситуация. Допишите ваш код так, чтобы он обрабатывал эту ситуацию.
Асинхронная запись файла
Асинхронная запись текста в файл выполняется аналогично:
С помощью цикла создайте 10 файлов, содержащих целые числа от 1 до 10 .
Асинхронное чтение нескольких файлов
Пусть у нас есть два файла с числами. Давайте найдем произведение этих чисел. Очевидно, что для этого нам нужно прочитать оба этих файла.
Но, так как код асинхронный, нам нужно читать второй файл в коллбэке первого:
fs.readFile('readme1.txt', 'utf8', function(err, data1) < if (!err) < fs.readFile('readme2.txt', 'utf8', function(err, data2) < if (!err) < console.log(data1 * data2); >else < console.log('ошибка чтения файла readme2'); >>); > else < console.log('ошибка чтения файла readme1'); >>);Даны три файла с числами. Выведите в консоль сумму этих чисел.
Даны пять файлов с числами. Выведите в консоль сумму этих чисел.
Асинхронное чтение и запись файла
Предположим нам нужно прочитать файл, сделать его текстом операцию и записать обратно в этот или другой файл. В этом случае запись в файл нужно будет делать в коллбэке чтения:
Дан файл с числом. Запишите в этот файл квадрат этого числа.
Даны три файла с числами. Запишите в новый файл сумму этих чисел.
Стрелочные функции
Как правило коллбэки в NodeJS делают с помощью стрелочных функций. Это сокращает код, но несколько затрудняет понимание с непривычки.
Есть у нас значит файл, который мы построчно читаем синхронно (пример с сайта MS):
который выполняет чтение строки асинхронно.
Глубоко внутри методы ReadLine() и ReadLineAsync() вызывают в конечном счете один и тот же АПИ метод операционной системы, который выполняет чтение файла асинхронно (поскольку асинхронность же на уровне оборудования реализована?)? Или все же глубоко внутри на уровне операционной системы есть разные реализации чтения с диска?
Вопрос не касается только чтения файлов. Хочу лучше для себя понять как устроена асинхронность.
__________________Помощь в написании контрольных, курсовых и дипломных работ здесь
Синхронное и асинхронное чтение в Windows Forms Application
Доброго времени суток. Интересует простой вопрос. Мне нужно читать данные с usb-устройства.
Синхронное и асинхронное программирование. Лжетермины?
Я очень удивлен как называют вещи в программировании не своими именами. Сейчас интересуюсь.

Синхронное и асинхронное программирование. Парадокс терминологии
Я очень удивлен как называют вещи в программировании не своими именами. Сейчас интересуюсь.
Что такое синхронное и асинхронное выполнение операций
Объясните пожалуйста, что такое синхронное и асинхронное выполнение операций ? :scratch:
WaitForSingleObject занимается тем, что ждет, когда объект перейдет в сигнальное состояние, при этом поток, вызвавший ее, совершенно не расходует процессорное время. Но тут непонятен важный момент: поток просто засыпает и не использует процессор, либо же пока там происходит ожидание, поток может выполнять какие-то другие задачи? Причем поток в данном случае это же поток на уровне операционной системы, а не на уровне приложения? Но тут непонятен важный момент: поток просто засыпает и не использует процессор, либо же пока там происходит ожидание, поток может выполнять какие-то другие задачи? Причем поток в данном случае это же поток на уровне операционной системы, а не на уровне приложения?
Даже создавать и контролировать потоки нужно только в исключительных случаях.
А то как он будет использован ОС пока ваша задача в нём простаивает, вообще, ни с какой стороны не имеет значения.
nicolas2008, а "thread pool" это какой-то пул потоков на уровне ОС?
V0fka, что такое асинхронная работа?
В компе всё работает только синхронно.
Вы можете только в своей ЗАДАЧЕ создать и запустить другую ЗАДАЧУ и продолжить дальше выполнение своей задачи.
Другая задача, в любом случае, на каком-то уровне будет выполняться синхронно.
То есть асинхронность это не волшебная палочка которая выполняет виртуально код, это всего лишь создание разных задач которые выполняются независимо друг от друга.
Но каждая задача сама по себе - синхронная.
Добавлено через 4 минуты
А какая разница?
Занят он, спит, или ещё чё делает.
Для вашей задачи верхнего уровня, важно только одно - завершилась созданная задача или нет.
Даже в каком потоке она выполняется - неважно.
Может быть даже в том, что и основная задача.
Добавлено через 1 минуту
randok, спасибо, но вопрос не совсем в этом. Надеюсь из описания ниже будет более понятно о чем я хочу узнать.
Допустим, в файле который мы читаем в GetFileLines() у нас 1 строка и ReadLine() этой одной строки у нас выполняется очень долго по каким-то причинам. Пускай ReadLine() отрабатывает у нас 5 секунд.
В какой-то момент у нас появилась возможность делать асинхронные контроллеры. Я не помню сейчас точно ли они наследуются от одного и того же класса, но нам это не важно сейчас, допустим да. Вместе с этим зная о том, что у нас для чтения строки есть метод ReadLineAsync мы могли бы переписать наш контроллер таким образом:
Что бы мы получили от этого. Если в 10:17 поступает 1000 запросов на GetFileLines() и в 10:18 поступает 1000 запросов на GetCurrentDate, то от GetCurrentDate мы бы получили ответ сразу практически, т.е. где-то в те же 10:18, а ответ от GetFileLines получили бы как и в предыдущем случае где-то через5 сек. Таким образом мы обработали больше запросов за одно и то же время.
Добавлено через 1 минуту
Одну скобку (закрывающую) пропустил
Элд Хасп, так не работает . И вопрос как раз в том, как сделать что бы заработало. Вопрос возникает не потому, что мне принципиально не хочется использовать готовый функционал, а потому что я хотел бы разобраться как этот функционал работает.
Я сейчас понял, что это даже в консольном приложении можно проверить. Вот:
5 сек, а с MyLongOperationAsync будет
Я сейчас понял, что это даже в консольном приложении можно проверить. Вот:Да, теперь стало понятно.
Внутреннею реализацию ReadLineAsync вы всё равно не измените.
Тем более, что она ещё и различна для разных платформ.
Наверное, надо просто регулировать количество потоков в пуле.
Если их на пределе - расширять его.
Если слишком много простаивает - сокращать.
Глобально хочу понять, можно ли превратить в реально асинхронный код что угодно и как это делается. Либо же для этого должна быть возможность на уровне АПИ операционной системы или ещё что-то типа того? Я не изменить её хочу, я хочу понять как оно устроено внтури, за счет чего работает.
Я не могу найти сейчас где читал.
Но суть такова.
Работа с файлами реализована partial классами.
И часть этих классов адаптивна к платформе и обращается к низкоуровневым вызовам конкретной ОС.
Поэтому, (например) в Window 10 и в Unix, реализация у этих методов различна.
В Windows она реализована (насколько помню) через отпускание потоков и ожидания результатов через системные прерывания.
В Unix - ожидающие потоки.
И всё это реализовано даже не на уровне Net или COM, а на уровне ядра ОС.
И при любом апгрейде ОС - может быть изменено.
И вот теперь сами подумайте, есть толк от того, что вы потратите кучу времени и усилий на то чтобы выяснить конкретный механизм, настроить под него своё приложение, а на следующий день поймаете очередной апгрейд из-за которого вся ваша оптимизация "коту под хвост"?
Раз вы работаете с высокоуровневым ЯП, то не надо лезть глубоко вниз.
Нужно создавать решения работающие одинаково эффективно независимо "от низов".
Элд Хасп, ещё раз хочу подчеркнуть, что у меня нет цели сделать свой велосипед для чтения файлов, цель - разобраться как это (асинхронная работа) устроено внутри. Поэтому если вы ещё не потеряли интерес к этой беседе (я очень надеюсь, что не потеряли), я хотел бы продолжить. Мне кажется, что ещё немного осталось, что бы я на текущий момент успокоился с этим вопросом .
Получается, что на самом низком уровне для достижения асинхронности мы должны использовать соответствующий функционал операционной системы. То как она это делает - это уже не интересно. Точнее интересно, но не в рамках этой темы.
Помимо каких-то параметров для чтения файла, там обязательно должен быть какой-то колбэк, который вызовет операционная система. Сам метод, который производит чтение - выполняется моментально, не блокируя ничего и не дожидаясь окончания чтения. Если это так, то читать файл асинхронно можно было бы как-то так (псевдокод):
Код этот работает так, что поток в котором он выполняется нигде не блокируется. В большинстве случаев, наверное, этот код будет выводить сначала Done, потом Callback. Но важно то, что нигде не блокируется поток.
Если то что я написал выше похоже на правду, то мне не до конца понятно теперь вот что. Я теперь хочу завернуть это все в Task (что бы использовать async/await), при этом что бы это действительно работало асинхронно (без блокирования потоков). Такого эффекта я могу достичь просто используя TaskCompletionSource или тут тоже не все так просто?
V0fka, и да, и нет.
API обращается к низкоуровневым системным вызовам.
В Windows (не знаю во всех версиях или нет, но те что наследуют этот механизм от DOS) при обращении к файлу вызывается системное прерывание с передачей нужных параметров.
На этом вызывающая часть метода прекращает работу.
Внешнее устройство, выполнив обращение, заполняет переданный буфер данными.
И теперь надо как-то сообщить методу верхнего уровня, что данные получены и можно продолжить работу.
Вот в разрыве между системным прерывание и прерыванием от устройства и кроются различия в ОС.
Даже в DOS (однопоток) можно сделать по разному.
Самый примитивный подход - бесконечный цикл проверяющий возвращён результат или нет.
Более продвинутый, заморозка потока (чтобы разгрузить проц) и разморозка его по полученному прерыванию от устройства.
В Windows, в UNIX вариантов намного больше.
В этом есть и свои плюсы, и свои минусы.
С одной стороны потоков много и можно не заморачиваться, тем что заблокирован какой-то из них или нет.
С другой, порой неизвестность конкретной реализации может привести к непредвиденным проблема, типа как у вас.
И так как это недокументированные особенности, это приводит к тому, что и смысла выяснять эту реализацию нет.
Потому, что MS (если мы говорим о Windows) в любой момент может эту реализацию поменять.
И это даже может быть нигде не объявлено, так как MS не считает это качественной характеристикой.
Ну, поменял какой-то инженер реализацию, по его мнению это улучшило код.
А кто это проверял, если это не существенно?
Будут проверять только, если после релиза обновления, появятся жалобы.
И жалоб должно быть не одна-две.
Поэтому вы можете разбираться как всё это устроено.
Но с одной стороны вам придётся лезть "в самые низы" Системы и эти "низы" у разных систем даже в рамках одной платформы могут быть реализованы по разному.
А с другой стороны, даже разобравшись вы не сможете на этом построить своё приложение.
Ваше приложение может использовать только ДОКУМЕТИРОВАННЫЕ методы работы.
В противном случае при поддержке продукта вам придётся отслеживать каждое обновление (даже незначительное) всех ОС на которых работает ваше приложение.
И тестировать как это обновление повлияло на работу вашего приложения.
Асинхронность позволяет вынести отдельные задачи из основного потока в специальные асинхронные методы или блоки кода. Особенно это актуально в графических программах, где продолжительные задачи могу блокировать интерфейс пользователя. И чтобы этого не произошло, нужно задействовать асинхронность. Также асинхронность несет выгоды в веб-приложениях при обработке запросов от пользователей, при обращении к базам данных или сетевым ресурсам. При больших запросах к базе данных асинхронный метод просто уснет на время, пока не получит данные от БД, а основной поток сможет продолжить свою работу. В синхронном же приложении, если бы код получения данных находился в основном потоке, этот поток просто бы блокировался на время получения данных.
Асинхонный метод обладает следующими признаками:
В заголовке метода используется модификатор async
Метод содержит одно или несколько выражений await
В качестве возвращаемого типа используется один из следующих:
Асинхронный метод, как и обычный, может использовать любое количество параметров или не использовать их вообще. Однако асинхронный метод не может определять параметры с модификаторами out и ref .
Также стоит отметить, что слово async , которое указывается в определении метода, не делает автоматически метод асинхронным. Оно лишь указывает, что данный метод может содержать одно или несколько выражений await .
Рассмотрим пример асинхронного метода:
Здесь прежде всего определен обычный метод подсчета факториала. Для имитации долгой работы в нем используется задержка на 8 секунд с помощью метода Thread.Sleep() . Условно это некоторый метод, который выполняет некоторую работу продолжительное время. Но для упрощения понимания он просто подсчитывает факториал числа 6.
Также здесь определен асинхронный метод FactorialAsync() . Асинхронным он является потому, что имеет в определении перед возвращаемым типом модификатор async , его возвращаемым типом является void, и в теле метода определено выражение await .
Выражение await определяет задачу, которая будет выполняться асинхронно. В данном случае подобная задача представляет выполнение функции факториала:
По негласным правилам в названии асинхроннных методов принято использовать суффикс Async - Factorial Async () , хотя в принципе это необязательно делать.
Сам факториал мы получаем в асинхронном методе FactorialAsync . Асинхронным он является потому, что он объявлен с модификатором async и содержит использование ключевого слова await .
И в методе Main мы вызываем этот асинхронный метод.
Посмотрим, какой у программы будет консольный вывод:
Разберем поэтапно, что здесь происходит:
Запускается метод Main, в котором вызывается асинхронный метод FactorialAsync.
Метод FactorialAsync начинает выполняться синхронно вплоть до выражения await.
В этом и преимущество асинхронных методов - асинхронная задача, которая может выполняться довольно долгое время, не блокирует метод Main, и мы можем продолжать работу с ним, например, вводить и обрабатывать данные.
Когда асинхронная задача завершила свое выполнение (в случае выше - подсчитала факториал числа), продолжает работу асинхронный метод FactorialAsync, который вызвал асинхронную задачу.
Функция факториала, возможно, представляет не самый показательный пример, так как в реальности в данном случае нет смысла делать ее асинхронной. Но рассмотрим другой пример - чтение-запись файла:
Асинхронный метод ReadWriteAsync() выполняет запись в файл некоторой строки и затем считывает записанный файл. Подобные операции могут занимать продолжительное время, особенно при больших объемах данных, поэтому такие операции лучше делать асинхронными.
Аналогично в классе StreamReader определен метод ReadToEndAsync() , который также представляет асинхронную операцию и который возвращает весь считанный текст.
Далее в методе Main вызывается асинхронный метод ReadWriteAsync:
И опять же, когда выполнение в методе ReadWriteAsync доходит до первого выражения await, управление возвращается в метод Main, и мы можем продолжать с ним работу. Запись в файл и считывание файла будут производиться параллельно и не будут блокировать работу метода Main.
Определение асинхронной операции
Можно определить асинхронную операцию с помощью лямбда-выражения:
Передача параметров в асинхронную операцию
Выше вычислялся факториал 6, но, допустим, мы хотим вычислять факториалы разных чисел:
Получение результата из асинхронной операции
Асинхронная операция может возвращать некоторый результат, получить который мы можем так же, как и при вызове обычного метода:
Читайте также: