
Что такое collection framework
Обновлено: 30.06.2024
Java Коллекции являются одним из столпов Java Core. Они используются почти в каждом приложении, поэтому мы просто обязаны уметь использовать Java Collections Framework эффективно.
Что такое Коллекции?
Например: банка конфет, список имен и т.д. Коллекции используются почти в каждом языке программирования и Java не является исключением. Как только коллекции появились в Java, то насчитывали всего несколько классов: Vector, Stack, Hashtable, Array. Но уже в Java 1.2 появился полноценный Java Collections Framework, с которым мы и будем сегодня знакомиться.
Коллекции в Java состоят нескольких частей
Преимущества Java Collections Framework
В Java Collections Framework есть следующие преимущества:
Интерфейсы коллекций
Следует отметить, что платформа Java не предоставляет отдельные интерфейсы для каждого типа коллекций. Если какая-то операция не поддерживается, то реализация коллекции бросает UnsupportedOperationException.
Кратко по каждой коллекции
Интерфейс итератора (Iterator)
Итератор предоставляет методы для перебора элементов любой коллекции. Мы можем получить экземпляр итератора из коллекции с помощью метода iterator . Итераторы позволяют удалить элементы из базовой коллекции во время выполнения итерации.
Интерфейс множества (Set)
Набор представляет собой коллекцию, которая не может содержать повторяющиеся элементы. Этот интерфейс представляет математическую абстракцию для представления множеств в виде колоды карт.
Платформа Java содержит три реализации Set : HashSet, TreeSet и LinkedHashSet.И нтерфейс Set не позволяет осуществлять произвольный доступ к элементу в коллекции. Мы можем использовать итератор или цикл по каждому элементу для перебора элементов.
Интерфейс Список (List)
Список представляет собой упорядоченный набор элементов и может содержать повторяющиеся элементы. Вы можете получить доступ к любому элементу по индексу. Список представляет собой динамический массив. Список является одним из наиболее используемых типов коллекций. ArrayList и LinkedList классы являются реализацией интерфейса List .
Работа с массивами данных, их структурирование, поиск соответствий между ними, фильтрация — все это основа любой программы, написанной на Java. Поэтому программистам важно иметь в своем арсенале инструменты, которые максимально упростили бы и структурировали работу с этими данными. Именно здесь и берут свое начало коллекции фреймворков на Java.
Что такое Collections Framework
Это набор различных интерфейсов для работы с группами объектов при программировании на Java . Коллекции позволяют производить манипуляции с массивами (Array), очередями (Queue, Stack), списками (List), ключами и значениями (Map) и другими типами объектов.
Любая коллекция на Java строго структурирована: одни интерфейсы подчиняют другие, последние же — расширяют функционал своих «старших братьев» по иерархии.
Структура Java Collections Framework
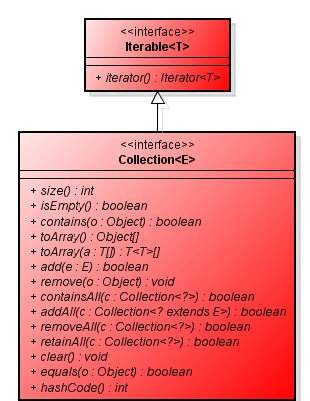
В основе иерархической структуры Java Collections Framework лежит интерфейс Collection. Это главенствующий интерфейс. Общая коллекция вмещает в себя все остальные виды коллекций и позволяет работать с группами объектов благодаря основным методам, среди которых:
- add(…) — добавить;
- remove(…) — убрать;
- clear(…) — очистить.
Интерфейс Collection наследуется от Iterable, а значит все подчиненные ему коллекции являются итерируемыми вне зависимости от типа их реализации. Благодаря этому в Collection вы можете получить итератор, который позволит вам пройтись по другим интерфейсам коллекций.
Итератор позволит пройтись по другим интерфейсам коллекций
Интерфейсу Collections подчинены три главных интерфейса:
- Set — позволяет работать с множествами данных;
- List — взаимодействует со списками данных;
- Queue — работает с очередью.
Интерфейс Map работает с данными типа «ключ/значение». Он стоит в этом списке отдельно, и чуть позже я объясню, почему это так. А пока давайте пройдемся по основным типам коллекций и выясним, за что отвечает каждая из них.
Интерфейс List и его реализации — ArrayList и LinkedList
List — это упорядоченная коллекция, наиболее часто используемая в Java Collections Framework. Этот интерфейс контролирует, где вставлен каждый элемент списка. При работе с List пользователю доступны элементы списка по их целочисленному индексу (позиции в списке).

Работа с интерфейсом List
Интерфейс List имеет две стандартные реализации — ArrayList и LinkedList.
Смысл в том, что можно написать и другие реализации, но в JDK уже есть две, которые доступны «из коробки».
ArrayList содержит внутри себя массив, длина которого будет увеличиваться автоматически при добавлении в него новых элементов.
Вторая имплементация интерфейса List — класс LinkedList. Это список с двумя связями, где каждый элемент содержит ссылку на предшествующий и следующий элементы списка.

Вторая имплементация интерфейса List — класс LinkedList
ArrayList и LinkedList — идентичны, то есть их методы полностью совпадают. Они оба могут добавлять и извлекать элементы из любой части списка. Так в чем же отличие? Главная разница между ними в цикломатической сложности операций — количестве линейно независимых маршрутов, проходящих через код программы. Чем меньшее количество маршрутных точек будет проходить каждая отдельно взятая команда, тем быстрее будет работать программа.
Для наглядности различий в цикломатической сложности между двумя классами рассмотрим таблицу:

Различия в цикломатической сложности между классами LinkedList и ArrayList
Как видите, основные преимущества класса LinkedList связаны с операциями (iterator.remove() и ListIterator.add(E element) . Их цикломатическая сложность всегда будет равна О(1) . В случае добавления add(E element) лучше использовать LinkedList, а вот для get(int index) — ArrayList.
Так же дела обстоят с оператором add(int index, E element) . Цикломатическая сложность этой операции для LinkedList будет ниже только в том случае, если сам индекс будет равен нулю. Для всех остальных случаев разумнее использовать именно ArrayList.
Это же касается и операции remove : для класса LinkedList ее цикломатическая сложность будет вдвое меньше, чем для ArrayList. Забегая наперед скажу, что именно ArrayList используют в подавляющем случае работ в интерфейсе List.
Интерфейс Set
Set — это коллекция, которая не содержит повторяющихся элементов. Этот интерфейс создан для моделирования абстракций математического множества.

Иерархия Set включает в себя два интерфейса — SortedSet и NavigableSet — и три основных класса. О последних расскажу подробнее:
- HashSet — коллекция, которая не позволяет хранение одинаковых элементов благодаря содержанию в себе объекта HashMap. Он использует для хранения данных хэш-таблицы.
- LinkedHashSet — подобная HashSet, в которой элементы объединены между собой в порядковый список. В этом случае элементы хранятся в том же порядке, в котором и добавляются (благодаря содержанию в себе объекта LinkedHashMap).
- TreeSet — коллекция, которая использует для хранения элементов упорядоченное по значениям дерево. TreeSet содержит в себе TreeMap — коллекцию, которая использует для хранения своих элементов сбалансированное красно-черное бинарное дерево. Благодаря этому операции add , remove и contains в этой коллекции займут гарантированное время, равное log(n) . А это — весомое преимущество по сравнению с другими имплементациями интерфейса Set .
Интерфейс Queue
Все мы не любим очереди: кому нравится напрасно тратить свое время в ожидании чего-то? Но вы точно полюбите очереди, если научитесь с ним работать 🙂 В Java Collections Framework за работу с очередью отвечает интерфейс Queue, который имеет довольно простую иерархию:

Queue способен упорядочить элементы в очереди по двум основным типам:
- при помощи полученного в конструкторе интерфейса Comparator, который сравнивает новые объекты в очереди с предыдущими;
- с помощью интерфейса Comparable, который необходим для упорядочения элементов в соответствии с их натуральным порядком.
Интерфейс Map
Это коллекция предназначена для работы с данными типа «ключ/значение». Под ключом мы имеем ввиду объект, который используем для извлечения данных, которые он в себе содержит. В структурном плане Map не наследует коллекцию Iterable и имеет ряд уникальных методов, характерных только для него.

У этого интерфейса схожая с Set структурная иерархия классов. Map реализуется с помощью четырех имплементаций: HashMap, TreeMap (о них я писал выше), LinkedHashMap и WeakHashMap:
- LinkedHashMap расширяет функционал HashMap и способен организовать перебор элементов в первоначальном порядке. То есть при осуществлении итерации по методу LinkedHashMap все объекты будут возвращены в строгом порядке их добавления.
- WeakHashMap — класс, который организовывает слабые ссылки объектов со своими ключами. Используется для динамических объектов. Например, при построении систем с функцией сбора мусора. Она не вносится в перечень объектов, подлежащих удалению из-за того, что игнорируется сборщиком мусора при выявлении объектов, которые в ней содержаться.
Коллекции в Java достаточно объемны. Они содержат в себе массу интерфейсов и реализаций, о которых точно можно написать не одну статью.
При этом именно Java Collections Framework включает в себя весь функционал, необходимый для написания многозадачного кода любой сложности.
Правильное понимание принципов работы с коллекциями останется одним из главных навыков для качественного программирования на Java.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Этот материал – не редакционный, это – личное мнение его автора. Редакция может не разделять это мнение.
Highload нужны авторы технических текстов. Вы наш человек, если разбираетесь в разработке, знаете языки программирования и умеете просто писать о сложном!
Откликнуться на вакансию можно здесь .

Начать стоить с самого начала. Почему коллекции (Collection)? Сам термин берёт своё начало из таких вещей, как "Теория типов" и "Абстрактные типы данных". Но если не смотреть на какие-то высокие материи, то когда у нас несколько вещей, то мы можем назвать их "коллекция вещей". Те, кто собирают предметы. Вообще само слово коллекционировать происходит от лат. collectio «собирание, сбор». То есть коллекция — это сбор чего-то, контейнер для каких-то элементов. Итак, у нас есть коллекция элементов. Что мы можем захотеть с ней делать:

Как видно, мы можем захотеть довольно логичные вещи. А ещё мы понимаем, что мы можем захотеть что-то делать с несколькими коллекциями:

Соответственно, для описание такого общего поведения для всех коллекций написали разработчики Java интерфейс java.util.Collection. Интерфейс Collection — это то место, откуда берут начало все коллекции. Collection — это идея, это представление о том, как должны себя вести все коллекции. Поэтому, термин "Коллекция" выражена в виде интерфейса. Естественно, интерфейсу нужны реализации. Интерфейс java.util.Collection имеет абстрактный класс AbstractCollection , то есть некоторая "абстрактная коллекция", которая представляет собой скелет для остальных реализаций (о чём написано в JavaDoc над классом java.util.AbstractCollection ). Говоря о коллекциях вернёмся ещё раз вспомним, что мы хотим итерироваться по ним. Это значит, что мы хотим перебирать элементы один за другим. Это очень важная концепция. Поэтому, интерфейс Collection наследуется от Iterable . Это очень важно, т.к. во-первых, всё что Iterable должно уметь возвращать Iterator по своему содержимому. А во-вторых, всё что Iterable может использоваться в циклах for-each-loop . И именно при помощи итератора в AbstractCollection реализованы такие методы, как contains , toArray , remove . И путь к познанию коллекций начинается с одной из самых распространённых структур данных — списка, т.е. List .

Списки (List)
Итак, списки занимают важное место в иерархии коллекций:

Как мы видим, списки реализуют интерфейс java.util.List. Списки выражают то, что у нас есть коллекция элементов, которые расположены в некоторой последовательности друг за другом. Каждый элемент имеет индекс (как в массиве). Как правило, список позволяет иметь элементы с одинаковым значением. Как мы уже сказали выше, List знает про индекс элемента. Это позволяет получить ( get ) элемент по индексу или задать значением для определённого индекса ( set ). Методы коллекций add , addAll , remove позволяют указать индекс, с которого необходимо их выполнять. Кроме того, у List есть своя версия итератора, которая называется ListIterator . Этот итератор знает про индекс элемента, поэтому он умеет итерироваться не только вперёд, но и назад. Его даже можно создать от определённого места в коллекции. Среди всех реализаций можно выделить две самые часто используемые: ArrayList и LinkedList . Во-первых, ArrayList — это список ( List ) на основе массива ( Array ). Это позволяет добиться "Произвольного доступа" (Random Access) к элементам. Произвольный доступ — это возможность сразу достать элемент по индексу, а не перебирать все элементы, пока не найдём элемент с нужным индексом. Именно массив как основа позволяет этого достичь. Напротив, LinkedList — это связанный (Linked) список (List). Каждая запись в связанном списке представлена в виде Entry , которая хранит сами данные, а так же ссылку на следующую (next) и предыдущую (previous) Entry . Таким образом LinkedList реализует "Последовательный доступ" (Sequential Access). Понятно, что чтобы найти 5-тый элемент нам придётся пройти от первого элемента до последнего, т.к. у нас нет напрямую доступа к пятому элементу. Мы можем получить к нему доступ только от 4-го элемента. Разница в их концепции приведена ниже:

Разбор этой задачи можно посмотреть тут: "Implement A Queue Using Stacks — The Queue ADT ("Implement Queue Using Stacks" on LeetCode)". Вот мы плавно и переходим к новой структуре данных — очередь.

Очередь (Queue)
Очередь (Queue) — это структура, знакомая нам из жизни. Очереди в магазины, к врачам. Кто первее пришёл (First In), тот первее и выйдет из очереди (First Out). В Java очередь представлена интерфейсом java.util.Queue. Согласно Javadoc очереди, очередь добавляет следующие методы:

Как видите, есть методы-приказы (их невыполнение чревато исключением) и есть методы-просьбы (невозможность их выполнить не приводит к ошибкам). Кроме того, можно получить элемент без удаления (peek или элемент). У интерфейса очереди есть так же полезный наследник — Deque. Это так называемая "двусторонняя очередь". То есть такая очередь позволяет использовать эту структуру как с начала, так и с конца. В документации сказано, что "Deques can also be used as LIFO (Last-In-First-Out) stacks. This interface should be used in preference to the legacy Stack class.", то есть вместо Stack рекомендуется использовать реализации Deque. В Javadoc показано, какие методы описывает интерфейс Deque:

- Супер статья на хабре: "Структуры данных. Неформальный гайд"
- Понятное объяснение про "кучу": "Фоксфорд: Информатика. Структуры данных: Куча (heap)"
- Статья с хабра про Binary Heap: "Структуры данных: двоичная куча (binary heap)"
- "Introduction to Binary Heaps (MaxHeaps)"
Давайте посмотрим на какие-нибудь примеры блокирующих очередей. А они ведь интересные. Например, BlockingQueue реализуют: PriorityBlockingQueue, SynchronousQueue, ArrayBlockingQueue, DelayQueue, LinkedBlockingQueue. А вот BlockingDeque реализуют из стандартного Collection Frameworks всего LinkedBlockingDeque . Каждая очередь — тема отдельного обзора. А в рамках данного обзора изобразим иерархию классов не только с List , но и с Queue :

Как мы видим из схемы, интерфейсы и классы Java Collections Framework сильно переплетены. Давайте добавим ещё одну ветвь иерархии — Set .

Set — переводится как "набор". От очереди и списка Set отличается большей абстракцией над хранением элементов. Set — как мешок с предметами, где неизвестно, как лежат предметы и в каком порядке они легли. В Java такой набор представлен интерфейсом java.util.Set. Как сказано в документации, Set — это "collection that contains no duplicate elements". Интересно, что сам интерфейс Set не добавляет новых методов к интерфейсу Collection , а лишь уточняет требования (про то, что не должно содержать дубликатов). Кроме того, из прошлого описания следует, что просто так из Set нельзя получить элемент. Для получения элементов используется Iterator. Set имеет ещё несколько связанных с собой интерфейсов. Первый это SortedSet . Как и следует из названия, SortedSet указывает на то, что такой набор отсортирован, а следовательно элементы реализуют интерфейс Comparable или указан Comparator . Кроме того, SortedSet предлагает несколько интересных методов:

Кроме того, есть методы first (самый маленький по значению элемент) и last (самый большой по значению элемент). У SortedSet есть наследник — NavigableSet . Цель этого интерфейса — описать методы навигации, которые нужны для более точного определения подходящих элементов. Из интересного — NavigableSet добавляет к привычному iterator (который идёт от меньшего к большему) итератор для обратного порядка — descendingIterator . Кроме того, NavigableSet позволяет при помощи метода descendingSet получить вид на себя (View), в котором элементы идут в обратном порядке. Это называется View , потому что через полученный элемент можно изменять элементы изначального Set . То есть по сути это представление изначальных данных другим способом, а не их копия. Интересно, что NavigableSet , подобно Queue , умеет pollFirst (минимальный) и pollLast (максимальный) элементы. То есть получает этот элемент и убирает из набора. Какие же есть реализации? Во-первых, самая известная реализация — на основе хэш-кода — HashSet. Другая не менее известная реализация — на основе красно-чёрного дерева — TreeSet. Давайте дорисуем нашу схему:

В рамках коллекций осталось разобрать иерархию — отшельников. Которая на первый взгляд стоит в стороне — java.util.Map .

Карты (Map)
Закончить можно занимательным фактом, что коллекция Set внутри себя использует Map , где добавляемые значения — это ключи, а значение везде одинаковое. Занимательно это потому, что Map не является коллекцией и возвращает Set , который является коллекцией, но по факту реализован как Map . Немного сюр, но вот так вот вышло )

Заключение
Хорошая новость — на этом данный обзор заканчивается. Плохая новость — это очень обзорная статья. Каждая реализация каждой из коллекций заслуживает отдельную статью, а ещё на каждый скрытый от наших глаз алгоритм. Но цель данного обзора - вспомнить, какие они есть и какие связи между интерфейсами. Надеюсь, у Вас получится после вдумчивого прочтения нарисовать по памяти схему коллекций.
Java Collections Framework это коллекция интерфейсов и классов, которые используются для сохранения и обработки данных.

Java Collections Framework состоит из следующих компонентов:
- List это упорядоченный список объектов (иногда еще называют последовательностью объектов). Элементы списка могут вставляться или извлекаться по их индексу в списке (индексация начинается с 0). В эту группу входят: ArrayList , LinkedList , Vector , Stack .
- Set это не упорядоченная коллекция. Главная особенность множеств - уникальность элементов, то есть один и тот же элемент не может содержаться в множестве дважды. Есть такие имплементации Set интерфейса: HashSet , TreeSet , LinkedHashSet , EnumSet . HashSet хранит элементы в хэш-таблице, что предполагает эффективную реализацию, но не гарантирует порядок итерации элементов. TreeSet хранит элементы в красно-чёрном дереве и упорядочивает элементы по их значениям, эта коллекция существено медленее чем HashSet . LinkedHashSet реализована как хэш-таблица и хранит элементы в связаном списке, в порядке котором они были вставленны.
- Map (иногда можно встретить названия: отображения, словарь, ассоциативный массив, карты) отображает ключи в значения и не может иметь дубликаты ключей. Есть три основных имплементации Map интерфейса HashMap , TreeMap и LinkedHashMap . HashMap не гарантирует воспроизводимость порядка вставки элементов. TreeMap хранит элементы в красно-чёрном дереве и упорядычивает элементы по их ключам и медленее чем HashMap . LinkedHashMap упорядычивает элементы в порядке их вставки.
- Iterator / ListIterator используются для итерации элементов коллекции. Основное отличие между Iterator и ListIterator в том, что первый позволяет итерировать только в одном направлении, а второй в обоих направлениях.
Выше сказаное можно резюмировать в такой таблице

Производительность методов каждого класса можно записать через O-нотацию
| Метод | Тип | Время |
|---|---|---|
| get, set | ArrayList | O(1) |
| add, remove | ArrayList | O(n) |
| contains, indexOf | ArrayList | O(n) |
| get, put, remove, containsKey | HashMap | O(1) |
| add, remove, contains | HashSet | O(1) |
| add, remove, contains | LinkedHashSet | O(1) |
| get, set, add, remove (с любого конца) | LinkedList | O(1) |
| get, set, add, remove (по индексу) | LinkedList | O(n) |
| contains, indexOf | LinkedList | O(n) |
| peek | PriorityQueue | O(1) |
| add, remove | PriorityQueue | O(log n) |
| remove, get, put, containsKey | TreeMap | O(log n) |
| add, remove, contains | TreeSet | O(log n) |
ArrayList
ArrayList это массив с изменяемым количесвтом элементов (стандартный array имеет фиксированый размер), его элементы могут быть доступны непосредственно по индексу. Он реализует все операции списка и позволят вставлять все объекты, включая null . Контейнер ArrayList , оптимизированный для произвольного доступа к элементам, но с относительно медленными операциями вставки/удаления элементов в середине списка.
В случае переполнения массива появляется необходимость в новом, имеющем больше места. Размещение и перемещение всех элементов будет занимать O(n) времени. Также, необходимо добавление и удаление элементов для передвижения существующих элементов в массиве. Это, возможно, самое большое неудобство в использовании ArrayList .
Поиск в ArrayList проходит за O(1). Удаление первого элемента (худший случай) происходит за O(n), для последнего элемента (лучший случай) за O(1). Вставка происходит за O(n).
LinkedList
LinkedList — это связанный список ссылок на элементы. Таким образом, для доступа к элементу в центре, приходится производить поиск с самого начала и до конца листа. С другой стороны, добавление и удаление элемента в LinkedList быстрее (чем в ArrayList ) по той причине, что эти операции лишь изменяют сам список.
Контейнер LinkedList , оптимизированный для последовательного доступа, с быстрыми операциями вставки/удаления в середине списка. Произвольный доступ к элементам LinkedList выполняется относительно медленно, т.к. требует полного перебора элементов. Класс представляет структуру данных связного списка и реализует интерфейсы List , Dequeue , Queue .
Поиск в LinkedList проходит за O(n). Удаление происходит за O(1). Вставка происходит за O(1).
Сравнение LinkedList и ArrayList по скорости операций:
| Метод | Arraylist | LinkedList |
|---|---|---|
| get(index) | O(1) | O(n) |
| add(E) | O(n) | O(1) |
| add(E, index) | O(n) | O(n) |
| remove(index) | O(n) | O(n) |
| Iterator.remove() | O(n) | O(1) |
| Iterator.add(E) | O(n) | O(1) |
Сравнеие производительности Arraylist и LinkedList

Vector
Vector это динамический массив, похожий на ArrayList , за исключением двух моментов: Vector синхронизирован (потоко-безопасен) и Vector содержит много legacy-методов. По умолчанию, Vector удваивает свой размер когда заканчивается выделенная под элементы память. ArrayList же увеличивает свой размер только на половину.
Stack
Стэк является подкласом Vector и работает по принципу LIFO (last-in-first-out rule) - последним пришел, первым ушел. Обратите внимание, что Stack и Vector оба потокобезопасны. Используйте стэк если вы хотите вставлять и удалять элементы только с вершины стэка, что полезно в рекурсивных алгоритмах.
HashSet , TreeSet и LinkedHashSet относятся к семейству Set . В множествах Set каждый элемент хранится только в одном экземпляре, а разные реализации Set используют разный порядок хранения элементов. В HashSet порядок элементов определяется по сложному алгоритму и не гарантирует порядок в котором элементы вставлялись. Если порядок хранения для вас важен, используйте контейнер TreeSet , в котором объекты хранятся отсортированными по возрастанию в порядке сравнения или LinkedHashSet с хранением элементов в порядке добавления.
Множества часто используются для проверки принадлежности, чтобы вы могли легко проверить, принадлежить ли объект заданному множеству, поэтому на практике обычно выбирается реализация HashSet , оптимизированная для быстрого поиска.
Сравним времени на операцию add() для HashSet , TreeSet , LinkedHashSet .

HashSet
HashSet расширяет AbstractSet и реализует интерфейс Set . HashSet создает коллекцию, которая использует хеш-таблицу для сохранения своих значений. Класс Object и его наследники имеют метод hashCode() , который используется классом HashSet для эффективного размещения объектов, заносимых в коллекцию. Ключ используется для определения уникальности элемента и называется хеш-кодом.
- HashSet не поддерживает порядок своих элементов, а это значит, что элементы будут возвращены в любом порядже.
- HashSet не разрешает хранить дубликаты. Если вы добавите существующий элемент, то старое значение будет переписано.
- HashSet разрешает добавить в колекцию null значение, но только одно значение.
- HashSet не синхронизировано.
LinkedHashSet
Класс LinkedHashSet расширяет класс HashSet , не добавляя никаких новых методов. Класс поддерживает связный список элементов множества в том порядке, в котором они вставлялись.
TreeSet
TreeSet реализует интерфейс SortedSet .
Класс TreeSet создаёт коллекцию, которая для хранения элементов использует дерево. Объекты сохраняются в отсортированном порядке по возрастанию.
Время доступа к элементам небольшое, что делает TreeSet отличным выбором для сохранения большого количкства отсортироыанных данных и к которым должен быть обеспечен быстрый доступ.
TreeSet не поддерживает хранение элементов типа null .
NavigableSet
Интерфейс NavigableSet наследуется от SortedSet и предоставляет возможность навигации по множеству в обоих направлениях.
Очереди предствляют собой упорядоченый список элементов, т.к. реализуют интерфейс List , но есть особености использования. Элементы вставляются в конец очереди, а извлекаются из начала очереди. Обычно, но не обязательно, очереди работают по принципу FIFO — первым пришел, первым ушел.
Используйте очередь если вы хотите обрабатывать поток элементов в том же порядке в котором они поступают. Хорошо для списка заданий и обработки запросов.
Queue
В Java Collections API интерфейс Queue реализован в
- LinkedList - реализует принцип FIFO.
- PriorityQueue - хранит элементы либо в естественном порядке (natural order) либо в соответсвии с Comparator , переданым в конструктор.
Deque
Deque (Double Ended Queues) это двухсторонняя очередь, которая позволяет вставлять/удалять элементы как с конца очереди, так и с начала. Deque интерфейс расширяет Queue интерфейс.
В Java Collections API интерфейс Deque реализован в
- ArrayDeque - базируется на массиве и используется при реализации стэка (принцип LIFO).
- LinkedList - базируется на двух-связном списке и используется при реализации очереди (принцип FIFO).
В контейнерах Map (отображения, словарь, ассоциативный массив, карты) хранятся два объекта: ключ и связанное с ним значение. Map позволяет искать объекты по ключу. Объект, ассоциированный с ключом, называется значением. И ключи, и значения являются объектами. Ключи могут быть уникальными, а значения могут дублироваться. Некоторые отображения допускают пустые ключи и пустые значения.
Интерфейс Map соотносит уникальные ключи со значениями. Ключ - это объект, который вы используете для последующего извлечения данных. Задавая ключ и значение, вы можете помещать значения в объект отображения. После того как это значение сохранено, вы можете получить его по ключу.
Основные методы - get() и put() , чтобы получить или поместить значения в отображение.
Интерфейс Map предоставляет три представления (view) хранящихся данных:
- множество всех ключей
- множество всех значений
- множество объектов Entry , содержащих в себе и ключ и значение
Отображения не поддерживают реализацию интерфейса Iterable , поэтому нельзя перебрать карту через цикл for в форме for-each . Можно перебрать отдельно ключи или значения или объекти Entry .
Интерфейс SortedMap расширяет интерфейс Map и гарантирует, что элементы размещаются в возрастающем порядке значений ключей.
Интерфейс NavigableMap расширяет интерфейс SortedMap и определяет поведение отображения, поддерживающее извлечение элементов на основе ближайшего соответствия заданному ключу или ключам.
Интерфейс Map.Entry позволяет работать с элементом отображения, в частности используется при переборе элементов. Основные мотеды интерфейса Map.Entry
- equals(Object o) сравнение на равенство двух элементов
- getKey() получить ключ элемента
- getValue() получить значение элемента
- hashCode() получить хэш-код элемента
- setValue(V value) замена значения элемента на value
HashMap
HashMap использует хэш-таблицу для реализации Map интерфейса, что позволяет операциям get() и put() выполнятся за константное время даже для больших наборов. HashMap обеспечивает максимальную скорость выборки, а порядок хранения его элементов не очевиден.
HashMap подобен Hashtable с нескольками исключениямия:
- HashTable потокобезопасна, а HashMap нет
- HashTable не может содержать элементы null , тогда как HashMap может содержать один ключ null и любое количество значений null
- Итератор у HashMap , в отличие от перечислителя HashTable , работает по принципу fail-fast (выдает исключение при любой несогласованности данных)
TreeMap
TreeMap реализует Map интерфейс с помощью структуры красно-чёрного дерева и хранит ключи отсортированными по возрастанию (естественный порядок, natural order). Переопределить сортировку можно предоставив экземпляр класса Comparator , метод compare которого и будет использован для сортировки ключей. Обратите внимание, что все ключи добавленные в словарь должны реализовывать интерфейс Comparable (это необходимо для сортировки).
TreeMap предоставляет быстрый доступ к своим элементам.
Для вставки, удаления и поиска элементов в Map лучше использовать HashMap . Если же нужно последовательно обходить карты в неком порядке то лучше использовать TreeMap . Иногда, в зависимости от размера коллекции, лучше добавить элементы в HashMap , а потом сконвертировать в TreeMap для упорядоченого обхода элементов.
LinkedHashMap
LinkedHashMap реализует связанный список элементов отображения и хранит ключи в порядке вставки. Также позволяет сортировать элементы в порядке последнего доступа. LinkedHashMap не обеспечивает скорость поиска как HashMap .
Читайте также: