
Как с помощью python зайти на сайт и получить оттуда информацию в файл
Обновлено: 01.07.2024
Недавно заглянув на КиноПоиск, я обнаружила, что за долгие годы успела оставить более 1000 оценок и подумала, что было бы интересно поисследовать эти данные подробнее: менялись ли мои вкусы в кино с течением времени? есть ли годовая/недельная сезонность в активности? коррелируют ли мои оценки с рейтингом КиноПоиска, IMDb или кинокритиков?
Но прежде чем анализировать и строить красивые графики, нужно получить данные. К сожалению, многие сервисы (и КиноПоиск не исключение) не имеют публичного API, так что, приходится засучить рукава и парсить html-страницы. Именно о том, как скачать и распарсить web-cайт, я и хочу рассказать в этой статье.
В первую очередь статья предназначена для тех, кто всегда хотел разобраться с Web Scrapping, но не доходили руки или не знал с чего начать.
Off-topic: к слову, Новый Кинопоиск под капотом использует запросы, которые возвращают данные об оценках в виде JSON, так что, задача могла быть решена и другим путем.
Задача
- Этап 1: выгрузить и сохранить html-страницы
- Этап 2: распарсить html в удобный для дальнейшего анализа формат (csv, json, pandas dataframe etc.)
Инструменты
Регулярные выражения, конечно, нам пригодятся, но использовать только их, на мой взгляд, слишком хардкорный путь, и они немного не для этого. Были придуманы более удобные инструменты для разбора html, так что перейдем к ним. , lxml
Это две наиболее популярные библиотеки для парсинга html и выбор одной из них, скорее, обусловлен личными предпочтениями. Более того, эти библиотеки тесно переплелись: BeautifulSoup стал использовать lxml в качестве внутреннего парсера для ускорения, а в lxml был добавлен модуль soupparser. Подробнее про плюсы и минусы этих библиотек можно почитать в обсуждении. Для сравнения подходов я буду парсить данные с помощью BeautifulSoup и используя XPath селекторы в модуле lxml.html.
Это уже не просто библиотека, а целый open-source framework для получения данных с веб-страниц. В нем есть множество полезных функций: асинхронные запросы, возможность использовать XPath и CSS селекторы для обработки данных, удобная работа с кодировками и многое другое (подробнее можно почитать тут). Если бы моя задача была не разовой выгрузкой, а production процессом, то я бы выбрала его. В текущей постановке это overkill.
Загрузка данных
Первая попытка
Приступим к выгрузке данных. Для начала, попробуем просто получить страницу по url и сохранить в локальный файл.

Открываем полученный файл и видим, что все не так просто: сайт распознал в нас робота и не спешит показывать данные.
Разберемся, как работает браузер
Однако, у браузера отлично получается получать информацию с сайта. Посмотрим, как именно он отправляет запрос. Для этого воспользуемся панелью "Сеть" в "Инструментах разработчика" в браузере (я использую для этого Firebug), обычно нужный нам запрос — самый продолжительный.

Как мы видим, браузер также передает в headers UserAgent, cookie и еще ряд параметров. Для начала попробуем просто передать в header корректный UserAgent.
На этот раз все получилось, теперь нам отдаются нужные данные. Стоит отметить, что иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке Requests.
Скачаем все оценки
Теперь мы умеем сохранять одну страницу с оценками. Но обычно у пользователя достаточно много оценок и нужно проитерироваться по всем страницам. Интересующий нас номер страницы легко передать непосредственно в url. Остается только вопрос: "Как понять сколько всего страниц с оценками?" Я решила эту проблему следующим образом: если указать слишком большой номер страницы, то нам вернется вот такая страница без таблицы с фильмами. Таким образом мы можем итерироваться по страницам до тех, пор пока находится блок с оценками фильмов ( <div > ).

Парсинг
Немного про XPath
XPath — это язык запросов к xml и xhtml документов. Мы будем использовать XPath селекторы при работе с библиотекой lxml (документация). Рассмотрим небольшой пример работы с XPath
Подробнее про синтаксис XPath также можно почитать на W3Schools.
Вернемся к нашей задаче
Теперь перейдем непосредственно к получению данных из html. Проще всего понять как устроена html-страница используя функцию "Инспектировать элемент" в браузере. В данном случае все довольно просто: вся таблица с оценками заключена в теге <div > . Выделим эту ноду:

Каждый фильм представлен как <div > или <div > . Рассмотрим, как вытащить русское название фильма и ссылку на страницу фильма (также узнаем, как получить текст и значение атрибута).
Еще небольшой хинт для debug'a: для того, чтобы посмотреть, что внутри выбранной ноды в BeautifulSoup можно просто распечатать ее, а в lxml воспользоваться функцией tostring() модуля etree.
Резюме

В результате, мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup и lxml, а также получили пригодные для дальнейшего анализа данные о просмотренных фильмах на КиноПоиске.
Полный код проекта можно найти на github'e.
Если необходимые вам данные разбросаны по разным HTML-страницам для их извлечения применяется скрапинг. Вы создаете код для автоматического посещения определенного перечня страниц, получения конкретного контента с этих страниц и сохранения его в базе данных или в текстовом файле. [1]
Скажем, вы хотите скачать данные по температуре за прошедший год, но у вас не получается найти источник, который предоставил бы вам все сведения за нужный отрезок времени или по нужному городу. К счастью, сайт Weather Underground предоставляет исторические данные о погоде. И плохая новость: на одной странице сведения можно получить только за один день (рис. 1).

Рис. 1. Температура в Москве по данным Weather Underground; чтобы увеличить картинку, кликните на ней правой кнопкой мыши и выберите опцию Открыть картинку в новой вкладке
Проходим по меню More –> Historical Weather и выбираем определенную дату (рис. 2).

Рис. 2. Окно поиска архивных данных о погоде
Нажмите Submit, откроется другая страница, где вам будут представлены подробные данные о погоде в выбранный вами день (рис. 3).

Рис. 3. Подробные сведения о погоде в выбранный день
Допустим вас интересует максимальная температура. Вы могли бы посетить 365 страниц и собрать требуемые данные. Но процесс можно ускорить с помощью кода. Для этого обратитесь к языку программирования Python и к библиотеке под названием BeautifulSoup, созданной Леонардом Ричардсоном.
> python setup.py install
Создайте файл в текстовом редакторе (например, в блокноте) и сохраните его как get-weather-data.py. Теперь вы можете заняться написанием кода. Загрузите страницу, на которой представлены исторические сведения о погоде (как на рис. 3). URL страницы с информаций о погоде в Москве за 1 января 2015 выглядит так (чтобы разместить столь длинную строку мне пришлось разбить ее несколькими пробелами):
Если в этом адресе вы удалите все, что следует за .html, страница будет по-прежнему загружаться, так что избавьтесь от этих лишних символов:
В URL дата указана как /2015/1/1. Чтобы загрузить страницу со сведениями о 2 января 2015 г. без использования выпадающего меню, просто измените параметр даты так, чтобы URL выглядел следующим образом:
Теперь загрузите страницу с помощью Python, используя функцию urlopen, хранящуюся в модуле urllib.request библиотеки urllib. Для начала импортируйте эту функцию в программу:
from urllib.request import urlopen
Чтобы загрузить страницу с данными о погоде за 1 января, введите код:
page = urllib.urlopen( " www.wunderground.com/history/airport/UUEE/2015/1/2/DailyHistory.html " )
Таким образом вы загрузите весь HTML-файл, на который указывает URL в переменной страница. Следующим шагом будет извлечение интересующего вас значения максимальной температуры из этого HTML. Beautiful Soup сделает выполнение данной задачи намного проще. Вслед за urllib импортируйте Beautiful Soup:
from bs4 import BeautifulSoup
Используйте функцию BeautifuLSoup, чтобы прочитать страницу, и произвести ее анализ.
Эта строчка кода прочитывает HTML, который представляет по сути одну длинную строку, а затем сохраняет элементы страницы, такие как заголовок или изображения, в удобном для работы виде. Например, если вы хотите найти все изображения на странице, вы можете использовать код:
images = soup.findAll( ' img ' )
В результате вы получите перечень всех изображений на странице Weather Underground, отображаемых с помощью HTML-тега <img />. Вам нужно первое изображение на странице? Введите:
Хотите второе изображение? Измените ноль на единицу. Если вам нужно значение src в первом теге <img />, тогда используйте:
src = first_image[ ' src ' ]
Ладно, вас ведь не интересуют изображения. Вы просто хотите извлечь максимальную температуру в Москве 1 января 2015 года. Чтобы найти ее, нужно потрудиться чуть подольше, но метод применяется все тот же. Вам нужно выяснить, что вставить в findAll(), а потому просмотрите исходный HTML. Это легко сделать в веб-браузере. В Google Chrome, например, кликните на странице правой кнопкой мыши и выберите Просмотреть код. Появится окно с HTML-кодом (рис. 4).

Рис. 4. Исходный HTML-код страницы Weather Underground
Прокрутите вниз до того места, где показана максимальная температура, или воспользуйтесь функцией поиска в браузере. Строка замыкается тегом <span> с классом wx-value. Это и есть ваш ключ. Вы теперь можете найти все элементы на странице с классом wx-value.
Как и в предыдущем примере, это дает вам в руки перечень всех случаев употребления wx-value. Вас интересует второй из них, который вы найдете с помощью строчки:
Вуаля! Вы впервые в жизни извлекли нужное вам значение из HTML-кода веб-страницы. Следующий шаг — проанализировать все страницы за 2015 год и извлечь из них необходимые данные. Для этого вернитесь к первоначальному URL:
Помните, как вы вручную изменили адрес, чтобы получить сведения о той дате, которая вас интересовала? Приведенный выше код относится к 1 января 2015 года. Если вам нужна страница за 2 января 2015 года, просто измените ту часть URL, в которой указана дата, на соответствующую. Чтобы получить данные за все дни 2015 года, загрузите все месяцы (с 1-го по 12-й), а затем загрузите каждый день каждого месяца. Ниже представлен весь скрипт с комментариями. Сохраните его в вашем файле get-weather-data-full.py.
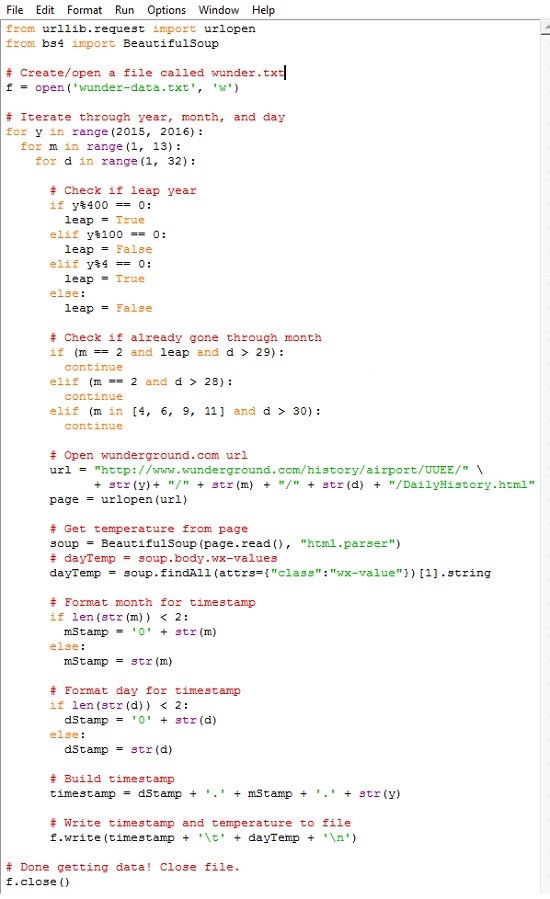
Вы наверняка узнали первые две строчки кода, с помощью которых вы импортировали необходимые библиотеки, — urllib и BeautifulSoup. Далее создается текстовый файл под названием wunder-data.txt с правами на запись, используя метод open(). Все данные, которые вы извлечете, будут сохраняться в этом текстовом файле, расположенном в той же папке, куда вы сохранили свой скрипт.
С помощью следующего блока, используя циклы for, компьютеру отдается команда просмотреть каждый год, месяц и день. Функция range() генерирует последовательность чисел, используемых для итераций цикла. Эта функция генерирует последовательность, начинающуюся с нуля и кончающуюся числом в скобках, не включая его. Поэтому, если вы укажите:
for y in range(2015):
Внешний цикл for проверяет, является ли год високосным. Число, обозначающее месяц, указывается в переменной m. Следующий цикл сообщает компьютеру, что надо посетить каждый день каждого месяца. Каждый отдельный день месяца указывается в переменной d.
Обратите внимание на то, что для повторения операции по дням используется range(1, 32). Это означает, что повтор будет производиться для каждого числа, начиная с 1 и по 31 (последнее значение не включается). Однако не в каждом месяце в году есть 31 день. В феврале их 28; в апреле, июне, сентябре и ноябре — по 30. Температурных показателей за 31 апреля нет, потому что такого дня не существует. Обратите внимание на то, о каком месяце идет речь, и действуйте сообразно этому. Если текущий месяц — февраль, и число больше 28, прервитесь и переходите к следующему месяцу.
Следующие строчки кода вы использовали для извлечения данных из одной конкретной страницы сайта Weather Underground. Отличие состоит в переменной месяца и дня в URL. Ее просто нужно менять для каждого дня, а не оставлять статичной — все прочее тут без изменений. Загрузите страницу, используя библиотеку urllib, произведите анализ контента с помощью Beautiful Soup, а затем извлеките максимальную температуру, с помощью второго появления класса wx-values.
Прогон займет некоторое время, так что наберитесь терпения. По сути, в процессе выполнения программы ваш компьютер загрузит по очереди 365 страниц – по одной на каждый день 2015 года. Когда выполнение скрипта завершится, у вас в рабочем каталоге появится файл под названием wunder-data.txt (рис. 5). Откройте его, и там вы найдете нужные вам данные в формате с разделителями табуляцией. В первой колонке вы увидите дату, во второй – температуру.

Рис. 5. Извлеченные данные в файле с разделителем табуляцией
Обратите также внимание, что, если вы будете запрашивать данные по будущему периоду (дата еще не наступила), то получите некорректный ответ. Запрос найдет второе вхождение тега с классом wx-value, но оно не будет соответствовать максимальной температуре выбранного дня (рис. 6).

Рис. 6. Для будущего периода второй тег класса wx-value не соответствует максимальной температуре выбранного дня
Любопытна история написания этой заметки. Мой друг несколько лет назад подарил мне книгу Нейтана Яу Искусство визуализации в бизнесе. Поскольку меня интересует обработка и представление информации, книга мне показалась любопытной, и я начал ее читать. Но… буквально с первых страниц автор уводит с проторенных дорожек. Критикуя Excel за его недостаточную мощь и гибкость, автор предлагает использовать программную обработку на основе языка Python. Тогда мне это показалось слишком сложным.
Но около месяца назад я вновь вернулся к книге Нейтана Яу. И теперь использование Python меня не отпугнуло. Я решил написать конспект книги, а, чтобы не перегружать его, специфические темы опубликовать отдельно. Первая из таких заметок перед вами. Надо сказать, что далась она непросто.
Для начала, код Нейтана Яу не запустился. Проблемы подстерегали практически на каждом шагу. Выяснилось, что код написан для Python 2, а последняя версия – это Python 3.5. Изучение Интернета подсказало, что язык был существенно переработан при переходе с версии 2 на 3. Мне показалось странным, потчевать читателей устаревшим кодом. Поэтому я установил последнюю из доступных на данный момент версий Python 3.5.1.
Чтобы попытаться самому переписать код, или хотя бы более грамотно задавать вопросы на форумах, я прочитал книгу Майк МакГрат. Программирование на Python для начинающих. Книга мне понравилась. Очень хорошо структурирована, сопровождается файлами с примерами. То, что надо! Она мне здорово помогла.
Следующая проблема была с запуском модуля BeautifulSoup. После импорта внутрь кода Python модуль не был виден. Я менял папки, запускал скрипт setup.py, ничего не помогало. Интенсивный поиск в Интернете натолкнул меня на только что вышедшую в издательстве ДМК Пресс книгу Райана Митчелла Скрапинг вебсайтов с помощью Python. Оцените, книга вышла 30 апреля 2016 г.! Здесь я почерпнул знания о библиотеке urllib, и о том, как установить модуль BeautifulSoup под Python 3. Критически важным было выполнить в командной строке
> python setup.py install
Эта команда конвертирует код модуля BeautifulSoup, адаптируя его к версии Python 3.
Далее оказалось, что с момента написания Нейтаном Яу своей книги на сайте Weather Underground произошли изменения в стилевом оформлении CSS. Поменялось имя тега, используемого для представления значения температуры: с nobr на wx-value.
И наконец, с переходом на версию Python 3, наверное, поменялся синтаксис извлечения значения из тега. У Нейтана Яу было:
Т.е., [ ].span.string следовало заменить на [ ].string. Я нигде не мог найти подсказки, что же следует изменить в первоначальном коде, чтобы извлечь не весь тег
а только его значение
Обращение на форум python.su не помогло. Я применил метод научного тыка, и после нескольких попыток получил то, что нужно.
Успехов вам в освоении языка Python!
[1] Заметка написана на основе материалов книги Нейтан Яу. Искусство визуализации в бизнесе. – М.: Манн, Иванов и Фербер, 2013. – С. 44–53.

Как-то я хотела купить авиабилеты и заметила, что цены изменяются несколько в течение дня. Я попыталась выяснить, когда наступает самый лучший момент для покупки билетов, но не нашла в Интернете ничего, что бы могло мне помочь решить эту задачу. Тогда я написала небольшую программу для автоматического сбора данных в Интернете — так называемую программу скрепинга. Программа извлекла информацию по моему запросу для определенного пункта назначения на выбранные мной даты и показала мне, когда стоимость становится минимальной.
Веб-скрепинг — это метод автоматизированного извлечения данных с веб-сайтов.
Я и м ею большой опыт веб-скрепинга и хочу с вами поделиться.
Этот пост предназначен для тех, кому интересно узнать об общих шаблонах проектирования, подвохах и правилах, связанных с веб-скрепингом. В статье представлено несколько реальных примеров и перечень типовых задач, таких как, например, что делать, чтобы вас не обнаружили, что можно делать, а что не следует и, наконец, как ускорить работу вашего скрепера с помощью распараллеливания.
Все примеры будут сопровождаться фрагментами кода на Python, так что вы можете сразу же ими воспользоваться. В этом материале также будет показано, как привлекать к работе полезные пакеты Python.
Реальные примеры
Существует различные причины и варианты необходимости использования сбора (скрэпинга) данных в Интернете. Позвольте мне перечислить некоторые из них:
-
, чтобы определить имеется ли в наличии одежда, которую вы хотите купить, со скидкой нескольких брендов одежды, собирая данные о них с вэб-страниц
- стоимость авиабилетов может меняться несколько раз в течение дня. Можно сканировать веб-сайт и дождаться момента, когда цена будет снижена
- проанализировать веб-сайты, чтобы определить, должна ли быть стартовая стоимость продажи низкой или высокой, чтобы привлечь больше участников на аукцион или коррелирует ли длительность проведения аукциона с более высокой ценой конечной ценой продажи
Руководство
- Применяемые пакеты
- Основной программный код
- Распространенные ошибки
- Общие правила
- Ускорение ‑ распараллеливание
Прежде чем мы приступим: БУДЬТЕ аккуратны с серверами; вы же НЕ ХОТИТЕ сломать вэб-сайт.
1. Известные пакеты и инструменты
Для веб-скрэпинга нет универсального решения, поскольку способ, с помощью которого хранится на каждом из веб-сайтов обычно специфичны. На самом деле, если вы хотите собрать данные с сайта, вам необходимо понять структуру сайта и, либо создать собственное решение, либо воспользоваться гибким и перенастраиваемым вариантом уже готового решения.
Изобретать колесо здесь не нужно: существует множество пакетов, которые скорее всего, вам вполне подойдут. В зависимости от ваших навыков программирования и предполагаемого варианта использования вы можете найти разные более или менее полезные для себя пакеты.
1.1 Проверяем параметры
Чтобы вам было проще проверять HTML-сайт, воспользуйтесь опцией инспектора в вашем вэб-браузере.

Раздел веб-сайта, который содержит мое имя, мой аватар и мое описание, называется hero hero--profile u-flexTOP (любопытно, что Medium называет своих писателей героями:)). Класс <h1>, который содержит мое имя, называется ui-h2 hero-title , а описание содержится в описании героя <p> классом ui-body hero-description .
Вы можете более подробно познакомиться с HTML-тэгами и различиями между классами и id здесь.
1.2 Скрэпинг
В моем случае я воспользовалась готовым методом «из коробки»: я просто хотела извлечь ссылки со всех страниц, получить доступ по каждой ссылке и извлечь из нее информацию.
1.3 BeautifulSoup с библиотекой Request
BeautifulSoup — это библиотека, позволяющая сделать синтаксический разбор (парсинг) HTML-кода. Кроме того, вам также потребуется библиотека Request , которая будет отображать содержимое URL-адреса. Однако, вы также должны позаботиться и о решении ряда прочих вопросов, таких как обработка ошибок, экспорт данных, распараллеливание и т.д.
Я выбрала BeautifulSoup, поскольку эта библиотека помогла мне понять сколько всего Scrapy может делать самостоятельно и, я надеюсь, помогла мне быстрее научиться на своих собственных ошибках.
2. Основной программный код
Начать скэпить вэб-сайт очень просто. В большинстве случаев просматриваете HTML-сайт, вы обнаружите те классы и идентификаторы, которые могут вам могут понадобиться. Допустим, у нас есть следующая структура html, и мы хотим извлечь элементы main_price .
Примечание: элемент discounted_price является необязательным.
Основной код вэб-скрепера должен импортировать библиотеки, выполнить запрос, проанализировать html и затем найти класс class main_price .
Может случиться так, что класс main_price находится в другом разделе веб-сайта. Чтобы избежать извлечения ненужного класса main_price из какой-либо другой части веб-страницы, мы могли бы сначала обратиться к id listings_prices и только затем найти все элементы с классом main_price .
3. Распространенные ошибки
3.1 Check robots.txt
3.2 HTML может быть злом
HTML-теги могут содержать идентификатор (id), класс или сразу оба этих элемента. Идентификатор (т.е. id) HTML описывает уникальный идентификатор, а класс HTML не является уникальным. Изменения в имени или элементе класса могут либо сломать ваш код, либо выдать вам неправильные результаты.
Есть два способа избежать, или, по крайней мере, предупредить это:
• Используйте конкретный идентификатор id , а не class , поскольку он с меньшей вероятностью будет изменен
- Проверьте, не возвращается ли элемент значение None.
Однако, поскольку некоторые поля могут быть необязательными (например, discounted_price в нашем HTML-примере), соответствующие элементы не будут отображаться в каждом списке. В этом случае вы можете подсчитать процентное соотношение частоты возврата None конкретным элементом в списке. Если это 100%, вы, возможно, захотите проверить, было ли изменено имя элемента.
3.3 Обмануть программу-агент
Каждый раз, когда вы посещаете веб-сайт, он получает информацию о вашем браузере через пользовательский агент. Некоторые веб-сайты не будут показывать вам какой-либо контент, если вы не предоставите им пользовательский агент. Кроме того, некоторые сайты предлагают разные материалы для разных браузеров. Веб-сайты не хотят блокировать разрешенных пользователей, но вы будете выглядеть подозрительно, если вы отправите 200 одинаковых запросов в секунду с помощью одного и того же пользовательского агента. Выход из этой ситуации может заключаться в том, чтобы сгенерировать (почти) случайного пользовательского агента или задать его самостоятельно.
3.4 Время ожидания запроса
По умолчанию Request будет продолжать ожидать ответ в течение неопределенного срока. Поэтому рекомендуется установить параметр таймаута.
3.5 Я заблокирован?
Частое появление кодов состояния, таких как 404 (не найдено), 403 (Запрещено), 408 (Тайм-аут запроса), может указывать на то, что вы заблокированы. Вы можете проверить эти коды ошибок и действовать соответственно.
Кроме того, будьте готовы обработать исключения из запроса.
3.6 Смена IP
Даже если вы рандомизировали своего пользовательского агента, все ваши запросы будут отправлены с одного и того же IP-адреса. Это вполне нормально, поскольку библиотеки, университеты, а также компании имеют всего несколько IP-адресов. Однако, если очень много запросов поступает с одного IP-адреса, сервер может это обнаружить.
Использование общих прокси, VPN или TOR может помочь вам стать незаметным;)
Если вы используете общий прокси-сервер, веб-сайт увидит IP-адрес прокси-сервера, а не ваш. VPN соединяет вас с другой сетью, а IP-адрес поставщика VPN будет отправлен на веб-сайт.
3.7 Ловушки для хакеров
Ловушки для хакеров — это средства для обнаружения сканеров или скреперов.
Такими средствами могут быть «скрытые» ссылки, которые не видны пользователям, но могут быть извлечены скреперами и/или вэб-спайдерами. Такие ссылки будут иметь набор стилей CSS display:none , их можно смешивать, задачая цвет фона или даже перемещаясь из видимой области страницы. Как только ваша программа посещает такую ссылку, ваш IP-адрес может быть помечен для дальнейшего расследования или даже мгновенно заблокирован.
Другой способ обнаружить хакеров — это добавить ссылки с бесконечно глубокими деревьями директорий. В этом случае вам нужно ограничить количество загруженных страниц или ограничить глубину обхода.
4. Общие правила
- Перед началом скрэпинга проверьте, есть ли у вас возможность воспользоваться публичными API. Публичные API предоставляют более простой и быстрый (и законный) поиск данных, по сравнению с веб-скрэпингом. Посмотрите API Twitter, который предоставляет API для различных целей.
- Если вы скрэпите много данных, вы можете воспользоваться базой данных, чтобы иметь возможность быстро анализировать получать данные с Интернета. В этом руководстве описано, как создать локальную базу данных с помощью Python.
- Будьте вежливы, терпеливы и уважительны. Как следует из этого ответа, рекомендуется оповещать пользователей о том, что вы собираете данные с их веб-сайта, чтобы они могли лучше отреагировать на возможные проблемы, причиной которых может стать ваш бот.
Опять таки, не перегружайте веб-сайт, отправляя сотни запросов в секунду.
5. Ускорение ‑ распараллеливание
Если вы решитесь на распараллеливание своей программы, будьте осторожны с реализацией, чтобы не “свалить” сервер. Обязательно прочитайте раздел «Распространенные ошибки», приведенный выше. Ознакомьтесь с определениями параллельного и последовательного выполнения, процессоров и потоков здесь и здесь.
Если вы извлекаете большое количество информации со страницы и выполняете некоторую предварительную обработку данных, количество повторных запросов в секунду, которое вы отправляете на страницу, может быть относительно низким.
В своем другом проекте я собирала цены на аренду квартиры и сделала для этого довольно сложную предварительную обработку данных, в результате чего мне удалось отправлять только один запрос в секунду. Чтобы собрать объявления размером в 4K, моя программа должна проработать около часа.
Чтобы отправлять запросы параллельно, вы можете воспользоваться пакетом multiprocessing.
Допустим, у нас есть 100 страниц, и мы хотим назначить каждому процессу равное количество страниц для обработки. Если n - количество процессоров, то вы можете равномерно распределить все страницы на n частей и назначить каждую часть отдельному процессору. Каждый процесс будет иметь свое имя, свою целевую функцию и свои аргументы для работы. После этого имя процесса можно использовать для включения записи данных в определенный файл.
Я назначила 1K страниц для каждого из 4-х процессоров, имевшихся у меня в распоряжении, в результате было создано 4 повторных запроса в секунду, что сократило время сбора данных моей программой до 17 минут.

Данные есть везде, на каждом посещенном вами сайте. Чаще всего они уже представлены в читаемом текстовом формате, пригодном для использования в новом проекте, однако, несмотря на то, что нужный текст всегда можно скопировать и вставить прямо со страницы сайта, когда речь заходит о больших данных — о тексте с десятка тысяч веб-сайтов — скрейпинг приходит на помощь.
Обучаться веб-скрейпингу (web-scraping) поначалу сложно, однако если вы начнете своё знакомство с большими данными, используя правильные инструменты, то предстоящий вам путь существенно облегчится.
В пошаговом руководстве вы узнаете, как сделать скрейпинг нескольких страниц веб-сайта с помощью самой простой и популярной библиотеки Python для скрейпинга: Beautiful Soup.
Руководство состоит из двух разделов. В первом разделе речь пойдет о том, как осуществить скрейпинг одной страницы, а во втором — о том, как скрейпить сразу нескольких страниц с помощью примера кода, из первого раздела.
Список рассматриваемых в руководстве тем:
- Что нужно для начала веб-скрейпинга?
- Установка, запуск и настройка Python-библиотеки Beautiful Soup.
- Раздел 1: cкрапинг одной страницы:
— Импорт библиотек.
— Получение HTML-содержимого веб-сайта.
— Анализ веб-сайта и его HTML-разметки.
— Одновременное нахождение нескольких HTML-элементов с помощью Beautiful Soup.
— Экспорт данных в txt -файл. - Раздел 2: cкрапинг нескольких страниц:
— Получение атрибута href .
— Нахождение нескольких элементов с помощью Beautiful Soup.
— Переход по каждой из необходимых ссылок.
Что нужно для начала веб-скрейпинга?
Перед началом руководства, убедитесь, что на вашем компьютере установлен Python 3 версии.
Давайте начнем ознакомление с пособием для новичков по настройке Beautiful Soup в Python!
Установка, запуск и настройка Python-библиотеки Beautiful Soup
- Начнём с установки Beautiful Soup на ваш компьютер. Для этого выполните следующую команду в командной строке или терминале:
- Теперь установите парсер: он понадобится для извлечения данных из HTML-документов. В руководстве предлагается использовать библиотеку-парсер lxml , следовательно, выполните установочную команду:
- Пришло время устанавливать библиотеку requests . Для этого выполните следующую команду в командной строке или терминале:
Наконец-то настройка окружения завершена — можно приступать к программированию!
Раздел 1: Скрейпинг одной страницы
Руководство бережно проведёт вас через каждую строчку кода, необходимого для создания вашего первого скрейпера веб-сайтов. Полный код вы найдете в самом конце статьи. Давайте начнем!
Импорт библиотек
Для скрейпинга нам пригодятся библиотеки BeautifulSoup и request , поэтому импортируем их в программу с помощью двух строчек кода:
Получение HTML-содержимого веб-сайта
Теперь, в образовательных целях, давайте получим все данные сайта, содержащего сотни страниц информации о фильмах; начнём со скрейпинга первой страницы, а затем уже разберёмся со скрейпингом множества страниц одновременно.
Наконец, воспользуемся парсером lxml для получения “супа” — объекта, содержащего все данные во вложенной структуре, которая понадобится нам в работе позднее:
Теперь, когда у нас уже есть объект soup , доступ к HTML в читабельном формате легко получается с помощью функции .prettify() . Несмотря на то, что HTML в текстовом редакторе также пригоден для ручного поиска конкретных его элементов, гораздо лучше сразу перейти к HTML-коду необходимого нам элемента страницы: в следующем шаге мы как раз это сделаем.
Анализ веб-сайта и его HTML-разметки
Важным шагом перед тем, как перейти к написанию кода, является анализ веб-сайта, скрейпинг которого производится, и полученного HTML-кода, ради нахождения самого лучшего подхода к решению задачи. Ниже приведен скриншот страницы описания фильма, по которому видно, что элементами, текст которых нужно получить, являются название фильма и реплики из него:

Movie Title — название фильма, Transcript — это диалоги из фильма
Теперь необходимо разобраться, как получить HTML только этих двух нужных нам элементов; выполните следующие действия:
- Перейдите на веб-страницу с диалогами из выбранного вами фильма.
- Наведите курсор на название фильма или его диалоги, а затем щелкните правой кнопкой мыши: появится меню, в котором выберите пункт “Исследовать”, чтобы открыть исходный код страницы сразу на нужном месте.
Ниже приведена уменьшенная версия HTML-кода, полученного после нажатия на пункт меню “Исследовать”. В дальнейшем в качестве справочника используется именно эта HTML-разметка, полезная при определении местоположения элементов в следующем шаге руководства.
Поиск HTML-элемента с помощью Beautiful Soup
Найти конкретный HTML-элемент в объекте, полученном с помощью Beautiful Soup — проще простого: нужно всего-то применить метод .find() к созданному ранее объекту из переменной soup .
В качестве примера давайте найдем блок, содержащий название фильма, описание и диалоги; нужный блок находится внутри тега article и обозначен классом main-article . Доступ к данному блоку осуществляется с помощью одной-единственной строчки кода:
Теперь давайте найдем название фильма и список реплик. Название фильма находится внутри тега h1 и не обозначено никаким классом, что никак не помешает нам его найти; после нахождения нужного элемента, было бы неплохо получить из него текст, используя метод .get_text() :
Список реплик из фильма расположен внутри тега div и обозначен классом full-script . В таком случае, чтобы получить текст, нужно изменить параметры по умолчанию в методе .get_text() . Во-первых, устанавливаем настройку strip=True , чтобы удалить все лишние пробелы. Затем добавим пробел в качестве разделителя separator="" , чтобы пробел ставился после каждой новой строки, то есть, после каждого нового символа перехода на новую строку \n :
На данный момент скрейпинг данных с одной страницы успешно завершён. Выведите в консоль или терминал значения переменных title и transcript , чтобы убедиться в корректности собственного кода на Python.
Экспорт данных в txt-файл
Скорее всего, ради возможности дальнейшего использования только что полученных в результате успешного скрейпинга данных, вы захотите куда-то их сохранить: например, экспортировать данные в формат .csv , .json или какой-либо другой; в данном примере извлеченные данные сохраняются в файле формата .txt :
При экспорте данных пригодится ключевое слово with , как показано в приведенном ниже коде:
Имейте в виду, что в примере при установке названия фильма в качестве имени файла используется f-string , известная как “форматируемая строка”.
После выполнения кода в вашем рабочем каталоге должен появиться файл в формате .txt .
Теперь, когда вы успешно выполнили скрейпинг данных с одной страницы, вы готовы приступать к скрейпингу сразу нескольких страниц!
Раздел 2: Скрейпинг нескольких страниц
Ниже представлен скриншот первой страницы сайта с диалогами из фильмов: сайт предоставляет аж 1 234 такие страницы, на каждой из которых размещено около 30-ти фильмов:

Pages — список страниц сайта, List of Movie Transctipts — список фильмов
Во второй части руководства вы узнаете, как скрейпить несколько ссылок, получая атрибут href для каждой из них. Во-первых, понадобится изменить веб-сайт для скрейпинга с используемого в первом примере на приведённый выше.
Новая переменная с идентификатором website , содержащая ссылку на веб-сайт, оформляется следующим образом:
Вы можете заметить в коде примера ещё одну новую переменную с идентификатором root — она пригодится позже.
Получение атрибута href
Сейчас вы узнаете, как получить атрибут href сразу для всех 30-ти фильмов, перечисленных на одной странице: для начала выберите любое название фильма из блока “список фильмов” на скриншоте выше.
Теперь необходимо получить HTML-разметку страницы. Каждый из HTML-тегов <a></a> относится к определенному названию фильма, причем ссылочный тег <a></a> выбранного вами фильма должен быть выделен синим цветом, как показано на скриншоте:

Теперь давайте найдем все ссылочные теги <a></a> на странице со списком фильмов.
Одновременное нахождение нескольких HTML-элементов с помощью Beautiful Soup.
Для нахождения нескольких элементов в Beautiful Soup пригодится специальный метод .find_all() с параметром-настройкой href=True : данный метод позволяет удобно и быстро извлекать ссылки, соответствующие каждой из страниц с диалогами:
Извлечь ссылки из href можно с помощью добавления указания на атрибут [‘href’] к выражению выше; однако метод .find_all() возвращает список, а не строки, поэтому придется получать атрибут href по одному внутри обходного цикла:
Теперь было бы неплохо создать свой список из ссылок в нужном формате, в чём нам поможет списковое включение, также известное как генератор списка:
При выводе списка ссылок на экран с помощью функции print() , вы увидите все те ссылки, веб-страницы которых планируется скрейпить. В следующем шаге руководства мы как раз реализуем скрейпинг каждой из них.
Переход по каждой из необходимых ссылок
Для получения диалогов фильмов по каждой из полученных на предыдущем этапе ссылок, выполним те же шаги, что и для одной ссылки ранее, но на этот раз воспользуемся циклом for , повторив таким образом все действия по нескольку раз:
Читайте также: