
Для чего нужен кластер из компьютеров
Обновлено: 04.07.2024
Кластер серверов – группа серверов, объединённых высокоскоростными каналами связи, представляющая с точки зрения пользователя единый аппаратный ресурс. Кластер - слабо связанная совокупность нескольких вычислительных систем, работающих совместно для выполнения общих приложений, и представляющихся пользователю единой системой. Один из первых архитекторов кластерной технологии Грегори Пфистер дал кластеру следующее определение: «Кластер – это разновидность параллельной или распределённой системы, которая:
- состоит из нескольких связанных между собой компьютеров;
- используется как единый, унифицированный компьютерный ресурс».
Содержание
Возможности
Возможностями при использовании кластерами серверов являются:
- управлять произвольным количеством аппаратных средств с помощью одного программного модуля;
- добавлять и усовершенствовать программные и аппаратные ресурсы, без остановки системы и масштабных архитектурных преобразований;
- обеспечивать бесперебойную работу системы, при выходе из строя одного или нескольких серверов;
- синхронизировать данные между серверами – единицами кластера;
- эффективно распределять клиентские запросы по серверам;
- использовать общую базу данных кластера.
По сути, главной задачей кластера серверов, является исключение простоя системы. В идеале, любой инцидент, связанный с внешним вмешательством или внутренним сбоем в работе ресурса, должен оставаться незамеченным для пользователя.
При проектировании систем с участием серверного кластера необходимо учитывать возможности клиентского программного обеспечения по идентификации кластера и совместной работе с командным модулем (Cluster Manager). В противном случае вероятна ситуация, при которой попытка программы-клиента с помощью модуля получить доступ к данным ресурса через другие сервера может получить отказ (конкретные механизмы в данном случае зависят от возможностей и настроек кластера и клиентского оборудования).
Модели формирования
Принято считать, что кластеры серверов делятся на две модели:
- Первая – это использование единого массива хранения информации, что дает возможность более быстрого переподключения при сбое. Однако в случае с объемной базой данных и большим количеством аппаратных единиц в системе, возможно падение производительности.
- Вторая – это модель, при которой серверы независимы, как и их периферия. В случае отказа перераспределение происходит между серверами. Здесь ситуация обратная – трафик в системе более свободен, однако, усложняется и ограничивается пользование общей базой данных.
В обоих случаях, существуют определенные и вполне эффективные инструменты для решения проблем, поэтому выбор конкретной модели кластера неограничен ничем, кроме требований к архитектуре системы. [Источник 1]
Различают следующие основные виды кластеров:
- отказоустойчивые кластеры (High-availability clusters, HA, кластеры высокой доступности)
- кластеры с балансировкой нагрузки (Load balancing clusters)
- вычислительные кластеры (High performance computing clusters, HPC)
- системы распределенных вычислений
Отказоустойчивые кластеры
Несомненно, основной характеристикой в кластере является отказоустойчивость. Это подтверждает и опрос пользователей: 95% опрошенных ответили, что в кластерах им необходимы надежность и отказоустойчивость. Однако не следует смешивать эти два понятия. Под отказоустойчивостью понимается доступность тех или иных функций в случае сбоя, другими словами, это резервирование функций и распределение нагрузки. А под надежностью понимается набор средств обеспечения защиты от сбоев.
Такие требования к надежности и отказоустойчивости кластерных систем обусловлены спецификой их использования. Приведем небольшой пример. Кластер обслуживает систему электронных платежей, поэтому если клиент в какой-то момент останется без обслуживания для компании-оператора, это ему будет дорого стоить. Другими словами, система должна работать в непрерывном режиме 24 часа в сутки и семь дней в неделю (7Ѕ24). При этом отказоустойчивости в 99% явно не достаточно, так как это означает, что почти четыре дня в году информационная система предприятия или оператора будет неработоспособной.
Это может показаться не таким уж и большим сроком, учитывая профилактические работы и техническое обслуживание системы. Но сегодняшнему клиенту абсолютно безразличны причины, по которым система не работает. Ему нужны услуги. Итак, приемлемой цифрой для отказоустойчивости становится 99,999%, что эквивалентно 5 минутам в год. Таких показателей позволяет достичь сама архитектура кластера. Приведем пример серверного кластера: каждый сервер в кластере остается относительно независимым, то есть его можно остановить и выключить (например, для проведения профилактических работ или установки дополнительного оборудования), не нарушая работоспособность кластера в целом. Тесное взаимодействие серверов, образующих кластер (узлов кластера), гарантирует максимальную производительность и минимальное время простоя приложений за счет того, что:
- в случае сбоя программного обеспечения на одном узле приложение продолжает функционировать (либо автоматически перезапускается) на других узлах кластера;
- сбой или отказ узла (или узлов) кластера по любой причине (включая ошибки персонала) не означает выхода из строя кластера в целом;
- профилактические и ремонтные работы, реконфигурацию и смену версий программного обеспечения в большинстве случаев можно осуществлять на узлах кластера поочередно, не прерывая работу приложений на других узлах кластера.
Возможные простои, которые не в состоянии предотвратить обычные системы, в кластере оборачиваются либо некоторым снижением производительности (если узлы выключаются из работы), либо существенным сокращением (приложения недоступны только на короткий промежуток времени, необходимый для переключения на другой узел), что позволяет обеспечить уровень готовности в 99,99%.
Масштабируемость
Высокая стоимость кластерных систем обусловлена их сложностью. Поэтому масштабируемость кластера довольно актуальна. Ведь компьютеры, производительность которых удовлетворяет сегодняшние требования, не обязательно будет удовлетворять их и в будущем. Практически при любом ресурсе в системе рано или поздно приходится сталкиваться с проблемой производительности. В этом случае возможно два варианта масштабирования: горизонтальное и вертикальное. Большинство компьютерных систем допускают несколько способов повышения их производительности: добавление памяти, увеличение числа процессоров в многопроцессорных системах или добавление новых адаптеров или дисков. Такое масштабирование называется вертикальным и позволяет временно улучшить производительность системы. Однако в системе будет установлено максимальное поддерживаемое количество памяти, процессоров или дисков, системные ресурсы будут исчерпаны. И пользователь столкнется с той же проблемой улучшения характеристик компьютерной системы, что и ранее.
Горизонтальное масштабирование предоставляет возможность добавлять в систему дополнительные компьютеры и распределять работу между ними. Таким образом, производительность новой системы в целом выходит за пределы предыдущей. Естественным ограничением такой системы будет программное обеспечение, которые вы решите на ней запускать. Самым простым примером использования такой системы является распределение различных приложений между разными компонентами системы. Например, вы можете переместить ваши офисные приложения на один кластерный узел приложения для Web на другой, корпоративные базы данных – на третий. Однако здесь возникает вопрос взаимодействия этих приложений между собой. И в этом случае масштабируемость обычно ограничивается данными, используемыми в приложениях. Различным приложениям, требующим доступ к одним и тем же данным, необходим способ, обеспечивающий доступ к данным с различных узлов такой системы. Решением в этом случае становятся технологии, которые, собственно, и делают кластер кластером, а не системой соединенных вместе машин. При этом, естественно, остается возможность вертикального масштабирования кластерной системы. Таким образом, за счет вертикального и горизонтального масштабирования кластерная модель обеспечивает серьезную защиту инвестиций потребителей.
В качестве варианта горизонтального масштабирования стоит также отметить использование группы компьютеров, соединенных через коммутатор, распределяющий нагрузку (технология Load Balancing). Здесь стоит отметить невысокую стоимость такого решения, в основном слагаемую из цены коммутатора (6 тыс. долл. и выше – в зависимости от функционального оснащения) и хост-адаптер (порядка нескольких сот долларов за каждый; хотя, конечно, можно использовать и обыкновенные сетевые карты). Такие решения находят основное применение на Web-узлах с высоким трафиком, где один сервер не справляется с обработкой всех поступающих запросов. Возможность распределения нагрузки между серверными узлами такой системы позволяет создавать на многих серверах единый Web-узел.
Вычислительные кластеры
Часто решения, похожие на вышеописанные, носят названия Beowulf-кластера. Такие системы прежде всего рассчитаны на максимальную вычислительную мощность. Поэтому дополнительные системы повышения надежности и отказоустойчивости просто не предусматриваются. Такое решение отличается чрезвычайно привлекательной ценой, и, наверное, поэтому наибольшую популярность приобрело во многих образовательных и научно-исследовательских организациях.
Постоянный спрос на высокие вычислительные мощности обусловил появление привлекательного для многих производителей рынка. Некоторые из них разработали собственные технологии соединения компьютеров в кластер. Наиболее известные из них – Myrinet производства MyriCom и cLAN фирмы Giganet. Myrinet является открытым стандартом. Для его реализации MyriCom предлагает широкий выбор сетевого оборудования по сравнительно невысоким ценам. На физическом уровне поддерживаются сетевые среды SAN (System Area Network), LAN (CL-2) и оптоволокно.
Вычислительный кластер – это набор соединенных между собой компьютеров (серверов), которые работают вместе и могут рассматриваться как единая система. В отличие от грид-вычислений, все узлы компьютерного кластера выполняют одну и ту же задачу и управляются одной системой управления.
Серверы кластера обычно соединяются между собой по быстродействующей локальной сети, причем на каждом из серверов работает собственный экземпляр операционной системы. В большинстве случаев все вычислительные узлы кластера используют одинаковое оборудование и одну и ту же операционную систему. Однако в некоторых инсталляциях, например, с использованием платформы приложений для организации кластеров OSCAR (Open Source Cluster Application Resources), могут использоваться различные операционные системы или разное серверное оборудование.
Кластеры обычно развертываются для большей производительности и доступности, чем то, что можно получить от одного компьютера, пусть даже очень мощного. Часто такое решение более экономично, чем отдельные компьютеры.
Компоненты кластера
Вычислительные кластеры обычно состоят из следующих компонентов:
- узел доступа;
- вычислительные узлы;
- файловый сервер;
- файловая или объектная СХД с общим доступом;
- локальная сеть LAN.
Виды кластеров
Различают следующие основные виды кластеров:
- кластеры высокой доступности (High-availability clusters, HA);
- кластеры с балансировкой нагрузки (Load balancing clusters);
- высокопроизводительные кластеры (High performance computing clusters, HPC).
Кластеры высокой доступности
Кластеры высокой доступности НА (high-availability cluster) известны также как отказоустойчивые (failover) кластеры, построенные по схеме сети с большой избыточностью (redundancy). Они применяются для критических серверных приложений, например сервера баз данных. Компьютерный кластер может называться НА-кластером, если он обеспечивает доступность приложений не менее, чем «пять девяток», т. е. приложение должно быть доступно (uptime) в течение 99,999 % времени за год.
Чрезвычайно высокая доступность в НА-кластерах достигается за счет использования специального программного обеспечения и аппаратных решений со схемами обнаружения отказов, а также благодаря работе по подготовке к отказам.
ПО для НА-кластеров обычно заблаговременно конфигурирует узел на резервном сервере и запускает на нем приложение в фоновом режиме так, чтобы основной экземпляр приложения мог немедленно переключиться на свою реплику на резервном компьютере при отказе основного.
НА-кластеры обычно используются для терминальных серверов, серверов баз данных, почтовых серверов, а также для серверов общего доступа к файлам. Они могут быть развернуты как на одном местоположении («серверной ферме»), так и в географически разнесенных местоположениях.
Но не следует думать, что технология кластера высокой доступности, или вообще кластеризация, могут служить заменой резервному копированию (backup), а также решениям катастрофоустойчивости (disaster recovery).
Кластеры с балансировкой нагрузки
Балансировка нагрузки – это эффективное распределение входящего сетевого трафика в группе (кластере) серверов.
Современные веб-сайты должны одновременно обслуживать сотни тысяч и даже миллионы запросов от пользователей или клиентов и не слишком задерживать их в получении контента: текста, видео или данных приложений. Чем больше серверов будут обслуживать эти запросы, тем лучше будет качество воспринимаемого сервиса для клиентов. Однако может возникнуть ситуация, когда одни серверы сайта будут работать с перегрузкой, а другие будут почти простаивать.
Балансировщик нагрузки направляет запросы клиентов равномерно на все серверы кластера, которые способны ответить на те или иные запросы. Таким образом, балансировщик максимизирует процент использования вычислительной емкости, а также обеспечивает то, что ни один сервер не оказывается перегруженным, вызывая общую деградацию производительности кластера.
Если какой-то сервер отказывает, то балансировщик перенаправляет трафик на оставшиеся серверы. Когда новый сервер добавляется к группе (кластеру), то балансировщик автоматически перераспределяет нагрузку на всех серверах с учетом вновь вступившего в работу.
Таким образом, балансировщик нагрузки выполняет следующие функции:
- Распределяет запросы клиентов и нагрузку сети эффективным образом в во всем кластере серверов.
- Обеспечивает высокую доступность и надежность посылкой запросов только на те серверы, которые находятся в режиме онлайн.
- Обеспечивает гибкость, добавляя или удаляя серверы по мере надобности.
Работа балансировщика нагрузки
Алгоритмы балансировки нагрузки
Различные алгоритмы балансировки предназначены для разных целей и достижения разных выгод. Можно назвать следующие алгоритмы балансировки:
- Round Robin – запросы распределяются по кластеру серверов последовательно.
- Least Connections – новый запрос посылается на сервер с наименьшим числом подключений клиентов, однако при этом учитывается и вычислительная мощность каждого сервера.
- Least Time – запросы посылаются на сервер, выбираемый по формуле, которая комбинирует быстроту ответа и наименьшее число активных запросов.
- Hash – распределяет запросы на основании определяемого пользователем ключа, например, IP-адреса клиента или URL запрашиваемого сайта.
- Random with Two Choices – выбираются два сервера по методу произвольного выбора и затем запрос посылается на один из них, который выбирается по критерию наименьшего числа подключений.
Программная и аппаратная балансировка нагрузки
Балансировщики нагрузки бывают двух типов: программные и аппаратные. Программные балансировщики можно установить на любой сервер достаточной для задачи емкости. Поставщики аппаратных балансировщиков просто загружают соответствующее программное обеспечение балансировки нагрузки на серверы со специализированными процессорами. Программные балансировщики менее дорогие и более гибкие. Можно также использовать облачные решения сервисов балансировки нагрузки, такие как AWS EC2.
Высокопроизводительные кластеры (HPC)
Высокопроизводительные вычисления HPC (High-performance computing) – это способность обрабатывать данные и выполнять сложные расчеты с высокой скоростью. Это понятие весьма относительное. Например, обычный лэптоп с тактовой частотой процессора в 3 ГГц может производить 3 миллиарда вычислений в секунду. Для обычного человека это очень большая скорость вычислений, однако она меркнет перед решениями HPC, которые могут выполнять квадриллионы вычислений в секунду.
Одно из наиболее известных решений HPC – это суперкомпьютер. Он содержит тысячи вычислительных узлов, которые работают вместе над одной или несколькими задачами, что называется параллельными вычислениями.
HPC очень важны для прогресса в научных, промышленных и общественных областях.
Такие технологии, как интернет вещей IoT (Internet of Things), искусственный интеллект AI (artificial intelligence), и аддитивное производство (3D imaging), требуют значительных объемов обработки данных, которые экспоненциально растут со временем. Для таких приложений, как живой стриминг спортивных событий в высоком разрешении, отслеживание зарождающихся тайфунов, тестирование новых продуктов, анализ финансовых рынков, – способность быстро обрабатывать большие объемы данных является критической.
Чтобы создать HPC-кластер, необходимо объединить много мощных компьютеров при помощи высокоскоростной сети с широкой полосой пропускания. В этом кластере на многих узлах одновременно работают приложения и алгоритмы, быстро выполняющие различные задачи.
Чтобы поддерживать высокую скорость вычислений, каждый компонент сети должен работать синхронно с другими. Например, компонент системы хранения должен быть способен записывать и извлекать данные так, чтобы не задерживать вычислительный узел. Точно так же и сеть должна быстро передавать данные между компонентами НРС-кластера. Если один компонент будет подтормаживать, он снизит производительность работы всего кластера.
Существует много технических решений построения НРС-кластера для тех или иных приложений. Однако типовая архитектура НРС-кластера выглядит примерно так, как показано на рисунке ниже.
Примеры реализации вычислительного кластера
В лаборатории вычислительного интеллекта создан вычислительный кластер для решения сложных задач анализа данных, моделирования и оптимизации процессов и систем.
Кластер представляет собой сеть из 11 машин с распределенной файловой системой NFS. Общее число ядер CPU в кластере – 61, из них высокопроизводительных – 48. Максимальное число параллельных высокоуровневых задач (потоков) – 109. Общее число ядер графического процессора CUDA GPU – 1920 (NVidia GTX 1070 DDR5 8Gb).
На оборудовании кластера успешно решены задачи анализа больших данных (Big Data): задача распознавания сигнала от процессов рождения суперсимметричных частиц, задача классификации кристаллических структур по данным порошковой дифракции, задача распределения нагрузки электросетей путем определения выработки электроэнергии тепловыми и гидроэлектростанциями с целью минимизации расходов, задача поиска оптимального расположения массива кольцевых антенн и другие задачи.
Архитектура вычислительного кластера
Другой вычислительный НРС-кластер дает возможность выполнять расчеты в любой области физики и проводить многодисциплинарные исследования.
Графические результаты расчета реактивного двигателя, полученные на НРС-клатере (источник: БГТУ «ВОЕНМЕХ»)
На рисунке показана визуализация результатов расчета реактивного двигателя, зависимость скорости расчетов и эффективности вычислений от количества ядер процессора.
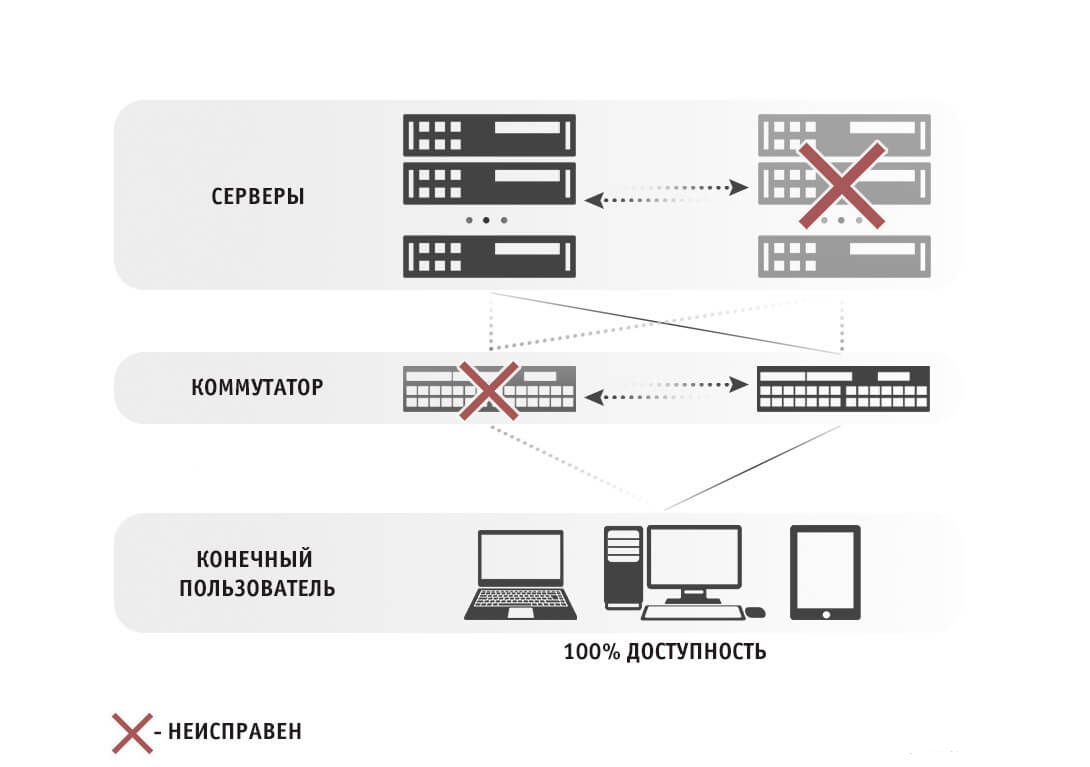
Кластер серверов - это группа серверов, работающих вместе в одной системе, чтобы обеспечить пользователям более высокую доступность. Эти кластеры используются для сокращения времени простоя, позволяя другому серверу продолжать работу в случае сбоя. Группа серверов подключена к одной системе. В тот момент, когда один из этих серверов становиться недоступным, рабочая нагрузка перераспределяется на другой сервер до того, как клиент испытывает какое-либо время простоя.
Виды кластеров:
Отказоустойчивые. Несколько серверов объединяются с целью дублирования друг друга.
Высокопроизводительные. На группу машин отправляются данные для обработки — кластер распределяет задачи по всем участникам для ускорения обработки.
Балансировщики. Все запросы на серверы распределяются в случайном порядке между нодами кластера.
Принято считать, что кластеры серверов делятся на две модели:
Первая — это использование единого массива хранения информации, что дает возможность более быстрого переподключения при сбое. Однако в случае с объемной базой данных и большим количеством аппаратных единиц в системе, возможно падение производительности.
Вторая — это модель, при которой серверы независимы, как и их периферия. В случае отказа перераспределение происходит между серверами. Здесь ситуация обратная — трафик в системе более свободен, однако, усложняется и ограничивается пользование общей базой данных.
Кластерная защита от сбоев и отключений
Основным обоснованием для кластеров серверов является защита от простоев и сбоев. Как упомянуто выше, кластерные серверы обеспечивают повышенную защиту от полного отключения сети во время сбоя питания, и предназначены для защиты от трех основных типов сбоев:
Сбой приложения/службы: сбой, который влияет на критически важные приложения и службы в сети.
Системный/аппаратный сбой: выходы из строя, которые влияют на такие компоненты, как процессоры, память, адаптеры, диски и источники питания.
Сбой датацентра: сбои датацентров, которые затрагивают несколько мест, как правило, вызваны стихийными бедствиями, которые приводят к массовым отключениям электроэнергии.
Основные возможности кластера серверов
кластер серверов может функционировать на одном или нескольких компьютерах (рабочих серверах);
на каждом рабочем сервере может функционировать один или несколько рабочих процессов, обслуживающих клиентские соединения в рамках данного кластера;
подключение новых клиентов к рабочим процессам кластера выполняется на основе анализа долгосрочной статистики загруженности рабочих процессов;
взаимодействие процессов кластера с клиентскими приложениями, между собой и с сервером баз данных осуществляется по протоколу TCP/IP;
процессы кластера сервера могут быть запущены как приложение, или как сервис.
Общая схема клиент-серверного варианта работы
В клиент-серверном варианте работы клиентское приложение взаимодействует с кластером серверов, который, в свою очередь, осуществляет взаимодействие с сервером баз данных.
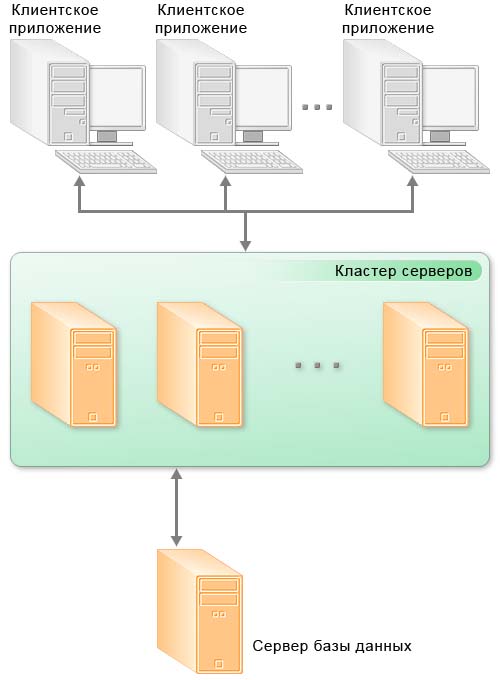
Один из компьютеров, входящих в состав кластера серверов, является центральным сервером кластера. Центральный сервер, помимо обслуживания клиентских соединений, управляет работой всего кластера и хранит реестр кластера.
Для клиентского соединения кластер адресуется по имени центрального сервера и номеру IP порта. Если используется стандартный IP порт, то достаточно указания одного имени центрального сервера.
При установке соединения клиентское приложение обращается к центральному серверу кластера. Центральный сервер, на основе анализа статистики загруженности рабочих процессов, направляет клиентское приложение к конкретному рабочему процессу, который будет его обслуживать. Этот процесс может находиться как на центральном сервере, так и на любом рабочем сервере кластера.
Рабочий процесс выполняет аутентификацию пользователя и обслуживает соединение до окончания сеанса работы клиента с данной информационной базой.
Зачем кластеризовать ваши серверы?
Существует три основных причины кластеризации серверов. Это доступность, масштабируемость и надежность. Ключ к защищенной ИТ-инфраструктуре лежит в избыточности. Создание кластера серверов в одной сети обеспечивает максимальную избыточность и гарантирует, что одна ошибка не приведет к отключению всей сети.
Сегодня бизнес-процессы многих компаний полностью завязаны на информационных
технологиях. С ростом такой зависимости организаций от работы вычислительных
сетей доступность сервисов в любое время и под любой нагрузкой играет большую
роль. Один компьютер может обеспечить лишь начальный уровень надежности и
масштабируемости, максимального же уровня можно добиться за счет объединения в
единую систему двух или нескольких компьютеров - кластер.
Для чего нужен кластер
Возможности Win2k3
Вообще говоря, одни кластеры предназначены для повышения доступности данных,
другие - для обеспечения максимальной производительности. В контексте статьи нас
будут интересовать MPP (Massive Parallel Processing) - кластеры, в
которых однотипные приложения выполняются на нескольких компьютерах, обеспечивая
масштабируемость сервисов. Существует несколько технологий, позволяющих
распределять нагрузку между несколькими серверами: перенаправление трафика,
трансляция адресов, DNS Round Robin, использование специальных
программ, работающих на прикладном уровне, вроде веб-акселераторов. В
Win2k3, в отличие от Win2k, поддержка кластеризации заложена изначально и
поддерживается два типа кластеров, отличающихся приложениями и спецификой
данных:
1. Кластеры NLB (Network Load Balancing) - обеспечивают
масштабируемость и высокую доступность служб и приложений на базе протоколов TCP
и UDP, объединяя в один кластер до 32 серверов с одинаковым набором данных, на
которых выполняются одни и те же приложения. Каждый запрос выполняется как
отдельная транзакция. Применяются для работы с наборами редко изменяющихся
данных, вроде WWW, ISA, службами терминалов и другими подобными сервисами.
2. Кластеры серверов – могут объединять до восьми узлов, их главная
задача - обеспечение доступности приложений при сбое. Состоят из активных и
пассивных узлов. Пассивный узел большую часть времени простаивает, играя роль
резерва основного узла. Для отдельных приложений есть возможность настроить
несколько активных серверов, распределяя нагрузку между ними. Оба узла
подключены к единому хранилищу данных. Кластер серверов используется для работы
с большими объемами часто изменяющихся данных (почтовые, файловые и
SQL-серверы). Причем такой кластер не может состоять из узлов, работающих под
управлением различных вариантов Win2k3: Enterprise или Datacenter (версии Web и
Standart кластеры серверов не поддерживают).
В Microsoft Application Center 2000 (и только) имелся еще один вид
кластера - CLB (Component Load Balancing), предоставляющий возможность
распределения приложений COM+ между несколькими серверами.
NLB-кластеры
1) unicast – одноадресная рассылка, когда вместо физического МАС
используется МАС виртуального адаптера кластера. В этом случае узлы кластера не
могут обмениваться между собой данными, используя МАС-адреса, только через IP
(или второй адаптер, не связанный с кластером);
2) multicast – многоадресная рассылка, МАС-адрес кластера назначается
физическому адресу, но не затирая его. Для реализации этого метода
маршрутизаторы должны поддерживать групповые МАС-адреса.
В пределах одного кластера следует использовать только один из этих режимов.
Можно настроить несколько NLB-кластеров на одном сетевом адаптере,
указав конкретные правила для портов. Такие кластеры называют виртуальными. Их
применение дает возможность задать для каждого приложения, узла или IP-адреса
конкретные компьютеры в составе первичного кластера, или блокировать трафик для
некоторого приложения, не затрагивая трафик для других программ, выполняющихся
на этом узле. Или, наоборот, NLB-компонент может быть привязан к нескольким
сетевым адаптерам, что позволит настроить ряд независимых кластеров на каждом
узле. Также следует знать, что настройка кластеров серверов и NLB на одном узле
невозможна, поскольку они по-разному работают с сетевыми устройствами.
Администратор может сделать некую гибридную конфигурацию, обладающую
достоинствами обоих методов, например, создав NLB-кластер и настроив репликацию
данных между узлами. Но репликация выполняется не постоянно, а время от времени,
поэтому информация на разных узлах некоторое время будет отличаться.
С теорией на этом закончим, хотя о построении кластеров можно рассказывать
еще долго, перечисляя возможности и пути наращивания, давая различные
рекомендации и варианты конкретной реализации. Все эти тонкости и нюансы оставим
для самостоятельного изучения и перейдем к практической части.
Настройка NLB-кластера
Для организации NLB-кластеров дополнительное ПО не требуется, все
производится имеющимися средствами Win2k3. Для создания, поддержки и мониторинга
NLB-кластеров используют компонент «Диспетчер балансировки сетевой нагрузки»
(Network Load Balancing Manager), который находится во вкладке
«Администрирование» «Панели управления» (команда NLBMgr). Так как компонент
«Балансировка нагрузки сети» ставится как стандартный сетевой драйвер Windows,
установку NLB можно выполнять и при помощи компонента «Сетевые подключения», в
котором доступен соответствующий пункт. Но лучше использовать только первый
вариант, одновременное задействование диспетчера NLB и «Сетевых подключений»
может привести к непредсказуемым результатам.
Диспетчер NLB позволяет настраивать и управлять из одного места работой сразу
нескольких кластеров и узлов.
Возможна также установка NLB-кластера на компьютере с одним сетевым
адаптером, связанным с компонентом «Балансировка нагрузки сети», но в этом
случае при режиме unicast диспетчер NLB на этом компьютере не может быть
использован для управления другими узлами, а сами узлы не могут обмениваться
друг с другом информацией.
Для упрощения будем считать, что операционные системы установлены, сетевые
подключения настроены (как обычно), узлы будущего кластера подключены к Active
Directory и у тебя есть соответствующие права.
Теперь вызываем диспетчер NLB. Кластеров у нас пока нет, поэтому появившееся
окно не содержит никакой информации. Выбираем в меню «Кластер» пункт «Новый» и
начинаем заполнять поля в окне «Параметры кластера». В поле «Настройка
IP-параметров кластера» вводим значение виртуального IP-адреса кластера, маску
подсети и полное имя. Значение виртуального МАС-адреса устанавливается
автоматически. Чуть ниже выбираем режим работы кластера: одноадресный или
многоадресный. Обрати внимание на флажок «Разрешить удаленное управление» - во
всех документах Microsoft настоятельно рекомендует его не использовать во
избежание проблем, связанных с безопасностью. Вместо этого следует применять
диспетчер или другие средства удаленного управления, например инструментарий
управления Windows (WMI). Если же решение об его использовании принято, следует
выполнить все надлежащие мероприятия по защите сети, прикрыв дополнительно
брандмауэром UDP-порты 1717 и 2504.
После заполнения всех полей нажимаем «Далее». В окне «IP-адреса кластера» при
необходимости добавляем дополнительные виртуальные IP-адреса, которые будут
использоваться этим кластером. В следующем окне «Правила для портов» можно
задать балансировку нагрузки для одного или для группы портов всех или
выбранного IP по протоколам UDP или TCP, а также блокировать доступ к кластеру
определенным портам (что межсетевой экран не заменяет). По умолчанию кластер
обрабатывает запросы для всех портов (0–65365); лучше этот список ограничить,
внеся в него только действительно необходимые. Хотя, если нет желания возиться,
можно оставить все, как есть. Кстати, в Win2k по умолчанию весь трафик,
направленный к кластеру, обрабатывал только узел, имевший наивысший приоритет,
остальные узлы подключались только при выходе из строя основного.
В режиме фильтрации «Несколько узлов» можно дополнительно указать вариант
определения сходства клиентов, чтобы направлять трафик от заданного клиента к
одному и тому же узлу кластера. Возможны три варианта: «Нет», «Одно» или «Класс
C». Выбор первого означает, что на любой запрос будет отвечать произвольный
узел. Но не следует его использовать, если в правиле выбран протокол UDP или
«Оба». При избрании остальных пунктов сходство клиентов будет определяться по
конкретному IP или диапазону сети класса С.
Далее подключаемся к узлу будущего кластера, введя его имя или реальный IP, и
определяем интерфейс, который будет подключен к сети кластера. В окне «Параметры
узла» выбираем из списка приоритет, уточняем сетевые настройки, задаем начальное
состояние узла (работает, остановлен, приостановлен). Приоритет одновременно
является уникальным идентификатором узла; чем меньше номер, тем выше приоритет.
Узел с приоритетом 1 является мастер-сервером, в первую очередь получающим
пакеты и действующим как менеджер маршрутизации.
Флажок «Сохранить состояние после перезагрузки компьютера» позволяет в случае
сбоя или перезагрузки этого узла автоматически ввести его в строй. После нажатия
на «Готово» в окне Диспетчера появится запись о новом кластере, в котором пока
присутствует один узел.
Следующий узел добавить также просто. Выбираем в меню «Добавить узел» либо
«Подключить к существующему», в зависимости от того, с какого компьютера
производится подключение (он уже входит в кластер или нет). Затем в окне
указываем имя или адрес компьютера, если прав для подключения достаточно, новый
узел будет подключен к кластеру. Первое время значок напротив его имени будет
отличаться, но когда завершится процесс схождения, он будет такой же, как и у
первого компьютера.
Так как диспетчер отображает свойства узлов на момент своего подключения, для
уточнения текущего состояния следует выбрать кластер и в контекстном меню пункт
«Обновить». Диспетчер подключится к кластеру и покажет обновленные данные.
После установки NLB-кластера не забудь изменить DNS-запись, чтобы
разрешение имени теперь показывало на IP-кластера.
Изменение загрузки сервера
В такой конфигурации все серверы будут загружены равномерно (за исключением
варианта «Один узел»). В некоторых случаях необходимо перераспределить нагрузку,
большую часть работы возложив на один из узлов (например, самый мощный).
Применительно к кластеру правила после их создания можно изменить, выбрав в
контекстном меню, появляющемся при щелчке на имени, пункт «Свойства кластера».
Здесь доступны все те настройки, о которых мы говорили выше. Пункт меню
«Свойства узла» предоставляет несколько больше возможностей. В «Параметрах узла»
можно изменить значение приоритета для конкретно выбранного узла. В «Правилах
для портов» добавить или удалить правило нельзя, это доступно только на уровне
кластера. Но, выбрав редактирование конкретного правила, мы получаем возможность
скорректировать некоторые настройки. Так, при установленном режиме фильтрации
«Несколько узлов» становится доступным пункт «Оценка нагрузки», позволяющий
перераспределить нагрузку на конкретный узел. По умолчанию установлен флажок
«Равная», но в «Оценке нагрузки» можно указать другое значение нагрузки на
конкретный узел, в процентах от общей загрузки кластера. Если активирован режим
фильтрации «Один узел», в этом окне появляется новый параметр «Приоритет
обработки». Используя его, можно сделать так, что трафик к определенному порту
будет в первую очередь обрабатываться одним узлом кластера, а к другому – другим
узлом.
Журналирование событий
Настраиваем IIS с репликацией
Кластер кластером, но без службы он смысла не имеет. Поэтому добавим IIS (Internet
Information Services). Сервер IIS входит в состав Win2k3, но, чтобы свести к
минимуму возможность атак на сервер, он по умолчанию не устанавливается.
Инсталлировать IIS можно двумя способами: посредством «Панели управления» или
мастером управления ролями данного сервера. Рассмотрим первый. Переходим в
«Панель управления – Установка и удаление программ» (Control Panel - Add or
Remove Programs), выбираем «Установку компонентов Windows» (Add/Remove Windows
Components). Теперь переходим в пункт «Сервер приложений» и отмечаем в «Службах
IIS» все, что необходимо. По умолчанию рабочим каталогом сервера является \Inetpub\wwwroot.
После установки IIS может выводить статические документы.
Вот, собственно, и все. Если в файл hosts, который находится в C:\Windows\System32\Drivers\Etc,
добавить запись для разрешения имени веб-сервера и IP-адрес кластера, то,
обратившись с локального узла, можно получить документ с веб-сервера. Для
репликации данных между узлами кластера используй службу DFS, о которой подробно
говорилось в последнем
номере за прошлый год.

Полную версию статьи
читай в февральском номере
Хакера!
Читайте также: