
Как указать путь к файлу node js
Обновлено: 07.07.2024
Для работы с файлами в Node.js используется встроенный модуль fs , который выполняет все синхронные и асинхронные операции ввода/вывода применительно к файлам. Чтение и запись файла могут осуществляться одним из двумя способов:
- с использованием Buffer ;
- через создание соответствующего потока.
Чтение файлов и директорий¶
Для чтения файла в асинхронном режиме используется метод Node.js readFile() , который принимает три параметра:
- путь к файлу;
- кодировка;
- callback-функция, вызываемая после получения содержимого файла.
Callback-функции передается два аргумента: ошибка и полученные данные в строковом формате. Если операция прошла успешна, то в качестве ошибки передается null .
Если в readFile() не указать кодировку, то данные файла будут возвращены в формате Buffer .
Поскольку метод выполняется асинхронно, то не происходит блокировки главного процесса Node.js. Но в некоторых случаях может понадобиться синхронное чтение файла, для этого есть метод readFileSync() , но при этом выполнение главного процесса будет заблокировано до тех пор, пока полностью не будет загружено содержимое файла.
Node.js readFileSync() возвращает результат чтения файла и принимает два параметра:
Обработка и перехват ошибок при использовании readFileSync() осуществляется с помощью конструкции try<. >catch() <. >.
Чтобы инициировать ошибку, укажите неправильный путь к файлу.
Методы readFile() и readFileSync() для работы с файлами используют Buffer . Но есть и другой способ считать содержимое файла: создать поток с помощью Node.js fs.createReadStream() . Любой поток в Node.js является экземпляром класса EventEmitter , который позволяет обрабатывать возникающие в потоке события.
Параметры, принимаемые fs.createReadStream() :
- путь к файлу;
- объект со следующими настройками:
- encoding - кодировка (по умолчанию utf8 );
- mode - режим доступа (по умолчанию 0o666 );
- autoClose - если true , то при событиях error и finish поток закроется автоматически (по умолчанию true ).
Вместо объекта настроек можно передать строку, которая будет задавать кодировку.
Использование потока имеет ряд преимуществ перед Buffer :
Для чтения директорий используются методы readdir() и readdirSync() , для асинхронного и синхронного режимов соответственно.
Node.js readdir() работает асинхронно и принимает три аргумента:
- путь к директории;
- кодировку;
- callback-функцию, которая принимает аргументами ошибку и массив файлов директории (при успешном выполнении операции ошибка передается как null ).
Node.js readdirSync() работает синхронно, возвращает массив найденных файлов и принимает два параметра:
Создание и запись файлов и директорий¶
В Node.js файлы могут быть записаны также синхронно и асинхронно. Для асинхронной записи имеется метод writeFile() , принимающий следующие аргументы:
- путь к файлу;
- данные для записи;
- параметры записи:
- кодировка (по умолчанию utf8 );
- права доступа (по умолчанию 0o666 );
- callback-функция, которая вызывается по завершению операции и единственным аргументом принимает ошибку (в случае успешной записи передается null ).
Если нет необходимости указывать параметры записи, то третьим параметром Node.js writeFile() можно сразу передать callback-функцию.
Для синхронной записи Node.js файла используйте writeFileSync() . Метод принимает все те же аргументы, что и writeFile() за исключением callback-функции. В качестве значения возвращает undefined .
Как и в случае с readFileSync() обработка ошибок происходит с помощью try<. >catch() <. >.
Методы writeFile() и writeFileSync() перезаписывают уже имеющуюся в файле информацию новыми данными. Если вам нужно внести новые данные без удаления старых, используйте методы appendFIle() и appendFileAsync() , которые имеют идентичные параметры.
Для записи файла через потока ввода имеется метод fs.createWriteStream() , который возвращает поток ввода и принимает два параметра:
- путь к файлу;
- объект со следующими настройками:
- encoding - кодировка (по умолчанию utf8 );
- mode - режим доступа (по умолчанию 0o666 );
- autoClose - если true , то при событиях error и finish поток закроется автоматически (по умолчанию true ).
Чтобы создать директорию, используйте методы mkdir() и mkdirSync() .
Node.js mkdir() работает асинхронно и принимает в качестве параметров:
- путь к директории;
- объект со следующими настройками:
- recursive - если true , создает директорию и все ее родительские директории согласно указанному пути, если они еще не существуют (по умолчанию false , т. е. все родительские директории уже должны быть созданы, иначе будет сгенерирована ошибка);
- mode - режим доступа, параметр не поддерживается на ОС Windows (по умолчанию 0o777 );
- callback-функцию, которая единственным аргументом принимает ошибку, при успешном создании директории передается null .
Вторым параметром можно сразу передать callback-функцию.
Node.js mkdirSync() создает директорию синхронно и возвращает undefined . Обработка ошибок осуществляется через try<. >catch() <. >. Метод mkdirSync() принимает те же параметры, что и mkdir() , за исключением callback-функции.
Удаление файлов и директорий¶
Чтобы удалить в Node.js файлы используйте методы unlink() и unlinkSync() .
Метод unlink() асинхронный и принимает имя файла, который нужно удалить, и callback-функцию с ошибкой в качестве параметра ( null , если удаление прошло успешно).
Для синхронного удаления файла используйте unlinkSync() , которому единственным аргументом передается имя файла.
Для удаления директорий имеются методы rmdir() и rmdirSync() соответственно. Они полностью идентичны unlink() и unlinkSync() , только вместо имени файла принимают имя директории.
Сегодня, в девятой части перевода руководства по Node.js, мы поговорим о работе с файлами. В частности, речь пойдёт о модулях fs и path — о файловых дескрипторах, о путях к файлам, о получении информации о файлах, об их чтении и записи, о работе с директориями.

Работа с файловыми дескрипторами в Node.js
Прежде чем вы сможете взаимодействовать с файлами, находящимися в файловой системе вашего сервера, вам необходимо получить дескриптор файла.
Дескриптор можно получить, воспользовавшись для открытия файла асинхронным методом open() из модуля fs :
Обратите внимание на второй параметр, r , использованный при вызове метода fs.open() . Это — флаг, который сообщает системе о том, что файл открывают для чтения. Вот ещё некоторые флаги, которые часто используются при работе с этим и некоторыми другими методами:
- r+ — открыть файл для чтения и для записи.
- w+ — открыть файл для чтения и для записи, установив указатель потока в начало файла. Если файл не существует — он создаётся.
- a — открыть файл для записи, установив указатель потока в конец файла. Если файл не существует — он создаётся.
- a+ — открыть файл для чтения и записи, установив указатель потока в конец файла. Если файл не существует — он создаётся.
После получения дескриптора любым из вышеописанных способов вы можете производить с ним необходимые операции.
Данные о файлах
С каждым файлом связан набор данных о нём, исследовать эти данные можно средствами Node.js. В частности, сделать это можно, используя метод stat() из модуля fs .
Вызывают этот метод, передавая ему путь к файлу, и, после того, как Node.js получит необходимые сведения о файле, он вызовет коллбэк, переданный методу stat() . Вот как это выглядит:
В Node.js имеется возможность синхронного получения сведений о файлах. При таком подходе главный поток блокируется до получения свойств файла:
Информация о файле попадёт в константу stats . Что это за информация? На самом деле, соответствующий объект предоставляет нам большое количество полезных свойств и методов:
- Методы .isFile() и .isDirectory() позволяют, соответственно, узнать, является ли исследуемый файл обычным файлом или директорией.
- Метод .isSymbolicLink() позволяет узнать, является ли файл символической ссылкой.
- Размер файла можно узнать, воспользовавшись свойством .size .
Пути к файлам в Node.js и модуль path
Путь к файлу — это адрес того места в файловой системе, где он расположен.
В Linux и macOS путь может выглядеть так:
В Windows пути выглядят немного иначе:
На различия в форматах записи путей при использовании разных операционных систем следует обращать внимание, учитывая операционную систему, используемую для развёртывания Node.js-сервера.
В Node.js есть стандартный модуль path , предназначенный для работы с путями к файлам. Перед использованием этого модуля в программе его надо подключить:
▍Получение информации о пути к файлу
Если у вас есть путь к файлу, то, используя возможности модуля path , вы можете, в удобном для восприятия и дальнейшей обработки виде, узнать подробности об этом пути. Выглядит это так:
Здесь, в строке notes , хранится путь к файлу. Для разбора пути использованы следующие методы модуля path :
- dirname() — возвращает родительскую директорию файла.
- basename() — возвращает имя файла.
- extname() — возвращает расширение файла.
▍Работа с путями к файлам
Несколько частей пути можно объединить, используя метод path.join() :
Найти абсолютный путь к файлу на основе относительного пути к нему можно с использованием метода path.resolve() :
В данном случае Node.js просто добавляет /flavio.txt к пути, ведущем к текущей рабочей директории. Если при вызове этого метода передать ещё один параметр, представляющий путь к папке, метод использует его в качестве базы для определения абсолютного пути:
Если путь, переданный в качестве первого параметра, начинается с косой черты — это означает, что он представляет собой абсолютный путь.
Вот ещё один полезный метод — path.normalize() . Он позволяет найти реальный путь к файлу, используя путь, в котором содержатся спецификаторы относительного пути вроде точки ( . ), двух точек ( .. ), или двух косых черт:
Методы resolve() и normalize() не проверяют существование директории. Они просто находят путь, основываясь на переданным им данным.
Чтение файлов в Node.js
Самый простой способ чтения файлов в Node.js заключается в использовании метода fs.readFile() с передачей ему пути к файлу и коллбэка, который будет вызван с передачей ему данных файла (или объекта ошибки):
Если надо, можно воспользоваться синхронной версией этого метода — fs.readFileSync() :
По умолчанию при чтении файлов используется кодировка utf8 , но кодировку можно задать и самостоятельно, передав методу соответствующий параметр.
Методы fs.readFile() и fs.readFileSync() считывают в память всё содержимое файла. Это означает, что работа с большими файлами с применением этих методов серьёзно отразится на потреблении памяти вашим приложением и окажет влияние на его производительность. Если с такими файлами нужно работать, лучше всего воспользоваться потоками.
Запись файлов в Node.js
В Node.js легче всего записывать файлы с использованием метода fs.writeFile() :
Есть и синхронная версия того же метода — fs.writeFileSync() :
Эти методы, по умолчанию, заменяют содержимое существующих файлов. Изменить их стандартное поведение можно, воспользовавшись соответствующим флагом:
Тут могут использоваться флаги, которые мы уже перечисляли в разделе, посвящённом дескрипторам. Подробности о флагах можно узнать здесь.
Присоединение данных к файлу
Метод fs.appendFile() (и его синхронную версию — fs.appendFileSync() ) удобно использовать для присоединения данных к концу файла:
Об использовании потоков
Выше мы описывали методы, которые, выполняя запись в файл, пишут в него весь объём переданных им данных, после чего, если используются их синхронные версии, возвращают управление программе, а если применяются асинхронные версии — вызывают коллбэки. Если вас такое состояние дел не устраивает — лучше будет воспользоваться потоками.
Работа с директориями в Node.js
Модуль fs предоставляет в распоряжение разработчика много удобных методов, которые можно использовать для работы с директориями.
▍Проверка существования папки
Для того чтобы проверить, существует ли директория и может ли Node.js получить к ней доступ, учитывая разрешения, можно использовать метод fs.access() .
▍Создание новой папки
Для того чтобы создавать новые папки, можно воспользоваться методами fs.mkdir() и fs.mkdirSync() :
▍Чтение содержимого папки
Для того чтобы прочесть содержимое папки, можно воспользоваться методами fs.readdir() и fs.readdirSync() . В этом примере осуществляется чтение содержимого папки — то есть — сведений о том, какие файлы и поддиректории в ней имеются, и возврат их относительных путей:
Вот так можно получить полный путь к файлу:
Результаты можно отфильтровать для того, чтобы получить только файлы и исключить из вывода директории:
▍Переименование папки
Для переименования папки можно воспользоваться методами fs.rename() и fs.renameSync() . Первый параметр — это текущий путь к папке, второй — новый:
Переименовать папку можно и с помощью синхронного метода fs.renameSync() :
▍Удаление папки
Для того чтобы удалить папку, можно воспользоваться методами fs.rmdir() или fs.rmdirSync() . Надо отметить, что удаление папки, в которой что-то есть, задача несколько более сложная, чем удаление пустой папки. Если вам нужно удалять такие папки, воспользуйтесь пакетом fs-extra, который весьма популярен и хорошо поддерживается. Он представляет собой замену модуля fs , расширяющую его возможности.
Метод remove() из пакета fs-extra умеет удалять папки, в которых уже что-то есть.
Установить этот модуль можно так:
Вот пример его использования:
Его методами можно пользоваться в виде промисов:
Допустимо и применение конструкции async/await:
Модуль fs
Выше мы уже сталкивались с некоторыми методами модуля fs , применяемыми при работе с файловой системой. На самом деле, он содержит ещё много полезного. Напомним, что он не нуждается в установке, для того, чтобы воспользоваться им в программе, его достаточно подключить:
После этого у вас будет доступ к его методам, среди которых отметим следующие, некоторые из которых вам уже знакомы:
- fs.rename()
- fs.renameSync()
- fs.write()
- fs.writeSync()
В Node.js 10 имеется экспериментальная поддержка этих API, основанных на промисах.
Исследуем метод fs.rename() . Вот асинхронная версия этого метода, использующая коллбэки:
При использовании его синхронной версии для обработки ошибок используется конструкция try/catch :
Основное различие между этими вариантами использования данного метода заключается в том, что во втором случае выполнение скрипта будет заблокировано до завершения файловой операции.
Модуль path
Модуль path, о некоторых возможностях которого мы тоже уже говорили, содержит множество полезных инструментов, позволяющих взаимодействовать с файловой системой. Как уже было сказано, устанавливать его не нужно, так как он является частью Node.js. Для того чтобы пользоваться им, его достаточно подключить:
Свойство path.sep этого модуля предоставляет символ, использующийся для разделения сегментов пути ( \ в Windows и / в Linux и macOS), а свойство path.delimiter даёт символ, используемый для отделения друг от друга нескольких путей ( ; в Windows и : в Linux и macOS).
Рассмотрим и проиллюстрируем примерами некоторые методы модуля path .
▍path.basename()
Возвращает последний фрагмент пути. Передав второй параметр этому методу можно убрать расширение файла.
▍path.dirname()
Возвращает ту часть пути, которая представляет имя директории:
▍path.extname()
Возвращает ту часть пути, которая представляет расширение файла:
▍path.isAbsolute()
Возвращает истинное значение если путь является абсолютным:
▍path.join()
Соединяет несколько частей пути:
▍path.normalize()
Пытается выяснить реальный путь на основе пути, который содержит символы, использующиеся при построении относительных путей вроде . , .. и // :
▍path.parse()
Преобразует путь в объект, свойства которого представляют отдельные части пути:
- root : корневая директория.
- dir : путь к файлу, начиная от корневой директории
- base : имя файла и расширение.
- name : имя файла.
- ext : расширение файла.
В результате его работы получается такой объект:
▍path.relative()
Принимает, в качестве аргументов, 2 пути. Возвращает относительный путь из первого пути ко второму, основываясь на текущей рабочей директории:
В этой главе мы рассмотрим, как при помощи Node.JS создать веб сервер, который будет возвращать файл юзеру из директории public. Может возникнуть вопрос, зачем здесь Node.JS? Почему бы не сделать это на другом сервере, например Nginx. Вопрос совершенно уместен, да для отдачи файлов, как правило, другие сервера будут более эффективны. С Другой стороны node, во первых, работает тоже весьма неплохо, а во вторых, может, перед отдачей файла, совершить какие то интеллектуальные действия. Например обратится к базе данных, проверить имеет ли юзер право на доступ к файлам, и только если имеет, тогда уже отдавать.

filePath . indexOf ( '\0' ) ) filePath = path . normalize ( path . join ( ROOT , filePath ) ) ;
Вот такой у нас получился код, с массой проверок, сейчас мы его подробно разберем.
sendFileSafe ( url . parse ( req . url ) . pathname , res ) ;он будет проверять, есть ли доступ к данному файлу
и если есть, отдавать
sendFileSafe ( url . parse ( req . url ) . pathname , res ) ;Для проверки доступа, мы будем использовать следующую, по сути заглушечную функцию,
return url . parse ( req . url , true ) . query . secret == 'o_O' ;
должно возвращать файл index.html и картинка здесь взята из директории deep\nodejs.jpg

А если бы я не указал seceret=o_O, то оно должно было выдать мне ошибку с кодом 403

Ну а если я попробовал указать вот так вот

тоже ошибка. И так для любых попыток выйти за пределы директории.
Итак смотрим функцию sendFileSafe(filePath, res), чтобы получить пример безопасной работы с путем от посетителя.
filePath . indexOf ( '\0' ) ) filePath = path . normalize ( path . join ( ROOT , filePath ) ) ;
Эта функция состоит из нескольких шагов. На первом шаге я пропускаю путь через decodeURIComponent(filePath),
Далее когда мы раскодировали запрос, время его проверить
filePath . indexOf ( '\0' ) )
есть такой специальный нулевой байт, который, по идеи, в строке url присутствовать не должен. Если он есть, это означает, что кто то его злонамеренно передал, потому что некоторые встроенные функции Node.JS будут работать с таким байтом некорректно. Соответственно, если такой байт есть, то мы тоже возвращаем- до свидание, запрос некорректен.
Теперь настало получить полный путь к файлу на диске. Для этого мы будем использовать модуль path.
filePath = path . normalize ( path . join ( ROOT , filePath ) ) ;Далее, если путь разрешен, то проверим, что по нему лежит. Если ничего нет, то fs.stat вернет ошибку ну или если даже ошибки нет, то нужно проверить файл ли это
3 thoughts on “24. Безопасный путь к файлу в fs и path”
Спасибо прочитал ваш учебник на одном дыхании
особенно понравилась тема :
21. Событийный цикл, библиотека libUV
в книжках описание данного вопроса как то не нашел
Рассмотрим объект module . Посмотрим на него в обычном REPL режиме :
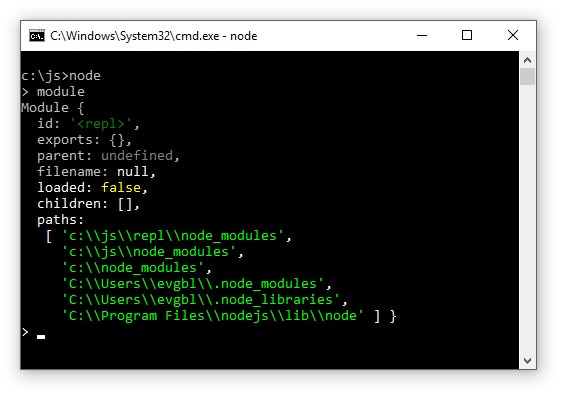
В свойстве id обычно используется полный путь к файлу. В режиме REPL это просто <repl> .
Каждому модулю соответствует определённый файл, содержимое которого загружается когда мы его подключаем функцией require .
Путь к файлу может быть указан как относительный, однако перед загрузкой файла в память, Node опеределяет его абсолютный путь.
Когда мы запрашиваем модуль без указания пути к нему :
Node будет искать файл find-me.js во всех путях указанных в module.paths , которые мы видели на скриншоте выше. Пути будут перебираться по порядку, начиная с папки node_modules которая находится в текущей директории.
Создадим папку node_modules в текущей директории и создадим в ней файл find-me.js такого создержания :
Тогда require('find-me'); найдёт этот модуль.
Если существует другой файл find-me.js по другому пути из module.paths , например в node_modules который в родительской директории, то он не будет загружен. Загрузится тот который будет найден раньше, а искать его Node будет именно в том порядке в котором указаны пути в module.paths .
Модуль в виде папки
find-me может быть папкой в node_modules . В таком случае require('find-me') будет искать файл index.js в этой папке.
Файл index.js будет использован по умолчанию когда мы подключаем папку. Однако мы можем поменять это поведение с помощью файла package.json который расположим в папке с модулем. В package.json в свойстве main можно указать другое имя файла который будет загружен вместо index.js . По сути новая точка входа.
Относительные и абсолютные пути
Несмотря на то что по умолчанию модули подключаются из node_modules , их можно подключать из любой папки используя относительные пути (./ и ../) или абсолютные которые начинаются с /.
Если к примеру файл find-me.js находится в папке lib , то мы можем подключить его так :
Отношения parent-child между файлами
Создадим файл lib/util.js :
Теперь запускаем файл index.js :
Обратите внимание как главный модуль index (id: '.') сейчас указан в качестве родителя parent для модуля lib/util .
Можно даже подключить модуль index из lib/util . Получится циклическая зависимость модулей. Это разрешено. Чтобы разобраться с этим получше, сначала разберёмся с другими концепциями объекта module .
exports, module.exports, и синхронная загрузка модулей
В любом модуле есть специальный объект exports . Вы могли заметить его в листингах выше. Можно добавить любые атрибуты к этому объекту. К примеру :
Теперь запустим index.js и увидим эти атрибуты :
Немного сократил выдачу чтобы лучше было видно. Объект exports теперь имеет те атрибуты которые мы задавали в каждом из модулей. Можете использовать сколько угодно атрибутов, и можно заменить весь объект на чтонибудь другое. К примеру можно заменить его на функцию :
Обратите внимание что мы не написали . Потомучто переменная exports в каждом модуле это всего лишь ссылка ( reference ) на module.exports . Если мы переопределим переменную exports , то мы потеряем эту ссылку и по сути просто создадим новую переменную, вместо того чтобы изменить module.exports , который на самом деле экспортирует свойства.
Объект module.exports который есть в каждом модуле, это то что возвращает функция require из этого модуля.
Поменяем файл index.js :
Свойства из lib/util экспортируются в констранту UTIL :
Рассмотрим атрибут loaded который есть в каждом модуле. В листингах выше можно заметить что loaded каждый раз имел значение false . Модуль module использует этот атрибут для отслеживая какой модуль был загружен ( значение true ), а какой еще загружается. Мы можем к примеру увидеть что модуль index.js был полностью загружен когда проверим объект module на следующем цикле event loop , используя вызов setImmediate :
В отложенном запуске console.log видим что lib/util.js и index.js полностью загрузились.
Объект exports становится завершённым когда Node завершает загрузку модуля и делает пометку loaded: true. Весь процесс подключения и загрузки модуля происходит синхронно. Это означает что нам нельзя изменять exports асинхронно. К примеру нельзя делать так :
Круговая, кольцевая, циклическая зависимость модулей.
Что случится если модуль 1 запросит модуль 2, а 2-й при этом запрашивает 1-й ? Чтобы ответить на этот вопрос создадим 2 файла в папке lib, module1.js и module2.js и чтобы каждый из них запрашивал другой.
Запускаем module1.js и видим следующее :
Мы подключаем module2 до того как module1 был полностью загружен. Т.е. module2 запрашивает module1 до того как тот полностью загрузился. В объекте exports мы получим те свойства которые были определены до начала круговой зависимости. Видим только свойство a , т.к. b и c были экспортированы после подключения module2 , который вывел на экран то что экспортирует module1 .
Node делает это очень просто. Во время загрузки модуля, он выстраивает объект exports . Вы можете подключать модуль и не ждать когда он закончит загрузку, просто получите частичный exports с тем что в нём определено на данный момент.
JSON и C/C++ аддоны
Можно нативно подключать файлы JSON и аддоны на C++ всё тойже функцией require . Вам даже не надо указываеть расширение файла.
Если расширение файла не указано, Node сначала будет искать .js файл. Если его нет, то попробует искать .json файл. Если и .json файл будет не найден, то попробует найти бинарный .node файл. Однако для избежания неоднозначности вам возможно лучше будет указать расширение файла, когда подключаете чтото кроме .js файла.
Подключение JSON файлов полезно в случае конфигурационных файлов. К примеру :
Подключается он так :
Как писать аддоны на C++ можно почитать тут.
Код каждого модуля оборачивается в функцию
Чтобы понять как это работает, вспомните чем отличается exports и module.exports . exports это всеголишь ссылка на module.exports .
Откуда же появляется объект exports , который виден глобально в пределах модуля ?
Вспомним как работают глобальные переменные в браузере. Когда мы объявляем :
В Node это происходит по другому. Когда мы объявляем переменную в одном модуле, в других модулях она не видна.
Перед компиляцией модуля, Node оборачивает весь код модуля в функцию, которую мы можем увидеть в свойстве wrapper объекта module .
Код модуля становится телом этой функции. Поэтому все переменные верхнего уровня в модуле имеют область видимости только в нём и не видны из других модулей.
У функции 5 аргументов : exports, require, module, __filename, и __dirname. Они только кажутся глобальными, но на самом деле у каждого модуля они свои. И получают свое значение когда Node запускает эту функцию враппер.
exports становится ссылкой на module.exports . require и module это экземпляры связанные с файлом модуля который мы запустили и они не являются глобальными. __filename содержит абсолютный путь к файлу, а __dirname соответственно к директории в которой он находится.
Также их можно увидеть через ключевое слово arguments .
Оборачивающая функция возвращает значение module.exports .
Это выглядит примерно так :
Объект require
Объект который обычно используется как функция. Аргумент имя модуля или путь, и возвращает module.exports .
Её можно переопределить к примеру так :
require.resolve
Объект require имеет свойство resolve . Это функция которая только резолвит модуль ( т.е. определяет абсолютный путь к нему ), но не запускает его на выполнение. Можно использовать чисто для проверки наличия модуля. Если модуля нет, то поймаешь исключение ( error, exception ).
require.main
Есть полезное свойство main , которое можно использовать для определения того запущен модуль напрямую или был подключен в другом модуле.
require.cache
Модули кэшируются в объекте require.cache . Почистить кэш можно просто удалив ключ из этого объекта, и при следующем запросе модуля, он будет перезагружен. Однако это не работает на нативных аддонах, и перезагрузка вызовет ошибку.
Допустим у нас есть модуль такой :
Если мы подключаем этот модуль несколько раз, то дата будет одной и тойже, т.к. экземпляр модуля берётся из кэша. По сути это как singleton.
Читайте также: