
Etl фреймворк что это
Обновлено: 07.07.2024
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents Loading
Copy raw contents
Copy raw contents
Модуль 4: Интеграция и трансформация данных - ETL и ELT
В 4-ом модуле нашего курса вы узнаете про интеграцию и трансформацию данных - ETL и ELT. Это ключевой элемент в аналитическом решении, с помощью которого мы наполняем данными хранилище данных и автоматизируем загрузку и трансформацию данных. Мы рассмотрим примеры популярных on-premise batch решений. Узнаете в чем отличие ETL от ELT, для чего нужны такие решения, что значит batch и on-premise, как с помощью ETL/ELT можно создавать модели данных, на примере dimensional modeling, рассмотрим рынок ETL/ELT. Потренируемся на классическом open-source ETL решении Pentaho DI и рассмотрим настольный инструмент от Tableau - Tableau Prep.
Модуль 4.1 Введение
Видео лекция - теория - Введение.
Модуль 4.2 Что такое ETL и ELT?
Мы часто слышим термин ETL, а иногда мы слышим про ELT. Это неотъемлемая часть любого аналитического решения, когда необходимо консолидировать данные из различных систем источников (Source) в едином месте, обычно, корпоративное или аналитическое хранилище данных (DW, которое является target для нас). Так же есть термин data pipeline, mapping и другие. Помимо терминов, есть еще роли - ETL разработчик и Data Engineer. В этом видео мы попробуем разобраться, что такое ETL, как термин и как инструмент.
Видео лекция - теория - Что такое ETL и ELT?.
Дополнительные материалы для изучения
-
(English) (Русский) (Русский) (Русский) (Русский) вы уже должны быть в состоянии прочесть диаграмму в статье (Русский) (Русский)
Модуль 4.3 Обзор рынка решений ETL
Инструментов для интеграции и трансформации данных (ETL/ELT) существует огромное множество. В этом уроке мы рассмотрим самые популярные решения на рынке и разделим их на типы по цене и удобству.
Видео лекция - теория - Обзор рынка ETL решений.
Дополнительные материалы для изучения
-
(Русский) (Русский) (Русский) (Русский) (Русский) (English) (English) (English) (English)
Павел Новичков, куратор 4-го модуля и ETL специалист, записал видео по установке Pentaho DI на примере Windows 10, с которым вы можете ознакомиться здесь
Модуль 4.4 2 ETL Компоненты и начало работы с ETL на примере Pentaho Data Integration
Мы уже должны понимать основные компоненты любого аналитического решения для больших и маленьких данных - это BI/DW/ETL. Понимать концептуально. В этом уроки мы поговорим про ETL решения и про требования и рекомендации, которые неплохо продумать перед началом создания data pipelines или data integration. Так же мы узнаем основные элементы open-source решения - Pentaho DI и потренируемся выполнять упражнения 2-го модуля с помощью UI ETL инструмента.
Видео лекция - теория - ETL Компоненты.
Видео лекция - практика - Начало работы с Pentaho DI
В качестве практики вам необходимо:
Модуль 4.5 34 ETL Подсистемы
Согласно Ральфу Кимбаллу (тот самый, который изобрел Dimensional Modeling), существует 34 ETL подсистемы, которые делятся на 4 основных категории:
- Data Extracting (получить данные из систем - E в ETL)
- Cleaning and Conforming Data (интеграция данных и подготовка к загрузке в DW - T в ETL)
- Delivering Data for Presentation (обработка данных в DW - L в ETL)
- Managing the ETL environment (управление и мониторинг компонентов ETL)
Само по себе понятие ETL подсистема - это некая абстракция. Не нужно копать глубоко. Как правило - это либо компонент ETL решения, например готовый компонент в Pentaho DI для создания SCD Type 2 (подсистема 9) или компонент для создания последовательности чисел, в случае необходимости генерации суррогатных ключей (подсистема 10). Это может быть функциональность ETL инструмента для обработки ошибок (подсистема 5) или возможность мониторинга выполнения ETL job (подсистема 27).
В этом уроке мы рассмотрим все 34 ETL подсистемы и при необходимости вы можете изучить их более детально.
Видео лекция - теория - ETL Подсистемы.
В качестве практики мы с вами рассмотрим упражнения из книги Pentaho Data Integration Beginner's Guide - Second Edition глава 8 и 9 - работа с базой данных. Мы планируем записать отдельное видео и инструкцию. Если вы хотите самостоятельно решить упражнение, то вы можете найти данную книгу и приступить к упражнениям. Если вы хотите более детально разобраться, то можете приступать к прочтению этой книги. Я сохранил все материалы для лабораторных работ в нашем git.
Дополнительные материалы для изучения
-
(English) отсюда я брал описание ETL подсистем (English) практика основ ETL на примере Pentaho DI (Русский) (English) (Русский) (Русский) (Русский) (English)
Модуль 4.6 Data Prep на примере Tableau Prep и Alteryx
С ETL/ELT мы более-менее разобрались. К счастью или к сожалению, на сегодняшний день существует огромное количество программ для интеграции и трансформации данных. Некоторые программы относятся к классу Data Prep. Я их называю настольными ETL инструментами для бизнес пользователей. Если BI инструмент нам позволяет с помощью drag and drop создать красивый дашборд, то data prep позволит нам подготовить данные для BI.
Дополнительные материалы для изучения
Вам необходимо построить Tableau Prep Flow или Alteryx Workflow и сохранить результат в своем git . Вы можете использовать данные Sales Superstore из модуля 1 и 2 или подключиться к БД Postgres (из 2-го и 3го модуля), в которую мы загружали данные. Альтернативно вы можете просто повторить существующие задания из Alteryx/Tableau tutorial, чтобы понять как работает инструмент.
Модуль 4.7 Fancy ETL инструменты
Моя любимая категория иснтрументов "Fancy", то есть чем-то не обычные, но очень популярные. В нашем уроке я упомяну 4 самых популярных иснтрумента, к тому open source. Я с ними плотно не работал, поэтому я лишь слегка их коснусь, чтобы вы знали об их существовании и по возможности попробовали. Ну а если вы уже про них знаете, то приходите к нам поделится опытом!
Видео лекция - теория - Fancy ETL инструменты.
Дополнительные материалы для изучения
Data Build Tool (dbt) tool
Вы можете выполнить один или несколько tutorial(s), чтобы попробовать fancy etl в деле. Это будет прекрасный пример вашего интереса к данному вопросу, который вы можете продемонстрировать на собеседовании и рассказать, как вы любите пробовать новые инструменты и изучать их особенности:
А также вы сможете взять данные из модуля 2 по Superstore на Postres и использвать инструменты выше, чтобы получить результат. Это уже серьезная заявка на звание Data Engineer.
Модуль 4.8 Требования к ETL разработчику и отличия от Data Engineer
Практически в описание к любой data вакансии мы можем встретить термин ETL. ETL роль очень важная, так как эти процессы отвечают за консолидацию данных в едином хранилище данных, а в некоторых случаях это может быть озеро данных. Концептуально вакансия ETL разработчик/инженер Data Engineer очень похоже, разница лишь в скилах и названии позиции.
Заключительный Проект по ETL
Павел Новичков подготовил для вас интересный проект на Pentaho DI.
Пожалуйста пройдите опрос по завершении Модуля 4. Так я смогу посмотреть, сколько человек закончило модуль, что было хорошо, а что можно улучшить.
По окончанию модуля 4, вы можете расшарить значок 04 | ETL в социальных сетях и рассказать о своих достижениях.

PS Если материал оказался полезным, вы можете поддержать авторов через ЮMoney или Patreon или Paypal
Многие начинающие аналитики не могут полностью разобраться, зачем нужно изучать ETL. Многим известны общие принципы работы с системой, так как они включают в себя действия: извлечение, преобразование, загрузку. Эти принципы понятны многим, кто изучает мир Big Data аналитики. А вот концепцию не всегда учащиеся, да и некоторые специалисты, схватывают сразу. Сегодня поговорим об этой системе более подробно.

Из чего состоит фреймворк ETL и с чем его «едят»
ETL — важнейший компонент бизнес-аналитики. Фреймворк ETL эксплуатируют для внедрения большого количества информационных систем. Это делается для их уникализации и анализа хранения данных.
Опытные аналитики знают, что есть много готовых ETL. Они выполняют функции загрузки данных в корпоративные хранилища. Ниже перечислены только некоторые из этих ETL:
- Informatica PowerCenter;
- Oracle Data Integrator;
- SAP Data Services;
- Talend Open Studio.
На практике эти коробочные решения не приносят эффективных результатов. Поэтому Data-аналитики стараются изобрести свой конвейер доставки и обработки информации.
Давайте посмотрим, почему так происходит. Возьмем обычный комплекс задач для аналитика:
- Сделать выборку данных из реляционных СУБД.
- Обработать полученные данные и сохранить в таблицу Apache Hive.
Чтобы выполнить эту задачу, дата-аналитики применяют ETL-фреймворк.

Как используется ETL дата-аналитиками
Для работы с описанной выше задачей используется два типа решений посредством фреймворка ETL. Первый из них — это потоковая обработка информации. Ее еще называют Stream. Для работы с потоковой обработкой информации используют инструмент Apache Ni Fi.
А вот для работы с пакетной обработкой подходит Apache Airflow. Это open-source-набор библиотек планирования и мониторинга процессов работы. Разработанный на Python, Apache Airflow помогает формировать и устанавливать цепочки задач как визуально, так и в программном виде, с помощью прописывания кода.
Как помогает ETL в работе дата-аналитика
В ERP-системах обычно творится бардак, который годами никто не может разобрать. Именно для структурирования этого бардака и была создана ETL.
Функции фреймворка заключаются в следующих действиях для разгребания ненужного мусора и поиска стоящих крупиц информации:
- найти случайные ошибки, появившиеся при вводе или переносе данных, а может быть, возникшие из-за багов;
- находить отличия в справочниках и детализациях между смежными IT-системами.
ETL автоматически приводит всю информацию к единой системе значений. Она дает надежность и обеспечивает качество данных для конечного пользователя. С помощью фреймворка можно проследить, из каких исходных данных сформировалось получившееся значение.
Следующий список дает знания начинающему аналитику о том, как работает ETL-система:
- подгружается информация из выбранных источников. Эта процедура нужна для затягивания в фреймворк информации произвольного качества. Главное на этом шаге — сверить суммы пришедших строк. Если получится, что в исходной системе строк больше, чем в Raw Data, то это значит, что где-то есть ошибки;
- она очищается от ошибок. Этот шаг дает возможность упорядочить полученные данные и исключить из них не валидную информацию;
- определяется соответствие данных и справочников. К утвержденной таблице пристраивается еще один тип столбцов, количество которых равно количеству справочников ЦС;
- происходит консолидация от транзакций до агрегатов;
- готовая информация выгружается в ЦС;
- происходит детализация.
Таким образом работает ETL-фреймворк.

Советы от опытных дата-аналитиков
Опытные аналитики рекомендуют при создании процесса загрузки оглядываться на потребности бизнеса. Если получается так, что загружаться данные будут неделю, а бизнесу требуется готовая аналитика через пять дней, то необходимо все снести и поставить на загрузку информацию заново, так как чуда не случится и, возможно, вы не впишетесь в указанные сроки.
Так как информация может загружаться волнами, рекомендуется сделать технический справочник под названием «Период загрузки», где будут изолированы процессы загрузки от разных периодов. Это нужно, чтобы не потерять историю изменения данных.
Необходимо всегда сохранять несколько версий работы. Например, начальную, рабочую и финальную. Таким образом дата-аналитик избежит путаницы в получаемых данных.
Получаемая информация всегда будет содержать какие-то ошибки. Поэтому постоянно перезагружать пакет из 100 гигабайт будет очень неэкономично. Рекомендуется делить этот пакет на небольшие части и проводить постепенную загрузку с постоянным обновлением. Опытные дата-аналитики советуют завести систему «файл-источник» и установить к нему интерфейс, который позволит снести документ, содержащий ошибки.
Зачем еще нужны ETL-фреймворки — примеры
Однако вышеописанными задачами и советами от дата-аналитиков целевые назначения ETL не заканчиваются. Этот фреймворк рассматривают как инструмент для переноса из разных источников в централизованный КХД.
Теперь давайте посмотрим один из примеров, когда используется ETL.
Принимают человека на работу. Разумеется, необходимо завести на него карточку во многих корпоративных системах. В крупных компаниях данным заданием занимаются специалисты, но работа их не скоординирована. В результате сотрудник долго не может получить собственную банковскую карту. А при увольнении сотрудников последние еще долго имеют доступ к своей рабочей электронной почте и другим благам организации. Естественно, это приводит к путанице, а в некоторых случаях конкуренты компании получают доступ к довольно долго остающейся открытой информации организации. ETL помогает быстро и эффективно решить эту проблему и закрыть дыры в структуре организации — вопрос добавления и удаления уволенных людей из БД в конкретном случае.
ETL-технологии дают возможность сделать автоматическим удаление аккаунтов человека из всех систем организации в случае увольнения без участия в этом отдела кадров. Вот как это происходит:
- В систему найма поступает информация о дате прекращения работы сотрудника в данной компании.
- Данные о начале процедуры блокировки его записи поступают контроллеру домена. Рабочая почта, все аккаунты сотрудника автоматически сохраняются и закрываются для доступа уволенного пользователя, а его электронная почта блокируется.
- Компания, которая увольняет сотрудника, может позволить себе полуавтоматический режим с отправкой заявления на блокировку в сервис технической поддержки штатного системного администратора.
Так на реальном примере работает ETL-система. Она позволяет, игнорируя человеческий фактор (ошибку или забывчивость), сделать за несколько дней или часов то, что обычные сотрудники будут делать в течение месяца.
Заключение
Теперь вы знаете, что такое ETL-система и как она работает. Если вам понравилась тема Data-аналитики и вы желаете поглубже изучить ее, реализовать мечту помогут курсы от DevEducation.
Способность data scientist-а извлекать ценность из данных тесно связана с тем, насколько развита инфраструктура хранения и обработки данных в компании. Это значит, что аналитик должен не только уметь строить модели, но и обладать достаточными навыками в области data engineering, чтобы соответствовать потребностям компании и браться за все более амбициозные проекты.
При этом, несмотря на всю важность, образование в сфере data engineering продолжает оставаться весьма ограниченным. Мне повезло, поскольку я успел поработать со многими инженерами, которые терпеливо объясняли мне каждый аспект работы с данными, но не все обладают такой возможностью. Именно поэтому я решил написать эту статью — введение в data engineering, в которой я расскажу о том, что такое ETL, разнице между SQL- и JVM-ориентированными ETL, нормализации и партиционировании данных и, наконец, рассмотрим пример запроса в Airflow.

Data Engineering
Maxime Beauchemin, один из разработчиков Airflow, так охарактеризовал data engineering: «Это область, которую можно рассматривать как смесь бизнес-аналитики и баз данных, которая привносит больше элементов программирования. Эта сфера включает в себя специализацию по работе с распределенными системами больших данных, расширенной экосистемой Hadoop и масштабируемыми вычислениями».
Среди множества навыков инженера данных можно выделить один, который является наиболее важным — способность разрабатывать, строить и поддерживать хранилища данных. Отсутствие качественной инфраструктуры хранения данных приводит к тому, что любая активность, связанная с анализом данных, либо слишком дорога, либо немасштабируема.
ETL: Extract, Transform, Load
Extract, Transform и Load — это 3 концептуально важных шага, определяющих, каким образом устроены большинство современных пайплайнов данных. На сегодняшний день это базовая модель того, как сырые данные сделать готовыми для анализа.

Extract. Это шаг, на котором датчики принимают на вход данные из различных источников (логов пользователей, копии реляционной БД, внешнего набора данных и т.д.), а затем передают их дальше для последующих преобразований.
Transform. Это «сердце» любого ETL, этап, когда мы применяем бизнес-логику и делаем фильтрацию, группировку и агрегирование, чтобы преобразовать сырые данные в готовый к анализу датасет. Эта процедура требует понимания бизнес задач и наличия базовых знаний в области.
Load. Наконец, мы загружаем обработанные данные и отправляем их в место конечного использования. Полученный набор данных может быть использован конечными пользователями, а может являться входным потоком к еще одному ETL.
Какой ETL-фреймворк выбрать?
В мире batch-обработки данных есть несколько платформ с открытым исходным кодом, с которыми можно попробовать поиграть. Некоторые из них: Azkaban — open-source воркфлоу менеджер от Linkedin, особенностью которого является облегченное управление зависимостями в Hadoop, Luigi — фреймворк от Spotify, базирующийся на Python и Airflow, который также основан на Python, от Airbnb.
У каждой платформы есть свои плюсы и минусы, многие эксперты пытаются их сравнивать (смотрите тут и тут). Выбирая тот или иной фреймворк, важно учитывать следующие характеристики:

Конфигурация. ETL-ы по своей природе довольно сложны, поэтому важно, как именно пользователь фреймворка будет их конструировать. Основан ли он на пользовательском интерфейсе или же запросы создаются на каком-либо языке программирования? Сегодня все большую популярность набирает именно второй способ, поскольку программирование пайплайнов делает их более гибкими, позволяя изменять любую деталь.
Мониторинг ошибок и оповещения. Объемные и долгие batch запросы рано или поздно падают с ошибкой, даже если в самой джобе багов нет. Как следствие, мониторинг и оповещения об ошибках выходят на первый план. Насколько хорошо фреймворк визуализирует прогресс запроса? Приходят ли оповещения вовремя?
Обратное заполнение данных (backfilling). Часто после построения готового пайплайна нам требуется вернуться назад и заново обработать исторические данных. В идеале нам бы не хотелось строить две независимые джобы: одну для обратного а исторических данных, а вторую для текущей деятельности. Насколько легко осуществлять backfilling c помощью данного фреймворка? Масштабируемо и эффективно ли полученное решение?
2 парадигмы: SQL против JVM
Как мы выяснили, у компаний есть огромный выбор того, какие инструменты использовать для ETL, и для начинающего data scientist-а не всегда понятно, какому именно фреймворку посвятить время. Это как раз про меня: в Washington Post Labs очередность джобов осуществлялась примитивно, с помощью Cron, в Twitter ETL джобы строились в Pig, а сейчас в Airbnb мы пишем пайплайны в Hive через Airflow. Поэтому перед тем, как пойти в ту или иную компанию, постарайтесь узнать, как именно организованы ETL в них. Упрощенно, можно выделить две основные парадигмы: SQL и JVM-ориентированные ETL.
JVM-ориентированные ETL обычно написаны на JVM-ориентированном языке (Java или Scala). Построение пайплайнов данных на таких языках означает задавать преобразования данных через пары «ключ-значение», однако писать пользовательские функции и тестировать джобы становится легче, поскольку не требуется использовать для этого другой язык программирования. Эта парадигма весьма популярна среди инженеров.
SQL-ориентированные ETL чаще всего пишутся на SQL, Presto или Hive. В них почти все крутится вокруг SQL и таблиц, что весьма удобно. В то же время написание пользовательских функций может быть проблематично, поскольку требует использования другого языка (к примеру, Java или Python). Такой подход популярен среди data scientist-ов.
Поработав с обеими парадигмами, я все-таки предпочитаю SQL-ориентированные ETL, поскольку, будучи начинающим data scientist-ом, намного легче выучить SQL, чем Java или Scala (если, конечно, вы еще с ними не знакомы) и сконцентрироваться на изучении новых практик, чем накладывать это поверх изучения нового языка.
Моделирование данных, нормализация и схема «звезды»
В процессе построения качественной аналитической платформы, главная цель дизайнера системы — сделать так, чтобы аналитические запросы было легко писать, а различные статистики считались эффективно. Для этого в первую очередь нужно определить модель данных.
В качестве одного из первых этапов моделирования данных необходимо понять, в какой степени таблицы должны быть нормализованы. В общем случае нормализованные таблицы отличаются более простыми схемами, более стандартизированными данными, а также исключают некоторые типы избыточности. В то же время использование таких таблиц приводит к тому, что для установления взаимоотношений между таблицами требуется больше аккуратности и усердия, запросы становятся сложнее (больше JOIN-ов), а также требуется поддерживать больше ETL джобов.
С другой стороны, гораздо легче писать запросы к денормализованным таблицам, поскольку все измерения и метрики уже соединены. Однако, учитывая больший размер таблиц, обработка данных становится медленнее (“Тут можно поспорить, ведь все зависит от того, как хранятся данные и какие запросы бывают. Можно, к примеру, хранить большие таблицы в Hbase и обращаться к отдельным колонкам, тогда запросы будут быстрыми” — прим. пер.).
Среди всех моделей данных, которые пытаются найти идеальный баланс между двумя подходами, одной из наиболее популярных (мы используем ее в Airbnb) является схема «звезды». Данная схема основана на построении нормализованных таблиц (таблиц фактов и таблиц измерений), из которых, в случае чего, могут быть получены денормализованные таблицы. В результате такой дизайн пытается найти баланс между легкостью аналитики и сложностью поддержки ETL.

Таблицы фактов и таблицы измерений
Чтобы лучше понять, как строить денормализованные таблицы из таблиц фактов и таблиц измерений, обсудим роли каждой из них:
Таблицы фактов чаще всего содержат транзакционные данные в определенные моменты времени. Каждая строка в таблице может быть чрезвычайно простой и чаще всего является одной транзакцией. У нас в Airbnb есть множество таблиц фактов, которые хранят данные по типу транзакций: бронирования, оформления заказов, отмены и т.д.
Таблицы измерений содержат медленно меняющиеся атрибуты определенных ключей из таблицы фактов, и их можно соединить с ней по этим ключам. Сами атрибуты могут быть организованы в рамках иерархической структуры. В Airbnb, к примеру, есть таблицы измерений с пользователями, заказами и рынками, которые помогают нам детально анализировать данные.
Ниже представлен простой пример того, как таблицы фактов и таблицы измерений (нормализованные) могут быть соединены, чтобы ответить на простой вопрос: сколько бронирований было сделано за последнюю неделю по каждому из рынков?
Партиционирование данных по временной метке
Сейчас, когда стоимость хранения данных очень мала, компании могут себе позволить хранить исторические данные в своих хранилищах, вместо того, чтобы выбрасывать. Обратная сторона такого тренда в том, что с накоплением количества данных аналитические запросы становятся неэффективными и медленными. Наряду с такими принципами SQL как «фильтровать данные чаще и раньше» и «использовать только те поля, которые нужны», можно выделить еще один, позволяющий увеличить эффективность запросов: партиционирование данных.
Основная идея партиционирования весьма проста — вместо того, чтобы хранить данные одним куском, разделим их на несколько независимых частей. Все части сохраняют первичный ключ из исходного куска, поэтому получить доступ к любым данным можно достаточно быстро.
В частности, использование временной метки в качестве ключа, по которому проходит партиционирование, имеет ряд преимуществ. Во-первых, в хранилищах типа S3 сырые данные часто сортированы по временной метке и хранятся в директориях, также отмеченных метками. Во-вторых, обычно batch-ETL джоб проходит примерно за один день, то есть новые партиции данных создаются каждый день для каждого джоба. Наконец, многие аналитические запросы включают в себя подсчет количества событий, произошедших за определенный временной промежуток, поэтому партиционирование по времени здесь очень кстати.
Обратное заполнение (backfilling) исторических данных
Еще одно важное преимущество использования временной метки в качестве ключа партиционирования — легкость обратного заполнения данных. Если ETL-пайплайн уже построен, то он рассчитывает метрики и измерения наперед, а не ретроспективно. Часто нам бы хотелось посмотреть на сложившиеся тренды путем расчета измерений в прошлом — этот процесс и называется backfilling.
Backfilling настолько распространен, что в Hive есть встроенная возможность динамического партиционирования, чтобы выполнять одни и те же SQL запросы по нескольким партициям сразу. Проиллюстрируем эту идею на примере: пусть требуется заполнить количество бронирований по каждому рынку для дашборда, начиная с earliest_ds и заканчивая latest_ds. Одно из возможных решений выглядит примерно так:
Такой запрос возможен, однако он слишком громоздкий, поскольку мы выполняем одну и ту же операцию, только над разными партициями. Используя динамическое партиционирование мы можем все упростить до одного запроса:
Отметим, что мы добавили ds в SELECT и GROUP BY выражения, расширили диапазон в операции WHERE и изменили синтаксис с PARTITION (ds= '>') на PARTITION (ds). Вся прелесть динамического партиционирования в том, что мы обернули GROUP BY ds вокруг необходимых операций, чтобы вставить результаты запроса во все партиции в один заход. Такой подход очень эффективен и используется во многих пайплайнах в Airbnb.
Теперь, рассмотрим все изученные концепции на примере ETL джобы в Airflow.
Направленный ациклический граф (DAG)
Казалось бы, с точки зрения идеи ETL джобы очень просты, однако на деле они часто очень запутаны и состоят из множества комбинаций Extract, Transform и Load операций. В этом случае очень полезно бывает визуализировать весь поток данных, используя граф, в котором узел отображает операцию, а стрелка — взаимосвязь между операциями. Учитывая, что каждая операция выполняется единожды, а данные идут дальше по графу, то он является направленным и ациклическим, отсюда и название.

Одна из особенностей интерфейса Airflow — это наличие механизма, который позволяет визуализировать пайплайн данных через DAG. Автор пайплайна должен задать взаимосвязи между операциями, чтобы Airflow записал спецификацию ETL джоба в отдельный файл.
При этом помимо DAG-ов, которые определяют порядок запуска операций, в Airflow есть операторы, которые задают, что необходимо выполнить в рамках пайплайна. Обычно есть 3 вида операторов, каждый из которых имитирует один из этапов ETL-процесса:
- Сенсоры: открывают поток данных по истечении определенного времени, либо когда данные из входного источника становятся доступны (по аналогии с Extract).
- Операторы: запускают определенные команды (выполни Python-файл, запрос в Hive и т.д.). По аналогии с Transform, операторы занимаются преобразованием данных.
- Трансферы: переносят данные из одного места в другое (как и на стадии Load).
Простой пример
Ниже представлен простой пример того, как объявить DAG-файл и определить структуру графа, используя операторы в Airflow, которые мы обсудили выше:
Когда граф будет построен, можно увидеть следующую картинку:

Итак, надеюсь, что в данной статье мне удалось максимально быстро и эффективно погрузить вас в интересную и многообразную сферу — Data Engineering. Мы изучили, что такое ETL, преимущества и недостатки различных ETL-платформ. Затем обсудили моделирование данных и схему «звезды», в частности, а также рассмотрели отличия таблиц фактов от таблиц измерений. Наконец, рассмотрев такие концепции как партиционирование данных и backfilling, мы перешли к примеру небольшого ETL джоба в Airflow. Теперь вы можете самостоятельно изучать работу с данными, наращивая багаж своих знаний. Еще увидимся!
Роберт отмечает недостаточное количество программ по data engineering в мире, однако мы таковую проводим, и уже не в первый раз. В октябре у нас стартует Data Engineer 3.0, регистрируйтесь и расширяйте свои профессиональные возможности!

Сложные ETL-процессы, как правило, разбиваются на цепочку более простых.
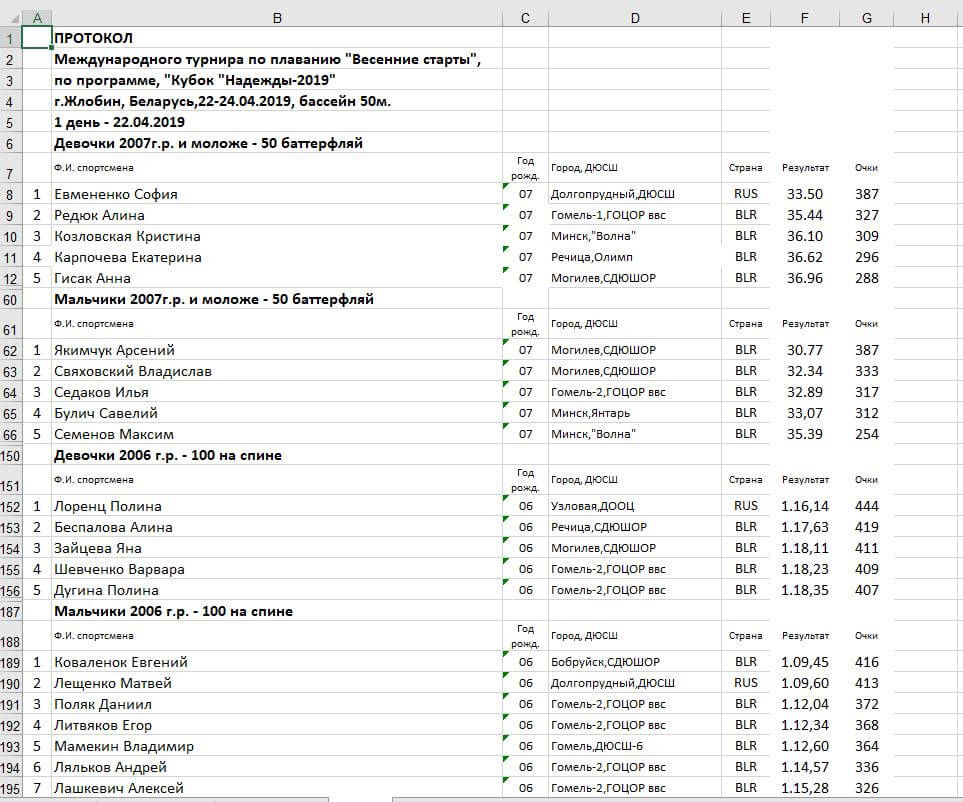
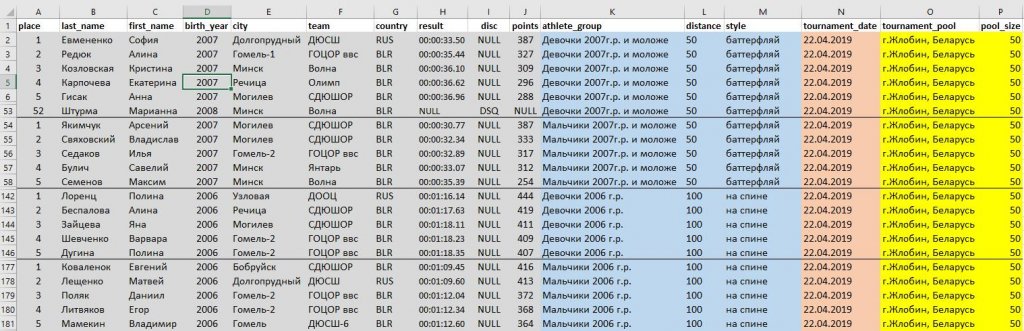
Рассмотрим частный случай импорта данных из внешнего файла. Например, из Excel или csv.
Образец файла с исходными данными (протокол проведенных соревнований по плаванию):
Модель данных в целевой БД:
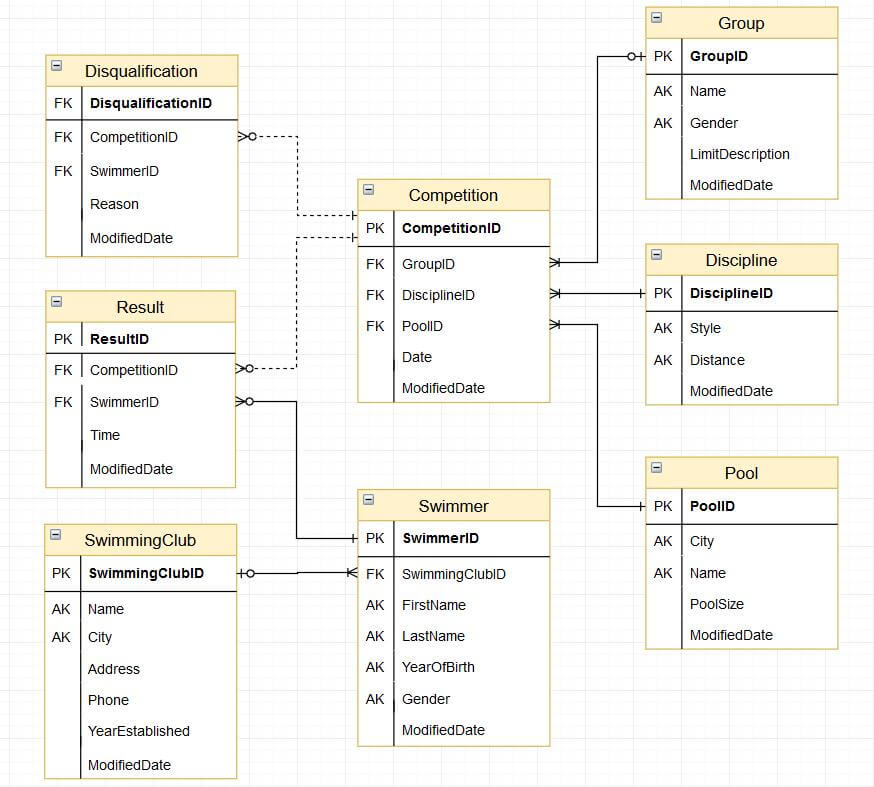
Загрузка данных в модель выше довольно сложная задача, учитывая, что исходные данные находятся в неструктурированном виде. В данной статье мы ограничимся подготовкой последних для загрузки в стейджинговую (т.е. промежуточную с точки зрения целевой модели) таблицу.
Промежуточная таблица в данном случае позволяет сконцентрироваться на процессе первоначальной подготовки данных и переносе их из внешнего неструктурированного источника (см. скриншот выше) во внутренний, очищенный и удобный с точки зрения БД для последующей работы формат.
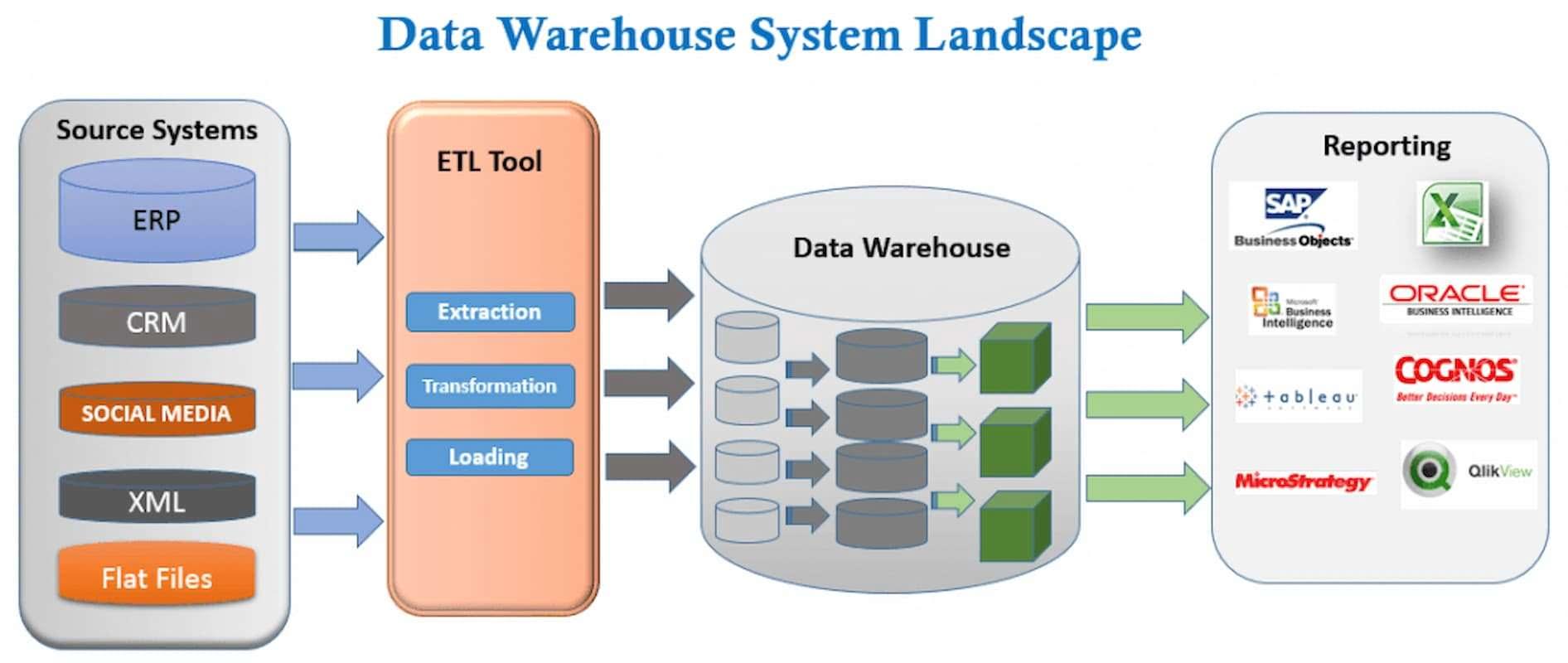
Архитектура ETL (мы концентрируемся на ETL 1):
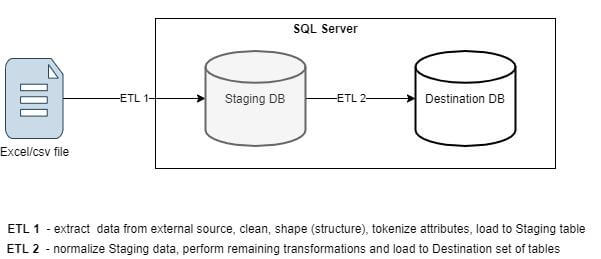
Для определения возможной схемы стейджинговой таблицы проведем первичный data profiling, определив:
- метрики исходных данных (список атрибутов, их типы, длину строковых полей, null/not null, потенциальный ключ, степень соответствия целевым атрибутам и пр);
- аномалии (грязные или отсутствующие данные, множественные значения и пр);
- возможный способ осуществления парсинга.
Требования к Staging-ETL (v1.0):

Глядя на исходные данные, приходим к выводу что в них присутствуют множественные значения. Мы не будем готовы загрузить такие данные в целевые таблицы (например, строки Фамилия+Имя, Клуб+Город, Группа+Длина дистанции+Стиль плавания).
Нужно детальное сравнение исходных данных с целевыми атрибутами и уточнение требований.
Уточненные требования:
Создадим рабочую таблицу для загрузки “сырых” исходных данных.
Фактически, мы будем создавать ELT (Extract-Load-Transform) а не ETL (Extract-Transform-Load) код. Другими словами, все трансформации и очистку данных мы будем делать ПОСЛЕ загрузки сырых данных в БД.
Будем полагать исходные данные находятся в текстовом файле формата csv.
Если, изначально данные находятся в Excel, конверсию в csv можно предварительно сделать программно или средствами самого Excel.
Грузим данные в рабочую таблицу:
Commands completed successfully.
(1470 rows affected)
(5 rows affected)

Альтернативно, ту же задачу можно было сделать с помощью мастера импорта данных или с помощью
Попробуем решить задачу одним запросом SELECT, разбив его на ряд CTE-модулей
(30 rows affected)

Внимательно проанализировав полученный результат, мы находим признак грязных данных (Будник Виктория в названии группы).

Нужна доработка кода выше под эту особенность и строго продуманный подход к тому, как мы будем парсить исходные данные. Попытка выработать этот самый строгий подход дана в размеченном скриншоте ниже.
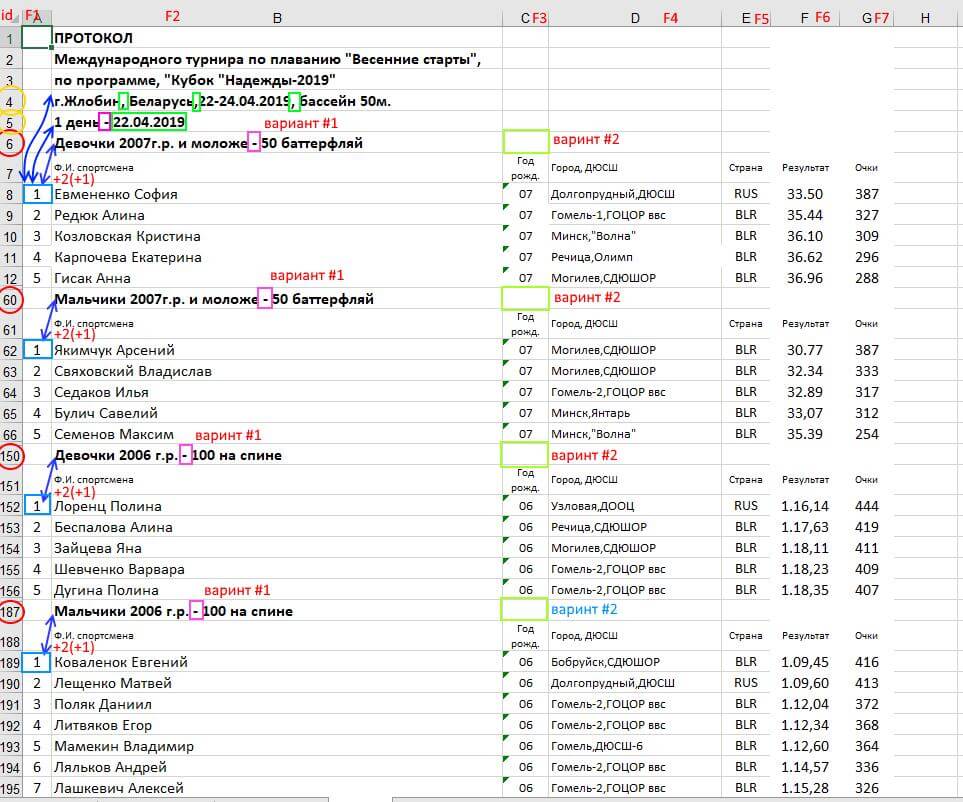
(30 rows affected)

Определение списка соревновательных дней:
(2 rows affected)

Определение места проведения соревнования:

(100 rows affected)
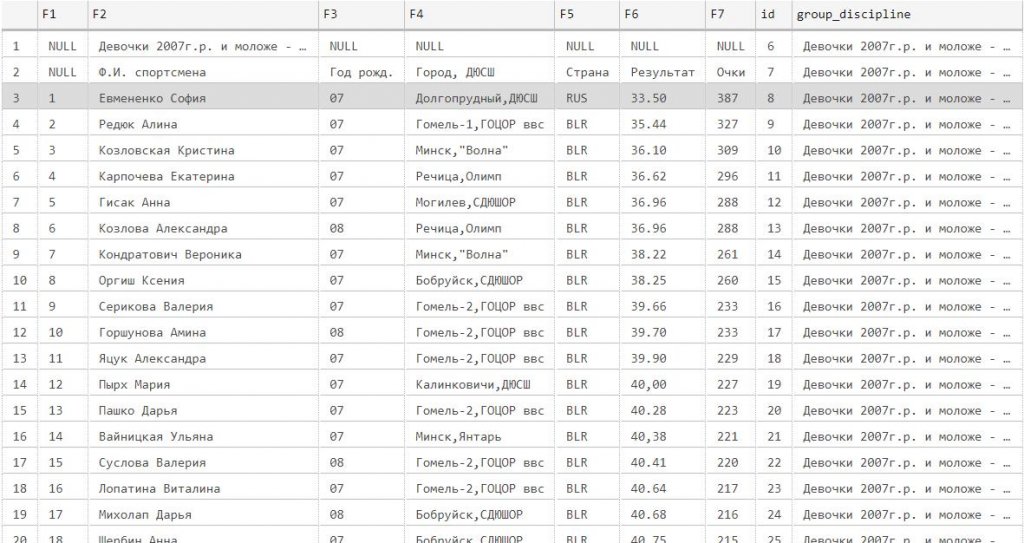
Мы приблизились к выполнению требований.
Теперь сконцентрируемся на разбиении множественных атрибутов на атомарные значения.
Попробуем разбить Фамилию Имя:

Проверим корректно ли происходит разбиение на всем множестве записей (у всех таких записей значение в колонке F1 не пусто):
(324 rows affected)
(106 rows affected)


Время на data profiling было потрачено не зря! Порой имя спортсмена содержит символы (в/к), что, вероятнее всего, означает что он участвовал в соревновании вне конкурса.

Для того чтобы загрузить лишь имя спортсмена, в поле first_name нужно взять первое слово (в случае если их несколько):
(99 rows affected)

Сделаем подобные проверки для каждого поля. Подкорректируем формулы извлечения атрибутов для всех имеющихся проблем.
Заметим, помимо прочего, что у всех атрибутов могут быть пробелы как До, так и После их значения. Для их удаления будем применять ltrim(rtrim(value)).
Высокий процент грязных данных после работы парсера говорит как о плохом качестве исходных данных, так и о плохой работе ETL-специалиста в части его подготовительной (исследовательской) работы перед написанием ETL.
Еще одна проблема – результаты заплывов (время). Строки не находятся в едином формате и, соответственно, не конвертируются в тип time(2).
Среди значений времени присутствуют строки, дробная часть может отсутствовать, а может быть отделена от целой как точкой, так и запятой.
Будем разбивать значения этого исходного поля на два новых: результат-время и результат-дисквалификация. При этом само поле результат-время разложим на компоненты hh-mm-ss-ms с намерением впоследствии применить функцию timefromparts(hh, mm, ss, ms, precision) и тем самым сконвертировать результат из типа varchar к типу time(2).
(12 rows affected)

Теперь соберем все вместе.
Окончательный вариант:
(2 rows affected)

Используя язык SQL, мы создали основу ELT-процесса парсинга полуструктурированных данных.
Заметим, что код выше не является идеальным. Это скорее R&D-решение, полученное дата-аналитиком в процессе исследования исходных данных. Вопрос оптимизации будет решен дата-инженером во время создания полноценного ETL-процесса.
* Материалы, использованные в статье (код, исходный Excel-файл, результаты работы парсера, выгруженные в csv-файл) можно получить по этой ссылке.
Автор материала – Тимофей Гавриленко, преподаватель Тренинг-центра ISsoft.

Образование: окончил с отличием математический факультет Гомельского Государственного Университета им. Франциска Скорины.
Microsoft Certified Professional (70-464, 70-465).
Работа: c 2011 года работает в компании ISsoft (ETL/BI Developer, Release Manager, Data Analyst/Architect, SQL Training Manager), на протяжении 10 лет до этого выступал как Sysadmin, DBA, Software Engineer.
В свободное время ведет бесплатные образовательные курсы для детей и взрослых, желающих повысить свой уровень компьютерной грамотности и переквалифицироваться в IT-специалиста.

Исходя из этих соображений, вот вам лучшие инструменты Python ETL на 2021 год. Некоторые из них позволяют управлять каждым этапом процесса ETL, в то время как другие превосходны только на отдельных этапах. Для того, что бы было легче сравнивать они разделены на группы.
Для анализа и машинного обучения данных много требуется. Можно было бы собрать их самостоятельно, но это крайне утомительно. Тут на помощь приходят готовые датасеты в самых разных категориях:
Системы управления рабочим процессом — Workflow management systems (WMS)
Сначала мы рассмотрим инструменты Python meta-ETL. Системы управления рабочим процессом (WMS) позволяют планировать, организовывать и отслеживать любые повторяющиеся задачи в вашем бизнесе. Таким образом, вы можете использовать WMS для настройки и запуска рабочих процессов ETL.
Apache Airflow
С помощью Airflow вы строите рабочие процессы как направленные ациклические графы (DAG). Затем для максимальной эффективности планировщик распределяет задачи между множества процессоров. Для управления и редактирования ваших DAG есть удобный веб-интерфейс, а также хороший набор инструментов, которые упрощают выполнение «операции из командной строки .
Вот простой DAG, адаптированный из учебника для начинающих, который запускает пару простых команд bash каждый день:
Luigi
Luigi поставляется с веб-интерфейсом, который позволяет пользователю визуализировать задачи и обрабатывать зависимости. Концептуально он похож на GNU Make, но предназначен не только для Hadoop (хотя и упрощает работу с Hadoop). Кроме того, создавать рабочие процессы довольно просто, поскольку все они являются просто классами Python.
Вот схема того, как выглядит типичная задача (адаптировано из документации ). Ваш конвейер ETL состоит из множества таких задач, связанных вместе.
Хотя пакет регулярно обновляется, он не так активно развивается, как Airflow, а документация устарела, так как она завалена кодом Python 2. Если вы справитесь с этим, Luigi может стать вашим инструментом ETL, если у вас есть большие, длительные задания с данными, которые просто нужно выполнить.
Обработка данных
Ядром ETL является обработка данных. Хотя с этим справляется множество инструментов Python, некоторые из них специально разработаны для этой задачи. Давайте посмотрим на возможные варианты:
pandas
Pandas , пожалуй, наиболее широко используемый набор инструментов для обработки и анализа данных во вселенной Python. Благодаря постоянному развитию и удивительно интуитивно понятному API, в pandas можно делать все, что угодно.
Вот пример, в котором мы извлекаем данные из файла CSV, применяем некоторые преобразования данных и загружаем их в базу данных PostgreSQL:
Однако есть загвоздка. Pandas разработан в первую очередь как инструмент анализа данных. Таким образом, он делает все в памяти и может работать довольно медленно, если вы работаете с большими данными. Это был бы хороший выбор для создания экспериментального конвейера ETL, но если вы хотите запустить в производство большой конвейер ETL, этот инструмент, вероятно, не для вас.
Spark
Вот пример кода, показывающий, как инициализировать сеанс Spark, читать в CSV, применять некоторые преобразования и записывать в другой CSV:
Очевидно, Spark может делать гораздо больше, чем просто читать и писать в файлы CSV, но это дает вам представление о его интуитивно понятном API. Подумайте о Spark, если вам нужна скорость и объем операций с данными.
Petl ориентирован только на ETL. Таким образом, он более эффективен, чем pandas, поскольку он не загружает базу данных в память каждый раз, когда выполняет строку кода. С другой стороны, он не включает дополнительных функций, таких как встроенный анализ данных или визуализация.
Вот пример того, как читать в нескольких файлах CSV,объедините их вместе и запишите в новый файл CSV:
Petl все еще находится в активной разработке, но существует расширенная библиотека petlx , которая предоставляет расширения для работы с массивом различных типов данных. Одно предостережение: документация немного устарели и содержит некоторые опечатки. Зато у него солидная пользовательская база и хороший функционал. Если вы хотите сосредоточиться исключительно на ETL, petl может стать для вас инструментом Python.
Мы обсудили некоторые инструменты, которые можно комбинировать для создания собственного решения Python ETL (например, Airflow и Spark). Но теперь давайте посмотрим на инструменты Python, которые могут обрабатывать каждый шаг процесса извлечения-преобразования-загрузки.
Bonobo
Если вам нравится работать с Python, вы не хотите изучать новый API и хотите создавать полусложные масштабируемые конвейеры ETL, Bonobo может быть именно тем, что вам нужно.
Bonobo имеет инструменты ETL для создания конвейеров данных, которые могут обрабатывать несколько источников данных параллельно, и имеет расширение SQLAlchemy (в настоящее время в альфа-версии), которое позволяет подключать конвейер напрямую к базам данных SQL.
Эта структура должна быть доступна для всех, кто имеет базовый уровень владения Python, и включает в себя визуализатор графа процесса ETL, который упрощает отслеживание вашего процесса. Кроме того, вы можете начать работу в течение 10 минут благодаря превосходно написанному руководству.
Вот базовый конвейер Bonobo ETL, адаптированный из учебника. Обратите внимание, что все это просто функция или генератор Python.
Вы можете связать эти функции вместе в виде графика (исключенного здесь для краткости) и запустить его в командной строке как простой файл Python, например, $ python my_etl_job.py .
Одна из проблем заключается в том, что Bonobo еще не до версии 1.0, и их Github не обновлялся с июля 2019 года. Кроме того, документация утверждает, что Bonobo находится в стадии интенсивной разработки и может быть не полностью стабильной. Таким образом, Bonobo может быть хорошей основой для быстрого создания небольших конвейеров, но может быть не лучшим долгосрочным решением, по крайней мере, до выпуска версии 1.0.
Если вы взглянули на Airflow и считаете, что он слишком сложен для того, что вам нужно, и вам не нравится идея писать всю логику ETL самостоятельно, Mara может быть для вас хорошим вариантом. Mara характеризуется, как «легковесная самодостаточная среда ETL, находящуюся на полпути между простыми скриптами и Apache Airflow».
Mara снижает сложность вашего конвейера ETL, делая некоторые предположения. Вот некоторые из них: 1) у вас должен быть PostgreSQL в качестве механизма обработки данных, 2) вы используете декларативный код Python для определения ваших конвейеров интеграции данных, 3) вы используете командную строку в качестве основного инструмента для взаимодействия с вашими базами данных, и 4) вы используете их красиво оформленный веб-интерфейс (который можно вставить в любое приложение Flask) в качестве основного инструмента для проверки, запуска и отладки ваших конвейеров.
Вот демонстрационный Mara-конвейер, который трижды проверяет локальный хост:
Обратите внимание, что документация все еще находится в стадии разработки, и что Mara изначально не работает в Windows. Однако он все еще находится в активной разработке, поэтому, если вы хотите что-то среднее между двумя крайностями, упомянутыми выше, попробуйте Mara.
Pygrametl
Pygrametl описывает себя как «среду Python, которая предлагает часто используемые функции для разработки процессов извлечения-преобразования-загрузки (ETL)». Впервые он был создан еще в 2009 году и с тех пор постоянно обновляется.
Pygrametl предоставляет объектно-ориентированные абстракции для часто используемых операций, таких как взаимодействие между различными источниками данных, запуск параллельной обработки данных или создание схем снежинок. Поскольку это фреймворк, вы можете легко интегрировать его с другим кодом Python. Действительно, в документации говорится, что он используется в производственных системах в секторах транспорта, финансов и здравоохранения.
Учебное пособие для начинающих невероятно всеобъемлющее и проведет вас через создание собственного мини-курса хранилищ данных с таблицами, содержащими стандартные размеры, SlowlyChangingDimensions и SnowflakedDimensions.
В приведенном ниже примере мы создаем FactTable для книжного магазина с подробным описанием того, какие книги были проданы и в какое время:
Одним из потенциальных недостатков является то, что эта библиотека существует уже более десяти лет, но еще не приобрела широкой популярности. Это может указывать на то, что на практике это не так удобно. Однако pygrametl работает как в CPython, так и в Jython, поэтому он может быть хорошим выбором, если у вас есть существующий код Java и/или драйверы JDBC в конвейере обработки ETL.
Маленький, но мощный
Следующие ниже инструменты Python ETL не являются полноценными решениями ETL, но предназначены для выполнения тяжелой работы на определенной части процесса. Если вы смешиваете много инструментов, подумайте о добавлении одного из следующих.
Функция принимает два аргумента odo (источник, цель) и преобразует источник в цель. Итак, чтобы преобразовать кортеж (1, 2, 3) в список, выполните:
Или для перехода между HDF5 и PostgreSQL выполните:
Odo работает под капотом, соединяя разные типы данных через путь/сеть преобразований (hodos означает «путь» по-гречески), поэтому, если один путь не работает, может быть другой способ выполнить преобразование.
Более того, odo использует собственные возможности загрузки CSV баз данных на основе SQL, которые значительно быстрее, чем при использовании чистого Python. Документация показывает, что Odo в 11 раз быстрее, чем чтение вашего CSV-файла в pandas, а затем его отправка в базу данных. Если вы обнаружите, что загружаете много данных из CSV в базы данных SQL, odo может стать для вас инструментом ETL.
Обратите внимание, что Github не обновлялся несколько лет, поэтому odo может быть не полностью стабильным. Но многие файловые системы обратно совместимы, так что это не может быть проблемой.
ETLAlchemy
Этот легкий инструмент Python ETL позволяет выполнять миграцию между любыми двумя типами СУБД всего за 4 строки кода. ETLAlchemy может перенести вас от MySQL к SQLite, от SQL Server к Postgres или любой другой разновидности комбинаций.
Вот код в действии:
Довольно просто, да?
Последний раз Github обновлялся в январе 2019 года, но сообщает, что они все еще находятся в активной разработке. Если вы хотите быстро переходить между разными вариантами SQL, этот инструмент ETL может быть для вас.
(Результаты будут отличаться от приведенных выше, поскольку фид обновляется несколько раз в день).
Riko все еще находится в стадии разработки, поэтому, если вы ищете движок потоковой обработки, это может быть вашим ответом.
Locopy
Capital One создал мощный инструмент Python ETL с Locopy, который позволяет легко (раз) загружать и копировать данные в Redshift или Snowflake. API прост, понятен и выполняет свою работу.
Например, вот как вы можете загрузить данные из Redshift в CSV:
Он все еще активно поддерживается, поэтому, если вы ищете специально инструмент, который упрощает ETL с Redshift и Snowflake, обратите внимание на locopy.
Инструменты, проверенные временем
Вот список инструментов, которые мы рекомендовали в прошлом, но сейчас они не находятся в активной разработке. Возможно, вам удастся их использовать в краткосрочной перспективе, но мы не советуем вам создавать что-либо большого размера из-за присущей им нестабильности из-за отсутствия разработки.
Bubbles
Carry
Etlpy
Более простая альтернатива
Если вы просто хотите синхронизировать, хранить и легко получать доступ к своим данным, Panoply для вас. Вместо того, чтобы тратить недели на кодирование конвейера ETL на Python, сделать это за несколько минут и щелкнуть мышью с Panoply. Это единственный инструмент конвейера данных, который легко помещает все ваши бизнес-данные в одно место, предоставляет всем сотрудникам неограниченный доступ, который им нужен, и не требует обслуживания. Кроме того, у Panoply есть встроенное хранилище, поэтому вам не нужно манипулировать несколькими поставщиками, чтобы обеспечить поток данных.
Читайте также: