
Как найти удаленный файл в интернете
Обновлено: 06.07.2024
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Этичный хакинг и тестирование на проникновение, информационная безопасность
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
Какие существуют веб-архивы Интернета
Я знаю о трёх архивах веб-сайтов (если вы знаете больше, то пишите их в комментариях):
Этот сервис веб архива ещё известен как Wayback Machine. Имеет разные дополнительные функции, чаще всего используется инструментами по восстановлению сайтов и информации.


В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.

Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.


Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:

Кроме календаря доступна следующие страницы:
Changes
"Changes" — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:

И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
Summary
В этой вкладке статистика о количестве изменений MIME-типов.

Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Поиск по Интернет архиву
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:

Показ страницы на определённую дату
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы

Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
Данный сервис сохраняет следующие части страницы:
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Дату можно продолжить далее, указав часы, минуты и секунды:
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
Также возможно обратиться ко всем снимкам указанного URL:
Все сохранённые страницы домена:
Все сохранённые страницы всех субдоменов
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
Архив интернет (Web archive) — это бесплатный сервис по поиску архивных копий сайтов. С помощью данного сервиса вы можете проверить внешний вид и содержимое страницы в сети интернет на определённую дату.
Поиск сразу по всем Веб-архивам
Может так случиться, что интересующая страница или файл отсутствует в веб архиве. В этом случае можно попытаться найти интересующую сохранённую страницу в другом Архиве Интернета. Специально для этого я сделал довольно простой сервис, который для введённого адреса даёт ссылки на снимки страницы в рассмотренных трёх архивах.

Что делать, если удалённая страница не сохранена ни в одном из архивов?
Архивы Интернета сохраняют страницы только если какой-то пользователь сделал на это запрос — они не имеют функции обходчиков и ищут новые страницы и ссылки. По этой причине возможно, что интересующая вас страница оказалась удалено до того, как была сохранена в каком-либо веб-архиве.
Тем не менее можно воспользоваться услугами поисковых движков, которые активно ищут новые ссылки и оперативно сохраняют новые страницы. Для показа страницы из кэша Google нужно в поиске Гугла ввести
Если ввести подобный запрос в поиск Google, то сразу будет открыта страница из кэша.
Для просмотра текстовой версии можно использовать ссылку вида:
Для просмотра исходного кода веб страницы из кэша Google используйте ссылку вида:
Например, текстовый вид:
Как полностью скачать сайт из веб-архива
Если вы хотите восстановить удалённый сайт, то вам поможет программа Wayback Machine Downloader.

Структура скаченных файлов:

Локальная копия сайта, обратите внимание на провайдера Интернет услуг:

Как скачать все изменения страницы из веб-архива
Если вас интересует не весь сайт, а определённая страница, но при этом вам нужно проследить все изменения на ней, то в этом случае используйте программу Waybackpack.


Как узнать все страницы сайта, которые сохранены в веб-архиве
Для получения ссылок, которые хранятся в Архиве Интернета, используйте программу waybackurls.
Эта программа извлекает все URL указанного домена, о которых знает Wayback Machine. Это можно использовать для быстрого составления карты сайта.
Заключение
Предыдущие три программы рассмотрены совсем кратко. Дополнительную информацию об их установке и об имеющихся опциях вы сможете найти по ссылкам на карточки этих программ.
Но 24 года назад, лишь в 1996 году Брюстером Кейлом была организована некоммерческая организация Internet Arсhive, собирающая копии веб-сайтов, с 2001 года предоставившая публичный доступ к своей Waybackmachine (накопилось свыше 50 петабайт данных и число перевалило за полтриллиона страниц).
Но, к сожалению, материалы за около 5 лет, когда сайты были, а архива не было, фактически потеряны.
Распадаются страны (например, домен .yu — Югославия), упраздняются организации, прекращают работу сайты, следовательно сведения бесследно исчезают.
Информация — это история и культура.
Например, сайт прекратившей работу компании, создавшей один из первых интернет-браузеров:

Лучшие практики того,
как можно вручную сохранить ценную информацию [почти] навечно (на примере Пикабу).
Чтобы сохранить АДРЕС_СТРАНИЦЫ, нужно прописать:
Чтобы найти АДРЕС_СТРАНИЦЫ потом:
1) Web-страницы публично открытых сайтов (когда waybackmachine срабатывает).
2) Текстовая информация.
А потом дополнительно для спокойствия сохраняем в Waybackmachine.
Обе ссылки можно дать, например, в комментарии.
3.1) Файлы по ссылкам.
Стандартно. Упомянутый Архив Интернета сохраняет файлы, если дать на них прямую ссылку.
В комментариях можно дать ссылку на резервную копию файла.
3.2) Файлы по ссылкам, когда waybackmachine не сработал, ИЛИ же закрытые файлы.
Во-первых, применимо, когда сохранение не проходит из-за настроек сервера.
Во-вторых, применимо, когда у вас есть свой файл, который хочется опубликовать и сделать так, чтобы ссылка на него была доступна в комментариях и в будущем, навсегда.
Последовательность действий моя:
- дополнительно сохраняем полученную ссылку в Waybackmachine;
- в комментариях к странице даём обе ссылки;
- опционно: сохраняем в waybackmachine ещё и статью с комментариями (где будут эти ссылки).
Критерии хостинга: без регистрации, получается прямая ссылка (которая сохранится в Waybackmachine), а бонусом идёт вечное хранение (как утверждается). Но если и не вечное, то зеркало будет в Архиве Интернета.
Если у вас есть подпадающие под эти критерии хостинги — кидайте в комментарии.
4.1) Web-страницы публично открытых сайтов, когда waybackmachine не сработал, ИЛИ же закрытые страницы.
Во-первых, применимо, когда сохранение конкретной страницы не проходит опять-таки из-за настроек сервера (например, сайт подгружает информацию по нажатию мыши).
Во-вторых, применимо, когда есть информация, которая доступна после авторизации, а давать логин-пароль не рационально.
С первым примером всё ясно.
Типичный пример второго — та же Лепра, или страница с закрытого паблика соцсети, или страница с электронной почты. Сделать копию HTML, не давая доступа к учётной записи, чтобы показать, можно.
Доступный аналог (к сожалению, в отличие от исчезнувшего сервиса ссылки не сокращает и хранит информацию у себя не вечно, хотя с первостепенной задачей справляется):
- зайти на сайт, скопировать букмарклет себе в браузер (или быть готовым запустить скрипт, например, через консоль);
- зайти на нужную страницу;
- запустить букмарклет, чтобы осуществить копирование страницы. Учтите, она пропадёт в скором времени!
- дополнительно сохранить её с помощью в waybackmachine навечно;
- в комментарии к странице даём обе ссылки;
- опционно: сохраняем в waybackmachine ещё и статью с комментариями (где будут эти ссылки).
Как подменить:
Типичные примеры спасения файлов, когда ссылка в посте больше не работает, и иное:
1. Пикабу: Векторные дома в изометри, раздаю бесплатно:) (с сайта, указанного в посте, не грузится, но Архив Интернета скопировал).
2. Голосовое управление офисной оргтехникой (по ссылке в посте не грузится, но файл залит на хостинг, а потом сохранён в Архив Интернета).
4. Аналогичный файл javascript сайта-аналога, не был сохранён. А был сохранён позавчера мной, и я был первым. Если что с сайтом случится, файл останется.

Web-технологии
233 поста 4.5K подписчиков
Правила сообщества
1. Не оскорблять других пользователей
2. Не пытаться продвигать свои услуги под видом тематических постов
3. Не заниматься рекламой
4. Никакой табличной верстки
5. Тег сообщества(не обязателен) pikaweb
Ниче не понял. Оставил комент чтоб потом зайти почитать, что умные люди скажут.
Спасибо за пост. А можно сохранить весь сайт целиком с файлами? Например, есть сайт на сервере, по какой - то причине сервер вышел из строя, снэпшота ос нет. Можно сделать полную резервную копию сайта, чтобы потом на заново устаенленной ос на сервере можно было восстановить полноценный рабочий сайт?
Хм. А как можно вытащить с Wayback Machine сайт, который там уже есть, но целиком, со всем флешем?
Через простое сохранение страницы — не выходит, внутренние элементы флеша не сохраняются. Но в самом архиве всё работает, даже файлы скачать можно.
Не волнуйтесь, в Америке весь интернет копирует АНБ. Так что всегда можно написать им и восстановить:)
использую diigo. Умеет сохранять все кешируя
А вдруг кто-нибудь знает, как скопировать и заархивировать свой блог на ЖЖ?
Панические атаки, антидепрессанты и обучение по 16 часов в день. Как я пытаюсь стать программистом

Интернет пестрит рекламными баннерами в духе "Изучи programmingLanguageName (подставьте название любого популярного языка) с нуля за 3 месяца и устройся на работу с зп от 100 000 вечнодеревянных". Предложение, конечно, заманчивое, но вряд ли осуществимое на практике для среднего человека без опыта разработки и не являющегося гением. Попытаюсь рассказать о своём пути в IT.
В апреле мой работодатель решил закрыть бизнес и я оказался на улице. Было принято окончательное решение стать разработчиком. К этому моменту у меня за плечами был опыт изучения JS примерно полгода и примерно месяц изучения React. Я решил, что смогу за пару месяцев подтянуть знания до уровня, позволяющего претендовать на позицию junior frontend-developer. Следующие 2 месяца я начинал занятия в 10-11 часов утра и заканчивал в 2-3 ночи. Без праздников и выходных. Оказалось, что кроме HTML, CSS и JavaScript нужно знать ещё кучу разных технологий и библиотек вроде Redux, Webpack, Material-UI, formik, axios, да тысячи их. Также было сделано открытие: знать синтаксис языка, писать ToDo и решать задачи на codewars !== быть программистом.
В общем, список того, что нужно изучить в процессе только разрастался. Я начал переживать, что ошибся в оценке сроков, нужных для трудоустройства. Деньги заканчивались. Рассылка резюме не давала нужных результатов. Я не получал даже приглашения на интервью. Думаю, что это в совокупности с ещё рядом факторов спровоцировали первую паническую атаку. Букет, состоящий из высокого давления, головокружения, нехватки воздуха и дикого страха смерти прямо здесь и сейчас даёт весьма интересные ощущения. Терапевты из платной и бесплатной клиник поставили диагноз гипертония. На мой вопрос почему у меня развилась гипертония в 27 лет был дан ответ: "Что вы хотите, - возраст. Даже железо стареет". Сначала панические атаки были раз в неделю, спустя некоторое время они стали возникать каждый день. Нормально учиться стало невозможно. В таком состоянии я пробыл около 3 месяцев, пока наконец не попал к неврологу, который выписал антидепрессанты. Я вернулся к учёбе.
На данный момент прошло 1,5 года с момента, как я впервые встретился с HTML. До сих пор не получилось устроиться на работу. Программирование мне очень нравится и, думаю, что я его не брошу, даже если ничего не выйдет с работой. Идея окунуться в омут с головой, не имея солидной финансовой подушки, была весьма авантюрной. О решении не идти на платные курсы, готовящие профессиональных разработчиков за срок от недели до 3 месяцев не жалею, поскольку до сих пор не вижу их преимуществ перед самообучением.

Наглядно про веб-технологии

Перевод, думаю, не нужен :)
Во все тяжкие: Веб-разработчик с нуля. 1 год

"Еще до встречи с Юнаковым он уже жил по правилу: не отступать и не теряться. Не вышло—повтори. Правило, чем-то напоминающее цирковой обычай: не удался прыжок, упал с лошади или с проволоки — повтори, не откладывая в долгий ящик, повтори, преодолевая боль и страх, повторяй до тех пор, пока не добьешься своего, иначе тебе никогда не избавиться от неуверенности в решающий момент. Александр Крон - "Капитан дальнего плавания".
Цель — Senior Frontend Developer.
Язык: JavaScript.
Возраст: 29 лет.
Работа (настоящее время): Trainee Frontend Developer в компании "Корус Консалтинг СНГ".
Локация: г. Санкт-Петербург.
Привет! Пролетел год, с того самого дня, как я твердо решил освоить профессию инженера-программиста (веб-разработчика). И в этом посте мне не хочется рассказывать в привычной мне манере о том, что я сделал за последний месяц и о трудностях с которыми столкнулся. Вкратце, расскажу об этом в конце поста, а сейчас позволю себе кое-что поведать.
Этот год был интересен для меня не столько программированием, сколько открытием для себя новой плоскости, знакомство с людьми, чье мышление и навыки довольно интересны сами по себе.
Каждый человек рожден для того, чтобы развить в себе способность разбираться за короткий промежуток времени и решить задачу в любой сфере, неважно в какой. В истории, примеров людей, реализовавших эту способность, десятки. Современная жизнь требует от человека решение задач в разных плоскостях, но общество заставляет становиться узкоспециализированным специалистом в одной сфере, абсолютно неспособного ни на что, стоит только его вытянуть за пределы его плоскости влияния. И, как вы понимаете, жизнь со всеми ее ситуациями делает и будет продолжать делать это с каждым. Неважно, программист ты или врач, сантехник или менеджер, тебе обязательно придется столкнуться с реалиями жизни и со сферами, которые тебе не знакомы. Поэтому очень важно научиться быстро разбираться в любой сфере и принимать правильные решения.
К чему это я веду? К тому, чтобы глядя на мой пример, вы ни в коем случае, не закрывались в четырех стенах с компьютером в обнимку. Со стороны может показаться, что моя история - это история человека, который решил "жить программированием", что он только и делает, что программирует и больше ему ничего не интересно. Нет, это не так.
Моя жизнь не заканчивается программированием. Для меня программирование сейчас - это лишь сфера, которая мне показалась год назад очень хорошей для того, чтобы освоить определенные навыки и почувствовать под ногами опору в профессиональной сфере. Сейчас она мне кажется до сих пор такой сферой. Получилось ли это? Еще нет, я в начале пути, но определенно кое-какие успехи есть, и чувствую я себя увереннее. И я абсолютный противник такого образа жизни, при котором мышление человека фиксируется на одной плоскости и практически никогда оттуда не смещается. Иногда, да, требуется длительная фокусировка на сфере, но не фиксация.
Что касается программирования - то это обычная профессиональная плоскость, со своими особенностями и определенными требуемыми навыками. Она интересная, как и многие другие сферы, но она не особенная.
Сейчас у меня начался второй месяц стажировки и учебы в компании "Корус Консалтинг СНГ". Могу с уверенностью сказать, что за этот месяц я понял и освоил, с помощью преподавателя, больше, чем за несколько месяцев самостоятельной работы. Это к тому, что если есть возможность учиться у кого-то, кто уже прошел такой же путь - то обязательно делайте это. Еще я понял, что конкретные технологии абсолютно не имеют значения. React, Vue, Angular. это все не важно. Если вы понимаете главные принципы построения программы, принципы взаимодействия ее частей и тот язык на глубоком уровне, на базе которого происходит всё это построение, то вы очень быстро перейдете на любую абстракцию и будете спокойно ее использовать.
Меня недавно спросили -"Как закреплять элементарные основы по JS (if, for, простые функции) на практике? откуда брать задания? с задачами на learn-javascript я более менее справляюсь, но этого мало."
Хочу написать для всех. Задайте себе вопрос: К чему вы идете? Вы хотите научиться решать задачки с Codewars или вы хотите устроиться в компанию и решать коммерческие задачи, тем самым зарабатывая деньги? Если ответ второй, то тогда начните с тестовых заданий в компании (или компанию, если есть такая, в которую вы хотите попасть). И пляшите от тестового задания. Всё, что вам необходимо знать и уметь для решения этой и подобных задач, с полным понимаем, того что вы делаете, и будет тем, куда вам необходимо прикладывать усилия. Про собеседования, на которых вас заставляют решать задачи, абсолютно никак не связанные с будущими задачами на работе - я промолчу.
В связи с этим, я решил помочь таким же как и я и создал базу тестовых заданий для frontend разработчиков. На данный момент она пополняется исключительно теми заданиями, которые присылали мне. По мере возможности, я буду ее пополнять. Я думаю, еще порядка 15-20 заданий, я в ближайшие дни туда выложу. Так же, приветствую пулреквесты. На гитхабе есть подобный репозиторий, но там очень мало тестовых, и в основном задания от крупных компаний. Но ведь больше как раз маленьких компаний, и было бы хорошо +- понимать, какие тестовые могут быть в этой компании и вообще, какие навыки и знания будут требоваться при работе там, с учетом особенности сферы и т.д. С другой стороны это позволит работодателям не расслабляться и постоянно менять тестовые. Дабы действительно брать на работу только тех, кто решил задачу, а не тех, кто скопировал решение из чужого репозитория или канала на ютубе, а потом будет сидеть и тупить на работе.
Что же касается моего развития, то я публично выкладываю материалы, которые я закончил изучать. Можете смело глядеть и подбирать для себя то, что хотите. У меня вкус хороший, надеюсь.
Всем профессионального роста и силы. Не забывайте, что мир сам по себе тайна, которую стоит раскрыть для себя. Не капсулируйте весь мир в одной плоскости!
На прошлой неделе Сельский арбитражник опубликовал схему с микроспендами в Facebook. Схема никакого палива в себе не несла, это просто описание штатного функционала Facebook, куда и какой тикет писать.
Спустя 20 минут все источники, в которых была опубликована схема, были почищены. Сельский отредактировал пост на Telegra.ph и удалил запись со своего канала. Аналогичным образом поступил и Желтый веб, который одним из первых обратил внимание на тему и сделал репост на свой канал.
Как только на горизонте появилась возможность быстро срубить бабла, к делу подключаются инфоцыгане. Некоторые скопировали схему и после того, как автор её удалил, они начали ей торговать.
Абсурдность ситуации в том, что арбитражники не особо вникают, рабочая тема или нет. Срабатывает синдром упущенной выгоды и рука тянется к электронному кошельку, когда очередной продавец воздуха называет цену «кнопки Бабло».

Если не успели увидеть пост с эксклюзивной инфой, совсем необязательно покупать «копию» даже за 100 рублей. Достаточно проявить смекалку и можно найти удалённый контент за несколько минут.
Первый вариант — Telemetr
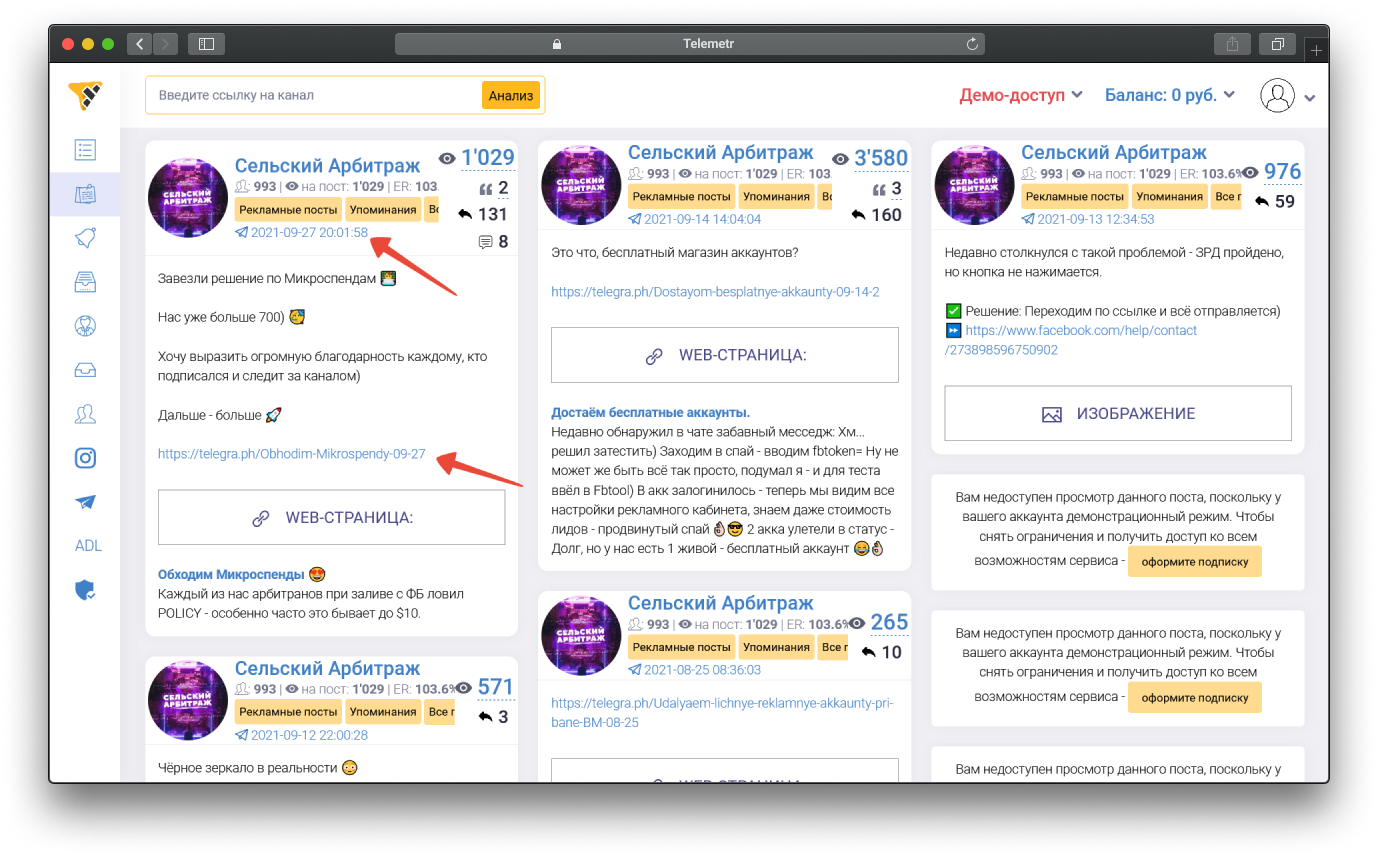
- Находим канал в сервисе Telemetr.
- Ищём удалённый пост.
- Копируем ссылку и проверяем наличие цитирования в Google.
- В данном случае ничего нет. Канал приватный и посты с него не индексируются.

Промокод CPARIP даёт 15% скидки на оплату подписки в «Телеметре»
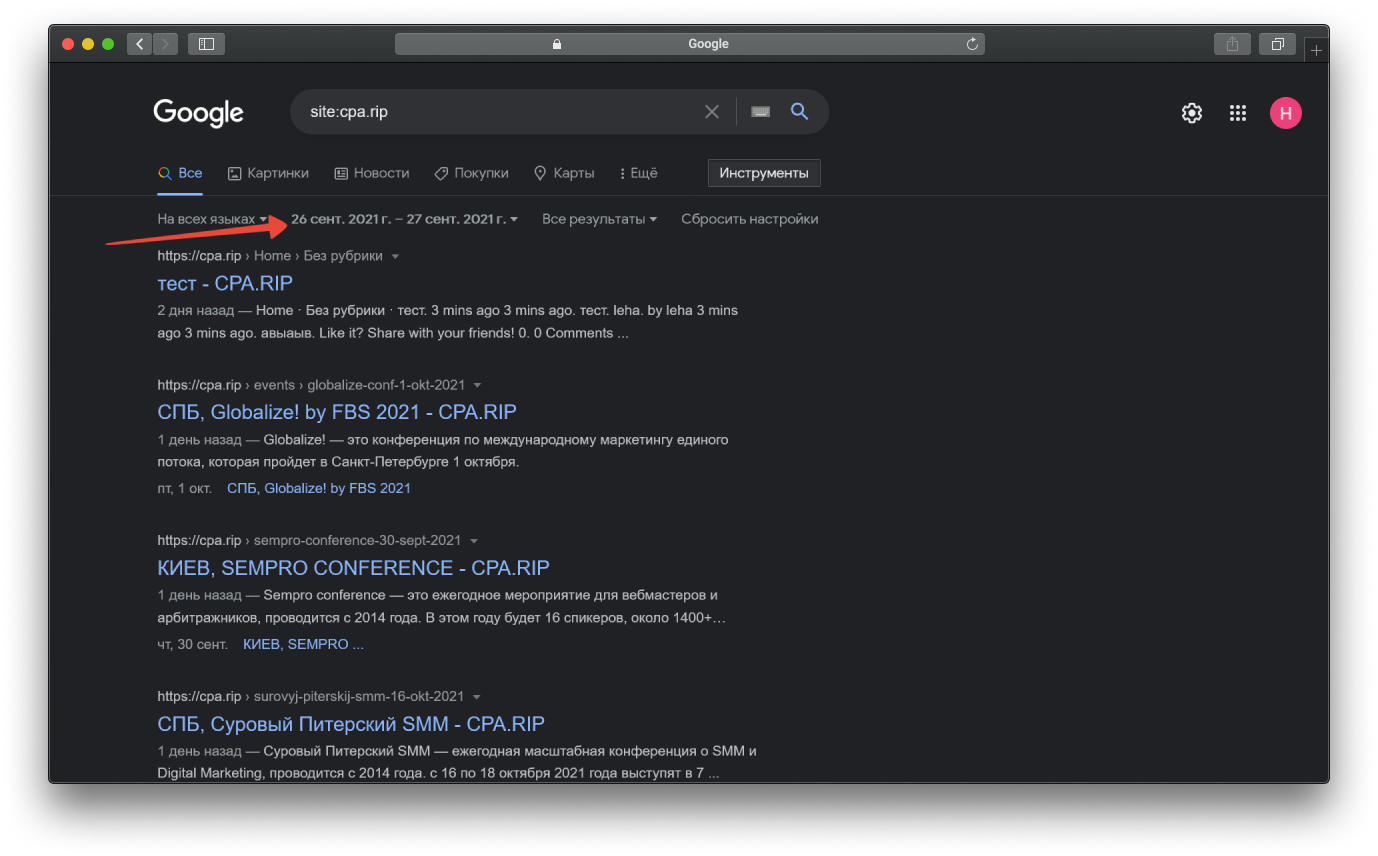
Второй вариант — Яндекс/Google
Если материала провисел больше 10-20 минут на каком либо сайте, то очень велика вероятность, что он попал в индекс поисковиков.
-
Идём в Google и выставляем в настройках нужный интервал дат. В выдаче пусто, потому что пост быстро потёрли.

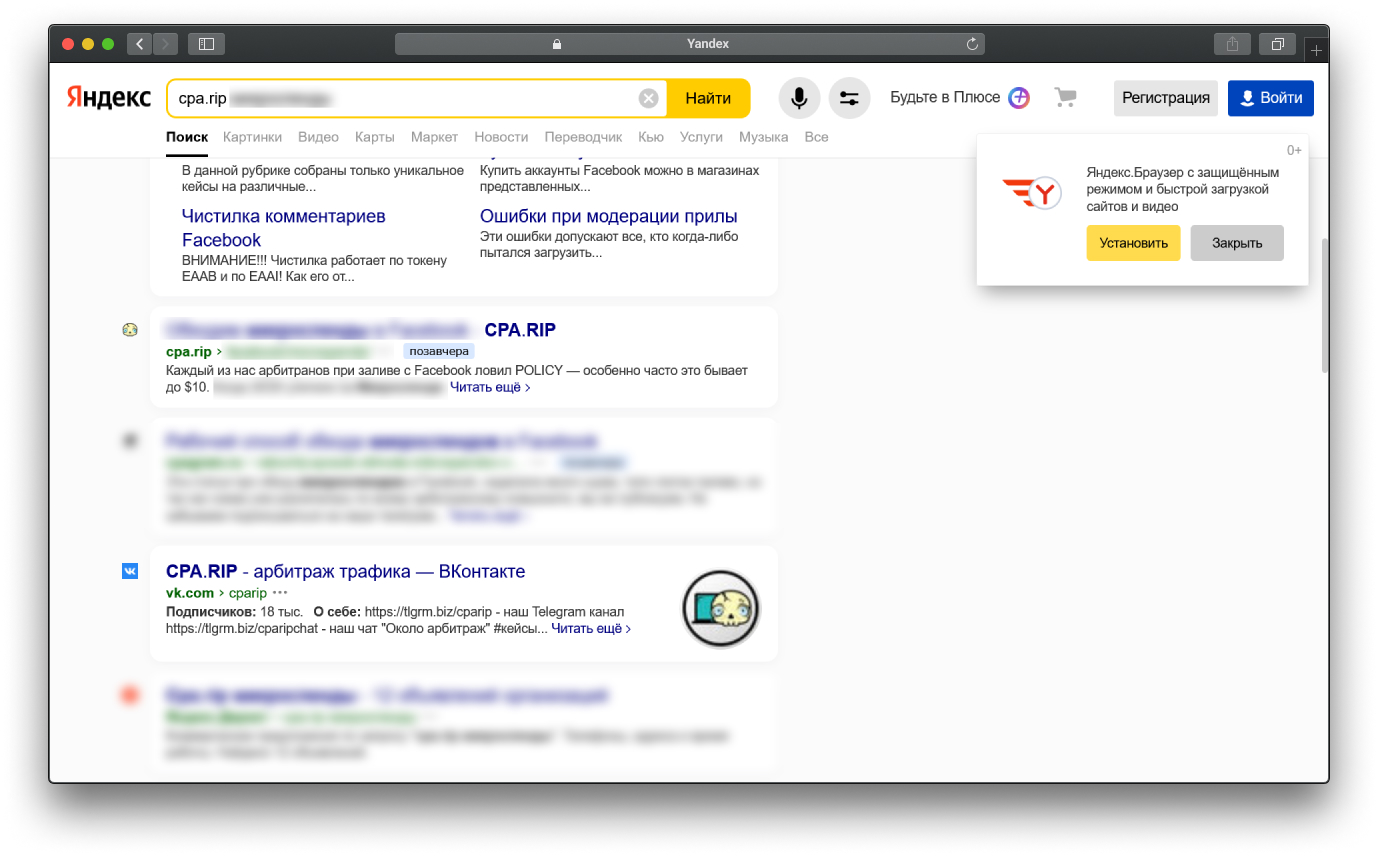


Может вы знаете еще варианты поиска удаленного контента? Напишите их в комментарии 😀
Читайте также: