
Как сохранить массив numpy в файл
Обновлено: 04.07.2024
Статистическое программное обеспечение Stata позволяет сохранять короткие текстовые фрагменты в наборе данных. Это достигается либо с использованием notes и/или characteristics .
Это функция, которая имеет большое значение для меня, поскольку она позволяет мне сохранять разнообразную информацию, начиная от напоминаний и списков дел до информации о том, как я генерировал данные, или даже в том, какой метод оценки для конкретной переменной был.
Для небольшого массива NumPy я пришел к выводу, что комбинация функции numpy.savez() и dictionary может адекватно хранить всю соответствующую информацию в одном файле.
Однако остается вопрос:
Есть ли лучшие способы потенциально включить другие части информации в файл, содержащий массив NumPy или (большой) Pandas DataFrame ?
Мне особенно интересно узнать о каких-либо плюсах и минусах любых предложений, которые вы можете иметь с примерами. Чем меньше зависимостей, тем лучше.
ОТВЕТЫ
Ответ 1
Есть много вариантов. Я буду обсуждать только HDF5, потому что у меня есть опыт использования этого формата.
Преимущества: Portable (может быть прочитан за пределами Python), встроенное сжатие, недоступность памяти, поддержка метаданных.
Недостатки: Опора на один низкоуровневый API C, возможность повреждения данных как одного файла, удаление данных не уменьшает размер автоматически.
По моему опыту, для повышения производительности и мобильности, не используйте pyTables / HDFStore для хранения числовых данных. Вместо этого вы можете использовать интуитивно понятный интерфейс, предоставляемый h5py .
Хранить массив
Сжатие и поршень
Существует множество вариантов сжатия, например, blosc и lzf являются хорошим выбором для производительности сжатия и декомпрессии. Примечание. gzip является родным; другие фильтры сжатия могут не поставляться по умолчанию при установке HDF5.
Chunking - это еще один вариант, который при согласовании с тем, как вы читаете данные из памяти, может значительно повысить производительность.
Добавить некоторые атрибуты
Сохранить словарь
Доступ из памяти
Нет никакой замены для чтения документации h5py , которая предоставляет большую часть C API, но вы должны видеть из вышеизложенного, существует значительная гибкость.
Ответ 2
Я согласен с JPP в том, что хранение hdf5 является хорошим вариантом. Разница между его решением и моим мином - это использование ячеек памяти Pandas вместо массивов numpy. Я предпочитаю структуру данных, так как это позволяет использовать смешанные типы, многоуровневое индексирование (даже индексирование даты и времени, что очень важно для моей работы) и маркировка столбцов, что помогает мне помнить, как организованы разные наборы данных. Кроме того, Pandas обеспечивает множество встроенных функциональных возможностей (как numpy). Еще одно преимущество использования Pandas заключается в создании встроенного hdf-создателя (например, pandas.DataFrame.to_hdf), который я нахожу удобным
При хранении данных в h5 у вас есть возможность хранить словарь метаданных, что может быть вашими заметками для себя или фактическими метаданными, которые не нужно хранить в фрейме данных (я также использую это для установки флагов, например,
Ответ 3
Практический способ может заключаться в встраивании метаданных непосредственно в массив Numpy. Преимущество состоит в том, что, как вы хотите, нет никакой дополнительной зависимости, и это очень простое использование в коде. Однако это не полностью отвечает на ваш вопрос, потому что вам по-прежнему нужен механизм для сохранения данных, и я бы рекомендовал использовать решение jpp с использованием HDF5.
Чтобы включить метаданные в ndarray , в документации есть пример. Вы в основном должны подклассы в ndarray и добавить поле info или metadata или любой другой.
Это даст (код из приведенной выше ссылки)
Чтобы сохранить данные через numpy , вам необходимо перегрузить функцию write или использовать другое решение.
Ответ 4
Ответ jpp довольно всеобъемлющий, просто хотел упомянуть, что паркет pandas v22 очень удобен и быстр, и почти без каких-либо недостатков vs csv (допустим, возможно, перерыв на кофе).
В момент написания вам также понадобится
Что касается добавления информации, у вас есть метаданные, которые привязаны к данным
Ответ 5
Это интересный вопрос, хотя я считаю очень открытым.
Текстовые фрагменты
Для текстовых фрагментов, которые имеют буквальные заметки (как в, а не в коде, а не данные), я действительно не знаю, каков ваш вариант использования, но я не понимаю, почему я отклоняюсь от использования обычного with open() as f.
Небольшие коллекции различных данных
Конечно, ваш npz работает. На самом деле то, что вы делаете, очень похоже на создание словаря со всем, что вы хотите сохранить и проследить этот словарь.
См. Здесь для обсуждения различий между pickle и npz (но в основном, npz оптимизирован для массивов numpy).
Лично я бы сказал, что если вы не храните массивы Numpy, я бы использовал pickle и даже реализовал бы быстрый класс MyNotes который в основном является словарем для сохранения материала в нем, с некоторыми дополнительными функциями, которые могут вам понадобиться.
Сбор больших объектов
Для действительно больших np.arrays или dataframes, которые я использовал до формата HDF5. Хорошо, что он уже встроен в панды, и вы можете напрямую df.to_hdf5() . Это необходимо под pytables -installation должно быть довольно безболезненным с пипсом или conda-, но напрямую с помощью pytables может быть гораздо больнее.
Опять же, эта идея очень похожа: вы создаете HDFStore, который является довольно большим словарем, в котором вы можете хранить (почти любые) объекты. Преимущество состоит в том, что формат использует пространство более разумно, используя повторение аналогичных значений. Когда я использовал его для хранения некоторых
2 Гбайт данных, он смог уменьшить его почти на полный порядок (
Последний игрок: feather
Feather - это проект, созданный Уэсом Маккинни и Хэдли Викхем поверх структуры Apache Arrow, для сохранения данных в двоичном формате, который является агностиком языка (и поэтому вы можете читать R и Python). Тем не менее, он все еще находится в разработке, и в прошлый раз, когда я проверил, они не поощряли его использовать для долгосрочного хранения (поскольку спецификация может измениться в будущих версиях), а не просто использовать его для связи между R и Python.
Оба они только что запустили Ursalabs, буквально всего несколько недель назад, которые будут продолжать развивать эту и подобные инициативы.
Ответ 6
Вы указали в качестве причин этого вопроса:
. он позволяет мне сохранять разнообразную информацию, начиная от напоминаний и списков дел, до информации о том, как я создал данные, или даже о том, какой метод оценки для конкретной переменной был.
Могу ли я предложить другую парадигму, чем предложенная Stata? Заметки и характеристики кажутся очень ограниченными и ограничиваются только текстом. Вместо этого вы должны использовать Jupyter Notebook для своих проектов исследований и анализа данных. Он предоставляет такую богатую среду для документирования вашего рабочего процесса и сбора деталей, мыслей и идей, когда вы проводите анализ и исследования. Его можно легко разделить, и он готов к презентации.
Вот галерея интересных Jupyter Notebooks во многих отраслях и дисциплинах, чтобы продемонстрировать множество функций и использовать ноутбуки. Он может расширить ваши горизонты, не пытаясь разработать способ маркировки простых фрагментов текста для ваших данных.
NumPy не поставляется с Python по умолчанию, поэтому его необходимо установить. Как я рекомендовал дляПандыустановка, самый простой способ получить NumPy (вместе с кучей других пакетов) - это установитьанаконда, Если вы не хотите устанавливать все эти пакеты и просто устанавливать NumPy, вы можете загрузить версию для вашей операционной системы сэта страница,
После того, как вы скачали и установили NumPy, вам нужно импортировать его каждый раз, когда вы захотите использовать его в Python IDE (Интегрированная среда развития) нравитсяБлокнот JupyterилиSpyder(они оба поставляются с Anaconda по умолчанию). Напоминаем, что импорт библиотеки означает загрузку ее в память, и тогда она будет доступна для вас. Для импорта NumPy вам нужно написать следующий код:
Создание массивов NumPy, загрузка и сохранение файлов
NumPy работает с объектами Python, называемыми многомернымимассивы, Массивы в основном представляют собой наборы значений, и они имеют одно или несколько измерений. Структура данных массива NumPy также называетсяndarray, сокращение от n-мерного массива. Массив с одним измерением называетсявектори массив с двумя измерениями называетсяматрица, Наборы данных обычно создаются в виде матриц, и гораздо проще открывать их с помощью NumPy, например, вместо работы со списком списков.
Превратить список в массив NumPy довольно просто:
И печать / отображение массива будет выглядеть так:
Другой вариант - открыть файл CSV, используяnp.genfromtxt ()функция:
Аргумент внутри скобок - это имя файла (и путь, если необходимо), разделитель установлен на «;», чтобы убедиться, что он анализируется правильно - вы можете использовать разные символы для разбора (например, «,»); и skip_header, установленный в «1», заставит csv загружаться в массив без строки заголовка. Вы можете просто не включать его, если вам нужны заголовки (по умолчанию это ноль).
Еще одна интересная особенность - возможность создавать различные массивы, такие как случайные массивы: np.random.rand(3,4) создаст массив случайных чисел 3x4 между 0 и 1, в то время как np.random.rand(7,6)*100 создаст массив случайных чисел размером от 7 до 6 в диапазоне от 0 до 100; Вы также можете определить размер массива по-другому: np.random.randint(10,size=(3,2)) создает массив размером 3x2 со случайными числами от 0 до 9. Помните, что при использовании этого синтаксиса последняя цифра (10) не входит в диапазон.
Также возможно создать массив всех нулей: np.zeros(4,3) (4x3 массив всех нулей) или единицы np.ones((4)) (4х1 массив из них); вы можете командовать np.full((3,2),8) создать массив 3х2, полный 8. Вы, конечно, можете изменить каждое из этих чисел, чтобы получить нужный вам массив.
Работа и проверка массивов
Теперь, когда у вас есть загруженный массив, вы можете проверить его размер (количество элементов), набрав array.size и его форму (размеры - строки и столбцы), набрав array.shape , Вы можете использовать array.dtype чтобы получить типы данных массива (с плавающей точкой, целые числа и т. д. - см. больше вNumPy документация) и если вам нужно преобразовать тип данных, вы можете использовать array.astype(dtype) команда. Если вам нужно преобразовать массив NumPy в список Python, для этого тоже есть команда: array.tolist() ,
Индексирование и нарезка
Индексирование и нарезка массивов NumPy работает очень похоже на работу со списками Python: array[5] вернет элемент в 5-м индексе, и array[2,5] вернет элемент в index [2] [5]. Вы также можете выбрать первые пять элементов, например, с помощью двоеточия (:). array[0:5] вернет первые пять элементов (индекс 0–4) и array[0:5,4] вернет первые пять элементов в столбце 4. Вы можете использовать array[:2] получить элементы от начала до индекса 2 (не включая индекс 2) или array[2:] вернуться со 2-го индекса до конца массива. array[:,1] вернет элементы с индексом 1 во всех строках
Присвоение значений массиву NumPy, опять же, очень похоже на это в списках Python: array[1]=4 присвоит значение 4 элементу с индексом 1; Вы можете сделать это для нескольких значений: array[1,5]=10 или используйте нарезку при назначении значений: array[:,10]=10 изменит весь 11-й столбец на значение 10.
Сортировка и изменение формы
array.sort() может использоваться для сортировки вашего массива NumPy - вы можете передавать различные аргументы в скобках, чтобы определить, что вы хотите отсортировать (например, используя аргумент «order = string / list of strings»). См. больше примеров вдокументация). array.sort(axis=0) отсортирует конкретную ось массива - строки или столбцы. two_d_arr.flatten() сгладит 2-мерный массив в 1-мерный массив. array.T будет транспонировать массив - то есть столбцы станут строками и наоборот. array.reshape(x,y) изменил бы ваш массив до размера, который вы установили с помощью x и y. array.resize((x,y)) изменит форму массива на x и y и заполнит новые значения нулями.
Объединение и расщепление
Вы можете использовать np.concatenate((array1,array2),axis=0) объединить два массива NumPy - это добавит массив 2 в виде строк в конец массива 1, в то время как np.concatenate((array1,array2),axis=1) добавит массив 2 в качестве столбцов в конец массива 1. np.split(array,2) будет разбить массив на два подмассива и np.hsplit(array,5) разделит массив горизонтально напятыепоказатель.
Добавление и удаление элементов
Конечно, есть команды для добавления и удаления элементов из массивов NumPy:
- np.append(array,values) добавит значения в конец массива.
- np.insert(array, 3, values) вставит значения в массив перед индексом 3
- np.delete(array, 4, axis=0) удалит строку по индексу 4 массива
- np.delete(array, 5, axis=1) удалит столбец по индексу 5 массива
Описательная статистика
Вы можете использовать методы NumPy для получения описательной статистики по массивам NumPy:
- np.mean(array,axis=0) вернет среднее значение по определенной оси (0 или 1)
- array.sum() вернет сумму массива
- array.min() вернет минимальное значение массива
- array.max(axis=0) вернет максимальное значение конкретной оси
- np.var(array) вернет дисперсию массива
- np.std(array,axis=1) вернет стандартное отклонение конкретной оси
- array.corrcoef() вернет коэффициент корреляции массива
- numpy.median(array) вернет медиану элементов массива
Делать математику с NumPy
Любое руководство по NumPy не будет полным без числовых и математических операций, которые вы можете выполнять с NumPy! Давайте рассмотрим их:
np.add(array ,1) добавит 1 к каждому элементу в массиве и np.add(array1,array2) добавит массив 2 к массиву 1. То же самое относится и к np.subtract(), np.multiply(), np.divide() and np.power() - все эти команды будут работать точно так же, как описано выше.
Вы также можете заставить NumPy возвращать различные значения из массива, например:
- np.sqrt(array) вернет квадратный корень каждого элемента в массиве
- np.sin(array) вернет синус каждого элемента в массиве
- np.log(array) вернет натуральный логарифм каждого элемента в массиве
- np.abs(arr) вернет абсолютное значение каждого элемента в массиве
- np.array_equal(arr1,arr2) вернется True если массивы имеют одинаковые элементы и форму
Можно округлить разные значения в массиве: np.ceil(array) округляется до ближайшего целого числа, np.floor(array) будет округляться до ближайшего целого числа и np.round(array) будет округлять до ближайшего целого числа.
Визуально, данный массив выглядит следующим образом:
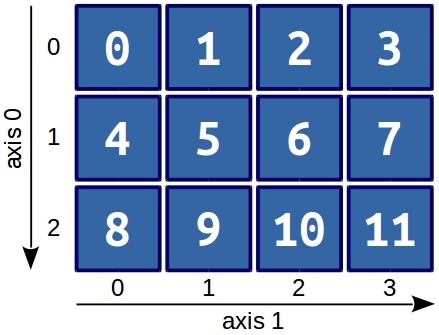
Глядя на картинку, становится понятно, что первая ось (и индекс соответственно) - это строки, вторая ось - это столбцы. Т.е. получить элемент 9 можно простой командой:
Снова можно подумать, что ничего нового - все как в стандартном Python. Да, так и есть, и, это круто!
Еще круто, то что NumPy добавляет к удобному и привычному синтаксису Python, весьма удобные трюки, например - транслирование массивов:
В данном примере, без всяких циклов, мы умножили каждый столбец из массива a на соответствующий элемент из массива b .
Т.е. мы как бы транслировали (в какой-то степени можно сказать - растянули) массив b по массиву a .
То же самое мы можем проделать с каждой строкой массива a :
В данном случае мы просто прибавили к массиву a массив-столбец c . И получили, то что хотели.
При работе с двумерными или трехмерными массивами, особенно с массивами большей размерности, становится очень важным удобство работы с элементами массива, которые расположены вдоль отдельных измерений - его осей.
Например, у нас есть двумерный массив и мы хотим узнать его минимальные элементы по строкам и столбцам.
Для начала создадим массив из случайных чисел и пусть, для нашего удобства, эти числа будут целыми:
Минимальный элемент в данном массиве это:
А вот минимальные элементы по столбцам и строкам:
Такое поведение заложено практически во все функции и методы NumPy:
Что насчет вычислений, их скорости и занимаемой памяти?
Для примера, создадим трехмерный массив:
Почему именно трехмерный?
На самом деле реальный мир вовсе не ограничивается таблицами, векторами и матрицами.
Еще существуют тензоры, кватернионы, октавы. А некоторые данные, гораздо удобнее представлять именно в трехмерном и четырехмерном представлении:
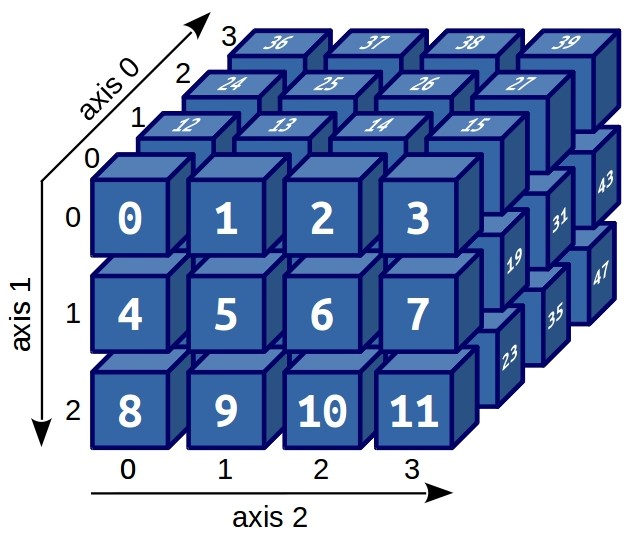
Визуализация (и хорошее воображение) позволяет сразу догадаться, как устроена индексация трехмерных массивов. Например, если нам нужно вытащить из данного массива число 31, то достаточно выполнить:
В самом деле, у массивов есть целый ряд важных атрибутов. Например, количество осей массива (его размерность), которую при работе с очень большими массивами, не всегда легко увидеть:
Массив a действительно трехмерный.
Но иногда становится интересно, а на сколько же большой массив перед нами. Например, какой он формы, т.е. сколько элементов расположено вдоль каждой оси? Ответить позволяет метод ndarray.shape :
Метод ndarray.size просто возвращает общее количество элементов массива:
Еще может встать такой вопрос - сколько памяти занимает наш массив?
Иногда даже возникает такой вопрос - влезет ли результирующий массив после всех вычислений в оперативную память?
Что бы на него ответить надо знать, сколько "весит" один элемент массива:
ndarray.itemsize возвращает размер элемента в байтах.
Теперь мы можем узнать сколько "весит" наш массив:
Итого - 384 байта. На самом деле, размер занимаемой массивом памяти, зависит не только от количества элементов в нем, но и от испльзуемого типа данных:
dtype('int64') - означает, что используется целочисленный тип данных, в котором для хранения одного числа выделяется 64 бита памяти.
Но если мы выполним какие-нибудь вычисления с массивом, то тип данных может измениться:
Теперь у нас есть еще один массив - массив b и его тип данных 'float64' - вещественные числа (числа с плавающей точкой) длинной 64 бита.
И так, массив может быть создан из обычного списка или кортежа Python с использованием функции array() .
Причем тип полученного массива зависит от типа элементов последовательности:
Функция array() преобразует последовательности последовательностей в двумерные массивы, а последовательности последовательностей, которые тоже состоят из последовательностей в трехмерные массивы.
То есть уровень вложенности исходной последовательности определяет размерность получаемого массива:
Очень часто возникает задача создания массива определенного размера, причем, чем заполнен массив абсолютно неважно.
В этом случае можно воспользоваться циклами или генераторами списков (кортежей), но NumPy для таких случаев предлагает более быстрые и менее затратные функции-заполнители.
Функция zeros заполняет массив нулями, функция ones - единицами, а функция empty - случайными числами, которые зависят от состояния памяти.
По умолчанию, тип создаваемого массива - float64 .
Для создания последовательностей чисел NumPy предоставляет функцию arange , которая возвращает одномерные массивы:
Если функция arange используется с аргументами типа float , то предсказать количество элементов в возвращаемом массиве не так-то просто.
Гораздо чаще возникает необходимость указания не шага изменения чисел в диапазоне, а количества чисел в заданном диапазоне.
Функция linspace , так же как и arange принимает три аргумента, но третий аргумент, как раз и указывает количество чисел в диапазоне.
Функция linspace удобна еще и тем, что может быть использована для вычисления значений функций на заданном множестве точек:
Чтобы быстрее разобраться с примерами печати массивов воспользуемся методом ndarray.reshape() , который позволяет изменять размеры массивов.
Одномерные массивы в NumPy печатаются в виде строк:
Двумерные массивы печатаются в виде матриц:
Трехмерные массивы печатаются в виде списка матриц, которые разделены пустой строкой:
Можете поэкспериментировать с печатью массивов большей размерности и вы убедитесь, что в ней довольно легко ориентироваться.
В случае, если массив очень большой (больше 1000 элементов), NumPy печатает только начало и конец массива, заменяя его центральную часть многоточием.
Если необходимо выводить весь массив целиком, то такое поведение печати можно изменить с помощью set_printoptions .
Занимаясь научными вычислениями, вы получаете результаты, которые должны быть обязательно сохранены.
Самый надежный способ хранения - это загрузка массивов с результатами в файл, так как их легко хранить и передавать.
Для данных нужд, NumPy предоставляет очень удобные инструменты, позволяющие производить загрузку и выгрузку массивов в файлы различных форматов, а также производить их сжатие, необходимое для больших массивов.
NumPy имеет два собственных формата файлов .npy - для хранения массивов без сжатия и .npz - для предварительного сжатия массивов.
Есть ли способ вывести массив NumPy в файл CSV? У меня есть двумерный массив NumPy, и мне нужно создать дамп в удобочитаемом формате.
numpy.savetxt сохраняет массив в текст файл.
tofile - удобная функция сделать это:
На странице руководства есть несколько полезных заметок:
Это удобная функция для быстрого хранения данных массива. Информация о порядке байтов и точности теряется, поэтому этот метод не является хорошим выбором для файлов, предназначенных для архивирования данных или передачи данных между компьютерами с различным порядком байтов. Некоторые из этих проблем могут быть преодолены путем вывода данных в виде текстовых файлов за счет скорости и размера файла.
Заметка. Эта функция не создает многострочные CSV-файлы, она сохраняет все в одну строку.
Вы также можете сделать это с чистым Python без использования каких-либо модулей.
В Python мы используем модуль csv.writer () для записи данных в файлы csv. Этот модуль похож на модуль csv.reader ().
Разделитель - это строка, используемая для разделения полей. Значением по умолчанию является запятая (,).
Запись массивов записей в виде CSV-файлов с заголовками требует немного больше работы.
В этом примере читается файл CSV с заголовком в первой строке, а затем записывается тот же файл.
Обратите внимание, что этот пример не рассматривает строки с запятыми. Чтобы рассмотреть кавычки для нечисловых данных, используйте пакет csv :
Если вы хотите сохранить массив numpy (например, your_array = np.array([[1,2],[3,4]]) ) в одной ячейке, вы можете сначала преобразовать его с помощью your_array.tolist() .
Затем сохраните его обычным способом в одну ячейку с delimiter=';' и ячейка в csv-файле будет выглядеть так [[1, 2], [2, 4]]
Тогда вы можете восстановить ваш массив следующим образом: >
Вы можете использовать pandas . Требуется дополнительная память, так что это не всегда возможно, но очень быстро и просто в использовании.
Если вы не хотите заголовок или индекс, используйте to_csv("/path/to/file.csv", header=None, index=None)
если вы хотите написать в столбце:
Здесь «a» - это имя массива numpy, а «file» - переменная для записи в файл.
Если вы хотите написать в строке:
Я считаю, что вы также можете сделать это довольно просто следующим образом:
- Конвертировать массив Numpy в фрейм данных Pandas
- Сохранить как CSV
Как уже говорилось, лучший способ вывести массив в файл CSV - использовать метод .savetxt(. ) . Тем не менее, есть определенные вещи, которые мы должны знать, чтобы сделать это правильно.
Например, если у вас есть пустой массив с dtype = np.int32 в качестве
И хотите сохранить, используя savetxt как
Он будет хранить данные в экспоненциальном формате с плавающей запятой как
Вам придется изменить форматирование, используя параметр fmt как
Хранить данные в оригинальном формате
Сохранение данных в сжатом формате gz
Кроме того, savetxt может использоваться для хранения данных в сжатом формате .gz , что может быть полезно при передаче данных по сети.
Нам просто нужно изменить расширение файла на .gz , и numpy позаботится обо всем автоматически
Читайте также: