Как тестировать xml файл
Обновлено: 06.07.2024
Некоторых пользователей, например, смущает большое количество окон, появляющихся при редактировании теста. У многих уже есть готовые тесты, набранные в текстовых редакторах, например MS Word, или просто отсканированные с бумажных копий, и занесение всей информации в редактор тестов методом copy+paste становиться трудоемким, особенно при большом количестве вопросов.
VeralTest предоставляет такую возможность. Все дело в том, что формат файлов, в которых хранятся тесты, основан на языке XML – специальном языке разметки гипертекста. Файлы *.xtf, используемые VeralTest, представляют собой zip архивы, в которых содержится файл content.xml (это непосредственно сам тест) и файлы рисунков, используемых в тесте. Чтобы проверить это, достаточно изменить расширение файла на zip и распаковать полученный архив.
Краткие сведения о языке XML
XML – это универсальный язык разметки, позволяющий с помощью специальных ключевых слов (тегов) выделять в тексте определенные элементы. Звучит сложно? Ну хорошо, вот простой пример: Рассмотрим один из самых распространенных документов – письмо электронной почты. Какие элементы можно выделить в этом документе?
1. Адрес отравителя; 2. Арес получателя; 3. Тема письма; 4. Текст письма. На языке XML этот документ можно записать так:
Ключевые слова <mail>, </mail>, <from>, </from>, <to>, </to>, <content>, </content> и есть теги, они отделяют одни элементы документа от других. Из нашего примера легко видеть, что каждый тег имеет своего «однофамильца» - отличающегося только символом «/» перед названием. Это открывающий и закрывающий теги. Пара таких тегов называется «Контейнер». Почему контейнер? Потому что, как и любой контейнер, он может хранить что-нибудь внутри себя. Например, контейнер <content></content> содержит внутри себя текст письма, а контейнер <from></from> – адрес отправителя. Особняком в этом примере стоит контейнер <mail></mail> - он хранит в себе все письмо целиком. Про него можно сказать, что он хранит не только текст, но и другие контейнеры.
И так, любой XML документ – это набор контейнеров. Каждый контейнер состоит из открывающего и закрывающего тега. Открывающий тег должен быть записан в виде <имя_тега>, а закрывающий – в виде </имя_тега>. Внутри контейнера может содержаться текст или другие контейнеры. Видите, как все просто!
Внимательный читатель, конечно же, задаст вопрос: «А какие имена должны быть у тегов?». И вот на этот вопрос я, к сожалению, не смогу ответить. И дело здесь не в том, что я плохо знаком с языком XML, просто язык XML задает лишь правила написания тегов, а имена тегов могут быть любыми. Наш пример можно записать и в таком виде:
С точки зрения XML этот документ имеет такое же право на существование, как и предыдущий.
Атрибут записывается в виде имя=”значение”. Значение атрибута всегда должно помещаться в кавычки.
И еще: Любой XML документ должен начинаться с такой строки:
Закрывающий тег здесь не нужен.
Что нам понадобиться
Создаем простой тест
Рассмотрим создание простого теста. Наш тест будет состоять из двух вопросов, вопрос с единичным выбором ответа и вопрос с множественным выбором ответа:Кто автор произведения «Евгений Онегин»?
Какие из этих городов находятся в Российской Федерации?
- Кишинев
- Ярославль
- Минск
- Нижний Новгород
Теперь рассмотрим, как этот тест должен быть записан при помощи XML.
Посмотрим, из каких элементов состоит написанный нами текст.
Первая строчка – это стандартный заголовок XML документа. Мы уже говорили о нем выше. Атрибут encoding указывает кодировку, в которой записан текст.
Вторая строчка задает ссылку на файл, в котором хранятся правила для составления тестов на языке XML. Вот в нем-то как раз и указано, какие названия элементов могут использоваться и в каком порядке элементы должны следовать.
Первые две строчки используются без изменений в любом тесте, поэтому при создании новых тестов их можно просто скопировать их из этого примера и вставить в начало нового документа.
Далее следует элемент <test> - это корневой элемент, который содержит собственно сам тест.
Внутри блока <questions> находятся непосредственно сами вопросы. В системе VeralTest различают пять типов вопросов, и каждый тип вопроса задается собственным элементом. Перечислим их:
Вопрос с единичным выбором
Вопрос с множественным выбором
Вопрос с вводом числа
Вопрос с вводом текста
Вопрос с сопоставлением
В нашем примере присутствуют вопросы двух типов: Вопрос с единичным выбором и Вопрос с множественным выбором, поэтому мы используем элементы <single> и <check>.
В нашем примере в первом вопросе правильным ответом является второй (b), а во втором вопросе – второй и четвертый (b,d). Пусть за каждый правильный выбор тестируемому дается один балл. Тогда, при описании первого вопроса мы задаем rating=”1” у второго элемента <answer>, а у всех остальных – rating=”0”. У второго вопроса значение атрибута rating=”1” устанавливаем у второго и четвертого элемента <answer>, а у остальных – rating=”0”.
Таким образом, при правильном ответе на оба вопроса испытуемый получит три балла.
Запишите этот пример в удобном для вас текстовом редакторе. Будьте внимательны, не допускайте ошибок при написании элементов, иначе ничего не получится.
После того, как тест составлен, нужно сохранить его с именем content.xml. Если вы пользуетесь специализированным XML редактором, то достаточно просто нажать на кнопку «Сохранить» и дать название content сохраняемому файлу.
Если вы пользуетесь редактором простого текста, например блокнотом, то выберите пункт меню «Файл/сохранить как», в диалоговом окне сохранения выберите тип файла: «Все файлы» и дайте имя сохраняемому файлу content.xml.
Если вы пользуетесь текстовым процессором типа MS Word, то задача несколько усложняется. Вам сначала надо сохранить файл как обычный текст (*.txt), а затем переименовать его в content.xml
Следующим шагом будет упаковка полученного файла content.xml в архив zip. Пользователи Windows версии XP и выше могут сделать это следующим образом:
Пользователям младших версий Windows для упаковки придется использовать сторонние архиваторы: WinZip, WinRar и т.д.
Последний шаг состоит в переименовании полученного zip архива content.zip. Дайте файлу удобное название и расширение: *.xtf, например mytest.xtf
Заключение
Проверять файл по XSD-схеме целесообрано в исключительных случаях, например, если скрипт xml-healer.py не справился с исправлением файла. Подробнее в главе IV. Скрипт для замены служебных символов в XML .
XMLPad уступает по удобству и возможностям MS Visual Studio, но если вы не являетесь программистом и у вас не установлена MS Visual Studio, лучше воспользоваться XMLPad.
Проверка по XSD-схеме в XMLPad¶
- Откройте XML-файл, который требуется проверить в XMLPad File > Open.

- Чтобы проверить файл по заданной XSD-схеме, его надо с ней ассоциировать. Перейдите в меню XML > Assign Schema/DTD.

- Выберите W3C Schema и нажмите Browse, затем выберите XSD-схему для проверки.


- После того, как XSD-схема ассоциирована, нажмите F7 или XML > Validate, чтобы проверить файл. В нижней части окна будут выведены ошибки, нажав на которые можно подсветить строку, в которой они находятся.

Для удобства отображения можно включить переносы строк Edit > Word Wrap.
Проверка по XSD-схеме в MS Visual Studio¶
- Откройте XML-файл, который требуется проверить в MS Visual Studio Файл > Открыть > Файл.

- Чтобы проверить файл по заданной XSD-схеме, его надо с ней ассоциировать. Перейдите в меню XML-код > Схемы. .


Проверка на соответсвие XSD-схеме будет осуществляться автоматически на лету. Внизу в окне Списка ошибок будет отображаться список ошибок. При нажатии на ошибку, она будет подсвечена в редакторе.
Добавить окно Списка ошибок можно через Вид > Списка ошибок.
Если вы тестируете API, то должны знать про два основных формата передачи данных:
Сегодня я расскажу вам про XML. В списке доп литературы будет ссылка на книгу по XML, у меня нет цели ее дублировать, но я расскажу про этот формат тем, кто XML еще в глаза не видел. А дальше уже гуглим сами ))
Ссылка на Хабр (там содержание кликабельное)
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.

Содержание
- Как устроен XML
- Теги
- Корневой элемент
- Значение элемента
- Атрибуты элемента
- XML пролог
- XSD-схема
- Практика: составляем свой запрос
- 1. Есть корневой элемент
- 2. У каждого элемента есть закрывающийся тег
- 3. Теги регистрозависимы
- 4. Правильная вложенность элементов
- 5. Атрибуты оформлены в кавычках
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
И разберемся, что означает эта запись.
![]()
Тега всегда два:
![]()
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!
![]()
Корневой элемент
![]()
Он мог бы называться по другому:
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
![]()
![]()
![]()
![]()
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.
![]()
Но оба значения идут без кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
![]()
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<attribute type="PHONE" rawId="AL.2.PH.1">
Давайте разберем эту запись. У нас есть основной элемент party.
![]()
У него есть 3 атрибута:
![]()
Внутри party есть элементы field.
![]()
![]()
Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
![]()
У элемента attribute есть атрибуты:
![]()
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?>
XSD-схема
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- .
![]()
Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!
![]()
Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.
![]()
Итого, как используется схема при разработке SOAP API:
Правильный запрос
Неправильный запрос
< wrap : doRegister >
< email > olga @ gmail . com </ email >
<name> Ольга </name>
< wrap : doRegister >
< email > name @ gmail . com </ email >
Нет обязательного поля name
<password> Парольчик </password>
< wrap : doRegister >
< mail > test @ gmail . com </ mail >
</ wrap : doRegister >
Опечатка в названии тега ( mail вместо email )
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
А в WSDl сервиса она записана еще проще:
<part name="email" type="xsd:string"/>
<part name="name" type="xsd:string"/>
<part name="password" type="xsd:string"/>
Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
Практика: составляем свой запрос
![]()
Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
![]()
1. Есть корневой элемент
Delphi site: daily Delphi-news, documentation, articles, review, interview, computer humor.
По мере того как данные, переносимые протоколом XML, становятся все более важными, растет значимость полного тестирования полезных данных XML. Следуя рекомендациям рис. 19-1, можно тестировать полезные данные XML, создавая разные тэги - слишком длинные, слишком короткие или состоящие из недействительных символов. Также поэкспериментируйте с объемом полезных данных XML: увеличьте его или сведите практически к нулю. Наконец, уделите внимание самим данным.
Изучив созданный XML-файл, вы обнаружите, что имя и название должности представляют собой очень длинные строки, а возраст - случайное число. Вы можете создать очень большие XML-файлы, содержащие тысячи объектов.
Тестирование SOAP-сервисов
Не забудьте применить различные методы мутации, описанные ранее в этой главе.
Тестирование на предмет атак с использованием кросс-сайтовых сценариев и внедрения кода сценариев
В главе 13 мы обсудили атаки с применением кросс-сайтовых сценариев (crosssite scripting, XSS) и опасности принятия данных, вводимых пользователем. А сейчас вы узнаете, как проверить уязвимость вашего Web-приложения для атак с применением сценариев. Методы, о которых сейчас пойдет речь, не охватывают все виды подобных атак, поэтому при создании тестовых сценариев рекомендую обратиться к главе 13 за сведениями о других видах атак. Сложность тестирования на предмет наличия XSS-брешей отличается для разных их типов: одни тестировать проще, другие - сложнее.
Совет Иногда приходится добавлять во входные данные один или несколько переводов каретки или строки [метасимволы (Cpm)] - некоторые Web-сайты анализируют только первую строку входной информации.
Следующий сценарий на Perl создает входные данные для формы и ищет возвращенный текст. Если выходные данные содержат введенный текст, страницу придется исследовать более пристально, так как весьма вероятно, что она уязвима для XSS. Сценарий выполняет еще одну операцию: проверяет, выполняет ли какая-либо XSS-обработка на сервере. Имейте в виду, что этот код не обнаружит все бреши. XSS-дыра может не проявиться в результирующей странице, а лишь на одной из следующих. Поэтому тестировать приложение придется особо тщательно.
print "Похоже, никакой XSS-обработки не выполняется в $url\n";
print "Похоже, какая-то XSS-обработка поддерживается в $url\n";
![]()
Поскольку XML имеет важное значение при разработке приложений, большинство современных фреймворков используют его для передачи данных (когда имеется большой файл XML, его нужно отредактировать и выполнить некоторые операции). Редакторы XML – это специализированные инструменты, использующие DTD и различные структуры, вроде схем и деревьев.
Рассмотрим наиболее популярные из них.
Oxygen
Oxygen – это кроссплатформенный редактор, написанный на Java. Он поддерживает несколько функций для редактирования документов:
- проверку правильности формы XML;
- валидацию по таким схемам, как DTD, W3C XML Schema, RELAX NG, Schematron, NRL и NVDL schemas.
Oxygen XML предлагает три подхода к редактированию документа XML:
- Текстовый: вариант по умолчанию.
- Вид сетки: документ XML форматируется в электронную таблицу, в которой левый столбец хранит элементы, комментарии и инструкции по обработке, а следующий столбец показывает атрибуты корневых элементов и каждого первого уникального дочернего элемента.
- Авторское представление: предлагает формат WYSIWYM (то, что ты видишь, есть то, что ты имеешь в виду). Такой формат понятен и удобен человеку, при этом он сохраняет вложенность и семантику.
Emacs для XML
![]()
Emacs известен как мощный текстовый редактор, предпочитаемый разработчиками UNIX. Он может работать с XML не только на UNIX-платформах, но и в Windows, MS-DOS и OS X.
В Emacs существуют следующие режимы редактирования XML:
- sgml-mode.el
- PSGML
- PSGMLx
- nXMLMode
- XML-poly
- xml-lite.el
- XML Authoring Environment (XAE)
- XSL-Mode
nXMLMode – основной режим редактирования XML в Emacs. Он поддерживает schema-sensitive.
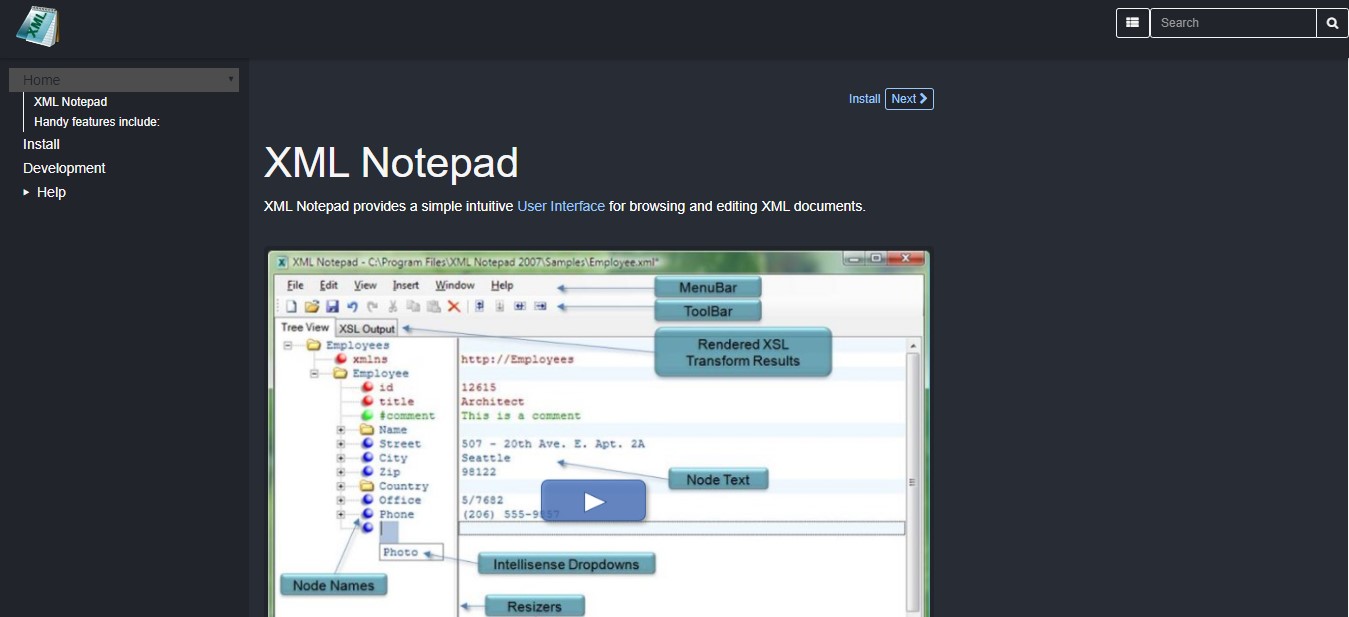
XML Notepad
XML Notepad – редактор для XML с открытым исходным кодом. Он поддерживает древовидное представление, вывод XSL в левой панели, текст ноды справа и окно отладки внизу.
![]()
Программа поставляется с редактируемым Tree View, которое содержит обновляемые имена и значения нод, обновляемые в текстовом представлении.
Поддерживается IntelliSense для автодополнения кода и поиска синтаксических ошибок. Также включены выражения XPath и XInclude. Редактор имеет хорошую производительность при работе с большими документами XML и проверяет XML-схемы на лету. В него включено средство просмотра HTML для изучения выходных данных преобразования XSLT.
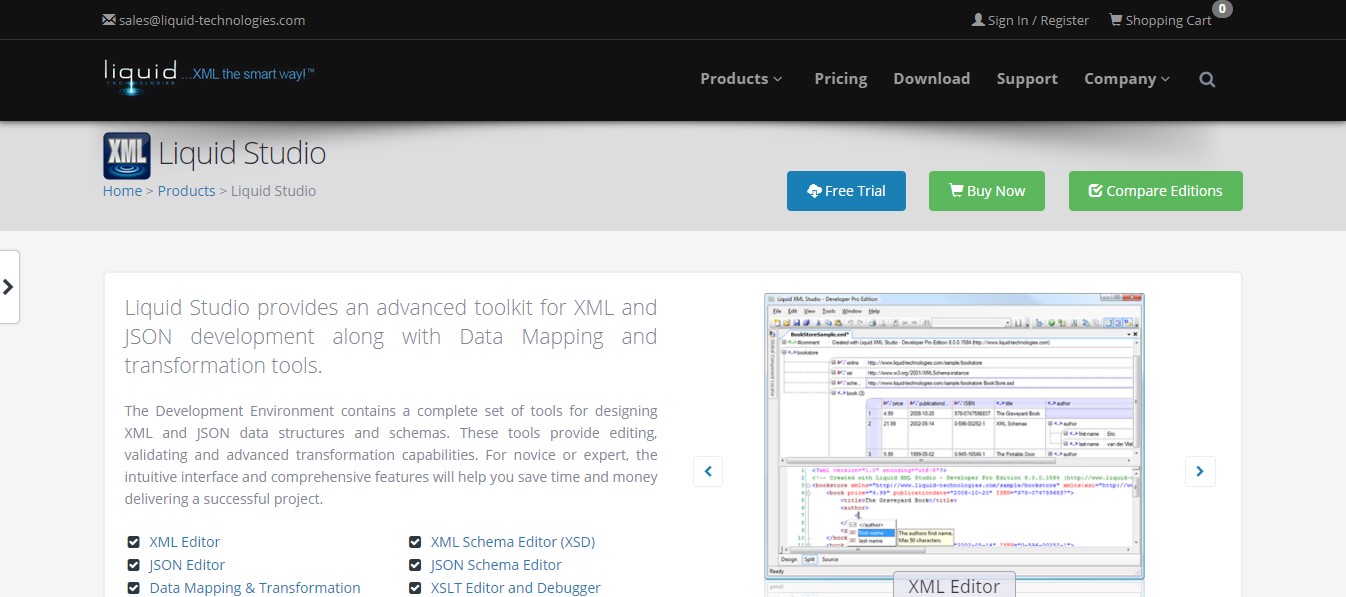
Liquid XML Studio IDE
![]()
Liquid XML Studio IDE – XML-редактор, основанный на Windows и биндинге данных. Включает в себя Graphical XML Schema Editor, Graphical JSON Schema Editor, Graphical XML editor и редактор DTD. Он также поставляется с расширением пользовательского интерфейса для Microsoft Visual Studio через Visual Studio Industry Partner (VSIP).
Stylus Studio
Stylus Studio – эта IDE написана на C++ и распространяется на условиях проприетарной лицензии стоимостью от 99 долларов. Программа позволяет редактировать и преобразовывать XML-документы для электронного обмена данными(EDI), CSV и реляционные данные. Поддерживаются XQuery Editing, XQuery Mapping, XQuery Debugging.
![]()
Студия поддерживает три представления XML: просмотр текста, дерево и сетка. Древовидное представление используется для минимизации кода и раскраски синтаксиса. Оно полезно при редактировании больших файлов, а сетка выигрышно смотрится при выполнении вычислений, когда необходимо просмотреть свой документ XML в виде электронной таблицы.
Komodo
Помимо поддержки XML, Komodo умеет работать с HTML, Perl, Ruby, Python, Java и т. д. Это простой, но функциональный инструмент. Автодополнение кода функционирует великолепно, макет лаконичен и интуитивно понятен. Софт имеет платную версию под названием Komodo IDE, включающую в себя модульное тестирование, синхронизацию нескольких рабочих станций и интеграцию с GitHub и BitBucket.
![]()
Komodo поддерживает закладки и метки, позаимствованные у Emacs.
Отслеживание изменений позволяет откатиться назад. Поле трекера позволяет управлять изменениями исходного кода (SCC), когда документ находится на стадии пересмотра. Если архив находится в SCC, то ядро трекера показывает изменения, сопоставленные с последним коммитом.
Редактор исходного кода Kate предлагает окно отладки, проводник и плагины. Среди них KTextEditor для редактирования тем, предоставляемых KSyntaxHighlighting. Он имеет возможность просмотра источников HTML, редактирования конфигурационных файлов и выполнения задач по расписанию.
Плагин проверки XML проверяет файл на наличие предупреждений и ошибок, которые появятся в окне Kate, а основанный на libxmlcalled плагин под названием «XML Completion» проверяет, следует ли документ правилам DTD.
![]()
NotePad ++
![]()
Notepad++ – это текстовый редактор с лицензией GPL. Он имеет хорошую производительность, потому как основан на компоненте редактирования Scintilla и написан на C++. Инструмент поддерживает подсветку синтаксиса, форматирование/минимизацию кода, а также незначительное автодополнение для разных языков программирования, сценариев и разметки.
К сожалению в редакторе нет интеллектуального автодополнения кода и проверки синтаксиса.
Notepad++ поставляется с основанным на libXML2 плагином XML Tools для поддержки набора полезных инструментов и редактирования XML-документов.
Для установки переходим в раздел Plugins -> Plugin Admin и находим «XML tools». Плагин обеспечивает проверку XML, XSD и DTD путем верификации формата и синтаксиса. Он поддерживает текущий XML Path и Xpath.
Это онлайн-едактор XML , предоставляющий различные сервисы:
- XML Sitemap Editor: позволяет редактировать кастомные XML sitemap-ы сайтов, которые можно загрузить по URL-адресу или загрузить файл локально.
- Online XML To Text Converter: преобразование XML в текстовые файлы.
- Online XML Validator: проверка и валидация схемы на соответствие DTD.
- XPath Editor: создание и оценка выражения XPath, а также проверка путей.
Плагин обеспечивает преобразование из XSD в XML, XML в Excel, JSON в XML, а также имеет редактор JSON и вьювер.
Adobe FrameMaker
Adobe FrameMaker – инструмент от Adobe для XML и DITA (Darwin Information Typing Architecture). Он содержит редактор WYSIWYG для XML-дизайна и обладает удобными сочетаниями клавиш для навигации.
![]()
Редактор имеет удобные для начинающих структурированные средства просмотра для нод и атрибутов XML-данных. Также он обеспечивает простое встраивание роликов из Youtube, CSS3, markdown и поддержку медиафайлов. Может быть использован в качестве PDF-редактора путем преобразования XML в DITA, который визуализируется в формат PDF.
XMLSpy
XMLSpy позиционируется как редактор JSON и XML со встроенным конструктором схем. Он поддерживает интеграцию с Visual Studio и Eclipse, а также имеет XPath builder, валидатор и отладчик.
![]()
Редактор может генерировать визуальные диаграммы из XML-данных.
Особенностью XMLSpy является валидация XML SmartFix, которая обнаруживает ошибки и автоматически применяет выбранные пользователем исправления.
ExtendsClass
ExtendsClass – это бесплатный набор инструментов для разработчиков, позволяющий сравнивать ноды XML и визуализировать семантические различия.
![]()
Инструмент XML diff выполняет семантическое сравнение пары «атрибут-значение» у каждого объекта. Сравнение затрагивает каждый узел в соответствии с его положением в массиве, а XML-строки сортируются и форматируются, чтобы найти семантические различия, а не только текстовые.
Editix
Editix – это качественный XML -редактор с открытым исходным кодом и множеством функций, вроде редактирования XSLT , отладчика, редактора XQuery , редактора сетки, редактора визуальных схем и множеством других. Основным интерфейсом этого редактора является глобальное вью. Мануал пользователя со скриншотами доступен по ссылке.
![]()
В последней версии предусмотрен бесплатный онлайн-инструмент – XPath tester. Разработчики также включили новую опцию – создание XML-документов из JSON и построение схемы из XML-документа с помощью редактора схем W3C.
Code Beautify
![]()
Code beautify отлично подходит для быстрого редактирования. Вы можете загрузить XML-файл по URL. Софт генерирует древовидное представление для XML, позволяет конвертировать XML в JSON, поддерживает проверку синтаксиса XML, минификацию и предоставляет онлайн-тестер XPath.
Online XML Tools
Online XML Tools – набор XML-инструментов, разработанных компанией B rowserling . Он поддерживает следующие функции: prettify, minify, validate , конвертацию XML в YAML, JSON TSV, Base64, CSV и наоборот.
![]()
Заключение
Существует множество доступных приложений для редактирования XML. При выборе лучшего из них для разработки стоит решить, хотите вы получить продукт, который не сильно ударит по бюджету команды, или тот, который дает крутые дополнительные возможности и требует минимальных затрат времени на использование.
Читайте также: