
Как распарсить xml файл в sql
Обновлено: 05.07.2024
Казалось бы, зачем вообще может возникнуть необходимость разбирать XML на стороне БД?
В этой статье я хотел бы продемонстрировать на сколько легко и непринужденно можно разобрать XML различной степени сложности используя инструментальные средства Oracle Database.
Мне совершенно не хотелось бы здесь касаться DOM парсера. Скажу лишь, что он есть, реализуется пакетом DBMS_XMLDOM. Временами он может оказаться крайне полезным разработчику, а разобраться с ним, не составит труда любому, сталкивавшемуся ранее с DOM парсерами от других производителей.
Инновационной особенностью оракла является тип XMLType и средства работы с ним. Этот тип является частью технологии XML DB, которая включена в поставку Oracle Database начиная с версии 9.2.
Исходный текст документа XML может быть передан конструктору XMLType в виде значений типов CLOB, BLOB, VARCHAR2, BFILE. Пожалуй, стоит отметить, что BFILE позволяет загрузить файл с файловой системы сервера — никак не клиента, потому если наш XML находится на стороне клиента и он достаточно велик, чтобы быть переданным в виде строки в запросе, пожалуй, следует озаботиться возможностью доставки файла с XML содержимым на файловую систему сервера.
Пример создания экземпляра XMLType, с содержимым, передаваемым в строке:
Создав экземпляр XMLType, можно попытаться сделать первые робкие шажки для разбора нашего XML. Тип XMLType реализует метод Extract, который, принимая XPatch выражение, возвращает фрагмент XML, сочетающийся с этим выражением. Фрагмент XML (XML Fragment), в отличии от правильно построенного XML (whellformed XML) допускает отсутствие корневого элемента (или же, другими словами, допускающий более одного корневого элемента в своем составе).
Так в примере ниже, три выражения возвращают три фрагмента XML. Первый возвращает все вхождения элемента word, второй возвращает только первое его вхождение, третий возвращает фрагмент текстового содержимого элемента word, для которого значение атрибута seq равняется двум.
Здесь, думаю, стоит поставить жирный акцент на том, что в третьем случае возвращается именно фрагмент XML, никак не значение этого элемента. Различия станут заметны лишь тогда, когда это значение будет содержать подстановочные (escaped) символы, вроде &,>. Для того, чтобы получить значение элемента, следует использовать функцию extractValue. Тут упомяну, что основные методы XMLType, продублированы SQL функциями, или же наоборот, основные функции работы с XMLType реализованы в виде его методов. Однако extractValue — исключение. extractValue представлена только в виде фунации. XMLType, к сожалению, не реализует метод extractValue.
Пожалуй, следует еще упомянуть о правилах работы с пространствами имен. Не всякого интуиция приводит к верному пониманию этих механизмов работы. Функции (и метод) extract, extractValue, как один из параметров принимают описание пространства имен. Описанные в этом параметре пространства имен могут быть использованы в XPath выражении. И именно это я хочу подчеркнуть особо. Обратите внимание на третий случай. Пространства имен в XML и XPatch выражениях имеют разные псевдонимы, но одинаковые URI, потому разбор происходит успешно.
Итак, научившись извлекать значения, теперь следовало бы научиться их разделять. Напомню, в первом случае, для первого примера, мы пытались выбрать все элементы word из XML, и нам это удалось, мы получили два элемента word, однако получили мы их в одном фрагменте. Для того, чтобы представить фрагмент, содержащий несколько корневых элементов в виде последовательности фрагментов, каждый из которых содержит по одному корневому элементу существует конвейерная (pipelined) функция XMLSeqence. Функция возвращает XMLSequenceType, который представляет собой таблицу значений XMLType.
Если вдруг кто запамятовал, напомню, что конвейерные функции возвращают как бы коллекции, потому при вызове оборачиваются выражением table. К результатам этих функций обращаются, используя виртуальный столбец column_value, либо же выражение value(), а потому для табличного выражения(table collection excpression) следует определить псевдоним. Если вдруг кто и не знал этого, рекомендую заучить это как мантру, понимание придет со временем, и то, лишь если понадобится.
Простейший пример использования XMLSequence:
Попытаюсь проговорить что здесь происходит, хоть и опасаюсь, что по-русски это окажется намного более сумбурно, и куда менее понятно, нежели на SQL. В выражении from мы сначала создаем экземпляр XMLType, передавая ему строку, содержащую текст XML. Далее, используя метод extract, мы извлекаем в один фрагмент все элементы b, которые содержит элемент а. Полученный фрагмент XML передается параметром в конвейерную функцию XMLSequence, для вызова которой, согласно правилам грамматики, используется предложение table. Набору записей, описываемым этим предложением, присваивается псевдоним t. В select-list'e мы получаем экземпляр объекта возвращенного табличным выражением t, он у нас имеет тип XMLType. Для каждой строки возвращаемой табличным выражением этот экземпляр содержит один фрагмент элемента b исходного XML. Передаем этот объект в качестве параметра функции extractValue. Результат — на лицо.
На самом деле, все далеко не так сложно, как получается в моем изложении. К этому достаточно лишь малость привыкнуть. Но насилие над мозгом еще не в полной степени завершено. То, что у нас получилось на данном этапе, работает только для одного XML документа. Если у нас исходный текст нескольких XML лежит в табличке и нам нужно разобрать сразу несколько из них, нам придется вспомнить еще что такое левая корреляция (left correlation). Здесь тоже нет ничего военного. Эта штука придумана Ораклом и специально для табличных выражений (table collection expression). Суть сводится к тому, что в табличном выражении могут использоваться значения (столбцы) из наборов данных, определенных в выражении from перед (слева) от самого табличного выражения. На практике это выглядит совсем не так ужасно, как на слух:
Здесь в табличном выражении t используется значение xml таблицы demo3. Выражение будет вычислено для каждой строки таблицы demo3. Это и есть то самое, что называется таким вычурным словом — левая корреляция.
Описанного функционала вполне достаточно, чтобы разобрать XML практически любой сложности. Этими средствами нельзя разобрать, пожалуй, лишь иерархически представленные данные заведомо неизвестной глубины вложенности. Для разбора подобных структур придется прибегнуть к XSLT, чтобы привести XML к более удобочитаемому виду. XSLT преобразование осуществляется функцией XMLTransform, которая в качестве первого параметра принимает XMLType исходного документа, второго XMLType XSL шаблона, а возвращает XMLType результата преобразования.
В принципе, на этом с теорией можно и закончить. В завершение лишь продемонстрирую пример извлечения элементов с разных уровней вложенностей XML. У новичков это, порой, вызывает сложности.
Как видите, здесь нет ничего нового. Все та же левая корреляция. Единственное, на что хотелось бы обратить внимание, на (+) в конце табличного выражения subdtl. Как, наверное, не сложно догадаться, он обозначает, что следует использовать внешнее соединение. Если бы мы его не указали, мы не получили бы строки с detail 3.
Итак, что же предстало пред нашими глазами? Мы имеем один объектный тип, сравнительно ограниченный набор функций, дающий практически не ограниченный набор возможностей. Мне безумно нравится эта реализация. Особенно меня восторгает то, что Oracle corp не пришлось рихтовать семантику их SQL, чтобы вписать в него XML. Все описанные особенности — объекты, конвейерные функции, табличные выражения используются этой технологией, но не созданы специально для нее. Получается, подобную реализацию мог бы воплотить кто угодно. Эта реализация жирной линией подчеркивает мощь и гибкость ораклиного SQL движка.
На этой ноте я мог бы и закончить, однако мне покоя не дает предвосхищаемый мною вопрос, да с упреком. «Дружище, ты в каком веке вообще живешь, ты на календарь давно заглядывал? На дворе близится к концу 2011й год, уже далеко не первый продакшн поднят на 11r2 версии датабазы, а ты все жуешь девятошный функционал». Да, есть такой грешок за мной. Я прекрасно знаю, что в 10й версии ввели чудный XMLTable, полностью задвигающий на задний план только что описанный мною функционал. Позволяющий еще легче и еще более не принужденно разбирать XML. Однако по XMLTable у меня еще не достаточно опыта, чтобы сказать что либо сверх и без того очевидного. Потому ограничусь лишь простой демонстрацией.
Покажу на том же примере:
Казалось бы, букв стало много больше, может возникнуть справедливый вопрос… а в чем же профит инновации? Профит в том, что первым параметром в XMLTable передается уже не XPath выражение, а XQuery. А значит, объединение может быть произведено именно его средствами, а не средствами SQL. XMLTable обещает быть еще той вкуснятиной, но, увы, повторюсь, мне о нем пока нечего рассказать.
В отличие от более простого MySQL, у MS SQL даже в Express версии есть достаточно реальная поддержка XML. В PostgreSQL такая поддержка в принципе тоже есть, но в виде отдельных пакетов.
С помощью XML-поддержки можно сделать много полезного в MS SQL - многое но не все! В самый нужный момент микрософтовцы как всегда затупили. Билл Гейтс даже принял на работу к себе 700 копрофилов и зоофилов в надежде, что интеллектуальный потенциал микрософта хоть чуть-чуть увеличится, но увы, даже они не додумались подсказать главного - по стандарту XML идентификаторы могут иметь минус внутри идентификатора неймспейса схемы. Впрочем, мы все знаем, что ни билогейтсовские копрофилы, ни зоофилы, ни все остальные микрософтовцы интернет-стандартов никогда не читали.
Итак, что же все-таки возможно сделать с помощью встроенной в MS SQL поддержки XML?
C помощью встроенной в MS SQL поддержки XPATH-выражений можно довольно удобно распарсить простейшие XML :
Однако, на практике, увы, как правило возникают гораздо более сложные задачи. Как бы для них предусмотрена конструкция WITH NAMESPACE , однако она не поддерживает совершенно обычные стандартные идентификаторы схем. Да и выгребать вручную идентификаторы замучаешься. А если схема то одна, то другая? Как динамически менять схемы в уродской конструкции WITH NAMESPACE ?
Здесь на помощь придут только SQL CLR сборки, о которых много сказано на моем сайте Однако, делать полностью универсальную сборку - которой бы могли воспользоваться все, я не вижу смысла. У нее будет слишком гиморойный синтаксис вызова. Я вижу смысл только автоматизировать выгребание неймспейсов, а собственно вписывание XPATH выражений оставить на откуп пользователю.
Таким образом, ниже я покажу сборку, которая распарсит стандартный SOAP и вернет вместо XML просто табличку:
Обратите внимание, что это как раз противоположная операция преобразования от другой распространенной операции, многократно описанной на моем сайте - Этюды на ASP2. Делаем RSS-канал на одной SQL-процедуре - когда требуется реляционные данные преобразовать в XML (тоже на уровне SQL).
Итак, вот долгожданное чудо - код SQL CLR сборки с табличным возвратом (на примере парсинга SOAP-ответа платежного сервиса Assist ):
Как видите, табличная сборка вполне тривиальна. Функция AssistResponse (137-189) читает из базы XML, декларирует формат выходной таблички и обьявляет что имя функции, заполняющей каждую строку таблички - FillOneRow.
Класс OneRow (7-134) готовит данные для одной строки нашей таблички, которая должна получиться в итоге вызова сборки. А сама функция FillOneRow (191-266) в нашем случае получается тупо заглушкой, которая копирует данные из класса OneRow в созданную в строке 181 каждую новую строку таблички.
Небольшая хитрость, до которой так и не сумели додуматься в гавнософте - это сбор и автоматическое добавление всех существующих в SOAP неймспейсов. Это я делаю в строках 269-320. И непосредственно перед вызовом XPATH-выражений, с помощью которых я выковыриваю из XML данные (53-54,62-92) я автоматически собираю неймспейсы по XML cвоим сервисом. В итоге я могу тупо копировать XPATH например из Альтовы, не заморачиваясь каждый раз - а какой же мне сейчас нужен NamespaceManager для этого отбора?
Ну вот собственно и все. Надеюсь после этой моей публикации ни задачка парсинга SOAP внутри MS SQL, ни задача коллекционирования Namespace по XML уже ни у кого проблем вызывать не будет.
Не только на C++. Новые технологии, процессы и Agile.
понедельник, 21 марта 2011 г.
Работа с XML в SQL запросах
В современных проектах XML встречается довольно часто. Несмотря на избыточность, этот язык разметки данных стал очень популярным из-за своей универсальности. Если нам нужно распарсить какой-то конфиг файл на XML, то практически в каждом языке программирования есть удобная библиотека. В C++ мне нравится Xerces-C++ своей кроссплатформенностью, однако, готов согласиться, если кто-то скажет, что это, местами, не самый удобный инструмент.
Сейчас я хочу рассмотреть сценарий работы с данными в виде XML, которые могут храниться в базе данных. Современные серверы БД поддерживают, в разной степени, тип данных XML. Я буду приводить примеры в MySql, т. к. под рукой в данный момент есть только он. Например, у нас есть таблица xmltest:
Далее, будем считать, что в поле conf хранятся данные каждого пользователя системы следующего вида:
Итак, можно загрузить все данные пользователей и каждый конфиг разобрать своим любимым парсером XML, но что, если мы всего лишь хотим посмотреть сколько у каждого пользователя любимых сайтов? Это можно узнать за один SQL запрос используя язык XQuery+XPath:
Этот запрос для каждого пользователя выдаст количество элементов Page в поле conf. Поскольку в XML элементы не уникальны и могут повторятся, то указываем в квадратных скобках, что нужен первый по порядку элемент. Если это не указать, то запрос вернет набор элементов, как в случае с Page.
Если мы хотим получить атрибут элемента, то показываем это символом @:
Такой запрос выдаст идентификатор первой страницы для каждого пользователя.
Стоит отметить, что для разных реализаций SQL синтаксис запроса будет отличаться, например, в MS SQL Server последний запрос будет выглядеть так:
Поля XML можно не только выводить, но и использовать в условиях поиска, например:
Такой запрос выдаст параметр Option из раздела CoreOptions для всех пользователей, у которых есть закладки.
Сегодня мы начнем рассматривать достаточно полезную возможность SQL сервера от компании Microsoft – это возможность хранить и обрабатывать данные в формате XML. В данном материале мы рассмотрим основные функции Transact-SQL для обработки данного типа данных.
XML очень популярный тип данных, так как данными такого типа достаточно легко обмениваться со множеством различных приложений, поэтому начинающий программист T-SQL должен иметь представление о том, как хранить эти данные и как их обрабатывать на SQL.
Например, в прошлой статье про журналирование изменений данных таблицы мы хранили старые и новые записи в простом текстовом формате, хотя могли использовать для этого XML.
Итак, приступим, для того чтобы хранить в таблице XML-данные, необходимо выбрать соответствующий тип, он так и называется xml. Запросы будем выполнять в среде Management Studio.
Примечание! Все примеры выполнены в Microsoft SQL Server 2008.

Как видите все просто, мы создали таблицу, в которой два столба:
- Id- идентификатор записи;
- Xmldate – соответственно, какие-то XML данные.
Теперь давайте запишем туда что-нибудь, для этого выполним простой запрос INSERT.
Здесь мы просто вручную разметили xml документ и записали его в нашу таблицу. Для того чтобы просто увидеть данные в этой таблице, xml отображается в читабельном виде, выполните запрос используя оператор select:
Вы получите данные вида

Функции T-SQL для работы с XML данными
Данные функции называют методами, и начнем мы с метода query.
и в ответ Вы получите данные вида.
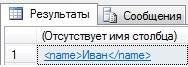
Надеюсь, смысл этого метода понятен.
Далее рассмотрим функцию modify.
Для удаления узла используйте запрос.
Здесь мы удалили узел lastname, для проверки используйте запрос select к данной таблице.
Для вставки узла используйте запрос.
Здесь мы добавили узел lastname обратно в каталог. Для проверки используйте тот же самый запрос select.
Для обновления значения в узле используйте следующий запрос.
Здесь в первом узле name (ну он у нас один) мы изменили значение «Иван» на «Сергей».
Переходим к методу value.
Иногда требуется запросом из таблицы не с xml данными получить данные xml, это тоже можно сделать, например, в следующем запросе мы записываем в переменную типа XML строку таблицы table с идентификатором 2, а затем просто получаем эти значения.
И еще один пример для наглядности (картинка ниже), он похож на предыдущий, но в нем мы просто подставляем статические данные.
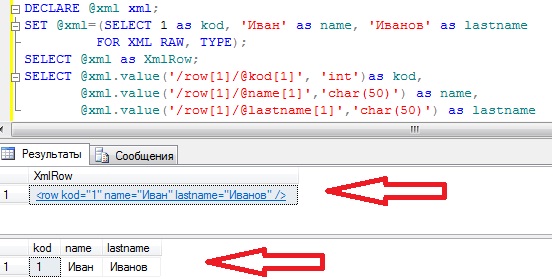
У меня на этом все. Удачи!
Заметка! Для комплексного изучения языка SQL и T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, которые помогут Вам «с нуля» научиться работать с SQL и программировать на T-SQL в Microsoft SQL Server.
Читайте также: