
Как посмотреть структуру файла
Обновлено: 07.07.2024
Файловая структура *nix-систем серьёзно отличается от структуры в Windows и заслуживает отдельного внимания. Начнём с базовых понятий. Файловая структура представляет собой дерево, в узлах которого находятся директории (файлы специального типа), а в листьях — файлы.
Кстати, понятие "папка" в *nix-системах не используется, говорят "директория" или "каталог", хотя по существу эти термины означают одно и то же.
В Windows мы привыкли, что имя файла может быть набрано в разных регистрах, и это всегда один и тот же файл, то есть имена регистронезависимы. В *nix-системах регистр имеет значение. Файлы index.html , Index.html , INDEX.HTML и index.HTML — это разные файлы. Всегда обращайте внимание на регистр, потому что ошибиться довольно легко.
macOS в этой ситуации идёт по пути Windows и тоже не учитывает регистр
Говорят, что в *nix "всё есть файл". На нижнем уровне так и есть (почти). Директория — это специальный файл, который содержит список файлов. Любое подключаемое устройство становится файлом или директорией, если это накопитель. Такая концепция довольно удобна для разработчиков, потому что печать на принтер и вывод на экран между собой ничем не отличаются — для кода это просто "запись в файл". На пользовательском уровне директория всё же отличается от файла и имеет собственные команды для создания, удаления и модификации.
Не во все директории можно заходить, не все файлы можно читать или менять, и не все программы можно запускать. В *nix-системах развитая система прав, завязанная на пользователей и группы. О ней мы поговорим отдельно позже. Сейчас достаточно знать, что такие ограничения есть. Их можно увидеть в выводе команды ls -l .
В отличие от Windows, в *nix-системах отсутствует понятие "расширение файла". Точка — полноправная часть имени. Это не значит, что в юниксах невозможно понять тип файла. Это возможно, более того, файлы почти всегда именуются так же, как и в Windows, например hello.mp3, но важно понимать, что вся эта строчка — имя файла. Нередко встречаются и такие имена: index.html.haml . В *nix также есть скрытые файлы, но, в отличие от Windows, это не свойство файла, а определённое имя файла. Все файлы и директории, начинающиеся с точки, считаются скрытыми. Вывести все файлы, включая скрытые, можно командой ls -a :
Обратите внимание на две особые директории, обозначенные "точкой" ( . ) и "двумя точками" ( .. ). Точка означает текущую директорию, а две точки — директорию верхнего уровня. Именно благодаря этой схеме работает команда cd .. , которая перемещает нас на уровень выше.
Кроме обычных файлов, в *nix существует ряд других:
- Hard Link — дополнительное имя для уже существующего файла.
- Symbolic link — символическая ссылка, такой файл похож на ярлык в Windows. Если удалить основной файл, то символическая ссылка начнёт вести в никуда.
- Socket — специальный файл, через который происходит взаимодействие между разными процессами операционной системы. Программисты постоянно сталкиваются с сокетами в реальной жизни.
Это наиболее важные на начальном этапе знакомства с файловой системой типы файлов. Есть ещё и другие типы, но не будем сейчас заострять на них внимание.
Для каждого формата файла существует формальное описание, стандарт. Стандарты могут быть открытые (описание опубликовано) и закрытые (описание держится в секрете). Часто открытые типы можно узнать по расширению имени (.bmp, .mp3, .pdf). Описание закрытых форматов иногда можно найти на форумах. Некоторые форматы содержат сигнатуру - несколько байтов в начале - по которым их можно узнать. Например, "rar", "PK" (zip), "%PDF", "BM" (bmp), "II" или "MM" (tiff). Сигнатура может быть и двоичной.
Вскрыть неизвестный формат - это сложная хакерская задача. Как сказал PAV , это процесс творческий и не формализуемый .
Для каждого формата файла существует формальное описание, стандарт. Стандарты могут быть открытые (описание опубликовано) и закрытые (описание держится в секрете). Часто открытые типы можно узнать по расширению имени (.bmp, .mp3, .pdf). Описание закрытых форматов иногда можно найти на форумах. Некоторые форматы содержат сигнатуру - несколько байтов в начале - по которым их можно узнать. Например, "rar", "PK" (zip), "%PDF", "BM" (bmp), "II" или "MM" (tiff). Сигнатура может быть и двоичной.Спасибо про это знаем.
Вскрыть неизвестный формат - это сложная хакерская задача. Как сказал PAV , это процесс творческий и не формализуемый .Вот как раз я про это и хотел спросить в первом посте.
Просто возможно я тупо написал вопрос. Написал что-то типа ребуса, хотя можно было так просто.
Каким способом хакеры взламывают формат. Т.е. по сути им надо определить структуру файла, а сам формат не столь важен. Его можно любым hex редактором просмотреть в заголовке файла(впринципе как написано выше).
Да и если никто не хочет отвечать, понимаю. Все просто умные настолько, что объяснить даже не в состоянии. Да все начинали с малого(просто все себя уже считают отличными кодерами), а помочь то друг другу вряд ли кто хочет.
Во-первых, смотрят на него в hex-редакторе и исходя из своего богатого опыта, сравнивая с уже известными им форматами, могут многое про него узнать. Но если формат не похож на остальные, то этот способ ничего не даст.
Во-вторых, берут программу, которая этот формат записывает (или там аппаратное устройство), подают этой программе на вход различные параметры и смотрят, какие файлы получаются на выходе. Сравнивая файлы, находят отличия, и если формат несложный и незашифрованный, то можно "расколоть" если не весь формат, то его часть.
В-третьих (если формат сложный или зашифрованный) взламывают программу или аппаратное устройство (например, запускают программу под отладчиком, находят в ней место, в которой происходит ввод параметров, и прослеживают путь этого параметра до записи в файл; либо передавая программе доступные корректные файлы этого формата, прослеживают обратный путь: от чтения файла до какого-либо обнаружения его содержимого). Расшифровка формата получается как побочный эффект взлома программы либо устройства.
Возможно даже, что я тут перечислил все способы. Не исключаю, что если ни один из них осуществить не удастся, то ни один хакер больше ничего не сможет сделать.
берут программу, которая этот формат записывает (или там аппаратное устройство), подают этой программе на вход различные параметры и смотрят, какие файлы получаются на выходе. Сравнивая файлы, находят отличия, и если формат несложный и незашифрованный, то можно "расколоть" если не весь формат, то его часть.Какую программу берут?
И каким образом происходит *раскол*?
Я имею в виду, что Ваш файл не сам по себе нас интересует, с какой-то целью? Он, наверное, используется какой-то программой? Например: файл сохранения для компьютерной игры; Вы его хотите понять, чтобы поменять и сделать себе бесконечное число жизней. В данном случае программой выступает игра, которую и хочется обмануть (её и нужно запустить под отладчиком), а файл --- лишь средство.
Или вот ещё пример: файл содержит информацию о том, с какого банковского счёта, на какой и сколько перевести денег. Хочется его подделать, чтобы 0.01% средств со счёта ОАО "Газпром" попали на наш счёт. "Газпром" большой, для него такая сумма всё равно ничего не значит, а нам бы она очень даже не помешала. Здесь "программой" будет информационная система банка. Однако в данном случае есть подозрения, что нам её просто так не дадут погонять под отладчиком, и этот метод реализовать сложнее.
Чтобы сориентироваться в разнообразных средствах взлома разнообразных систем, Вам, действительно, нужно обращаться на специализированные (хакерские) форумы. Здесь если и есть подобного рода специалисты, то вряд ли они будут Вам подсказывать конкретные средства и приёмы. Хотя бы потому, что подобная деятельность, вообще-то, уголовно наказуема. Я имею в виду, что Ваш файл не сам по себе нас интересует, с какой-то целью? Он, наверное, используется какой-то программой? Например: файл сохранения для компьютерной игры; Вы его хотите понять, чтобы поменять и сделать себе бесконечное число жизней. В данном случае программой выступает игра, которую и хочется обмануть (её и нужно запустить под отладчиком), а файл --- лишь средство.
Вы правы речь идет об игре, только она в данном случае под приставку. И как знаете у нее нет как такового exe файла, запускается напрямую из биоса(приставка дримкаст, благо есть норм. эмуляторы).
Файл содержит в себе текстуры, модели(точно не уверен). Но как таковой он содержит информацию(координаты текстур и модели), после чего передает информацию процессору и он подгружает это в игру.
Так вот собственно файл этот я и хочу попробывать взломать. Написать програмку(но вот структуру файла увы не знаю ). Экспортер текстурок есть, а моделек нет.
Отладчик вроде есть на эмуле.
Да и простите за столь назойливые вопросы.
Да и если это так наказуемо(хотя японцы вряд ли сюда полезут), то можно в личку.
Файлы… что вообще может быть проще? Мы все привыкли создавать, удалять, редактировать, перекидываться файлами.
Но можем ли мы заглянуть внутрь каждого файла и понять как он устроен? Конечно можем, поэтому сегодня мы немного покопаемся в бинарном коде и пощупаем метаданные.
Заодно узнаем, почему iPhone зависает от SMS и распотрошим PowerPoint.
Почему форматов файлов так много?
Если бы мы просто могли взглянуть на сырые данные, которые хранятся внутри жесткого диска или SSD, то мы бы не увидели никаких файлов: мы бы увидели только нолики и единички. Потому как, в любом случае, в памяти компьютера всё хранится в виде сплошного потока двоичного кода.
Но как же тогда понять, где заканчивается один файл и начинается другой?
Поначалу эту проблему человечество решало брутально. Люди записывали один файл на один жесткий диск, чтобы уж точно не ошибиться. Поэтому раньше словом файл называли не отдельную область на жестком диске, а прям целое устройство. К примеру IBM 305.

CTSS (Compatible Time-Sharing System)
Но потом, люди придумали файловые системы. Если очень упростить, это такое оглавление в котором указано имя файла, где он начинается и его длина. А также всякие метаданные, типа время создания, изменения, и можно ли его перезаписывать.

Но для того чтобы прочитать файл, знать его местоположение и границы на жестком диске недостаточно, ведь нам нужно как-то расшифровать бинарный код.
Для этого и существуют различные форматы файлов. В большинстве операционных систем форматы файлов указываются в виде расширения, которое отделяется точкой от имени файла. А если вы не видите расширения, это нормально. Потому что, по умолчанию, современные ОС их скрывают, но можно поставить галочку в настройках.
Расширение даёт подсказку операционной системе и программам, о том какой тип данных он содержит и как это всё структурировано. Например, увидев файл droider.jpg операционная система и мы, люди, сразу понимаем, что это картинка в формате JPEG.
Естественно, для типов данных и разных задач оптимальной будет разная структура файла. Поэтому и форматов файлов существует огромная масса.
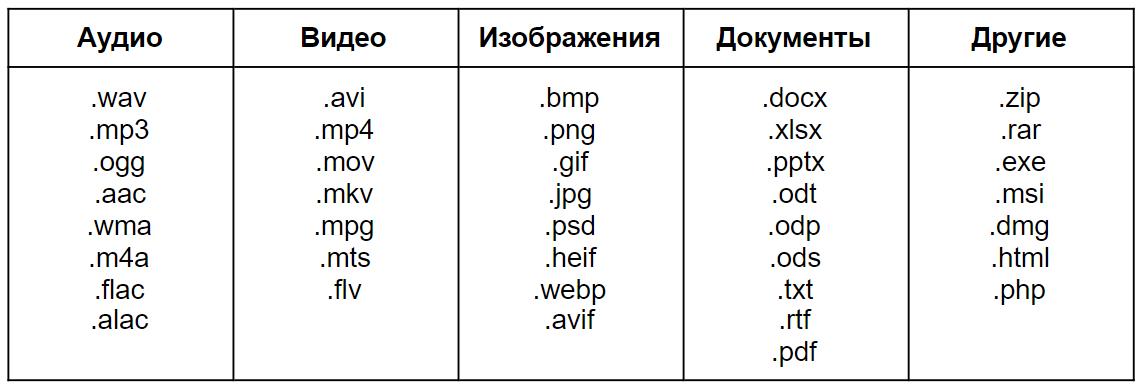
Поэтому давайте разберем, как устроены наиболее популярные форматы файлов от более простых к более сложным.
Каждый символ в TXT-формате хранится в виде бинарного кода.
То что мы с вами видим как осмысленный текст, операционная система видит вот так:
01001000 01100101 01101100 01101100 01101111 00101100 00100000 01110111 01101111 01110010 01101100 01100100 00100001
Подобрав правильную кодировку остается дело техники. Система сопоставляет бинарный код с таблицей кодировки UTF-8 и готово! Но что будет если система подберет кодировку неправильно? Вариантов не много, скорее всего мы увидим крякозябры:
И такое часто случается, так как TXT-файл не содержит никакой дополнительной информации о кодировке. И это большой недостаток формата.
И вдобавок, эту таблицу нужно было загрузить в оперативную память при загрузке компьютера, а у типового ПК в начале 80-х годов редко было больше 640 килобайт оперативки. А использовать 16-битные таблицы (65536 вариантов) было просто невозможно, такая таблица просто не влезла бы в память.
Но мощность компьютеров росла и проблема ушла. К таблицам с латинскими символами добавились кириллические, которые занимали уже не по 8 бит, а по 16 бит каждый. Поэтому текст на русском занимает в два раза больше памяти, при том же количестве символов.
11010000 10011111 11010001 10000000 11010000 10111000 11010000 10110010 11010000 10110101 11010001 10000010 00101100 00100000 11010000 10111100 11010000 10111000 11010001 10000000 00100001
11010000 10011111 — П
11010001 10000000 — р
10111000 11010000 — и
11010000 10110010 — в
Старики помнят лайфхак, если писать SMS на латинице, то влезет в два раза больше текста. Всё это как раз из-за кодировки.
Так вот, чтобы у операционной системы не было проблем с пониманием как прочитать файл. Помимо самих данных, в разные форматы стали добавлять данные о данных. То есть метаданные, которые хранятся прямо внутри файла и содержат дополнительную информацию о том, как этот файл прочитать.
Это простой аудиоформат, который содержит несжатый. Всё CD диски записаны в формате WAV.

Первые 44 байта классического WAV-файла содержат заголовок, к котором указывается полезнейшая информация:
- количество аудио каналов,
- частота дискретизации,
- битовая глубина
- и многое другое.
Все эти данные позволяют быть уверенным, что аудио будет воспроизведено корректно.
Открытые и проприетарные форматы
Структура WAV хорошо известна и наверное такой файл сможет прочитать практически любой плеер. Всё потому, что WAV-файл — это пример открытого формата.
Есть и другие открытые форматы, которыми вы ежедневно пользуетесь. Например:
Но бывают и закрытые форматы файлов, а точнее проприетарные. Открытие и редактирование таких файлов сторонним софтом часто либо вообще запрещено, либо распространяется по лицензиям.
Проприетарные форматы всем прекрасны, но в отдельных случаях они препятствуют конкуренции в сфере программного обеспечения, так как приводят к замыканию на поставщике. Есть даже такой термин Vendor lock-in.
Старый офис
Например, раньше такая ситуация была с форматами Microsoft Office: DOC, XLS, PPT.
Такая ситуация не очень нравилась Европейскому Союзу. Поэтому, ЕС взъелся на тему ограничения конкуренции. В итоге, форматы файлов опубличили, и все научились хотя бы их читать, но для записи в старые форматы, по-прежнему, нужна лицензия Microsoft. И параллельно этому начали разрабатываться открытые форматы.
ODF и OOXML
1 мая 2006 года на свет появился формат формат ODF, что буквально расшифровывается как открытый формат документов для офисных приложений. Он был разработан консорциумом OASIS и Sun Microsystems.
- ODF — Open Document Format for Office Application
- OASIS — Organization for the Advancement of Structured Information Standards
Формат основан на универсальном языке разметки XML. А сам файл ODF представляет из себя ZIP-архив с папками, XML-файлами и всякими вложениями в виде картинок, видео и прочим. Иными словами, если открыть такой файл через архиватор мы можем спокойно увидеть все внутренности. Вот так пример открытости!

Microsoft тоже не спал. Под давлением Европейского суда они объединились с рядом компаний в ассоциацию ECMA и разработали свой открытый формат Office Open XML, который появился на свет чуть позже в 2006 году.
OOXML стандартизирован European Computer Manufacturers Association. Standard ECMA-376
К привычным форматом конце добавилась буква X и мы получили: DOCX, XLSX, PPTX.
OOXML — Office Open XML (DOCX, XLSX, PPTX)
OOXML, в целом, очень похож на ODF. Он также основан на XML-разметке и также представляет из себя ZIP-архив. Поэтому вы также можете заглянуть внутрь офисных файлов при помощи любого архиватора. Можно даже вытащить картинки и даже подменить их, что бывает особенно удобно при работе с презентациями или когда вам присылают текстовый документ с картинками внутри файла.

Тем не менее, кто-то всё таки смог прочитать всю эту документацию и поэтому на свет появились классные офисные пакеты, например МойОфис, которые умеют работать и ODF форматом, и с Office Open XML, и даже с устаревшими форматами типа DOC.
Но есть важная ремарка про старые форматы. Как правило, современный софт умеет их только читать, но не записывать, потому как это действие требует приобретение лицензии Microsoft. Впрочем, в наше время это действие, мягко говоря, бессмысленно.
МойОфис
Перейдём теории к практике. Как видите, форматов файлов много. У всех форматов есть своя специфика и история. Поэтому, если мы говорим про офисное ПО, важно, чтобы оно работало как с можно большим количеством форматов. И что приятно, такой софт есть. Одно из таких приложений сделали нашими разработчики и назвали его МойОфис.
Вообще, МойОфис — это хороший пример, современного приложения. Во-первых, есть бесплатные десктопная и мобильная версии приложения для работы с текстом и таблицами. На секундочку, это не урезанные, полнофункциональные приложения, без рекламы!
Во-вторых, мобильную версию приложения «МойОфис Документы» хочется отдельно похвалить, хотя у него и так высокий рейтинг в AppStore и GooglePlay. Приложение очень удобное и быстрое. Приложение работает со всеми форматами OOXML, OpenDocument, и даже с устаревшими бинарными форматами (DOC, XLS).
А еще все работает в одном приложении. Вместо того чтобы отдельно качать программу для презентаций, таблиц, текста и даже PDF, достаточно поставить «МойОфис Документы» и готово. Почему все так не делают?
Также ребята первыми в мире добавили в офисное приложение функцию аудиокомментариев. Чтобы вы понимали, это не голосовой ввод с клавиатуры, когда просто вводишь текст голосом, то этот голос улетает на расшифровку на сторонние серверы, обрабатывается там и возвращается обратно в виде текста. Тут же всё устроено просто и безотказно: приложение записывает голос и размещает аудиозапись внутри документа. То есть голос не покидает пределов пользовательского устройства, и хранится только внутри самого документа. Прогрессивненько. А что так можно было?
В десктопной версии есть тоже куча мелочей ускоряющих работу:
- Меню быстрых действий, которое можно открыть сочетанием клавиш [Ctrl]+[/] в любом месте документа.
- Есть подсказки быстрых клавиш
- Более удобная работа с абзацами и прочее, прочее.
- А главное, приложение просто удобное и понятное. Без труда сможет разобраться хоть школьник, хоть бабушка.
В общем, попробуйте программы МойОфис у себя дома и на смартфоне. Вы точно ничего не потеряете, потому как бесплатные версии со всем необходимым функционалом для частного использования и щедрые пробные версии для офисов.
Итого

Что мы в итоге узнали? Файлы бывают нескольких типов:
Начали появляться вопросы подобного типа, обычно связанные с сериализацией. Считаю необходимым разместить подробный ответ на эту тему, чтобы не плодить однотипные ответы и комментарии к вопросам.

Ок, что мы можем знать про файл?
1. Допустим мы знаем только имя файла
Существует также понятие "полное имя", которое задается как сочетание пути (перечисление промежуточных папок) и собственно имени файла.
Само по себе имя дает информации о файле не больше чем имя незнакомого человека, которого вы ни разу не видели. Имя файла позволяет только отличить один файл от другого и использовать это имя вместо физического адреса на диске.
В первом примере был упомянут "тип файла", а что это такое? Тип файла, или расширение имени, это искусственная конструкция, в общем случае, не имеющая ни чего общего с реальным типом файла. Ближайшая аналогия - фамилия человека, по идее она должна говорить о принадлежности к определенной семье, но если собрать всех однофамильцев - то найти у них общего предка скорее всего не удастся. Расширение имени изначально - точка и три буквы после имени файла (.exe, .bat). В настоящее время, ограничений на длину расширения практически нет и существуют составные расширения (.FB2.ZIP, .TAR.GZ), в основном такие расширения у различных архивов. Кроме того, точку можно использовать как часть основного имени.
Какое расширение у файла с абсолютно корректным именем: I.big.file.with.long.name ?
Ответ: какой угодно, от *.name до *.big.file.with.long.name , но Windows опознает только *.name , т.к. исторически получает тип, путем выборки символов из имени с права до первой точки.
Основное назначение этой части имени - подсказать системе, какой значок на нем рисовать и какую программу запустить, когда вместо явного запуска программы мы "запускаем" нужный нам файл, без глубокого анализа содержимого файла. Это легко проверить: возьмите файл с фотографией и переименуйте в test.txt, а затем в командной строке наберите <полный путь к файлу>\test.txt . В результате откроется текстовый редактор (блокнот или любой другой, который у вас назначен для файлов типа *.txt с мало понятным содержимым, там же фотография, а не текст. Можете еще поиграть с этим файлом меняя ему расширение произвольным образом и запуская программы, для которых он не предназначен.
Таким образом, имя файла не сообщает ни нам (человеку), ни программе ни какой полезной информации о содержании файла. А как-же тогда другие программы узнают свои файлы? - по внутренней структуре.
2. Допустим мы знаем особенности структуры файла.
Программы знают как устроены файлы, с которыми они умеют работать. Это означает, что вы можете любой программой попытаться открыть любой файл, но если программа не опознает знакомую внутреннюю структуру или найдет в ней ошибки, то она может отказаться открывать такой файл, сообщив о несовместимости форматов. Еще раз повторю, совместимость форматов не зависит от расширения файла. Это зависит только от расположения конкретных байтов в конкретном файле, требования к которому известны программе, которой вы пытаетесь этот файл открыть. А как же блокнот (notepad и все возможные вариации на тему)? Почему он открывает любые файлы? Да просто потому, что простой текст без форматирования (plain text) не имеет ни каких отличительных черт, это просто последовательность байт, которая не содержит ничего, даже указаний на кодировку символов.
Для широко используемых форматов в сети можно найти описания или даже стандарты, в которых описано, какие (по порядковым номерам) байты, за что в этом типе файлов отвечают.
При открытии произвольного файла, нужно сравнить структуру файла с ожидаемой известной структурой. Если ключевые особенности совпали, нужно проверить корректность опознанной структуры. И только после подтверждения корректности можно утверждать, что файл имеет конкретный тип и может быть открыт конкретной программой.
Таким образом, опознать реальный тип файла можно только по его структуре. И чем более жестко заданы ограничения структуры на формат и расположение данных, тем менее вероятно ложное срабатывание.
Если файл записываете вы, и вы же потом собираетесь его читать, то позаботьтесь о том, чтобы ваша программа записывала и читала данные файла всегда в одном и том же порядке в случае бинарных файлов. Либо используйте характерные маркеры разметки, по аналогии с XML или JSON, которые позволяют использовать простой текст для хранения сложных объектов.
Если нужно просто узнать что за файл такой вам подсунули:
В *nix существует команда file (Спасибо @avp), которая позволяет опознавать файлы на основе ряда тестов. Наиболее интересный из них - magic.
Для Windows можно воспользоваться аналогичной, но, увы, сторонней программой, встроенных средств не предусмотрено. Например TrID - File Identifier для командной строки (спасибо @firepro)
Связанный: Как создать точку восстановления системы в Windows 10?
Что такое просмотр в виде дерева?
Давайте рассмотрим пример папки проекта Bootstrap, как показано ниже, с разными папками для таблиц стилей CSS и файлов JavaScript (JS).
Структура файлов может быть более сложной, как показано ниже, в каждой папке может быть несколько файлов.
В проводнике Windows нет способов, вы можете понять всю структуру каталога. Каждый раз вам нужно использовать навигацию для перемещения вверх или вниз, чтобы найти файл. В проекте важно иметь файлы в правильной папке и использовать относительный путь при связывании файлов в других документах. Здесь идет использование древовидной структуры. В Windows есть команда «Дерево», которая позволяет просматривать файлы / папки в древовидной структуре. Вы действительно можете загрузить структуру любого каталога с помощью древовидной команды и использовать ее для справки.
Как загрузить древовидное представление каталогов в Windows 10?
Есть два способа просмотреть папки в древовидной структуре.
- Использование команды tree в проводнике
- Получить древовидную структуру из командной строки
Просмотр древовидной структуры в проводнике Windows
Нет прямого способа просмотра папок / подпапок / файлов в проводнике Windows в формате дерева. Команда «Дерево» работает в проводнике Windows, но немного по-другому. Он использует командную строку для создания файла в виде дерева. Посмотрим, как это сделать.
- Нажмите сочетания клавиш «Win + E» и откройте «Проводник» или откройте его, дважды щелкнув «Этот компьютер» на рабочем столе. Перейдите в папку, из которой вы хотите выполнить эту команду, или чтобы просмотреть ее структуру. В нашем случае мы переходим в папку «SWSetup».
- Перейдите в адресную строку и введите команду, как показано ниже:

Команда дерева для создания файла
Синтаксис команды Tree:

Результирующее древовидное представление каталога
Вы можете создать древовидную структуру для любой конкретной папки. Если папка находится в «D: test», вы должны использовать следующую команду в адресной строке проводника. Он создаст файл tree.doc в папке D: test.
Связанный: Исправьте медленный ноутбук и ускорьте Windows 10.
Просмотр древовидной структуры с помощью командной строки
Теперь вы можете использовать команду «Дерево» в командной строке и сразу же просматривать формат древовидной структуры всех файлов. Следуйте инструкциям, приведенным ниже:
- Перейдите в меню «Пуск», введите «Командная строка» и нажмите клавишу «Ввод» на клавиатуре.
- Введите команду «CD» и укажите путь к папке / подпапке / диску, для которой вы хотите получить представление в виде дерева. В нашем случае это наша пользовательская папка, поэтому путь будет (CD C: users yourname).
- Для быстрого просмотра перейдите к папке / диску, для которого вы хотите увидеть структуру. Введите команду «Дерево» и нажмите клавишу ввода. Убедитесь, что вы используете эту команду там, где количество папок меньше.

Простая древовидная команда для просмотра файлов
- Чтобы загрузить содержимое в отдельный файл, введите tree / f / a> Resultant.txt и нажмите клавишу ввода. Теперь вернитесь в папку, и вы найдете созданный файл с именем Resultant. Откройте файл, чтобы увидеть чистый структурированный древовидный формат выбранного каталога.
Вы также можете использовать Windows PowerShell вместо командной строки для просмотра древовидной структуры любого каталога.
Читайте также: