
Из каких разделов состоит файл базы данных
Обновлено: 07.07.2024
ИНФОРМАТИКА- НАУКА, ИЗУЧАЮЩАЯ СПОСОБЫ АВТОМАТИЗИРОВАННОГО СОЗДАНИЯ, ХРАНЕНИЯ, ОБРАБОТКИ, ИСПОЛЬЗОВАНИЯ, ПЕРЕДАЧИ И ЗАЩИТЫ ИНФОРМАЦИИ.
ИНФОРМАЦИЯ – ЭТО НАБОР СИМВОЛОВ, ГРАФИЧЕСКИХ ОБРАЗОВ ИЛИ ЗВУКОВЫХ СИГНАЛОВ, НЕСУЩИХ ОПРЕДЕЛЕННУЮ СМЫСЛОВУЮ НАГРУЗКУ.
ЭЛЕКТРОННО-ВЫЧИСЛИТЕЛЬНАЯ МАШИНА (ЭВМ) ИЛИ КОМПЬЮТЕР (англ. computer- -вычислитель)-УСТРОЙСТВО ДЛЯ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ИНФОРМАЦИИ. Принципиальное отличие использования ЭВМ от всех других способов обработки информации заключается в способности выполнения определенных операций без непосредственного участия человека, но по заранее составленной им программе. Информация в современном мире приравнивается по своему значению для развития общества или страны к важнейшим ресурсам наряду с сырьем и энергией. Еще в 1971 году президент Академии наук США Ф.Хандлер говорил: "Наша экономика основана не на естественных ресурсах, а на умах и применении научного знания".
В развитых странах большинство работающих заняты не в сфере производства, а в той или иной степени занимаются обработкой информации. Поэтому философы называют нашу эпоху постиндустриальной. В 1983 году американский сенатор Г.Харт охарактеризовал этот процесс так: "Мы переходим от экономики, основанной на тяжелой промышленности, к экономике, которая все больше ориентируется на информацию, новейшую технику и технологию, средства связи и услуги.."
2. КРАТКАЯ ИСТОРИЯ РАЗВИТИЯ ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ.
Вся история развития человеческого общества связана с накоплением и обменом информацией (наскальная живопись, письменность, библиотеки, почта, телефон, радио, счеты и механические арифмометры и др.). Коренной перелом в области технологии обработки информации начался после второй мировой войны.
В вычислительных машинах первого поколения основными элементами были электронные лампы. Эти машины занимали громадные залы, весили сотни тонн и расходовали сотни киловатт электроэнергии. Их быстродействие и надежность были низкими, а стоимость достигала 500-700 тысяч долларов.
Появление более мощных и дешевых ЭВМ второго поколения стало возможным благодаря изобретению в 1948 году полупроводниковых устройств- транзисторов. Главный недостаток машин первого и второго поколений заключался в том, что они собирались из большого числа компонент, соединяемых между собой. Точки соединения (пайки) являются самыми ненадежными местами в электронной технике, поэтому эти ЭВМ часто выходили из строя.
В ЭВМ третьего поколения (с середины 60-х годов ХХ века) стали использоваться интегральные микросхемы (чипы)- устройства, содержащие в себе тысячи транзисторов и других элементов, но изготовляемые как единое целое, без сварных или паяных соединений этих элементов между собой. Это привело не только к резкому увеличению надежности ЭВМ, но и к снижению размеров, энергопотребления и стоимости (до 50 тысяч долларов).
История ЭВМ четвертого поколения началась в 1970 году, когда ранее никому не известная американская фирма INTEL создала большую интегральную схему (БИС), содержащую в себе практически всю основную электронику компьютера. Цена одной такой схемы (микропроцессора) составляла всего несколько десятков долларов, что в итоге и привело к снижению цен на ЭВМ до уровня доступных широкому кругу пользователей.
СОВРЕМЕННЫЕ КОМПЬТЕРЫ- ЭТО ЭВМ ЧЕТВЕРТОГО ПОКОЛЕНИЯ, В КОТОРЫХ ИСПОЛЬЗУЮТСЯ БОЛЬШИЕ ИНТЕГРАЛЬНЫЕ СХЕМЫ.
90-ые годы ХХ-го века ознаменовались бурным развитием компьютерных сетей, охватывающих весь мир. Именно к началу 90-ых количество подключенных к ним компьютеров достигло такого большого значения, что объем ресурсов доступных пользователям сетей привел к переходу ЭВМ в новое качество. Компьютеры стали инструментом для принципиально нового способа общения людей через сети, обеспечивающего практически неограниченный доступ к информации, находящейся на огромном множестве компьюторов во всем мире - "глобальной информационной среде обитания".
6.ПРЕДСТАВЛЕНИЕ ИНФОРМАЦИИ В КОМПЬЮТЕРЕ И ЕЕ ОБЪЕМ.
ЭТО СВЯЗАНО С ТЕМ, ЧТО ИНФОРМАЦИЮ, ПРЕДСТАВЛЕННУЮ В ТАКОМ ВИДЕ, ЛЕГКО ТЕХНИЧЕСКИ СМОДЕЛИРОВАТЬ, НАПРИМЕР, В ВИДЕ ЭЛЕКТРИЧЕСКИХ СИГНАЛОВ. Если в какой-то момент времени по проводнику идет ток, то по нему передается единица, если тока нет- ноль. Аналогично, если направление магнитного поля на каком-то участке поверхности магнитного диска одно- на этом участке записан ноль, другое- единица. Если определенный участок поверхности оптического диска отражает лазерный луч- на нем записан ноль, не отражает- единица.
ОБЪЕМ ИНФОРМАЦИИ, НЕОБХОДИМЫЙ ДЛЯ ЗАПОМИНАНИЯ ОДНОГО ИЗ ДВУХ СИМВОЛОВ-0 ИЛИ 1, НАЗЫВАЕТСЯ 1 БИТ (англ. binary digit- двоичная единица). 1 бит- минимально возможный объем информации. Он соответствует промежутку времени, в течение которого по проводнику передается или не передается электрический сигнал, участку поверхности магнитного диска, частицы которого намагничены в том или другом направлении, участку поверхности оптического диска, который отражает или не отражает лазерный луч, одному триггеру, находящемуся в одном из двух возможных состояний.
Итак, если у нас есть один бит, то с его помощью мы можем закодировать один из двух символов- либо 0, либо 1.
Если же есть 2 бита, то из них можно составить один из четырех вариантов кодов: 00 , 01 , 10 , 11 .
Если есть 3 бита- один из восьми: 000 , 001 , 010 , 100 , 110 , 101 , 011 , 111 .
1 бит- 2 варианта,
2 бита- 4 варианта,
3 бита- 8 вариантов;
Продолжая дальше, получим:
4 бита- 16 вариантов,
5 бит- 32 варианта,
6 бит- 64 варианта,
7 бит- 128 вариантов,
8 бит- 256 вариантов,
9 бит- 512 вариантов,
10 бит- 1024 варианта,
N бит - 2 в степени N вариантов.
В обычной жизни нам достаточно 150-160 стандартных символов (больших и маленьких русских и латинских букв, цифр, знаков препинания, арифметических действий и т.п.). Если каждому из них будет соответствовать свой код из нулей и единиц, то 7 бит для этого будет недостаточно (7 бит позволят закодировать только 128 различных символов), поэтому используют 8 бит.
ДЛЯ КОДИРОВАНИЯ ОДНОГО ПРИВЫЧНОГО ЧЕЛОВЕКУ СИМВОЛА В КОМПЬЮТЕРЕ ИСПОЛЬЗУЕТСЯ 8 БИТ, ЧТО ПОЗВОЛЯЕТ ЗАКОДИРОВАТЬ 256 РАЗЛИЧНЫХ СИМВОЛОВ.
СТАНДАРТНЫЙ НАБОР ИЗ 256 СИМВОЛОВ НАЗЫВАЕТСЯ ASCII ( произносится "аски", означает "Американский Стандартный Код для Обмена Информацией"- англ. American Standart Code for Information Interchange).
ОН ВКЛЮЧАЕТ В СЕБЯ БОЛЬШИЕ И МАЛЕНЬКИЕ РУССКИЕ И ЛАТИНСКИЕ БУКВЫ, ЦИФРЫ, ЗНАКИ ПРЕПИНАНИЯ И АРИФМЕТИЧЕСКИХ ДЕЙСТВИЙ И Т.П.
A - 01000001, B - 01000010, C - 01000011, D - 01000100, и т.д.
Таким образом, если человек создает текстовый файл и записывает его на диск, то на самом деле каждый введенный человеком символ хранится в памяти компьютера в виде набора из восьми нулей и единиц. При выводе этого текста на экран или на бумагу специальные схемы - знакогенераторы видеоадаптера (устройства, управляющего работой дисплея) или принтера образуют в соответствии с этими кодами изображения соответствующих символов.
Набор ASCII был разработан в США Американским Национальным Институтом Стандартов (ANSI), но может быть использован и в других странах, поскольку вторая половина из 256 стандартных символов, т.е. 128 символов, могут быть с помощью специальных программ заменены на другие, в частности на символы национального алфавита, в нашем случае - буквы кириллицы. Поэтому, например, передавать по электронной почте за границу тексты, содержащие русские буквы, бессмысленно. В англоязычных странах на экране дисплея вместо русской буквы Ь будет высвечиваться символ английского фунта стерлинга, вместо буквы р - греческая буква альфа, вместо буквы л - одна вторая и т.д.
ОБЪЕМ ИНФОРМАЦИИ, НЕОБХОДИМЫЙ ДЛЯ ЗАПОМИНАНИЯ ОДНОГО СИМВОЛА ASCII НАЗЫВАЕТСЯ 1 БАЙТ.
Очевидно что, поскольку под один стандартный ASCII-символ отводится 8 бит,
Остальные единицы объема информации являются производными от байта:
1 КИЛОБАЙТ = 1024 БАЙТА И СООТВЕТСТВУЕТ ПРИМЕРНО ПОЛОВИНЕ СТРАНИЦЫ ТЕКСТА,
1 МЕГАБАЙТ = 1024 КИЛОБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 500 СТРАНИЦАМ ТЕКСТА,
1 ГИГАБАЙТ = 1024 МЕГАБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 2 КОМПЛЕКТАМ ЭНЦИКЛОПЕДИИ,
1 ТЕРАБАЙТ = 1024 ГИГАБАЙТАМ И СООТВЕТСТВУЕТ ПРИМЕРНО 2000 КОМПЛЕКТАМ ЭНЦИКЛОПЕДИИ.
Обратите внимание, что в информатике смысл приставок кило- , мега- и других в общепринятом смысле выполняется не точно, а приближенно, поскольку соответствует увеличению не в 1000, а в 1024 раза.
СКОРОСТЬ ПЕРЕДАЧИ ИНФОРМАЦИИ ПО ЛИНИЯМ СВЯЗИ ИЗМЕРЯЕТСЯ В БОДАХ.
1 БОД = 1 БИТ/СЕК.
В частности, если говорят, что пропускная способность какого-то устройства составляет 28 Килобод, то это значит, что с его помощью можно передать по линии связи около 28 тысяч нулей и единиц за одну секунду.
7. СЖАТИЕ ИНФОРМАЦИИ НА ДИСКЕ
ИНФОРМАЦИЮ НА ДИСКЕ МОЖНО ОБРАБОТАТЬ С ПОМОЩЬЮ СПЕЦИАЛЬНЫХ ПРОГРАММ ТАКИМ ОБРАЗОМ, ЧТОБЫ ОНА ЗАНИМАЛА МЕНЬШИЙ ОБЪЕМ.
Существуют различные методы сжатия информации. Некоторые из них ориентированы на сжатие текстовых файлов, другие - графических, и т.д. Однако во всех них используется общая идея, заключающаяся в замене повторяющихся последовательностей бит более короткими кодами. Например, в романе Л.Н.Толстого "Война и мир" несколько миллионов слов, но большинство из них повторяется не один раз, а некоторые- до нескольких тысяч раз. Если все слова пронумеровать, текст можно хранить в виде последовательности чисел - по одному на слово, причем если повторяются слова, то повторяются и числа. Поэтому, такой текст (особенно очень большой, поскольку в нем чаще будут повторяться одни и те же слова) будет занимать меньше места.
Сжатие информации используют, если объем носителя информации недостаточен для хранения требуемого объема информации или информацию надо послать по электронной почте
Программы, используемые при сжатии отдельных файлов называются архиваторами. Эти программы часто позволяют достичь степени сжатия информации в несколько раз.
В данном посте база SQLite будет рассмотрена в разрезе, вы можете найти информацию о строении файла базы данных, о представлении данных в памяти, а также информацию о структуре и файловом представлении В – дерева.
Формат файла базы данных
Вся база данных хранится в одном файле на диске под названием «main database file». Во время транзакций, SQLite хранит дополнительную информацию во втором файле: журнал отката (rollback journal), либо, если база работает в режиме WAL, лог-файл с информацией о записях. Если приложение или компьютер отключился до окончания транзакции, то данные файлы называются «hot journal» или «hot WAL file» и содержат необходимую информацию для восстановления базы в согласованное состояние.
Основной файл базы состоит из одной или нескольких страниц. Все страницы в одной базе имеют одинаковый размер, который может быть от 512 до 65536 байт. Размер страницы для файла базы определяется целым 2-ух байтовым числом со смещением 16 байт от начала файла базы данных.
Все страницы пронумерованы от 1 до 2147483646 (2^31 – 2). Минимальный размер базы: одна страница размеров 512 байт, максимальный размер базы: 2147483646 страниц по 65536 байт (
Заголовок
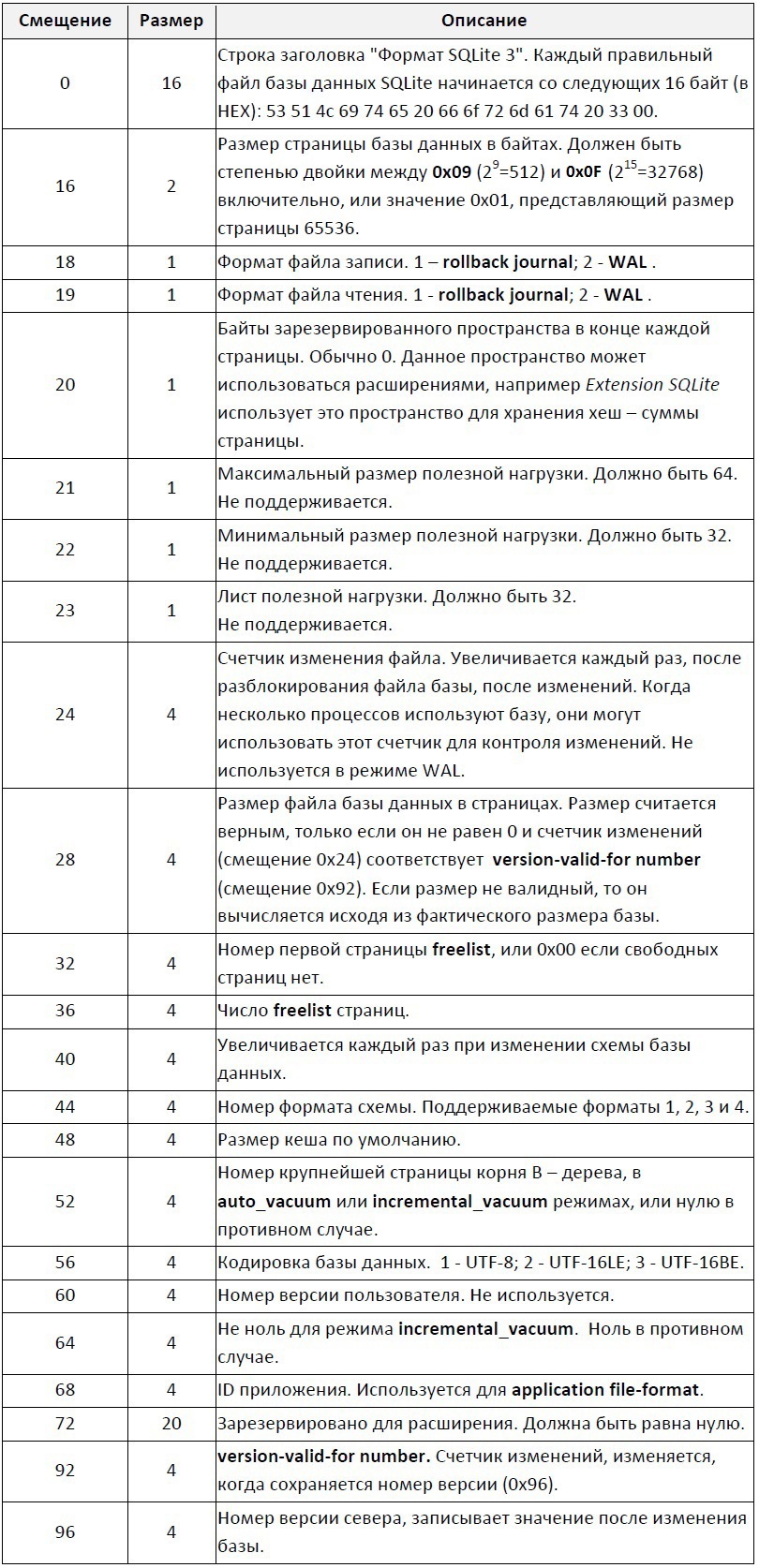
Первый 100 байт файла базы данных содержат заголовок базы, в таблице 1 представлена схема заголовка.
Lock-byte страница
Freelist
Список пустых страниц организован как связный список. Каждый элемент списка состоит из двух чисел по 4 байта. Первое число определяет номер следующего элемента freelist (trunk pointer), либо равняется нулю, если список кончился. Второе число, это указатель на страницу данных (Leaf page numbers). На рисунке ниже показана схема данной структуры.

B — tree
SQLite использует две вида деревьев: «table B – tree» (на листьях хранятся данные) и «index B – tree» (на листьях хранятся ключи).
Каждая запись в «table B – tree» состоит из 64-битового целое ключа и до 2147483647 байт произвольных данных. Ключ «table B – tree» соответствует ROWID таблицы SQL.
Каждая запись в «index B – tree» состоит из произвольного ключа до 2147483647 байт в длину.
- Заголовок файла базы данных (100 байт)
- Заголовок страницы B-дерева (8 или 12 байт)
- Массив указателей ячеек
- Незанятое пространство
- Содержимое ячейки
- Зарезервированное место
Заголовок файла базы данных встречается только на первой странице, которая всегда является старицей «table B – tree». Все остальные страницы B-дерева в базе не имеют этого заголовка.
Заголовок страницы B-дерева имеет размер 8 байт для страниц листьев и 12 байт для внутренних страниц. В таблице 2 представлена структура заголовка страницы.

Freeblock — это структура, используемая для определения незанятого пространства внутри страницы B-дерева. Freeblock организованы в виде цепочки. Первые 2 байта в freeblock (от старшего к младшему), это смещением до следующего freeblock, или ноль, если freeblock является последним в цепочке. Третий и четвертый байты – целое число, размер freeblock в байтах, включая заголовок в 4 байта. Freeblocks всегда связаны в порядке возрастания смещения.
Число фрагментированных байт – это общее число неиспользуемых байт в области содержимого ячейки.
Массив указателей ячеек состоит из K 2-байтовых целочисленных смещений содержимого ячеек (при K ячейках в B-дереве). Массив отсортирован по возрастанию (от наименьших ключей к наибольшим).
Незанятое пространство — это область между последней ячейкой массива указателей и началом первой ячейки.
Зарезервированное место в конце каждой страницы используется расширениями для хранения информации о странице. Размер зарезервированной области определяется в заголовке базы (по умолчанию равен нулю).
Representation
TABLE
TABLEWITHOUT ROWID
Каждая таблица (без ROWID) представляется в базе в виде index b — tree. Отличие от таблиц с rowid, заключается в том, что ключ каждой записи SQL таблицы хранится в виде record format, при чем столбцы ключа хранятся как указаны в PRIMARY KEY, а остальные в порядке указанном в объявлении таблицы.
Таким образом записи в index b — tree представляются также как и в table b — tree, кроме порядка столбцов и того, что содержание строки хранится в ключе дерева, а не в качестве данных на листьях как в table b — tree.
INDEX
Каждый индекс (объявленный CREATE INDEX, PRIMARY KEY или UNIQUE) представляется в базе в виду index b — tree. Каждая запись в таком дереве соответствует строки в SQL таблице. Ключ индексного дерева представляет собой последовательность значений столбцов указанных в индексе и завершается значением ключа строки (rowid или primary key) в record format.
UPD 13:44: переработан раздел Representation, спасибо за критику mayorovp (можно было конечно и пошевелиться, ну да ладно).
После того как вы инсталлировали Microsoft SQL Server 2000, а затем спроектировали размещение баз данных и дисков, можно приступить к созданию баз данных. SQL Server 2000 применяет усовершенствованные методы хранения данных и управления дисковой памятью, появившиеся в SQL Server 7. В более ранних версиях продукта для размещения данных использовались логические устройства и сегменты фиксированного размера, но SQL Server 2000 использует файлы и группы файлов, которые могут быть сконфигурированы на автоматический рост или уменьшение. В данной лекции будет подробно рассказано о файлах и группах файлов, а также рассказано, как управлять ростом базы данных . Вы также познакомитесь с тремя методиками создания баз данных, узнаете, как просматривать информацию о базах данных и как удалять ненужные базы данных .
Структура базы данных
Каждая база данных SQL Server состоит из набора файлов операционной системы. Эти файлы могут группироваться в группы файлов, что облегчает их администрирование, помогает в размещении данных и повышает производительность. В данном разделе вы познакомитесь с файлами и группами файлов SQL Server и узнаете об их значении для создания баз данных.
Файлы
Как мы уже сказали, база данных SQL Server состоит из набора файлов операционной системы. Файл базы данных может быть либо файлом данных, либо файлом журнала. Файлы данных служат для хранения данных и объектов, таких как таблицы, индексы, представления, триггеры и хранимые процедуры. Имеется два типа файлов данных: первичные и вторичные. Файлы журналов служат только для хранения информации из журналов транзакций. Место на диске, отводимое для файлов журналов всегда должно администрироваться отдельно от места, отводимого для данных, и никогда не должно быть частью файла данных.
Каждая база данных должна создаваться хотя бы с одним файлом данных и с одним файлом журнала; файлы не могут быть использованы более чем в одной базе данных – т.е., базы данных не могут разделять файлы (использовать файлы совместно). В приведенном ниже перечне указаны три типа файлов, которые могут быть использованы в базах данных:
- Первичные файлы данных. Первичные файлы данных содержат всю информацию для запуска базы данных и ее системных таблиц и объектов. Они указывают на другие файлы, созданные в базе данных. Они могут также содержать таблицы и объекты, задаваемые пользователем, хотя это и не обязательно. Каждая база данных может иметь ровно один первичный файл . Для этих файлов рекомендуется применять расширение .mdf.
- Вторичные файлы данных. Вторичные файлы данных не являются обязательными. Они могут хранить данные и объекты, которые отсутствуют в первичном файле. База данных может вообще не иметь ни одного вторичного файла (если все ее данные хранятся в первичном файле). Можно иметь ноль, один или несколько вторичных файлов. Для некоторых баз данных требуется иметь несколько вторичных файлов, чтобы размещать данные по нескольким отдельным дискам. (Это не RAID-массивы дисков, как вы увидите из следующего раздела). Для этих файлов рекомендуется применять расширение .ndf.
- Файлы журналов транзакций. Файлы журналов транзакций хранят всю информацию из журнала транзакций, служащую для восстановления базы данных. Каждая база данных должна иметь хотя бы один файл журнала, а может иметь и несколько файлов журналов. Для этих файлов рекомендуется применять расширение .ldf.
Простая база данных может иметь один первичный файл данных, достаточно большой, чтобы в него могли поместиться все данные и объекты и один файл – журнал транзакций. Более сложная база данных может иметь один первичный файл данных, пять вторичных файлов данных и два файла – журнала транзакций.
Но как же данные смогут размещаться по многим файлам данных? А вот для этого и применяются группы файлов.
Группы файлов
При помощи групп файлов можно группировать файлы, это нужно для администрирования и размещения данных. (Группы файлов похожи на сегменты в Microsoft SQL Server 6.5 и в более ранних версиях.) Применение групп файлов позволяет повысить производительность базы данных, т.к. становится возможным создание базы данных, размещенной на многих дисках, на многих контроллерах и на RAID-массивах. (Про RAID-массивы см. "Конфигурирование и планирование подсистемы ввода-вывода" .) При помощи групп файлов можно создавать таблицы и индексы, размещаемые на заданных физических дисках, контроллерах и массивах дисков. В данной лекции мы рассмотрим некоторые примеры такой работы.
Имеются три типа групп файлов со следующими основными свойствами:
- Первичные группы файлов. Содержат первичный файл данных и все остальные файлы, не помещенные в другие группы файлов. К первичной группе файлов базы данных отнесены системные таблицы, задающие пользователей, объекты и полномочия для этой базы данных. SQL Server автоматически создает эти системные таблицы всякий раз, когда вы создаете базу данных.
- Пользовательские группы файлов. Все группы файлов, заданные пользователем в процессе создания (или последующего изменения) базы данных. Создавая таблицу или индекс, вы можете задать, чтобы они помещались в заданную пользовательскую группу файлов.
- Стандартная группа файлов. Содержит все страницы для таблиц и индексов, у которых при создании не была задана конкретная группа файлов. По умолчанию, стандартной группой файлов является первичная группа файлов. Члены роли db_owner могут менять стандартную группу файлов, делая стандартной ту либо иную группу файлов. В каждый момент времени стандартной может быть лишь какая-то одна группа файлов, и, повторим, если стандартная группа файлов не была задана явно, то первичная группа файлов автоматически будет стандартной. Чтобы изменить стандартную группу файлов, воспользуйтесь следующей командой Transact SQL (T-SQL):
Чтобы повысить производительность, вы можете управлять размещением данных, создавая таблицы и индексы в разных группах файлов. Так, вы можете пожелать поместить таблицу, доступ к которой бывает часто, в группу файлов на большом массиве дисков (например, составленным из 10 дисков), а другую таблицу, доступ к которой бывает реже, поместить в другую группу файлов, расположенную на отдельном, меньшем массиве дисков (например, из 4 дисков). Таким образом, можно размещать таблицы, доступ к которым происходит чаще, по большему количеству дисков, позволяя этим дискам осуществлять параллельный ввод-вывод. Если вы не применяете массивы RAID и у вас имеется несколько дисковых накопителей, то у вас остается возможность применения групп файлов. Например, вы можете создать по отдельному файлу для каждого дискового накопителя, разместив каждый файл в отдельную пользовательскую группу файлов. Тогда вы сможете поместить каждую таблицу или индекс в отдельный файл (и на отдельный диск), назначив группу файлов при создании этой таблицы или индекса. Пример размещения файлов показан на рис. 9.1: один первичный файл данных размещен в первичной группе файлов на диске C, по одному вторичному файлу данных размещено в каждой из пользовательских групп файлов (FG1 и FG2) на дисках E и F и один файл-журнал размещен на диске G. После этого вы можете создавать таблицы и индексы в каждой из пользовательских групп файлов – FG1 или FG2.
Рис. 9.1. Применение групп файлов для управления размещением данных
А может быть, вы будете применять пользовательскую группу файлов для распределения данных по нескольким дискам. На рис. 9.2 показана пользовательская группа файлов FG1, состоящая из двух вторичных файлов данных, один из которых находится на диске E, а другой – на диске F (диске G размещен файл-журнал, а на C – первичный файл ). В этом примере мы снова предполагаем, что каждый файл базы данных создан на отдельном физическом дисковом накопителе, и у нас нет аппаратной реализации RAID. Таблицы и индексы, созданные в этой пользовательской группе файлов, будут размещены сразу на двух дисках, потому что SQL Server применяет стратегию пропорционального расходования ресурсов.
Рис. 9.2. Применение одной группы файлов для распределения данных по нескольким дискам
Если вы применяете RAID-систему, то вам может потребоваться распределить данные из большой таблицы по нескольким логическим дискам-массивам, сконфигурированным на двух или на нескольких RAID-контроллерах. Для этого вам надо будет создать пользовательскую группу файлов, с файлами, соответствующими каждому из этих контроллеров. Допустим, вы создали два вторичных файла данных, каждый – на своем массиве дисков, а каждый логический массив состоит из восьми физических дисков и сконфигурирован как RAID 5. Эти два массива обслуживаются двумя отдельными RAID-контроллерами. Чтобы создать таблицу или индекс, располагающуюся на обоих этих контроллерах (т.е. на всех 16 дисковых накопителях), создайте одну пользовательскую группу файлов, в которую поместите оба файла, а затем создайте таблицу или индекс в этой группе файлов. Пользовательская группа файлов FG1 распределена по 16 физическим дискам (двум логическим дискам – RAID-массивам) (см. рис. 9.3). Там также показаны первичный файл данных на другом контроллере (с RAID 1) и файл журнала еще на одном контроллере (с RAID 10 ).
SQL Server позволяет оптимизировать распределение ваших данных по дисковым накопителям, за счет автоматического пропорционального расслоения (распределения) данных по всем файлам группы файлов. "Расслоение" (striping) – это термин, применяемый для описания распределения данных по нескольким файлам базы данных. Расслоение файлов SQL Server работает независимо от расслоения дисков RAID-массивов и, как вы видели из наших примеров, может применяться как в сочетании с RAID, так и самостоятельно.
Чтобы обеспечить расслоение данных, SQL Server записывает данные в файлы в объемах, пропорциональных свободному месту, остающемуся в файлах (относительно свободному месту в других файлах). Место для таблиц и индексов распределяется в виде экстентов (extents). Экстент – это единица для измерения места на диске, один экстент состоит из 8 страниц, а одна страница состоит из 8 Кб, так что один экстент состоит из 64 Кб. Допустим, нужно распределить 5 экстентов на файл F1, в котором свободно 400 Мб, и на файл F2, в котором свободно 100 Мб; тогда 4 экстента будут распределены на файл F1 и один экстент распределен на файл F2. Оба файла заполнятся до конца примерно одновременно, благодаря чему операции ввода-вывода будут распределяться по дискам более равномерно. Пропорциональное заполнение будет применяться и для пользовательских, и для первичных групп файлов. Если задать все файлы в группе файлов имеющими одинаковый начальный размер, то данные, по мере их загрузки, будут распределяться по файлам равномерно. Этот метод, когда в группах создаются файлы одинакового начального размера, можно порекомендовать для равномерного распределения данных по дисковым накопителям и, одновременно с этим, для равномерного распределения операций ввода-вывода.
Рис. 9.3. Распределение пользовательской группы файлов по нескольким RAID-контроллерам
Другая польза от применения групп файлов состоит в том, что SQL Server может выполнять резервные копирования базы данных файлами или группами файлов. Если ваша база данных слишком велика, чтобы ее можно было скопировать за один раз, то вы можете копировать ее по частям. (О методике такого резервного копирования см. "Резервное копирование Microsoft SQL Server" .)

MySQL - это система управления базами данных. А для управления необходимо знать структуру баз данных. Это очень важная статья, поэтому обязательно её прочтите.
Структура базы данных следующая:
- База данных состоит из одной или нескольких таблиц.
- Каждая таблица имеет одно или несколько полей.
- В каждой таблице имеется одна или несколько записей.
А теперь немного поподробнее каждый пункт. Как было сказано выше, база данных состоит из набора таблиц. Примером таблиц в базе данных могут быть, например, таблица пользователей сайта, таблица статей, таблица с разделами сайта и так далее.
В каждой из этих таблиц имеется одно или несколько полей. Например, в таблице пользователей сайта могут быть такие поля: логин, пароль, e-mail и другие. В таблице со статьями могут быть такие поля: название статьи, автор статьи, текст статьи, дата создания и другие. Надеюсь, суть понятна.
И, наконец, в таблице содержатся записи. Запись - это строка в таблице, где каждая ячейка содержит значение соответствующего поля. Например, для пользователя сайта может быть такая запись: "Adm 123456 adm@mail.ru". Каждое из этих значений находится в своей ячейке таблицы.
Чтобы стало ещё понятнее, то представьте таблицу, обычную таблицу. У таблицы есть заголовки каждого столбца. Эти заголовки называются полями. Затем идёт содержимое таблицы. Это содержимое и называется записями. В общем, всё очень прозрачно, и никаких выходящих за рамки выкрутасов базы данных не имеют. Всё проще некуда.
Резюмирую. Структура базы данных:
- База данных.
- Таблицы.
- Поля таблицы.
- Записи в таблицах.
P.S. С наступившим 2011-ым годом! Удачи Вам и успеха!

Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
Она выглядит вот так:
Комментарии ( 0 ):
Читайте также: