
Фундаментальная проблема компьютерных систем
Обновлено: 05.07.2024
Можно допустить существование следующих альтернативных схем. Одна, фон-неймановская, предполагает, что вычислительным процессом управляет поток команд , а данные, в основном статичные, выбираются из каких-то систем хранения или из памяти. Вторая схема основывается на том, что процессом вычислений управляют входные потоки данных , которые на входе системы попадают в подготовленную вычислительную инфраструктуру, обладающую естественным параллелизмом. С точки зрения реализации первая схема гораздо проще, кроме того, она универсальна, программы компилируются и записываются в память , а вторая требует специальной сборки нужной для определенной задачи аппаратной конфигурации. Вторая схема старше; пример тому - табуляторы, изобретенные Германом Холлеритом и с успехом использовавшиеся на протяжении нескольких десятилетий. Корпорация IBM достигла своего могущества и стала одной из самых влиятельных компаний в США, производя электромеханические табуляторы для обработки больших массивов информации, не требующей выполнения логических операций. Их программирование осуществлялось посредством коммутации на пульте, а далее устройство управления в соответствии с заданной программой координировало работу остальных устройств.
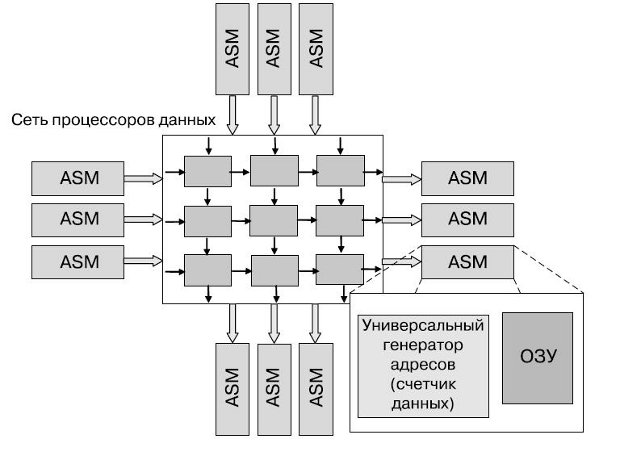
От машины фон Неймана антимашина [1] отличается наличием одного или нескольких счетчиков данных, управляющих потоками данных. Она программируется с использованием потокового обеспечения (Flowware), а роль центрального процессора в ней играют один или несколько процессоров данных ( Data Path Unit, DPU). Центральной частью антимашины может стать память с автоматической последовательностью (Auto-Sequence Memory ) ( рис. 1.1).
Асимметрия между машиной и антимашиной наблюдается во всем, за исключением того, что антимашина допускает параллелизм внутренних циклов, а это значит, что в ней решается проблема параллельной обработки данных. В антимашине доступ к памяти обеспечивается не по адресу команды или фрагмента данных, записанному в соответствующий регистр , а посредством универсального генератора адресов ( Generic Address Generator , GAG). Его преимущество в том, что он позволяет передавать блоки и потоки данных . В то же время компиляция , посредством которой создается специализированная под определенную задачу система, заключается в объединении нужного количества настроенных процессоров данных в общий массив ( Data Process Array , DPA), на котором выполняются алгоритмы Flowware и который может быть реконфигурируемым.
Методология GAG непоследовательна, а потому обладает такими достоинствами, как возможность работы с двумерными адресами, что дает неоспоримые преимущества при работе с видеоданными и при выполнении параллельных вычислений. Счетчик данных ( data counter ) - альтернатива счетчику команд в машине фон Неймана; его содержимым управляет Flowware. Для новой методологии придумано и новое название - twin . paradigm ; оно отражает симбиоз вычислительных ядер двух классов как обычных центральных процессоров, построенных по фон-неймановской схеме, так и процессоров данных, реализующих антимашины.
Главные отличия антимашины от машины фон Неймана в том, что антимашина по природе своей параллельна и к тому же нестатична - ее нужно программировать индивидуально, а не просто загружать различные программы в универсальную машину. Существуют наработки, которые хотя бы могут дать представление о том, как и из чего можно собрать антимашину. Реализовать ее можно средствами реконфигурируемого компьютинга.
Теоретически возможно существование трех подходов к созданию реконфигурируемых процессоров.
Специализированные процессоры (Application-Specific Standard Processor ). Процессоры, имеющие набор команд, адаптированный к определенным приложениям.
Конфигурируемые процессоры ( Configurable Processor ). Своего рода "заготовки" для создания специализированных процессоров, содержат в себе необходимый набор компонентов, адаптируемый к требованиям приложений. В таком случае проектирование специализированного процессора оказывается проще, чем с чистого листа.
Динамические реконфигурируемые процессоры ( Dynamically Reconfigurable Processor ). Процессоры, содержащие стандартное ядро и расширяющее его возможности устройство, которое может быть запрограммировано в процессе исполнения ; обычно это бывает программируемая логическая матрица ( Field Programmable Gate - Array , FPGA ).
В качестве еще одного пути развития вычислительных средств, сочетающего в себе и переход к параллельным системам и процессорам, и управление данными , можно назвать постепенный переход к системам на базе или с применением искусственного интеллекта. Действительно, если рассмотреть традиционное сравнение характеристик систем искусственного интеллекта с традиционными программными системами, видно, что в них подразумевается и адаптивность структуры, и высокий уровень параллелизма - таким образом, есть потенциальная возможность наиболее полно использовать возможности многоядерных архитектур ( таблица 1.1 [3]).
Также следует отметить, что интерес к системам на базе искусственного интеллекта (ИИ) возрос - это связано отчасти и с успехами в области полупроводниковой техники, позволяющими получать достаточно компактные устройства, которые имеют достаточно ресурсов для поддержания приложений ИИ. Одним из направлений ИИ, близкого по структуре к параллельным системам, являются искусственные нейронные сети , которые обладают рядом свойств, делающих их незаменимыми во многих приложениях. Применительно к задачам - это способность к обобщению, выявлению скрытых закономерностей, способность настраиваться на задачу, отсутствие необходимости выстраивать аналитические модели. Применительно к организации вычислений - нейросети позволяют наиболее полно использовать аппаратные ресурсы системы (в частности, для параллельной системы возможна наиболее полная загрузка вычислительных ядер).
В настоящее время системы, реализующие нейронные сети, представляют большой интерес для науки и техники, поскольку способны сократить время решения ряда задач, предложить путь к более простой аппаратно-программной реализации. Основные задачи, в которых применение искусственных нейронных сетей считается перспективным - это распознавание объектов, человеческой речи, эффективное сжатие данных, медицинский и биометрический анализ образов, обработка теплового изображения, интеллектуальное управление , экономическое прогнозирование, прогнозирование потребления электроэнергии, интеллектуальные антенны и ряд других.
Краткие итоги
Основные постулаты современного этапа развития вычислительной техники - повышение энергоэффективности и снижение общего энергопотребления; совершенствование подсистемы памяти с целью устранения "бутылочного горлышка" при операциях обращения к памяти; параллельное исполнение команд, возможно, на разных ядрах.
В качестве специализированных направлений выделяют системы, управляемые данными ; реконфигурируемые системы и процессы; системы на основе алгоритмов и принципов искусственного интеллекта.
Мнения специалистов, несмотря на разногласия в оценке эффективности существующего программного обеспечения, в целом за переход к процессорам со многими вычислительными ядрами.
Авторы: Резенькова Эльвира Евгеньевна, Гурова Евгения Александровна
Должность: студентка института пимиф
Учебное заведение: ФГБОУ ВО "Армавирский государственный педагогический университет"
Населённый пункт: г. Армавир Краснодарский край
Наименование материала: статья
Тема: Решение фундаментальной проблемы современного развития вычислительной техники
Раздел: высшее образование
Решение фундаментальной проблемы современного развития
вычислительной техники
Вычислительное машиностроение в начале своего развития не имело собственной
приходилось использовать радиолампы, транзисторы, диоды, активные и реактивные
сопротивления и другие приборы радиотехники, которые далеко не всегда обладали
необходим для усиления радиосигнала. Это свойство указанных приборов в ВТ не
требуется, более того, - оно снижает частотные свойства элементной базы ЭВМ.
Рассматриваемый линейный участок затягивает переходный процесс и тем самым
увеличивает время срабатывания элемента. И только в семидесятые годы прошлого
получило в практическое пользование собственную элементную базу. В микросхемах
характеристики сведен к минимуму.
разработчиков. Человечество находилось у порога ЭВМ нового поколения. Казалось,
стоило выполнить только один небольшой шаг, и такие машины появятся. Однако
первым увидел круг проблем в ВТ, которые мешают использованию преимуществ
микроэлектронной элементной базы. Его идеи рекурсивной машины, макроконвейера
отходят от классического понимания ЭВМ, заложенного первооткрывателями ВТ -
С.А. Лебедевым и создателями первых вычислительных машин на Западе, описание
которых блестяще выполнил математик фон Нейман. В.М. Глушков понимал, что в
микроэлектроники и вычислительной техники для создания новой концепции ЭВМ,
которая, с одной стороны, удовлетворяла бы пользователя и, с другой, максимально
использовала бы преимущества микроэлектронной элементной базы. Именно этому
научному подходу посвящена настоящая работа.
Проблемы современного развития вычислительной техники
научно-техническим прогрессом. Во-первых, требуется решение ряда задач, которые
по сложности не могут быть реализованы современными средствами ВТ в заданное
время, либо само их решение на созданных средствах должно носить качественно
новый характер. Во-вторых, совершенствование микроэлектронной элементной базы,
технологические возможности которой предъявляют свои требования к структурным,
архитектурным, схемным решениям и накладывают существенные ограничения на
создаваемые вычислительные машины.
На современном этапе первый фактор требует средства ВТ, которые позволили бы
решать задачи, приведенные в следующем списке:
(нелинейный анализ, решение уравнения Власова);
выдерживающих высокий уровень радиации;
расчет сложных конструкций в машиностроении при создании: летательных
аппаратов (решение задач аэродинамики), крупных энергетических установок,
средств обработки данных (расчет сложных схем в микроэлектронике), САПР
месторождений нефти, газа, полезных ископаемых (решение систем линейных
уравнений большой размерности);
изучение строения живой материи, в том числе биологии человека, создание
генома человека, разработка фармацевтических препаратов (решение уравнений
Белоусова-Жебатинского, интегрального уравнения Вольтера);
освоение космоса, изучение природных космических объектов (решение систем
линейных уравнений большой размерности);
решение задачи реального времени (задачи специального назначения);
организация обработки баз данных, экспертных оценок сложных объектов.
Обратим внимание на характерную особенность влияния задач пользователя на ВТ.
возможностей современной элементной базы привела к асимметрии в развитии ВТ.
Начался перекос в затратах на аппаратуру и программное обеспечение. В. М. Глушков
программного обеспечения, аппаратура по своей стоимости играет роль обертки. К
известный американский ученый Я. Чу обратил внимание научной общественности на
то, что стоимость математического обеспечения в 1968г. составляла 50%, от общей
стоимости системы. Он заметил что, затраты на это обеспечение неуклонно растут по
активном освоении микроэлектроники. В настоящее время стоимость математического
обеспечения уже давно превысила за 90% от общей стоимости системы. Дороговизна
программного обеспечения объясняется непомерным ростом количества данных, а
также возрастающей при этом сложностью алгоритмов их переработки. Кроме того,
следует обратить внимание еще и на то, что, если изготовление аппаратуры имеет
довольно сильную тенденцию к автоматизации на технологической линейке завода-
изготовителя, то программное обеспечение, как правило, сводится к ручному труду,
Компьютеры, даже персональные, становятся все сложнее. Не так уж давно в гудящем на столе ящике все было просто — чем больше частота, тем больше производительность. Теперь же системы стали многоядерными, многопроцессорными, в них появились специализированные ускорители, компьютеры все чаще объединяются в кластеры.
Зачем? Как во всем этом многообразии разобраться?
Что значит SIMD, SMP, GPGPU и другие страшные слова, которые встречаются все чаще?
Каковы границы применимости существующих технологий повышения производительности?
Введение
Откуда такие сложности?
Компьютерные мощности быстро растут и все время кажется, что все, существующей скорости хватит на все.
Но нет — растущая производительность позволяет решать проблемы, к которым раньше нельзя было подступиться. Даже на бытовом уровне есть задачи, которые загрузят ваш компьютер надолго, например кодирование домашнего видео. В промышленности и науке таких задач еще больше: огромные базы данных, молекулярно-динамические расчеты, моделирование сложных механизмов — автомобилей, реактивных двигателей, все это требует возрастающей мощности вычислений.
В предыдущие годы основной рост производительности обеспечивался достаточно просто, с помощью уменьшения размеров элементов микропроцессоров. При этом падало энергопотребление и росли частоты работы, компьютеры становились все быстрее, сохраняя, в общих чертах, свою архитектуру. Менялся техпроцесс производства микросхем и мегагерцы вырастали в гигагерцы, радуя пользователей возросшей производительностью, ведь если «мега» это миллион, то «гига» это уже миллиард операций в секунду.
Но, как известно, рай бывает либо не навсегда, либо не для всех, и не так давно он в компьютерном мире закончился. Оказалось, частоту дальше повышать нельзя — растут токи утечки, процессоры перегреваются и обойти это не получается. Можно, конечно, развивать системы охлаждения, применять водные радиаторы или совсем уж жидким азотом охлаждать — но это не для каждого пользователя доступно, только для суперкомпьютеров или техноманьяков. Да и при любом охлаждении возможность роста была небольшой, где-то раза в два максимум, что для пользователей, привыкших к геометрической прогрессии, было неприемлемо.
Казалось, что закон Мура, по которому число транзисторов и связанная с ним производительность компьютеров удваивалась каждые полтора-два года, перестанет действовать.
Пришло время думать и экспериментировать, вспоминая все возможные способы увеличения скорости вычислений.
Формула производительности
Возьмем самую общую формулу производительности:

Видим, что производительность можно измерять в количестве выполняемых инструкций за секунду.
Распишем процесс поподробнее, введем туда тактовую частоту:

Первая часть полученного произведения — количество инструкций, выполняемых за один такт (IPC, Instruction Per Clock), вторая — количество тактов процессора в единицу времени, тактовая частота.
Таким образом, для увеличения производительности нужно или поднимать тактовую частоту или увеличивать количество инструкций, выполняемых за один такт.
Т.к. рост частоты остановился, придется увеличивать количество исполняемых «за раз» инструкций.
Включаем параллельность
Как же увеличить количество инструкций, исполняемых за один такт?
Очевидно, выполняя несколько инструкций за один раз, параллельно. Но как это сделать?
Все сильно зависит от выполняемой программы.
Если программа написана программистом как однопоточная, где все инструкции выполняются последовательно, друг за другом, то процессору (или компилятору) придется «думать за человека» и искать части программы, которые можно выполнить одновременно, распараллелить.
Параллелизм на уровне инструкций
Возьмем простенькую программу:
a = 1
b = 2
c = a + b
Первые две инструкции вполне можно выполнять параллельно, только третья от них зависит. А значит — всю программу можно выполнить за два шага, а не за три.
Процессор, который умеет сам определять независимые и непротиворечащие друг другу инструкции и параллельно их выполнять, называется суперскалярным.
Очень многие современные процессоры, включая и последние x86 — суперскалярные процессоры, но есть и другой путь: упростить процессор и возложить поиск параллельности на компилятор. Процессор при этом выполняет команды «пачками», которые заготовил для него компилятор программы, в каждой такой «пачке» — набор инструкций, которые не зависят друг от друга и могут исполняться параллельно. Такая архитектура называется VLIW (very long instruction word — «очень длинная машинная команда»), её дальнейшее развитие получило имя EPIC (explicitly parallel instruction computing) — микропроцессорная архитектура с явным параллелизмом команд)
Самые известные процессоры с такой архитектурой — Intel Itanium.
Есть и третий вариант увеличения количества инструкций, выполняемых за один такт, это технология Hyper Threading В этой технологии суперскалярный процессор самостоятельно распараллеливает не команды одного потока, а команды нескольких (в современных процессорах — двух) параллельно запущенных потоков.
Т.е. физически процессорное ядро одно, но простаивающие при выполнении одной задачи мощности процессора могут быть использованы для выполнения другой. Операционная система видит один процессор (или одно ядро процессора) с технологией Hyper Threading как два независимых процессора. Но на самом деле, конечно, Hyper Threading работает хуже, чем реальные два независимых процессора т.к. задачи на нем будут конкурировать за вычислительные мощности между собой.
Технологии параллелизма на уровне инструкций активно развивались в 90е и первую половину 2000х годов, но в настоящее время их потенциал практически исчерпан. Можно переставлять местами команды, переименовывать регистры и использовать другие оптимизации, выделяя из последовательного кода параллельно исполняющиеся участки, но все равно зависимости и ветвления не дадут полностью автоматически распараллелить код. Параллелизм на уровне инструкций хорош тем, что не требует вмешательства человека — но этим он и плох: пока человек умнее микропроцессора, писать по-настоящему параллельный код придется ему.
Параллелизм на уровне данных
Векторные процессоры
Мы уже упоминали скалярность, но кроме скаляра есть и вектор, и кроме суперскалярных процессоров есть векторные.
Векторные процессоры выполняют какую-то операцию над целыми массивами данных, векторами. В «чистом» виде векторные процессоры применялись в суперкомьютерах для научных вычислений в 80-е годы.
По классификации Флинна, векторные процессоры относятся к SIMD — (single instruction, multiple data — одиночный поток команд, множественный поток данных).
В настоящее время в процессорах x86 реализовано множество векторных расширений — это MMX, 3DNow!, SSE, SSE2 и др.
Вот как, например, выглядит умножение четырех пар чисел одной командой с применением SSE:
float a[4] = < 300.0, 4.0, 4.0, 12.0 >;
float b[4] = < 1.5, 2.5, 3.5, 4.5 >;
__asm movups xmm0, a ; // поместить 4 переменные с плавающей точкой из a в регистр xmm0
movups xmm1, b ; // поместить 4 переменные с плавающей точкой из b в регистр xmm1
mulps xmm1, xmm0 ; // перемножить пакеты плавающих точек: xmm1=xmm1*xmm0
movups a, xmm1 ; // выгрузить результаты из регистра xmm1 по адресам a
>;
Таким образом, вместо четырех последовательных скалярных умножений мы сделали только одно — векторное.
Векторные процессоры могут значительно ускорить вычисления над большими объемами данных, но сфера их применимости ограничена, далеко не везде применимы типовые операции над фиксированными массивами.
Впрочем, гонка векторизации вычислений далеко не закончена — так в последних процессорах Intel появилось новое векторное расширение AVX (Advanced Vector Extension)
Но гораздо интереснее сейчас выглядят
Графические процессоры

Теоретическая вычислительная мощность процессоров в современных видеокартах растет гораздо быстрее, чем в обычных процессорах (посмотрим знаменитую картинку от NVIDIA)
Не так давно эта мощность была приспособлена для универсальных высокопроизводительных вычислений с помощью CUDA/OpenCL.
Архитектура графических процессоров (GPGPU, General Purpose computation on GPU – универсальные расчеты средствами видеокарты), близка к уже рассмотренной SIMD.
Она называется SIMT — (single instruction, multiple threads, одна инструкция — множество потоков). Так же как в SIMD операции производятся с массивами данных, но степеней свободы гораздо больше — для каждой ячейки обрабатываемых данных работает отдельная нить команд.
В результате
1) Параллельно могут выполняться сотни операций над сотнями ячеек данных.
2) В каждом потоке выполняется произвольная последовательность команд, она может обращаться к разным ячейкам.
3) Возможны ветвления. При этом, правда, параллельно могут выполняться только нити с одной и той же последовательностью операций.
GPGPU позволяют достичь на некоторых задачах впечатляющих результатов. но существуют и принципиальные ограничения, не позволяющие этой технологии стать универсальной палочкой-выручалочкой, а именно
1) Ускорить на GPU можно только хорошо параллелящийся по данным код.
2) GPU использует собственную память. Трансфер данных между памятью GPU и памятью компьютера довольно затратен.
3) Алгоритмы с большим количеством ветвлений работают на GPU неэффективно
Мультиархитектуры-
Итак, мы дошли до полностью параллельных архитектур — независимо параллельных и по командам, и по данным.
В классификации Флинна это MIMD (Multiple Instruction stream, Multiple Data stream — Множественный поток Команд, Множественный поток Данных).
Для использования всей мощности таких систем нужны многопоточные программы, их выполнение можно «разбросать» на несколько микропроцессоров и этим достичь увеличения производительности без роста частоты. Различные технологии многопоточности давно применялись в суперкомпьютерах, сейчас они «спустились с небес» к простым пользователям и многоядерный процессор уже скорее правило, чем исключение. Но многоядерность далеко не панацея.
Суров закон, но это закон
Параллельность, это хороший способ обойти ограничение роста тактовой частоты, но у него есть собственные ограничения.
Прежде всего, это закон Амдала, который гласит
Ускорение выполнения программы за счет распараллеливания её инструкций на множестве вычислителей ограничено временем, необходимым для выполнения её последовательных инструкций.
Ускорение кода зависит от числа процессоров и параллельности кода согласно формуле

Действительно, с помощью параллельного выполнения мы можем ускорить время выполнения только параллельного кода.
В любой же программе кроме параллельного кода есть и последовательные участки и ускорить их с помощью увеличения количества процессоров не получится, над ними будет работать только один процессор.

Например, если выполнение последовательного кода занимает всего 25% от времени выполнения всей программы, то ускорить эту программу более чем в 4 раза не получится никак.
Давайте построим график зависимости ускорения нашей программы от количества параллельно работающих вычислителей-процессоров. Подставив в формулу 1/4 последовательного кода и 3/4 параллельного, получим
Грустно? Еще как.
Самый быстрый в мире суперкомпьютер с тысячами процессоров и терабайтами памяти на нашей, вроде бы даже неплохо (75%!) параллелящейся задаче, меньше чем вдвое быстрее обычного настольного четырехядерника.
Причем всё еще хуже, чем в этом идеальном случае. В реальном мире затраты обеспечение параллельности никогда не равны нулю и потому при добавлении все новых и новых процессоров производительность, начиная с некоторого момента, начнет падать.
Но как же тогда используется мощь современных очень-очень многоядерных суперкомпьютеров?
Во многих алгоритмах время исполнения параллельного кода сильно зависит от количества обрабатываемых данных, а время исполнения последовательного кода — нет. Чем больше данных требуется обработать, тем больше выигрыш от параллельности их обработки. Потому «загоняя» на суперкомп большие объемы данных получаем хорошее ускорение.
Например перемножая матрицы 3*3 на суперкомпьютере мы вряд ли заметим разницу с обычным однопроцессорным вариантом, а вот умножение матриц, размером 1000*1000 уже будет вполне оправдано на многоядерной машине.
Есть такой простой пример: 9 женщин за 1 месяц не могут родить одного ребенка. Параллельность здесь не работает. Но вот та же 81 женщина за 9 месяцев могут родить (берем максимальную эффективность!) 81 ребенка, т.е.получим максимальную теоретическую производительность от увеличения параллельности, 9 ребенков в месяц или, в среднем, тот же один ребенок в месяц на 9 женщин.
Большим компьютерам — большие задачи!
Мультипроцессор
Мультипроцессор — это компьютерная система, которая содержит несколько процессоров и одно видимое для всех процессоров. адресное пространство.
Мультипроцессоры отличаются по организации работы с памятью.
Системы с общей памятью

В таких системах множество процессоров (и процессорных кэшей) имеет доступ к одной и той же физической оперативной памяти. Такая модель часто называется симметричной мультипроцессорностью (SMP). Доступ к памяти при таком построении системы называется UMA (uniform memory access, равномерный доступ) т.к. любой процессор может обратиться к любой ячейке памяти и скорость этого обращения не зависит от адреса памяти. Однако каждый микропроцессор может использовать свой собственный кэш.
Несколько подсистем кэш-памяти процессоров, как правило, подключены к общей памяти через шину
Посмотрим на рисунок.
Что у нас хорошего?
Любой процессор обращается ко всей памяти и вся она работает одинаково. Программировать для таких систем проще, чем для любых других мультиархитектур. Плохо то, что все процессоры обращаются к памяти через шину, и с ростом числа вычислительных ядер пропускная способность этой шины быстро становится узким местом.
Добавляет головной боли и проблема обеспечения когерентности кэшей.
Когерентность кэша
Допустим, у нас есть многопроцессорный компьютер. Каждый процессор имеет свой кэш, ну, как на рисунке вверху. Пусть некоторую ячейку памяти читали несколько процессоров — и она попала к ним в кэши. Ничего страшного, пока это ячейка неизменна — из быстрых кэшей она читается и как-то используется в вычислениях.
Если же в результате работы программы один из процессоров изменит эту ячейку памяти, чтоб не было рассогласования, чтоб все остальные процессоры «видели» это обновление придется изменять содержимое кэша всех процессоров и как-то тормозить их на время этого обновления.
Хорошо если число ядер/процессоров 2, как в настольном компьютере, а если 8 или 16? И если все они обмениваются данными через одну шину?
Потери в производительности могут быть очень значительные.
Многоядерные процессоры

Как бы снизить нагрузку на шину?
Прежде всего можно перестать её использовать для обеспечения когерентности. Что для этого проще всего сделать?
Да-да, использовать общий кэш. Так устроены большинство современных многоядерных процессоров.
Посмотрим на картинку, найдем два отличия от предыдущей.
Да, кэш теперь один на всех, соответственно, проблема когерентности не стоит. А еще круги превратились в прямоугольники, это символизирует тот факт, что все ядра и кэши находятся на одном кристалле. В реальной действительности картинка несколько сложнее, кэши бывают многоуровневыми, часть общие, часть нет, для связи между ними может использоваться специальная шина, но все настоящие многоядерные процессоры не используют внешнюю шину для обеспечения когерентности кэша, а значит — снижают нагрузку на нее.
Многоядерные процессоры — один из основных способов повышения производительности современных компьютеров.
Уже выпускаются 6 ядерные процессоры, в дальшейшем ядер будет еще больше… где пределы?
Прежде всего «ядерность» процессоров ограничивается тепловыделением, чем больше транзисторов одновременно работают в одном кристалле, тем больше этот кристалл греется, тем сложнее его охлаждать.
А второе большое ограничение — опять же пропускная способность внешней шины. Много ядер требуют много данных, чтоб их перемалывать, скорости шины перестает хватать, приходится отказываться от SMP в пользу
NUMA (Non-Uniform Memory Access — «неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — архитектура, в которой, при общем адресном пространстве, скорость доступа к памяти зависит от ее расположения Обычно у процессора есть " своя" память, обращение к которой быстрее и «чужая», доступ к которой медленнее.
В современных системах это выглядит примерно так

Процессоры соединены с памятью и друг с другом с помощью быстрой шины, в случае AMD это Hyper Transport, в случае последних процессоров Intel это QuickPath Interconnect
Т.к. нет общей для всех шины то, при работе со «своей» памятью, она перестает быть узким местом системы.
NUMA архитектура позволяет создавать достаточно производительные многопроцессорные системы, а учитывая многоядерность современных процессоров получим уже очень серьезную вычислительную мощность «в одном корпусе», ограниченную в основном сложностью обеспечения кэш-когерентности этой путаницы процессоров и памяти.
Но если нам нужна еще большая мощность, придется объединять несколько мультипроцессоров в
Мультикомпьютер
Сводим все воедино
Ну вот, вкратце пробежались почти по всем технологиям и принципам построения мощных вычислительных систем.
Теперь есть возможность представить себе строение современного суперкомпьютера.
Это мультикомпьютер-кластер, каждый узел которого — NUMA или SMP система с несколькими процессорами, каждый из процессоров с несколькими ядрами, каждое ядро с возможностью суперскалярного внутреннего параллелизма и векторными расширениями. Вдобавок ко всему этому во многих суперкомпьютерах установлены GPGPU — ускорители.
У всех этих технологий есть плюсы и ограничения, есть тонкости в применении.
А теперь попробуйте эффективно загрузить-запрограммировать всё это великолепие!
Задача нетривиальная… но очень интересная.
Что-то будет дальше?
Научиться организовывать ее работу по образу и подобию работы человеческого мозга.
Способ представления решения задачи должен быть понятен человеку и описываться знакомыми понятиями
Метод решения – максимальное использование в ИАИС естественного языка.
Задача создания средств общения на понятийном уровне ("концептуальный интерфейс"), с помощью которых машины и люди могли бы обмениваться знаниями в доступном человеку виде (в форме понятий!).
Принципы, заложенные в основу ИАИС должны соответствовать принципам организации интеллектуальной деятельности человека.
Роль когнитивных исследований – изучение и моделирование человеческих знаний и когнитивных процессов (принятия решений, обучение, восприятие, запоминание, использование естественного языка …).
Главная цель когнитологии – понять общие закономерности наших знаний.
Первоочередная научная проблема – проблема представления знаний.
Суть проблемы представления знаний – найти способ выражения общих закономерностей нашего мира.
Проблема представления знаний сводится к проблеме концептуального моделирования ПО.
Определение. Концептуальная модель – модель ПО, состоящая из перечня всех понятий, используемых для описания этой ПО, вместе с их свойствами и характеристиками, классификации этих понятий по типам, ситуациям, признакам в данной ПО.
Основа концептуального моделирования – концептуальный анализ.
Цель концептуального анализа – выявление элементов ПО, их свойств и взаимосвязей.
Процедура не формализована (!). Используемые методы:
1. Методы экспертных оценок (снижают субъективность).
2. Методы системных исследований (системный и классификационный анализ) – помогают организовать плохо структурированное знание.
Задача классификационного анализа – отражение и выражение логическими средствами отношений между классами, т.е. родовидовых отношений, существующих в естественных системах и отображенных в естественном языке.
Вывод: Ключевая научная проблема при разработке ИАИС – проблема концептуального классификационного моделирования.
4. Проблемы концептуального классификационного моделирования для систем, основанных на знаниях Основные проблемы теории классификации
Классификация необходима в любой области знаний, при любой целесообразной деятельности человека.
Классификационное движение – самостоятельное научное направление.
Национальные общества по классификации, Международная федерация классификационных обществ.
Разработка общей теории классификации.
Первая проблема теории классификации: "Что следует считать важным, существенным для построения классов, должна ли общность признаков быть формальной, или она должна быть содержательной?"
Кант критиковал формальный подход (классификация животного мира по сходству). Классификационная схема должна отражать существенные отношения, и ее целью должно быть подведение родов под законы.
Гегель: классификация должна учитывать сущность предмета.
Вторая проблема теории классификации: "Является ли классификация результатом упорядочения природного хаоса или она есть отражение системности, существующей в самих природных объектах?"
Убежденность в системной природе естественных объектов – в естественности системности.
Анализ понятия "естественный класс объектов". Его соотнесение с "естественной классификацией (ЕК)".
Тесная связь системного анализа (системного подхода) и классификационного анализа (теории классификации).
Создание системного классификационного анализа.
Актуальность и необходимость исследования ЕК. Путь построения ЕК – системный анализ естественных классов объектов с учетом содержательных, т.е. сущностных признаков.
Вывод: в основе проблем теории классификации и системного классификационного анализа лежит проблема, связанная с естественной классификацией.
Сущностный подход к классификации
Использование системного анализа при классифицировании (учет содержательных сущностных признаков).
Феноменологическая классификация – учитывает очевидно выделяющиеся броские признаки.
Характерологическая классификация – учитывает выделяющиеся броские признаки, но такие, которые являются следствием скрытых существенных свойств.
"Идеалом классификации по ее познавательной ценности является сущностная, т.е. опирающаяся как на свое основание именно на сущностные признаки классифицируемых объектов. Поэтому, при рассмотрении общих вопросов классификации, сущностной классификации необходимо уделять главное внимание, хотя сущностная классификация, естественно, как идеал, далеко не всегда достижима".
Проблема построения ЕК является задачей фундаментальной науки.
Действительно научным решением какой-либо проблемы является решение, опирающееся на знание сущности рассматриваемого объекта.
Знание не свойств, существенных на чей-либо взгляд или для каких-либо целей, а сущности этого объекта.
"Сущность объектов, как правило, скрыта от прямого наблюдения и лишь реконструируется путем установления устойчивых причин явлений по наблюдаемым следствиям этих причин".
Правильный подход к определению существенных свойств исследуемых объектов и процессов и к самому понятию сущность – ключ к решению проблемы.
Два представления по этому вопросу в научной практике.
1. Вещам реальной действительности присуща внутренняя причина устойчивости их свойств; эта причина есть сущность вещи. (единственность сущности)
2. Сущность определяется лишь по отношению к некоторой системе. Нельзя спрашивать, существен или нет некоторый признак безотносительно к какой-либо системе.
Системология – современный системный подход. Причина возникновения и развития у любого объекта или процесса, как системы, вполне определенных свойств (в том числе существенных, а также сущностных, т.е. сущности) исходит из надсистемы этой системы и представляет собой запрос надсистемы на необходимую для нее функцию системы.
1. Сущность системы (объекта) формируется вследствие наличия у надсистемы (объекта более высокого порядка) "потребности" в системе с определенной сущностью, выполняющей в надсистеме определенную функцию.
2. "Потребность" надсистемы (любой природы – технической, биологической, социальной) в поддержании ее свойств как целого называется в системологии функциональным запросом на определенные взаимодействия данной системы.
3. Функциональный запрос надсистемы становится для системы определяющим (детерминирующим) фактором (причиной), т.е. внешней детерминантой, для ее функции в этой надсистеме.
4. Внешняя детерминанта сама есть следствие функции надсистемы в наднадсистеме.
5. Причиной существования определенных внутренних (поддерживающих функциональные) свойств системы является ее внутренняя детерминанта, формирующая запросы системы на определенные поддерживающие ее функции подсистем.
6. Функциональные свойства, ради наличия и для поддержания которых сформировалась данная система, называются в системологии сущностными свойствами.
7. Все другие свойства системы могут оказаться существенными с точки зрения какого-либо аспекта ее рассмотрения или практического использования, т.е. с точки зрения любой другой надсистемы, не той в которой рассматриваемая система сформировалась.
8. Сущность системы есть, с одной стороны, следствие функционального запроса надсистемы в виде необходимых надсистеме функциональных свойств этой системы и, с другой стороны, внутренняя причина того, что у системы имеются ее сущностные (функциональные) свойства в виде определенных внутренних свойств системы, поддерживающих ее функционирование.
Определение надсистемы и функционального запроса к системе для анализа ее существенных или сущностных свойств является обязательным и необходимым этапом.
"Если мы хотим системно, сущностно, диалектически подойти к познанию интересующей нас системы, мы должны иметь хотя бы гипотезу относительно того, (1) элементом какой надсистемы является данная система, (2) какова функция надсистемы, (3) на каком этапе развития надсистемы возникла у нее такая модификация функции и, следовательно, (4) такая модификация в инвариантных свойствах надсистемы, (5) для поддержания которой потребовалась определенная перестройка надсистемы, связанная, в частности, с (6) запросом на (7) возникновение изучаемой нами системы".
Если определяются надсистема и функциональный запрос, которые представляют собой причину формирования данной системы, то определяются ее сущностные свойства (сущность).
Если определяются какие-либо другие надсистема и функциональный запрос, то определяются существенные для этой надсистемы свойства, но не сущностные.
Вывод: применение вышеназванных положений позволяет обеспечить сущностный подход к классификации, что, в свою очередь, позволяет подойти к решению проблем системного классификационного анализа и построению ЕК.
Критерии естественной классификации
Проблема выработки критериев ЕК.
Первый критерий ЕК (более 150 лет назад в середине XIX века, Уэвелл): "Чем больше общих утверждений об объектах даст возможность сделать классификация, тем она естественнее …"
В классификационной структуре (схеме) по месту объекта можно предсказать его свойства, так как они определяются связями объекта. (Шрейдер)
ЕК должна выражать закон взаимосвязи систем реальной действительности. (Бокий)
ЕК – это форма представления закона природы, форма выражения наших знаний об объективных зависимостях, существующих в мире между некоторыми объектами. (Забродин)
Сложность построения ЕК. ЕК – явление культуры.
Вывод: ЕК играет важнейшую роль в науке, а также для создания эффективных современных интеллектуальных систем и технологий.
Проблема моделирования естественной классификации
Для построения ЕК необходима методология, позволяющая:
1. Рассматривать не только конкретные объекты, но и классы объектов.
2. Определять естественные классы, необходимые для построения ЕК.
3. Определять сущностные свойства как объектов, так и их классов.
4. Указывать место классов объектов в ЕК и порядок их следования.
5. Определить критерии ЕК и построить ее модель.
5. Исходные (аксиоматические) понятия Единство универсума
Принцип единства мира. Специальный философский термин – бытие.
Вывод: ЕК должна обязательно иметь одну единственную инициальную вершину.
Иерархическая структура универсума
Принцип системности: свойства систем находятся в отношении поддержания функциональной способности целого:
1. Внутренние свойства системы поддерживают ее функционирование в надсистеме.
2. Функциональные свойства системы поддерживают функционирование надсистемы в наднадсистеме.
3. Функциональные свойства надсистемы поддерживают функционирование наднадсистемы.
Вывод: ЕК должна иметь иерархическую структуру.
Интенсиональность и параметричность классификации
С экстенсиональной точки зрения, классификация – описание структуры разбиения ПО.
С интенсиональной точки зрения, классификация связана с признаками, на основании которых разбивается ПО.
Параметричность – учет в структуре классификации свойств объектов.
Вывод: в ЕК должны быть учтены объекты и их свойства.
Следствие: свойства, попадая в классификацию, сами становятся ее элементами, свойства которых также должны быть учтены. (Свойства–свойств, Свойства–свойства–свойств …)
6. Структура естественной классификации
Эукариоты (клетки обладают ядрами). Прокариоты (клетки не обладают ядрами).
Читайте также: