
Днк компьютер принцип работы
Обновлено: 04.07.2024
Скорость работы и объемы хранения цифровых данных выросли за последние 50 лет невероятно, но компьютерная эволюция подходит к пределу физических возможностей. Закон Мура, сформулированный еще в 1965 году, гласит, что компьютерная мощность (транзисторная плотность) удваивается примерно каждые полтора года, но как может этот рост продолжаться и не упереться в ограничения, налагаемые фундаментальной физикой?
Современные компьютеры работают на электрическом разряде и манипулируют битами информации, существующими в двух видах: 0 и 1. Квантовые компьютеры, с другой стороны, не настолько ограничены. Они кодируют информацию через 0 и 1, одновременно применяя принципы квантовой механики — наложение и перепутывание, то есть вместо последовательной работы сначала над одним расчетом, потом над другим (хоть и очень быстро) квантовые компьютеры могут обрабатывать сразу несколько разных задач одновременно. Фокус- покус: нам явится компьютер со скоростью обработки данных в миллион или более раз выше, чем любая доступная сейчас техника, но что еще важнее — возникнет компьютер, способный решать задачи, которые обычным вычислительным машинам не под силу, к примеру, распознавать образы или взламывать коды.

У квантовых компьютерных технологий есть и еще одно большое преимущество. Для обыкновенных кремниевых компьютеров перегрев и расход электричества — всегдашняя проблема. А для квантовых — нет. Они уже существуют? Прямо сейчас, задешево, практичные и удобные — пока нет. Но можно довольно уверенно говорить, что появятся.
Живые компьютеры?
Если вам кажется, что уж это-то ни в какие ворота, что скажете о компьютерах на основе ДНК (дезоксирибонуклеиновой кислоты)? Опять-таки текущая незадача — физические ограничения по скорости и миниатюризации, обусловленные неизбежными кремниевыми чипами. А если мы применим биочипы, сделанные из живой материи, и создадим субатомарные процессоры и не станем полагаться на кремнезем, произведенный из силикатного песка? Ведь по сути, кремниевые чипы производятся путем расплавления обычного песка в слитки и нарезки их на тончайшие пластинки, которые потом разнообразно обрабатываются и инженерно дополняются.
«Взгляните на компьютерную память — в начале 1970-х один мегабайт стоил дороже дома, а теперь стоит дешевле конфеты» Жиль Тома, компания «СТ Микроэлектронике», Швейцария

Хотите верьте, хотите нет, но, вероятно, следующее поколение компьютеров будет создано на базе ДНК. Наши тела работают как суперкомпьютеры — наша ДНК вечно хранит информацию о нас. Поэтому, судя по всему, есть возможность разработать компьютеры, которые хранят, добывают и обрабатывают данные в триллионы раз быстрее, чем что угодно из нам известного. ДНК — предмет громадного интереса и активного изучения, в том числе и в связи с другими страшно перспективными областями науки — нанобиологией и биомолекулярной инженерией. Все они в целом имеют дело с материалами на наноуровне (1-100 нанометров).
И как же нам применять все это в повседневной жизни? Магниторезистивная оперативная память (MRAM), например, — продукт нанотехнологий, который того и гляди произведет немало шуму: MRAM позволяет сохранять изображения почти мгновенно. В будущем телефоны или камеры могут также стать нанотехнологичными. Через несколько лет похожие наработки позволят вашему компьютеру включаться или выключаться за одну тысячную секунды, а не так бесконечно долго, как некоторым сейчас кажется.
«Компьютерная эра еще даже не началась. У нас сейчас всего лишь крошечные игрушки, не намного лучше бухгалтерских счетов. Подлинная задача — подобраться к фундаментальным законам физики как можно ближе» Ричард Стэнли Уильямз (р. 1951), американский исследователь, нанотехнолог, старший партнер Лаборатории квантовых исследований компании «Хьюлетт-Пэкард»
Разумеется, компьютеры уже существуют в наших телах — на ином уровне. Для описания взаимодействий между человеческим мозгом и центральной нервной системой прижился термин «welmare» — «влажное обеспечение». Он отчасти намекает на электрохимическую природу нашего мозга, а отчасти — на взаимодействие между нейронами (наше « hardware », или «оборудование»), а также нервные импульсы — «программное обеспечение» (« software »). А может, это мозг — программное обеспечение, а все остальное — оборудование? Мы позже убедимся, что тут все неоднозначно.
Будущие возможности
К чему же мы будем применять эти сверхбыстрые, сверхмаленькие и сверхдешевые компьютеры? Будем надеяться, не только для игры в «Злых птичек». Мы сможем мгновенно просмотреть 250 000 электронных писем и выделить два самых важных. Или мы станем смотреть кино через контактные линзы? Может, мы просто будем записывать и собирать все, что происходит на наших глазах от рождения до смерти (ну или правительства этим займутся).
Возможно, эти компьютеры будут управлять городами или даже всей планетой. А может, они научатся писать сонеты, как Шекспир, или картины, как Пикассо. Может, мы найдем им применение для шифровки щекотливой информации, предсказания погоды или поиска лекарства от рака. Ничто из вышеперечисленного не так уж далеко в будущем — если учесть скорость, с которой ведутся некоторые разработки, связанные с компьютерами и искусственным интеллектом.
Но один вопрос по-прежнему остается открытым. Если мы изобретем новые квантовые или ДНК-компьютеры и они возьмутся генерировать для нас уйму данных, как с ней будет разбираться интернет-инфраструктура или наши старомодные биологические мозги? Если мы продолжим удваивать мощность компьютеров каждые полтора года — а некоторые уверены, что для квантовых и ДНК-компьютеров это вполне реально, — то через десять лет компьютеры станут в 100 раз мощнее, чем то, что сейчас есть в нашем распоряжении. Через 25 лет — в 100 000 раз. К тому времени наши данные примутся жить своей жизнью. У нас будет больше машин и алгоритмов, чем разговоров друг с другом, а голову мы станем ломать преимущественно над тем, как втолковать машинам, что это значит — быть человеком.
Больше всего

Мыслящая пробирка
В 1994 году один американский ученый выдвинул идею использования ДНК в эксперименте со сложной математической задачей. Бред? Задумайтесь о собственном теле, которое при помощи биохимических реакций управляет вашим мозгом, придумывающим способы создания биологического компьютера. Наступает 2002 год, и израильские ученые объявляют о создании ДНК-, или биомолекулярного, компьютера на основе химических реакций в жидком растворе — вместо кремниевых чипов и электронов. В результате получилась машина, работающая в 100 000 раз быстрее любого ПК того времени. Более того, их можно делать микроскопическими — триллион таких компьютеров будет размером с каплю воды и, вероятно, сможет в ней и разместиться.
В настоящее время в поисках реальной альтернативы полупроводниковым технологиям создания новых вычислительных систем ученые обращают все большее внимание на биотехнологии, или биокомпьютинг , который представляет собой гибрид информационных, молекулярных технологий, а также биохимии. Биокомпьютинг позволяет решать сложные вычислительные задачи, используя методы, принятые в биохимии и молекулярной биологии, организуя вычисления при помощи живых тканей, клеток, вирусов и биомолекул. Наибольшее распространение получил подход, где в качестве основного элемента (процессора) используются молекулы дезоксирибонуклеиновой кислоты . Центральное место в этом подходе занимает так называемый ДНК-процессор . Кроме ДНК, в качестве биопроцессора могут использоваться также белковые молекулы и биологические мембраны .
ДНК-процессоры
Так же, как и любой другой процессор, ДНК-процессор характеризуется структурой и набором команд. В нашем случае структура процессора – это структура молекулы ДНК. А набор команд – это перечень биохимических операций с молекулами. Принцип устройства компьютерной ДНК-памяти основан на последовательном соединении четырех нуклеотидов (основных кирпичиков ДНК-цепи). Три нуклеотида, соединяясь в любой последовательности, образуют элементарную ячейку памяти – кодон, совокупность которых формирует затем цепь ДНК. Основная трудность в разработке ДНК-компьютеров связана с проведением избирательных однокодонных реакций (взаимодействий) внутри цепи ДНК. Однако прогресс есть уже и в этом направлении. Существует экспериментальное оборудование, позволяющее работать с одним из 1020 кодонов или молекул ДНК. Другой проблемой является самосборка ДНК, приводящая к потере информации. Ее преодолевают введением в клетку специальных ингибиторов – веществ, предотвращающих химическую реакцию самосшивки.
Использование молекул ДНК для организации вычислений – это не слишком новая идея. Теоретическое обоснование подобной возможности было сделано еще в 50-х годах прошлого века (Р.П. Фейманом). В деталях эта теория была проработана в 70-х годах Ч. Бенеттом и в 80-х М. Конрадом.
Первый компьютер на базе ДНК был создан еще в 1994 г. американским ученым Леонардом Адлеманом. Он смешал в пробирке молекулу ДНК, в которой были закодированы исходные данные, и специальным образом подобранные ферменты. В результате химической реакции структура ДНК изменилась таким образом, что в ней в закодированном виде был представлен ответ задачи. Поскольку вычисления проводились в ходе химической реакции с участием ферментов, на них было затрачено очень мало времени.
Вслед за работой Адлемана последовали другие. Ллойд Смит из Университета Висконсин решил с помощью ДНК задачу доставки четырех сортов пиццы по четырем адресам, которая подразумевала 16 вариантов ответа. Ученые из Принстонского университета решили комбинаторную шахматную задачу: при помощи РНК нашли правильный ход шахматного коня на доске из девяти клеток (всего их 512 вариантов).
Ричард Липтон из Принстона первым показал, как, используя ДНК, кодировать двоичные числа и решать проблему удовлетворения логического выражения. Суть ее в том, что, имея некоторое логическое выражение, включающее n логических переменных, нужно найти все комбинации значений переменных, делающих выражение истинным. Задачу можно решить только перебором 2n комбинаций. Все эти комбинации легко закодировать с помощью ДНК, а дальше действовать по методике Адлемана. Липтон предложил также способ взлома шифра DES (американский криптографический), трактуемого как своеобразное логическое выражение.
Первую модель биокомпьютера, правда, в виде механизма из пластмассы, в 1999 г. создал Ихуд Шапиро из Вейцмановского института естественных наук. Она имитировала работу "молекулярной машины" в живой клетке, собирающей белковые молекулы по информации с ДНК, используя РНК в качестве посредника между ДНК и белком.
А в 2001 г. Шапиро удалось реализовать вычислительное устройство на основе ДНК, которое может работать почти без вмешательства человека. Система имитирует машину Тьюринга — одну из фундаментальных концепций вычислительной техники. Машина Тьюринга шаг за шагом считывает данные и в зависимости от их значений принимает решения о дальнейших действиях. Теоретически она может решить любую вычислительную задачу. По своей природе молекулы ДНК работают аналогичным образом, распадаясь и рекомбинируясь в соответствии с информацией, закодированной в цепочках химических соединений.
Разработанная в Вейцмановском институте установка кодирует входные данные и программы в состоящих из двух цепей молекулах ДНК и смешивает их с двумя ферментами. Молекулы фермента выполняли роль аппаратного, а молекулы ДНК – программного обеспечения. Один фермент расщепляет молекулу ДНК с входными данными на отрезки разной длины в зависимости от содержащегося в ней кода. А другой рекомбинирует эти отрезки в соответствии с их кодом и кодом молекулы ДНК с программой. Процесс продолжается вдоль входной цепи, и, когда доходит до конца, получается выходная молекула, соответствующая конечному состоянию системы.
Этот механизм может использоваться для решения самых разных задач. Хотя на уровне отдельных молекул обработка ДНК происходит медленно, со скоростью от 500 до 1000 бит/с, что во много миллионов раз медленнее современных кремниевых процессоров, по своей природе она допускает массовый параллелизм. По оценкам Шапиро и его коллег, в одной пробирке может одновременно происходить триллион процессов, так что при потребляемой мощности в единицы нановатт может выполняться миллиард операций в секунду.
Компьютер, построенный Olympus Optical, имеет молекулярную и электронную составляющие. Первая осуществляет химические реакции между молекулами ДНК, обеспечивает поиск и выделение результата вычислений. Вторая – обрабатывает информацию и анализирует полученные результаты.
Возможностями биокомпьютеров заинтересовались и военные. Американское агентство по исследованиям в области обороны DARPA выполняет проект, получивший название Bio-Comp (Biological Computations, биологические вычисления). Его цель – создание мощных вычислительных систем на основе ДНК.
Пока до практического применения компьютеров на базе ДНК еще очень далеко. Однако в будущем их смогут использовать не только для вычислений, но и как своеобразные нанофабрики лекарств. Поместив подобное "устройство" в клетку, врачи смогут влиять на ее состояние, исцеляя человека от самых опасных недугов.
Клеточные компьютеры представляют собой самоорганизующиеся колонии различных "умных" микроорганизмов, в геном которых удалось включить некую логическую схему, которая могла бы активизироваться в присутствии определенного вещества. Для этой цели идеально подошли бы бактерии, стакан с которыми и представлял бы собой компьютер. Такие компьютеры очень дешевы в производстве. Им не нужна стерильная атмосфера, как при производстве полупроводников.
Главное свойство такого компьютера состоит в том, что каждая его клетка представляет собой миниатюрную химическую лабораторию. Если биоорганизм запрограммирован, то он просто производит нужные вещества. Достаточно вырастить одну клетку, обладающую заданными качествами, и можно легко и быстро вырастить тысячи клеток с такой же программой.
Основная проблема, с которой сталкиваются создатели клеточных биокомпьютеров, – организация всех клеток в единую работающую систему. На сегодня практические достижения в области клеточных компьютеров напоминают достижения 20-х годов в области ламповых и полупроводниковых компьютеров. Сейчас в Лаборатории искусственного интеллекта Массачусетского технологического университета создана клетка, способная хранить на генетическом уровне 1 бит информации. Также разрабатываются технологии, позволяющие единичной бактерии отыскивать своих соседей, образовывать с ними упорядоченную структуру и осуществлять массив параллельных операций.
В 2001 г. американские ученые создали трансгенные микроорганизмы (т. е. микроорганизмы с искусственно измененными генами), клетки которых могут выполнять логические операции И и ИЛИ.
Специалисты лаборатории Оук-Ридж, штат Теннесси, использовали способность генов синтезировать тот или иной белок под воздействием определенной группы химических раздражителей. Ученые изменили генетический код бактерий Pseudomonas putida таким образом, что их клетки обрели способность выполнять простые логические операции. Например, при выполнении операции И в клетку подаются два вещества (по сути – входные операнды), под влиянием которых ген вырабатывает определенный белок. Теперь ученые пытаются создать на базе этих клеток более сложные логические элементы, а также подумывают о возможности создания клетки, выполняющей параллельно несколько логических операций.
Потенциал биокомпьютеров очень велик. К достоинствам, выгодно отличающим их от компьютеров, основанных на кремниевых технологиях, относятся:
- более простая технология изготовления, не требующая для своей реализации столь жестких условий, как при производстве полупроводников;
- использование не бинарного, а тернарного кода (информация кодируется тройками нуклеотидов), что позволит за меньшее количество шагов перебрать большее число вариантов при анализе сложных систем;
- потенциально исключительно высокая производительность, которая может составлять до 10 14 операций в секунду за счет одновременного вступления в реакцию триллионов молекул ДНК;
- возможность хранить данные с плотностью, в триллионы раз превышающей показатели оптических дисков;
- исключительно низкое энергопотребление.
Однако, наряду с очевидными достоинствами, биокомпьютеры имеют и существенные недостатки, такие как:
- сложность со считыванием результатов – современные способы определения кодирующей последовательности несовершенны, сложны, трудоемки и дороги;
- низкая точность вычислений, связанная с возникновением мутаций, прилипанием молекул к стенкам сосудов и т.д.;
- невозможность длительного хранения результатов вычислений в связи с распадом ДНК в течение времени.
Хотя до практического использования биокомпьютеров еще очень далеко, и они вряд ли будут рассчитаны на широкие массы пользователей, предполагается, что они найдут достойное применение в медицине и фармакологии, а также с их помощью станет возможным объединение информационных и биотехнологий.
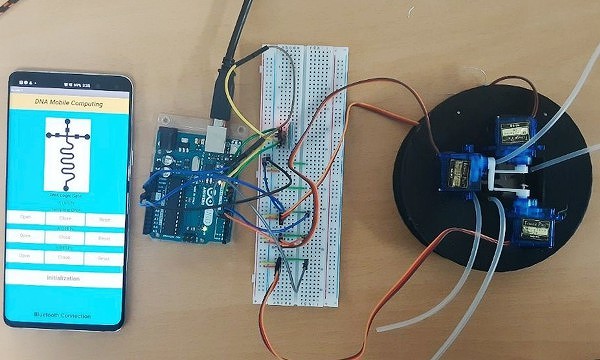
Группа ученых из Национального университета в Инчхоне (INU), Южная Корея, объявила о разработке первой в мире технологии выполнения классических вычислений на базе молекул ДНК. Свое изобретение исследователи назвали «Микрожидкостный процессор» (Microfluidic Processing Unit, MPU).
Разработка южнокорейских ученых впервые описана в статье Programmable DNA-Based Boolean Logic Microfluidic Processing Unit («Программируемый микрожидкостный процессор для работы с двоичной логикой на основе ДНК), которая была опубликована в последнем выпуске научного журнала ACS Nano, выпускаемого Американским химическим обществом (American Chemical Society). В ней подробно описан лабораторный прототип MPU, который выполнен в компактном форм-факторе, включает элементы обработки ДНК для исполнения ряда основных операций двоичной (булевой) логики, и может быть запрограммирован с обычного ПК или смартфона.
По словам ученых, уже первый прототип MPU смог выполнять ключевые операции AND, OR, XOR и NOT, работа с которыми подтвердила возможность использования молекул ДНК не только для хранения данных – как считалось ранее, но и для полноценных вычислений.
«Мы надеемся, что в будущем процессоры на основе ДНК заменят традиционные электронные чипы, поскольку они потребляют меньше энергии, и это поможет с глобальным потеплением, сказал – руководитель исследования из INU д-р Ёнджун Сонг (Dr. Youngjun Song). – Процессоры на базе ДНК также позволят создать платформы для сложных вычислений – таких как задачи глубокого машинного обучения и математического моделирования».
Как сделать свой ДНК-процессор
Ранее использование молекул ДНК для вычислительных нужд обсуждалось в научной среде преимущественно в ключе использования таких решений для хранения информации. Молекулы ДНК действительно подходят для решений, способных хранить огромные объемы данных, однако минусом такой технологии является чрезвычайно низкая скорость чтения и записи – до одной секунды на запись одной базы данных средних размеров в хранилище на основе ДНК.
Проблема в первую очередь связана с принципом хранения данных в ДНК, который требует другого подхода к обработке информации. По мнению ученых, естественным решением проблемы стал бы процессор на молекулах ДНК с аналогичным принципом форматирования данных. Именно в поисках решения этого вопроса работали южнокорейские ученые.
Как пояснили в своей статье исследователи, использование закодированных информацией цепочек дезоксирибонуклеиновой кислоты (ДНК) в качестве материала для молекулярных вычислений обеспечивает логический вычислительный процесс за счет каскадных и параллельных цепных реакций, однако реакции при вычислениях на основе комбинационной логики на основе ДНК в основном достигаются посредством ручного процесса путем добавления желаемых молекул ДНК в одну микропробирку (субстрат).
Как показало исследование, использование микрожидкостных микросхем на основе ДНК для операций булевой логики (логика «истинно/ложно», где сравниваются входящие данные и возвращается значение «истина» или «ложь» в зависимости от типа операции или используемого «логического элемента» - прим. CNews) может обеспечить автоматизированную работу, программируемое управление и бесшовную комбинационную работу логики по аналогии с электронным микропроцессором.
Для изготовления микрожидкостного молекулярного ДНК-чипа, способного выполнять булеву логику, команда ученых использовала систему 3D-печати с использованием методов двустороннего формования. Логический вентиль в лабораторном эксперименте состоял из одноцепочечной ДНК-матрицы, а в качестве входных данных использовались различные одноцепочечные ДНК.
Появится одно цифровое окно для всех социальных ведомств
Когда часть входной ДНК имела последовательность Уотсона-Крика, комплементарную матричной ДНК, она спаривалась и образовывала двухцепочечную ДНК, при этом результат считался истинным или ложным в зависимости от размера окончательной ДНК.
Управление прототипом ДНК-процессора осуществлялось необычным способом – с помощью системы клапанов с электроприводом, которая выполняет серию реакций для быстрого и удобного исполнения комбинации логических операций. Эту систему клапанов можно программировать с помощью ПК или смартфона.
Совокупность ДНК-чипа и управляющего ПО в итоге и была названа «микрожидкостным процессором» (MPU).
Дальнейшие перспективы проекта
По мнению авторов проекта, разработанная ими система клапанов для программируемого MPU на основе ДНК открывает путь к созданию более сложных систем с каскадами реакций, которые смогут кодировать расширенный список функции.
«Будущие исследования будут сосредоточены на создании вычислительных решений полностью на основе ДНК с алгоритмами ДНК и системами хранения ДНК», - говорит д-р Сонг.
Пока что для управления чипом необходима внешняя система, однако ученые полагают, что в перспективе удастся сформировать MPU булевой логики на основе ДНК, которым можно будет программировать с помощью специального языка программирования. Такие системы, по мнению разработчиков, смогут найти широкое распространение в более сложных функциональных решениях – таких как модули арифметических вычислений или нейроморфные схемы.

Возможности применения кремния для создания чипов и компьютеров не бесконечны, и в недалекой перспективе может оказаться, что весь его потенциал создателями компьютеров уже исчерпан и большей вычислительной мощи от подобных микросхем не добиться.
Осознавая это, многие гиганты отрасли обращают пристальное внимание на альтернативные технологии и материалы, которые в будущем могли бы полноценно заменить силиконовые платы и со временем превзойти их. Среди таких в настоящее время особо перспективными считаются углеродные нанотрубки и квантовые процессоры.
Помимо двух указанных технологий потенциалом обладают и биологические макромолекулы, о способностях которых хранить и передавать информацию, известно с 1950-х годов. Речь идет о нуклеиновых кислотах и, прежде всего, дезоксирибонуклеиновой кислоте, известной большинству просто как ДНК.

Это уже успевшая стать знаменитой молекула имеет форму двойной спирали. Она располагается в ядрах почти всех живых организмов и обладает колоссальными возможностями в области хранения большого количества информации: в одном миллилитре способны уместиться 10 трлн. молекул, в которых может храниться до 10 Тб данных и, теоретически, они могут производить до 10 трлн операций в секунду. Т.е. такой биологический микрокомпьютер будет настолько невелик, что один триллион подобных «машин» сможет одновременно работать в одной единственной капле воды.


Использование ДНК в сфере нанотехнологий было начато в 1980-х годах, когда Надриан Зиман (Nadrian Seeman) с коллегами в Нью-Йоркском университете взялись за разработку ДНК-машин. К тому моменту биохимиками были полученные всеобъемлющие сведения о структуре, принципе работы этой нуклеиновой кислоты, а также многих природных веществах, ферментах в частности, способных влиять на нее.

ДНК-машины могли быть созданы потому, что двойная цепочка молекулы построена по строгим принципам комплементарности, а это значит, что можно предсказывать какая часть прикрепится и куда, т.е. присутствует эффект «избирательного прилипания».

Ну а область ДНК- вычислений была открыта Леонардом Эдлманом (Leonard Adleman), сотрудником университета Южной Калифорнии (University of Southern California), в 1994 г. Ему удалось успешно продемонстрировать возможности нуклеиновой кислоты как формы вычисления. В качестве примера им было представлено решение задачи Гамильтона о нахождении пути (задачи о коммивояжере) при помощи одной пробирки с ДНК. Суть задачи заключалась в нахождении кратчайшего пути между семью пунктами. Решение ее в традиционных компьютерах требует вычисления с перебором каждого варианта, а использование ДНК дает возможность с помощью ферментов получить все возможные ответы и затем, рассортировав результаты, найти единственный верный вариант.

Ограничением в применении предложенного Эдлманом способа стала трудоемкость проводимых операций, так как все этапы осуществлялись под наблюдением специалистов, а также незначительный масштаб его исследования: найден ответ на задачу с семью пунктами посещения, при этом потребовалась лишь одна пробирка материала. Если же предположить, что их будет около двухсот, то масса нуклеиновой кислоты, требуемой для решения задачи, соcтавит не менее массы всей нашей планеты.
Создание ДНК-компьютера предварило выявление явного совпадения между способом обработки информации в нуклеиновой кислоте и работой машиной Туринга (Turing) -теоретического устройства, хранящего и обрабатывающего данные как последовательность символов, а именно так это и происходит в живых клетках. В 2002 г. исследователи из израильского института науки Вайзмана в городе Реговот (Weizmann Institute of Science in Rehovot) разработали программируемую молекулярную вычислительную машину, состоящую из ферментов и молекул ДНК вместо кремниевых микрочипов. Причем при создании своего изобретения в отличие от профессора Эдлмана они не стремились разработать нечто, что пригодно для решения лишь одной конкретной задачи, а пытались реализовать компьютер, способный быть использованным для достижения хотя бы нескольких целей. Использовались ими те же цепочки нуклеиновой кислоты и ферменты. И в начале своих исследований они обнаружили, что созданная система способна распознавать поступающие сигналы двух видов: ноль и единицу. В ней для ввода и вывода информации применялись исключительно молекулы ДНК, управление которыми осуществляли ферменты. В итоге выяснилось, что созданная система способна давать ответ почти на восемь сотен вопросов.

А в 2004 г. в журнале Нэйчур (Nature) была опубликована статься о создании простейшего ДНК-компьютера: «Автономный молекулярный компьютер для логического контроля экспресии генов» (An autonomous molecular computer for logical control of gene expression). Там описывался ДНК-компьютер, соединенный с входным/выходным модулем: при наличии экспрессии генов (реализации генетической информации в синтезируемых белках) в раковой клетке включалась система подведения химиопрепарата. Автором изобретения стала группа ученых из этого же Вайзмановского университета: Эхуд Шапиро (Ehud Shapiro), Яков Бененсон (Yaakov Benenson), Биньямин Гил (Binyamin Gil), Ури Бен-Дор (Uri Ben-Dor) и Ривка Адар (Rivka Adar).
В суммарном подсчете коллективная вычислительная мощь биологических компьютеров в израильском устройстве составляет миллиард операций в секунду при точности вычислений более 99,8%. Затраты же энергии на эти вычисления составляют менее одной миллиардной доли Ватта, что делает возможным функционирование таких нанокомпьютеров внутри человеческого тела.
ДНК-компьютеры создаются последние годы во многих научно-исследовательских центрах мира, пытающихся объединить потенциал биологии и информационных технологий.
В клетках живых организмов хранение и воспроизведение информации с нуклеиновых кислот РНК и ДНК осуществляется при помощи ряда ферментов. ДНК-молекулы под воздействием энзимов могут выполнять такие базовые операции, как разрезание, копирование, вставка и др., которые с ними в норме осуществляются в ядре клеток. На их использовании и основана работа вычислительных машин, содержащих ДНК. Те же ферменты применяются для хранения, воспроизведения данных с нуклеиновых кислот, а также для починки носителей в случае их повреждения.
.jpg)
На примере последней рассмотрим виды и принцип работы энзимов.
Починка (репарация) существует двух видов: эксцизионная и рекомбинационная.
Основная роль в разрыве молекул ДНК принадлежит энодонуклеазам (они же рестриктазы).
Все рестрикционные эндонуклеазы узнают специфические, довольно короткие последовательности ДНК и связываются с ними. Этот процесс сопровождается разрезанием молекулы ДНК либо в самом месте узнавания, либо в каком-то другом, что определяется типом фермента. Различают 3 основных класса рестриктаз: 1, 2 и 3.
Все рестриктазы узнают на двуспиральной ДНК строго определенные последовательности, но рестриктазы 1-го класса осуществляют разрывы в произвольных точках молекулы ДНК, а рестриктазы 2-го и 3-го классов узнают и расщепляют ДНК в строго определенных участках внутри мест узнавания или на фиксированном от них расстоянии.
Большинство рестриктаз класса 2 узнают последовательности, содержащие от 4 до 6 нуклеотидных пар.
Таким образом, существует набор ферментов, осуществляющих все возможные действия с молекулой ДНК: разъединение двойной цепочки на две, разрезание и сшивание в конкретных участках, последовательное считывание данных с цепи, создание новой молекулы на основе уже имеющейся. Эти принципы и лежат в основе работы простейших ДНК-компьютеров.
Очевидно, что упомянутые изобретения на данном этапе пока значительно уступают применяемым повсеместно традиционным компьютерам, однако не исключено, что в ближайшем будущем они будут усовершенствованы и станут пригодны для выполнения простейших приложений, а через несколько десятилетий вполне смогут осуществлять самые серьезные задачи. Если не так, то эти две полярные технологии в обозримом будущем в силах дополнить друг друга. А пока у ученых есть широчайшее поле для деятельности, чтобы выяснить, каковы потенциалы клетки в области хранения, передачи, воспроизведения информации, каковы пути осуществления этого и есть ли у человека возможность подчинить эти неведомые силы себе для использования в собственных нуждах.

Будем надеяться, что необходимая длительность исследований в области биологических компьютеров не заставит крупных производителей устремить взгляды только в альтернативные разработки.
Несовершенство технологии вовсе не говорит о ее нежизнеспособности. Представляется возможным использование ДНК-компьютеров в широком спектре биомедицинских и фармацевтических исследований. Вероятно использование подобных компьютеров внутри тела человека для диагностики и лечения всевозможной, в том числе раковой патологии. Открываются огромные перспективы в сфере создания генетически модифицированных продуктов и в области селекции, что весьма актуально на фоне мировых проблем с продовольствием. Генная инженерия могла бы получить превосходное средство управления вирусными телами и бактериальными клетками.
Но пока сфера ДНК-вычислений находится на раннем этапе своего развития, однако на протяжении ближайших лет эта технология получит реальное применение в различных отраслях.
Ну а теоретические расчеты позволяют предполагать, что ДНК-компьютеры в итоге способны превзойти силиконовые чипы, особенно в случае задач, требующих выполнения одновременно большого количества операций.
Related posts
Apple против Microsoft: осеннее противостояние гигантов
01«Да плевать, что покажет Microsoft! Ох и глупо устраивать презентацию за день до Apple!» — пронеслось.
Скандальный сентябрь: как не везло Apple, Samsung и Microsoft
Каким был первый месяц осени в IT-индустрии, а точнее у производителей смартфонов? Спойлер: не очень удачным.
Почему Android называют в честь десертов?
Хоть и не все Android-смартфоны об этом знают, Google регулярно обновляет свою мобильную платформу. У версий названия.
Вычисления на основе ДНК рассматриваются как одна из технологий, которая изменит технологическую отрасль в будущем. Группа исследователей из Инчхонского национального университета в Южной Корее разработала довольно простой процессор, построенный на базе молекул ДНК. Учёные уверены, что такие чипы в будущем смогут заменить традиционные кремниевые процессоры.

Использование молекул ДНК в технологической сфере рассматривалось в качестве средства хранения информации. Исследователи экспериментировали с ДНК, создавая ёмкие решения для хранения информации. Однако у таких продуктов есть проблемы со скоростью чтения и записи данных. Это связано с тем, что хранение информации в ДНК работает по своеобразному принципу и требует новых подходов к работе с данными. Таким образом, исследователи пришли к выводу, что решением проблемы может стать процессор, основанный на молекулах ДНК, который будет работать по тому же принципу, что и ДНК-накопители. Именно такое устройство представили корейские учёные.
По данным издания The Register, исследователи из Инчхонского национального университета в Южной Корее разработали новую технологию, которая использует молекулы ДНК для простых вычислений. Устройство выполнено в виде чипа, который получил название Microfluidic Processing Unit (MPU). Первый прототип MPU может выполнять базовые операции компьютерной логики, такие как AND, OR, XOR и NOT, которые являются довольно простыми, однако знаменуют огромный скачок вперёд. Раньше для выполнения каких-либо операций с ДНК исследователям приходилось вручную настраивать сложные конфигурации, которые выполнялись в реакционных пробирках. Этот подход был очень медленным и непрактичным. MPU же совершает все вычисления автоматически, используя 3D-принтер. Это снижает сложность и позволяет сделать первый шаг к созданию пригодного для реального использования процессора на основе молекул ДНК.
Исследователи управляли чипом с ПК, хотя, по их словам, делать это можно и со смартфона. Это значит, что для управления им по-прежнему требуются внешние инструменты. Учёные заявляют, что «будущие исследования будут сосредоточены на создании решений для вычисления на полной ДНК, с алгоритмами ДНК и системами хранения на базе ДНК». Исследователи утверждают, что с таким убедительным подтверждением жизнеспособности концепции, как они представили, будущее процессоров на базе ДНК может наступить совсем скоро.
Читайте также: