
Что такое veritas oracle
Обновлено: 05.07.2024
Veritas Cluster Server (переименованный в Veritas Infoscale Availability, также известный как VCS и также продаваемый в комплекте с продуктом SFHA ) - это кластерное программное обеспечение высокой доступности для компьютерных систем Unix , Linux и Microsoft Windows , созданное Veritas Technologies . Он предоставляет возможности кластера приложений для систем, на которых работают другие приложения, включая базы данных , совместное использование файлов в сети и веб-сайты электронной коммерции .
СОДЕРЖАНИЕ
Описание
Кластеры высокой доступности (HAC) улучшают доступность приложений за счет сбоя или переключения их в группе систем - в отличие от высокопроизводительных кластеров , которые повышают производительность приложений за счет их одновременного запуска в нескольких системах.
Большинство реализаций Veritas Cluster Server пытаются обеспечить доступность в кластере, устраняя единые точки отказа за счет использования избыточных компонентов, таких как несколько сетевых карт, сетей хранения данных в дополнение к использованию VCS.
Подобные продукты включают Fujitsu PRIMECLUSTER , IBM PowerHA System Mirror , HP Serviceguard , IBM Tivoli System Automation for Multiplatforms (SA MP), Linux-HA , OpenSAF , Microsoft Cluster Server (MSCS), NEC ExpressCluster , Red Hat Cluster Suite , SteelEye LifeKeeper и Sun Кластер . VCS - один из немногих продуктов в отрасли, который обеспечивает как высокую доступность, так и аварийное восстановление для всех основных операционных систем, одновременно поддерживая более 40 основных технологий приложений / репликации из коробки.
Базовая архитектура VCS включает LLT (транспорт с низкой задержкой), GAB (глобальные службы членства и протокол атомарной широковещательной рассылки), HAD (демон высокой доступности) и кластерные агенты.
LLT находится в нижней части архитектуры и действует как канал между GAB и базовой сетью. Он получает информацию от GAB и передает ее намеченным узлам-участникам. Хотя модуль LLT на одном узле взаимодействует с каждым другим узлом в кластере, связь между отдельными узлами всегда 1: 1. Таким образом, в случае, если определенная информация должна быть передана через все узлы кластера, предполагая кластер из 6 узлов, 6 различных пакетов отправляются через целевые межсоединения отдельных машин.
GAB определяет, какие машины являются частью кластера, и минимальное количество узлов, которые должны присутствовать и работать для формирования кластера (это минимальное количество называется начальным числом). GAB действует как абстрактный уровень, к которому могут быть подключены другие службы кластера. Каждая из этих служб кластера должна регистрироваться в GAB, и ей назначается заранее определенное уникальное имя порта (один алфавит). GAB имеет как клиентский, так и серверный компонент. Клиентский компонент используется для отправки информации с использованием уровня GAB и регистрируется в серверном компоненте как порт "a". HAD регистрируется в GAB как порт "h". Серверная часть GAB взаимодействует с модулями GAB на других узлах кластера для сохранения информации о членстве в отношении различных портов. Информация о членстве сообщает, все ли модули кластера, соответствующие портам (например, GAB (порт «a»), HAD (порт «h») и т. Д.) На разных узлах кластера, находятся в хорошем состоянии и могут ли взаимодействовать друг с другом заданным образом. .
Уровень HAD - это место, где обеспечивается фактическая высокая доступность приложений. Это место, где приложения фактически подключаются к платформе высокой доступности. HAD регистрируется в GAB на порту "h". Модуль HAD, работающий на одном узле, взаимодействует с модулями HAD, работающими на других узлах кластера, чтобы гарантировать, что все узлы кластера имеют одинаковую информацию о конфигурации и состоянии кластера.
Чтобы приложения могли подключаться к High Availability Framework, ему необходимо программное обеспечение Cluster Agent. Программное обеспечение агента кластера может быть общим или специфическим для каждого типа приложения. Например, чтобы Oracle использовала структуру HA (High Availability) в VCS, ей необходимо программное обеспечение агента. VCS в основе своей является общим программным обеспечением кластера и может не знать, как различные приложения запускаются, останавливаются, отслеживают, очищают и т. Д. Эта информация должна быть закодирована в программном обеспечении агента. Программное обеспечение агента можно рассматривать как переводчик между приложением и средой высокой доступности. Например, если HAD необходимо остановить базу данных Oracle, по умолчанию он не будет знать, как ее остановить, однако, если на нем запущен агент Oracle DB, он попросит агент Oracle остановить базу данных и, по определению, агент выдаст команды, специфичные для версии и конфигурации БД, и отслеживание состояния остановки.
Важные файлы, в которых хранится информация о конфигурации кластера:
LLT: / etc / llttab, / etc / llthosts
GAB: / etc / gabtab
HAD (VCS): /etc/VRTSvcs/conf/config/main.cf, /etc/VRTSvcs/conf/config/types.cf, / etc / VRTSvcs / conf / sysname
Veritas Cluster Server для Windows доступен как отдельный продукт. Он также продается в комплекте с Storage Foundation как Storage Foundation HA для Windows; Veritas Cluster Server для AIX, HP-UX, Linux и Solaris поставляется как отдельный продукт.
Продукт Veritas Cluster Server включает консоль управления VCS - программное обеспечение для управления несколькими кластерами, которое автоматизирует аварийное восстановление в центрах обработки данных.
Вопрос связан с желанием че-нить натюнить.
В текущей конфигурации спользуется oracle 11 в качестве датафайлов raw devices (volumes of VxVM).
На сколько понял из почерпнутой инфы от симантика, Veritas Quick IO, при использовании фс, по производительности можно приравнять к raw devic`ам (допоускаю такой вариант при использовании специальных алгоритмов). Но основоной вопрос не в этом, а в Veritas ODM: будет ли прирост в скорости (дисковой производительности) если мою конфигурацию использовать с ODM? В рекламной документации вроде как лучше, но интересно за счет чего, был ли у кого практический опыт?
Тут народ на 99.99% состоит из колхозников, которые в лучшем случае низкобюджетные NAS видели, и то, у "знакомых".
Практические тесты показывают, что в случае решений Symantec/Veritas разницы между RAW, ODM и QuickIO нет, вернее она в несчастных процентах, т.е. роли никакой не играет.
Выбор же той или иной технологии лежит исключительно в плоскости тех или иных фич (Resilvering vs DRL) и вопросов их лицензирования.
И вообще этот сама постановка как-бы идиотична. ODM сделан специально для Oracle, тем
самым - наиболее логичная с практической точки зрения (даже в вопросах техподдержки).
по поводу "сказали вам строем ходить - идите, не стесняйтесь" это к нам не очень относится. Некоторе право голоса имеем, потому и хочу разобраться.
У поддержки спрашивал - говорят "Ну да, с использованием ODM должно быть лучше". А как это достигается, какой механизм - никто не отвечает.
Проскакивает кое-где информация о том что в ODM используется меньший набор функций для операций ввода-вывода (две или три) по сравнению с библиотеками Oracle (около 10, если не ошибаюсь), но как это влияет на производительность - не понимаю.
Так же про фичи - может правда есть какие-нибудь полезности? но ни где не нашел их описания.
по поводу "сказали вам строем ходить - идите, не стесняйтесь" это к нам не очень относится. Некоторе право голоса имеем, потому и хочу разобраться.
У поддержки спрашивал - говорят "Ну да, с использованием ODM должно быть лучше". А как это достигается, какой механизм - никто не отвечает.
Нашел, вот тока ни кто не хочет объяснять - так как не могут, не понимают, один ты умничаешь а толку нет.
Вот ответь хотябы на такой вопрос, где правда в докуметации от симантека или SUN?:
SUN:
Solaris
KAIO is available for raw devices and Quick I/O files.
No special configuration is required.
так что же тогда включает ODM при использовании raw девайсов?
Мне эти знания и твои "на слабо" - глубоко фиолетовы. А так - вообще ответы на такие вопросы стоят денег.
Задавай их сразу поставщикам оборудования.
Может быть тебе что-то и ответят.
ODM помогает только для файловой системы VxFS, для разных типов нагрузки OLTP/DSS получаются разные результаты, но обычно VxFS+ODM отстает от raw devices/volumes процентов на 5-10, процентов 10-15 выигрывает у ASM-а и много выигрывает у UFS/ext3/ZFS (иногда в разы). Это все из практики на больших базах.
Сейчас есть Cached ODM, который еще не удалось попробовать, но заявляется, что для OLTP-нагрузок он даже быстрее raw devices за счет кеширования.
про Quick I/O нужно понемногу забывать, т.к. ODM включает в себя все features Quick I/O (кроме неудобств с псевдо-именами :-)
единственное исключение из этого, если использовать свежий ODM и старый Oracle 9i - не поддерживается - либо использовать старую версию ODM-а, либо Quick I/O (или перейти хотя бы на Oracle 10g - с ним поддерживается).
использовать ODM с raw devices/volumes можно, но такого прироста производительности как с файловой системой VxFS не будет
ODM помогает только для файловой системы VxFS, для разных типов нагрузки OLTP/DSS получаются разные результаты, но обычно VxFS+ODM отстает от raw devices/volumes процентов на 5-10, процентов 10-15 выигрывает у ASM-а и много выигрывает у UFS/ext3/ZFS (иногда в разы). Это все из практики на больших базах.
Сейчас есть Cached ODM, который еще не удалось попробовать, но заявляется, что для OLTP-нагрузок он даже быстрее raw devices за счет кеширования.
про Quick I/O нужно понемногу забывать, т.к. ODM включает в себя все features Quick I/O (кроме неудобств с псевдо-именами :-)
единственное исключение из этого, если использовать свежий ODM и старый Oracle 9i - не поддерживается - либо использовать старую версию ODM-а, либо Quick I/O (или перейти хотя бы на Oracle 10g - с ним поддерживается).
использовать ODM с raw devices/volumes можно, но такого прироста производительности как с файловой системой VxFS не будет
Сервер Veritas Cluster Server обеспечивает высокую готовность наиболее важных приложений в центре хранения данных. Он автоматически реагирует на сбои, выполняя восстановление приложений. В случае выхода из строя всего сайта он перезапускает приложения в другом центре хранения данных, поэтому даже в случае аварии IT-услуги остаются доступными.
Большинство критически важных для бизнеса приложений состоят сегодня из нескольких звеньев, включающих в себя, например, веб-компоненты, собственно приложения, промежуточное ПО и базы данных. Все они размещаются на различных серверах, платформах, на физических и виртуальных ресурсах, использующих различные системы хранения данных. Поэтому обеспечение полной доступности бизнес-сервисов является серьезной проблемой в наши дни. IT-компаниям приходится работать с множеством инструментов, выполнять ряд ручных операций и обеспечивать координацию действий групп специалистов в случае недоступности сервиса – как запланированного, так и внепланового.
Veritas Cluster Server 6.0 и Symantec Application HA 6.0, поддерживающие новую функцию Virtual Business Services (VBS) созданы специально для постоянной поддержки высокого уровня готовности и сокращения перерывов доступа к сервисам для всего спектра современных бизнес-приложений. Они позволяют управлять многозвеньевой структурой как единым целым. Администраторы могут запускать, останавливать, проводить тестирование без влияния на доступность сервисов и восстанавливать комплексные приложения в один клик мышкой, обеспечивая гибкость и мобильность для бизнес-сервисов. Veritas Cluster Server предлагает пользователям удобные средства для поддержки приложений без дополнительного конфигурирования. Система доступна для всех популярных ОС и платформах виртуализации, включая IBM AIX, HP-UX, Oracle Solaris, Linux, Microsoft Windows и VMware.
Компания Symantec выпустила в сентябре 2012 года бесплатное расширение для своей кластерной файловой системы Veritas Cluster File System для сетей хранения данных, которое значительно сокращает стоимость аналитической обработки больших массивов корпоративных данных.
Своим названием новое решение Symantec обязано программной платформе с открытыми исходными текстами Apache Hadoop, предназначенной для разработки систем аналитической обработки больших массивов данных. Такие системы могут проанализировать массив информации размером в несколько петабайт и выявить важные для бизнеса закономерности и тенденции. Например, определить пользовательские предпочтения или дать рекомендации по ценовой политике, основываясь на сведениях базы данных продаж.
Symantec Enterprise Solution for Hadoop образует дополнительный уровень в сети хранения данных SAN под управлением Veritas Cluster File System, который позволяет подключить аналитические приложения непосредственно к «живым» базам данных. Это избавляет от затрат на построение и сопровождение отдельного хранилища данных для системы аналитической обработки, а также устраняет дорогостоящие операции по копированию в нее данных основных бизнес-приложений.
Новое решение Symantec разработано в сотрудничестве со специалистами компании Hortonworks, предоставляющей услуги и поддержку в рамках проекта Apache Hadoop. По заявлению разработчиков, решение значительно повышает оперативность анализа, обеспечивает функции повышенной доступности, позволяет выполнять несколько аналитических задач без снижения производительности и обеспечивает обработку массивов информации размером до 16 петабайт.
Symantec Enterprise Solution for Hadoop поддерживает системы аналитической обработки больших массивов данных Hortonworks Data Platform 1.0 и Apache Hadoop 1.0.2.
Основные функции
- Обеспечивает автоматическое аварийное переключение приложений и баз данных в пределах локального центра хранения данных или на несколько удаленных центров хранения данных.
- Поддерживает разнотипные физические и виртуальные операционные системы благодаря наличию готовых решений для всех основных баз данных, приложений и типов памяти.
- Обеспечивает полное тестирование послеаварийного восстановления без сбоев в работе приложений.
- Позволяет контролировать, настраивать и создавать отчеты для нескольких кластеров Veritas на различных платформах через одну консоль с веб-интерфейсом.
Основные особенности
- Обеспечивает готовность наиболее важных приложений и баз данных во время плановых или внеплановых перерывов в работе, отслеживая состояние приложений и перенося их на другие ресурсы в случае аварии или сбоя.
- Сокращает затраты на обучение и труд, а также лицензирование и поддержку программного обеспечения за счет применения единого инструмента работы с кластерами для всех платформ физических и виртуальных операционных систем.
- Обеспечивает уверенность в эффективности выбранного плана послеаварийного восстановления.
- Повышает эффективность работы администратора благодаря расширенным функциям визуализации, автоматизации стандартных задач создания отчетов, централизованному контролю за работой глобальных приложений и централизованному управлению уведомлениями на основе политик.
Veritas Cluster Server 6.0
Компания Symantec объявила осенью 2012 года о реализации новых функций для восстановления и сохранения работоспособности систем в очередной версии своего решения Veritas Cluster Server (VCS) 6.0. Обновленная система VCS обеспечивает восстановление виртуальных машин в аварийных ситуациях без заметных простоев для конечных пользователей.
Официальный выпуск новой версии VCS 6.0 запланирован на 22 октября 2012 года. В этом решении администраторы заказчикам смогут легко переключать проблемную виртуальную машину на новую платформу. Причиной для такого переключения могут послужить различные сбои в работе приложений, виртуализованной операционной системы или гипервизора ESX. В ходе процедуры аварийного переключения вся нагрузка исходной машины переносится на новую виртуальную машину, создаваемую на другом гипервизоре, которые не испытывает проблем с исполнением нагрузки.
Представители компании Symantec, которая сейчас владеет маркой Veritas, подчеркивают, что в традиционных системах проблемы в операционной системе внутри виртуальной машины не позволяют выполнить аварийное переключение, поскольку уровень сбоя оказывается слишком серьезным. Тем не менее, в новой версии технологии кластеризации VCS такую виртуальную машину со сбоями легко перенести на другую виртуальную машину в кластере, где проблем не наблюдается. Таким образом, работу приложения можно продолжить вообще без простоев. Поскольку никаких перезагрузок виртуальных машин не требуется, подобный подход практически полностью исключает простои при устранении отказов.
Предыдущая версия Symantec VCS уже предлагала заказчикам функции для обеспечения повышенной доступности для виртуальных машин, но только на случай аппаратных сбоев, но не сбоев в приложениях. Кроме того, у инструментов Symantec VCS есть серьезное преимущество по сравнению со встроенными технологиями в платформе VMware – это защита и оборудования, и программного обеспечения с использованием одних и тех же инструментов управления. Фактически, технология Symantec VCS обеспечивает централизованный контроль повышенной доступности приложений как для физических, так и для виртуальных серверов.
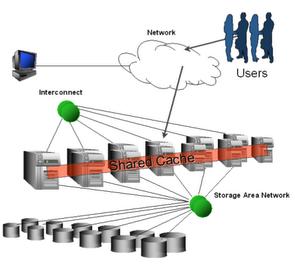
Высоконагруженные сайты, доступность "5 nines". На заднем фоне (backend) куча обрабатываемой информации в базе данных. А что, если железо забарахлит, если вылетит какая-то давно не проявлявшаяся ошибка в ОС, упадет сетевой интерфейс? Что будет с доступностью информации? Из чистого любопытства я решил рассмотреть, какие решения вышеперечисленным проблемам предлагает Oracle . Последние версии, в отличие от Oracle 9i, называются Oracle 10g (или 11g), где g - означает "grid", распределенные вычисления. В основе распределенных вычислений "как ни крути" лежат кластера, и дополнительные технологии репликации данных (DataGuard, Streams). В этой статье в общих чертах описано, как устроен кластер на базе Oracle 10g. Называется он Real Application Cluster ( RAC ).
Статья не претендует на полноту и всеобъемлемость, также в ней исключены настройки (дабы не увеличивать в объеме). Смысл - просто дать представление о технологии RAC.
Статью хотелось написать как можно доступнее, чтобы прочесть ее было интересно даже человеку, мало знакомому с СУБД Oracle. Поэтому рискну начать описание с аспектов наиболее часто встречаемой конфигурации БД - single-instance, когда на одном физическом сервере располагается одна база данных (RDBMS) Oracle. Это не имеет непосредственного отношения к кластеру, но основные требования и принципы работы будут одинаковы.
Введение. Single-instance.
- область хранения данных, т.е. физические файлы на диске (datastorage) (сама БД)
- экземпляр БД (получающая и обрабатывающая эти данные в оперативной памяти) (СУБД)
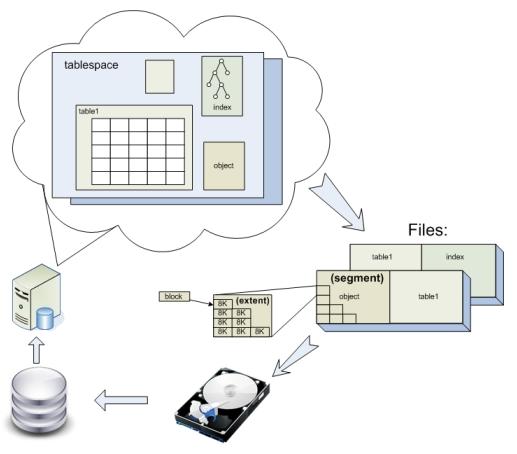
Во всех современных реляционных БД данные хранятся в таблицах. Таблицы, индексы и другие объекты в Oracle хранятся в логических контейнерах - табличных пространствах ( tablespace ). Физически же tablespace располагаются в одном или нескольких файлах на диске. Хранятся они следующим образом:
Каждый объект БД (таблицы, индексы, сегменты отката и.т.п.) хранится в отдельном сегменте - области диска, которая может занимать пространство в одном или нескольких файлах. Сегменты в свою очередь, состоят из одного или нескольких экстентов. Экстент - это непрерывный фрагмента пространства в файле. Экстенты состоят из блоков. Блок - наименьшая единица выделения пространства в Oracle, по умолчанию равная 8K. В блоках хранятся строки данных, индексов или промежуточные результаты блокировок. Именно блоками сервер Oracle обычно выполняет чтение и запись на диск. Блоки имеют адрес, так называемый DBA ( Database Block Address ).
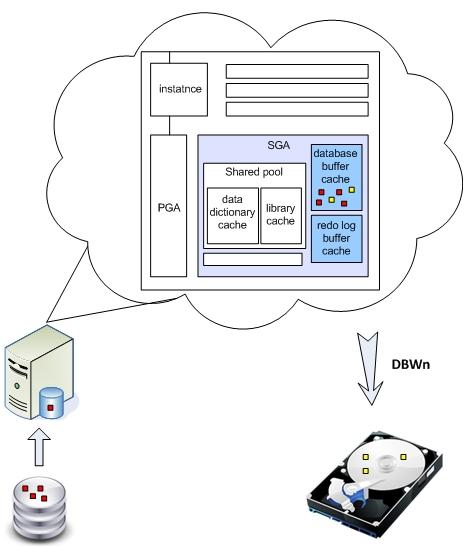
При любом обращении DML (Data Manipulation Language) к базе данных, Oracle подгружает соответствующие блоки с диска в оперативную память, а именно в буферный кэш . Хотя возможно, что они уже там присутствуют, и тогда к диску обращаться не нужно. Если запрос изменял данные (update, insert, delete), то изменения блоков происходят непосредственно в буферном кэше, и они помечаются как dirty (грязные). Но блоки не сразу сбрасываются на диск. Ведь диск - самое узкое место любой базы данных, поэтому Oracle старается как можно меньше к нему обращаться. Грязные блоки будут сброшены на диск автоматически фоновым процессом DBWn при прохождении контрольной точки (checkpoint) или при переключении журнала.
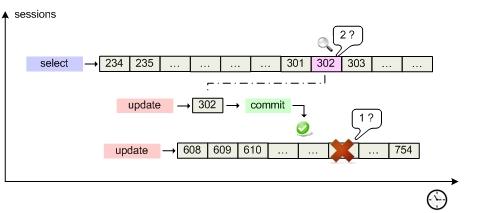
- Что будет, если Oracle упадет где-то на середине длинной транзакции (если бы она вносила изменения)?
- Какие же данные прочтет первая транзакция, когда в кэше у нее "под носом" другая транзакция изменила блок?
- журнал повтора (redo log)
- сегмент отмены (undo)
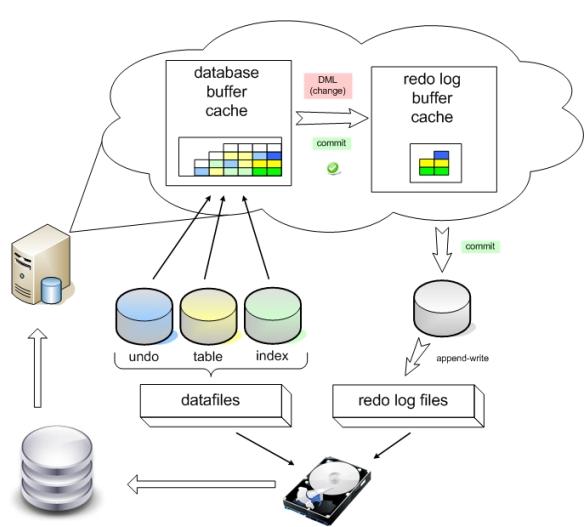
Когда в базу данных поступает запрос на изменение, то Oracle применяет его в буферном кэше, параллельно внося информацию, достаточную для повторения этого действия, в буфер повторного изменения ( redo log buffer ), находящийся в оперативной памяти. Как только транзакция завершается, происходит ее подтверждение (commit), и сервер сбрасывает содержимое redo buffer log на диск в redo log в режиме append-write и фиксирует транзакцию. Такой подход гораздо менее затратен, чем запись на диск непосредственно измененного блока. При сбое сервера кэш и все изменения в нем потеряются, но файлы redo log останутся. При включении Oracle начнет с того, что заглянет в них и повторно выполнит изменения таблиц (транзакции), которые не были отражены в datafiles. Это называется "накатить" изменения из redo, roll-forward. Online redo log сбрасывается на диск ( LGWR ) при подтверждении транзакции, при прохождении checkpoint или каждые 3 секунды (default).
С undo немного посложнее. С каждой таблицей в соседнем сегменте хранится ассоциированный с ней сегмент отмены . При запросе DML вместе с блоками таблицы обязательно подгружаются данные из сегмента отката и хранятся также в буферном кэше. Когда данные в таблице изменяются в кэше, в кэше так же происходит изменение данных undo, туда вносятся "противодействия". То есть, если в таблицу был внесен insert, то в сегмент отката вносится delete, delete - insert, update - вносится предыдущее значение строки. Блоки (и соответствующие данные undo) помечаются как грязные и переходят в redo log buffer. Да-да, в redo журнал записываются не только инструкции, какие изменения стоит внести (redo), но и какие у них противодействия (undo). Так как LGWR сбрасывает redo log buffer каждые 3 секунды, то при неудачном выполнении длительной транзакции (на пару минут), когда после минуты сервер упал, в redo будут записи не завершенные commit. Oracle, как проснется, накатит их (roll-forward), и по восстановленным (из redo log) в памяти сегментам отката данных отменит (roll-back) все незафиксированные транзакции. Справедливость восстановлена.
Кратко стоит упомянуть еще одно неоспоримое преимущество undo сегмента. По второму сценарию (из схемы) когда select дойдет до чтения блока (DBA) 500, он вдруг обнаружит что этот блок в кэше уже был изменен (пометка грязный), и поэтому обратится к сегменту отката, для того чтобы получить соответствующее предыдущее состояние блока. Если такого предыдущего состояния (flashback) в кэше не присутствовало, он прочитает его с диска, и продолжит выполнение select. Таким образом, даже при длительном "select count(money) from bookkeeping" дебет с кредитом сойдется. Согласованно по чтению (CR).
Отвлеклись. Пора искать подступы к кластерной конфигурации. =)
Уровень доступа к данным. ASM.
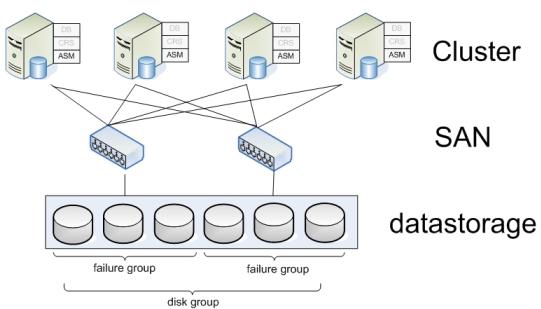
Хранилищем ( datastorage ) в больших БД почти всегда выступает SAN ( Storage Area Network ), который предоставляет прозрачный интерфейс серверам к дисковым массивам.
Сторонние производители (Hitachi, HP, Sun, Veritas) предлагают комплексные решения по организации таких SAN на базе ряда протоколов (самым распространенным является Fibre Channel), с дополнительными функциональными возможностями: зеркалирование, распределение нагрузки, подключение дисков на лету, распределение пространства между разделами и.т.п.
Позиция корпорации Oracle в вопросе построения базы данных любого масштаба сводится к тому, что Вам нужно только соответствующее ПО от Oracle (с соответствующими лицензиями), а выбранное оборудование - по возможности (если средства останутся после покупки Oracle :). Таким образом, для построения высоконагруженной БД можно обойтись без дорогостоящих SPARC серверов и фаршированных SAN, используя сервера на бесплатном Linux и дешевые RAID-массивы.
На уровне доступа к данным и дискам Oracle предлагает свое решение - ASM ( Automatic Storage Management ). Это отдельно устанавливаемый на каждый узел кластера мини-экземпляр Oracle (INSTANCE_TYPE = ASM), предоставляющий сервисы работы с дисками.
Oracle старается избегать обращений к диску, т.к. это является, пожалуй, основным bottleneck любой БД. Oracle выполняет функции кэширования данных, но ведь и файловые системы так же буферизуют запись на диск. А зачем дважды буферизировать данные? Причем, если Oracle подтвердил транзакцию и получил уведомления том, что изменения в файлы внесены, желательно, чтобы они уже находились там, а не в кэше, на случай "падения" БД. Поэтому рекомендуется использовать RAW devices (диски без файловой системы), что делает ASM.
- отсутствие необходимости в отдельном ПО для управления разделами дисков
- нет необходимости в файловой системе
Disk group - объединение нескольких дисков. При записи файлов на диски данные записываются экстентами размерами по 1 МБ, распределяя их по всем дискам в группе. Это делается для того, чтобы обеспечить высокую доступность, ведь части одной таблицы (из tablespace) разбросаны по разным физическим дискам.
- Зеркалирование данных:
как правило, 2-х или 3-х ступенчатое, т.е. данные одновременно записываются на 2 или 3 диска. Для зеркалирования диску указываются не более 8 дисков-партнеров, на которые будут распределяться копии данных. - Автоматическая балансировка нагрузки на диски (обеспечение высокой доступности):
если данные tablespace разместить на 10 дисках и, в некоторый момент времени, чтение данных из определенных дисков будет "зашкаливать", ASM сам обратится к таким же экстентам, но находящимся на зеркалированных дисках. - Автоматическая ребалансировка:
При удалении диска, ASM на лету продублирует экстенты, которые он содержал, на другие оставшиеся в группе диски. При добавлении в группу диска, переместит экстенты в группе так, что на каждом диске окажется приблизительно равное число экстентов.
Предположим, что несколько дисков подключены к определенному контроллеру- и, таким образом, представляют собой, SPF - single point of failure (При выходе из строя контроллера теряем весь дисковый массив). У ASM есть технология определения Failure Groups внутри Disk Group. При этом механизме зеркалирование будет раскидывать копии экстентов по дискам, находящимся в различных failure groups, чтобы избежать SPF ( Single Point of Failure ), например, при смерти SAN или RAID контроллера.
Таким образом, кластер теперь может хранить и читать данные с общего файлового хранилища.
Пора на уровень повыше.
Clusterware. CRS.
На данном уровне необходимо обеспечить координацию и совместную работу узлов кластера, т.е. clusterware слой: где-то между самим экземпляром базы данных и дисковым хранилищем:
CRS ( Cluster-Ready Services ) - набор сервисов, обеспечивающий совместную работу узлов, отказоустойчивость, высокую доступность системы, восстановление системы после сбоя. CRS выглядит как "мини-экземпляр" БД (ПО) устанавливаемый на каждый узел кластера. Устанавливать CRS - в обязательном порядке для построения Oracle RAC. Кроме того, CRS можно интегрировать с решениями clusterware от сторонних производителей, таких как HP или Sun.
Опять немного "терминологии"…
- CSSD - Cluster Synchronization Service Daemon
- CRSD - Cluster Ready Services Daemon
- EVMD - Event Monitor Daemon
| x | Назначение (вкратце) | С какими правами работает | При смерти процесса, перезагружается: |
| CSSD | Механизм синхронизации для взаимодействия узлов в кластерной среде. | user | процесс |
| CRSD | Основной "движок" для поддержки доступности ресурсов | root | хост |
| EVMD | Процесс оповещения о событиях, происходящих в кластере | user | процесс |
Как уже стало ясно из таблички, самым главным процессом, "самым могущественным демоном", является CRSD ( Cluster Ready Services Daemon ). В его обязанности входит: запуск, остановка узла, генерация failure logs, реконфигурация кластера в случае падения узла, он также отвечает за восстановление после сбоев и поддержку файла профилей OCR. Если демон падает, то узел целиком перезагружается. CRS управляет ресурсами OCR: Global Service Daemon (GSD), ONS Daemon, Virtual Internet Protocol (VIP), listeners, databases, instances, and services.
- Node Membership (NM). Каждую секунду проверяет heartbeat между узлами. NM также показывает остальным узлам, что он имеет доступ к так называемому voting disk (если их несколько, то хотя бы к большинству), делая регулярно туда записи. Если узел не отвечает на heartbeat или не оставляет запись на voting disk в течение нескольких секунд (10 для Linux, 12 для Solaris), то master узел исключает его из кластера.
- Group Membership (GM). Функция отвечает за своевременное оповещение при добавлении / удалении / выпадении узла из кластера, для последующей реконфигурации кластера.
CSSD предоставляет динамическую информацию о узлах и экземплярах, которые являются частью его на текущий момент, и отвечает за блокировки ресурсов в кластере.
Информатором в кластере выступает EVMD ( Event Manager Daemon ), который оповещает узлы о событиях: о том, что узел запущен, потерял связь, восстанавливается. Он выступает связующим звеном между CRSD и CSSD. Оповещения также направляются в ONS (Oracle Notification Services), универсальный шлюз Oracle, через который оповещения можно рассылать, например, в виде SMS или e-mail.
Стартует кластер примерно по следующей схеме: CSSD читает из общего хранилища OCR, откуда считывает кластерную конфигурацию, чтобы опознать, где расположен voting disk, читает voting disk, чтобы узнать сколько узлов (поднялось) в кластере и их имена, устанавливает соединения с соседними узлами по протоколу IPC. Обмениваясь heartbeat, проверяет, все ли соседние узлы поднялись, и выясняет, кто в текущей конфигурации определился как master. Ведущим (master) узлом становится первый запустившийся узел . После старта, все запущенные узлы регистрируются у master, и впоследствии будут предоставлять ему информацию о своих ресурсах.
Уровнем выше CRS на узлах установлены экземпляры базы данных.
Друг с другом узлы общаются по private сети - Cluster Interconnect , по протоколу IPC ( Interprocess Communication ). К ней предъявляются требования: высокая ширина пропускной способности и малые задержки. Она может строиться на основе высокоскоростных версий Ethernet, решений сторонних поставщиков (HP, Veritas, Sun), или же набирающего популярность InfiniBand . Последний кроме высокой пропускной способности пишет и читает непосредственно из буфера приложения, без необходимости в осуществлении вызовов уровня ядра. Поверх IP Oracle рекомендует использовать UDP для Linux, и TCP для среды Windows. Также при передаче пакетов по interconnect Oracle рекомендует укладываться в рамки 6-15 ms для задержек.
Читайте также: