
Как кодируется текст в памяти компьютера по информатике 7
Обновлено: 07.07.2024
Сайт учителя информатики. Технологические карты уроков, Подготовка к ОГЭ и ЕГЭ, полезный материал и многое другое.
Информатика. 10 класса. Босова Л.Л. Оглавление
§14. Кодирование текстовой информации
Компьютеры третьего поколения «научились» работать с текстовой информацией.
Текстовая информация по своей природе дискретна, т. к. представляется последовательностью отдельных символов.
Для компьютерного представления текстовой информации достаточно:
1) определить множество всех символов (алфавит), требуемых для представления текстовой информации;
2) выстроить все символы используемого алфавита в некоторой последовательности (присвоить каждому символу алфавита свой номер);
3) получить для каждого символа n-разрядный двоичный код (n ≤ 2 n ), переведя номер этого символа в двоичную систему счисления.
В памяти компьютера хранятся специальные кодовые таблицы, в которых для каждого символа указан его двоичный код. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
14.1. Кодировка ASCII и её расширения
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.). Этот код 7-битовый: общее количество символов составляет 2 7 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII

Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10). В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251

Таблица 3.10
Кодировка КОИ-8

Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах. Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов. Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
14.2. Стандарт Unicode
В Unicode на кодирование символов отводится 31 бит. Первые 128 символов (коды 0-127) совпадают с таблицей ASCII. Далее размещены основные алфавиты современных языков: они полностью умещаются в первой части таблицы, их коды не превосходят 65 536 = 2 16 .
Стандарт Unicode описывает алфавиты всех известных, в том числе и «мёртвых», языков. Для языков, имеющих несколько алфавитов или вариантов написания (например, японского и индийского), закодированы все варианты. В кодировку Unicode внесены все математические и иные научные символьные обозначения и даже некоторые придуманные языки (например, язык эльфов из трилогии Дж. Р. Р. Толкина «Властелин колец»).
Всего современная версия Unicode позволяет закодировать более миллиона различных знаков, но реально используется чуть менее 110 000 кодовых позиций.
Для представления символов в памяти компьютера в стандарте Unicode имеется несколько кодировок.
В операционных системах семейства Windows используется кодировка UTF-16. В ней все наиболее важные символы кодируются с помощью 2 байт (16 бит), а редко используемые — с помощью 4 байт.
В операционной системе Linux применяется кодировка UTF-8, в которой символы могут занимать от 1 (символы, входящие в таблицу ASCII) до 4 байт. Если значительную часть текста составляют цифры и латинские буквы, то это позволяет в несколько раз уменьшить размер файла по сравнению с кодировкой UTF-16.
Кодировки Unicode позволяют включать в один документ символы самых разных языков, но их использование ведёт к увеличению размеров текстовых файлов.
Мы уже касались этого вопроса, рассматривая алфавитный подход к измерению информации.
Оценим в байтах объём текстовой информации в современном словаре иностранных слов из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы).
Будем считать, что при записи используется кодировка «один символ — один байт». Количество символов во всем словаре равно:
80 • 60 • 740 = 3 552 000.
Следовательно, объём равен
3 552 000 байт = 3 468,75 Кбайт ≈ 3,39 Мбайт.
Если же использовать кодировку UTF-16, то объём этой же текстовой информации в байтах возрастёт в 2 раза и составит 6,78 Мбайт.
САМОЕ ГЛАВНОЕ
Текстовая информация по своей природе дискретна, т. к. представляется последовательностью отдельных символов.
В памяти компьютера хранятся специальные кодовые таблицы, в которых для каждого символа указан его двоичный код. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode (Юникод), позволяющий использовать в текстах любые символы любых языков мира. Кодировки Unicode позволяют включать в один документ символы самых разных языков, но их использование ведёт к увеличению размеров текстовых файлов.
Вопросы и задания
1. Какова основная идея представления текстовой информации в компьютере?
2. Что представляет собой кодировка ASCII? Сколько символов она включает? Какие это символы?
3. Как известно, кодовые таблицы каждому символу алфавита ставят в соответствие его двоичный код. Как, в таком случае, вы можете объяснить вид таблицы 3.8 «Кодировка ASCII»?
4. С помощью таблицы 3.8:
5. Что представляют собой расширения ASCII-кодировки? Назовите основные расширения ASCII-кодировки, содержащие русские буквы.
6. Сравните подходы к расположению русских букв в кодировках Windows-1251 и КОИ-8.
7. Представьте в кодировке Windows-1251 текст «Знание — сила!»:
1) шестнадцатеричным кодом;
2) двоичным кодом;
3) десятичным кодом.
8. Представьте в кодировке КОИ-8 текст «Дело в шляпе!»:
1) шестнадцатеричным кодом;
2) двоичным кодом;
3) десятичным кодом.
9. Что является содержимым файла, созданного в современном текстовом процессоре?
10. В кодировке Unicode на каждый символ отводится 2 байта. Определите в этой кодировке информационный объём следующей строки:
Где родился, там и сгодился.
11. Набранный на компьютере текст содержит 2 страницы. На каждой странице 32 строки, в каждой строке 64 символа. Определите информационный объём текста в кодировке Unicode, в которой каждый символ кодируется 16 битами.
13. В текстовом процессоре MS Word откройте таблицу символов (вкладка Вставка ⇒ Символ ⇒ Другие символы):


В поле Шрифт установите Times New Roman, в поле из — кириллица (дес.).
Кодирование текстовой информации — очень распространенное явление. Один и тот же текст может быть закодирован в нескольких форматах. Принято считать, что кодирование текстовой информации появилось с приходом компьютеров. Это и так и не так одновременно. Кодировка в том виде, в котором мы ее знаем, действительно к нам пришла с приходом компьютеров. Но над самим процессом кодирования люди бьются уже много сотен лет. Ведь, по большому счету, сама письменность уже является способом закодировать человеческую речь, для ее дальнейшего использования. Вот и получается, что любая окружающая нас информация никогда не бывает представленной в чистом виде, потому что она уже каким-то образом закодирована. Но сейчас не об этом.
Кодирование текстовой информации
Самый распространенный способ кодирования текстовой информации — это ее двоичное представление, которое сплошь и рядом используется в каждом компьютере, роботе, станке и т. д. Все кодируется в виде слов в двоичном представлении.
Сама технология двоичного представления информации зародилась еще задолго до появления первых компьютеров. Среди первых устройств, которые использовали двоичный метод кодирования, был аппарат Бодо — телеграфный аппарат, который кодировал информацию в 5 битах в двоичном представлении. Суть кодировки заключалась в простой последовательности электрических импульсов:
- 0 — импульс отсутствует;
- 1 — импульс присутствует.
В компьютерный мир такая кодировка пришла вместе с персонализацией самих компьютеров. То есть в первых компьютерах не было такой кодировки. Но как только компьютеры стали уходить «в массы», то резко обнаружилась потребность обрабатывать компьютерами большое количество именно текстовой информации, которую нужно было как-то кодировать. Тенденция обрабатывать большое количество текстовой информации сохранилась и в современных устройствах.
Так получилось, что двоичное кодирование в компьютерах связано только с двумя символами «0» и «1», которые выстраиваются в определенной логической последовательности. А сам язык подобной кодировки стал называться машинным.
Кодирование текстовой информации и компьютеры
Если смотреть на текст глазами компьютера, то в тексте нет предложений, абзацев, заголовков и т. д., потому что весь текст просто состоит из отдельных символов. Причем символами будут являться не только буквы, но и цифры, и любые другие специальные знаки (+, -,*,= и т. д.). Что самое интересное, даже пробелы, перенос строки и табуляция — для компьютера это тоже отдельные символы.
Для справки. Есть уникальный язык программирования, который в качестве своих операторов использует только пробелы, табуляции и переносы строки. Практического применения этот язык не имеет, но он есть.
Кодирование текстовой информации в компьютерных устройствах сводится к тому, что каждому отдельному символу присваивается уникальное десятичное значение от 0 и до 255 или его эквивалент в двоичной форме от 00000000 и до 11111111. Люди могут различать символы по их внешнему виду, а компьютерное устройство только по их уникальному коду.
Рассмотрите, как происходит процесс. Мы нажимаем нужный нам символ на клавиатуре, ориентируясь на их внешний вид. В оперативную память компьютера он попадает в двоичном представлении, а когда компьютер его выводит нам на экран, то происходит процесс декодирования, чтобы мы увидели знакомый нам символ.

Кодирование текстовой информации и таблицы кодировок
Таблица кодировки — это место, где прописано какому символу какой код относится. Все таблицы кодировки являются согласованными — это нужно, чтобы не возникало путаницы между документами, закодированными по одной таблице, но на разных устройствах.
На сегодняшний день существует множество таблиц кодировок. Из-за этого часто возникают проблемы с переносом текстовых документов между устройствами. Так получается, что если текстовая информация была закодирована по одной какой-то таблице, то и раскодирована она может быть только по этой таблице. Если попытаться раскодировать другой таблицей, то в результате получим только набор непонятных символов, но никак не читабельный текст.
В чем преимущества компьютера при работе с текстом? 1 - создавать тексты не тратя на это бумаги. 2 - компактное размещение текста на магнитном носителе (текст книги в 500 страниц размещается на дискету). 3 - если текст становится ненужным то дискету можно очистить и записать заново. 4 - можно копировать файлы с текстом в любых количествах. 5 - можно быстро переслать текст по электронной почте. 6 - экономя бумагу мы сохраним леса на нашей планете.
В чем заключается главное неудобство хранения текстов в дисковых файлах? Прочитать их можно только с помощью компьютера.
Что такое гипертекст? Это способ организации текстовой информации, внутри которой установлены смысловые связи между ее различными фрагментами. пример
Информатика Программа Программное обеспечение
Это наука, изучающая все аспекты получения, хранения, преобразования, передачи и использования информации.
Это указание на последовательность действий (команд), которую должен выполнить компьютер, чтобы решить поставленную задачу обработки информации.
Это вся совокупность программ, хранящихся в его долговременной памяти.
Как закодирован текст в памяти компьютера? 1. в компьютерном алфавите 256 символов. 2. один символ такого алфавита несет 8 бит информации: 2 8 = 256. 8 бит = 1 байт. 3. двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти. 4. все символы компьютерного алфавита пронумерованы от 0 до 255. 5. каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111.
Таблица кодировки. Имеет стандартную часть, стоящую на всех компьютерах. Стр. 72 рис. 3.1 И альтернативную часть (национальную) стр. 73 – 76.рис.3.2
Задание №1 На странице 71 зашифровано слово из 4 букв, по стандартной части кода расшифруйте его.
Задание № 2 Используя альтернативную часть кода зашифруйте загадку. Затем обменяйтесь шифровками с соседом по парте и расшифруйте загадки. Запишите ответ с помощью кодировки. Вновь обменяйтесь тетрадями и проверьте отгадку. Если все верно поставьте себе «5»
Задание №3 Расшифруйте с помощью ASCII слово 99 111 109 112 117 116 101 114 Какая последовательность десятичных кодов будет соответствовать этому же слову, записанному заглавными буквами? 67 79 77 80 85 84 69 82 Найдите закономерность
1. Все буквы стоят по алфавиту, поэтому достаточно знать код одной буквы, чтобы расшифровать слово. 2. Разница между десятичным кодом строчной латинского алфавита и десятичным кодом соответствующей заглавной буквы равна 32: 99 – 32 = 67
Задание №4 Сколько бит памяти компьютера займет слово «микропроцессор»? Решение: Слово состоит из 14 букв. Каждая буква является символом компьютерного алфавита и поэтому занимает 1 байт памяти. Слово займет 14 байт = 112 бит памяти, т.к. 1 байт = 8 бит.
Задание №5 Текст занимает 0,25 Кбайт памяти компьютера. Сколько символов содержит этот текст? Решение: 0,25 Кбайт * 1024 = 256 байт. Т.к. 1 символ = 1 байт, алфавит содержит 256 символов
Задание №6 Текст занимает полных 5 страниц. На каждой странице размещается 30 строк по 70 символов в строке. Какой объём оперативной памяти (в байтах) займёт этот текст? Решение: 30*70*5 = 10500 символов. Т.к. 1 символ = 1 байт, то весь текст занимает 10500 байт памяти.
Домашнее задание Параграф №13, вопросы после параграфа.
По теме: методические разработки, презентации и конспекты

Виды компьютерной памяти и их сравнение.
Виды компьютерной памяти и их сравнение.Свойства оперативной памяти. Презентация к уроку в 7 классе по И.Г. Семакину.

Конспект урока по информатике на тему Технология ввода текста. Редактирование текста вставка, удаление и замена символов; вставка и удаление пустых строк.
Конспект урока по информатике на тему: Технология ввода текста. Редактирование текста: вставка, удаление и замена символов; вставка и удаление пустых строк. Цель урока: научить техноло.

Презентация к уроку "Тексты в компьютерной памяти"
Презентация к уроку "Тексты в компьютерной памяти".

План-конспект урока по теме "Виды компьютерной памяти"
План-конспект урока по теме: "Виды компьютерной памяти" с применением ЭОР.

Тексты в компьютерной памяти: кодирование символов. Тестовые файлы
Тексты в компьютерной памяти: кодирование символов. Тестовые файлы.

Практическая работа № 1 по теме «Представление информации в компьютерной памяти».
Практическая работапо теме «Представление информации в компьютерной памяти» расчитана для 7 - 8 класса содержит в себе 2 вариант.
Самостоятельная работа "Тексты в компьютерной памяти"
Самостоятельная работа по информатике к параграфу "Тексты в компьютерной памяти" Семакин И.Г.

Цель урока: формирование понятий о способах представления и организации текстов в компьютерной памяти.
Задачи:
- обучающие: Знакомство со способами кодирования текстовой информации
- развивающие: развитие логического мышления учащихся, познавательного интереса, формирование информационной культуры и потребности в приобретении знаний.
- воспитательные: воспитание стремления быть прилежным и добиваться успеха, ответственности, самостоятельности.
Тип урока: Введение нового материала
Формы работы учащихся фронтальная, индивидуальная
Необходимое техническое оборудование: 7 компьютеров, мультимедиа проектор, интерактивная доска, раздаточный материал – 7 шт.
Используемые технологии: ИКТ, проблемно – ориентированные
Используемые методы: словесные, наглядно - иллюстративные
Структура и ход урока
- Мотивация.
- Здравствуйте, ребята! Я рада вас видеть всех на уроке. Посмотрели друг на друга, улыбнулись и сели. Все ли присутствуют на уроке? Хорошо.
- Давайте вспомним правила техники безопасности в компьютерном классе и правила работы на ПК.
Какие правила техники безопасности необходимо соблюдать в компьютерном классе?
К чему может привести нарушение правил техники безопасности?
Как правильно организовать свое рабочее место за компьютером?
К чему может привести неправильная организация рабочего места? Может ли компьютер оказать негативное влияние на здоровье пользователя?
- Тема нашего урока «Представление текстов в памяти компьютера. Кодировочные таблицы». Мы познакомимся со способами представления и организации текстов в компьютерной памяти.
Каковы цели нашего урока?
- Понять, как кодируются символы в памяти компьютера.
- Осознать, что существуют различные кодировки русских букв.
- Научиться определять коды символов в разных кодировках.
- Введение нового материала.
- Сегодня нет ни одного предприятия, ни одного учреждения, где бы ни применялся компьютер. Одним из самых массовых приложений компьютера является работа с тестовой информацией. Но компьютеры не с самого рождения могли обрабатывать символьную информацию. Лишь с конца 60 - х годов они стали использоваться для обработки текстов и в настоящее время большинство пользователей ПК занимаются вводом, редактированием и форматированием текстовой информации. Давайте рассмотрим недостатки и преимущества бумажных и компьютерных технологий.
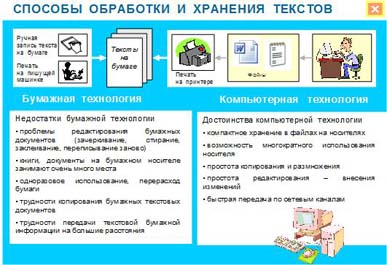
«Заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация. Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и других. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
Для представления текстовой информации в компьютере используется алфавит мощностью 256 символов. 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Вспомним формулу, связывающую информационный вес символа алфавита и мощность алфавита: N= 2 i
- Посчитайте, чему равен информационный вес одного символа такого алфавита? (8 бит или 1 байт)
- В каком виде представлена информация в памяти компьютера? (В двоичном виде 0 или 1)
- Текст – это информация? (Да)
- Как текст представляется в памяти компьютера?
Ресурс 2. Тексты в памяти компьютера.
А давайте рассмотрим свойства компьютерных документов.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки. (определение записать в тетрадь)
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена). На практике можно встретиться и с другой таблицей – КОИ - 8 (Код обмена информацией), которая используется в глобальных компьютерных сетях.
Рассмотрим таблицу кодов ASCII
Ресурс №4. Кодирование текста. Таблица кодировки.
Международным стандартом является лишь первая половина таблицы, т. е. символы с номерами от 0 (00000000), до 127 (01111111). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы.
Символы с номерами от 0 до 31 принято называть управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т. п.
Символ 32 - пробел, т. е. пустая позиция в тексте. Все остальные отражаются определенными знаками.
Соблюдение лексикографического порядка в расположении символов (буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений) называется принципом последовательного кодирования алфавита.
Запись определения в тетрадь.
Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Давайте немного отдохнём.
Упражнения для рук и плечевого пояса:
- Поднять плечи, опустить плечи. Повторить 6 – 8 раз. Расслабить плечи.
- Руки согнуть перед грудью. На счет 1 – 2 – пружинящие рывки назад согнутыми руками, на счет 3 – 4 – то же, но прямыми. Повторить 4 – 6 раз. Расслабить плечи.
Упражнения для туловища и ног:
- На счет 1 - 2 - шаг влево, руки к плечам, прогнуться. На счет 3 – 4 – то же, но в другую сторону. Повторить 3 - 4 раза.
- Ноги врозь, руки за голову. На счет 1 – резкий поворот налево, на счет 2 – направо. Повторить 3 - 4 раза.
Гимнастика для глаз:
- Сядьте на стул, закройте глаза, расслабьте мышцы лица, свободно, без напряжения откиньтесь на спинку стула, положите руки на бедра (10 – 15 секунд).
- Откройте глаза и посмотрите вдаль перед собой (2 – 3 секунды). Переведите взгляд на кончик НОСА (3 – 5 секунд). Повторите 2 раза.
- Закрепление изученного материала.
Работа с учебником.
№1 Закодируйте с помощью кодировочной таблицы ASCII и представьте в шестнадцатеричной системе счисления следующие тексты:
- Password;
- Windows;
- Информация;
- Paint.
№2 Декодируйте с помощью кодировочной таблицы ASCII следующие тексты, заданные шестнадцатеричным кодом:
- 54 6F 72 6E 61 64 6F; (Tornado)
- 49 20 6С 6F 76 65 20 79 6F 75; (I love you)
- 32 2A 78 2B 79 3D 30. (2+x+y=0)
- Не используем кодировочные таблицы
№1 Буква «I »в таблице кодировки символов имеет десятичный код 105. что зашифровано последовательностью десятичных кодов: 108 105 110 107?
№2 Десятичный код (номер) буквы «е» в таблице кодировки символов ASCII равен 101. Какая последовательность десятичных кодов будет соответствовать слову:
- file; 2) help?
- А теперь выполните практическую работу на компьютере. Будь внимательны.
- Что мы с вами узнали на уроке?
- Как кодируются символы в памяти компьютера?
- Из - за чего часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую?
- Сколько существует различных кодировок русских букв?
- Как можно определять коды символов в разных кодировках?
- Достигнута ли цель урока?
- Каковы результаты деятельности класса, собственные результаты?
- Что необходимо сделать в дальнейшем?
- Выставление оценок за урок.
§ 13, карточки д/з № 10 ресурс №6.
Ознакомьтесь с домашним заданием. Все ли всем понятно? Есть вопросы? Спасибо за урок. До свидания.

Читайте также: