
Как компьютер различает символы по их коду по их начертанию
Обновлено: 02.07.2024
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже (обратите особое внимание!) пробелы между словами. Да, не удивляйтесь: пустое место в тексте тоже должно иметь свое обозначение.
Вспомним некоторые известные нам факты:
Множество символов, с помощью которых записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации: N = 2 b ,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить практически все необходимые символы. Такой алфавит называется достаточным.
Т.к. 256 = 2 8 , то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
Двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
Каким же образом текстовая информация представлена в памяти компьютера?
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу.
Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Международным стандартом для ПК стала таблица ASCII (читается аски) (Американский стандартный код для информационного обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0(00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер
Символ
0 - 31
00000000 - 00011111
Символы с номерами от 0 до 31 принято называть управляющими.
Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п.
32 - 127
00100000 - 01111111
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы.
Символ 32 - пробел, т.е. пустая позиция в тексте.
Все остальные отражаются определенными знаками.
128 - 255
10000000 - 11111111
Альтернативная часть таблицы (русская).
Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.
Первая половина таблицы кодов ASCII
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Вторая половина таблицы кодов ASCII
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 ("CP" означает "Code Page", "кодовая страница").
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
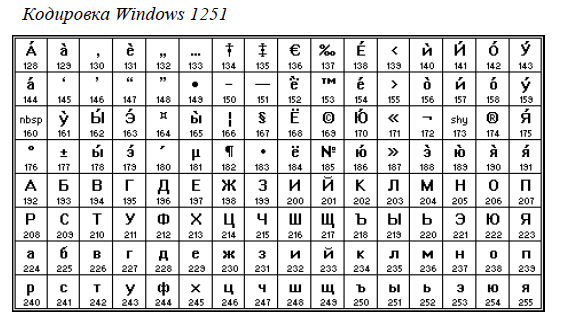
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.

В данный момент вы не можете посмотреть или раздать видеоурок ученикам
Чтобы получить доступ к этому и другим видеоурокам комплекта, вам нужно добавить его в личный кабинет, приобрев в каталоге.
Получите невероятные возможности



Конспект урока "Оценка количественных параметров текстовых документов"
· информационный объем текста.
Ежедневно каждый человек сталкивается с разными видами информации. Увидев важную информацию, можно записать её в компьютер, чтобы затем воспользоваться ей. В компьютер можно поместить фотографию своего друга или видеосъёмку о том, как вы провели каникулы. Но ввести в компьютер вкус мороженого или мягкость пледа никак нельзя.
Компьютер - это электронная машина, которая работает с сигналами. То есть он работать только информацией, которую можно превратить в сигналы. Если бы люди умели превращать в сигналы вкус или запах, то компьютер мог бы работать и с такой информацией.
Как вы уже знаете, вся информация, независимо от того, какая она графическая, видео или звуковая, представляется в компьютере с помощью чисел, это всего два символа двоичного кода, 0 и 1, которые легко перевести в сигналы.
Более 60% информации, представленной в компьютере, является текстовой информацией. В компьютерном алфавите 256 символов. Сюда входят заглавные и прописные буквы латинского и русского алфавитов, знаки препинания, печатные и непечатные символы, а также комбинации клавиш. человек различает текст по начертанию символов.

А вот компьютер различает символы, которые вводят в компьютер, по их двоичному коду. Вы нажимаете на клавиатуре символьную клавишу, в компьютер мгновенно поступает определённая последовательность электрических импульсов разной силы, которую можно представить в виде цепочки из восьми нулей и единиц (двоичного кода).

Мы уже говорили о том, что разрядность двоичного кода i и количество возможных кодовых комбинаций N связаны соотношением:

Восьмиразрядный двоичный код позволяет получить 256 различных кодовых комбинаций, то есть:

С помощью 256 кодовых комбинаций можно закодировать все символы, расположенные на клавиатуре компьютера, — строчные и прописные русские и латинские буквы, цифры, знаки препинания, знаки арифметических операций, скобки и т. д., а также ряд управляющих символов, без которых невозможно создание текстового документа (удаление предыдущего символа, переход на новую строку строки, пробел и др.).
Для создания 256 комбинаций необходимо 8 ячеек, содержащих 1 или 0. Поэтому каждому символу компьютерного алфавита в памяти компьютера отводится регистр – 8 ячеек.
Чтобы информация на всех компьютерах читалась одинаково, были созданы различные таблицы кодов. В СССР – это КОИ7 и КОИ8, в Америке –ASCII. Для кодирования информации в Windows используют таблицу ANSI.
С помощью кодовых таблиц устанавливается соответствие между изображениями и кодами символов.
Кодовая таблица содержит коды для 256 различных символов, пронумерованных от 0 до 255. Первые 128 кодов во всех кодовых таблицах соответствуют одним и тем же символам:
· коды с номерами от 0 до 32 соответствуют управляющим символам;
· коды с номерами от 33 до 127 соответствуют изображаемым символам — латинским буквам, знакам препинания, цифрам, знакам арифметических операций и т. д.
· Коды с номерами от 128 до 255 используются для кодирования букв национального алфавита, символов национальной валюты и т. п.
Поэтому в кодовых таблицах для разных языков одному и тому же коду соответствуют разные символы. Более того, для многих языков существует несколько вариантов кодовых таблиц. Так для русского языка их более десятка.
Например, последовательности двоичных кодов:

в кодировке Windows будет соответствовать слово «Урок», а в кодировке КОИ-8 — бессмысленный набор символов.
Естественно, пользователь не будет каждый раз перекодировать текстовые документы, это делают специальные программы-конверторы, встроенные в операционную систему и приложения.
Однако, восьмиразрядные кодировки обладают одним серьёзным ограничением: их количество различных кодов символов не хватает, для того чтобы можно было одновременно пользоваться более чем двумя языками. Для того чтобы на компьютере можно было устанавливать больше языков был разработан новый стандарт кодирования символов, получивший название Юникод.

Этот стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода».

С помощью этого стандарта можно закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
В Юникод каждый символ кодируется шестнадцатиразрядным двоичным кодом. Такое количество разрядов позволяет закодировать

С каждым годом Юникод получает всё более широкое распространение.

В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
• 8 битов или 1 байт — если используется восьмиразрядная кодировка;
• 16 битов или 2 байта — если используется шестнадцатиразрядная кодировка.
Информационным объёмом фрагмента текста будем называть количество битов, байтов или производных единиц (килобайтов, мегабайтов и т. д.), необходимых для записи этого фрагмента заранее оговорённым способом двоичного кодирования.
Перейдём к практической части урока.
Давайте практически найдём информационный объем текста.
Итак, Книга содержит 150 страниц. На каждой странице - 40 строк. В каждой строке 60 символов (включая пробелы). Нужно найти информационный объем текста, если используется восьмиразрядная кодировка.

Рассмотрим следующую задачу
Информационный объем текста, подготовленного с помощью компьютера, равен 3,5 Мегабайт. Нужно найти сколько символов содержит этот текст, если используется восьмиразрядная кодировка.

Рассмотрим следующую задачу

Средняя скорость передачи данных по некоторому каналу связи равна 29 Килобит в секунду. Сколько секунд потребуется для передачи по этому каналу 50 страниц текста, если считать, что один символ кодируется одним байтом и на каждой странице в среднем 96 символов?

И последняя задача.
Пользователь компьютера, хорошо владеющий навыками ввода информации с клавиатуры, может вводить в минуту 100 знаков. Мощность алфавита, используемого в компьютере равна 256. Какое количество информации в байтах может ввести пользователь в компьютер за 1 минуту.

Пришло время подвести итоги урока.
Текст состоит из символов — букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду.
Соответствие между изображениями и кодами символов устанавливается с помощью кодовых таблиц.
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может
• 8 бит (1 байт) — если используется восьмиразрядная кодировка;
• или 16 бит (2 байта) — если используется шестнадцатиразрядная кодировка.
Информационный объём фрагмента текста — это количество битов, байтов (килобайтов, мегабайтов), необходимых для записи фрагмента оговорённым способом кодирования.

§ 2. Представление текстовой информации в компьютере
Всякий текст состоит из символов - букв, цифр, знаков препинания и т. д., - которые человек различает по начертанию. Однако для компьютерного представления текстовой информации такой метод неудобен, а для компьютерной обработки текстов - и вовсе неприемлем. Используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел - кодов символов, его составляющих. При выводе текста на экран монитора или принтер необходимо восстановить изображения всех символов, составляющих данный текст. Для этого используются кодовые таблицы символов, в которых для каждого символа устанавливается соответствие между его кодом и изображением. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Основой для компьютерных стандартов кодирования символов послужил ASCII ( American Standard Code for Information Interchange ) - американский стандартный код для обмена информацией, разработанный в 1960-х годах и применяемый в США для любых видов передачи информации. В нём используется `7`-битное кодирование: общее количество символов составляет `2^7=128`, из них первые `32` символа - «управляющие», а остальные - «изображаемые», т. е. имеющие графическое изображение. Управляющие символы должны восприниматься устройством вывода текста как команды, например:
Cимвол
Действие
Английское название
Подача стандартного звукового сигнала
Затереть предыдущий символ
Конец текстового файла
End Of File (EOF)
Отмена предыдущего ввода
К изображаемым символам в ASCII относятся буквы английского (латинского) алфавита (заглавные и прописные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Фрагмент кодировки ASCII приведён в таблице.
Символ
Десятичный код
Двоичный код
Символ
Десятичный код
Двоичный код
Хотя в ASCII символы кодируются `7`-ю битами, в памяти компьютера под каждый символ отводится ровно `1` байт (`8` бит). И получается, что один бит из каждого байта не используется.
Главный недостаток стандарта ASCII заключается в том, что он рассчитан на передачу только текста, состоящего из английских букв . Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII-кодировки, в которых применялись однобайтные коды символов; при этом первые `128` символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со `128`-го по `255`-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано по нескольку вариантов кодовых таблиц (например, для русского языка их около десятка).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Указав кодовую таблицу, автоматически выбирают и язык, которым можно пользоваться в дополнение к английскому; точнее, выбирается то, как будут интерпретироваться символы с кодами более `127`.
Несовпадение кодовых таблиц приводит к ряду неприятных эффектов: один и тот же текст (неанглийский) имеет различное компьютерное представление в разных кодировках, соответственно, текст, набранный в одной кодировке, будет нечитабельным в другой!
Однобайтовые кодировки обладают одним серьёзным ограничением: количество различных кодов символов в отдельно взятой кодировке недостаточно велико, чтобы можно было пользоваться одновременно несколькими языками. Для устранения этого ограничения в 1993-м году был разработан новый стандарт кодирования символов, получивший название Unicode, который, по замыслу его разработчиков, позволил бы использовать в текстах любые символы всех языков мира.
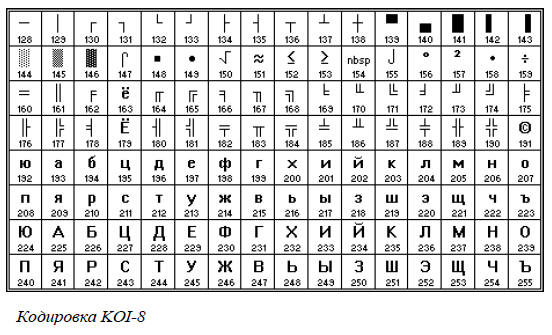
В Unicode на кодирование символов отводится `32` бита. Первые `128` символов (коды `0-127`) совпадают с таблицей ASCII, все основные алфавиты современных языков полностью умещаются в первые `65536` кодов (`65536=2^16`), а в целом стандарт Unicode описывает все алфавиты современных и мёртвых языков; для языков, имеющих несколько алфавитов или вариантов написания (например, японский и индийский), закодированы все варианты; внесены все математические и иные научные символьные обозначения, и даже - некоторые придуманные языки (например, письменности эльфов и Мордора из эпических произведений Дж.Р.Р. Толкиена). Потенциальная информационная ёмкость Unicode столь велика, что сейчас используется менее одной тысячной части возможных кодов символов!
В современных компьютерах и операционных системах используется укороченная, `16`-битная версия Unicode, в которую входят все современные алфавиты; эта часть Unicode называется базовой многоязыковой страницей (Base Multilingual Plane, BMP).
Описание слайда:
Презентация к уроку информатики
«Кодирование
текстовой информации»
Описание слайда:
Текстовая информация
- информация, выраженная с помощью естественных
и формальных языков в письменной форме.
Примеры
Далее
Описание слайда:
Текстовая информация
- информация, выраженная с помощью естественных
и формальных языков в письменной форме.
Примеры
Стихотворение в книге
Описание слайда:
Текстовая информация
- информация, выраженная с помощью естественных
и формальных языков в письменной форме.
Примеры
Статья в газете
Описание слайда:
Текстовая информация
- информация, выраженная с помощью естественных
и формальных языков в письменной форме.
Примеры
Таблица умножения на обложке тетради
Описание слайда:
Текстовая информация
- информация, выраженная с помощью естественных
и формальных языков в письменной форме.
Примеры
Расписание движения поездов
Описание слайда:
Текстовая информация
- информация, выраженная с помощью естественных
и формальных языков в письменной форме.
Примеры
Визитная карточка
Описание слайда:
Текстовая информация
- информация, выраженная с помощью естественных
и формальных языков в письменной форме.
Примеры
Текст учебника
Описание слайда:
Компьютер
- основное средство для обработки текстовой информации
(в настоящее время)
Далее
Историческое развитие персонального компьютера
Описание слайда:
Программист Майкл Шрейер (Michael Shrayer)
разработал первый в мире текстовый редактор
Electric Pencil
для персональных компьютеров,
доступных для домашнего использования.
Первый в мире текстовый редактор
Electric Pencil
Далее
Описание слайда:
В компьютере информация представлена в двоичном коде, используется всего два символа 0 и 1.
Современный компьютер
может обрабатывать числовую, текстовую, графическую,
звуковую и видео информацию.
Такое кодирование называют двоичным,
а сами логические последовательности
нулей и единиц - машинным языком.
Почему?
Потому что удобно представлять информацию
в виде последовательности электрических импульсов:
импульс отсутствует - 0, импульс есть - 1.
Далее
Описание слайда:
Кодирование текстовой информации
процесс её преобразования из формы,
удобной для непосредственного использования,
в форму, удобную для передачи, хранения, автоматической переработки и сохранения от несанкционированного доступа.
Прописные и строчные буквы русского алфавита
Прописные и строчные буквы латинского алфавита
Цифры
Специальные знаки
(знаки арифметических
действий,
знаки препинания и др.)
достаточно 256 различных символов
Далее
Описание слайда:
Информационный объем символа
N=2I .
I = 8 бит = 1 байт.
Чтобы закодировать каждый из 256 символов,
необходимо 8 бит или 1 байт информации.
Далее
Описание слайда:
Двоичное кодирования
текстовой информации
- преобразование изображения символа в его двоичный код.
соответствующий ему двоичный код
от до
символ
уникальный десятичный код от 0 до 255
или
Происходит при вводе в компьютер текстовой информации.
Далее
Описание слайда:
различает символы
по их начертанию
различает символы
по их двоичному коду
Человек
Компьютер
А
Б
В
Далее
Описание слайда:
Ввод в компьютер
текстовой информации
Двоичное кодирование
Пользователь
нажимает на клавиатуре
клавишу с символом.
В компьютер поступает определенная последовательность
из восьми
электрических импульсов (двоичный код символа).
Код символа хранится
в оперативной памяти компьютера,
где занимает одну ячейку.
А
Далее
Описание слайда:
Вывод символа
на экран компьютера
Двоичное декодирование
Преобразование кода символа в его изображение.
А
Двоичное декодирование
текстовой информации
- обратный процесс двоичному кодированию.
Далее
Описание слайда:
Кодовая таблица
– таблица, в которой фиксируется двоичный код,
присвоенный символу.
Коды с 0 по 32
соответствуют
операциям
(перевод строки,
ввод пробела и т.д.).
Коды с 33 по 127
– интернациональные –
соответствуют символам латинского
алфавита, цифрам, знакам арифметических
операций и знакам препинания.
Коды с 128 по 256
– национальные.
Далее
Описание слайда:
ASCII – базовая кодировка текста для латиницы.
ASCII
(American Standard Code for Information Interchange)
– американский стандартный код для обмена информацией.
Коды 0-32 – управляющие коды,
им не соответствуют никакие символы языков,
они не выводятся ни на экран, ни на устройства печати,
ими можно управлять тем, как производится вывод прочих данных.
ASCII кодирует первую половину символов
с числовыми кодами от 0 до 127.
Далее
Описание слайда:
Базовая таблица кодировки ASCII
Далее
Описание слайда:
Пять однобайтовых кодовых таблиц
для русских букв
Windows
MS-DOS
КОИ-8
Mac
ISO
Далее
Описание слайда:
Кодировка Windows
Является наиболее распространенной в настоящее время. Обозначается сокращением CP1251
(CP означает Code Page – кодовая страница).
Описание слайда:
Кодировка MS-DOS
Осталась со времени господства операционной системы MS DOS
(начало 90-х годов).
Описание слайда:
Кодировка КОИ-8
КОИ-8 (код обмена информацией, восьмизначный)
– один из первых стандартов кодирования русских букв.
Кодировка применялась еще в 70-е гг. XX в.,
а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
Описание слайда:
Кодировка ISO
Была утверждена Международной организацией
по стандартизации (International Standards Organization, ISO)
в качестве стандарта для русского языка.
Описание слайда:
Кодировка Mac
Используется
на компьютерах
фирмы Apple,
работающих
под управлением операционной системы Mac OS.
Описание слайда:
Один двоичный код
- различные символы в разных кодовых таблицах.
Тексты, созданные в одной кодировке,
не будут правильно отражаться в другой.
Далее
Описание слайда:
Unicode
– новый международный стандарт,
в настоящее время получивший широкое распространение.
На каждый символ отводится 2 байта = 16 бит.
Можно закодировать 2 16 = 65 536 различных символов.
русский
алфавит
латинский
алфавит
цифры
знаки
математические символы
греческий
алфавит
иврит
арабский
алфавит
другие
алфавиты
Далее
Описание слайда:
Описание слайда:
Описание слайда:
Описание слайда:
Вопрос 1. Двоичное кодирование текстовой информации – это …
в) представление текстовой информации в компьютере в виде последовательности 0 и 1;
а) представление текстовой информации в компьютере в виде последовательности символов русского алфавита;
б) представление текстовой информации в компьютере в виде последовательности символов русского и латинского алфавитов;
г) представление текстовой информации в компьютере в виде последовательности цифр 0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
Далее
неверный ответ
неверный ответ
неверный ответ
Выберите правильное определение:
Описание слайда:
Вопрос 2. В вычислительной технике используется двоичное кодирование потому, что …
в) так сложилось исторически;
б) такой способ кодирования легко реализовать технически: 1 – есть импульс, 0 – нет импульса;
а) такой способ кодирования основан на двоичной системе счисления;
г) двоичное кодирование в компьютере не используется.
Далее
Выберите правильный ответ:
неверный ответ
неверный ответ
неверный ответ
Описание слайда:
Вопрос 3. В информатике символы
0 и 1 называются…
а) цифры 0 и 1;
б) кодирующие символы;
в) кодовые цифры;
г) двоичные цифры.
Далее
неверный ответ
неверный ответ
неверный ответ
Выберите правильный ответ:
Описание слайда:
Вопрос 4. Если информационный объем символа равен 8 битам, то всего можно закодировать …?
а) 256 символов;
б) 65 536 символов;
в) 2 символа;
г) 8 символов.
Далее
неверный ответ
неверный ответ
неверный ответ
Выберите правильный ответ:
Описание слайда:
Вопрос 5. Кодовая таблица – это …
а) таблица, в которой фиксируется двоичный код, присвоенный символу;
б) устройство компьютера, управляющее его ресурсами
в процессе обработки текстовой информации;
в) программа, управляющая ресурсами компьютера
при обработке текстовой информации;
г) совокупность пронумерованных строк и столбцов.
Далее
неверный ответ
неверный ответ
неверный ответ
Выберите правильное определение:
Описание слайда:
Вопрос 6. Укажите две однобайтовые кодовые таблицы для русских букв.
б) КОИ-8;
а) КОИ-7;
в) ASCII;
г) Windows;
д) Unicode.
Далее
неверный ответ
неверный ответ
неверный ответ
Выберите правильные ответы:
Описание слайда:
Работа с тестом завершена
Далее
Описание слайда:
Если Вы считаете, что материал нарушает авторские права либо по каким-то другим причинам должен быть удален с сайта, Вы можете оставить жалобу на материал.
Читайте также: