
Для чего предназначены индексы индексные файлы в базах данных
Обновлено: 07.07.2024
Как уже отмечалось в предыдущей лекции, одной из важнейших задач разработки физической модели данных ХД является обеспечение гарантии того, что ХД обеспечивает требуемый уровень производительности. В той же лекции мы рассмотрели основной подход к решению этой задачи — денормализацию таблиц физической модели данных ХД в рамках подхода реляционной модели. В настоящей лекции мы продолжим обсуждать методы борьбы за производительность ХД и сконцентрируем свое внимание на СУБД -ориентированных средствах для решения этой задачи: индексах , секциях, кластерах .
Повышение производительности запросов: индексы
Индексирование
Индексирование (indexing) — это способ обеспечения быстрого доступа к значениям колонки или комбинации колонок. Физически новые строки добавляются в конец таблицы, результатом чего становится неупорядоченное размещение значений в колонках. Без использования каких-либо методов упорядочения данных единственным способом просмотра значения колонки со стороны СУБД является последовательный просмотр каждой строки от начала таблицы к ее концу — так называемое сканирование таблицы. Производительность такого сканирования пропорциональна размеру таблицы, размеру физической страницы БД и длине строки таблицы.
Одним из способов внесения отношения порядка в значения колонок без нарушения физического расположения строк таблицы является создание объекта реляционной СУБД — индекса (index). Индекс — это объект в реляционной БД, который предназначен для организации быстрого доступа к строкам таблицы по значениям одной или более колонок этих строк.
Концептуально действие индекса состоит в следующем. В индексе содержатся упорядоченный список значений колонки или комбинации колонок, а также сведения о местонахождении на жестком диске соответствующих этим значениям строк таблицы. Значения колонки в индексе упорядочены. Несмотря на то, что порядок строк в таблице случаен, индекс можно быстро просмотреть, чтобы найти конкретное значение. Упорядоченный индекс можно просмотреть во много раз быстрее, чем неупорядоченную таблицу. Чем выше степень различия значений ключа в колонке, тем быстрее будет выполняться доступ к строкам этой таблицы.
Так, при вставке новой записи в таблицу проверка уникальности первичного ключа реализуется не реальным просмотром таблицы БД, а тем, что требование уникальности предъявляется к значениям колонки первичного ключа в индексе . Таким образом, индекс — это объект базы данных, который может существенно сократить время поиска нужных строк в таблице.
Индексы занимают место в БД. При вводе новых данных или удалении данных СУБД приходится обновлять и таблицы, и индексы . Это может замедлить выполнение операций модификации данных, особенно для таблиц с большим числом строк, как в ХД. Таким образом, может появиться проблема, суть которой состоит в возникновении конфликта между скоростью обновления данных в таблице и скоростью ее считываний. При разрешении этой проблемы следует придерживаться следующего эмпирического правила: создавать индексы для колонок первичных ключей и других колонок, часто используемых в тех запросах, в которых для выборки данных применяются логические критерии. Если в результате скорость обновления данных ухудшается, то можно рассмотреть вопрос об удалении некоторых индексов .
Каждая таблица БД может иметь один или несколько индексов . Индексы создаются по одной колонке или нескольким колонкам таблицы. Колонки, входящие в индекс , принято называть ключевыми полями (key fields), или ключами . Индексы могут быть уникальными и неуникальными. Уникальность индекса означает, что не существует двух строк с одним и тем же значением ключа индекса . Неуникальный индекс может иметь несколько ключей с одинаковыми значениями.
Основными целями создания индексов в БД являются:
- ускорение поиска строк в таблицах;
- обеспечение уникального значения в колонках;
- извлечение строк в заданном порядке на основании значений индексированных колонок (что оправдано только для очень больших таблиц, когда использование предложения ORDER ухудшает производительность).
На этапе создания физической модели данных ХД необходимо принять ряд важных решений о том, что и как индексировать; при этом важно четко сформулировать правила индексирования . Для каждого ИТ-проекта с ХД необходимо создать и оформить в письменном виде правила индексирования как часть общих правил обеспечения производительности. Поддержка и сопровождение индексов в процессе эксплуатации ХД является в основном задачей администратора БД . Решая задачи обеспечения производительности, администратор БД будет ставить вопрос о перепроектировании ее физической структуры (обратные задачи проектирования), в том числе и вопрос об удалении и создании новых индексов . Он может решать эти задачи самостоятельно. Тем более важно знать, по каким правилам и из каких соображений создавались индексы того или иного типа. Разработка таких правил значительно повысит качество эксплуатации ХД с точки зрения обеспечения ее производительности.
Чтобы решать эти задачи, проектировщик должен знать, как работает индекс , какие типы индексов поддерживает СУБД, и понимать смысл методов индексирования .
Сначала мы опишем типы индексов вместе с методами индексирования для каждого типа, затем разберем вопрос о том, как работает индекс , и в заключение дадим некоторые рекомендации по созданию и использованию индексов .
Индекс со структурой B-Tree
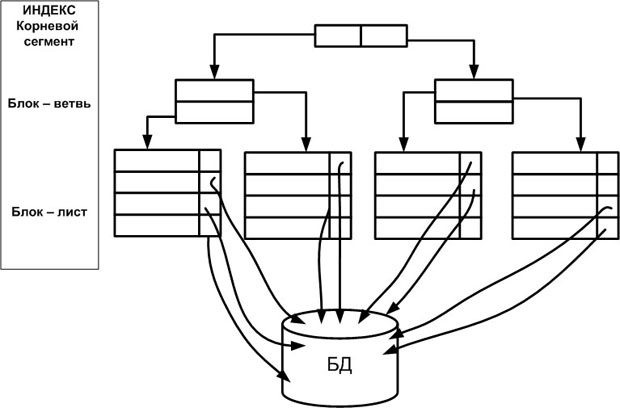
Индекс на основе сбалансированной иерархической структуры (или индекс B-Tree, balanced tree structured object) напоминает дерево, если смотреть на него снизу вверх. При работе СУБД с этой структурой сначала считывается самый верхний блок — корневой узел (root), затем блок на следующем уровне — блок-ветвь (branch), и так далее, до тех пор, пока не будет извлечен блок-лист ( leaf ) с индексируемыми колонками (колонкой) строки. Обратим внимание, что значения индексируемых колонок сохраняется в индексе ( рис. 20.1).
Такая структура позволяет сократить до минимума число операций ввода-вывода. Для получения индексируемых колонок строки обычно требуется одно посещение блока-листа, т.е. физической страницы файловой структуры БД, отведенной под индекс .
увеличить изображение
Рис. 20.1. Концептуальная организация B-Tree индекса
Следует отметить два случая, когда после выборки индексируемых колонок строки из индекса может понадобиться несколько посещений физической страницы индекса :
- когда строка имеет длину более одной физической страницы файловой структуры БД — так называемая расщепленная строка ;
- когда строка за время своего существования в БД увеличилась и была перемещена из исходной страницы в другую страницу — так называемая мигрировавшая строка.
Индекс B-Tree характеризуется количеством уровней в индексе – высотой (height). Чем меньше уровней, тем выше производительность.
Индекс B-Tree — это физический объект реляционной БД, организованный по принципу сбалансированной иерархической структуры и обладающий набором свойств. Сформулируем некоторые свойства индексов со структурой B-Tree .
- Количество операций ввода-вывода, необходимых для получения идентификатора строки, зависит от числа уровней ветвления дерева. По мере увеличения индекса в результате добавления новых данных СУБД добавляет в него новые уровни, чтобы обеспечить сбалансированность дерева. Однако в действительности таких уровней редко бывает более четырех.
- Корневой узел и узлы — ветви индекса сжимаются и поэтому содержат ровно столько начальных байтов значения ключа, сколько нужно для того, чтобы отличить его от других значений. Узлы-листья содержат полное значение ключа.
- Значения в индексе упорядочиваются по ключевому значению, а физические страницы индекса организуются в двунаправленный список. Это обеспечивает последовательный доступ к индексу и позволяет использовать индекс для выполнения операции ORDER BY в запросе.
- Индекс можно использовать для поиска как точного соответствия, так и диапазона значений.
- Индексы могут быть построены для нескольких колонок таблицы — так называемый составной индекс . СУБД использует составные индексы для выполнения тех запросов, в которых задана лидирующая часть составного ключа . Например, составной индекс для обработки запроса SELECT * FROM EMPLOYEE WHERE Job='Инженер'; применяться не будет.
- СУБД обычно сама принимает решение, использовать индекс или нет.
- Значения колонок NULL не индексируются. Если для таких колонок строится индекс , то СУБД будет отказываться применять его в некоторых операциях, например, ORDER BY .
В СУБД семейства MS SQL Server все индексы организованы на основе сбалансированной иерархической структуры. Помимо того, что индексы обладают свойствами уникальности ( UNIQUE ) и неуникальности, индексы в СУБД семейства MS SQL Server могут быть кластеризованными ( CLUSTERED ) или некластеризованными ( NONCLUSTERED ), являющимися индексами по умолчанию.
Кластеризованный индекс – это индекс, в котором логический порядок значений ключа определяет физический порядок соответствующих строк в таблице. На нижнем (конечном) уровне такого индекса хранятся действительные строки данных таблицы. Для таблицы или представления в каждый момент времени может существовать только один кластеризованный индекс .
Некластеризованный индекс – это индекс, в котором задается логическое упорядочение для таблицы. Логический порядок строк в некластеризованном индексе не влияет на их физический порядок. Для каждой таблицы можно создать до 999 некластеризованных индексов , независимо от того, каким образом они создаются: неявно, с помощью ограничений PRIMARY KEY и UNIQUE , или явно, с помощью команды CREATE INDEX , которая была рассмотрена в "Знакомство с CASE инструментом" .
По умолчанию кластеризованный индекс занимает одну секцию на дисковом пространстве. Если кластеризованный индекс занимает несколько секций, каждая секция включает сбалансированное дерево, содержащее данные этой секции. Например, если кластеризованный индекс занимает четыре секции, существует четыре сбалансированных дерева: по одному в каждой секции.
SQL Server движется вниз по индексу , чтобы найти строку, соответствующую ключу кластеризованного индекса . Чтобы найти диапазон ключей, SQL Server сначала находит начальное значение ключа в диапазоне, а затем сканирует страницы данных, используя указатели на следующую и предыдущую страницу. Чтобы найти первую страницу в цепочке страниц данных, SQL Server движется по самым левым указателям от корня индекса .
В зависимости от типов данных каждая структура кластеризованного индекса состоит из одной или более единиц распределения, которые применяются для хранения и управления данными секциями. Для каждой секции кластеризованный индекс содержит как минимум одну единицу распределения IN_ROW_DATA . Для хранения столбцов больших объектов ( LOB ) кластеризованному индексу требуется одна единица распределения LOB_DATA для каждой секции. Кроме того, для хранения строк переменной длины, которые превышают ограничение на размер строки, равное 8 060 байтам, для каждой секции требуется одна единица распределения ROW_OVERFLOW_DATA .
По своей организации некластеризованные индексы отличаются от кластеризованных следующим: строки данных в базовой таблице не сортируются и хранятся в порядке, который основан на их некластеризованных ключах; конечный уровень некластеризованного индекса состоит из страниц индекса вместо страниц данных.
Некластеризованные индексы могут определяться на таблице или представлении с кластеризованным индексом либо на куче. Каждая строка некластеризованного индекса содержит некластеризованное ключевое значение и указатель на строку. Этот указатель определяет строку данных кластеризованного индекса или кучи, содержащую ключевое значение.
Указатели строк на строках некластеризованных индексов являются либо указателем на строку, либо ключом кластеризованного индекса для строки, как описано ниже.
Если таблица является кучей (то есть не содержит кластеризованный индекс ), то указатель строки является указателем на строку. Указатель строится на основе идентификатора файла ( ID ), номера страницы и номера строки на странице. Весь указатель целиком называется идентификатором строки ( RID ).
Если для таблицы имеется кластеризованный индекс или индекс построен на индексированном представлении, то указатель строки — это ключ кластеризованного индекса для строки. Если кластеризованный индекс не является уникальным индексом , то SQL Server создает все имеющиеся повторяющиеся ключи уникальными путем добавления внутри созданного значения, называемого uniqueifier . Это четырехбайтовое значение невидимо для пользователей. Оно применяется тогда, когда необходимо сделать кластеризованный ключ уникальным, чтобы использовать в некластеризованных индексах . SQL Server получает строку данных путем поиска по кластеризованному индексу , задействуя ключ кластеризованного индекса , который хранится в конечной строке некластеризованного индекса .
По умолчанию некластеризованный индекс включает одну секцию. Если он состоит из нескольких секций, то каждая секция имеет структуру сбалансированного дерева, в которой содержатся индексные строки для данной конкретной секции. Например, если некластеризованный индекс содержит четыре секции, то существуют четыре структуры сбалансированного дерева, по одной на каждую секцию.
В зависимости от типов данных в некластеризованном индексе каждая его структура будет содержать одну или более единиц распределения, в которых хранятся данные для определенной секции. Каждый некластеризованный индекс будет иметь по меньшей мере одну единицу распределения IN_ROW_DATA на секцию, в которой хранятся страницы сбалансированного дерева индекса . Некластеризованный индекс будет также содержать одну единицу распределения LOB_DATA на секцию, если в индексе есть столбцы типа большого объекта (LOB). Кроме того, некластеризованный индекс будет включать одну единицу распределения ROW_OVERFLOW_DATA на секцию, если в индексе имеются столбцы переменной длины, в которых превышается максимальный размер строки, равный 8 060 байт.
Далее в примерах, если не оговорено особо, мы будем использовать таблицу "Служащий" (EMPLOYEE) ( рис. 20.2) из "Проектирования модели ХД по логической модели" . Повторим ее здесь.

Создадим для таблицы "Служащий" (EMPLOYEE) составной индекс по колонкам "Фамилия" (Ename) и "Должность" (Job).
- Принимает ключ поиска в качестве ввода
- Эффективно возвращает коллекцию совпадающих записей.
Из этого руководства по индексированию СУБД вы узнаете:
Типы индексации

Индексация базы данных определяется на основе ее атрибутов индексации. Два основных типа методов индексации:
- Первичная индексация
- Вторичная индексация
Первичная индексация
Первичная индексация также делится на два типа.
Плотный индекс
В плотном индексе запись создается для каждого поискового ключа, оцененного в базе данных. Это помогает быстрее выполнять поиск, но требует больше места для хранения записей индекса. В этом индексировании записи метода содержат значение ключа поиска и указывают на реальную запись на диске.

Разреженный индекс
Это индексная запись, которая отображается только для некоторых значений в файле. Разреженный индекс поможет вам решить проблемы плотного индексирования. В этом методе методики индексирования диапазон столбцов индекса хранит один и тот же адрес блока данных, и когда данные должны быть извлечены, адрес блока будет выбран.
Однако разреженный индекс хранит записи индекса только для некоторых значений ключа поиска. Ему требуется меньше места, меньше затрат на обслуживание для вставки и удаления, но он медленнее по сравнению с плотным индексом для поиска записей.
Пример разреженного индекса

Вторичный индекс может быть создан с помощью поля, которое имеет уникальное значение для каждой записи, и это должен быть ключ-кандидат. Он также известен как некластеризованный индекс.
Этот двухуровневый метод индексации базы данных используется для уменьшения размера отображения первого уровня. Для первого уровня из-за этого выбирается большой диапазон чисел; размер отображения всегда остается небольшим.
Пример вторичной индексации
В базе данных банковского счета данные хранятся последовательно с помощью acc_no; Вы можете найти все счета в конкретном отделении банка ABC.

Индекс кластеризации
В кластеризованном индексе сами записи хранятся в индексе, а не в указателях. Иногда индекс создается для столбцов не первичного ключа, которые могут быть не уникальными для каждой записи. В такой ситуации вы можете сгруппировать два или более столбцов, чтобы получить уникальные значения и создать индекс, который называется кластеризованным индексом. Это также поможет вам быстрее идентифицировать запись.
Пример:
Давайте предположим, что компания набрала много сотрудников в различных отделах. В этом случае кластерная индексация должна быть создана для всех сотрудников, принадлежащих к одному отделу.
Что такое многоуровневый индекс?
Многоуровневое индексирование создается, когда первичный индекс не помещается в памяти. В этом методе индексации вы можете сократить число обращений к диску, чтобы сократить любую запись и сохранить ее на диске в виде последовательного файла, а также создать разреженную базу для этого файла.

B-Tree Index
Более того, все конечные узлы связаны между собой списком ссылок, что позволяет дереву B поддерживать как произвольный, так и последовательный доступ.
Многие слышали о том, что индексы в базах данных это весьма полезная штука. Но, одно дело слышать, а другое представлять себе их устройство хотя бы на базовом уровне. Поэтому в рамках данной статьи для начинающих, я рассмотрю этот вопрос, применяя простые и понятные каждому выражения и аналогии из жизни.
Что такое индекс базы данных и зачем он нужен?
Чтобы понять зачем нужны индексы в базе данных и что он собой представляет, сейчас рассмотрим простой пример.
Представьте себе, что у вас есть полочка для книг. При этом изначально эта полочка с книгами пуста. Книги вам то приносят, то уносят, то делают в них какие-то корректировки (к примеру, мемуары или может быть черновики) и тому подобное.
Так как полочка маленькая, то вы как-то не особо задумывались о какой-либо системе классификации, а просто вставляете книги в любые пустые места.
Каждый раз когда-то вам или кому-то необходимо найти определенную книгу, возникает необходимость просматривать все книги с самого начала полочки до первой попавшейся (если нужна только одна книга) или полностью все (если нужно собрать все копии). В принципе, для одной полочки это весьма необременительно.
Теперь, представьте себе, что речь идет не об одной полочке, а об огромном помещении, где находятся тысячи книг.
Тут-то вы и начинаете задумываться о том, что неплохо бы ввести какую-то систему классификации, например, по названию книги. Конечно, полностью сортировать все эти тысячи книг в алфавитном порядке вы не собираетесь, плюс с этим возникло бы куча других вопросов (как добавить книгу в уже заполненную полку и прочие).
Конечно, для поддержки такой системы требуется дополнительное время, но все же оно существенно меньше, чем попытка найти вслепую книгу из тысячи (пара минут против нескольких часов и более).
Так вот, в данном примере, если переносить это в базу данных:
Какие бывают индексы?
Вообще, в зависимости от типов баз данных, индексы могут быть очень разными и реализоваться за счет специфических математических механизмов. Но, наиболее частым является древовидный индекс, так как поддерживать такой индекс относительно просто и максимальная скорость поиска в нем составляет логарифм по числу максимального количества дочерних узлом от общего количества записей (плюс минус некоторые технические моменты).
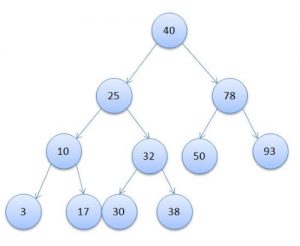
Как видите, очень похоже на перевернутое обычное зеленое дерево, у которого ветки растут не вверх, а вниз.
Максимальное количество дочерних узлов, как вероятно уже догадались по картинке, это то количество дочерних узлов, больше которого у одного узла не может быть.
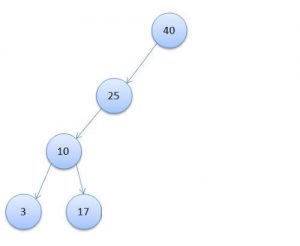
Так же отмечу, что такая скорость достигается за счет того, что дерево строится специальным образом, чтобы не возникало таких ситуаций, как на картинке ниже, где максимальная скорость поиска будет сравнима с простым перебором всех записей.
Практически во всех базах данных, существует деление по уникальности:
Важно отметить, что если для таблицы создается уникальный индекс, то это означает, что при попытке добавить запись со значением, которое уже встречалось, или же изменить значение какой-то записи на существующее, то база данных не позволит сделать такое действие и будет ругаться (выдавать ошибки). В случае же с неуникальным индексом таких проблем нет.
Так же стоит знать, что индексы делятся по количеству входящих в них полей:
Немного упрощая, поиск будет выглядит примерно так.
1. Вначале вы ищите в каталоге с именами необходимую страничку с названием.
2. Затем в этой страничке смотрите, где находится соответствующий каталог с авторами.
3. Берете этот каталог и уже в нем находите страничку, где указано месторасположение всех книг с этим автором и названием.
При этом важно понимать, что для каждого названия будет создаваться собственный каталог авторов. То есть в обратном порядке, к сожалению, поиск не осуществить. Если же требуется поиск вначале по автору, а уже затем по названиям книг, то необходимо создавать отдельный составной каталог (составной индекс).
Существуют и другие моменты, но чаще всего достаточно знать хотя бы эти базовые знания.
Индексы в MySQL (Mysql indexes) — отличный инструмент для оптимизации SQL запросов. Чтобы понять, как они работают, посмотрим на работу с данными без них.
1. Чтение данных с диска
На жестком диске нет такого понятия, как файл. Есть понятие блок. Один файл обычно занимает несколько блоков. Каждый блок знает, какой блок идет после него. Файл делится на куски и каждый кусок сохраняется в пустой блок.
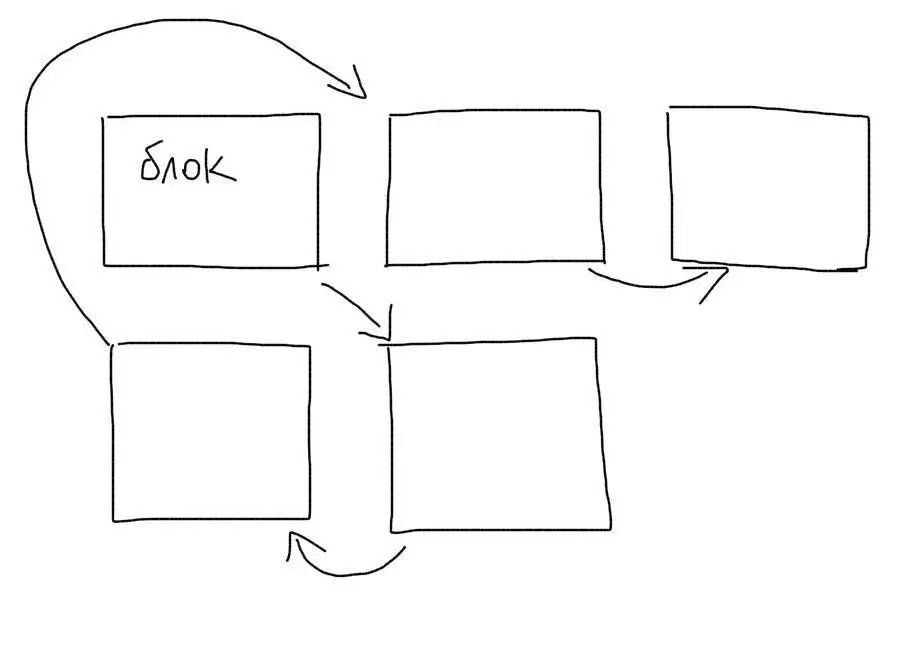
При чтении файла, мы по очереди проходимся по всем блокам и собираем файл из кусков. Блоки одного файла могут быть раскиданы по диску (фрагментация). Тогда чтение файла замедлится, так как понадобится прыгать по разным участкам диска.
Когда мы ищем что-то внутри файла, нам понадобится пройтись по всем блокам, в которых он сохранен. Если файл очень большой, то и количество блоков будет значительным. Необходимость перепрыгивать с блока на блок, которые могут находиться в разных местах, сильно замедлит поиск данных.
2. Поиск данных в MySQL
MySQL при этом открывает файл, где хранятся данные из таблицы users. А дальше — начинает перебирать весь файл, чтобы найти нужные записи.
Кроме этого, MySQL будет сравнивать данные в каждой строке таблицы со значением в запросе. Допустим работа ведется с таблицей, в которой есть 10 записей. Тогда MySQL прочитает все 10 записей, сравнит колонку age каждой из них со значением 29 и отберет только подходящие данные:

Итак, есть две проблемы при чтении данных:
- Низкая скорость чтения файлов из-за расположения блоков в разных частях диска (фрагментация).
- Большое количество операций сравнения для поиска нужных данных.
3. Сортировка данных
Представим, что мы отсортировали наши 10 записей по убыванию. Тогда используя алгоритм бинарного поиска, мы могли бы максимум за 4 операции отобрать нужные нам значения:
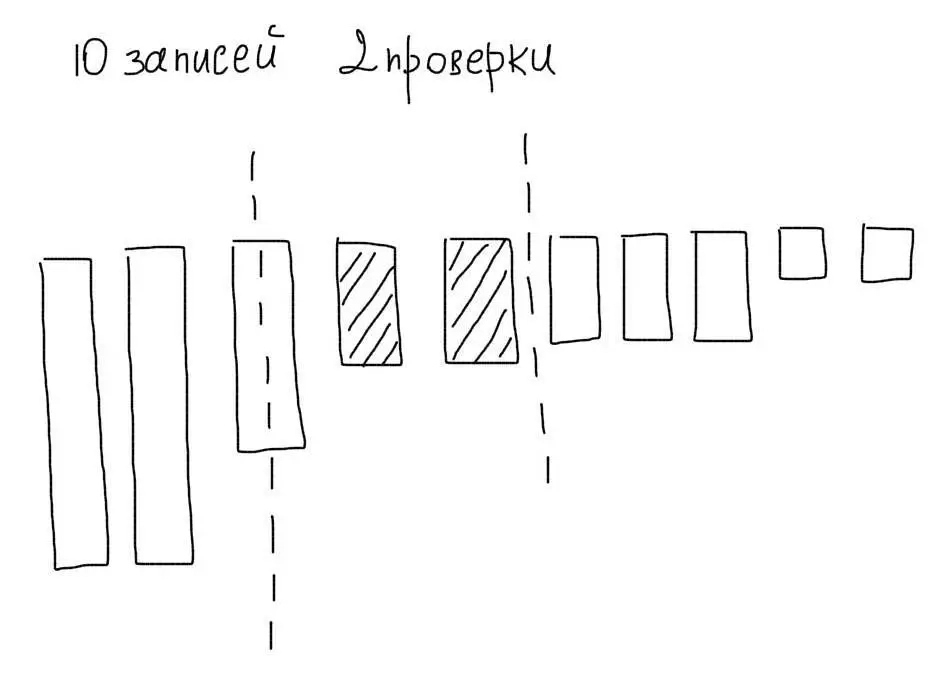
Кроме меньшего количества операций сравнения, мы сэкономили бы на чтении ненужных записей.
4. Выбор индексов в MySQL
В самом простом случае, индекс необходимо создавать для тех колонок, которые присутствуют в условии WHERE.
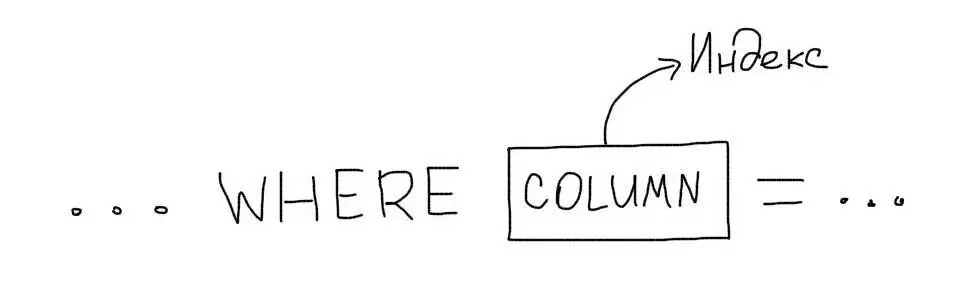
Рассмотрим запрос из примера:
Нам необходимо создать индекс на колонку age:
После этой операции MySQL начнет использовать индекс age для выполнения подобных запросов. Индекс будет использоваться и для выборок по диапазонам значений этой колонки:
Сортировка
Для запросов такого вида:
Внутренности хранения индексов
Представим, что наша таблица выглядит так:
После создания индекса на колонку age, MySQL сохранит все ее значения в отсортированном виде:
Кроме этого, будет сохранена связь между значением в индексе и записью, которой соответствует это значение. Обычно для этого используется первичный ключ:
Уникальные индексы
MySQL поддерживает уникальные индексы. Это удобно для колонок, значения в которых должны быть уникальными по всей таблице. Такие индексы улучшают эффективность выборки для уникальных значений. Например:
На колонку email необходимо создать уникальный индекс:
Тогда при поиске данных, MySQL остановится после обнаружения первого соответствия. В случае обычного индекса будет обязательно проведена еще одна проверка (следующего значения в индексе).
5. Составные индексы
MySQL может использовать только один индекс для запроса (кроме случаев, когда MySQL способен объединить результаты выборок по нескольким индексам). Поэтому, для запросов, в которых используется несколько колонок, необходимо использовать составные индексы.
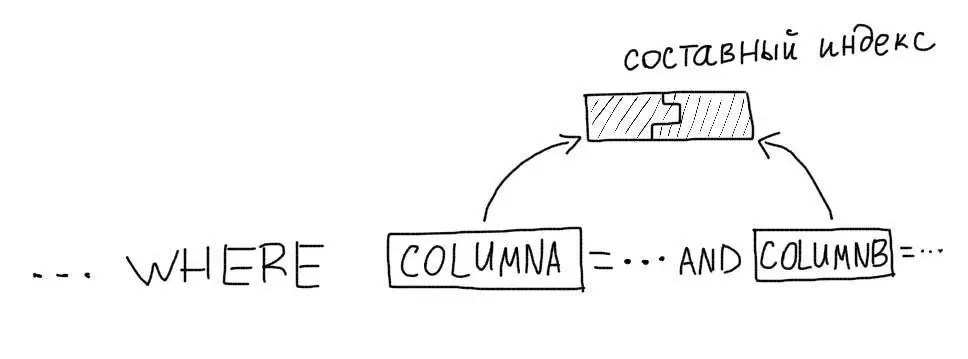
Рассмотрим такой запрос:
Нам следует создать составной индекс на обе колонки:
Устройство составного индекса
Чтобы правильно использовать составные индексы, необходимо понять структуру их хранения. Все работает точно так же, как и для обычного индекса. Но для значений используются значения всех входящих колонок сразу. Для таблицы с такими данными:
значения составного индекса будут такими:
Это означает, что очередность колонок в индексе будет играть большую роль. Обычно колонки, которые используются в условиях WHERE, следует ставить в начало индекса. Колонки из ORDER BY — в конец.
Поиск по диапазону
Представим, что наш запрос будет использовать не сравнение, а поиск по диапазону:
Тогда MySQL не сможет использовать полный индекс, т.к. значения gender будут отличаться для разных значений колонки age. В этом случае база данных попытается использовать часть индекса (только age), чтобы выполнить этот запрос:
Сортировка
Составные индексы также можно использовать, если выполняется сортировка:
В этом случае нам нужно будет создать индекс в другом порядке, т.к. сортировка (ORDER) происходит после фильтрации (WHERE):
Такой порядок колонок в индексе позволит выполнить фильтрацию по первой части индекса, а затем отсортировать результат по второй.
Колонок в индексе может быть больше, если требуется:
В этом случае следует создать такой индекс:
6. Использование EXPLAIN для анализа индексов
Инструкция EXPLAIN покажет данные об использовании индексов для конкретного запроса. Например:
Колонка key показывает используемый индекс. Колонка possible_keys показывает все индексы, которые могут быть использованы для этого запроса. Колонка rows показывает число записей, которые пришлось прочитать базе данных для выполнения этого запроса (в таблице всего 336 записей).
Как видим, в примере не используется ни один индекс. После создания индекса:
Прочитана всего одна запись, так как был использован индекс.
Проверка длины составных индексов
Explain также поможет определить правильность использования составного индекса. Проверим запрос из примера (с индексом на колонки age и gender):
Если мы изменим точное сравнение на поиск по диапазону, увидим что MySQL использует только часть индекса:
Это сигнал о том, что созданный индекс не подходит для этого запроса. Если же мы создадим правильный индекс:
В этом случае MySQL использует весь индекс gender_age, т.к. порядок колонок в нем позволяет сделать эту выборку.
7. Селективность индексов
Вернемся к запросу:
Для такого запроса необходимо создать составной индекс. Но как правильно выбрать последовательность колонок в индексе? Варианта два:
Подойдут оба. Но работать они будут с разной эффективностью.
Чтобы понять это, рассмотрим уникальность значений каждой колонки и количество соответствующих записей в таблице:
68 rows in set (0.00 sec)
Эта информация говорит нам вот о чем:
Если колонка age будет идти первой в индексе, тогда MySQL после первой части индекса сократит количество записей до 200. Останется сделать выборку по ним. Если же колонка gender будет идти первой, то количество записей будет сокращено до 6000 после первой части индекса. Т.е. на порядок больше, чем в случае age.
Это значит, что индекс age_gender будет работать лучше, чем gender_age.
8. Первичные ключи
Первичный ключ (Primary Key) — это особый тип индекса, который является идентификатором записей в таблице. Он обязательно уникальный и указывается при создании таблиц:
При использовании таблиц InnoDB всегда определяйте первичные ключи. Если первичного ключа нет, MySQL все равно создаст виртуальный скрытый ключ.
Кластерные индексы
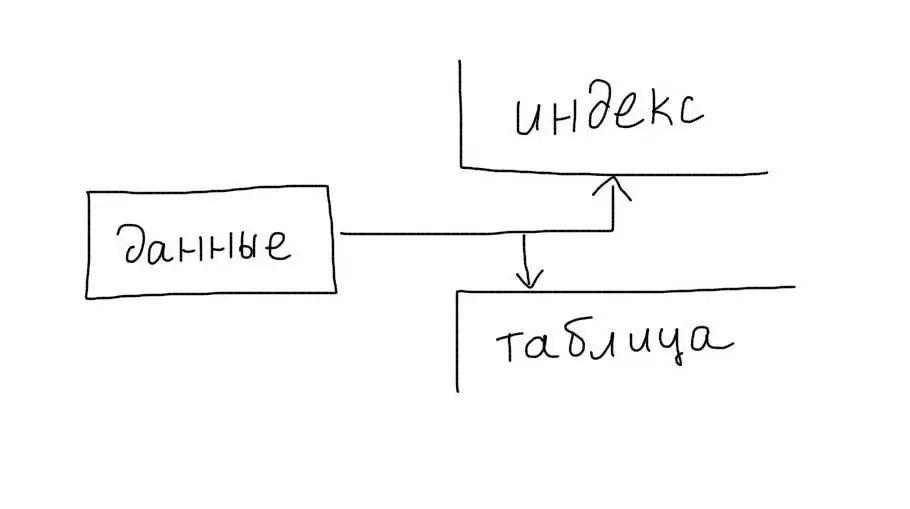
Обычные индексы являются некластерными. Это означает, что сам индекс хранит только ссылки на записи таблицы. Когда происходит работа с индексом, определяется только список записей (точнее список их первичных ключей), подходящих под запрос. После этого происходит еще один запрос — для получения данных каждой записи из этого списка.
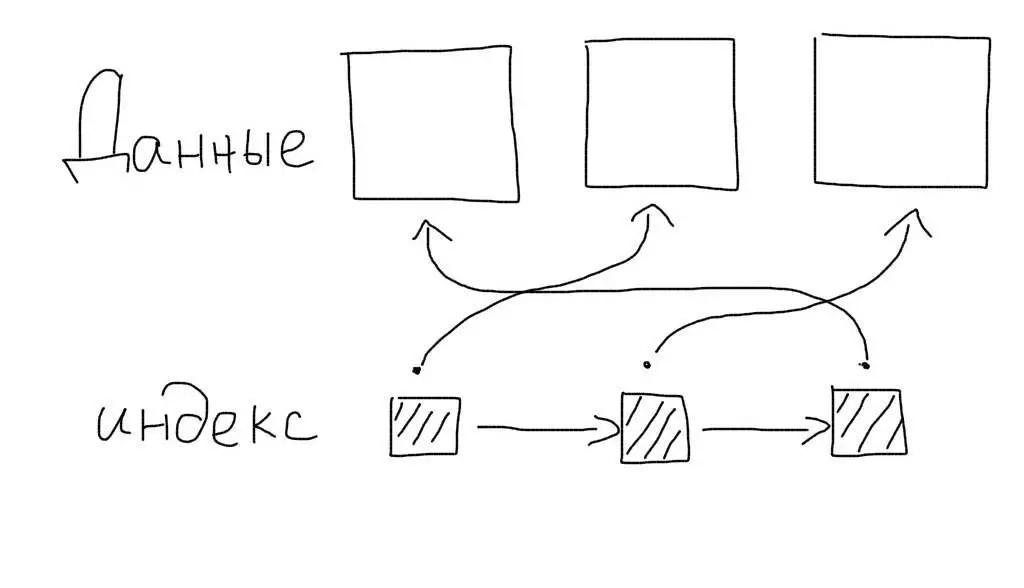
Кластерные индексы сохраняют данные записей целиком, а не ссылки на них. При работе с таким индексом не требуется дополнительной операции чтения данных.
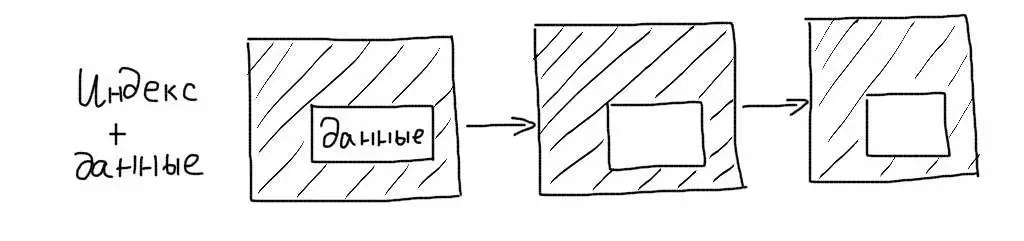
Первичные ключи таблиц InnoDB являются кластерными. Поэтому выборки по ним происходят очень эффективно.
Overhead
Важно помнить, что индексы предполагают дополнительные операции записи на диск. При каждом обновлении или добавлении данных в таблицу, происходит также запись и обновление данных в индексе.
Создавайте только необходимые индексы, чтобы не расходовать зря ресурсы сервера. Контролируйте размеры индексов для Ваших таблиц:
Когда создавать индексы?
- Индексы следует создавать по мере обнаружения медленных запросов. В этом поможет slow log в MySQL. Запросы, которые выполняются более 1 секунды, являются первыми кандидатами на оптимизацию.
- Начинайте создание индексов с самых частых запросов. Запрос, выполняющийся секунду, но 1000 раз в день наносит больше ущерба, чем 10-секундный запрос, который выполняется несколько раз в день.
- Не создавайте индексы на таблицах, число записей в которых меньше нескольких тысяч. Для таких размеров выигрыш от использования индекса будет почти незаметен.
- Не создавайте индексы заранее, например, в среде разработки. Индексы должны устанавливаться исключительно под форму и тип нагрузки работающей системы.
- Удаляйте неиспользуемые индексы.
Самое важное
Выделяйте достаточно времени на анализ и организацию индексов в MySQL (и других базах данных). На это может уйти намного больше времени, чем на проектирование структуры базы данных. Удобно будет организовать тестовую среду с копией реальных данных и проверять там разные структуры индексов.
Не создавайте индексы на каждую колонку, которая есть в запросе, MySQL так не работает. Используйте уникальные индексы, где необходимо. Всегда устанавливайте первичные ключи.
Highload нужны авторы технических текстов. Вы наш человек, если разбираетесь в разработке, знаете языки программирования и умеете просто писать о сложном!
Откликнуться на вакансию можно здесь .
Основные понятия о шардинге и репликации
Примеры ad-hoc запросов и технологии для их исполнения
Настройка Master-Master репликации на MySQL за 6 шагов
Как создать и использовать составной индекс в Mysql
Анализ медленных PHP скриптов с помощью XHprof
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Читайте также: