
Для построения кэш памяти используются
Обновлено: 07.07.2024
Кэш-память (КП), или кэш, представляет собой организованную в виде ассоциативного запоминающего устройства (АЗУ) быстродействующую буферную память ограниченного объема, которая располагается между регистрами процессора и относительно медленной основной памятью и хранит наиболее часто используемую информацию совместно с ее признаками (тегами), в качестве которых выступает часть адресного кода.
В процессе работы отдельные блоки информации копируются из основной памяти в кэш - память . При обращении процессора за командой или данными сначала проверяется их наличие в КП. Если необходимая информация находится в кэше, она быстро извлекается. Это кэш-попадание. Если необходимая информация в КП отсутствует ( кэш-промах ), то она выбирается из основной памяти, передается в микропроцессор и одновременно заносится в кэш - память . Повышение быстродействия вычислительной системы достигается в том случае, когда кэш-попадания реализуются намного чаще, чем кэш-промахи.
Зададимся вопросом: "А как определить наиболее часто используемую информацию? Неужели сначала кто-то анализирует ход выполнения программы, определяет, какие команды и данные чаще используются, а потом, при следующем запуске программы, эти данные переписываются в кэш - память и уже тогда программа выполняется эффективно?" Конечно нет. Хотя в современных микропроцессорах имеется определенный механизм, который позволяет в некоторой степени реализовать этот принцип. Но в основном, конечно, кэш - память сама отбирает информацию, которая чаще всего используется. Рассмотрим, как это происходит.
Механизм сохранения информации в кэш-памяти
При включении микропроцессора в работу вся информация в его кэш-памяти недостоверна.
При обращении к памяти микропроцессор, как уже отмечалось, сначала проверяет, не содержится ли искомая информация в кэш-памяти.
Для этого сформированный им физический адрес сравнивается с адресами ячеек памяти, которые были ранее кэшированы из ОЗУ в КП.
При первом обращении такой информации в кэш -памяти, естественно, нет, и это соответствует кэш-промаху. Тогда микропроцессор проводит обращение к оперативной памяти, извлекает нужную информацию, использует ее в своей работе, но одновременно записывает эту информацию в кэш .
Если бы в кэш - память заносилась только востребованная микропроцессором в данный момент информация , то, скорее всего, при следующем обращении вновь произошел бы кэш-промах: вряд ли следующее обращение произойдет к той же самой команде или к тому же самому операнду. Кэш-попадания происходили бы лишь после того, как в КП накопится достаточно большой фрагмент программы, содержащий некоторые циклические участки кода, или фрагмент данных, подлежащих повторной обработке. Для того чтобы уже следующее обращение к КП приводило как можно чаще к кэш-попаданиям, передача из оперативной памяти в кэш - память происходит не теми порциями (байтами или словами), которые востребованы микропроцессором в данном обращении, а так называемыми строками. То есть кэш - память и оперативная память с точки зрения кэширования организуются в виде строк. Длина строки превышает максимально возможную длину востребованных микропроцессором данных. Обычно она составляет от 16 до 64 байт и выровнена в памяти по границе соответствующего раздела (рис. 4.1).
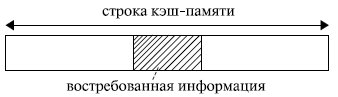
Рис. 4.1. Организация обмена между оперативной и кэш-памятью
Высокий процент кэш-попаданий в этом случае обеспечивается благодаря тому, что в большинстве случаев программы обращаются к ячейкам памяти, расположенным вблизи от ранее использованных. Это свойство, называемое принципом локальности ссылок, обеспечивает эффективность использования КП. Оно подразумевает, что при исполнении программы в течение некоторого относительно малого интервала времени происходит обращение к памяти в пределах ограниченного диапазона адресов (как по коду программы, так и по данным).
Например, микропроцессору для своей работы потребовалось 2 байта информации. Если строка имеет длину 16 байт , то в кэш переписываются не только нужные 2 байта, но и некоторое их окружение. Когда микропроцессор обращается за новой информацией, в силу локальности ссылок, скорее всего, обращение произойдет по соседнему адресу. Затем опять по соседнему, опять по соседнему и т. д. Таким образом, ряд следующих обращений будет происходить непосредственно к кэш -памяти, минуя оперативную память (кэш-попадания). Когда очередной сформированный микропроцессором физический адрес выйдет за пределы строки кэш -памяти (произойдет кэш-промах ), будет выполнена подкачка в кэш новой строки, и вновь ряд последующих обращений вызовет кэш-попадания.
Чем длиннее используемая при обмене между оперативной и кэшпамятью строка, тем больше вероятность того, что следующее обращение произойдет в пределах этой строки. Но в то же время чем длиннее строка, тем дольше она будет перекачиваться из оперативной памяти в кэш . И если очередная команда окажется командой перехода или выборка данных начнется из нового массива, то есть следующее обращение произойдет не по соседнему адресу, то время, затраченное на передачу длинной строки, будет использовано напрасно. Поэтому при выборе длины строки должен быть разумный компромисс между соотношением времени обращения к оперативной и кэш -памяти и вероятностью достаточно удаленного перехода от текущего адреса при выполнении программы. Обычно длина строки определяется в результате моделирования аппаратно-программной структуры системы .
После того как в КП накопится достаточно большой объем информации, увеличивается вероятность того, что формирование очередного адреса приведет к кэш-попаданию. Особенно велика вероятность этого при выполнении циклических участков программы.
Старая информация по возможности сохраняется в кэш -памяти. Ее замена на новую определяется емкостью, организацией и стратегией обновления кэша.
Типы кэш-памяти
Если каждая строка ОЗУ имеет только одно фиксированное место , на котором она может находиться в кэш -памяти, то такая кэш - память называется памятью с прямым отображением.
Предположим, что ОЗУ состоит из 1000 строк с номерами от 0 до 999, а кэш - память имеет емкость только 100 строк. В кэш -памяти с прямым отображением строки ОЗУ с номерами 0, 100, 200, . 900 могут сохраняться только в строке 0 КП и нигде иначе, строки 1, 101, 201, …, 901
ОЗУ - в строке 1 КП, строки ОЗУ с номерами 99, 199, …, 999 сохраняются в строке 99 кэш -памяти (рис. 4.2). Такая организация кэш -памяти обеспечивает быстрый поиск в ней нужной информации: необходимо проверить ее наличие только в одном месте. Однако емкость КП при этом используется не в полной мере: несмотря на то, что часть кэш -памяти может быть не заполнена, будет происходить вытеснение из нее полезной информации при последовательных обращениях, например, к строкам 101, 301, 101 ОЗУ .
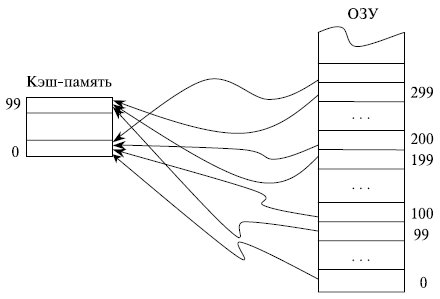
Рис. 4.2. Принцип организации кэш-памяти с прямым отображением
Кэш - память называется полностью ассоциативной, если каждая строка ОЗУ может располагаться в любом месте кэш -памяти.
В полностью ассоциативной кэш -памяти максимально используется весь ее объем: вытеснение сохраненной в КП информации проводится лишь после ее полного заполнения. Однако поиск в кэш -памяти, организованной подобным образом, представляет собой трудную задачу.
Компромиссом между этими двумя способами организации кэш -памяти служит множественно-ассоциативная КП, в которой каждая строка ОЗУ может находиться по ограниченному множеству мест в кэш -памяти.
При необходимости замещения информации в кэш -памяти на новую используется несколько стратегий замещения. Наиболее известными среди них являются:
- LRU - замещается строка, к которой дольше всего не было обращений;
- FIFO - замещается самая давняя по пребыванию в кэш-памяти строка;
- Random - замещение проходит случайным образом.
Последний вариант, существенно экономя аппаратные средства по сравнению с другими подходами, в ряде случаев обеспечивает и более эффективное использование кэш -памяти. Предположим, например, что КП имеет объем 4 строки, а некоторый циклический участок программы имеет длину 5 строк. В этом случае при стратегиях LRU и FIFO кэш - память окажется фактически бесполезной ввиду отсутствия кэш -попаданий. В то же время при использовании стратегии случайного замещения информации часть обращений к КП приведет к кэш -попаданиям.
Некоторые эвристические оценки вероятности кэш -промаха при разных стратегиях замещения (в процентах) представлены в табл. 4.1.
Анализ таблицы показывает, что:
- увеличением емкости кэша, естественно, уменьшается вероятность кэш-промаха, но даже при незначительной на сегодняшний день емкости кэш-памяти в 16 Кбайт около 95 % обращений происходят к КП, минуя оперативную память;
- чем больше степень ассоциативности кэш-памяти, тем больше вероятность кэш-попадания за счет более полного заполнения КП (время поиска информации в КП в данном анализе не учитывается);
- механизм LRU обеспечивает более высокую вероятность кэш-попадания по сравнению с механизмом случайного замещения Random , однако этот выигрыш не очень значителен.
Соответствие между данными в оперативной памяти и в кэш -памяти обеспечивается внесением изменений в те области ОЗУ , для которых данные в кэш -памяти подверглись изменениям. Существует два основных способа реализации этих действий: со сквозной записью ( writethrough ) и с обратной записью ( write-back ).
При считывании оба способа работают идентично. При записи кэширование со сквозной записью обновляет основную память параллельно с обновлением информации в КП. Это несколько снижает быстродействие системы, так как микропроцессор впоследствии может вновь обратиться по этому же адресу для записи информации, и предыдущая пересылка строки кэш -памяти в ОЗУ окажется бесполезной. Однако при таком подходе содержимое соответствующих друг другу строк ОЗУ и КП всегда идентично. Это играет большую роль в мультипроцессорных системах с общей оперативной памятью.
Кэширование с обратной записью модифицирует строку ОЗУ лишь при вытеснении строки кэш -памяти, например, в случае необходимости освобождения места для записи новой строки из ОЗУ в уже заполненную КП. Операции обратной записи также инициируются механизмом поддержания согласованности кэш -памяти при работе мультипроцессорной системы с общей оперативной памятью.
Промежуточное положение между этими подходами занимает способ, при котором все строки, предназначенные для передачи из КП в ОЗУ , предварительно накапливаются в некотором буфере. Передача осуществляется либо при вытеснении строки, как в случае кэширования с обратной записью, либо при необходимости согласования кэш -памяти нескольких микропроцессоров в мультипроцессорной системе, либо при заполнении буфера. Такая передача проводится в пакетном режиме, что более эффективно, чем передача отдельной строки.
На днях решил систематизировать знания, касающиеся принципов отображения оперативной памяти на кэш память процессора. В результате чего и родилась данная статья.
Кэш память процессора используется для уменьшения времени простоя процессора при обращении к RAM.
Основная идея кэширования опирается на свойство локальности данных и инструкций: если происходит обращение по некоторому адресу, то велика вероятность, что в ближайшее время произойдет обращение к памяти по тому же адресу либо по соседним адресам.
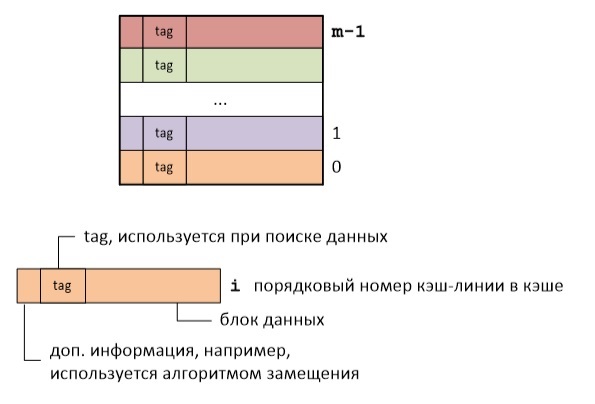
Логически кэш-память представляет собой набор кэш-линий. Каждая кэш-линия хранит блок данных определенного размера и дополнительную информацию. Под размером кэш-линии понимают обычно размер блока данных, который в ней хранится. Для архитектуры x86 размер кэш линии составляет 64 байта.
Так вот суть кэширования состоит в разбиении RAM на кэш-линии и отображении их на кэш-линии кэш-памяти. Возможно несколько вариантов такого отображения.
DIRECT MAPPING
Основная идея прямого отображения (direct mapping) RAM на кэш-память состоит в следующем: RAM делится на сегменты, причем размер каждого сегмента равен размеру кэша, а каждый сегмент в свою очередь делится на блоки, размер каждого блока равен размеру кэш-линии.

Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на одну и ту же кэш-линию кэша:
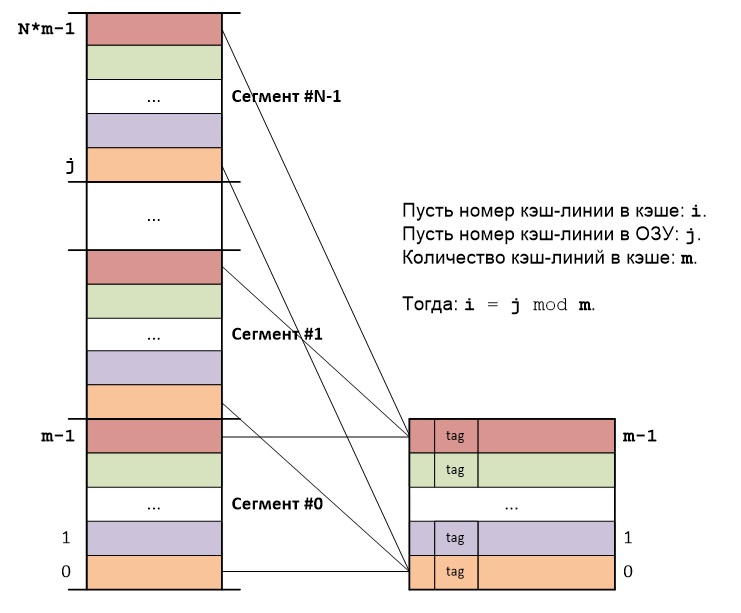
Адрес каждого байта представляет собой сумму порядкового номера сегмента, порядкового номера кэш-линии внутри сегмента и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера сегментов, а порядковые номера кэш-линий внутри сегментов и порядковые номера байт внутри кэш-линий — повторяются.
Таким образом нет необходимости хранить полный адрес кэш-линии, достаточно сохранить только старшую часть адреса. Тэг (tag) каждой кэш-линии как раз и хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий в кэше.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий внутри каждого сегмента потребуется: log2m бит.
m = Объем кэш-памяти/Размер кэш линии.
Для адресации N сегментов RAM: log2N бит.
N = Объем RAM/Размер сегмента.
Для адресации байта потребуется: log2N + log2m + log2b бит.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер кэш-линии в кэше.
2. Тэг кэш-линии с данным номером сравнивается со старшей частью адреса (log2N).
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
FULLY ASSOCIATIVE MAPPING
Основная идея полностью ассоциативного отображения (fully associative mapping) RAM на кэш-память состоит в следующем: RAM делится на блоки, размер которых равен размеру кэш-линий, а каждый блок RAM может сохраняться в любой кэш-линии кэша:
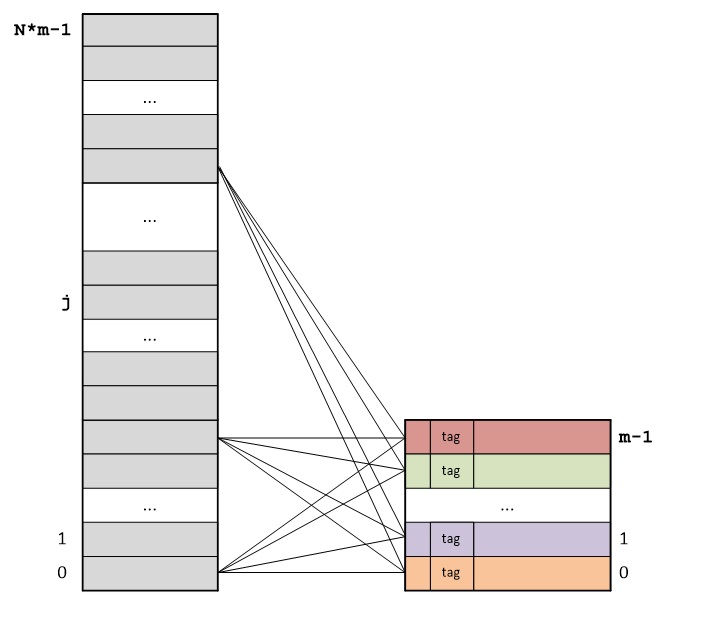
Адрес каждого байта представляет собой сумму порядкового номера кэш-линии и порядкового номера байта внутри кэш-линии. Отсюда следует, что адреса байт различаются только старшими частями, представляющими собой порядковые номера кэш-линий. Порядковые номера байт внутри кэш-линий повторяются.
Тэг (tag) каждой кэш-линии хранит старшую часть адреса первого байта в данной кэш-линии.
b — размер кэш-линии.
m — количество кэш-линий, умещающихся в RAM.
Для адресации b байт внутри каждой кэш-линии потребуется: log2b бит.
Для адресации m кэш-линий: log2m бит.
m = Размер RAM/Размер кэш-линии.
Для адресации байта потребуется: log2m + log2b бит.
Этапы поиска в кэше:
1. Тэги всех кэш-линий сравниваются со старшей частью адреса одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
SET ASSOCIATIVE MAPPING
Основная идея наборно ассоциативного отображения (set associative mapping) RAM на кэш-память состоит в следующем: RAM делится также как и в прямом отображении, а сам кэш состоит из k кэшей (k каналов), использующих прямое отображение.
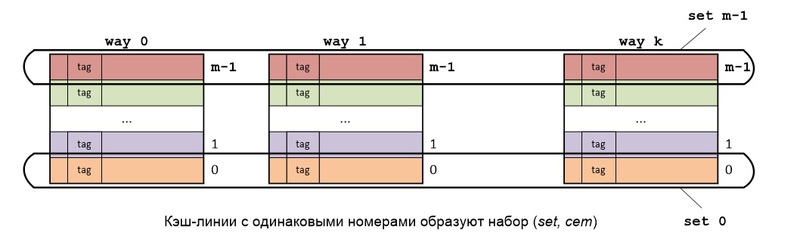
Кэш-линии, имеющие одинаковые номера во всех каналах, образуют set (набор, сэт). Каждый set представляет собой кэш, в котором используется полностью ассоциативное отображение.
Блоки RAM из разных сегментов, но с одинаковыми номерами в этих сегментах, всегда будут отображаться на один и тот же set кэша. Если в данном сете есть свободные кэш-линии, то считываемый из RAM блок будет сохраняться в свободную кэш-линию, если же все кэш-линии сета заняты, то кэш-линия выбирается согласно используемому алгоритму замещения.
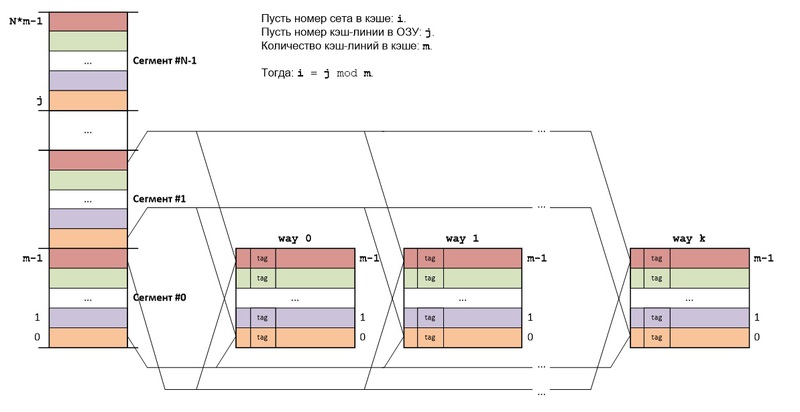
Структура адреса байта в точности такая же, как и в прямом отображении: log2N + log2m + log2b бит, но т.к. set представляет собой k различных кэш-линий, то поиск в кэше немного отличается.
Этапы поиска в кэше:
1. Извлекается средняя часть адреса (log2m), определяющая номер сэта в кэше.
2. Тэги всех кэш-линий данного сета сравниваются со старшей частью адреса (log2N) одновременно.
Если было совпадение по одному из тэгов, то произошло кэш-попадание.
Если не было совпадение ни по одному из тэгов, то произошел кэш-промах.
Т.о количество каналов кэша определяет количество одновременно сравниваемых тэгов.

Для многих пользователей основополагающими критериями выбора процессора являются его тактовая частота и количество вычислительных ядер. А вот параметры кэш-памяти многие просматривают поверхностно, а то и вовсе не уделяют им должного внимания. А зря!
В данном материале поговорим об устройстве и назначении сверхбыстрой памяти процессора, а также ее влиянии на общую скорость работы персонального компьютера.
Предпосылки создания кэш-памяти
Любому пользователю, мало-мальски знакомому с компьютером, известно, что в составе ПК работает сразу несколько типов памяти. Это медленная постоянная память (классические жесткие диски или более быстрые SSD-накопители), быстрая оперативная память и сверхбыстрая кэш-память самого процессора. Оперативная память энергозависимая, поэтому каждый раз, когда вы выключаете или перезагружаете компьютер, все хранящиеся в ней данные очищаются, в отличие от постоянной памяти, в которой данные сохраняются до тех пор, пока это нужно пользователю. Именно в постоянную память записаны все программы и файлы, необходимые как для работы компьютера, так и для комфортной работы за ним.
Каждый раз при запуске программы из постоянной памяти, ее наиболее часто используемые данные или вся программа целиком «подгружаются» в оперативную память. Это делается для ускорения обработки данных процессором. Считывать и обрабатывать данные из оперативной памяти процессор будет значительно быстрей, а, следовательно, и система будет работать значительно быстрее в сравнении с тем, если бы массивы данных поступали напрямую из не очень быстрых (по меркам процессорных вычислений) накопителей.
Если бы не было «оперативки», то процесс считывания напрямую с накопителя занимал бы непозволительно огромное, по меркам вычислительной мощности процессора, время.

Но вот незадача, какой бы быстрой ни была оперативная память, процессор всегда работает быстрее. Процессор — это настолько сверхмощный «калькулятор», что произвести самые сложные вычисления для него — это даже не доля секунды, а миллионные доли секунды.
Производительность процессора в любом компьютере всегда ограничена скоростью считывания из оперативной памяти.
Процессоры развиваются так же быстро, как память, поэтому несоответствие в их производительности и скорости сохраняется. Производство полупроводниковых изделий постоянно совершенствуется, поэтому на пластину процессора, которая сохраняет те же размеры, что и 10 лет назад, теперь можно поместить намного больше транзисторов. Как следствие, вычислительная мощность за это время увеличилась. Впрочем, не все производители используют новые технологии для увеличения именно вычислительной мощности. К примеру, производители оперативной памяти ставят во главу угла увеличение ее емкости: ведь потребитель намного больше ценит объем, нежели ее быстродействие. Когда на компьютере запущена программа и процессор обращается к ОЗУ, то с момента запроса до получения данных из оперативной памяти проходит несколько циклов процессора. А это неправильно — вычислительная мощность процессора простаивает, и относительно медленная «оперативка» тормозит его работу.
Такое положение дел, конечно же, мало кого устраивает. Одним из вариантов решения проблемы могло бы стать размещение блока сверхбыстрой памяти непосредственно на теле кристалла процессора и, как следствие, его слаженная работа с вычислительным ядром. Но проблема, мешающая реализации этой идеи, кроется не в уровне технологий, а в экономической плоскости. Такой подход увеличит размеры готового процессора и существенно повысит его итоговую стоимость.

Объяснить простому пользователю, голосующему своими кровными сбережениями, что такой процессор самый быстрый и самый лучший, но за него придется отдать значительно больше денег — довольно проблематично. К тому же существует множество стандартов, направленных на унификацию оборудования, которым следуют производители «железа». В общем, поместить оперативную память прямо на кристалл процессора не представляется возможным по ряду объективных причин.
Как работает кэш-память
Как стало понятно из постановки задачи, данные должны поступать в процессор достаточно быстро. По меркам человека — это миг, но для вычислительного ядра — достаточно большой промежуток времени, и его нужно как можно эффективнее минимизировать. Вот здесь на выручку и приходит технология, которая называется кэш-памятью. Кэш-память — это сверхбыстрая память, которую располагают прямо на кристалле процессора. Извлечение данных из этой памяти не занимает столько времени, сколько бы потребовалось для извлечения того же объема из оперативной памяти, следовательно, процессор молниеносно получает все необходимые данные и может тут же их обрабатывать.
Кэш-память — это, по сути, та же оперативная память, только более быстрая и дорогая. Она имеет небольшой объем и является одним из компонентов современного процессора.
На этом преимущества технологии кэширования не заканчиваются. Помимо своего основного параметра — скорости доступа к ячейкам кэш-памяти, т. е. своей аппаратной составляющей, кэш-память имеет еще и множество других крутых функций. Таких, к примеру, как предугадывание, какие именно данные и команды понадобятся пользователю в дальнейшей работе и заблаговременная загрузка их в свои ячейки. Но не стоит путать это со спекулятивным исполнением, в котором часть команд выполняется рандомно, дабы исключить простаивание вычислительных мощностей процессора.
Спекулятивное исполнение — метод оптимизации работы процессора, когда последний выполняет команды, которые могут и не понадобиться в дальнейшем. Использование метода в современных процессорах довольно существенно повышает их производительность.
Речь идет именно об анализе потока данных и предугадывании команд, которые могут понадобиться в скором будущем (попадании в кэш). Это так называемый идеальный кэш, способный предсказать ближайшие команды и заблаговременно выгрузить их из ОЗУ в ячейки сверхбыстрой памяти. В идеале их надо выбирать таким образом, чтобы конечный результат имел нулевой процент «промахов».
Но как процессор это делает? Процессор что, следит за пользователем? В некоторой степени да. Он выгружает данные из оперативной памяти в кэш-память для того, чтобы иметь к ним мгновенный доступ, и делает это на основе предыдущих данных, которые ранее были помещены в кэш в этом сеансе работы. Существует несколько способов, увеличивающих число «попаданий» (угадываний), а точнее, уменьшающих число «промахов». Это временная и пространственная локальность — два главных принципа кэш-памяти, благодаря которым процессор выбирает, какие данные нужно поместить из оперативной памяти в кэш.
Временная локальность
Процессор смотрит, какие данные недавно содержались в его кэше, и снова помещает их в кэш. Все просто: высока вероятность того, что выполняя какие-либо задачи, пользователь, скорее всего, повторит эти же действия. Процессор подгружает в ячейки сверхбыстрой памяти наиболее часто выполняемые задачи и сопутствующие команды, чтобы иметь к ним прямой доступ и мгновенно обрабатывать запросы.
Пространственная локальность
Принцип пространственной локальности несколько сложней. Когда пользователь выполняет какие-то действия, процессор помещает в кэш не только данные, которые находятся по одному адресу, но еще и данные, которые находятся в соседних адресах. Логика проста — если пользователь работает с какой-то программой, то ему, возможно, понадобятся не только те команды, которые уже использовались, но и сопутствующие «слова», которые располагаются рядом.
Набор таких адресов называется строкой (блоком) кэша, а количество считанных данных — длиной кэша.
При пространственной локации процессор сначала ищет данные, загруженные в кэш, и, если их там не находит, то обращается к оперативной памяти.
Иерархия кэш-памяти
Любой современный процессор имеет в своей структуре несколько уровней кэш-памяти. В спецификации процессора они обозначаются как L1, L2, L3 и т. д.

Если провести аналогию между устройством кэш-памяти процессора и рабочим местом, скажем столяра или представителя любой другой профессии, то можно увидеть интересную закономерность. Наиболее востребованный в работе инструмент находится под рукой, а тот, что используется реже, расположен дальше от рабочей зоны.
Так же организована и работа быстрых ячеек кэша. Ячейки памяти первого уровня (L1) располагаются на кристалле в непосредственной близости от вычислительного ядра. Эта память — самая быстрая, но и самая малая по объему. В нее помещаются наиболее востребованные данные и команды. Для передачи данных оттуда потребуется всего около 5 тактовых циклов. Как правило, кэш-память первого уровня состоит из двух блоков, каждый из которых имеет размер 32 КБ. Один из них — кэш данных первого уровня, второй — кэш инструкций первого уровня. Они отвечают за работу с блоками данных и молниеносное обращение к командам.
Кэш второго и третьего уровня больше по объему, но за счет того, что L2 и L3 удалены от вычислительного ядра, при обращении к ним будут более длительные временные интервалы. Более наглядно устройство кэш-памяти проиллюстрировано в следующем видео.
Кэш L2, который также содержит команды и данные, занимает уже до 512 КБ, чтобы обеспечить необходимый объем данных кэшу нижнего уровня. Но на обработку запросов уходит в два раза больше времени. Кэш третьего уровня имеет размеры уже от 2 до 32 МБ (и постоянно увеличивается вслед за развитием технологий), но и его скорость заметно ниже. Она превышает 30 тактовых циклов.

Процессор запрашивает команды и данные, обрабатывая их, что называется, параллельными курсами. За счет этого и достигается потрясающая скорость работы. В качестве примера рассмотрим процессоры Intel. Принцип работы таков: в кэше хранятся данные и их адрес (тэг кэша). Сначала процессор ищет их в L1. Если информация не найдена (возник промах кэша), то в L1 будет создан новый тэг, а поиск данных продолжится на других уровнях. Для того, чтобы освободить место под новый тэг, информация, не используемая в данный момент, переносится на уровень L2. В результате данные постоянно перемещаются с одного уровня на другой.
Также при хранении одних и тех же данных могут задействоваться различные уровни кэша, например, L1 и L3. Это так называемые инклюзивные кэши. Использование лишнего объема памяти окупается скоростью поиска. Если процессор не нашел данные на нижнем уровне, ему не придется искать их на верхних уровнях кэша. В этом случае задействованы кэши-жертвы. Это полностью ассоциативный кэш, который используется для хранения блоков, вытесненных из кэша при замене. Он предназначен для уменьшения количества промахов. Например, кэши-жертвы L3 будут хранить информацию из L2. В то же время данные, которые хранятся в L2, остаются только там, что помогает сэкономить место в памяти, однако усложняет поиск данных: системе приходится искать необходимый тэг в L3, который заметно больше по размеру.
В некоторых политиках записи информация хранится в кэше и основной системной памяти. Современные процессоры работают следующим образом: когда данные пишутся в кэш, происходит задержка перед тем, как эта информация будет записана в системную память. Во время задержки данные остаются в кэше, после чего их «вытесняет» в ОЗУ.
Итак, кэш-память процессора — очень важный параметр современного процессора. От количества уровней кэша и объема ячеек сверхбыстрой памяти на каждом из уровней, во многом зависит скорость и производительность системы. Особенно хорошо это ощущается в компьютерах, ориентированных на гейминг или сложные вычисления.
Рис. 5.36. Типовые значения ключевых параметров для кэш-памяти рабочих станций и серверов
Все термины, которые были определены раньше могут быть использованы и для кэш-памяти, хотя слово "строка" (line) часто употребляется вместо слова "блок" (block).
На рисунке 5.36 представлен типичный набор параметров, который используется для описания кэш-памяти.
Рассмотрим организацию кэш-памяти более детально, отвечая на четыре вопроса об иерархии памяти.
1. Где может размещаться блок в кэш-памяти?
- Если каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти, то такая кэш-память называется кэшем с прямым отображением (direct mapped). Это наиболее простая организация кэш-памяти, при которой для отображение адресов блоков основной памяти на адреса кэш-памяти просто используются младшие разряды адреса блока. Таким образом, все блоки основной памяти, имеющие одинаковые младшие разряды в своем адресе, попадают в один блок кэш-памяти, т.е.
- Если некоторый блок основной памяти может располагаться на любом месте кэш-памяти, то кэш называется полностью ассоциативным (fully associative).
- Если некоторый блок основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется множественно-ассоциативным (set associative). Обычно множество представляет собой группу из двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется множественно-ассоциативным с n каналами (n-way set associative). Для размещения блока прежде всего необходимо определить множество. Множество определяется младшими разрядами адреса блока памяти (индексом):
Далее, блок может размещаться на любом месте данного множества.
Диапазон возможных организаций кэш-памяти очень широк: кэш-память с прямым отображением есть просто одноканальная множественно-ассоциативная кэш-память, а полностью ассоциативная кэш-память с m блоками может быть названа m-канальной множественно-ассоциативной. В современных процессорах как правило используется либо кэш-память с прямым отображением, либо двух- (четырех-) канальная множественно-ассоциативная кэш-память.
2. Как найти блок, находящийся в кэш-памяти?
У каждого блока в кэш-памяти имеется адресный тег, указывающий, какой блок в основной памяти данный блок кэш-памяти представляет. Эти теги обычно одновременно сравниваются с выработанным процессором адресом блока памяти.
Кроме того, необходим способ определения того, что блок кэш-памяти содержит достоверную или пригодную для использования информацию. Наиболее общим способом решения этой проблемы является добавление к тегу так называемого бита достоверности (valid bit).
Адресация множественно-ассоциативной кэш-памяти осуществляется путем деления адреса, поступающего из процессора, на три части: поле смещения используется для выбора байта внутри блока кэш-памяти, поле индекса определяет номер множества, а поле тега используется для сравнения. Если общий размер кэш-памяти зафиксировать, то увеличение степени ассоциативности приводит к увеличению количества блоков в множестве, при этом уменьшается размер индекса и увеличивается размер тега.
3. Какой блок кэш-памяти должен быть замещен при промахе?
При возникновении промаха, контроллер кэш-памяти должен выбрать подлежащий замещению блок. Польза от использования организации с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые. Выбирать просто нечего: на попадание проверяется только один блок и только этот блок может быть замещен. При полностью ассоциативной или множественно-ассоциативной организации кэш-памяти имеются несколько блоков, из которых надо выбрать кандидата в случае промаха. Как правило для замещения блоков применяются две основных стратегии: случайная и LRU.
В первом случае, чтобы иметь равномерное распределение, блоки-кандидаты выбираются случайно. В некоторых системах, чтобы получить воспроизводимое поведение, которое особенно полезно во время отладки аппаратуры, используют псевдослучайный алгоритм замещения.
Во втором случае, чтобы уменьшить вероятность выбрасывания информации, которая скоро может потребоваться, все обращения к блокам фиксируются. Заменяется тот блок, который не использовался дольше всех (LRU - Least-Recently Used).
Рис. 5.37. Сравнение долей промахов для алгоритма LRU и случайного алгоритма замещения
при нескольких размерах кэша и разных ассоциативностях при размере блока 16 байт
4. Что происходит во время записи?
При обращениях к кэш-памяти на реальных программах преобладают обращения по чтению. Все обращения за командами являются обращениями по чтению и большинство команд не пишут в память. Обычно операции записи составляют менее 10% общего трафика памяти. Желание сделать общий случай более быстрым означает оптимизацию кэш-памяти для выполнения операций чтения, однако при реализации высокопроизводительной обработки данных нельзя пренебрегать и скоростью операций записи.
К счастью, общий случай является и более простым. Блок из кэш-памяти может быть прочитан в то же самое время, когда читается и сравнивается его тег. Таким образом, чтение блока начинается сразу как только становится доступным адрес блока. Если чтение происходит с попаданием, то блок немедленно направляется в процессор. Если же происходит промах, то от заранее считанного блока нет никакой пользы, правда нет и никакого вреда.
Однако при выполнении операции записи ситуация коренным образом меняется. Именно процессор определяет размер записи (обычно от 1 до 8 байтов) и только эта часть блока может быть изменена. В общем случае это подразумевает выполнение над блоком последовательности операций чтение-модификация-запись: чтение оригинала блока, модификацию его части и запись нового значения блока. Более того, модификация блока не может начинаться до тех пор, пока проверяется тег, чтобы убедиться в том, что обращение является попаданием. Поскольку проверка тегов не может выполняться параллельно с другой работой, то операции записи отнимают больше времени, чем операции чтения.
- сквозная запись (write through, store through) - информация записывается в два места: в блок кэш-памяти и в блок более низкого уровня памяти.
- запись с обратным копированием (write back, copy back, store in) - информация записывается только в блок кэш-памяти. Модифицированный блок кэш-памяти записывается в основную память только когда он замещается. Для сокращения частоты копирования блоков при замещении обычно с каждым блоком кэш-памяти связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает был ли модифицирован блок, находящийся в кэш-памяти. Если он не модифицировался, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.
Оба подхода к организации записи имеют свои преимущества и недостатки. При записи с обратным копированием операции записи выполняются со скоростью кэш-памяти, и несколько записей в один и тот же блок требуют только одной записи в память более низкого уровня. Поскольку в этом случае обращения к основной памяти происходят реже, вообще говоря требуется меньшая полоса пропускания памяти, что очень привлекательно для мультипроцессорных систем. При сквозной записи промахи по чтению не влияют на записи в более высокий уровень, и, кроме того, сквозная запись проще для реализации, чем запись с обратным копированием. Сквозная запись имеет также преимущество в том, что основная память имеет наиболее свежую копию данных. Это важно в мультипроцессорных системах, а также для организации ввода/вывода.
Рис. 5.38. Обобщение методов оптимизации кэш-памяти
- разместить запись в кэш-памяти (write allocate) (называется также выборкой при записи (fetch on write)). Блок загружается в кэш-память, вслед за чем выполняются действия аналогичные выполняющимся при выполнении записи с попаданием. Это похоже на промах при чтении.
- не размещать запись в кэш-памяти (называется также записью в окружение (write around)). Блок модифицируется на более низком уровне и не загружается в кэш-память.
Обычно в кэш-памяти, реализующей запись с обратным копированием, используется размещение записи в кэш-памяти (в надежде, что последующая запись в этот блок будет перехвачена), а в кэш-памяти со сквозной записью размещение записи в кэш-памяти часто не используется (поскольку последующая запись в этот блок все равно пойдет в память).
Увеличение производительности кэш-памяти
Формула для среднего времени доступа к памяти в системах с кэш-памятью выглядит следующим образом:
Эта формула наглядно показывает пути оптимизации работы кэш-памяти: сокращение доли промахов, сокращение потерь при промахе, а также сокращение времени обращения к кэш-памяти при попадании. На рисунке 5.38 кратко представлены различные методы, которые используются в настоящее время для увеличения производительности кэш-памяти. Использование тех или иных методов определяется прежде всего целью разработки, при этом конструкторы современных компьютеров заботятся о том, чтобы система оказалась сбалансированной по всем параметрам.
При обращение процессором на прямую к оперативной памяти, ОП не успевает обслуживать поступающие заявки, процессору в этом случае приходится простаивать. Поэтому необходимо какими-либо методами согласовать быстродействие процессора и ОП. Сделать это можно 2 способами:
1. Построить ОП на более быстродействующей элементной базе (дорогостоящий)
2. Использовать специальное структурное решение при организации уровней подсистемы памяти, а именно включений между процессором и ОП быстродействующий КЭШ.
Отличительными особенностями КЭШ являются:
1. Малый объем (от 8кбайт)
2. Быстродействие сравнимое с быстродействием процессора.
КЭШ – это тайник, недоступно для программ, так как не может быть адресовано машинными командами.

Суть заключается в следующем, когда процессору понадобилась информация, сначала он обращается к КЭШ памяти, если информация там есть (такое событие называется КЭШ попаданием), то нужное слово извлекается из КЭШ и передается процессору. Если нет (КЭШ промах), то идет обращение к оперативной памяти, информация помещается в КЭШ затем передается процессору.

Пусть ОП состоит из 2 n адресуемых слов, можно представить ОП под совокупность блоков фиксированной длинны по «к» слов в каждом. Тогда емкость оперативной памяти можно записать следующим выражением M= 2 n / k.
КЭШ память состоит из C строк по «к» слов в каждой. Причем емкость КЭШ во много раз меньше емкости ОП.
В процессе выполнения задачи, некоторое подмножество блоков в ОП находятся строго в КЭШ. Каждая строка в КЭШ снабжается ТЭГом, является служебной областью, как правило ТЭГ содержит старшие разряды поля адресов памяти. ТЭГ нужен для установления соответствия между ОП и КЭШ.
Структурная организация КЭШ

Важной отличительной особенностью КЭШ является то, что две операции передачи слова и загрузка блока в ОП могут происходить одновременно. КЭШ соединен с процессором линиями: адрес, данные, управление. Линии данные и адрес подключены к соответствующим буфером. Эти буферы имеют выход на системную магистраль, через которую они могут обмениваться с ОП информацией. Если происходит событие КЭШ попадания, то буферы адреса и данных блокируется.
Если происходит КЭШ попадание, то буферы адреса и данных блокируются, весь процесс обращения ведется без участия ОП.
Если происходит событие КЭШ промах, то затребованный процессором адрес выставляется в буфер адреса , передается на системную магистраль, затем происходит поиск в ОП, блок информации копируется в буфер данных, затем передается в КЭШ, затем ЦП.
Читайте также: