
Как узнать кодировку файла
Обновлено: 06.07.2024
в нашем приложении, мы получаем текстовые файлы ( .txt , .csv , etc.) из различных источников. При чтении эти файлы иногда содержат мусор, потому что файлы, созданные в другой / неизвестной кодовой странице.
есть ли способ (автоматически) определить кодировку текстового файла?
на detectEncodingFromByteOrderMarks на StreamReader конструктор, работает на UTF8 и другие отмеченные unicode файлы, но я ищу способ обнаружения кодовых страниц, таких как ibm850 , windows1252 .
Спасибо за ваши ответы, это то, что я сделал.
файлы, которые мы получаем от конечных пользователей, они не имеют понятия о кодовых страниц. Получатели также являются конечными пользователями, теперь это то, что они знают о кодовых страницах: кодовые страницы существуют и раздражают.
устранение:
- откройте полученный файл в блокноте, посмотрите на искаженный фрагмент текста. Если кого-то зовут Франсуа или что-то вроде того, с вашим человеком интеллект вы можете догадаться об этом.
- я создал небольшое приложение, которое пользователь может использовать для открытия файла, и введите текст, который пользователь знает, что он появится в файле, когда используется правильная кодовая страница.
- цикл через все кодовые страницы и отображать те, которые дают решение с предоставленным пользователем текстом.
- если появляется несколько кодовых страниц, попросите пользователя указать больше текста.
вы не можете обнаружить кодовую страницу, вам нужно сказать это. Вы можете анализировать байты и угадывать их, но это может дать некоторые странные (иногда забавные) результаты. Я не могу найти его сейчас, но я уверен, что блокнот можно обмануть, показывая английский текст на китайском языке.
В Частности Джоэл говорит:
Если вы хотите обнаружить кодировки без UTF (т. е. без BOM), вы в основном занимаетесь эвристикой и статистическим анализом текста. Возможно, вы захотите взглянуть на Mozilla paper об универсальном обнаружении кодировок (та же ссылка, с лучшим форматированием через Wayback Machine).
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или --mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
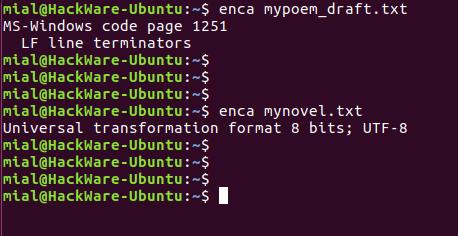
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
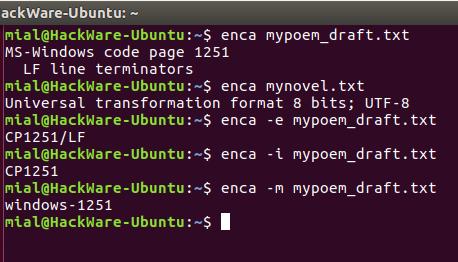
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.

то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или --from-code означает кодировку исходного файла -t или --to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
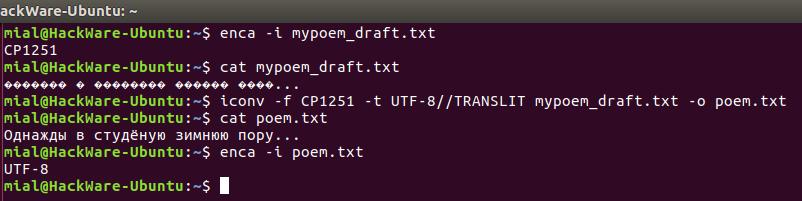
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
В моей файловой системе (Windows 7) у меня есть несколько текстовых файлов (это файлы сценариев SQL, если это имеет значение).
При открытии с помощью Notepad ++ в меню «Кодировка» сообщается, что некоторые из них имеют кодировку «UCS-2 Little Endian», а некоторые - «UTF-8 без BOM».
В чем здесь разница? Все они кажутся совершенно правильными сценариями. Как я могу сказать, какие кодировки у файла без Notepad ++?
Существует довольно простой способ использования Firefox. Откройте файл, используя Firefox, затем выберите «Просмотр»> «Кодировка символов». Подробно здесь . использовать эвристику. Оформить заказ enca и chardet для систем POSIX. Я думаю, что альтернативный ответ - TRIAL и ERROR. iconv в частности это полезно для этой цели. По сути, вы перебираете поврежденные строки символов / текста в различных кодировках, чтобы увидеть, какой из них работает. Вы выигрываете, когда персонажи больше не портятся. Я хотел бы ответить здесь, с программным примером. Но это, к сожалению, защищенный вопрос. FF использует детекторы Mozilla Charset . Еще один простой способ - открыть файл с помощью MS word, он будет правильно угадывать файлы даже для различных древних китайских и японских Если chardet или chardetect не доступно в вашей системе, вы можете установить пакет через менеджер пакетов (например, apt search chardet - на ubuntu / debian, обычно называемый пакетом python-chardet или python3-chardet ), или через pip с pip install chardet (или pip install cchardet для более быстрой версии c-optimized).Файлы обычно указывают свою кодировку с заголовком файла. Есть много примеров здесь . Однако даже читая заголовок, вы никогда не можете быть уверены, какую кодировку файл действительно использует .
Например, файл с первыми тремя байтами 0xEF,0xBB,0xBF , вероятно , является файлом в кодировке UTF-8. Однако это может быть файл ISO-8859-1, который начинается с символов  . Или это может быть совершенно другой тип файла.
Notepad ++ делает все возможное, чтобы угадать, какую кодировку использует файл, и в большинстве случаев он делает это правильно. Хотя иногда это не так - поэтому меню «Кодировка» есть, поэтому вы можете отменить его лучшее предположение.
Для двух кодировок вы упоминаете:
- Файлы "Little Endian UCS-2" - это файлы UTF-16 (основанные на том, что я понимаю из информации здесь ), поэтому, вероятно, начнем с 0xFF,0xFE первых 2 байтов. Из того, что я могу сказать, Notepad ++ описывает их как «UCS-2», поскольку он не поддерживает определенные аспекты UTF-16.
- Файлы «UTF-8 без BOM» не имеют байтов заголовков. Вот что означает бит «без спецификации».
Тебе нельзя. Если бы вы могли это сделать, не было бы так много веб-сайтов или текстовых файлов со «случайным бредом». Вот почему кодирование обычно отправляется вместе с полезной нагрузкой в виде метаданных.
В противном случае все, что вы можете сделать, - это «умное предположение», но результат часто неоднозначен, поскольку одна и та же последовательность байтов может быть допустимой в нескольких кодировках.
Есть программа которая обрабатывает текстовый файл. Нужно перед открытием и работой с файлом чтобы программа проверила кодировку текста. Подскажите как это реализовать, я только начинаю осваивать Java, буду признателен за пример кода.
80.2k 7 7 золотых знаков 66 66 серебряных знаков 146 146 бронзовых знаков
Вообще это непростая задача и я думаю не всегда возможно это сделать. Обычно кодировку определяют заранее. Но действительно (как и сказал @metalurgus) довольно много информации в сети. Хотя, нужно понимать, что для решения такой задачи понадобится использовать какую-нибудь стороннюю библиотеку думаю вот это рассуждение подходит: определение кодировки
1,935 10 10 серебряных знаков 11 11 бронзовых знаков это все очень геморно выглядит, может я не стой стороны зашол. ситуация такая, программа открывает и обрабатывает текстовый файл, но файл может попасть в любой кодировку, нужно или проверять кодировку чтобы не было крякозябр или как то запретить обработку если файл не подходит под конкретную кодировку. @TСPakko и это просто так не запретишь (на файле не написано в какой кодировке там символы), только если читать и выкидывать ошибку разбора фала, если у него есть какой-то определённый формат (xml, css и т.д.).Коллеги уже писали, что единого рецепта как бы нет, но я таки попытаюсь описать примерный паттерн решения этой задачи:
1) Получаем список поддерживаемых данной платформой кодировок Charset.availableCharset()
2) Берем первую по списку charset и читаем строчку из файла:
3) Берем Yandex Словарь и оформляем JSon запрос lookup, запоминаем статистику переводов
4) После прогона всех доступных кодировок выбираем ту, которая получила наилучшую статистику - это и будет наша искомая кодировка.
Есть программа которая обрабатывает текстовый файл. Нужно перед открытием и работой с файлом чтобы программа проверила кодировку текста. Подскажите как это реализовать, я только начинаю осваивать Java, буду признателен за пример кода.
80.2k 7 7 золотых знаков 66 66 серебряных знаков 146 146 бронзовых знаков
Вообще это непростая задача и я думаю не всегда возможно это сделать. Обычно кодировку определяют заранее. Но действительно (как и сказал @metalurgus) довольно много информации в сети. Хотя, нужно понимать, что для решения такой задачи понадобится использовать какую-нибудь стороннюю библиотеку думаю вот это рассуждение подходит: определение кодировки
1,935 10 10 серебряных знаков 11 11 бронзовых знаков это все очень геморно выглядит, может я не стой стороны зашол. ситуация такая, программа открывает и обрабатывает текстовый файл, но файл может попасть в любой кодировку, нужно или проверять кодировку чтобы не было крякозябр или как то запретить обработку если файл не подходит под конкретную кодировку. @TСPakko и это просто так не запретишь (на файле не написано в какой кодировке там символы), только если читать и выкидывать ошибку разбора фала, если у него есть какой-то определённый формат (xml, css и т.д.).Коллеги уже писали, что единого рецепта как бы нет, но я таки попытаюсь описать примерный паттерн решения этой задачи:
1) Получаем список поддерживаемых данной платформой кодировок Charset.availableCharset()
2) Берем первую по списку charset и читаем строчку из файла:
3) Берем Yandex Словарь и оформляем JSon запрос lookup, запоминаем статистику переводов
4) После прогона всех доступных кодировок выбираем ту, которая получила наилучшую статистику - это и будет наша искомая кодировка.
Читайте также: