Поэтому все более популярными становятся пиринговые сети, в которых обычные пользователи, соединяясь друг с другом, сами обмениваются файлами. Фактически пользователь качает файл с чужого компьютера, а не со специального сервера. В то же время с его разрешения кто-то скачивает добро с его собственного ПК.
В последнее время на Западе эти файлообменные сети подвергаются серьезным гонениям. Они оказались настоящим бичом для поборников авторских прав. Особенно это касается аудио-, видеопродукции и игр. Начались многочисленные судебные кампании. А такие организации, как RIAA (Американская ассоциация звукозаписывающих компаний), дискредитируют пиринговые сети, публикуя в них фальшивые файлы, содержание которых не соответствует названию. Это даже привело к потере популярности у некоторых сетей.
Всем привет, это следующий урок о том, как правильно искать информацию в сети с помощью Google. Есть одна хитрость, которая, впрочем как всегда, никаким секретом не является. Мало кто из нас задумывается, но логически это понимают все – интернет это далеко не только веб-страницы ресурсов. Это видео, фото и аудио файлы, это документы различных форматов и многое другое. Даже не всегда на том или ином ресурсе в силу каких-то обстоятельств (в том числе и по недосмотру владельца файла) мы имеем доступ к нему по прямой ссылке для скачивания. Но в сети они есть и Google их прекрасно видит. Файлы проиндексированы поисковой системой, а значит, они доступны и для нас. Так что найти нужный документ бывает проще, чем каждый из нас думает. Давайте найдём их.
Перед тем, как перейти конкретно к поиску, стоит упомянуть о специальном сервисе Google, о котором, оказывается, мало кто знает. Это страница расширенного поиска:
Я нарочно оставлю это без комментариев, там всё по-русски. Изучайте и пользуйтесь. Это, скажем, страница продвинутого поиска без знания операторов Google.
У каждого из файлов есть своё расширение, которое определяет тип программы, с помощью которой ему положено открываться. По умолчанию тип сокрыт от глаз пользователя. Но не для Google. Даже не зная названия документа полностью, вы сможете (теоретически) попытаться найти нужный документ, зная, что он имеет вид, например, документа Word из набора Microsoft Office. Вобщем, Google понимает вот такие расширения:
И некоторые другие, более специфичные. Если вы собираетесь найти нужный документ , например, обязательно в формате Word с расширением .docx, то можно попробовать задать этот параметр (без точки перед расширением) уже в поисковой строке. Это должно выглядеть так:
По аналогии с известным вам исключением ненужной информации из поисковой выдачи, можно, наоборот, исключить из неё ненужные расширения и работать только с определёнными их типами. Используем, тем самым, оператор исключения «-». Например:
Всё. В поисковой выдаче страниц с договором в формате Word не будет. Будут PDF, TXT, но не Word.
Как найти нужный документ на конкретном сайте или домене.
Так вот, чтобы заняться поиском только по конкретной доменной зоне, укажите тип домена в поисковом запросе с помощью оператора “site:”. Например:
И при наборе информации в определённой зоне:
Google будет искать результаты только в русскоязычном интернете (рунете).
По аналогии с доменной зоной можно сократить место поиска до конкретного веб-сайта. Например, если нужно прочитать справку о том или ином событий в операционной системе Windows, есть смысл обратиться к первоисточнику. Ищите в пределах только официальной справки от Microsoft на официальном сайте. Для этого используйте тот же самый оператор в таком виде:
Преимущественно медиафайлы. На полном серьезе, без шуток.
![Попытка скачать хотя бы один файл]()
Увы, частая ситуация в попытке хоть что-то скачать
Зачем это нужно?
• Отличие контента ТВ- и DVD-версии
Например, мультсериал «Дарья» лишился почти всей музыки, которая была в ТВ-версии, из-за юридических проблем с перелицензированием. Долгое время люди, желающие посмотреть данный сериал, стояли перед выбором: либо полноценная ТВ-версия с музыкой и плохим качеством видео, либо DVD-версия с хорошим качеством, но без музыки.
• Региональные различия
Справедливы как для видео, так и для музыки. Мультсериал W.I.T.C.H. выпускался с 4 разными опенингами, только один из которых попал на DVD.
Зачастую, музыкальные альбомы, выпускаемые для рынка Японии, содержат бонусные треки, которых нет в других изданиях.
Как вы уже поняли, причин может быть множество. Где искать непопулярные и старые файлы?
История Usenet
![Чтение email-рассылок через NNTP]()
С увеличением пропускной способности линий, улучшением модемов и их протоколов, к девяностым сеть уже вовсю использовали для передачи бинарных файлов: вареза, музыки, видеофайлов. Делалось это примерно таким же образом, как и в Email: файл разбивается на небольшие части (тома), кодируется печатными символами в 7-битной кодировке с использованием Base64 или uuencode, и отправляется в ньюсгруппу. Кодирование в 7 бит добавляет около 30% накладных расходов на передачу файла. Спецификация позволяет использовать большинство символов из ASCII-таблицы, поэтому в 2001 году появляется алгоритм передачи файлов yEnc, увеличивающий файл всего на 1-2%, экранируя только символы переноса строки, NULL-байты и символ равенства (=). Им пользуются и по сей день.
Для контроля целостности и восстановления поврежденных или отсутствующих данных используется Parchive.
![Загрузка файлов в Usenet]()
До 2008 года крупнейшие Usenet-провайдеры хранили бинарные файлы около 100-150 дней с момента их загрузки (так называемый retention time, срок хранения файлов). С 2008 года самые крупные провайдеры вообще перестали что-либо удалять, и на текущий момент можно без проблем скачать файлы восьмилетней давности, а провайдеры поменьше выставили retention time в 1000+ дней, что тоже немало. К этому моменту текстовое общение в Usenet сошло на нет и сеть использовалась преимущественно для хранения и передачи файлов.
Начиная где-то с середины 2011 года за сетью начали следить правообладатели, из-за чего Usenet-провайдерам пришлось удалять файлы, что сильно повлияло на целостность релизов. Некоторые провайдеры сделали автоматизированные системы удаления файлов, чтобы правообладатели могли удалять загрузки самостоятельно. Дабы предотвратить или хотя бы замедлить обнаружение файлов правообладателями, энтузиасты начинают загружать файлы с обфусцированными именами, в архивах под паролями, и добавляют их в каталоги систем индексации релизов (indexers), доступ к которым, как правило, осуществляется либо за деньги, либо по приглашениям. Обычными способами ни найти, ни скачать такие релизы не удастся.
В современной России о Usenet почти никому не известно, хотя рунет зарождался именно с него, по протоколу UUCP, и был одним из двух рабочих каналов для связи с Западом во время путча 1991 года (второй — FIDO). Сейчас Usenet наиболее популярен в странах, законы которых позволяют штрафовать пользователей за скачивание или раздачу контента, защищенного авторским правом, например, в Германии. В отличие от BitTorrent, узнать IP-адресы пользователей Usenet сторонней организации невозможно.
Подключение к Usenet
Теперь нужно каким-то образом получить nzb-файл с метаинформацией, это что-то вроде .torrent-файла. Если у вас его нет, нужно воспользоваться поисковиком-индексатором.
Индексаторы
Скачивание с Usenet
![Поиск the.fp.2011 в nzbking, нашелся файл с паролем]()
Файлы, защищенные паролем, как правило, являются просто фейками.
![Поиск the.fp.2011 в nzbking, нашелся DVDRip]()
На второй странице обнаруживается DVDRip, с адекватным размером, в архиве без пароля — хороший знак.
![BDRip the.fp.2011 в nzbking]()
На третьей странице находим BDRip и несколько DVDRip'ов, похожих на настоящие (судя по размеру файла и дате загрузки).
Выбираем файлы, которые хотим скачать, нажимаем кнопку «Download NZB», скачиваем .nzb-файл и импортируем его в NZBGet или SABnzbd, предварительно вписав данные своего Usenet-аккаунта в настройки программы. Начинается скачивание со скоростью канала моего провайдера.
![Скачивание файла через NZBGet]()
По окончанию скачивания, NZBGet автоматически распакует архивы и удалит их. Файл размером 6.74 ГБ, загруженный 4.5 года назад, скачался за 15 минут!
Internet Relay Chat — протокол текстового общения, до сих пор пользующийся популярностью у разработчиков свободного ПО, администраторов торрент-трекеров, анимешников и авторов ботнетов из-за своей простоты. Появившийся в 1989 году, IRC стал стандартом групповых чатов в интернете на долгие годы, и начинает терять популярность только к середине 2000-х, с приходом ICQ и Jabber. В IRC существует возможность передачи файлов — DCC , на основе которой в 1994 году был написан первый бот для автоматического распространения доступных боту файлов — Xabi DCC (отсюда и название — XDCC).
На сегодняшний день существуют как отдельные каналы, так и целые серверы, посвященные файлообмену через XDCC. Почти у любой мало-мальски серьезной аниме релиз-группы, у которой даже может не быть веб-сайта, есть свой бот, с которого можно скачать все релизы группы независимо от их возраста. Популярность XDCC обусловлена функциональностью скриптов, легкостью их настройки и администрирования: выкладывающему релиз достаточно загрузить каким-либо образом файл на сервер с ботом, например по FTP, а бот сам добавит его в индекс, оповестит пользователей на канале о появлении нового файла, автоматически отправит его пользователям, подписавшимся на обновления этого бота (например, если это новый эпизод сериала).
В специальных IRC-сетях распространяют варез, свежие и не очень фильмы, музыку, игры, книги. XDCC не наделен вниманием правообладателей, поэтому у ботов можно найти множество вещей, которые сложно найти в других местах.
Индексаторы
Скачивание из IRC
![Поиск книги на IRC-канале]()
Попробуем скачать «How Music Got Free» («Как музыка стала свободной» по-русски) — замечательная книга об истории музыкальной индустрии, технологиях обмена музыкой и человеке, который почти в одиночку стащил 2000 альбомов и выложил их в сеть.
![Прием ZIP-архива]()
Бот присылает результат поиска в виде ZIP-архива с текстовым файлом:
![Запрос на скачивание файла]()
Отправляем боту запрос на скачивание файла:
![Прием файла]()
…и принимаем его!
Конечно, не обязательно искать напрямую на канале. Если вы нашли нужный файл через индексатор, можете сразу запросить его у бота командой, которую вам сгенерирует сайт.
Direct Connect-сеть представляет собой клиент-серверную архитектуру, где все коммуникации, кроме непосредственно обмена файлами, происходят через сервер. В DC++ есть возможность расшаривания файлов и директорий, поиск файлов с учетом их типа (видео, аудио, архивы, документы, образы дисков), ссылки на файлы, независящие от имени файла и, конечно же, чат, из-за чего DC++-хабы были очень популярны в локальных сетях интернет-провайдеров РФ. Сибирский провайдер GoodLine рекламировал свой внутрисетевой хаб на уличных рекламных щитах, писал ПО для упрощения файлообмена и даже встраивал его в свои Set-top box, чтобы клиенты могли смотреть новинки кинематографа прямо с телевизора. На хабе сидело более 100000 человек — больше, чем в любом другом хабе в мире.
![EiskaltDC++, хаб allavtovo]()
Из-за того, что пользователю достаточно указать путь к файлам, к которым он хочет открыть публичный доступ, в DC++ можно найти жуткое, малоизвестное старьё, которое, по мнению пользователя с этим файлом, уж точно никому не сдалось, но он его все равно расшарил, так, на всякий случай.
![Поиск в DC++]()
3 человека раздают видеоурок 11-летней давности, который ни одному вменяемому человеку смотреть не захочется, поверьте.
Скачивание из DC++
Вам потребуется какой-нибудь DC-клиент. Под Windows рекомендую FlylinkDC++ (который, к тому же, поддерживает BitTorrent), под Linux — EiskaltDC++ и AirDC++ Web. Далее нужно подключиться к популярным хабам, лучше сразу к десятку. Список хабов есть в самих программах, но можно воспользоваться специальной страницей и скопировать адреса оттуда.
Настоятельно рекомендую включить «активный» режим, пробросить порты, ввести ваш внешний IP-адрес в настройках программы и удостовериться, что к вам возможны подключения извне, иначе, в «пассивном» режиме у вас будут ограничения на количество результатов поиска, вы не сможете качать файлы с других пользователей в «пассивном» режиме.
Поиск и скачивание файлов интуитивно понятно: вводите название, опционально выбираете тип контента и фильтр по размеру, нажимаете кнопку поиска, кликаете два раза по результату, файл начинает скачиваться. Также можно посмотреть все файлы пользователя (и, например, скачать папку с найденным файлом целиком), нажав правой кнопкой по конкретному результату и выбрав соответствующий пункт меню.
![Скачивание файла в DC++]()
Если нужного вам файла не нашлось, имеет смысл периодически повторять поиск. Некоторые люди запускают DC-клиент только тогда, когда им нужно что-то скачать, и вам нужно поймать момент, чтобы найти файл у таких пользователей.
Индексаторы
Поиск внутри программы может найти только файлы пользователей, находящихся в DC-сети на момент поиска, поэтому индексаторы очень полезны для нахождения и скачивания файлов с редко запускающих программу людей.
ed2k — протокол децентрализованной передачи файлов, требующий сервер-хаб для нахождения пользователей и соединения с ними. Был протоколом №1 для передачи файлов среди всех слоев населения, до закрытия самого популярного сервера Razorback 2 в 2006 году и роста популярности BitTorrent.
eDonkey2000 выжил. Этому поспособствовал протокол полностью децентрализованного обмена Kad, который был внедрен в сторонние клиенты незадолго до закрытия Razorback 2 и главного сервера оригинальной программы, уступающей в функциональности и скорости альтернативным реализациям.
В ed2k можно найти примерно то же самое, что и в DC++ — старые файлы, ТВ-шоу на разных языках, разнообразную музыку, игры, варез, старые книги по программированию, математике, биологии. Новинки, разумеется, тоже в наличии. Хоть протокол и поддерживает чаты и просмотр всех файлов пользователя в открытом доступе, эти функции по умолчанию отключены, и, скорее всего, вам не удастся пообщаться с интересующими вас людьми через программу.
Скачивание в eDonkey2000 / Kad
Как вы уже догадались, потребуется ed2k-клиент. Хороший выбор для Linux — aMule, для Windows, наверное, eMule, хоть он и не обновлялся с 2011 (Обновление: появилась официальная версия eMule от сообщества, доступная для скачивания на официальном сайте, она обновляется). Крайне рекомендую пробросить порты, чтобы иметь возможность скачивать с пользователей за NAT (LowID).
Процесс поиска и скачивания файлов очень похож на таковой в DC++ — вводим поисковой запрос, получаем результаты поиска с пользователей, находящихся онлайн, кликаем на файлы для начала скачивания.
Файл отобразится в результатах даже в том случае, у пользователей, находящихся онлайн, есть только его части, но не файл целиком.
![Поиск фильма We Live In Public в ed2k]()
Вводим поисковую фразу, получаем результаты:
![Скачивание фильма We Live In Public в ed2k]()
Кликаем, начинается скачивание:
Загрузка файла может растянуться на недели и месяцы. По какой-то причине, многие пользователи сети имеют отвратительное интернет-соединение, да еще и появляются раз в неделю на пару часов, а то и меньше.
Soulseek — централизованная сеть обмена музыкальным файлами по принципу P2P, созданная в 2000 году одним из разработчиков Napster. Долгое время была популярна среди слушателей и авторов IDM и прочей электронной музыки, и по сей день сеть развивается и остается хорошим местом для поиска аудиофайлов. Есть групповые и приватные чаты, возможность раздачи файлов только друзьям, удобный поиск музыки с указанием битрейта и других характеристик аудиофайлов. Некоторые поисковые запросы цензурируются.
Существует официальный кроссплатформенный проприетарный клиент SoulseekQt и два развивающихся неофициальных: Nicotine+ и Museek+.
Почти в каждом регионе существуют свои местные файлообменники, пользующиеся популярностью у конкретной языковой группы. Например, на uloz.to можно найти много чешского и словацкого контента, zone-telechargement.ws подойдет любителям французского языка, а chomikuj.pl для поляков.
До совсем недавнего времени большое количество контента можно было найти на ex.ua, но увы.
Не всегда достаточно искать файлы только по названию материала, так можно упустить сценические релизы.
Рели́зная гру́ппа — сообщество людей-энтузиастов, объединенных идеей свободы информации. Выпускает электронные копии CD или DVD с фильмами, музыкой, программами и играми для компьютеров и игровых приставок, руководствуясь правилами релизов и соревнуясь со своими коллегами-конкурентами в скорости и качестве выпуска таких копий (релизов). Сообщество релизных групп, объединенных одной темой (музыка определенного жанра, кинофильмы или варез), называется сценой.
Попробуем узнать сценическое название архивов с релизом We Live In Public от PUZZLE на Layer13:
![We Live In Public на Layer13]()
![Поиск по сценическому имени архива в Usenet]()
NFO-файл называется «puzzle-wlip.nfo». Названия архивов практически всегда, в 99% случаев совпадают с названием NFO, поэтому попробуем поискать это название в Usenet-индексаторе:
Ура, теперь мы можем скачать DVD фильма!
Обычные поисковые системы вроде Google не всегда будут вам помощниками. Во-первых, Google следует букве закона и удаляет (скрывает) результаты с сайтов, о которых сообщают ему правообладатели в рамках DMCA , во-вторых, поиск контента с названием из спецсимволов затруднен: проблемно найти что-либо о W.I.T.C.H., вам постоянно подсовывают информацию о Witch, The Witch или Blair Witch. Я предпочитаю пользоваться DuckDuckGo, Bing и метапоисковиком SearX — через них можно найти материалы, недоступные в Google.
Если вас интересует релиз на конкретном языке, уместней узнать локализованное название и совершать поиск по нему. Получить подобную информацию можно на Wikipedia, IMDb и других подобных сайтах.
![Информация о группах на Anidb]()
Для аниме есть anidb, хранящий информацию о релизах групп на разных языках. Карточка группы, как правило, содержит ссылку на сайт или IRC-канал, где можно пообщаться с ее членами и скачать файлы через XDCC.
![Информация о файле на anidb]()
Помимо источника, разрешения видео, языков аудиодорожек и субтитров, на anidb есть TTH-хеш для DC++ и ed2k-ссылка для каждого файла.
Иногда случается так, что вы хотите скачать свободно распространяемый музыкальный альбом 2007 года, выпущенный исполнителем, которого знает три с половиной человека. Вы находите торрент-файл, запускаете его, загрузка доходит до 14,7% и… всё. Проходят дни и недели, а загрузка стоит на месте. Вы начинаете искать альбом в Google, рыщете по форумам и наконец находите ссылки на какие-нибудь файлообменники, но они уже давно не работают.
Такое происходит всё чаще и чаще — правообладатели постоянно закрывают полезные ресурсы. И если популярный контент найти по-прежнему не проблема, отыскать какой-нибудь телевизионный сериал семилетней давности на испанском языке может быть крайне трудно.
Что бы вам ни понадобилось в интернете, есть ряд способов это отыскать. Мы предлагаем все нижеперечисленные варианты исключительно для ознакомления с контентом, но ни в коем случае не для воровства.
Usenet
До 2008 года крупные провайдеры Usenet хранили файлы лишь 100–150 дней, однако затем файлы стали храниться вечно. Более мелкие провайдеры оставляют контент на 1 000 и более дней, чего зачастую тоже достаточно.
Примерно в середине 2001 года Usenet стали замечать правообладатели, из-за чего провайдерам пришлось удалять защищённый авторским правом контент. Но энтузиасты быстро нашли обходной путь: они стали давать файлам запутанные названия, защищать архивы паролями и добавлять их на специальные сайты, к которым можно получить доступ только по приглашению.
В России о существовании Usenet почти никто не знает, чего не скажешь о странах, где власти усердно борются с пиратством. В отличие от протокола BitTorrent, в Usenet нельзя определить IP-адрес пользователя без помощи провайдера сервиса или поставщика интернет-услуг.
Как подключиться к Usenet
В большинстве случаев бесплатно подключиться не выйдет. Придётся довольствоваться либо малым временем хранения файлов, либо низкой скоростью, либо доступом только к текстовым группам.
Провайдеры предлагают два типа платного доступа: ежемесячную подписку с неограниченным объёмом загружаемых данных или неограниченные по времени тарифы с лимитированным трафиком. Второй вариант — для тех, кому лишь иногда требуется что-то скачать. Крупнейшие поставщики таких услуг — Altopia, Giganews, Eweka, NewsHosting, Astraweb.
Теперь нужно понять, где брать NZB-файлы с метаинформацией — что-то вроде торрент-файлов. Для этого используются специальные поисковые движки — индексаторы.
Индексаторы
Публичные индексаторы полны спама и вирусов, но они всё ещё годятся для поиска файлов, загруженных пять или более лет назад. Вот некоторые из них:
Бесплатные индексаторы, требующие регистрации, больше подходят для поиска новых файлов. Они хорошо структурированы, у контента есть не только названия, но и описания с картинками. Можно попробовать следующие:
Также существуют индексаторы только для определённых типов контента. Например, anizb подойдёт поклонникам аниме, а albumsindex — тем, кто ищет музыку.
Скачивание из Usenet
В качестве примера возьмём «Фрейзер Парк» (The FP) — малоизвестный фильм 2011 года, вариант которого в разрешении 1080p отыскать практически невозможно. Нужно найти NZB-файл и запустить его через программу вроде NZBGet или SABnzbd.
Здесь доступна только одна часть из 3 867. Вы не можете скачать такой файл, он помечен красным.
Защищённые паролями файлы (Password protected) обычно являются фальшивками.
На второй странице видим нормальный DVDRip — подходящий размер файла, никаких паролей.
На этой странице есть BDRip и несколько нормальных DVDRip, судя по размеру и дате загрузки.
Выберите нужный фильм, нажмите «Загрузить NZB» (Download NZB) и импортируйте файл в NZBGet или SABnzbd, в которых необходимо ввести данные аккаунта Usenet. Когда скачивание закончится, программа сама распакует архивы и удалит их.
IRC / DCC / XDCC
IRC — старый протокол для текстового общения, из-за своей простоты по-прежнему популярный среди разработчиков, администраторов торрент-трекеров и любителей аниме. IRC поддерживает передачу файлов посредством DCC.
Сегодня существуют IRC-каналы и даже серверы, предназначенные исключительно для передачи файлов с помощью скрипта XDCC. Он популярен благодаря простоте использования и администрирования ботов: пользователю достаточно загрузить файл на FTP, а бот автоматически добавит его в индекс и уведомит об этом членов канала.
Есть специальные приватные IRC-сети с программами, новыми и не очень фильмами, музыкой и играми. Агентства по борьбе с нарушителями авторских прав об XDCC почти ничего не знают, поэтому в таких сетях можно найти много того, чего нет в других местах.
Индексаторы
У большинства XDCC-ботов есть веб-интерфейсы. Контент общей направленности можно найти здесь:
Как качать через IRC
Вам потребуется IRC-клиент. Подойдёт почти любой — подавляющее большинство поддерживает DCC. Подключитесь к интересующему вас серверу и начинайте качать.
Крупнейшие серверы с книгами:
Фильмы:
Западная и японская анимация:
Попробуем скачать «Как музыка стала свободной» (How Music Got Free) — книгу о музыкальной индустрии, написанную Стивеном Уиттом (Stephen Witt).
Бот отреагировал на запрос @search и отправил результаты в виде ZIP-файла по DCC.
Отправляем запрос на скачивание.
И принимаем файл.
Если вы нашли файл с помощью индексатора, то вам не нужно искать его на канале. Просто отправьте боту запрос на загрузку, используя команду с сайта индексатора.
В DC-сети все коммуникации осуществляются через сервер, называемый хабом. В ней можно искать конкретные типы файлов: аудио, видео, архивы, документы, образы дисков.
Делиться файлами в DC++ очень просто: достаточно поставить галочку напротив папки, к которой вы хотите предоставить общий доступ. За счёт этого можно отыскать что-то совершенно невообразимое — что-то, о чём вы сами уже давно забыли, но что может кому-то внезапно пригодиться.
Как качать через DC++
Подойдёт любой клиент. Для Windows лучшим вариантом является FlylinkDC++. Пользователи Linux могут выбирать между EiskaltDC++ и AirDC++ Web.
Подключитесь к разным хабам — чем больше, тем лучше. Список хабов есть в самом клиенте, также их можно найти по специальной ссылке.
Поиск и загрузка реализованы удобно: введите запрос, выберите тип контента, нажмите «Искать» и два раза щёлкните по результату, чтобы скачать файл. Также можно просмотреть список всех открытых пользователем файлов и загрузить все файлы из выбранной папки. Для этого нужно правой кнопкой мыши щёлкнуть по поисковому результату и выбрать соответствующий пункт.
Если что-то не нашли, попробуйте позже. Зачастую люди включают DC-клиент только когда им самим нужно что-то загрузить.
Индексаторы
Встроенный поиск находит только файлы в списках пользователей, находящихся в онлайн-режиме. Чтобы отыскать редкий контент, вам понадобится индексатор.
eDonkey2000 (ed2k), Kad
Как и DC++, ed2k — протокол децентрализованной передачи данных с централизованным хабом для поиска и соединения пользователей друг с другом. В eDonkey2000 можно найти почти то же самое, что и в DC++: старые сериалы с разной озвучкой, музыку, программы, игры, старые книги для программистов, а также книги по математике и биологии. Впрочем, есть здесь и новые релизы.
Как качать через eDonkey2000 / KAD
Вам нужен ed2k-клиент. Хороший выбор для Linux — aMule. Пользователям Windows подойдёт eMule, несмотря на то что он не обновлялся с 2011 года.
Поиск и скачивание реализованы почти так же, как в DC++. Введите запрос, получите результаты от онлайн-пользователей, два раза щёлкните по нужному файлу, чтобы загрузить его.
Поищем «Мы живём на людях» (We Live In Public) — малоизвестный документальный фильм 2009 года, в котором рассказывается об интернете 90-х годов.
Введите запрос, нажмите «Пуск» (Start) и ждите, пока не появятся результаты.
Два раза щёлкните по файлу, чтобы начать загрузку.
Скачивание одного файла может длиться недели и даже месяцы. По какой-то непонятной причине у большинства пользователей ed2k невероятно низкая скорость соединения с интернетом, причём в онлайн они выходят лишь на несколько часов в неделю. Поэтому запаситесь терпением.
Soulseek
Это централизованная сеть для прямого обмена музыкой. Известна в IDM-сообществе и всё ещё находится в активной разработке. Здесь есть группы и приватные чаты, возможность делиться файлами с друзьями и поиск по битрейту.
Самый популярный клиент — официальный SoulseekQt. Есть также два неофициальных — Nicotine+ и Museek+.
BitTorrent DHT
Все современные BitTorrent-клиенты могут искать пиров через распределённую хеш-таблицу (DHT). Эта функция используется DHT-индексаторами: они получают торрент-файлы с данными из сторонних DHT-запросов и сохраняют их в свои базы. Через такие индексаторы можно искать редкие и неопубликованные торрент-файлы или похожие на них, но с большим количеством раздающих.
Список некоторых популярных индексаторов:
DHT-индексаторы известны тем, что долго не живут. Поэтому что-то из списка на момент публикации материала уже может не работать.
Сайты и FTP-серверы для обмена файлами
Почти в каждом регионе есть свои сайты для обмена файлами. Например, среди чехов популярен uloz.to, среди французов — zone-telechargement.ws, а среди поляков — chomikuj.pl.
FTP-индексаторы редко помогают найти что-то нужное, но попытаться всё равно можно:
Сайты для поиска на файлообменниках тоже малоэффективны, но не стоит забывать и о них:
![]()
Получение частных данных не всегда означает взлом — иногда они опубликованы в общем доступе. Знание настроек Google и немного смекалки позволят найти массу интересного — от номеров кредиток до документов ФБР.
WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.
К интернету сегодня подключают всё подряд, мало заботясь об ограничении доступа. Поэтому многие приватные данные становятся добычей поисковиков. Роботы-«пауки» уже не ограничиваются веб-страницами, а индексируют весь доступный в Сети контент и постоянно добавляют в свои базы не предназначенную для разглашения информацию. Узнать эти секреты просто — нужно лишь знать, как именно спросить о них.
Ищем файлы
В умелых руках Google быстро найдет все, что плохо лежит в Сети, — например, личную информацию и файлы для служебного использования. Их частенько прячут, как ключ под половиком: настоящих ограничений доступа нет, данные просто лежат на задворках сайта, куда не ведут ссылки. Стандартный веб-интерфейс Google предоставляет лишь базовые настройки расширенного поиска, но даже их будет достаточно.
Ограничить поиск по файлам определенного вида в Google можно с помощью двух операторов: filetype и ext . Первый задает формат, который поисковик определил по заголовку файла, второй — расширение файла, независимо от его внутреннего содержимого. При поиске в обоих случаях нужно указывать лишь расширение. Изначально оператор ext было удобно использовать в тех случаях, когда специфические признаки формата у файла отсутствовали (например, для поиска конфигурационных файлов ini и cfg, внутри которых может быть все что угодно). Сейчас алгоритмы Google изменились, и видимой разницы между операторами нет — результаты в большинстве случаев выходят одинаковые.
![Результаты поиска с filetype и ext теперь одинаковые]()
Результаты поиска с filetype и ext теперь одинаковые
Реверс малвари
Фильтруем выдачу
По умолчанию слова и вообще любые введенные символы Google ищет по всем файлам на проиндексированных страницах. Ограничить область поиска можно по домену верхнего уровня, конкретному сайту или по месту расположения искомой последовательности в самих файлах. Для первых двух вариантов используется оператор site, после которого вводится имя домена или выбранного сайта. В третьем случае целый набор операторов позволяет искать информацию в служебных полях и метаданных. Например, allinurl отыщет заданное в теле самих ссылок, allinanchor — в тексте, снабженном тегом <a name> , allintitle — в заголовках страниц, allintext — в теле страниц.
Для каждого оператора есть облегченная версия с более коротким названием (без приставки all). Разница в том, что allinurl отыщет ссылки со всеми словами, а inurl — только с первым из них. Второе и последующие слова из запроса могут встречаться на веб-страницах где угодно. Оператор inurl тоже имеет отличия от другого схожего по смыслу — site . Первый также позволяет находить любую последовательность символов в ссылке на искомый документ (например, /cgi-bin/), что широко используется для поиска компонентов с известными уязвимостями.
Попробуем на практике. Берем фильтр allintext и делаем так, чтобы запрос выдал список номеров и проверочных кодов кредиток, срок действия которых истечет только через два года (или когда их владельцам надоест кормить всех подряд).
![275 тысяч актуальных кредиток, фейков и ханипотов для любителей халявы]()
275 тысяч актуальных кредиток, фейков и ханипотов для любителей халявы
Когда читаешь в новостях, что юный хакер «взломал серверы» Пентагона или NASA, украв секретные сведения, то в большинстве случаев речь идет именно о такой элементарной технике использования Google. Предположим, нас интересует список сотрудников NASA и их контактные данные. Наверняка такой перечень есть в электронном виде. Для удобства или по недосмотру он может лежать и на самом сайте организации. Логично, что в этом случае на него не будет ссылок, поскольку предназначен он для внутреннего использования. Какие слова могут быть в таком файле? Как минимум — поле «адрес». Проверить все эти предположения проще простого.
![Используя два оператора, можно получить «секретные» документы NASA за 0,36 с]()
Используя два оператора, можно получить «секретные» документы NASA за 0,36 с
и получаем ссылки на файлы со списками сотрудников.
![Адреса и телефоны ключевых сотрудников NASA в файле Excel]()
Адреса и телефоны ключевых сотрудников NASA в файле Excel
Пользуемся бюрократией
Подобные находки — приятная мелочь. По-настоящему же солидный улов обеспечивает более детальное знание операторов Google для веб-мастеров, самой Сети и особенностей структуры искомого. Зная детали, можно легко отфильтровать выдачу и уточнить свойства нужных файлов, чтобы в остатке получить действительно ценные данные. Забавно, что здесь на помощь приходит бюрократия. Она плодит типовые формулировки, по которым удобно искать случайно просочившиеся в Сеть секретные сведения.
Например, обязательный в канцелярии министерства обороны США штамп Distribution statement означает стандартизированные ограничения на распространение документа. Литерой A отмечаются публичные релизы, в которых нет ничего секретного; B — предназначенные только для внутреннего использования, C — строго конфиденциальные и так далее до F. Отдельно стоит литера X, которой отмечены особо ценные сведения, представляющие государственную тайну высшего уровня. Пускай такие документы ищут те, кому это положено делать по долгу службы, а мы ограничимся файлами с литерой С. Согласно директиве DoDI 5230.24, такая маркировка присваивается документам, содержащим описание критически важных технологий, попадающих под экспортный контроль. Обнаружить столь тщательно охраняемые сведения можно на сайтах в домене верхнего уровня .mil, выделенного для армии США.
![Пример штампа в документе уровня секретности С]()
Пример штампа в документе уровня секретности С
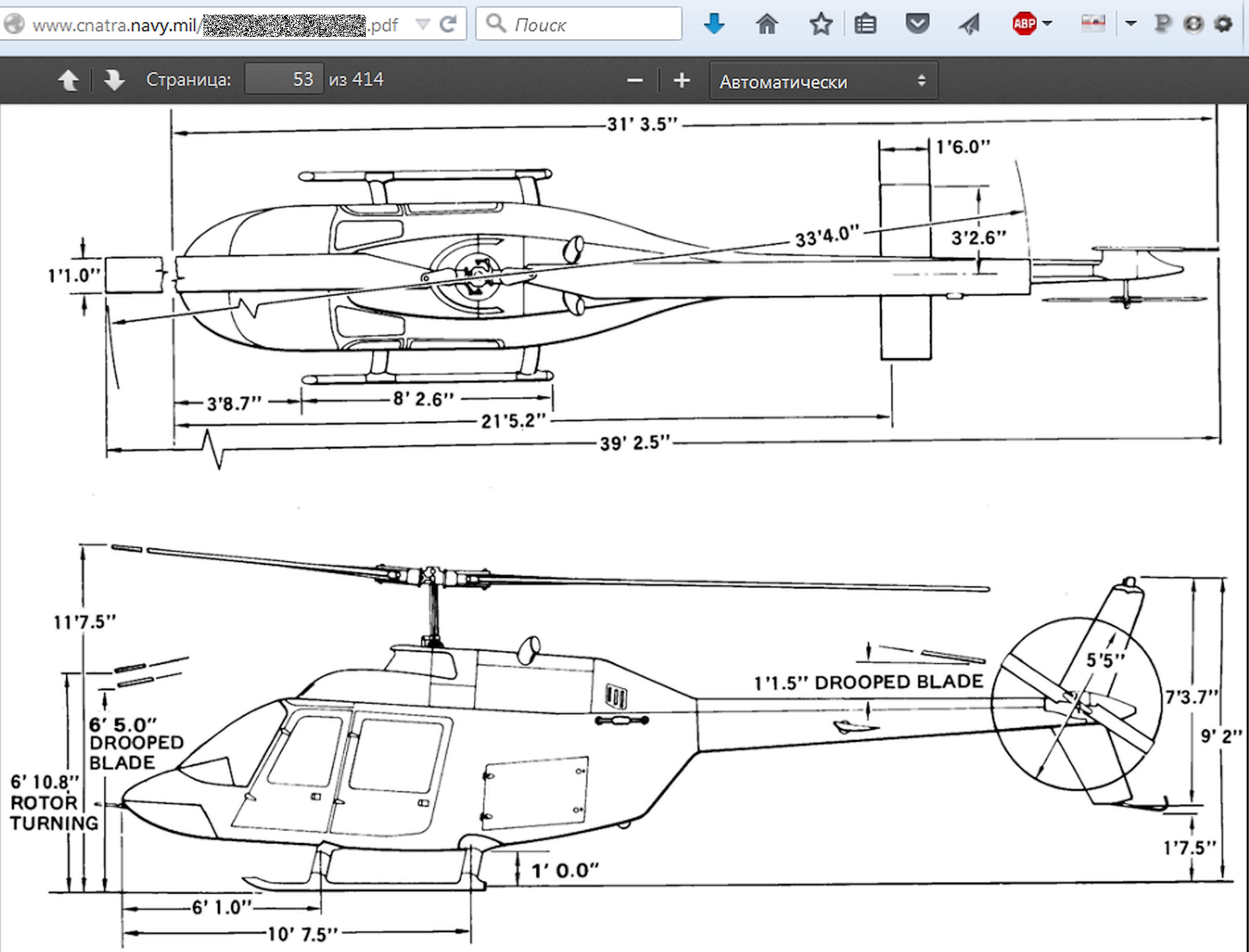
![Чертеж из руководства к учебно-боевому вертолету TH-57С Sea Ranger]()
Чертеж из руководства к учебно-боевому вертолету TH-57С Sea Ranger
Внимательно изучив любой документ с сайта в домене .mil, можно увидеть и другие маркеры для уточнения поиска. Например, отсылку к экспортным ограничениям «Sec 2751», по которой также удобно искать интересную техническую информацию. Время от времени ее изымают с официальных сайтов, где она однажды засветилась, поэтому, если в поисковой выдаче не удается перейти по интересной ссылке, воспользуйся кешем Гугла (оператор cache) или сайтом Internet Archive.
Забираемся в облака
Помимо случайно рассекреченных документов правительственных ведомств, в кеше Гугла временами всплывают ссылки на личные файлы из Dropbox и других сервисов хранения данных, которые создают «приватные» ссылки на публично опубликованные данные. С альтернативными и самодельными сервисами еще хуже. Например, следующий запрос находит данные всех клиентов Verizon, у которых на роутере установлен и активно используется FTP-сервер.
![Серийники, документы и еще сорок тысяч файлов с частных облаков]()
Серийники, документы и еще сорок тысяч файлов с частных облаков
Подсматриваем конфиги
До повальной миграции в облака в качестве удаленных хранилищ рулили простые FTP-серверы, в которых тоже хватало уязвимостей. Многие из них актуальны до сих пор. Например, у популярной программы WS_FTP Professional данные о конфигурации, пользовательских аккаунтах и паролях хранятся в файле ws_ftp.ini . Его просто найти и прочитать, поскольку все записи сохраняются в текстовом формате, а пароли шифруются алгоритмом Triple DES после минимальной обфускации. В большинстве версий достаточно просто отбросить первый байт.
![Один из файлов ws_ftp.ini в открытом доступе]()
Один из файлов ws_ftp.ini в открытом доступе
Расшифровать такие пароли легко с помощью утилиты WS_FTP Password Decryptor или бесплатного веб-сервиса.
![Расшифровка пароля занимает около секунды]()
Расшифровка пароля занимает около секунды
Говоря о взломе произвольного сайта, обычно подразумевают получение пароля из логов и бэкапов конфигурационных файлов CMS или приложений для электронной коммерции. Если знаешь их типовую структуру, то легко сможешь указать ключевые слова. Строки, подобные встречающимся в ws_ftp.ini , крайне распространены. Например, в Drupal и PrestaShop обязательно есть идентификатор пользователя (UID) и соответствующий ему пароль (pwd), а хранится вся информация в файлах с расширением .inc. Искать их можно следующим образом:
![Пароль к базе данных открыто хранится в конфигурационном файле]()
Пароль к базе данных открыто хранится в конфигурационном файле
С появлением на серверах Windows место конфигурационных файлов отчасти занял реестр. Искать по его веткам можно точно таким же образом, используя reg в качестве типа файла. Например, вот так:
![Серверы с открытыми окнами]()
Серверы с открытыми окнами
Не забываем про очевидное
Иногда добраться до закрытой информации удается с помощью случайно открытых и попавших в поле зрения Google данных. Идеальный вариант — найти список паролей в каком-нибудь распространенном формате. Хранить сведения аккаунтов в текстовом файле, документе Word или электронной таблице Excel могут только отчаянные люди, но как раз их всегда хватает.
![Национальный НИИ здоровья им. Ли Дэнхуэя случайно засветил список паролей]()
Национальный НИИ здоровья им. Ли Дэнхуэя случайно засветил список паролей
С одной стороны, есть масса средств для предотвращения подобных инцидентов. Необходимо указывать адекватные права доступа в htaccess, патчить CMS, не использовать левые скрипты и закрывать прочие дыры. Существует также файл со списком исключений robots.txt, запрещающий поисковикам индексировать указанные в нем файлы и каталоги. С другой стороны, если структура robots.txt на каком-то сервере отличается от стандартной, то сразу становится видно, что на нем пытаются скрыть.
![Белый дом приветствует роботов]()
Белый дом приветствует роботов
Список каталогов и файлов на любом сайте предваряется стандартной надписью index of. Поскольку для служебных целей она должна встречаться в заголовке, то имеет смысл ограничить ее поиск оператором intitle . Интересные вещи находятся в каталогах /admin/, /personal/, /etc/ и даже /secret/.
![Goolge помогает зреть в корень списка директорий]()
Goolge помогает зреть в корень списка директорий
Следим за обновлениями
Дырявых систем сегодня так много, что проблема заключается уже не в том, чтобы найти одну из них, а в том, чтобы выбрать самые интересные (для изучения и повышения собственной защищенности, разумеется). Примеры поисковых запросов, раскрывающие чьи-то секреты, получили название Google dorks. Одной из первых утилит автоматической проверки защищенности сайтов по известным запросам в Google была McAfee SiteDigger, но ее последняя версия вышла в 2009 году. Сейчас для упрощения поиска уязвимостей есть масса других средств. К примеру, SearchDiggity авторства Bishop Fox, а также пополняемые базы с подборкой актуальных примеров.
Актуальность тут крайне важна: старые уязвимости закрывают очень медленно, но Google и его поисковая выдача меняются постоянно. Есть разница даже между фильтром «за последнюю секунду» ( &tbs=qdr:s в конце урла запроса) и «в реальном времени» ( &tbs=qdr:1 ).
Временной интервал даты последнего обновления файла у Google тоже указывается неявно. Через графический веб-интерфейс можно выбрать один из типовых периодов (час, день, неделя и так далее) либо задать диапазон дат, но такой способ не годится для автоматизации.
По виду адресной строки можно догадаться только о способе ограничить вывод результатов с помощью конструкции &tbs=qdr: . Буква y после нее задает лимит в один год ( &tbs=qdr:y ), m показывает результаты за последний месяц, w — за неделю, d — за прошедший день, h — за последний час, n — за минуту, а s — за секунду. Самые свежие результаты, только что ставшие известными Google, находится при помощи фильтра &tbs=qdr:1 .
Если требуется написать хитрый скрипт, то будет полезно знать, что диапазон дат задается в Google в юлианском формате через оператор daterange . Например, вот так можно найти список документов PDF со словом confidential, загруженных c 1 января по 1 июля 2015 года.
Диапазон указывается в формате юлианских дат без учета дробной части. Переводить их вручную с григорианского календаря неудобно. Проще воспользоваться конвертером дат.
Таргетируемся и снова фильтруем
Помимо указания дополнительных операторов в поисковом запросе их можно отправлять прямо в теле ссылки. Например, уточнению filetype:pdf соответствует конструкция as_filetype=pdf . Таким образом удобно задавать любые уточнения. Допустим, выдача результатов только из Республики Гондурас задается добавлением в поисковый URL конструкции cr=countryHN , а только из города Бобруйск — gcs=Bobruisk . В разделе для разработчиков можно найти полный список.
Средства автоматизации Google призваны облегчить жизнь, но часто добавляют проблем. Например, по IP пользователя через WHOIS определяется его город. На основании этой информации в Google не только балансируется нагрузка между серверами, но и меняются результаты поисковой выдачи. В зависимости от региона при одном и том же запросе на первую страницу попадут разные результаты, а часть из них может вовсе оказаться скрытой. Почувствовать себя космополитом и искать информацию из любой страны поможет ее двухбуквенный код после директивы gl=country . Например, код Нидерландов — NL, а Ватикану и Северной Корее в Google свой код не положен.
Часто поисковая выдача оказывается замусоренной даже после использования нескольких продвинутых фильтров. В таком случае легко уточнить запрос, добавив к нему несколько слов-исключений (перед каждым из них ставится знак минус). Например, со словом Personal часто употребляются banking , names и tutorial . Поэтому более чистые поисковые результаты покажет не хрестоматийный пример запроса, а уточненный:
Пример напоследок
Искушенный хакер отличается тем, что обеспечивает себя всем необходимым самостоятельно. Например, VPN — штука удобная, но либо дорогая, либо временная и с ограничениями. Оформлять подписку для себя одного слишком накладно. Хорошо, что есть групповые подписки, а с помощью Google легко стать частью какой-нибудь группы. Для этого достаточно найти файл конфигурации Cisco VPN, у которого довольно нестандартное расширение PCF и узнаваемый путь: Program Files\Cisco Systems\VPN Client\Profiles . Один запрос, и ты вливаешься, к примеру, в дружный коллектив Боннского университета.
![Поступить в Боннский университет значительно сложнее, чем подключиться к их VPN]()
Поступить в Боннский университет значительно сложнее, чем подключиться к их VPN
Google находит конфигурационные файлы с паролями, но многие из них записаны в зашифрованном виде или заменены хешами. Если видишь строки фиксированной длины, то сразу ищи сервис расшифровки.
При помощи Google выполняются сотни разных типов атак и тестов на проникновение. Есть множество вариантов, затрагивающих популярные программы, основные форматы баз данных, многочисленные уязвимости PHP, облаков и так далее. Если точно представлять то, что ищешь, это сильно упростит получение нужной информации (особенно той, которую не планировали делать всеобщим достоянием). Не Shodan единый питает интересными идеями, но всякая база проиндексированных сетевых ресурсов!
Читайте также: