
Как посмотреть байты в файле
Обновлено: 29.06.2024
Как оказалось, узнать размер файла в языке C - совсем нетривиальная задача. В процессе её решения как минимум вы обязательно столкнетесь с переполнением целочисленного типа данных. В данной статье я приведу 4 способа получения размера файла с использованием функций из стандартной библиотеки C, функций из библиотеки POSIX и функций из библиотек Windows.
Способ 1: решение "в лоб" (скомпилируется везде, но работает очень долго)
Мы просто откроем файл в бинарном режиме и в цикле считаем из него байт за байтом.
Очевидным недостатком способа является скорость работы. Если у нас файл будет на много гигабайт, то только размер файла будет считаться относительно долго (это сколько байт то надо считать?), а надо же еще остальную программу выполнять.
Достоинство такого способа - работать должен на любой платформе. Ну и конечно можно ускорить процесс за счет считывания бОльшего количества байт.
Способ 2: с использованием функций fseek и ftell (ограничен для объемных файлов и работает не всегда верно)
Данный способ основан на использовании функций стандартной библиотеки C: fseek и ftell. Что происходит - открываем файл в бинарном режиме, перемещаем внутренний указатель положения в файле сразу в конец с помощью fseek, получаем номер последнего байта с помощью ftell.
Проблем у данного способа несколько.
Первое - это возвращаемый тип функции ftell. У разных компиляторов на разных платформах по разному. Если у вас 32х битная система, то данный способ будет работать только для файлов, размером меньше 2048 Мб, поскольку максимальное значение для возвращаемого функцией типа long там будет 2147483647. На системах с большей разрядностью будет работать лучше, из-за большего значения максимума для long. Но подобная нестабильность будет мешать. Хотя у меня на 64х битой системе на компиляторе gcc данный способ для файлов больше 8 Гб выводил некорректные значения.
Второе - гарантированность работы fseek и ftell. Коротко говоря, на разных платформах работает по-разному. Где то будет точно возвращать значение положения последнего байта, где то будет возвращать неверное значение. То есть точность данного способа негарантированна.
Плюсом является то, что эти функции из стандартной библиотеки - скомпилируется почти везде.
Стоит сказать, что хитрые инженеры из Microsoft придумали функции _fseeki64 и _ftelli64, которые, как понятно из их названия, работают с int64, что решает проблему с размером файла в MSVC под Windows.
Способ 3: (под Linux (POSIX))
Данный способ основан на использовании системном вызове fstat с использованием специальной структуры struct stat. Как работает: открываем файл через open() или fopen(), вызываем fstat для дескриптора файла (если открыли через fopen, то в fstat надо положить результат fileno от указателя потока FILE), указав на буферную структуру для результатов, и получаем значения поля буферной структуры st_size.
У меня есть файл размером чуть больше 500 МБ, который вызывает некоторые проблемы.
Я считаю, что проблема в соглашении конца строки (EOL). Я хотел бы посмотреть на файл в его неинтерпретированной необработанной форме (1), чтобы подтвердить соглашение EOL о файле.
Как я могу просмотреть «двоичный» файл, используя что-то встроенное в Windows 7? Я бы предпочел не загружать что-либо дополнительное.
(1) Мой коллега и я открыли файл в текстовых редакторах, и они показывают строки, как и следовало ожидать. Но оба текстовых редактора будут открывать файлы с различными соглашениями EOL и интерпретировать их автоматически. (TextEdit и Emacs 24.2. Для Emacs я создал второй файл с использованием только первых 4K-байтов head -c4096 в окне Linux и открыл его из окна Windows.
Я попытался использовать hexl-режим в Emacs, но когда я перешел в hexl-режим и вернулся в текстовый режим, содержимое буфера изменилось, добавив видимый ^ M в конец каждой строки, так что я не доверяя этому на данный момент.
Я полагаю, что проблема может быть в конце строки символов. Редакторы, которые мы с коллегой пытались (1), просто автоматически определили в конце строки и показали нам строки. И на основании других доказательств я считаю, что конвенция EOL касается только возврата каретки. (2) вернуть только.
Чтобы узнать, что на самом деле находится в файле, я хотел бы взглянуть на двоичное содержимое файла или, по крайней мере, на пару тысяч байт файла, предпочтительно в шестнадцатеричном формате, хотя я мог бы работать с десятичным или восьмеричным. На один ноль было бы довольно грубо смотреть.
ОБНОВИТЬ
За исключением предложенного DEBUG , все ответы ниже в той или иной степени работают. Я проголосовал за каждого из них как полезного. Мой вопрос был плохо сформирован. При тестировании каждого предложенного решения я обнаружил, что я действительно хотел, чтобы рядом просматривался шестнадцатеричный и текстовый контент, и что я хотел, чтобы это было что-то, где когда я наводил курсор на что-либо, либо на байтовое значение, либо на текстовый символ, то, что соответствовало на другая сторона будет выделена.
Все файлы на диске хранятся в виде двоичного (бинарного) кода. Последовательность цифр 1 и 0 определяет содержимое файла. В одном случае эти цифры могут составлять простой текст, в результате чего мы видим обычные текстовые файлы. В другом - это последовательность байт, которая несет самую разную информацию, например: аудио, видео, картинки или закодированный текст. Откройте в текстовом редакторе файлы .TXT и .EXE и вы почувствуете разницу.
В данной статье рассказано каким еще способом (кроме непосредственно расширения файла) можно идентифицировать формат двоичного файла, который не является обычным текстовым. Таких файлов большинство. Именно в них часто есть заголовок файла - это первые несколько байт в определенной последовательности. Часть заголовка может быть одинакова у файлов с одинаковым расширением. Эта часть отвечает за формат файла, для удобства назовем ее «дескриптор заголовка файла» (description с англ. - описание).
Таким образом, если необходимо более точно идентифицировать формат файла или файл переименован и его истинное расширение неизвестно, то узнать что это за файл можно с помощью дескриптора заголовка файла. У нас на сайте дескрипторы представлены в трех видах: HEX, ASCII и ASCII (расширенный). Опишем преимущества каждого представления.
HEX и ASCII. Чтобы определить дескриптор заголовка файла и, соответственно, формат файла, необходима программа, которая представляет файл в виде HEX (шестнадцатеричного кода). Это может быть любой HEX-редактор. Но лучше всего для наших целей подойдет программа MiniDumper (20 Кб).
Скачиваем программу, распаковываем ее, открываем. Далее нажимаем кнопку «Select file…», выбираем файл и видим следующее:
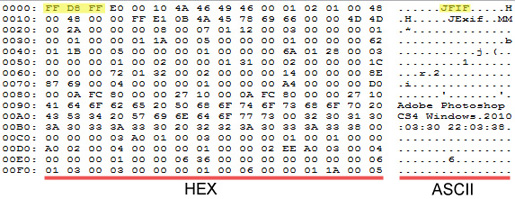
Берем первые 2-3 блока из левой колонки (HEX) или первые символы (точки не учитываем) из правой колонки (ASCII), как показано на рисунке; вводим в соответствующее поле расширенного поиска и получаем результат:
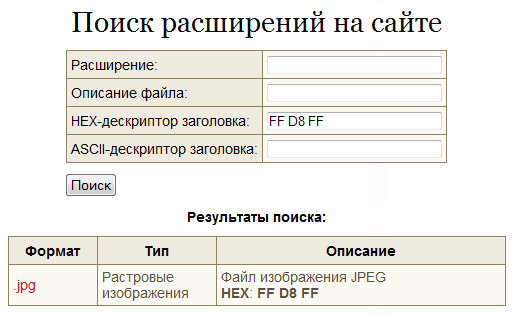
Если расширений найдено много, то можно увеличивать количество блоков до достижения однозначного результата. И наоборот, если Вы ничего не нашли, то следует уменьшить количество блоков.
ASCII (расширенный). ASCII с расширенной таблицей символов - кириллицей и специальными символами. Этот вариант специально создан для ленивых: просто откройте файл с помощью блокнота и ищите первые от начала значащие символы. Например:
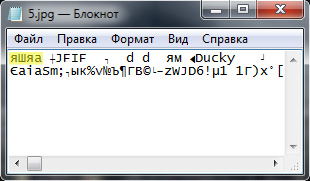
Далее, вставляем эти символы в соответствующее поле расширенного поиска и получаем результат:

Обращаем ваше внимание, что наиболее точным и продуктивным из всех трех вариантов будет поиск по HEX-декскрипторам, т.к. некоторые последовательности байт невозможно перевести в корректный ASCII-код и HEX-значения мы берем точно из начала файла.
Сканирование байтов в памяти, и получение начального адреса байтов
Привет форумчане! У меня вопрос, как просканировать память у процесса так, чтобы получить адрес.

Добавлени и удаление байтов у файла
Здравствуйте, мне нужно прибавить к исполняемому файлу несколько байт, что бы он не запускался, а.
Чтение байтов из файла
Здравсвуйте! Есть файл в котором записвны числа 1234567890. Есть такой код int amount, sum = 0; .
Здесь есть программа, которая делает это.
Если коротко, то:
Могу перепутать, так как набиваю сразу сюда, но суть в том, что fs.Read(buffer, 0, n) считывает в байтовый массив buffer n байт из файла fileInfo, начиная с позиции 0 в файле.
К тому же fs.Read возвращает кол-во считанных байт.
То есть если n байт считались успешно, то будет верно утверждение, что fs.Read(buffer, 0, n) == n; Но с этим аккуратнее, файлы больше 2 Гб так не откроются. Но с этим аккуратнее, файлы больше 2 Гб так не откроются.
у меня больше 100мб и не набирется
Добавлено через 6 минут
Error 1 The best overloaded method match for 'System.IO.Stream.Read(byte[], int, int)' has some invalid arguments C:\test3\test3\Form1.cs 39 7
Мне кажется, просто метод в основном потоке запускается, и программа визуально "подвисает" на долгое время.
Добавлено через 5 минут
Error 1 The best overloaded method match for 'System.IO.Stream.Read(byte[], int, int)' has some invalid arguments C:\test3\test3\Form1.cs 39 7 Это означает, что ты передал в метод какой-то/какие-то неподходящие аргументы. Посмотри, что надо писать в вызов этого метода на МСДН, там раздел Синтаксис - Параметры.
у меня больше 100мб и не набирется
Добавлено через 6 минут
Error 1 The best overloaded method match for 'System.IO.Stream.Read(byte[], int, int)' has some invalid arguments C:\test3\test3\Form1.cs 39 7
Так как по умолчанию длина не в Int хранится.Да, именно так. По умолчанию длина хранится в long, поэтому мы сначала конвертируем из long в int, а потом уже скармливаем ридеру.
Чтение и запись байтов из файла
Подскажите пожалуйста каким образом магу прочесть .дат файл чтобы прочесть байты и обратно.
Получить массив байтов файла
Есть такой код конвертера фаилов в байты: using System; using System.Collections.Generic;.
Чтение байтов с конца файла
У меня есть текстовый файл размером к примеру 35 кб мне надо считать 1 кб с конца файла .
Ошибка при чтении байтов из файла
Добрый день! Подскажите пожалуйста, что я делаю не так. Редактор выдаёт ошибку: "Невозможно.
Читайте также: