
Как автоматически скачивать файлы с сайта
Обновлено: 07.07.2024
Пришедшая из мира Linux, свободно распространяемая утилита Wget позволяет скачивать как отдельные файлы из интернета, так и сайты целиком, следуя по ссылкам на веб-страницах.
Чтобы получить подсказку по параметрам WGet наберите команду man wget в Linux или wget.exe --help в Windows.
Если предполагается загрузка с сайта какого-либо одного каталога (со всеми вложенными в него папками), то логичнее будет включить в командную строку параметр -np. Он не позволит утилите при поиске файлов подниматься по иерархии каталогов выше указанной директории:
Если загрузка данных была случайно прервана, то для возобновления закачки с места останова, необходимо в команду добавить ключ -с:
По умолчанию всё скаченное сохраняется в рабочей директории утилиты. Определить другое месторасположение копируемых файлов поможет параметр -P:
Наконец, если сетевые настройки вашей сети предполагают использование прокси-сервера, то его настройки необходимо сообщить программе. См. Конфигурирование WGET
Загрузка всех URL, указанных в файле FILE:
Скачивание файла в указанный каталог (-P):
Скачивание в фоновом режиме (-b):
Продолжить (-c continue) загрузку ранее не полностью загруженного файла:
luzer/my-archive/ и всех его подкаталогов, при этом не поднимаясь по иерархии каталогов выше:
Для того, чтобы во всех скачанных страницах ссылки преобразовывались в относительные для локального просмотра, необходимо использовать ключ -k:
Также поддерживается идентификация на сервере:
Скопировать весь сайт целиком:
Например, не загружать zip-архивы:
Залогиниться и скачать файлик ключа
Внимание! Регистр параметров WGet различен!
Базовые ключи запуска
-V
--version
Отображает версию Wget.
-h
--help
Выводит помощь с описанием всех ключей командной строки Wget.
-b
--background
Переход в фоновый режим сразу после запуска. Если выходной файл не задан -o, выход перенаправляется в wget-log.
-e command
--execute command
Выполнить command, как если бы она была частью файла .wgetrc. Команда, запущенная таким образом, будет выполнена после команд в .wgetrc, получая приоритет над ними. Для задания более чем одной команды wgetrc используйте несколько ключей -e.
Протоколирование и ключи входного файла
-a logfile
--append-output=logfile
Дописывать в logfile. То же, что -o, только logfile не перезаписывается, а дописывается. Если logfile не существует, будет создан новый файл.
-d
--debug
Включает вывод отладочной информации, т.е. различной информации, полезной для разработчиков Wget при некорректной работе. Системный администратор мог выбрать сборку Wget без поддержки отладки, в этом случае -d работать не будет. Помните, что сборка с поддержкой отладки всегда безопасна - Wget не будет выводить отладочной информации, пока она явно не затребована через -d.
-q
--quiet
Выключает вывод Wget.
-v
--verbose
Включает подробный вывод со всей возможной информацией. Задано по умолчанию.
-i file
--input-file=file
Читать URL из входного файла file, в этом случае URL не обязательно указывать в командной строке. Если адреса URL указаны в командной строке и во входном файле, первыми будут запрошены адреса из командной строки. Файл не должен (но может) быть документом HTML - достаточно последовательного списка адресов URL. Однако, при указании --force-html входной файл будет считаться html. В этом случае могут возникнуть проблемы с относительными ссылками, которые можно решить указанием <base href="url"> внутри входного файла или --base=url в командной строке.
-F
--force-html
При чтении списка адресов из файла устанавливает формат файла как HTML. Это позволяет организовать закачку по относительным ссылкам в локальном HTML-файле при указании <base href="url"> внутри входного файла или --base=url в командной строке.
-B URL
--base=URL
Используется совместно c -F для добавления URL к началу относительных ссылок во входном файле, заданном через -i.
Ключи скачивания
--bind-address=ADDRESS
При открытии клиентских TCP/IP соединений bind() на ADDRESS локальной машины. ADDRESS может указываться в виде имени хоста или IP-адреса. Этот ключ может быть полезен, если машине выделено несколько адресов IP.
-t number
--tries=number
Устанавливает количество попыток в number. Задание 0 или inf соответствует бесконечному числу попыток. По умолчанию равно 20, за исключением критических ошибок типа "в соединении отказано" или "файл не найден" (404), при которых попытки не возобновляются.
-O file
--output-document=file
Документы сохраняются не в соответствующие файлы, а конкатенируются в файл с именем file. Если file уже существует, то он будет перезаписан. Если в качестве file задано -, документы будут выведены в стандартный вывод (отменяя -k). Помните, что комбинация с -k нормально определена только для скачивания одного документа.
-nc
--no-clobber
Если файл скачивается более одного раза в один и тот же каталог, то поведение Wget определяется несколькими ключами, включая -nc. В некоторых случаях локальный файл будет затёрт или перезаписан при повторном скачивании, в других - сохранён.
При запуске Wget без -N, -nc или -r скачивание того же файла в тот же каталог приводит к тому, что исходная копия файла сохраняется, а новая копия записывается с именем file.1. Если файл скачивается вновь, то третья копия будет названа file.2 и т.д. Если указан ключ -nc, такое поведение подавляется, Wget откажется скачивать новые копии файла. Таким образом, "no-clobber" неверное употребление термина в данном режиме - предотвращается не затирание файлов (цифровые суффиксы уже предотвращали затирание), а создание множественных копий.
При запуске Wget с ключом -r, но без -N или -nc, перезакачка файла приводит к перезаписыванию на место старого. Добавление -nc предотвращает такое поведение, сохраняя исходные версии файлов и игнорируя любые новые версии на сервере.
При запуске Wget с ключом -N, с или без -r, решение о скачивании новой версии файла зависит от локальной и удалённой временных отметок и размера файла. -nc не может быть указан вместе с -N.
При указании -nc файлы с расширениями .html и .htm будут загружаться с локального диска и обрабатываться так, как если бы они были скачаны из сети.
-c
--continue
Продолжение закачки частично скачанного файла. Это полезно при необходимости завершить закачку, начатую другим процессом Wget или другой программой. Например:
Если в текущем каталоге имеется файл ls-lR.Z, то Wget будет считать его первой частью удалённого файла и запросит сервер о продолжении закачки с отступом от начала, равному длине локального файла.
Нет необходимости указывать этот ключ, чтобы текущий процесс Wget продолжил закачку при пи потере связи на полпути. Это изначальное поведение. -c влияет только на закачки, начатые до текущего процесса Wget, если локальные файлы уже существуют.
Без -c предыдущий пример сохранит удалённый файл в ls-lR.Z.1, оставив ls-lR.Z без изменения.
Начиная с версии Wget 1.7, при использовании -c с непустым файлом, Wget откажется начинать закачку сначала, если сервер не поддерживает закачку, т.к. это привело бы к потере скачанных данных. Удалите файл, если вы хотите начать закачку заново.
С другой стороны, при использовании -c локальный файл будет считаться недокачанным, если длина удалённого файла больше длины локального. В этом случае (длина(удалённая) - длина(локальная)) байт будет скачано и приклеено в конец локального файла. Это ожидаемое поведение в некоторых случаях: например, можно использовать -c для скачивания новой порции собранных данных или лог-файла.
Однако, если файл на сервере был изменён, а не просто дописан, то вы получите испорченный файл. Wget не обладает механизмами проверки, является ли локальный файл начальной частью удалённого файла. Следует быть особенно внимательным при использовании -c совместно с -r, т.к. каждый файл будет считаться недокачанным.
Испорченный файл также можно получить при использовании -c с кривым HTTP прокси, который добавляет строку тима "закачка прервана". В будущих версиях возможно добавление ключа "откат" для исправления таких случаев.
--progress=type
Выбор типа индикатора хода закачки. Возможные значения: "dot" и "bar".
Индикатор типа "bar" используется по умолчанию. Он отображает ASCII полосу хода загрузки (т.н. "термометр"). Если вывод не в TTY, то по умолчанию используется индикатор типа "dot".
Для переключения в режим "dot" укажите --progress=dot. Ход закачки отслеживается и выводится на экран в виде точек, где каждая точка представляет фиксированный размер скачанных данных.
При точечной закачке можно изменить стиль вывода, указав dot:style. Различные стили определяют различное значение для одной точки. По умолчанию одна точка представляет 1K, 10 точек образуют кластер, 50 точек в строке. Стиль binary является более "компьютер"-ориентированным - 8K на точку, 16 точек на кластер и 48 точек на строку (384K в строке). Стиль mega наиболее подходит для скачивания очень больших файлов - каждой точке соответствует 64K, 8 точек на кластер и 48 точек в строке (строка соответствует 3M).
Стиль по умолчанию можно задать через .wgetrc. Эта установка может быть переопределена в командной строке. Исключением является приоритет "dot" над "bar", если вывод не в TTY. Для непременного использования bar укажите --progress=bar:force.
-N
--timestamping
Включает использование временных отметок.
--spider
При запуске с этим ключом Wget ведёт себя как сетевой паук, он не скачивает страницы, а лишь проверяет их наличие. Например, с помощью Wget можно проверить закладки:
Эта функция требует большой доработки, чтобы Wget достиг функциональности реальных сетевых пауков.
-T seconds
--timeout=seconds
Устанавливает сетевое время ожидания в seconds секунд. Эквивалентно одновременному указанию --dns-timeout, --connect-timeout и --read-timeout.
Когда Wget соединяется или читает с удалённого хоста, он проверяет время ожидания и прерывает операцию при его истечении. Это предотвращает возникновение аномалий, таких как повисшее чтение или бесконечные попытки соединения. Единственное время ожидания, установленное по умолчанию, - это время ожидания чтения в 900 секунд. Установка времени ожидания в 0 отменяет проверки.
Если вы не знаете точно, что вы делаете, лучше не устанавливать никаких значений для ключей времени ожидания.
--dns-timeout=seconds
Устанавливает время ожидания для запросов DNS в seconds секунд. Незавершённые в указанное время запросы DNS будут неуспешны. По умолчанию никакое время ожидания для запросов DNS не устанавливается, кроме значений, определённых системными библиотеками.
--connect-timeout=seconds
Устанавливает время ожидания соединения в seconds секунд. TCP соединения, требующие большего времени на установку, будут отменены. По умолчанию никакое время ожидания соединения не устанавливается, кроме значений, определённых системными библиотеками.
--read-timeout=seconds
Устанавливает время ожидания чтения (и записи) в seconds секунд. Чтение, требующее большего времени, будет неуспешным. Значение по умолчанию равно 900 секунд.
--limit-rate=amount
Устанавливает ограничение скорости скачивания в amount байт в секунду. Значение может быть выражено в байтах, килобайтах с суффиксом k или мегабайтах с суффиксом m. Например, --limit-rate=20k установит ограничение скорости скачивания в 20KB/s. Такое ограничение полезно, если по какой-либо причине вы не хотите, чтобы Wget не утилизировал всю доступную полосу пропускания. Wget реализует ограничение через sleep на необходимое время после сетевого чтения, которое заняло меньше времени, чем указанное в ограничении. В итоге такая стратегия приводит к замедлению скорости TCP передачи приблизительно до указанного ограничения. Однако, для установления баланса требуется определённое время, поэтому не удивляйтесь, если ограничение будет плохо работать для небольших файлов.
-w seconds
--wait=seconds
Ждать указанное количество seconds секунд между закачками. Использование этой функции рекомендуется для снижения нагрузки на сервер уменьшением частоты запросов. Вместо секунд время может быть указано в минутах с суффиксом m, в часах с суффиксом h или днях с суффиксом d.
Указание большого значения полезно, если сеть или хост назначения недоступны, так чтобы Wget ждал достаточное время для исправления неполадок сети до следующей попытки.
--waitretry=seconds
Если вы не хотите, чтобы Wget ждал между различными закачками, а только между попытками для сорванных закачек, можно использовать этот ключ. Wget будет линейно наращивать паузу, ожидая 1 секунду после первого сбоя для данного файла, 2 секунды после второго сбоя и так далее до максимального значения seconds. Таким образом, значение 10 заставит Wget ждать до (1 + 2 + . + 10) = 55 секунд на файл. Этот ключ включён по умолчанию в глобальном файле wgetrc.
--random-wait
Некоторые веб-сайты могут анализировать логи для идентификации качалок, таких как Wget, изучая статистические похожести в паузах между запросами. Данный ключ устанавливает случайные паузы в диапазоне от 0 до 2 * wait секунд, где значение wait указывается ключом --wait. Это позволяет исключить Wget из такого анализа. В недавней статье на тему разработки популярных пользовательских платформ был представлен код, позволяющий проводить такой анализ на лету. Автор предлагал блокирование подсетей класса C для блокирования программ автоматического скачивания, несмотря на возможную смену адреса, назначенного DHCP. На создание ключа --random-wait подвигла эта больная рекомендация блокировать множество невиновных пользователей по вине одного.
-Y on/off
--proxy=on/off
Включает или выключает поддержку прокси. Если соответствующая переменная окружения установлена, то поддержка прокси включена по умолчанию.
Ключи каталогов
-nd
--no-directories
Не создавать структуру каталогов при рекурсивном скачивании. С этим ключом все файлы сохраняются в текущий каталог без затирания (если имя встречается больше одного раза, имена получат суффикс .n).
Если вам нужно лишь избавиться от структуры каталогов, то этот ключ может быть заменён комбинацией -nd и -P. Однако, в отличии от -nd, --cut-dirs не теряет подкаталоги - например, с -nH --cut-dirs=1, подкаталог beta/ будет сохранён как xxx/beta, как и ожидается.
-P prefix
--directory-prefix=prefix
Устанавливает корневой каталог в prefix. Корневой каталог - это каталог, куда будут сохранены все файлы и подкаталоги, т.е. вершина скачиваемого дерева. По умолчанию . (текущий каталог).
--no-cache
Отключает кеширование на стороне сервера. В этой ситуации Wget посылает удалённому серверу соответствующую директиву (Pragma: no-cache) для получения обновлённой, а не кешированной версии файла. Это особенно полезно для стирания устаревших документов на прокси серверах. Кеширование разрешено по умолчанию.
/.mozilla в директории вашего профиля. Полный путь обычно выглядит как
--header=additional-header
Укажите дополнительный заголовок additional-header для передачи HTTP серверу. Заголовки должны содержать ":" после одного или более непустых символов и недолжны содержать перевода строки. Вы можете указать несколько дополнительных заголовков, используя ключ --header многократно.
Указание в качестве заголовка пустой строки очищает все ранее указанные пользовательские заголовки.
--referer=url
Включает в запрос заголовок `Referer: url'. Полезен, если при выдаче документа сервер считает, что общается с интерактивным обозревателем, и проверяет, чтобы поле Referer содержало страницу, указывающую на запрашиваемый документ.
Все мы иногда качаем файлы из интернета. Если для этого использовать программы с графическим интерфейсом, то всё оказывается предельно просто. Однако, при работе в командной строке Linux дело несколько усложняется. Особенно — для тех, кто не знаком с подходящими инструментами. Один из таких инструментов — чрезвычайно мощная утилита wget, которая подходит для выполнения всех видов загрузок. Предлагаем вашему вниманию двенадцать примеров, разобрав которые, можно освоить основные возможности wget.

1. Загрузка одного файла
Если всё, что нужно — это загрузка одного файла, нам подойдёт следующая конструкция:
После ввода такой команды начнётся скачивание Nagios Core. В ходе этого процесса можно будет видеть данные о загрузке, например — сведения о том, какой объём данных уже загружен, текущую скорость, и то, сколько времени осталось до конца загрузки.
2. Загрузка файла и сохранение его с новым именем
Если мы хотим сохранить загруженный файл под именем, отличающимся от его исходного имени, нам пригодится команда wget с параметром -O :
При таком подходе загруженный файл будет сохранён под именем nagios_latest .
3. Ограничение скорости загрузки файлов
При необходимости скорость загрузки файлов с помощью wget можно ограничить. В результате эта операция не будет занимать весь доступный канал передачи данных и не повлияет на другие процессы, связанные с сетью. Сделать это можно, используя параметр --limit-rate и указав ограничение скорости, выраженное в байтах (в виде обычного числа), килобайтах (добавив после числа K ) или мегабайтах ( M ) в секунду:
Здесь задано ограничение скорости загрузки, равное 500 Кб/с.
4. Завершение прерванной загрузки
Если в ходе загрузки файлов эта операция была прервана, можно возобновить загрузку с помощью параметра -c команды wget :
Если этот параметр не использовать, то загрузка недокачанного файла начнётся сначала.
5. Фоновая загрузка файла
Если вы загружаете файл огромного размера и хотите выполнять эту операцию в фоне, сделать это можно, используя параметр -b :
6. Загрузка нескольких файлов
Если имеется список URL файлов, которые надо загрузить, но вам не хочется вручную запускать загрузки этих файлов, можно использовать параметр -I . Однако, перед тем, как начинать загрузку, нужно создать файл, содержащий все адреса. Например, сделать это можно такой командой:
В этот файл нужно поместить адреса — по одному в каждой строке. Далее, осталось лишь запустить wget , передав этой утилите только что созданный файл со списком загрузок:
Выполнение этой команды приведёт к поочерёдной загрузке всех файлов из списка.
7. Увеличение общего числа попыток загрузки файла
Для того, чтобы настроить число повторных попыток загрузки файла, можно использовать параметр --tries :
8. Загрузка файлов с FTP-сервера
Команда загрузки файла с анонимного FTP-сервера с помощью wget выглядит так:
Если для доступа к файлу требуются имя пользователя и пароль, то команда примет такой вид:
9. Создание локальной копии веб-сайта
Если нужно загрузить содержимое целого веб-сайта, сделать это можно, воспользовавшись параметром --mirror :
Обратите внимание на дополнительные параметры командной строки:
- -p : производится загрузка всех файлов, необходимых для корректного отображения HTML-страниц.
- --convert-links : ссылки в документах будут преобразованы для целей локального просмотра сайта.
- -P /home/dan : материалы будут сохранены в папку /home/dan .
10. Загрузка с сайта только файлов определённого типа
Для того, чтобы загрузить с сайта только файлы определённого типа, можно воспользоваться параметрами -r -A :
11. Пропуск файлов определённого типа
Если вы хотите скопировать целый веб-сайт, но при этом вам не нужны файлы определённого типа, отключить их загрузку можно с помощью параметра --reject :
12. Загрузка с использованием собственного .log-файла
Для того, чтобы загрузить файл и использовать при этом собственный .log -файл, воспользуйтесь параметром -o и укажите имя файла журнала:
Итоги
Wget — довольно простая в использовании, но весьма полезная утилита Linux. И, на самом деле то, о чём мы рассказали — лишь малая часть того, что она умеет. Надеемся, этот обзор поможет тем, кто не был знаком с wget, оценить эту программу, и, возможно, включить её в свой повседневный арсенал инструментов командной строки.
Буду писать на примере того, как это можно применить к парсеру Датакол. Например, по техническим причинам, Вы не смогли скачать файлы или Вы не хотите грузить парсинг скачкой файлов, Вы просто собрали данные, а возможно просто забыли, что нужно скачать и потом опомнились).
Что нужно для начала?
Сохраняйте его в текстовый файл, который назовем, к примеру "url-list.txt".
Далее нам понадобится утилита WGET, думаю некоторые из Вас уже слышали о ней.
Подготовка к работе
Далее, просто распаковывайте архив в любую папку, например, c:\wget
Эта утилита консольная, у нее нет графического интерфейса, поэтому, чтобы запускать её из командной строки из любого места, нужно прописать в свойствах системы путь к папке:
Если Вам кажется это слишком сложным и Вам это нужно на один раз, то можете не делать, а сразу приступить к следующим действиям.
Собираем все и начинаем
Итак, приступим, имеем следующие исходные данные:
- Файл со списком URL к файлам, предположим, что он у нас в корне диска С - c:\url-list.txt
- Создаем папку, куда будем скачивать файлы, предположим c:\files\
- Распаковали файлы с архива утилиты в папку c:\wget\
Когда эти 3 пункта готовы, открываем консоль. Для этого нажимаем комбинацию Win + R и вводим cmd и нажимаем enter
Сразу напишу готовую команду, а ниже расскажу, что к чему:
Если Вы не прописывали путь в свойствах системы, по моей инструкции выше, то для старта wget Вам нужно указать полный путь к ней, т.е
c:\wget\wget.exe вместо wget и команда для Вас будет выглядеть так
Теперь разбираем переменные:
Кому интересны все команды, а их ОЧЕНЬ много, то просто набираем в консоли
wget -h или c:\wget\wget.exe -h
Если Вам важна структура сохранения файлов как на источнике, то добавьте команду -x.
После того, как команда прописана, нажимаете enter и пойдет загрузка в указанную папку. На экране Вы будете видеть ЛОГ операций.
P.S строку для запуска лучше не писать в консоли, а приготовить ее заранее в любом редакторе, хоть в блокноте. Затем копируйте ее и в консоли нажимайте просто правую кнопку мыши или комбинацию Shift + Insert или Ctrl + V (эта комбинация раньше в консоли Windows не работала, сейчас на Win 10 работает, может работает и в ранних версиях, не знаю, когда добавили эту поддержку)
P.S чтобы собирать данные с серьезных порталов, однозначно нужны платные прокси.
Хорошие прокси от 33р за шт можно купить тут
И напоминаю, что по моей партнерской ссылке Вы получите 20% скидки на любой тариф, при покупке Датакол. Например, годовая лицензия будет стоить 6070руб. вместо 7590р .
Менеджеры закачки (часто называемые и менеджерами загрузки) значительно облегчают процесс скачивания файлов с серверов в интернете на локальный компьютер. Пользователь, посещая различные сайты, может добавить в менеджер ссылки на файлы, которые он хотел бы скачать и запустить их закачку после того, как сёрфинг закончен. Таким образом, закачка файлов при помощи менеджера может быть выполнена в то время, когда пользователь не работает в интернете. Многие менеджеры закачки позволяют указать время, когда необходимо скачать файлы, что бывает удобно при использовании диал-ап доступа в интернет: список файлов для закачки можно сформировать днём и запланировать закачку на ночное время, когда действует более дешёвый тариф на услуги доступа в сеть. В этом случае, менеджер сам дозвонится до провайдера, скачает файлы и выключит компьютер. Помимо этого, менеджеры могут докачивать файлы, то есть, если закачка была прервана и файл не был скачан полностью, то менеджер после повторного соединения с сервером продолжит скачивание файла с того места, где была прервана закачка, а не будет скачивать весь файл заново. На этом список возможностей менеджеров закачки не заканчивается, они могут интегрироваться с браузером, автоматически снижать скорость закачки, когда пользователь работает в интернете, хранить учётные данные для доступа к определённым серверам и так далее.
В этом путеводителе собраны краткие описания самых распространённых менеджеров и даны ссылки на сайты производителей.
К оглавлению Download Accelerator Plus
К оглавлению Free Download Manager
- Автоматический поиск зеркал (других серверов, откуда можно скачать файл).
- Автоматический запуск установки скачанного программного обеспечения.
- Категории файлов (возможность сохранить файлы разных типов в разных папках).
- Поиск файлов в интернете.
- Поиск ссылки на файл, если была добавлена в очередь битая ссылка или запрашиваемый файл был удалён на сервере.
- Интеграция в браузеры. Интеграция в плеер (в избранном автоматически появляются ссылки на скачанные аудио и видео файлы).
- Разархивация ZIP-архивов.
- Скачивание всех файлов со страницы.
- Планировщик закачек.
К оглавлению Internet Download Manager
- Работа через прокси-серверы, поддержка Basic, Negotiate, NTLM и Keberos аутентификации.
- Скачивание всех файлов со страницы.
- Категории файлов.
- Планировщик закачек.
- Автоматическая проверка на вирусы скачанных файлов.
- Интеграция в браузеры.


БЕЗ скриптов, макросов, регулярных выражений и командной строки.
Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что те могут скоро исчезнуть, а также менеджерам, собирающим базы контактов для рассылок.
Есть три основные цели извлечения/сохранения данных с сайта на свой компьютер:
- Чтобы не пропали;
- Чтобы использовать чужие картинки, видео, музыку, книги в своих проектах (от школьной презентации до полноценного веб-сайта);
- Чтобы искать на сайте информацию средствами Spotlight, когда Google не справляется (к примеру поиск изображений по exif-данным или музыки по исполнителю).
Ситуации, когда неожиданно понадобится автоматизированно сохранить какую-ту информацию с сайта, могут случиться с каждым и надо быть к ним готовым. Если вы умеете писать скрипты для работы с утилитами wget/curl, то можете смело закрывать эту статью. А если нет, то сейчас вы узнаете о самых простых приемах сохранения/извлечения данных с сайтов.
1. Скачиваем сайт целиком для просмотра оффлайн
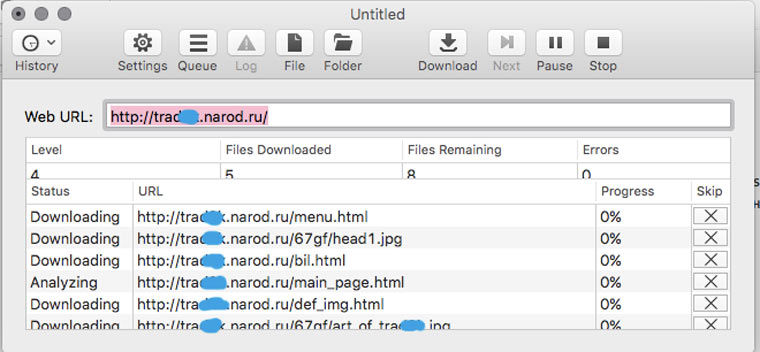
В OS X это можно сделать с помощью приложения HTTrack Website Copier, которая настраивается схожим образом.
Пользоваться Site Sucker очень просто. Открываем программу, выбираем пункт меню File -> New, указываем URL сайта, нажимаем кнопку Download и дожидаемся окончания скачивания.
2. Прикидываем сколько на сайте страниц
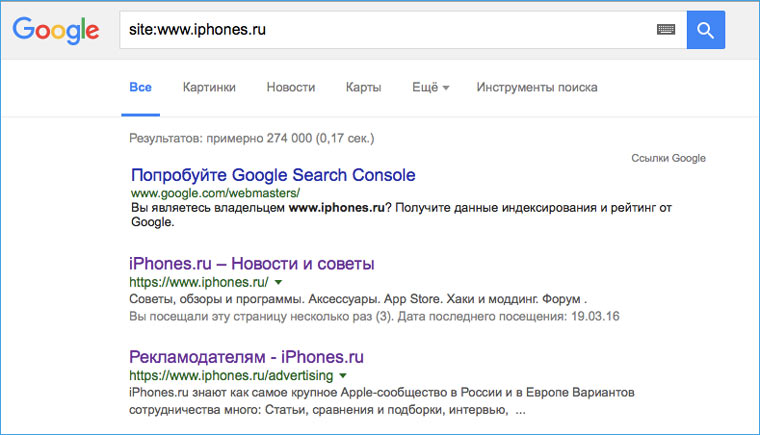
Перед тем как браться за скачивание сайта, необходимо приблизительно оценить его размер (не затянется ли процесс на долгие часы). Это можно сделать с помощью Google. Открываем поисковик и набираем команду site: адрес искомого сайта. После этого нам будет известно количество проиндексированных страниц. Эта цифра не соответствуют точному количеству страниц сайта, но она указывает на его порядок (сотни? тысячи? сотни тысяч?).
3. Устанавливаем ограничения на скачивание страниц сайта
![]()
Если вы обнаружили, что на сайте тысячи страниц, то можно ограничить число уровней глубины скачивания. К примеру, скачивать только те страницы, на которые есть ссылка с главной (уровень 2). Также можно ограничить размер загружаемых файлов, на случай, если владелец хранит на своем ресурсе tiff-файлы по 200 Мб и дистрибутивы Linux (и такое случается).
Сделать это можно в Settings -> Limits.
4. Скачиваем с сайта файлы определенного типа
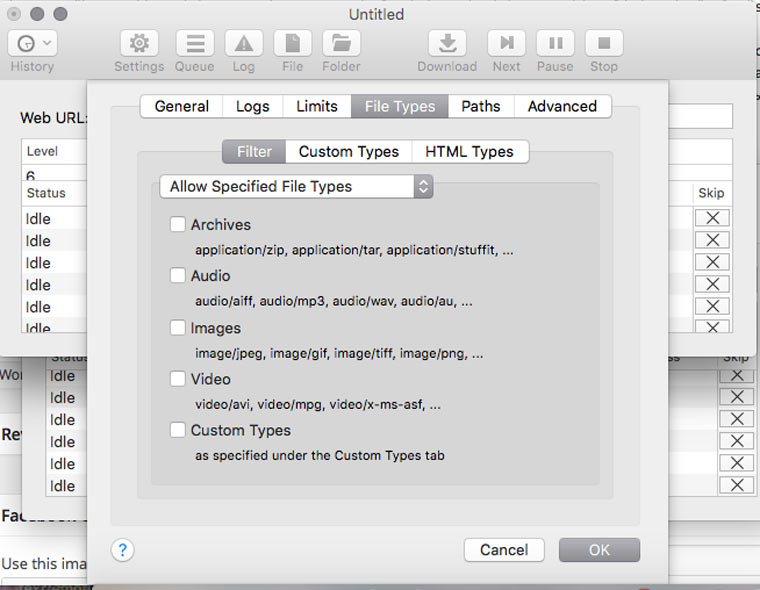
В Settings -> File Types -> Filters можно указать какие типы файлов разрешено скачивать, либо какие типы файлов запрещено скачивать (Allow Specified Filetypes/Disallow Specifies Filetypes). Таким образом можно извлечь все картинки с сайта (либо наоборот игнорировать их, чтобы места на диске не занимали), а также видео, аудио, архивы и десятки других типов файлов (они доступны в блоке Custom Types) от документов MS Word до скриптов на Perl.
5. Скачиваем только определенные папки
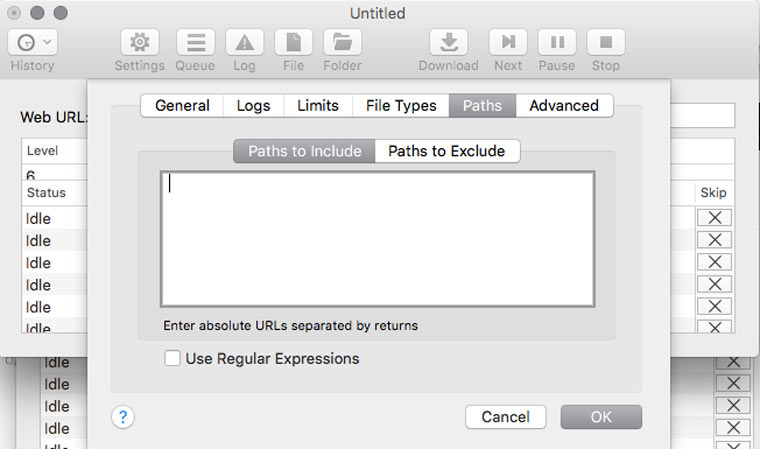
Если на сайте есть книги, чертежи, карты и прочие уникальные и полезные материалы, то они, как правило, лежат в отдельном каталоге (его можно отследить через адресную строку браузера) и можно настроить SiteSucker так, чтобы скачивать только его. Это делается в Settings -> Paths -> Paths to Include. А если вы хотите наоборот, запретить скачивание каких-то папок, то их адреса надо указать в блоке Paths to Exclude
6. Решаем вопрос с кодировкой
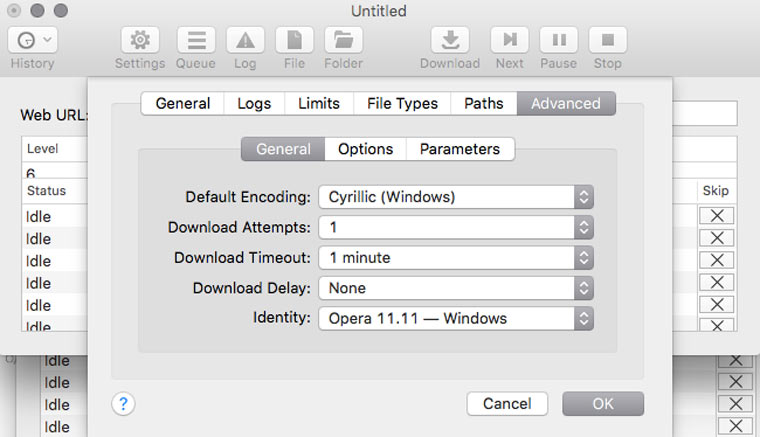
Если вы обнаружили, что скачанные страницы вместо текста содержат кракозябры, там можно попробовать решить эту проблему, поменяв кодировку в Settings -> Advanced -> General. Если неполадки возникли с русским сайтом, то скорее всего нужно указать кодировку Cyrillic Windows. Если это не сработает, то попробуйте найти искомую кодировку с помощью декодера Лебедева (в него надо вставлять текст с отображающихся криво веб-страниц).
7. Делаем снимок веб-страницы
Это может пригодиться для сравнения разных версий дизайна сайта, запечатления на память длинных эпичных перепалок в комментариях или в качестве альтернативы способу сохранения сайтов, описанного в предыдущих шести пунктах.
8. Сохраняем картинки только с определенной страницы
9. Извлекаем HEX-коды цветов с веб-сайта
10. Извлекаем из текста адреса электронной почты
11. Извлекаем из текста номера телефонов
А если надо отфильтровать в тексте заголовки, даты и прочую информацию, то к вам на помощь придут регулярные выражения и Sublime Text.
(2 голосов, общий рейтинг: 4.50 из 5)
Читайте также: