
Изменить файловую группу таблицы sql
Обновлено: 07.07.2024
В сегодняшней статье я хочу поговорить об очень важной теме SQL Server: как SQL Server обрабатывает файловые группы файлов. Когда вы используете команду CREATE DATABASE для создания простой базы данных, SQL Server создает для вас 2 файла:
- Файл данных (.mdf)
- Файл журнала транзакций (.ldf)
Сам файл данных создается в одной и только одной основной группе файлов. По умолчанию в основной группе файлов SQL Server хранит все данные (пользовательские таблицы, системные таблицы и т. Д.). Для чего нужны дополнительные файлы и файловые группы? Давайте взглянем.
Когда вы создаете дополнительные файловые группы для своих данных, вы можете сохранять в них определяемые вами таблицы и индексы. Это поможет вам во многих отношениях.
- Вы можете сохранить свою основную файловую группу небольшой.
- Вы можете разделить данные на несколько файловых групп (например, вы можете использовать файловые разделы в корпоративной версии).
- Вы можете выполнять операции резервного копирования и восстановления на уровне файловой группы. Это дает вам более точный контроль над стратегиями резервного копирования и восстановления.
- Команду DBCC CHECKDB можно запустить на уровне группы файлов, а не на уровне базы данных.
Как правило, у вас должна быть хотя бы одна группа подчиненных файлов, в которой вы можете хранить создаваемые вами объекты базы данных. Вы не должны хранить другие системные объекты, созданные SQL Server для вас, в основной файловой группе.
Когда вы создаете свою собственную файловую группу, вы также должны поместить в нее хотя бы один файл. Кроме того, в файловую группу можно добавлять дополнительные файлы. Это также улучшит вашу производительность загрузки, потому что SQL Server будет распространять данные по всем файлам, так называемые Алгоритм Round Robin Allocation (Алгоритм Round Robin Allocation). Первые 64 КБ хранятся в первом файле, вторые 64 КБ хранятся во втором файле, а третья область сохраняется в первом файле (в вашей файловой группе, когда у вас есть 2 файла).
Используя этот метод, SQL Server может находиться в буферном пуле Защелка выделяет несколько копий растровых страниц (PFS, GAM, SGAM) и повышает производительность загрузки. Вы также можете использовать этот метод для решения той же проблемы с конфигурацией по умолчанию в TempDb. Кроме того, SQL Server также гарантирует, что все файлы в группе файлов будут заполнены в один и тот же момент времени - с помощью так называемого Алгоритм пропорционального заполнения . Поэтому очень важно, чтобы все ваши файлы в группе файлов имели одинаковый начальный размер и параметры автоматического увеличения. в противном случае Алгоритм распределения циклического планирования не может работать должным образом.
Теперь мы рассмотрим следующий пример, как создать базу данных с несколькими файлами в группе дополнительных файлов. В следующем коде показана команда CREATE DATABASE, которую необходимо использовать для выполнения этой задачи.
После создания базы данных возникает вопрос, как поместить таблицу или индекс в определенную файловую группу? Вы можете использовать ключевое слово ON, чтобы вручную указать группу файлов, как показано в следующем коде:
Другой вариант: вы помечаете определенную группу файлов как группу файлов по умолчанию. Затем SQL Server автоматически создает новый объект базы данных в группе файлов, в которой не указано ключевое слово ON.
Это метод, который я обычно рекомендую, потому что вам больше не нужно думать об этом после создания объектов базы данных. Итак, теперь давайте создадим новую таблицу, которая будет автоматически сохранена в файловой группе FileGroup1.
Теперь проводим простой тест: вставляем в таблицу 40 000 записей. Каждая запись имеет размер 8 КБ. Итак, мы вставили в таблицу 320 МБ данных. Это то, что я только что упомянул Алгоритм распределения расписания опроса будет работать: SQL Server будет распределять данные между 2 файлами: первый файл содержит 160 МБ данных, а второй файл также будет иметь 160 МБ данных.
Затем вы можете проверить его на жестком диске, и вы увидите тот же размер, что и два файла.

Когда вы помещаете эти файлы на разные физические жесткие диски, вы можете получить к ним доступ одновременно. Это сила наличия нескольких файлов в файловой группе.
Вы также можете использовать следующий сценарий для получения информации о файле базы данных.
В сегодняшней статье я показал вам, как несколько групп файлов и несколько файлов в группе файлов упрощают управление вашей базой данных и как использовать несколько файлов в группе файлов. Алгоритм распределения циклического планирования.
Много людей, которые поневоле занимаются администрированием баз данных, могут не знать, как таблицы распределяются по файлам в файловых группах. Часто оказывается, что менее опытные люди путаются с файлами и файловыми группами, а также с тем, как SQL Server распределяет данные по файлам, и почему данные не перемещаются при добавлении файлов.
В этой статье показывается, как SQL Server обрабатывает данные, когда новые файлы добавляются в файловую группу. Мы также покажем, как распределить данные более равномерно, чтобы сбалансировать нагрузку чтения/записи.
Сценарий
Рассмотрим небольшой пример, который проиллюстрирует нашу цель. Когда у вас будет больше данных, проблема усугубится, но эффект остается тем же. Мы предполагаем, что у вас есть база данных с некоторым количеством данных. Вы можете видеть, что у меня имеется несколько таблиц с небольшим числом строк.
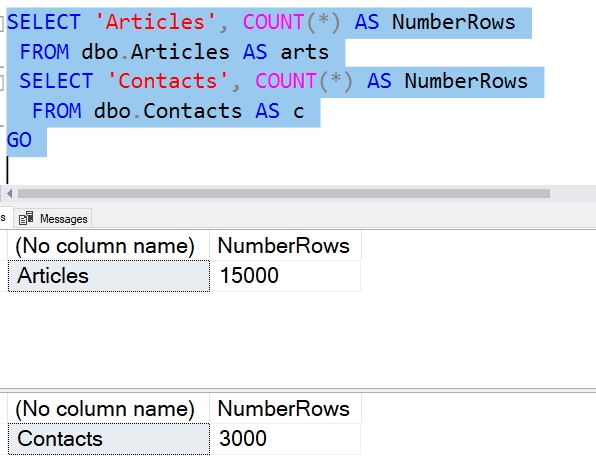
Однако моей базе данных не хватает места. По моим оценкам, если я добавляю несколько МБ данных в день, то скоро у меня закончится место.
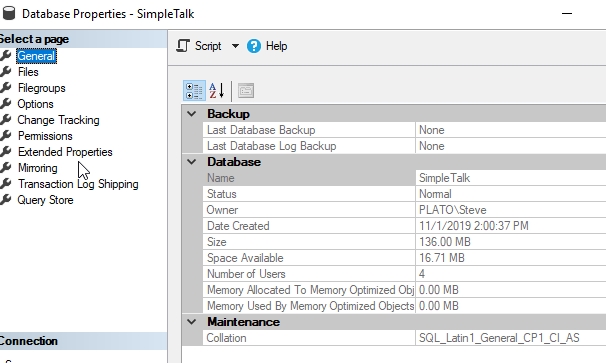
По умолчанию у меня есть одна файловая группа с единственным файлом. Как можно видеть, я имею файл на 128Мб и журнал размером 8Мб:
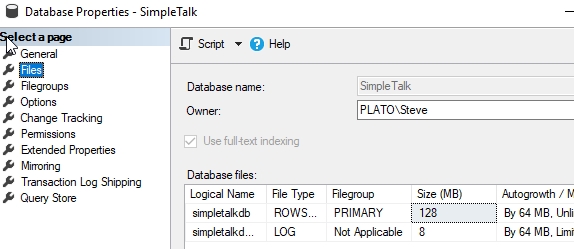
Обычно в таких ситуациях следует проявить активность и добавить несколько файлов данных для распределения нагрузки. Тут вы можете увидеть, что мы добавили 3 дополнительных файла данных в нашу базу. Когда я это делаю, то добавляю файлы того же размера, что и оригинальный файл. Это лучший способ гарантировать сбалансированность файловой группы.
Замечание. Я показываю это в графическом интерфейсе, но вы должны взять скрипт и выполнить его в команде ALTER DATABASE, а не визуальными действиями в Management Studio.
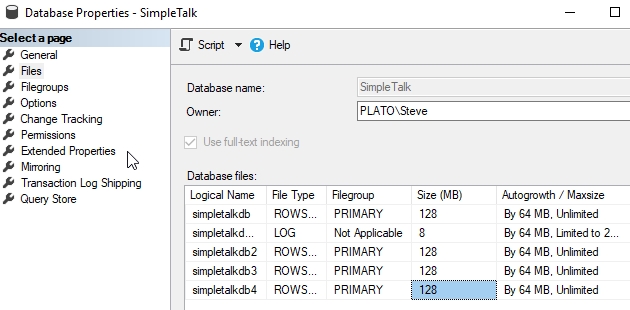
Теперь я могу сделать запрос к моим файлам. Для этого я выполню следующий код:
Вот результаты, которые я получаю. Мой первый файл (simpletalkdb) почти заполнен. Он имеет 15Мб, которые могут быть использованы, а остальные файлы используются незначительно (0.06Мб). В крайнем справа столбце показан процент свободного пространства, 13% для первого файла и 99% - для остальных.

Здесь пользователи часто испытывают недоумение. Почему мои данные не переместились для балансировки файлов? Если я добавлю новые данные, вот что я увижу. Я добавлю около 30 мегабайт данных и повторю запрос. Теперь результаты выглядят так:

В каждый файл были добавлены некоторые данные, но распределение не равномерное. Я имею почти 12% свободного пространства в одном файле при 90% свободного пространства в других. Почему?
Пропорциональное заполнение
SQL Server использует алгоритм пропорционального заполнения, который записывает существенно больше данных в пустые файлы, чем в заполненные. Он пытается (в конечном итоге) сбалансировать данные по всем файлам. Вы можете больше прочитать об этом на SQLServerCentral и SQLskills. Это алгоритм циклической записи, который решает, в какой файл писать, и, чем больше каждый файл имеет свободного пространства, тем больше данных в него записывается.
На практике лучше иметь файлы одинаковых размеров и приблизительно одинаковое количество данных в каждом из них. Это сбалансирует запись и улучшит производительность.
Балансировка данных
Если в этом состоит наша цель, то как получить равномерное распределение данных по файлам? Если мы продолжим добавлять данные, то в конечном итоге добьемся этого, но мы будем иметь все больше и больше записей, приходящихся на пустые файлы, пока не достигнем желаемого.
Если у вас есть кластеризованный индекс, самый простой способ попытаться сделать это с помощью перестройки индекса. Я могу использовать следующий код на самых больших таблицах:
По завершению перестройки, я могу снова выполнить запрос, показывающий распределение данных. Теперь оно выглядит так:

Это небольшое перемещение, т.к. мои новые файлы заполнены на 90% (грубо), а старый на 12%. Однако это не очень хорошо. Но если я проверю размер этих таблиц, то в них находится всего 13Мб. Это означает, что я ожидал получить примерно 2Мб в каждом файле. Так было бы при пропорциональной заливке, что хорошо.
Если у вас куча, это не сработает без перестройки всех индексов. Как только это будет сделано, вы можете использовать команду ALTER TABLE . REBUILD, чтобы перераспределить данные.
К сожалению, лучшим способом является полная очистка. Она рекомендуется, чтобы позволить данным постоянно равномерно распределяться по файлам при регулярной переиндексации в обычном режиме.
Если вы хотите выполнить очистку более быстро, можно сделать следующее. Сначала добавьте новую файловую группу и файл. Я сделаю это в базе данных, убедившись, что мой файл имеет достаточно места, чтобы содержать данные из моих больших таблиц.
Затем я хочу перестроить кластеризованный индекс, но перемещая его в новую файловую группу. Я буду использовать следующий код для перемещения обеих первичных ключей в новую файловую группу:
После перемещения данных нам нужно вернуть их назад. Повторим то же действие, но в другую файловую группу.
Если проверим файлы, то увидим следующее:

Теперь наш первый файл имеет 62% свободного пространства, а другие 3 файла - 75%. Довольно сбалансировано. Видно использование файла Temp, который не почистили, но мы можем удалить этот файл и файловую группу таким образом:
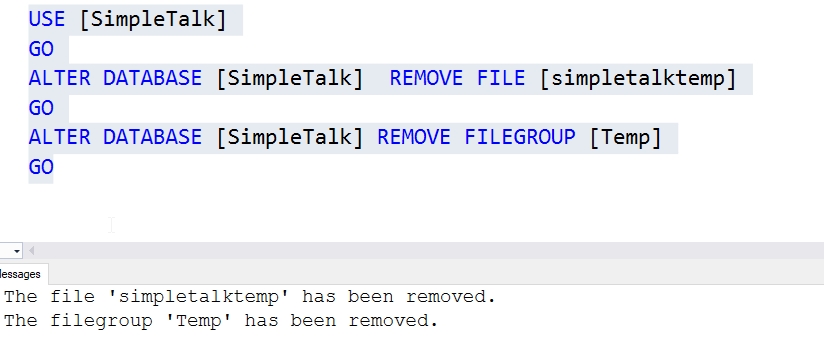
Не забудьте почистить. Если у вас есть пространство в существующей файловой группе, вы можете сделать то же самое, указывая эту файловую группу вместо Temp, когда перестраиваете кластеризованный индекс.
Заключение
В этой статье демонстрируется, что SQL Server не распределяет автоматически данные по файлам, если вы добавляете их в файловую группу. Вам нужно вручную это делать, или просто позволить естественным образом прийти к этому со временем. Любой способ будет работать, но остерегайтесь большой активности в более пустом файле, пока это состояние не достигнуто.
Также убедитесь, что вы устанавливаете одинаковые размеры и автоувеличение с исходным файлом, чтобы обеспечить эффективное функционирование вашего экземпляра.
Язык Transact-SQL поддерживает изменение структуры следующих объектов базы данных:
В последующих двух разделах описывается изменение первых двух объектов из этого списка: баз данных и таблиц. Изменение структуры последних четырех объектов этого списка будет описано при их обсуждении в следующих статьях.
Изменение базы данных
Для изменения физической структуры базы данных используется инструкция ALTER DATABASE. Язык Transact-SQL позволяет выполнять следующие действия по изменению свойств базы данных:
добавлять и удалять один или несколько файлов базы данных;
добавлять и удалять один или несколько файлов журнала;
добавлять и удалять файловые группы;
изменять свойства файлов или файловых групп;
устанавливать параметры базы данных;
изменять имя базы данных с помощью хранимой процедуры sp_rename.
Эти разные типы модификаций базы данных рассматриваются далее.
Добавление и удаление файлов базы данных, файлов журналов и файловых групп
Добавление или удаление файлов базы данных осуществляется посредством инструкции ALTER DATABASE. Операция добавления нового или удаления существующего файла указывается предложением ADD FILE и REMOVE FILE соответственно. Кроме этого, новый файл можно определить в существующую файловую группу посредством параметра TO FILEGROUP.
В примере ниже показано добавление нового файла базы данных в базу данных SampleDb:
В этом примере инструкция ALTER DATABASE добавляет новый файл с логическим именем sampledb_dat1. Здесь же указан начальный размер файла 10 Мбайт и автоувеличение по 5 Мбайт до максимального размера 100 Мбайт. Файлы журналов добавляются так же, как и файлы баз данных. Единственным отличием является то, что вместо предложения ADD FILE используется предложение ADD LOG FILE.
Удаления файлов (как файлов базы данных, так и файлов журнала) из базы данных осуществляется посредством предложения REMOVE FILE. Удаляемый файл должен быть пустым.
Новая файловая группа создается посредством предложения CREATE FILEGROUP, а существующая удаляется с помощью предложения DELETE FILEGROUP. Как и удаляемый файл, удаляемая файловая группа также должна быть пустой.
Изменение свойств файлов и файловых групп
С помощью предложения MODIFY FILE можно выполнять следующие действия по изменению свойств файла:
изменять логическое имя файла, используя параметр NEWNAME;
увеличивать значение свойства SIZE;
изменять значение свойств FILENAME, MAXSIZE и FILEGROWTH;
отмечать файл как OFFLINE.
Подобным образом с помощью предложения MODIFY FILEGROUP можно выполнять следующие действия по изменению свойств файловой группы:
изменять логическое имя файловой группы, используя параметр NAME;
помечать файловую группу, как файловую группу по умолчанию, используя для этого параметр DEFAULT;
помечать файловую группу как позволяющую осуществлять доступ только для чтения или для чтения и записи, используя для этого параметр read_only или read_write соответственно.
Установка опций базы данных
Для установки различных опций базы данных используется предложение SET инструкции ALTER DATABASE. Некоторым опциям можно присвоить только значения ON или OFF, но для большинства из них предоставляется выбор из списка возможных значений. Каждый параметр базы данных имеет значение по умолчанию, которое устанавливается в базе данных model. Поэтому значения определенных опций по умолчанию можно модифицировать, изменив соответствующим образом базу данных model.
Все опции, значения которых можно изменять, можно разбить на несколько групп, наиболее важными из которых являются опции состояния, опции автоматических действий и опции SQL.
Опции состояния управляют следующими возможностями:
доступом пользователей к базе данным (это опции single_user, restricted_user и multi_user);
статусом базы данных (это опции online, offline и emergency);
режимом чтения и записи (опции read_only и read_write).
Опции автоматических операций управляют, среди прочего, остановом базы данных (опция auto_close) и способом создания статистики индексов (опции auto_create_statistics и auto_update_statistics).
Опции SQL управляют соответствием базы данных и ее объектов стандарту ANSI. Значения всех операторов SQL можно узнать посредством функции DATABASEPROPERTY, а редактировать - с помощью инструкции ALTER DATABASE.
Опции восстановления full, bulk-logged и simple управляют процессом восстановления базы данных.
Хранение данных типа FILESTREAM
При описании типов данных T-SQL мы рассмотрели данные типа FILESTREAM и причины, по которым их используют. В этом разделе мы рассмотрим, как данные типа FILESTREAM можно сохранять в базе данных. Чтобы данные FILESTREAM можно было сохранять в базе данных, система должна быть должным образом инициирована. В следующем подразделе объясняется, как инициировать операционную систему и экземпляр базы данных для хранения данных типа FILESTREAM.
Инициирование хранилища FILESTREAM
Хранилище данных типа FILESTREAM требуется инициировать на двух уровнях:
для операционной системы Windows;
для конкретного экземпляра сервера базы данных.
Инициирование хранилища данных типа FILESTREAM на уровне системы осуществляется с помощью диспетчера конфигурации SQL Server Configuration Manager. Чтобы запустить диспетчер конфигурации, выполните следующую последовательность команд по умолчанию Пуск --> Все программы --> Microsoft SQL Server 2012 --> Configuration Tools . В открывшемся окне Sql Server Configuration Manager щелкните правой кнопкой пункт SQL Server Services (Службы SQL Server) и в появившемся контекстном меню выберите команду Open. В правой панели щелкните правой кнопкой экземпляр, для которого требуется разрешить хранилище FILESTREAM, и в контекстном меню выберите команду Properties. В открывшемся диалоговом окне SQL Server Properties выберите вкладку FILESTREAM:

Чтобы иметь возможность только читать данные типа FILESTREAM, установите флажок Enable FILESTREAM for Transact-SQL access (Разрешить FILESTREAM при доступе через Transact-SQL). Чтобы кроме чтения можно было также записывать данные, установите дополнительно флажок Enable FILESTREAM for file I/O streaming access (Разрешить использование FILESTREAM при доступе файлового ввода/вывода). Введите имя общей папки Windows в одноименное поле. Общая папка Windows используется для чтения и записи данных FILESTREAM, используя интерфейс API Win32. Если для возвращения пути для FILESTREAM BLOB использовать имя, то это будет имя общей папки Windows.
Диспетчер конфигурации SQL Server создаст на системе хоста новую общую папку с указанным именем. Чтобы применить изменения, нажмите кнопку OK.
Чтобы разрешить хранилище FILESTREAM, необходимо быть администратором Windows локальной системы и обладать правами администратора (sysadmin). Чтобы изменения вступили в силу, необходимо перезапустить экземпляр сервера базы данных.
Следующим шагом будет разрешить хранилище FILESTREAM для конкретного экземпляра. Мы рассмотрим, как выполнить эту задачу с помощью среды SQL Server Management Studio. (Для этого можно также воспользоваться хранимой системной процедурой sp_configure с параметром FILESTREAM ACCESS LEVEL.) Щелкните правой кнопкой требуемый экземпляр в обозревателе объектов и в появившемся контекстном меню выберите пункт Properties, в левой панели открывшегося диалогового окна Server Properties выберите пункт Advanced (Дополнительно):

После этого в правой панели из выпадающего списка выберите FILESTREAM Access Level (Уровень доступа FILESTREAM) одну из следующих опций:
Disabled
Отключено - хранилище FILESTREAM не разрешено.
Transact-SQL Access Enabled
Включен доступ с помощью Transact-SQL - к данным FILESTREAM можно обращаться посредством инструкций T-SQL.
Full Access Enabled
Включен полный доступ - к данным FILESTREAM можно обращаться как посредством инструкций T-SQL, так и через интерфейс API Win32.
Добавление файла в файловую группу
Разрешив хранилище FILESTREAM для требуемого экземпляра, можно сначала создать файловую группу для данных FILESTREAM (посредством инструкции ALTER DATABASE), а затем добавить файл в эту файловую группу, как это показано в примере ниже. (Конечно же, эту задачу также можно было бы выполнить с помощью инструкции CREATE DATABASE.)
Первая инструкция ALTER DATABASE в примере добавляет в базу данных SampleDb новую файловую группу Employee_FSGroup. Параметр CONTAINS FILESTREAM этой инструкции указывает системе, что данная файловая группа будет содержать только данные FILESTREAM. Вторая инструкция ALTER DATABASE добавляет в созданную файловую группу новый файл.
Теперь можно создавать таблицы, содержащие столбцы с типом данных FILESTREAM. Создание такой таблицы показано в примере ниже:
В этом примере таблица EmployeeInfo содержит столбец FilestreamData, тип данных которого должен быть VARBINARY(MAX). Определение такого столбца включает атрибут FILESTREAM, указывающий, что данные столбца сохраняются в файловой группе FILESTREAM. Для всех таблиц, в которых хранятся данные типа FILESTREAM, требуется наличие свойств UNIQUE ROWGUIDCOL. Поэтому таблица EmployeeInfo содержит столбец Id, определенный с использованием этих двух атрибутов.
Данные в столбце типа FILESTREAM вставляются посредством стандартной инструкции INSERT. А для считывания данных используется стандартная инструкция SELECT.
Автономные базы данных
Одна из значительных проблем с базами данных SQL Server состоит в том, что они трудно поддаются экспортированию и импортированию. Как рассматривалось ранее, базы данных можно присоединять и отсоединять, но при этом утрачиваются важные части и свойства присоединенных баз данных. (Основной проблемой в таких случаях является безопасность базы данных, в общем, и учетные записи, в частности, в которых после перемещения обычно отсутствует часть информации или содержится неправильная информация.)
Разработчики Microsoft планируют решить эти проблемы посредством использования автономных баз данных (contained databases). Автономная база данных содержит все параметры и данные, необходимые для определения базы данных, и изолирована от экземпляра Database Engine, на котором она установлена. Иными словами, база данных данного типа не имеет конфигурационных зависимостей от экземпляра и ее можно с легкостью перемещать с одного экземпляра SQL Server на другой.
По большому счету, что касается автономности, существует три вида баз данных:
полностью автономные базы данных;
частично автономные базы данных;
неавтономные базы данных.
Полностью автономными являются такие базы данных, объекты которых не могут перемещаться через границы приложения. (Граница приложения определяет область видимости приложения. Например, пользовательские функции находятся в границах приложения, в то время как функции, связанные с экземплярами сервера, находятся вне границ приложения.)
Частично автономные базы данных позволяют объектам пересекать границы приложения, в то время как неавтономные базы данных вообще не поддерживают концепции границы приложения.
В SQL Server 2012 поддерживаются частично автономные базы данных. В будущих версиях SQL Server также будет поддерживаться полная автономность. Базы данных предшествующих версий SQL Server являются неавтономными.
Рассмотрим, как создать частично автономную базу данных в SQL Server 2012. Если существующая база данных SampleDb является неавтономной (созданная, например, посредством инструкции CREATE DATABASE), с помощью инструкции ALTER DATABASE ее можно преобразовать в частично автономную, как это показано в примере ниже:
Инструкция ALTER DATABASE изменяет состояние автономности базы данных SampleDb с неавтономного на частично автономное. Это означает, что теперь система базы данных позволяет создавать как автономные, так неавтономные объекты для базы данных SampleDb. Все другие инструкции в примере являются вспомогательными для инструкции ALTER DATABASE.
Функция sp_configure является системной процедурой, с помощью которой можно, среди прочего, изменить дополнительные параметры конфигурации, такие как 'contained database authentication'. Чтобы изменить дополнительные параметры конфигурации, сначала нужно присвоить параметру 'show advanced options' значение 1, а потом переконфигурировать систему (инструкция RECONFIGURE). В конце кода этому параметру опять присваивается его значение по умолчанию - 0.
Теперь для базы данных SampleDb можно создать пользователя, не привязанного к учетной записи.
Изменение таблиц
Для модифицирования схемы таблицы применяется инструкция ALTER TABLE. Язык Transact-SQL позволяет осуществлять следующие виды изменений таблиц:
добавлять и удалять столбцы;
изменять свойства столбцов;
добавлять и удалять ограничения для обеспечения целостности;
разрешать или отключать ограничения;
переименовывать таблицы и другие объекты базы данных.
Эти типы изменений рассматриваются в последующих далее разделах.
Добавление и удаление столбцов
Чтобы добавить новый столбец в существующую таблицу, в инструкции ALTER TABLE используется предложение ADD. В одной инструкции ALTER TABLE можно добавить только один столбец. Применение предложения ADD показано в примере ниже:
В этом примере инструкция ALTER TABLE добавляет в таблицу Employee столбец PhoneNumber. Компонент Database Engine заполняет новый столбец значениями NULL или IDENTITY или указанными значениями по умолчанию. По этой причине новый столбец должен или поддерживать значения NULL, или для него должно быть указано значение по умолчанию.
Новый столбец нельзя вставить в таблицу в какой-либо конкретной позиции. Столбец, добавляемый предложением ADD, всегда вставляется в конец таблицы.
Столбцы из таблицы удаляются посредством предложения DROP COLUMN. Применение этого предложения показано в примере ниже:
В этом коде инструкция ALTER TABLE удаляет в таблице Employee столбец PhoneNumber, который был добавлен в эту таблицу предложением ADD ранее.
Изменение свойств столбцов
Для изменения свойств существующего столбца применяется предложение ALTER COLUMN инструкции ALTER TABLE. Изменению поддаются следующие свойства столбца:
поддержка значения NULL.
Применение предложения ALTER COLUMN показано в примере ниже:
Инструкция ALTER TABLE в этом примере изменяет начальные свойства (nchar(40), значения NULL разрешены) столбца Location таблицы Department на новые (nchar(25), значения NULL не разрешены).
Добавление и удаления ограничений для обеспечения целостности (ключей и проверок)
Для добавления в таблицу новых ограничений для обеспечения целостности используется параметр ADD CONSTRAINT инструкции ALTER TABLE. В примере ниже показано использование параметра ADD CONSTRAINT для добавления проверочного ограничения и определения первичного ключа таблицы:
Ограничения для обеспечения целостности можно удалить посредством предложения DROP CONSTRAINT инструкции ALTER TABLE, как это показано в примере ниже:
Определения существующих ограничений нельзя модифицировать. Чтобы изменить ограничение, его сначала нужно удалить, а потом создать новое, содержащее требуемые модификации.
Разрешение и запрещение ограничений
Как упоминалось ранее, ограничение для обеспечения целостности всегда имеет имя, которое может быть объявленным или явно посредством опции CONSTRAINT, или неявно посредством системы. Имена всех ограничений таблицы (объявленных как явно, так и неявно) можно просмотреть с помощью системной процедуры sp_helpconstraint.
В последующих операциях вставки или обновлений значений в соответствующий столбец ограничение по умолчанию обеспечивается принудительно. Кроме этого, при объявлении ограничения все существующие значения соответствующего столбца проверяются на удовлетворение условий ограничения. Начальная проверка не выполняется, если ограничение создается с параметром WITH NOCHECK. В таком случае ограничение будет проверяться только при последующих операциях вставки и обновлений значений соответствующего столбца. (Оба параметра - WITH CHECK и WITH NOCHECK - можно применять только с ограничениями проверки целостности CHECK и проверки внешнего ключа FOREIGN KEY.)
В примере ниже показано, как отключить все существующие ограничения таблицы:
Все ограничения таблицы Sales отключаются посредством ключевого слова ALL. Применять опцию NOCHECK не рекомендуется, поскольку любые подавленные нарушения условий ограничения могут вызвать ошибки при будущих обновлениях.
Переименование таблиц и других объектов баз данных
Для изменения имени существующей таблицы (и любых других объектов базы данных, таких как база данных, представление или хранимая процедура) применяется системная процедура sp_rename. В примере ниже показано использование этой системной процедуры:
Использовать системную процедуру sp_rename настоятельно не рекомендуется, поскольку изменение имен объектов может повлиять на другие объекты базы данных, которые ссылаются на них. Вместо этого следует удалить объект и воссоздать его с новым именем.
Удаление объектов баз данных
Все инструкции Transact-SQL для удаления объектов базы данных имеют следующий общий вид:
Для каждой инструкции CREATE object для создания объекта имеется соответствующая инструкция DROP object для удаления. Инструкция для удаления одной или нескольких баз данных имеет следующий вид:
Эта инструкция безвозвратно удаляет базу данных из системы баз данных. Для удаления одной или нескольких таблиц применяется следующая инструкция:
При удалении таблицы удаляются все ее данные, индексы и триггеры. Но представления, созданные по удаленной таблице, не удаляются. Таблицу может удалить только пользователь, имеющий соответствующие разрешения.
Кроме объектов DATABASE и TABLE, в параметре objects инструкции DROP можно указывать, среди прочих, следующие объекты:
У меня есть SQL Server 2008 Ent и база данных OLTP с двумя большими таблицами. Как я могу переместить эти таблицы в другую файловую группу без прерывания службы? Теперь, около 100-130 вставленных записей и 30-50 записей обновляются каждую секунду в этой таблице. Каждая таблица имеет около 100 миллионов записей и шесть полей (включая поле географии).
Я ищу решение через google, но все решения содержат "создать вторую таблицу, вставить строки из первой таблицы, падение первой таблицы, бла-бла бла".
могу ли я использовать функции разбиения для решения этой проблемы? Спасибо.
Если вы хотите просто переместить таблицу в новую файловую группу, вам нужно воссоздать кластеризованный индекс в таблице (в конце концов: кластеризованный индекс is данные таблицы) в новой файловой группе, которую вы хотите.
Вы можете сделать это с например:
или если ваш кластеризованный индекс уникальный:
это создает новый кластеризованный индекс и отбрасывает существующий, а также создает новый кластеризованный индекс в файловой группе, которую вы указанный - et вуаля, данные таблицы были перемещены в новую файловую группу.
посмотреть документы MSDN для создания индекса для получения подробной информации о всех доступных параметрах, которые вы можете указать.
Это, конечно, еще не связано с разделением, но это совсем другая история для себя.
чтобы ответить на этот вопрос, сначала мы должны понять
- если таблица не имеет индекса, ее данные называются кучу
- если таблица имеет кластеризованный индекс, этот индекс фактически табличных данных. Поэтому при перемещении кластеризованного индекса также будут перемещены данные.
первый шаг-узнать больше информации о таблице, которую мы хотим переместить. Мы делаем это, выполняя это T-SQL:
вывод покажет вам столбец под названием " Data_located_on_filegroup."Это удобный способ узнать, в какой файловой группе находятся данные вашей таблицы. Но более важным является вывод, который показывает вам информацию об индексах таблицы. (Если вы хотите видеть только информацию об индексах таблицы, просто запустите sp_helpindex N'<<your table name>>' ) в вашей таблице может быть 1) нет индексов (так что это куча), 2) один индекс или 3) несколько индексов. Если index_description начинается с ' кластеризованный, уникальный, . - это индекс, который вы хотите переместить. Если индекс также является первичным ключом, это нормально, вы все равно можете переместить его.
чтобы переместить индекс, запишите index_name и index_keys, показанные в результатах вышеуказанного запроса справки, затем используйте их для заполнения <<blanks>> в следующем запросе:
на DROP EXISTING, ONLINE параметры выше важны. DROP EXISTING убедитесь, что индекс не дублируется, и ONLINE держит таблицу онлайн пока вы двигаете он.
если индекс, который вы перемещаете,не кластеризованный индекс, а затем заменить UNIQUE CLUSTERED выше NONCLUSTERED
чтобы переместить таблицу кучи, добавьте к ней кластеризованный индекс, затем запустите приведенную выше инструкцию, чтобы переместить ее в другую файловую группу, а затем удалите индекс.
теперь возвращайся и беги sp_help на вашем столе, и проверьте результаты, чтобы увидеть, где ваши данные таблицы и индекса теперь находится.
если ваша таблица имеет более одного индекс, затем после выполнения вышеуказанного оператора для перемещения кластеризованного индекса, sp_helpindex покажет, что ваш кластеризованный индекс находится в новой файловой группе, но все остальные индексы по-прежнему будут в исходной файловой группе. Таблица будет продолжать нормально функционировать, но у вас должна быть веская причина, почему вы хотите, чтобы индексы находились в разных файловых группах. Если вы хотите, чтобы таблица и все ее индексы были в одной файловой группе, повторите приведенные выше инструкции для каждого индекса, подставляя CREATE [NONCLUSTERED, or other] . DROP EXISTING. при необходимости, в зависимости от типа индекса, который вы перемещаете.
секционирование-это одно из решений, но вы можете "переместить" кластеризованный индекс в новую файловую группу без прерывания обслуживания (при соблюдении некоторых условий см. ссылку ниже) с помощью
кластерный индекс is данные, и это то же самое, что и перемещение файловой группы.
Это зависит от того, кластеризован ли ваш первичный ключ или нет, что меняет то, как мы это сделаем
Как уже говорили другие друзья, такие как принятый ответ marc_s, следующий скриншот дает вам другой способ сделать это с помощью SSMS GUI.

обратите внимание, что вы можете легко перейти в другую файловую группу свойства index на вкладке storage
Примечание: перемещение таблицы в другую файловую группу работает только с Enterprise Edition.
Шаг 1 :
проверьте, в какой таблице файловой группы находится:
Шаг 2 :
переместить существующую таблицу / таблицы в новую файловую группу
если файловая группа, в которую вы хотите переместить таблица to еще не существует, затем создайте вторичную файловую группу, а затем переместите таблицу.
для перемещения таблицы в другую файловую группу необходимо переместить кластеризованный индекс таблицы в новую файловую группу. Конечный уровень некластеризованного индекса содержит табличные данные. Таким образом, перемещение кластеризованного индекса можно сделать в одном операторе, используя предложение DROP_EXISTING следующим образом:
Шаг 3:
переместить оставшиеся некластеризованные индексы во вторичную файловую группу
вы должны переместить некластеризованные индексы вручную, используя следующий синтаксис:
перемещение кучи в другую файловую группу:
как я знаю, единственный способ переместить кучу в другую файловую группу-временно добавить кластеризованный индекс в новую файловую группу, а затем удалить его (при необходимости).
Я думаю, что эти шаги очень просты и прямо вперед, чтобы переместить любую таблицу в другую файловую группу (через Management Studio):
переместите все некластеризованные индексы в новую файловую группу, просто изменив свойство FileGroup для каждого индекса
измените индекс кластера на некластерный и измените его файловую группу просто (как на предыдущем шаге)
Добавить новый временный индекс кластера с "новый файл группа " через эту команду (или через IDE) :
(вышеуказанная команда заставляет переместить все данные в новую файловую группу)
удалить вышеуказанный временный ПК (когда он делает свою работу превосходно!)
измените свой основной индекс кластера, чтобы снова стать индексом кластера (через IDE снова)
преимущество вышеуказанных шагов-не нужно отбрасывать существующие отношения FK. Также используя IDE предотвращает потери данных в ошибка условия.
Примечание: убедитесь, что дисковая квота не включена для вашей файловой группы или установить ее ocrrectly. В противном случае вы получите исключение" файловая группа заполнена"!
Читайте также: