Как считать строку из файла c в string
Обновлено: 04.07.2024
Хедер fstream предоставляет функционал для считывания данных из файла и для записи в файл. В целом он очень похож на хедер iostream , который работает с консолью, поскольку консоль это тоже файл. Поэтому все основные операции такие же, за мелкими отличиями, как в предыдущей теме по iostream.
Наиболее частые операции следующее:
- Методы проверки открыт ли файл is_open() и достигнут ли конец файла eof()
- Настройка форматированного вывода для >> с помощью width() и precision()
- Операции позиционирования tellg(), tellp() и seekg(), seekp()
Это не все возможности, которые предоставляет библиотека fstream. Рассматривать все сейчас мы не будем, поскольку их круг применения достаточно узок. Познакомимся с вышеперечисленными. Начнем с класса чтения.
Класс ifstream
Открытие файла в конструкторе выглядит так:
ifstream file ( "d:\\1\\файл.txt" ) ; // открываем файл в конструктореТак мы просим открыть файл txt с именем файл.txt, который лежит в папке с названием 1, а папка находится на диске d.
Использование метода open() удобно, если программист не хочет сразу привязываться к файлу. Вдруг нужно свойство класса или глобальную переменную, ну а открывать файл уже потом. Если же нужно открыть файл внутри некой функции, поработать с ним и закрыть, то можно прописать путь к файлу прямо в конструкторе. В общем зависит от ситуации.
Так все отработает нормально и файл откроется:
![библиотека fstream, работа с файлами в с++, программирование для начинающих]()
Второй вариант проверки с использованием метода is_open() :
Метод is_open() вернет 1, если файл найден и успешно открыт. Иначе вернет 0 и сработает код прописанный в блоке else .
Если файл успешно открыт, из него можно производить чтение.
Оператор считывания >>
Так же как и в iostream считывание можно организовать оператором >> , который указывает в какую переменную будет произведено считывание:
Считает вещественное, целое и строку. Считывание строки закончится, если появится пробел или конец строки. Стоит отметить, что оператор >> применяется к текстовым файлам. Считывание из бинарного файла производить лучше всего с помощью метода read().
Кстати этот оператор достаточно удобен, если стоит задача разделить файл на слова:
Методы getline() и get()
Считывание целой строки до перевода каретки производится так же как и в iostream методом getline(). Причем рекомендуется использовать его переопределеную версию в виде функции, если считывается строка типа string:
Если же читать нужно в массив символов char[], то либо get() либо getline() именно как методы:
Принцип в общем тот же, что и в аналогах из iostream: Указывается в параметрах буфер (переменная, куда будет производиться чтение), или точнее указатель на блок памяти (если переменная объявлена статически: char buffer[255] к примеру, то пишется в параметры &buffer), указывается максимальное количество считываемого (в примере это n), дабы не произошло переполнение и выход за пределы буфера и по необходимости символ-разделитель, до которого будет считка (в примере это пробел). Надеюсь я не больно наступлю на хобот фанатикам Си, если сажу что эти две функции на 99% взаимозаменяемы, и на 95% могут быть заменены методом read() .
Метод read()
Похож на предыдущий пример?
Метод close()
Метод eof()
Проверяет не достигнут ли конец файла. Т.е. можно ли из него продолжать чтение. Выше пример с считкой слов оператором >> как раз использует такую проверку.
Метод seekg()
Производит установку текущей позиции в нужную, указываемую числом. В этот метод так же передается способ позиционирования:
![Чтение из файла]()
Добрый день! В этой статье я расскажу о том, как написать программу, которая будет считывать строки из файла. Покажу как записать их в массив или вывести. При написании программы будут использоваться функции из стандартной библиотеки языка C++.
Стандартная библиотека языка C++ <fstream> включает множество функций для работы с файлами. Описание функций можно найти в сети или в учебниках по C++. Здесь же я опишу одну, которая позволит произвести чтение строки из файла.
Содержание файла strings.txt
Три строки, содержащиеся в файле, я запишу массив и выведу на экран.
Пингвин читает содержимое файла
Переходим к написанию программы на C++.
Нашей программе понадобятся два заголовочных файла <iostream> и <fstream>. Первый нужен будет для использования вывода на консоль, второй для работы с файлами.
Объявим две целочисленные константы len и strings, они будут хранить максимальную длину наших строк и количество строк. Объявим символьную константу ch, которая будет хранить разделяющий символ. Первые две константы будут использоваться для объявления массива. Мой файл содержит 3 строки
При помощи значений двух первых констант объявим двумерный массив символов.
Создадим объект класса ostream, в конструктор поместим адрес файла, флаги открытия.
Флаг ios::in позволяет открыть файл для считывания, ios::binary открывает его в двоичном режиме.
Далее стоит проверить открылся ли файл, если не открылся, то завершаем работу программы.
В данный момент программа имеет такой вид
Теперь остается описать алгоритм считывания строк из файла и занесения их в массив с последующим выводом. Для этого понадобится цикл от нуля до strings с инкрементом переменной r. Во время каждого прохода цикла используем перегруженную функцию getline() объекта fs с тремя аргументами.
fs.getline(Массив_символов, Макс_длина_строки, Разделитель_строк)
Функция считывает символы из файла, пока не считает количество равное Макс_длина_строки, либо не встретит на своём пути символ равный Разделитель_строк, а после записывает считанные символы в Массив_символов. В качестве разделителя в моём текстовом файле используется перенос строки.
После сразу же выводим содержимое строки, хранящееся в массиве, при помощи поточного вывода в консоль cout.
Весь листинг конечной программы
За счет константных переменных её можно легко модернизировать. Изменив константу strings, можно указать количество выводимых строк. Чтение из файла будет производится до тех пор, пока массив не заполнится нужным количеством строк. Изменив константу ch, можно изменить разделитель строк(Например, можно разделять их пробелом и занести в массив отдельные слова из файла и т.д.).
Если Вас интересует запись в файл, то почитайте статью о чтении из input.txt и записи данных в файл output.txt.
Пример работы string и пример считывания всех строк из файла в массив с последующим выводом
каков самый быстрый способ чтения текстового файла в строковую переменную?
Я понимаю, что это можно сделать несколькими способами, например, прочитать отдельные байты, а затем преобразовать их в строку. Я искал метод с минимальным кодированием.
![File Read Comparison]()
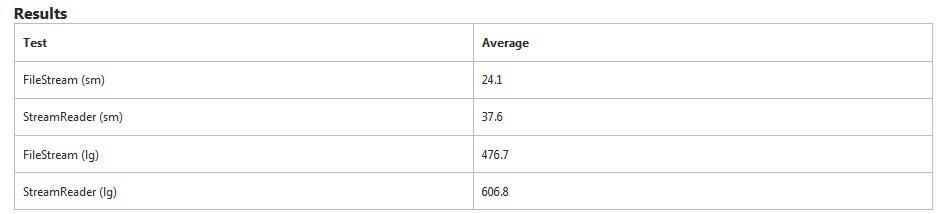
результаты. StreamReader намного быстрее для больших файлов с 10,000+ строки, но разница для небольших файлов незначительна. Как всегда, планируйте различные размеры файлов и используйте файл.ReadAllLines только когда производительность не критична.
StreamReader подход
As the File.ReadAllText подход был предложен другими, вы также можете попробовать быстрее (я не тестировал количественно влияние производительности, но, похоже, это быстрее, чем File.ReadAllText (см. сравнение ниже)). The разница в производительности будет видно только в случае больших файлов, хотя.
сравнение файлов.Readxxx () против StreamReader.Readxxx()
просмотр примерного код через помощью ILSpy я нашел следующее о File.ReadAllLines , File.ReadAllText .
- File.ReadAllText - использует StreamReader.ReadToEnd внутри
- File.ReadAllLines - тоже использует StreamReader.ReadLine внутренне с дополнительными накладными расходами на создание List<string> для возврата в виде прочитанных строк и зацикливания до конца файла.
Таким образом, оба метода являются дополнительный уровень удобства. построен на верх StreamReader . Это видно по показательной части метода.File.ReadAllText() реализация как декомпилированная ILSpy
посмотри .ReadAllText() метод
некоторые важные замечания:
этот метод открывает файл, считывает каждую строку файла, а затем добавляет каждая строка как элемент строки. Затем он закрывает файл. Линия определяется как последовательность символов возврата каретки ('\r'), подача строки ('\n') или возврат каретки сразу после этого по линии подачи. Результирующая строка не содержит завершающий возврата каретки и/или перевода строки.
этот метод пытается автоматически определить кодировку файла на основании наличия меток порядка байтов. Форматы кодирования UTF-8 и UTF-32 (и big-endian и little-endian) можно обнаружить.
используйте перегрузку метода ReadAllText(String, Encoding) при чтении файлы, которые могут содержать импортированный текст, поскольку не распознаны символы могут быть прочитаны неправильно.
дескриптор файла гарантированный быть закрытым этим методом, даже если возникают исключения
string text = File.ReadAllText("Path"); у вас есть весь текст в одну строковую переменную. Если вам нужна каждая строка отдельно, вы можете использовать это:
@Cris извините .Это цитата MSDN Microsoft
в этом эксперименте будут сравниваться два класса. The StreamReader и FileStream класс будет направлен на чтение двух файлов 10K и 200K в полном объеме из каталога приложений.
![enter image description here]()
FileStream - это очевидно быстрее в этом тесте. Это занимает еще 50% больше времени для StreamReader читать мелкий файл. Для большой файл, это заняло еще 27% времени.
StreamReader специально искал разрывы строк в то время как FileStream нет. Это объясняет часть дополнительного времени.
в зависимости от того, что приложение должно делать с разделом данных, может быть дополнительный синтаксический анализ, который потребует дополнительного времени обработки. Рассмотрим сценарий, в котором файл имеет столбцы данных, а строки - CR/LF запятыми. The StreamReader будет работать по строке текста, ища CR/LF , а затем приложение будет выполнять дополнительный синтаксический анализ, ища конкретное местоположение данных. (Вы подумали о струне. Субстрат приходит без цены?)
С другой стороны, FileStream читает данные порциями и активный разработчик мог бы написать немного больше логики, чтобы использовать поток в свою пользу. Если необходимые данные находятся в определенных позициях в файле, это, безусловно, путь, поскольку он сохраняет использование памяти вниз.
FileStream является лучшим механизмом для скорости, но займет больше логики.
Примеры работы с текстовыми файлами. Модификация файлов. Сортировка данных в файлах. Конвертирование данных файла в массив
В данной теме наводятся примеры решения известных задач, возникающих при обработке текстовых файлов на языке C++. Проработав решения этих задач, вы научитесь обрабатывать массивы строчных данных, управлять распределением памяти а также использовать средства C++ для работы с текстовыми файлами.
Содержание
- 2. Функция CountLinesInFile() . Подсчет количества строк в текстовом файле
- 3. Функция GetStringsFromFileC() . Получить массив (список) строк типа char* из текстового файла
- 4. Функция GetStringsFromFileS() . Получить массив строк типа string из текстового файла
- 5. Функция SetStringsToFileS() . Записать массив (список) строк типа string в текстовый файл
- 6. Функция ChangeStringInFileC() . Замена строки в текстовом файле
- 7. Функция RemoveStringFromFileByIndex() . Удаление строки из файла по его номеру
- 8. Функция InsertStringToFile() . Вставка строки в заданную позицию в файле
- 9. Функция SwapStringsInFile() . Обмен местами двух строк в файле
- 10. Функция ReverseStringsInFile() . Реверсирования строк файла (перестановка строк файла в обратном порядке)
- 11. Функция SortStringsInFile() . Сортировка строк в файле
- Связанные темы
Поиск на других ресурсах:
1. Как определить, что данные в текстовом файле закончились?
Для определения конца файла используется функция eof() . Функция возвращает результат типа bool . Прототип функции следующий
здесь std – пространство имен, в котором объявлена функция eof() .
Если при вызове функции текущий указатель чтения указывает на конец файла, то функция возвращает true . В противном случае функция возвращает false .
Пример 1.
Ниже приведен фрагмент кода, в котором используется функция eof() для определения, достигнут ли конец файла, которому соответствует экземпляр с именем inputFile
Пример 2.
Чаще всего функция eof() используется в цикле while при чтении строк файла
Как только будет достигнут конец файла inputFile , то произойдет выход из цикла.
2. Функция CountLinesInFile() . Подсчет количества строк в текстовом файле
Функция CountLinesInFile() возвращает количество строк в текстовом файле.
Использование функции GetStringsFromFileC() может быть, например, следующим:
4. Функция GetStringsFromFileS() . Получить массив строк типа string из текстового файла
Работа с типом string более удобна чем с типом char *. В следующем фрагменте кода реализована функция GetStringsFromFileS() , читающая строки из текстового файла и записывающая их в массив (список) типа string . Данная функция использует функцию CountLinesInFile() , которая описывается в пункте 2 данной темы.
Использование функции GetStringsFromFileS() может быть, например, следующим
Результат работы программы (содержимое файла TextFile1.txt ):
5. Функция SetStringsToFileS() . Записать массив (список) строк типа string в текстовый файл
При работе с текстовыми файлами полезна функция SaveStringsToFileS() , которая записывает массив строк в файл. В нижеследующих примерах эта функция будет использоваться для записи модифициованного списка в файл.
Ниже приведен пример использования функции SetStringsToFileS() .
6. Функция ChangeStringInFileC() . Замена строки в текстовом файле
В примере приведена функция, заменяющая строку в файле в заданной позиции. Данная функция использует следующие функции:
Данная функция не использует дополнительный файл для копирования. Функция получает строки файла в виде списка lines, которые служат копией файла. Затем происходит запись этих строк в этот же файл за исключением строки, которую нужно заменить в файле. В позиции замены записывается входная строка замены. Таким образом происходит замена строки в текстовом файле.
Использование данной функции може быть, например, следующим:
По желанию, можно изменить ввод входных данных (имя файла, позиция, строка замены).
7. Функция RemoveStringFromFileByIndex() . Удаление строки из файла по его номеру
Удаление строки из файла по его номеру можно выполнять по примеру п. 6 (замена строки в текстовом файле).
Общий алгоритм следующий:- прочитать все строки файла в массив (список);
- удалить строку из массива;
- записать модифицированный массив обратно в файл.
Для формирования списка строк можно использовать функции GetStringsFromFileC() и GetStringsFromFileS() , которые описаны в пунктах 3 и 4.
Текст функции удаления строки по его номеру следующий.
Использование функции может быть, например, следующим
8. Функция InsertStringToFile() . Вставка строки в заданную позицию в файле
Подход такой же, как в предыдущих пунктах. Нужно получить строки файла в виде массива (тип string или char *). Затем нужно вставить строку в массив и записать измененный массив строк обратно в файл.
Если значение позиции вставки равно количеству элементов в файле, то строка добавляется в конец файла.Вызов функции InsertStringToFile() в функции main() может быть следующим.
9. Функция SwapStringsInFile() . Обмен местами двух строк в файле
Сокращенный алгоритм функции SwapStringsInFile() следующий:
- Прочитать строки файла в список.
- Поменять строки в списке.
- Записать измененный список обратно в файл.
Текст функции обмена строк следующий.
Вызов функции SwapStringsInFile() из функции main() может быть следующим
10. Функция ReverseStringsInFile() . Реверсирования строк файла (перестановка строк файла в обратном порядке)
Алгоритм метода следующий:
- считать строки из файла и записать их в массив;
- обменять местами элементы массива так, чтобы строки массива размещались в обратном порядке;
- записать измененный массив снова в файл
Текст функции ReverseStringsInFile() следующий
Использование ReverseStringsInFile () может быть, например, следующим
11. Функция SortStringsInFile() . Сортировка строк в файле
В примере демонстрируется сортировка строк файла с помощью метода вставки. Предварительно строки копируются в массив и там сортируются. Затем, отсортированный массив строк обратно записывается в файл.
Читайте также: