
Как открыть файл qvd через qlikview
Обновлено: 03.07.2024
Можно ли хранить более одной таблицы данных в одном документе QVD?
Если да, то как я могу хранить и загружать несколько таблиц в/из этого QVD?
2 ответа
Может быть, кто-нибудь знает. Могу ли я увидеть через QlikView (что-то похожее на TableViewer) диаграмму с отношениями между моей таблицей в БД и объектами QV (я имею в виду таблицы, созданные в QlikView из файлов qvd).
У меня есть файл qvd, который содержит данные за два года. Я должен split эти данные в два файла qvd, один из которых принадлежит текущему году, а другой-следующему или прошлому году. Я пробовал использовать анализ времени. Но теперь я теряюсь, какой код использовать. Есть какие-нибудь идеи или.
Хранение таблиц
Вы не можете хранить более одной отдельной таблицы в файле QVD. Причина этого заключается в том, что формат QVD хранит только память "image" одной таблицы и как таковой не включает метаданные для любых ссылок на другие таблицы.
Поэтому, если вы хотите сохранить несколько таблиц в файле QVD, вы должны либо:
- Храните их как отдельные QVDs
- Объедините их в одну таблицу (например, через JOIN s, applymap и т. Д.), А затем сохраните таблицу в файле QVD.
Например, предположим, что у вас есть следующая схема:

Вы не можете сохранить эту модель в одном файле QVD. Оглядываясь назад на наши два варианта:
Хранить как отдельный QVDs
Вы можете немного изменить сценарий, чтобы:
Объедините их в одну таблицу
В зависимости от модели данных вы можете использовать JOINs и другие функции QV:
Погрузка
Чтобы загрузить данные из сохраненного QVDs, вам просто нужно добавить оператор LOAD в свой скрипт, например:
QlikView затем автоматически выведет ссылки на поля в соответствии с вашей исходной моделью, при условии, что имена полей совпадают с именами, сохраненными при хранении таблиц.
Если две таблицы не имеют общих имен полей, просто сохраните их как qvw, и вы сможете сохранить обе таблицы в файле панели мониторинга. Но он является собственностью и может быть открыт только QlikView, но, похоже, у вас уже есть продукт.
Похожие вопросы:
Как я могу создать файл qvd с помощью Qlikview или с помощью другого инструмента и как я могу использовать qlikview с помощью этого файла
Хорошо известно, что мы можем загружать данные из нескольких файлов .qvd в QlikView, используя стандартные символы подстановки DOS ( * и ? ), такие как: MyTable: LOAD * FROM [myDateStampedQvd*.qvd].
Я пытаюсь выяснить, есть ли способ создать семантический слой, подобный тому, что вы можете сделать с каталогами в Cognos и Universe в SAP-Business Objects, в QlikView. Я совершенно уверен, что это.
Может быть, кто-нибудь знает. Могу ли я увидеть через QlikView (что-то похожее на TableViewer) диаграмму с отношениями между моей таблицей в БД и объектами QV (я имею в виду таблицы, созданные в.
У меня есть файл qvd, который содержит данные за два года. Я должен split эти данные в два файла qvd, один из которых принадлежит текущему году, а другой-следующему или прошлому году. Я пробовал.
В SQL мы можем написать запрос типа: Select field1,field2,field3,field4,field5,field6,field7 from table1 t1,table2 t2,table3 t3 where t1.field1 = t3.field3 and t2.field2 = 'USD' В Qlikview я создал.
Я решил свою таблицу фактов с помощью этого поста ( обработка нескольких таблиц фактов в Qlikview )., но у меня есть проблема с таблицами сущностей. Я буду использовать пример в этом посте (.
я соединил две таблицы с левым соединением и сгенерирую qvd. Я бы хотел, чтобы генерировать данные на основе месяца даты. Например, если есть 12 дат с января по декабрь, то будет be 12 файлов qvd.
Я пытаюсь подключиться от QlikView к snowflake, чтобы загрузить данные на qvd Я установил необходимый драйвер: Заполнил все синие пробелы: Попытка подключиться с QlikView : После того как я нажму.
QlikView и его младший брат QlikSense — замечательные BI инструменты, достаточно популярные у нас в стране и "за рубежом". Очень часто эти системы сохраняют "промежуточные" результаты своей работы — данные, которые визуализируют их "дашборды" — в так называемые "QVD файлы". Часто QVD файлы используются в качестве основного хранилища в многоэтапных ETL процессах, построенных на базе Qlik. И тогда у некоторых (у меня, например, — я занимаюсь в компании вопросами инженерии данных) возникает вопрос — можно ли и как воспользоваться этими данными без QlikView/QlikSense? Или другой — а что там и правильно ли "оно" посчиталось?
QVD — это формат файла, оптимизированный для работы QlikView/QlikSense (чтение из запись информации этими приложениями в файлы такого формата происходит существенно быстрее, чем в файлы любого другого формата). Структура этого файла недокументирована и покрыта "мраком проприетарности", практически не существует приложений, которые способны работать такими файлами (читать и тем более писать). В этой серии статей я поделюсь своим опытом и полученными практическими познаниями: я знаю, как устроен QVD, умею напрямую и быстро его читать и в него писать.
Кому будет интересна данная информация: в первую очередь тем, кто работает с QlikView/QlikSense, а также тем, кто (как и я) хотел бы воспользоваться данными, хранящимися в QVD файлах. Ну и, конечно, всем любознательным.
Все, что написано в этой серии, базируется на моем личном опыте, что, разумеется, не является "документацией" или "гарантией" (того, что ваши файлы будут в точности такими, как я описал. Или того, что так это будет вечно). Также не могу гарантировать, что разобрал все случаи — наверняка могут найтись файлы, которые будут содержать что-то, не описанное мной (хотя бы просто потому, что мне такие варианты не попадались). Однако должен заметить, что информация проверена на большом (несколько сотен) наборе файлов, созданных разными людьми из разных систем при помощи разных версий QlikView/QlikSense.
И немного о том, как я это делал: начинал я с простого — небольшой inline пример, сохраняющийся в QVD. Далее — анализ бинарного файла, мозговые усилия, пробы и ошибки. Забегая вперед (я об этом более подробно скажу в заключении серии) у меня получилось достаточно эффективно читать и писать QVD файлы среднего размера (сотни гигабайт). Отправной точкой моего путешествия в мир QVD был вот этот GitHub, большое спасибо автору (пытался с ним связаться — не отвечает).
Какую я преследовал цель (кроме любопытства и желания проверить корректность данных, с которыми работает QlikView/QlikSense) — мне необходимо было прочитать содержимое QVD файла, т.е. воссоздать на его основе реляционную таблицу. И наоборот — выгрузить данные реляционной таблицы в QVD так, чтобы QlikView смог ее корректно загрузить.
Как я вижу эту серию статей
- введение, структура файла, метаданные (эта статья)
- хранение информации о колонках
- хранение информации о строках, достижения, планы
Структура файла
QVD файл создается скриптом QlikView/QlikSense в процессе загрузки данных в память приложения (результат работы команды STORE) и соответствует одной (реляционной) таблице QlikView/QlikSense. Он состоит из двух частей
- текстовой (метаданные) и
- бинарной (колонки и строки)
Метаданные представлены в виде XML (пример будет приведен ниже), бинарная часть начинается непосредственно после текстовой и состоит из двух блоков
- уникальные значения всех колонок (исходной таблицы)
- строки (исходной таблицы), ссылающиеся на уникальные значения колонок

Таким образом для таблицы из N колонок файл будет содержать N + 1 бинарный блок. Все части файла "плотно склеены" и идут друг за другом без каких-бы то ни было заполнителей и "хвостовиков".
Метаданные (XML)
QVD файл содержит достаточно много метаданных — "данных о данных". Он практически самодостаточен, судите сами, вот краткий перечень того, что есть в метаданных (более подробно я опишу их ниже):
- версия ПО, породившего файл
- дата и время создания файла
- файл QlikView/QlikSense, работа скрипта которого привела к созданию файла
- исходный код скрипта, породивший QVD файл
- имя таблицы
- информация о колонках (имена, типы, количества уникальных значений)
- количество строк
Метаданные хранятся в файле в текстовом виде и их можно увидеть в любой программе, которая может показать файл в текстовом виде (ну, почти в любой… в такой, которая не боится файлов больших размеров). Лично я смотрю метаинформацию при помощи more — достаточно удобно.
В дальнейшем изложении я буду использовать тестовую таблицу (использую синтаксис QlikView, но думаю, несложно будет домыслить):
Приведу в качестве примера метаданные для этой таблички
Мой опыт работы с QVD показывает, что структура XML не меняется от файла к файлу.
Прокомментирую наиболее важные элементы метаданных.
Общая информация
QvBuildNo
Номер билда того приложения QlikView/QlikSense, которое породило QVD файл.
CreatorDoc
Как правило содержит имя того QVW файла, скрипт которого породил QVD файл. В данном примере не заполнено, возможно, потому что использовался Personal Edition.
CreateUtcTime
Время создания QVD файла.
SourceCreateUtcTime, SourceFileUtcTime, SourceFileSize, StaleUtcTime
Не видел файлов, в которых эти поля были бы заполнены — пытливому уму: может быть, каких-то настроек не хватает?
TableName
Имя таблицы в QlikView (см. пример выше).
Информация о полях (колонках)
Кстати, слова "поле" и "колонка" для меня являются синонимами, не пугайтесь, если я их буду употреблять оба (постараюсь этого не делать, но все же. ).
Про каждое поле в QVD хранится информация о
FieldName
Имя поля (опять же в терминах QlikView, т.е. с учетом "AS")
BitOffset, BitWidth, Bias
Пока пропустим — это информация для "расшифровки строк", рассмотрим в третьей части, когда будет разбираться со строками.
Type, nDec, UseThou, Fmt, Dec, Thou
Хорошо задуманная (судя по названиям), но абсолютно бесполезная с точки зрения достижения моей цели информация (подробнее — во второй части, где будем говорить о колонках). Почему бесполезная? — тэг "Type" не коррелирует с типом данных, которые хранятся в бинарной части. По нему нельзя восстановить тип колонки (казалось бы — что может быть проще, есть же тэг Type!). В 90% случаев значением этого тэга будет строка UNKNOWN.
В метаданных о колонках бывают еще такие данные (в метаданных примера его нет, видимо, по причине малого размера)
Комментарий в комментариях не нуждается (кстати, в тех файлах, с которыми я работал, 100% пуст. ).
Тэги — тоже бесполезная (с точки зрения восстановления структуры таблицы) информация. Но по ней можно примерно догадаться, какого типа информация хранится в колонке. Я более подробно коснусь типизации во второй части — когда буду говорить о колонках: это важно. Но чуть более сложно, чем мне бы хотелось.
NoOfSymbols
Количество записей в бинарной части, относящейся к данной колонке. Как мы видим — в нашем примере это 5. Очень важная для расшифровки информация.
Offset
Смещение блока данных данной колонки в байтах относительно начала бинарной части файла. Также очень важно.
Length
Длина всего блока данных данной колонки в байтах. Отметим, что бинарное представление элемента колонки (ячейки таблицы) в общем случае имеет переменную длину (строка, например), поэтому длину нельзя вычислить, можно только взять из этого тэга (smile).
Информация о строках
Compression
Никогда не заполнено (в тех данных, с которыми я работал). Возможно, мы не используем эту опцию.
RecordByteSize
Размер записи о строке в байтах. Все строки представлены в бинарном блоке строк в виде битового индекса (об этом подробнее в третьей части), битовый индекс состоит из строк одинаковой длины.
NoOfRecords
Количество строк (в битовом индексе и в исходной таблице).
Offset
Смещение битового индекса (блока с информацией о строках) в байтах относительно начала бинарной части файла.
Length
Длина битового индекса в байтах.
В метаданных о строках бывают еще такие данные (опять же — короткий пример не позволяет увидеть все, но зато позволяет разобраться в сложном)
Не буду здесь слишком вдаваться в суть, она примерно понятна (исходные SELECT-ы, которые породили таблицу в QlikView), до конца я в этом еще не разобрался (иногда они двоятся)… (кроме одного — комментариев 100% нет (smile)).
Подытожим
- QVD файл является самодостаточным (т.е. его можно анализировать в отрыве от других данных)
- QVD файл состоит из текстовой (метаданные) и бинарной (колонки и битовый индекс) частей
- метаданные — это XML с вполне понятной семантикой
Любознательный читатель вправе тут спросить: "Пока не прозвучало ничего нового, все вышесказанное можно взять и посмотреть в XML заголовке QVD файла… Об этом уже неоднократно писали в разных интернетах, в чем новизна?". Все верно — первая часть практически полностью посвящена метаданным. Но это — не конец.
Что дальше — в следующей части мы подробно рассмотрим структуру бинарной части QVD файла, содержащего информацию о колонках (уникальные значения всех колонок таблицы).
QVD файлы составляют важную часть многих реализаций Qlik и являются идеальным способом хранения данных как в Qlik Sense, так и в QlikView. Однако вы можете не знать о том, что есть XML-заголовки для этих файлов, содержащие полезную информацию. Эта статья содержит описание XML-заголовков этот заголовок ссылки на загрузку вспомогательных утилит и описание способов их использования в Qlik Sense и QlikView.
Зачем использовать QVD файлы?
Этот вопрос мы уже подробно рассматривали в других наших статьях, поэтому здесь мы не будем подробно останавливаться на этом вопросе. Просто хотим еще раз сказать, что QVD файлы представляют собой метод наилучшей практики разделения уровней ETL и уровня представления данных в реализации приложений Qlik, они также необходимы для дополнительных нагрузок. Преимущества разбивки этапов ETL на отдельные задачи с QVD в качестве промежуточного файла — это то, благодаря чему различные части вашего кода могут быть протестированы и запускаться отдельно (что может ускорить разработку). Преимущества инкрементных нагрузок более очевидны, и вам нужно всего лишь вытащить последние или измененные данные из вашего источника данных, а остальные — из предварительно сохраненных QVD.
Что находится в XML-заголовке?
Самый простой способ узнать, что вам доступно в заголовке QVD, — это посмотреть. Если вы просто загрузите QVD в текстовый редактор, вы найдете заголовок вверху. Будьте осторожны, возможно, это не так разумно для очень больших QVD!

Когда вы посмотрите вниз по этому заголовку, вы найдете много полезной информации, включая приложение, которое создало QVD, информацию обо всех полях в QVD, содержимое этих полей и количество строк.

Загрузка XML-заголовка
Ниже, в этой статье, мы подробно опишем содержание этого заголовка и о том, как загрузить XML-заголовки QVD QlikView (загрузка заголовка в Qlik Sense выполняется аналогичным образом).
Просто создайте библиотеку, указывающую, где находятся ваши QVD (или вы, вероятно, уже это сделаете). Щелкните значок «Выбрать данные» точно так же, как и чтобы загрузить содержимое из QVD. Затем Qlik Sense корректно идентифицирует этот файл как QVD и предлагает прочитать его как распознанный формат файла. Используя раскрывающийся список, вы можете переопределить это, и сказать, что хотите загрузить часть XML-файла. Как только вы это сделаете, вы увидите заголовок XML в предварительном просмотре.
Когда вы нажмете «Вставить скрипт», код для загрузки заголовка QVD будет вставлен в ваш сценарий загрузки.
Мы заметили, что Qlik Sense может получить предварительный просмотр и код неправильно для больших QVD, но код одинаковый для любого QVD — сгенерируйте код на небольшом QVD, а затем укажите его на более крупный, который вам нужно прочитать.
Инструменты для просмотра заголовков QVD
Одним из инструментов, который я всегда рекомендую нашим клиентам, является QViewer, эта утилита позволяет вам дважды щелкнуть файл QVD и просмотреть содержимое. Он также имеет пункт меню, чтобы открыть метаданные этого QVD, видя значения, упомянутые выше. Еще один инструмент, который недавно привлек наше внимание, — это NodeGraph. Эта утилита, представляет собой совершенно потрясающий инструмент, и мы надеемся, что в ближайшее время она будет развиваться.
Однако, как мы уже писали выше, просматривать данные структуры QVD можно непосредственно в QlikView или Qlik Sense. Здесь данные заголовка QVD могут быть загружены вместе с другими данными и доступны для пользователей через тот же Hub или AccessPoint, к которым они уже привыкли. И этот способ не требует дополнительного лицензирования и может использоваться у клиентов.
Подробнее о QVD-файлах
QVD-файлы являются основой любого хорошо разработанного приложения QlikView. Вы храните свои данные и читаете их снова — просто.
Файлы QVD являются файлами XML
Если вы когда-либо были достаточно любопытны, чтобы открыть QVD-файл в текстовом редакторе, вы могли увидеть, что файл начинается с фрагмента XML. Если вы этого еще не сделали, почему бы не сделать это сейчас? Когда вы просматриваете заголовки, вы увидите некоторую базовую информацию, например, время создания QVD. Далее в заголовке указано количество строк в файле. Вы можете быть уверены, что эти значения можно отнести к использованию нескольких функций, например:
QvdNoOfRecords ( 'C: \ QlikView \ Data \ MyQVD.qvd');
QvdNoOfFields ( 'C: \ QlikView \ Data \ MyQVD.qvd');
Также в заголовке файла вы найдете информацию о структуре поля QVD и линейке QVD (начальные операторы SELECT или LOAD, которые пошли на сборку QVD. В целом это очень интересно посмотреть в текстовом редакторе, однако Qlik не предоставил нам никаких функций для извлечения этих данных.
После заголовка, QVD превращается в двоичный файл для хранения самих данных.
Получение XML из QVD
Вы можете знать, что вы можете загружать данные из XML-файла в Qlik. Таким образом, следует, что вы можете загрузить XML из своего QVD в таблицу. И действительно, вы можете.
Когда вы нажимаете кнопку «Файлы таблицы» в QlikView и выбираете QVD, QlikView автоматически меняет загрузку данных QVD и показывает вам контент:
Прямо под переключателем QVD есть выбор для XML. Когда вы нажимаете эту кнопку, отображается другой вид QVD:
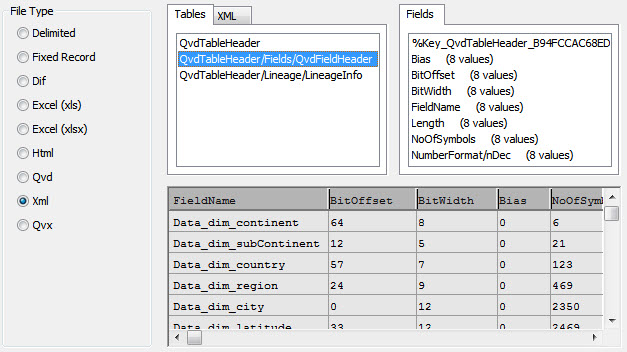
Вы увидите, что есть таблицы, которые вы можете выбрать: содержащие информацию заголовка, информацию о полях и данных. Информация о поле для QVD показана выше, вы можете щелкнуть по другим таблицам, чтобы просмотреть их содержимое.
При нажатии кнопки «Готово» код загружается из заголовков XML в ваш сценарий загрузки. Сценарий для информации о поле выглядит следующим образом:
Когда вы сохраняете и перезагружаете, у вас есть таблица, показывающая все поля вашего QVD.
Загрузка из нескольких файлов
Это дает нам простой способ получить некоторую информацию QVD в документе Qlik (QlikView или QlikSense). Но что, если мы хотим просмотреть информацию для всей папки, с несколькими QVD-файлами? Мы можем просто перебрать их циклом. Перебор выполняется с помощью цикла for / next в инструкции FileList. Для каждого файла мы хотим взять имя и добавить его в качестве поля. Код (после очистки) выглядит следующим образом:
Если вы также хотите добавить некоторую информацию из заголовка, например, такую как количество строк, вы можете добавить еще один оператор в цикле, чтобы вывести эти значения:
В завершении вы также можете вытянуть таблицу данных для каждого файла. Вы заметите, что все таблицы будут ассоциироваться в поле «Имя файла», так как мы сохраняем это одинаково между таблицами.
С помощью этих утверждений вы можете создать несколько разных диаграмм и таблиц по данным. Вы можете использовать полученное приложение для ответа на целый ряд вопросов о вашем слое данных, например:
- У каких QVD больше всего строк?
- Какие QVD имеют большинство полей?
- Какое название поля наиболее распространено в QVD?
- Какое приложение QVDCreator создало QVD для клиентов?
Пример из практики
Недавний прецедент, который я использовал для профилирования всех QVD в реализации, был для миграции решения с одного сервера на другой. После периода параллельного запуска нам необходимо было обеспечить, чтобы данные во всех QVD были одинаковыми на старом сервере и на новом сервере. Помещая дополнительный цикл вокруг этих операторов, чтобы посмотреть в двух местах, называя места в каждой таблице и используя составной ключ (местоположение и имя файла); Я создал приложение, которое профилировало QVD с обоих серверов. Несколько простых прямых таблиц позже, и я смог с уверенностью сказать, что QVD имеют одинаковые строки на обоих серверах.
Помимо того, что вы заинтересованы, вы можете обнаружить, что вы можете превратить приложение в полезную часть документации для ваших пользователей. Они могут найти, где поля находятся в QVD, особенно полезно, если вы собираетесь, например, позволить им самостоятельно работать в QlikSense.
Надеюсь, вы найдете эту статью полезной для себя, и она укажет вам на новые способы максимально использовать ваши QVD.

Сегодня расскажу о весьма полезном инструменте, QViewer, с описанием кейсов его использования на практике.
QViewer: что это такое
Инструмент QViewer позволяет быстро просмотреть файлы QVD. Он позволяет получить доступ к мета-данным QVD, а также искать и фильтровать данные по строкам. А если к нему еще добавить EasyMorph, то будет возможно и изменить содержимое QVD. Возможность быстрого просмотра этих файлов экономит массу времени. Инструмент создан Дмитрием Гудковым, один из списка Qlik Luminary.
НА ЗАМЕТКУ! QVD – специальный формат файла для хранения данных о таблицах приложений Qlik.
QVD: из какого это приложения
Часто в работе получается так, что набирается масса QVD, когда определить первоисточник и, из какого он взят приложения, сложно. А с помощью QViewer можно легко получить эту информацию. Открываем файл QVD двойным щелчком мыши, а затем выбираем мета-данные (клавиша F4). Так, будет виден путь к qvw, а также основные источника данных и выражения SQL.
В этом же окне будет информация с размером файла, количеством полей и строк.

Мета-данные: возможность оптимизации
QViewer позволяет провести оптимизацию мета-данных. Для этого откройте QViewer и нажмите F5. Так, откроется обзорная таблица с мета-данными, в которой будет видно количество уникальных значений, удельный вес, размер в байтах. Отсортируйте поля по байтам, вы увидите самые ресурсоёмкие поля.

Затем выберите поле (F2), чтобы увидеть их значения. Вот, например, ссылка ниже занимала 13 мб в документе – это стоит оптимизировать.

В таблице также будут представлены комментарии по полям QVD:

Вот, как это выглядит в QViewer:

Проверка данных
Когда проводишь процесс ETL, то обычно проходит немало времени.

При этом, например, для проверки, вместо очередного запуска QlikView для загрузки QVD и проверки его работы, я открываю его в QViewer. Так, более миллиона записей загрузится за 17 секунд.
![]()
Трансформации в QViewer с помощью EasyMorph
EasyMorph – инструмент ETL, который позволяет проводить трансформации в источниках данных, включая MS SQL Server, SQLite и ODBC. Полезный инструмент для тех BI-систем, где не встроен механизм ETL.

Просмотр ранее загруженных таблиц
Бывает так, что нужно просмотреть ранее загруженные таблицы Qlik. И, конечно, хочется видеть эту таблицу в связи с конкретной частью скрипта.
Используя подпроцедуру <add link>, можно вызвать скрипт для экспорта любой ранее загруженный таблицы в QVD с запуском скрипта:

После этого запускается подпроцедура там, где вы хотите создать файл QVD.

Когда вы выполните скрипт, скрипт QlikView запустится непрерывно, а QViewer откроется в другом окне, когда будет обращение к ранее загруженной таблице.

QViewer: попробывать
Для пользователей доступен демо-доступ к утилите, но в ней есть ограничение. Вы сможете загрузить только 100 000 записей.
Читайте также: