
Как установить вордстат на компьютер
Обновлено: 07.07.2024
Плагин Яндекс Вордстат Ассистент ( Yandex Wordstat Assistent) для браузера помогает автоматизировать сбор ключевых пользовательских запросов в Вордстат. Расширение бесплатное и легко устанавливается.
В начале обозначим общий список действий, которые можно осуществить:
- Возможность создавать списки ключей внутри плагина на основании таблиц Wordstat. Также можно как добавить ключи, так и удалить.
- Помимо предлагаемых сочетаний из выдачи Яндекс. Вордстат, расширение позволяет добавлять свои ключевые фразы.
- Плагин оснащен счетчиком числа слов словосочетаний и их частотность. Это означает, что можно увидеть в получившемся списке общее количество ключевых запросов и их суммарную частоту.
- Списки возможно сортировать по частотности, порядку их добавления и алфавиту.
- Список фраз, который получился в итоге, копируется одним кликом.
- Когда вы закрываете сервис, то все полученные результаты сохранятся в аккаунте, под которым вы работали.

Как скачать и установить Яндекс Вордстат Ассисент?

Для установки расширения Yandex Wordstat Assistant необходимо произвести три простых действия.
Алгоритм установки везде идентичный. Рассмотрим, установку и возможности использования Wordstat Assistant на примере браузера Google Chrome.
- Скачиваем нужную версию расширения Вордстат Ассистент для вашего браузера в магазине расширений для браузера. Например, Гугл Хром, Мозила или Яндекс Браузер.
- Нажимаем кнопку «Установить».
- Подтверждаем, свое намерение, нажав «Установить расширение».
Теперь все готово, осталось убедиться, что расширение установлено. Если процесс прошел успешно, то значок с уведомлением всегда будет отображен в браузере. Если значок, не появился, то следует перезапустить браузер.
Как правильно пользоваться?

Теперь более детально рассмотрим функции расширения:
- Добавление и удаление фраз из списка. Нажимая на плюс, мы добавляем в список нужное ключевое слово со страницы. Также можно добавить все фразы из таблицы, нажатием кнопки «Добавить все». К примеру, у нас есть запрос сохранить все нужные фразы из левой колонки со страницы один. Нажимаем кнопку добавить все со страницы один.
- Копировавние сформированного списка ключевых сочетаний, использую кнопку «Копировать».
- Добавление списка в редакторы таблиц ( к примеру, Эксель).
- Получение готового списка для продолжения обработки ключевых сочетаний с частотностью.
Как мы уже говорили, при закрытии браузера столбец ключевых запросов сохраняется, и помимо этого происходит синхронизация между открытыми вкладками. Проверка на дубли будет произведена автоматически. Также здесь есть три режима сортировки: порядок добавления, частотность, алфавит. Можно добавлять список ключевых запросов «вручную», что приносит большую пользу, если есть сохраненные списки, в которые нужно внести дополнение. Добавленные слова становятся бледно серыми в общем списке (такое выделение можно отключить).
Яндекс Вордстат – это сервис компании Яндекс, используемый для подбора ключевых слов путем анализа поисковых запросов пользователей.
Зачем нужен Вордстат
В основном он применяется для составления семантического ядра. Wordstat бесплатен, он является многофункциональным инструментом, но настолько простым, что разобраться сможет даже новичок. С помощью Вордстата возможно узнать подробную статистику запросов в системе Яндекс за последний месяц, и составить не только структуру целого сайта, но и отдельных его страниц. В практике сервис применяется для решения следующих проблем:
- Сбор наиболее полной семантики за счет расширений запросов;
- Проверка частотности запросов, в том числе и региональной;
- Проверка сезонности запросов.
Это самое основное, но есть конечно и более мелкие задачи, которые помогает решить Wordstat.
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис, вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:


Напрямую с вордстатом работают очень редко, однако я слышал офигенные истории, что в студии Ашманова, одной из самых крутых SEO-студий, сидят мартышки, которые каждый запрос вводят в Вордстат руками и копируют выдачу в .txt-файл. Я сразу представил сотню рабов, которые за день работы выполняют такой же объем, как один сеошник с Кей Коллектором.
Давайте теперь смотреть остальные функции интерфейса:

По регионам
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:


История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:

Но самое профессиональное начинается, когда вы работаете с операторами.
Какие операторы полезны при работе с Wordstat
Надо знать, как пользоваться операторами Яндекс Вордстата, чтобы наиболее эффективно работать в интерфейсе.
Базовые операторы




Вспомогательные операторы



Он кстати позволяет провести сравнение двух запросов, для этого я его в основном и использую.



Как видим, с неправильным порядком фразу почти никто не вводит:

Плагины
Yandex Wordstat Assistant
Yandex Wordstat Helper
Этот плагин попроще, чем предыдущий, но не менее популярен, его также можно устанавливать прямо с браузера. Хелпер сделан в виде виджета, который добавляется на страницу вордстата сразу после установки, нужно просто обновить страницу и можно начинать работу. Его функции:
- Возможность автоматической сортировки в алфавитном порядке;
- Проверяет наличие дублей, удаляя последние;
- Есть возможность обработки разных запросов в нескольких вкладках браузера. Нужные слова добавляются в один и тот же список;
- Есть счетчик слов;
- Возможность копирования уже готового списка в Excel, собрав всё воедино по начальным фразам.
Прежде чем решить, какой плагин использовать, попробуйте в действии и тот и другой, это позволит вам сделать правильный выбор.
Парсеры Вордстата
Для экономии времени при подборе ключевых слов часто пользуются специально предназначенными для этого автоматическими программами – парсерами, которые могут быть как платными, так и бесплатными.
Некоторые пацаны заказывают парсеры и чисто под свои нужды.
Лучший платный парсер Wordstat – KeyCollector. Используют его в основном те, кто профессионально занимается составлением семантики. Бесплатным аналогом КейКоллектора является программа Словоеб. Функции его урезаны, но составлять небольшие ядра с его помощью вполне реально.
Магадан тоже достаточно популярный парсер Вордстат, который тоже можно бесплатно скачать. Подбирает и анализирует запросы, есть поддержка регионов, предназначен для парсинга фраз Яндекс Директа.
Под конец хочу отметить, что Вордстат дает только те данные, которыми располагает Яндекс. Поэтому например частотность в Гугле и других поисковиках может быть совсем другая.

1) Чтобы добавить конкретные фразы в семантическое ядро, жмем на плюсики слева от них. Эти фразы появляются в окне Вордстатера, во вкладке «Общий список»:
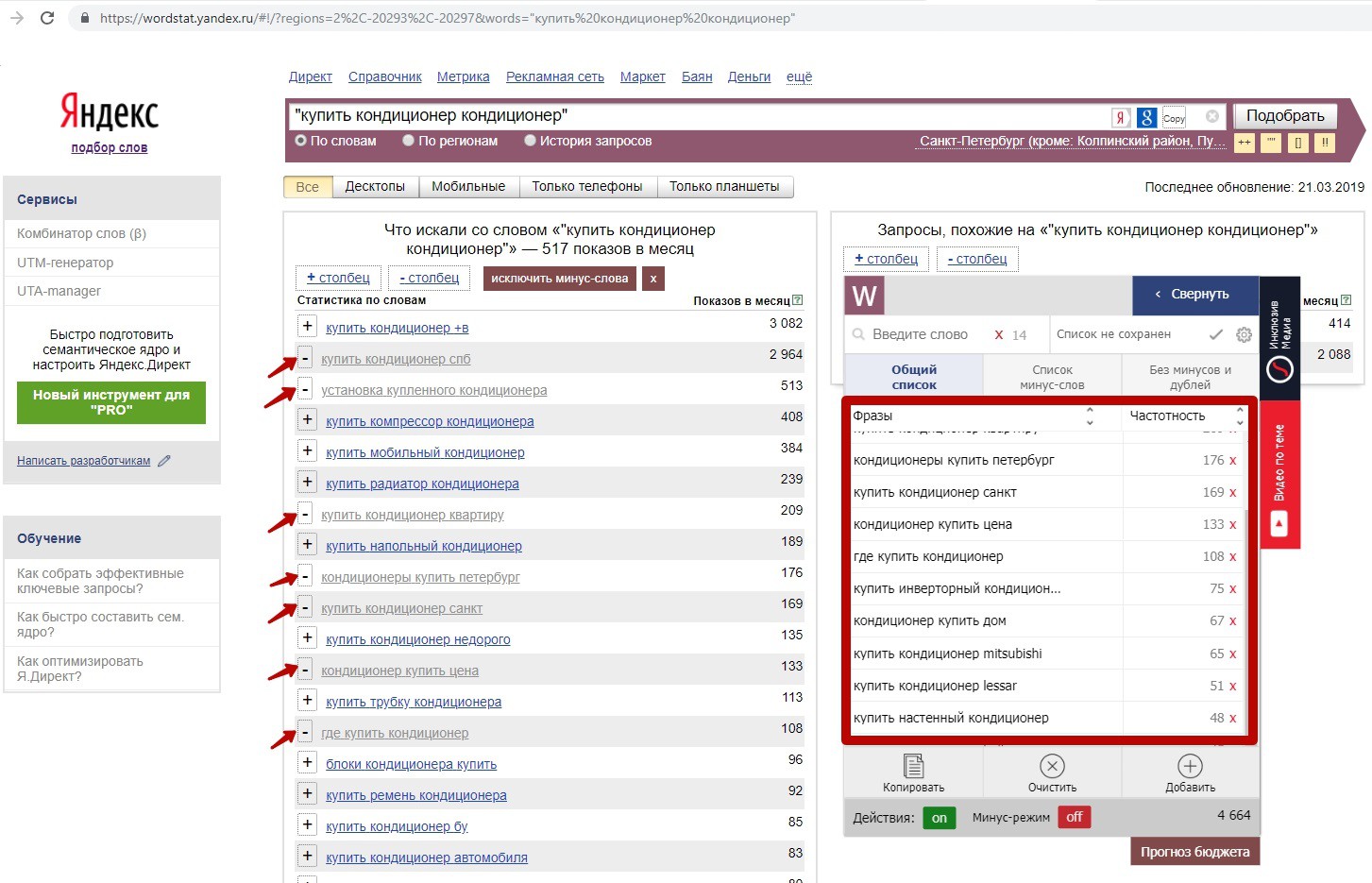
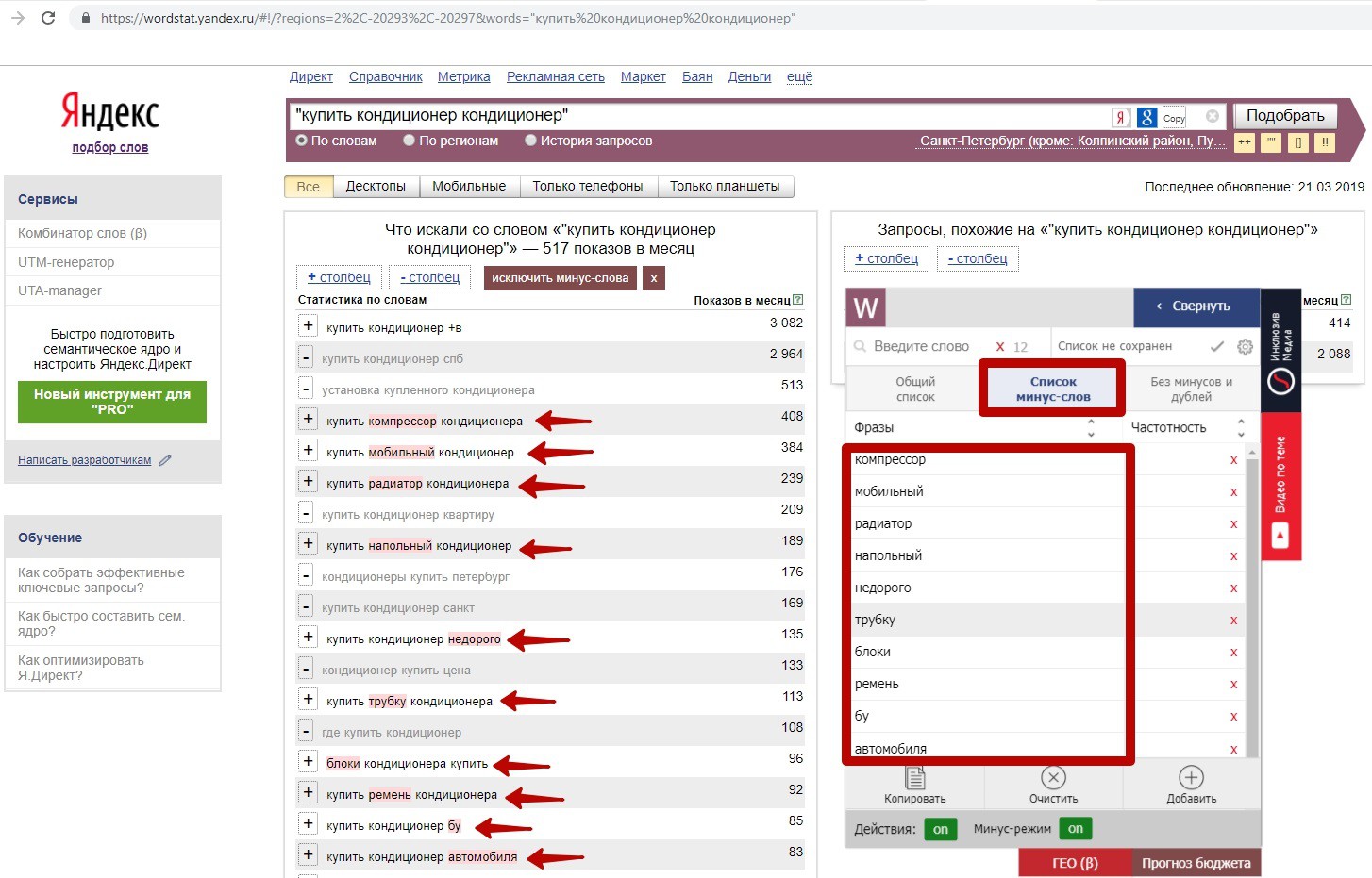
2) Чтобы добавить конкретные слова в минус-список, кликайте мышкой прямо на них.
Как в нашем примере – помечаем конкретные слова – компрессор, мобильный, напольный, радиатор, трубка, блоки, ремень, б/у, недорого, автомобиля и так далее.
После отметки они подсвечиваются розовым цветом в выдаче:
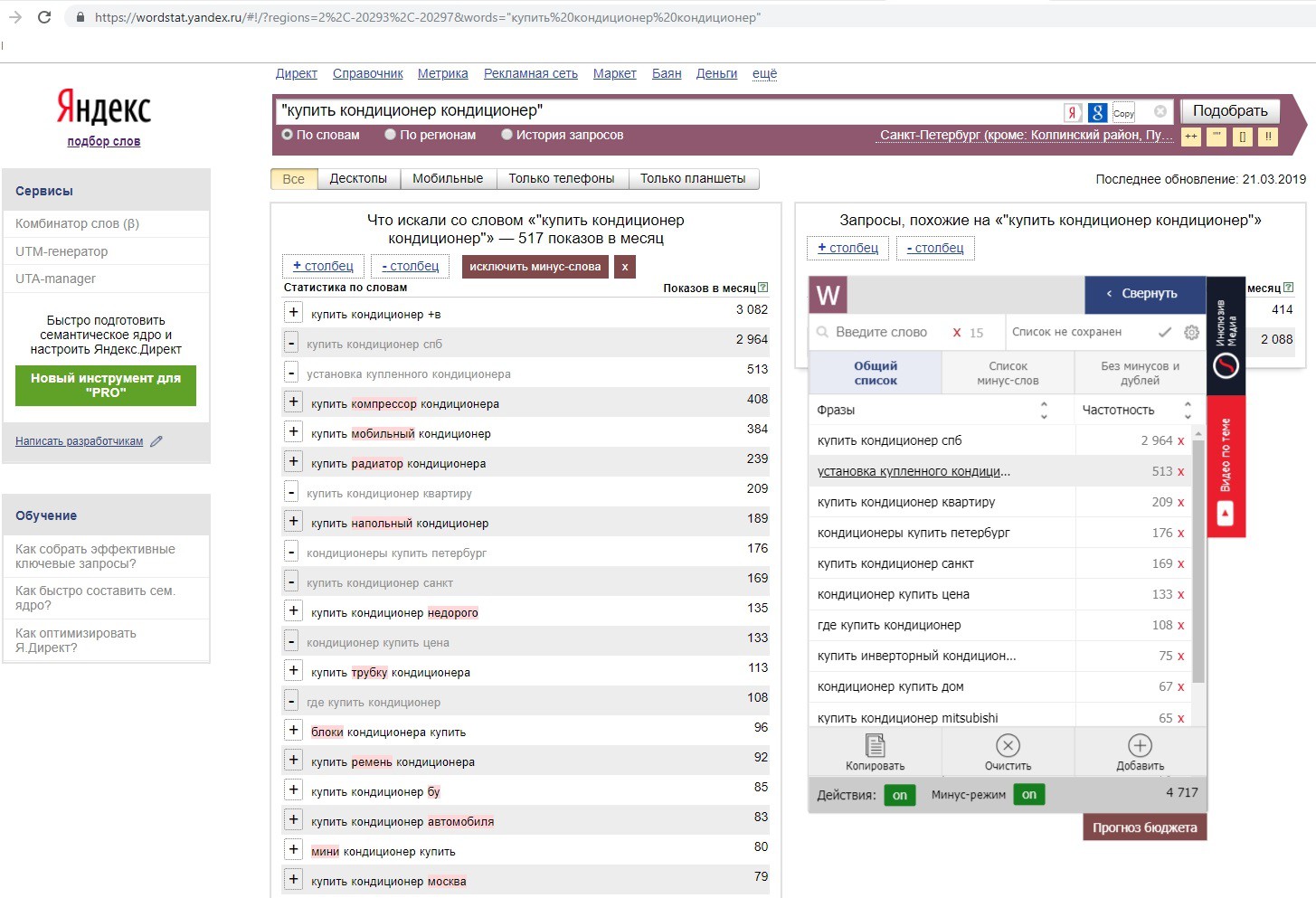
А также появляются в рабочем окне Вордстатера, во вкладке «Список минус-слов»:
3) Чтобы тут же в списке зафиксировать фразовое соответствие по какому-либо ключу, без всевозможных добавок, нажмите на значок кавычек справа от него:
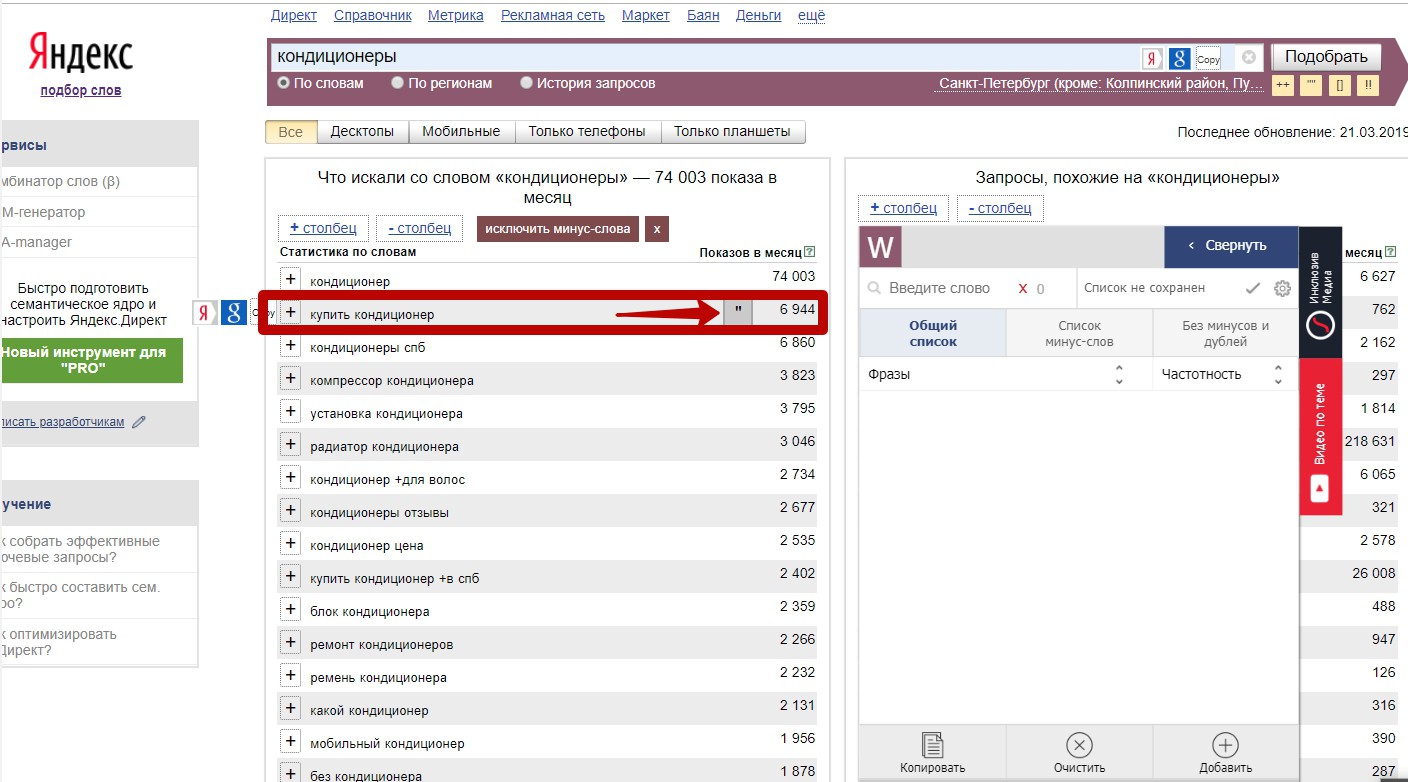
4) Чтобы посмотреть вложенные запросы после того, как взяли фразу в кавычки, жмем на значок «вложенность». Вот он, справа, в виде двух плюсиков:
В результате мы получаем список трехсловных фраз, содержащих слова «купить кондиционер»:
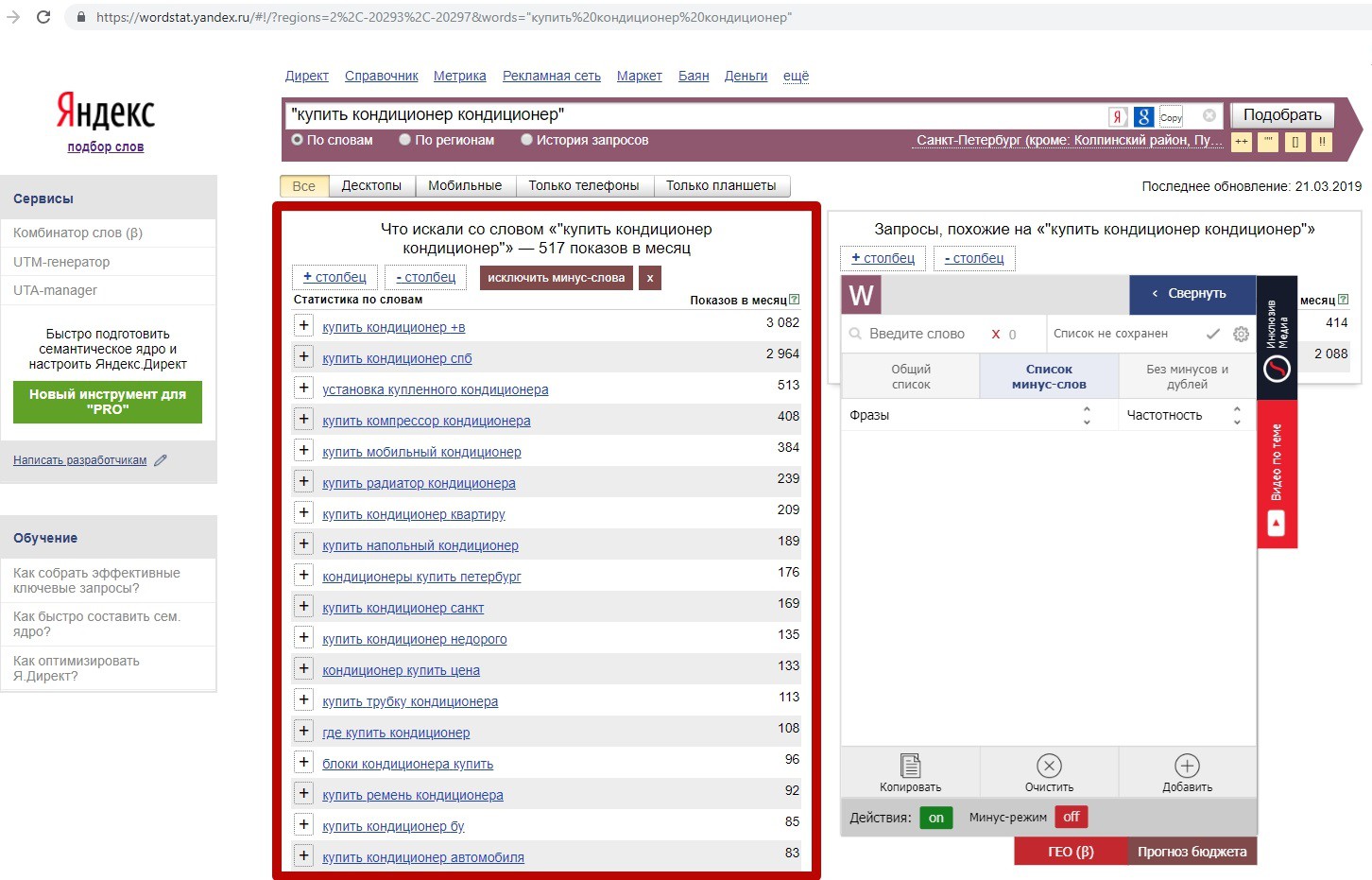
Любой из ключевиков в этом списке можно так же зафиксировать по фразовому соответствию и снова нажать на значок вложенности. Так вы увидите входящие в него 4-х словники. И так далее можно «копать» вглубь.
Что удобно, каждый вложенный список по какому-либо ключу Вордстатер открывает в новом окне браузера:

Многие люди не знают, как работать с трендами в интернете, где их искать. Перед тем, как начинать бизнес не знают, где посмотреть будет ли этот бизнес вообще популярен и нужен ли он. Поэтому напишу полный туториал, чтобы закрыть все вопросы по этой тематике.
Работать мы будем со специальным сервисом по сбору поисковых запросов пользователей Яндекса Вордстатом, интерфейс которого довольно прост и понятен:
В начале, по традиции, поставлю цели:
- Понять весь функционал и научиться работать с Вордстатом;
- Как правильно собирать семантику с максимальной релевантностью и CTR >50%;
- Так как мы на Хабре, поработаем с API Wordstat напрямую.
Ключевая роль сервиса заключается в том, что он помогает оценить пользовательский интерес к трендам, различным тематикам и подобрать ключевые слова для контекстной рекламы.
Знакомство с сервисом
Для того, чтобы начать пользоваться Вордстатом нам необходимо авторизоваться в аккаунте Яндекса:

После авторизации мы можем пользоваться сервисом. Просмотр данных поисковых запросов нам доступен во вкладке «По словам»:

В левой колонке мы видим статистику по словам, которые были вместе с вашим поисковым запросом и показы в месяц по ним. Для того, чтобы мы нашли наше слово в точном соответствии мы должны использовать операторы. В правой колонке показываются похожие по смыслу запросы на заданную нами фразу.
Наглядный пример использования ключевых слов с операторами:


Оператор "!" — фиксирует форму слова (число, падеж, время);

Оператор "[]" — Фиксирует порядок слов. При этом учитываются все словоформы и стоп-слова.

Подробнее об операторах читаем здесь.
По умолчанию Вордстат показывает запросы по всем типам устройств. Настройки можно изменять: десктоп/мобайл/только телефоны/только планшеты. В нашем случае отфильтруем только десктопы.

По умолчанию статистика показывается для всех регионов. Выбрать отображение статистики по интересующему нас региону можно во вкладке «Все регионы»:

Во вкладке «По регионам» отображаются данные со всех регионов, а также региональная популярность — доля, которую занимает регион в показах по слову, деленная на долю всех показов результатов поиска, пришедшихся на этот регион.

Для удобства эти же данные отображаются на карте:

Во вкладке «История запросов» мы видим данные по запросу, обычно за 1,5 года. Здесь наглядно можем оценить тренды и влияние их на определенные запросы.
Статистику можно смотреть как в абсолютных значениях, так и в относительных. Для получения относительного значения абсолютная цифра нормируется на количество показов результатов поиска Яндекса за соответствующий месяц.

На этом изучение инструменты можно закончить и приступить к следующей нашей цели — правильный сбор семантического ядра.
Правильный сбор семантического ядра
В интернете уйма сервисов и способов для сбора семантического ядра, а также искусственного его создания. Мы не будем создавать велосипед и танцевать с бубном, а соберем семантику легко, просто и бесплатно.
Для того, чтобы нам собрать нашу семантику, первым делом мы скачиваем с официального сайта Яндекса Директ Коммандер последней версии.
После загрузки запускаем программу, логинимся и создаем (без разницы с каким названием) кампанию:

Добавляем группу объявлений (по прежнему нет смысле заморачиваться с его названием):

Переходим во вкладку «Подбор фраз», и вуаля! Это тот же самый Вордстат, только в программе Директ Коммандер. Логика работы с ним такая же, только в отличии от веб версии Вордстата здесь мы можем сразу указать минус слова:

После того как мы тщательно отфильтруем весь список поисковых запросов от лишних запросов, можно приступать к экспорту нашей кампании в csv файл. Все, что остается нам сделать, это удалить лишние столбцы. Наше семантическое ядро находится в столбце «Фраза (с минус-словами)»:

Плюсы сбора семантики таким способом:
- Охват запросов с частотностью до 1 в месяц;
- Не наращиваем искусственную семантику, в которой наверняка будут запросы, которых в реальной истории поиска на самом деле нет;
- Увеличиваем CTR объявлений максимально (конечно не только благодаря семантике, но и правильному разбиению объявлений по кластерам запросов и их текстам. Однако все это на основе нашей семантики);
- Клики становятся для нас дешевле;
- Это абсолютно бесплатно.
Работа с API Wordstat
Прежде чем начать, ознакомимся с базовой информацией из справки Яндекс Директа.
Описание параметров
Обязательные GET параметры
request — Данные запроса
GET параметры
lr — код региона, если 0 — то все регионы
imp — если 1 — то важный запрос
Ответ содержит
status — Код статуса (0 — нет ошибок)
err_msg — Текст ошибок
data — Количество показов в месяц
На этом все цели, которые мы поставили перед собой, в конце статьи были достигнуты.

Собирать и группировать поисковые запросы, по которым будет происходить продвижение сайта (создание семантического ядра для Интернет-ресурса), необходимо для того, чтобы повысить успешность раскрутки, улучшить структуру представленного материала и сам контент. В процессе данной работы применяются специальные сервисы для отслеживания статистики поисковых систем, и одной из самых популярных является Yandex Wordstat Assistant.
Что такое яндекс вордстат Ассистент?
Яндекс Вордстат Ассистент – это универсальный плагин, который поможет веб-мастерам и SEO-специалистам значительно упростить сбор ключевых фраз и слов с соответствующего сервиса. Данное расширение может быть использовано с браузерами Opera, Chrome и Яндекс для отсортировки подходящих пользователю запросов для последующего их “ручного” разбора. Плагин находится в открытом доступе и распространяется совершенно бесплатно.
Где скачать?
Как установить?
Для установки специального расширения для создания семантического ядра в Яндекс Вордстат потребуется переключиться к дополнениям браузера и использовать строку поиска. Это можно сделать следующим образом:
- Открыть дополнения, воспользовавшись сочетанием кнопок “Ctrl+Shift+A” или последовательно открыв “Инструменты”->“Дополнения”.
- В поисковой строке следует указать “Wordstat Assistant” (без кавычек), после чего запустить процедуру поиска. Требуемое расширение окажется на первом месте в списке найденных дополнений. Установите его.
- Когда завершится установка Yandex Wordstat Assistant, можно сразу же приступать к сбору семантического ядра, даже браузер не придется перезагружать.
Как пользоваться?
После установки и активации расширения Wordstat Assistant, предназначенного для создания семантических ядер, справой стороны в списке всех плагинов появится соответствующая иконка. Нажмите на нее для запуска самого расширения.
После этого, кроме обычного интерфейса, откроется окно Яндекс Вордстат Ассистент. Через него и происходит все взаимодействие с данным расширением. Всего здесь предусмотрено только 5 кнопок, каждая из которой отвечает за конкретное действие:
- добавить фразы – предоставляет возможность добавлять найденные фразы из Вордстат в плагин Wordstat Assistant;
- копировать список в буфер обмена – можно копировать весь список поисковых фраз, однако частотность в этом случае не переносится в буфер обмена;
- копировать список с частотностью в буфер обмена – позволяет скопировать полный перечень подобранных фраз с показателями частотности для каждой;
- сортировка – позволит произвести отсортировку поисковых фраз по частотности, алфавиту и т.д.;
- очистить список – происходит полное очищение поля.
Кроме того, упрощение функционала коснулось и работы с поисковыми фразами. Если необходимо добавить какую-либо из них в плагин, достаточно нажать на плюс рядом с ней. Когда же понадобится удалить фразу, сделать это можно с помощью расположенного возле нее минуса.
После того, как завершите сбор всех необходимых для создания семантического ядра фраз, нужно скопировать полученную информацию (с указанием частотности или без нее) и переместить в таблицу Excel. В результате получится таблица, состоящая из двух столбцов – само поисковое слово и частотность его употребления.
Читайте также: