
Какой объем памяти займет слово информатика при кодировании с помощью стандарта ascii
Обновлено: 04.07.2024
Сайт учителя информатики. Технологические карты уроков, Подготовка к ОГЭ и ЕГЭ, полезный материал и многое другое.
Информатика. 10 класса. Босова Л.Л. Оглавление
§14. Кодирование текстовой информации
Компьютеры третьего поколения «научились» работать с текстовой информацией.
Текстовая информация по своей природе дискретна, т. к. представляется последовательностью отдельных символов.
Для компьютерного представления текстовой информации достаточно:
1) определить множество всех символов (алфавит), требуемых для представления текстовой информации;
2) выстроить все символы используемого алфавита в некоторой последовательности (присвоить каждому символу алфавита свой номер);
3) получить для каждого символа n-разрядный двоичный код (n ≤ 2 n ), переведя номер этого символа в двоичную систему счисления.
В памяти компьютера хранятся специальные кодовые таблицы, в которых для каждого символа указан его двоичный код. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
14.1. Кодировка ASCII и её расширения
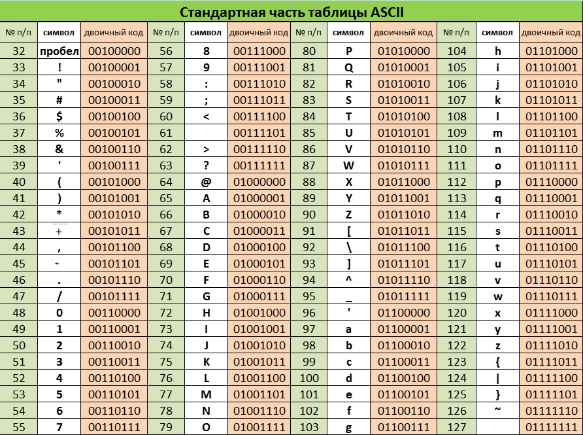
Основой для компьютерных стандартов кодирования символов послужил код ASCII (American Standard Code for Information Interchange) — американский стандартный код для обмена информацией, разработанный в 1960-х годах в США и применявшийся для любых, в том числе и некомпьютерных, способов передачи информации (телеграф, факсимильная связь и т. д.). Этот код 7-битовый: общее количество символов составляет 2 7 = 128, из них первые 32 символа — управляющие, а остальные — изображаемые, т. е. имеющие графическое изображение. К изображаемым символам в ASCII относятся буквы латинского алфавита (прописные и строчные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Кодировка ASCII приведена в табл. 3.8.
Таблица 3.8
Кодировка ASCII

Хотя для кодирования символов в ASCII достаточно 7 битов, в памяти компьютера под каждый символ отводится ровно 1 байт (8 битов), при этом код символа помещается в младшие биты, а в старший бит заносится 0.
Например, 01000001 — код прописной латинской буквы «А»; с помощью шестнадцатеричных цифр его можно записать как 41.
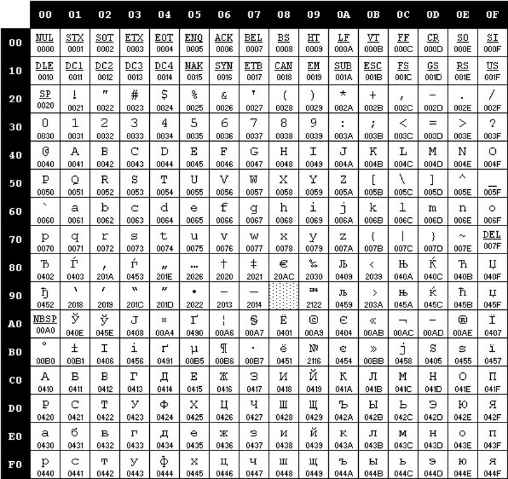
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Для русского языка наиболее распространёнными стали однобайтовые кодовые таблицы CP-866, Windows-1251 (табл. 3.9) и КОИ-8 (табл. 3.10). В них первые 128 символов совпадают с ASCII-кодировкой, а русские буквы размещены во второй части таблицы. Обратите внимание на то, что коды русских букв в этих кодировках различны.
Таблица 3.9
Кодировка Windows-1251

Таблица 3.10
Кодировка КОИ-8

Мы выяснили, что при нажатии на алфавитно-цифровую клавишу в компьютер посылается некоторая цепочка нулей и единиц. В текстовых файлах хранятся не изображения символов, а их коды.
При выводе текста на экран монитора или принтера необходимо восстановить изображения всех символов, составляющих данный текст, причём изображения эти могут быть разнообразны и достаточно причудливы. Внешний вид выводимых на экран символов кодируется и хранится в специальных шрифтовых файлах. Современные текстовые процессоры умеют внедрять шрифты в файл. В этом случае файл содержит не только коды символов, но и описание используемых в этом документе шрифтов. Кроме того, файлы, создаваемые с помощью текстовых процессоров, включают в себя и такие данные о форматировании текста, как его размер, начертание, размеры полей, отступов, межстрочных интервалов и другую дополнительную информацию.
14.2. Стандарт Unicode
В Unicode на кодирование символов отводится 31 бит. Первые 128 символов (коды 0-127) совпадают с таблицей ASCII. Далее размещены основные алфавиты современных языков: они полностью умещаются в первой части таблицы, их коды не превосходят 65 536 = 2 16 .
Стандарт Unicode описывает алфавиты всех известных, в том числе и «мёртвых», языков. Для языков, имеющих несколько алфавитов или вариантов написания (например, японского и индийского), закодированы все варианты. В кодировку Unicode внесены все математические и иные научные символьные обозначения и даже некоторые придуманные языки (например, язык эльфов из трилогии Дж. Р. Р. Толкина «Властелин колец»).
Всего современная версия Unicode позволяет закодировать более миллиона различных знаков, но реально используется чуть менее 110 000 кодовых позиций.
Для представления символов в памяти компьютера в стандарте Unicode имеется несколько кодировок.
В операционных системах семейства Windows используется кодировка UTF-16. В ней все наиболее важные символы кодируются с помощью 2 байт (16 бит), а редко используемые — с помощью 4 байт.
В операционной системе Linux применяется кодировка UTF-8, в которой символы могут занимать от 1 (символы, входящие в таблицу ASCII) до 4 байт. Если значительную часть текста составляют цифры и латинские буквы, то это позволяет в несколько раз уменьшить размер файла по сравнению с кодировкой UTF-16.
Кодировки Unicode позволяют включать в один документ символы самых разных языков, но их использование ведёт к увеличению размеров текстовых файлов.
Мы уже касались этого вопроса, рассматривая алфавитный подход к измерению информации.
Оценим в байтах объём текстовой информации в современном словаре иностранных слов из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы).
Будем считать, что при записи используется кодировка «один символ — один байт». Количество символов во всем словаре равно:
80 • 60 • 740 = 3 552 000.
Следовательно, объём равен
3 552 000 байт = 3 468,75 Кбайт ≈ 3,39 Мбайт.
Если же использовать кодировку UTF-16, то объём этой же текстовой информации в байтах возрастёт в 2 раза и составит 6,78 Мбайт.
САМОЕ ГЛАВНОЕ
Текстовая информация по своей природе дискретна, т. к. представляется последовательностью отдельных символов.
В памяти компьютера хранятся специальные кодовые таблицы, в которых для каждого символа указан его двоичный код. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode (Юникод), позволяющий использовать в текстах любые символы любых языков мира. Кодировки Unicode позволяют включать в один документ символы самых разных языков, но их использование ведёт к увеличению размеров текстовых файлов.
Вопросы и задания
1. Какова основная идея представления текстовой информации в компьютере?
2. Что представляет собой кодировка ASCII? Сколько символов она включает? Какие это символы?
3. Как известно, кодовые таблицы каждому символу алфавита ставят в соответствие его двоичный код. Как, в таком случае, вы можете объяснить вид таблицы 3.8 «Кодировка ASCII»?
4. С помощью таблицы 3.8:
5. Что представляют собой расширения ASCII-кодировки? Назовите основные расширения ASCII-кодировки, содержащие русские буквы.
6. Сравните подходы к расположению русских букв в кодировках Windows-1251 и КОИ-8.
7. Представьте в кодировке Windows-1251 текст «Знание — сила!»:
1) шестнадцатеричным кодом;
2) двоичным кодом;
3) десятичным кодом.
8. Представьте в кодировке КОИ-8 текст «Дело в шляпе!»:
1) шестнадцатеричным кодом;
2) двоичным кодом;
3) десятичным кодом.
9. Что является содержимым файла, созданного в современном текстовом процессоре?
10. В кодировке Unicode на каждый символ отводится 2 байта. Определите в этой кодировке информационный объём следующей строки:
Где родился, там и сгодился.
11. Набранный на компьютере текст содержит 2 страницы. На каждой странице 32 строки, в каждой строке 64 символа. Определите информационный объём текста в кодировке Unicode, в которой каждый символ кодируется 16 битами.
13. В текстовом процессоре MS Word откройте таблицу символов (вкладка Вставка ⇒ Символ ⇒ Другие символы):


В поле Шрифт установите Times New Roman, в поле из — кириллица (дес.).
Урок 13. Представление текстовой информации в компьютере. Кодовые таблицы.
Практическая работа № 4. Представление текстов. Сжатие текстов

В этом параграфе обсудим способы компьютерного кодирования текстовой, графической и звуковой информации. С текстовой и графической информацией конструкторы «научили» работать ЭВМ, начиная с третьего поколения (1970-е годы). А работу со звуком «освоили» лишь машины четвертого поколения, современные персональные компьютеры. С этого момента началось распространение технологии мультимедиа.
Что принципиально нового появлялось в устройстве компьютеров с освоением ими новых видов информации? Главным образом, это периферийные устройства для ввода и вывода текстов, графики, видео, звука. Процессор же и оперативная память по своим функциям изменились мало. Существенно возросло их быстродействие, объем памяти. Но как это было на первых поколениях ЭВМ, так и осталось на современных ПК — основным навыком процессора в обработке данных является умение выполнять вычисления с двоичными числами. Обработка текста, графики и звука представляет собой тоже обработку числовых данных. Если сказать еще точнее, то это обработка целых чисел. По этой причине компьютерные технологии называют цифровыми технологиями.
О том, как текст, графика и звук сводятся к целым числам, будет рассказано дальше. Предварительно отметим, что здесь мы снова встретимся с главной формулой информатики:
Смысл входящих в нее величин здесь следующий: i — разрядность ячейки памяти (в битах), N — количество различных целых положительных чисел, которые можно записать в эту ячейку.
Текстовая информация
Принципиально важно, что текстовая информация уже дискретна — состоит из отдельных знаков. Поэтому возникает лишь технический вопрос — как разместить ее в памяти компьютера.
Напомним о байтовом принципе организации памяти компьютеров, обсуждавшемся в курсе информатики основной школы. Вернемся к рис. 1.5. Каждая клеточка на нем обозначает бит памяти. Восемь подряд расположенных битов образуют байт памяти. Байты пронумерованы. Порядковый номер байта определяет его адрес в памяти компьютера. Именно по адресам процессор обращается к данным, читая или записывая их в память (рис. 1.10).

Поскольку в мире много языков и много алфавитов, постепенно совершается переход на международную систему кодировки Unicode, в которой используются многобайтовые коды. Например, если код символа занимает 2 байта, то с его помощью можно закодировать 2 16 = 65 536 различных символов.
Текстовый документ, хранящийся в памяти компьютера, состоит не только из кодов символьного алфавита. В нем также содержатся коды, управляющие форматами текста при его отображении на мониторе или на печати: тип и размер шрифта, положение строк, поля и отступы и пр. Кроме того, текстовые процессоры (например, Microsoft Word) позволяют включать в документ и редактировать такие «нелинейные» объекты, как таблицы, оглавления, ссылки и гиперссылки, историю вносимых изменений и т. д. Всё это также представляется в виде последовательности байтовых кодов.
Практикум
Практическая работа № 1.4 "Представление текстов. Сжатие текстов"
Цель работы: практическое закрепление знаний о представлении в компьютере текстовых данных.
Задание 1
Определить, какие символы кодируются таблицей ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows). Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.
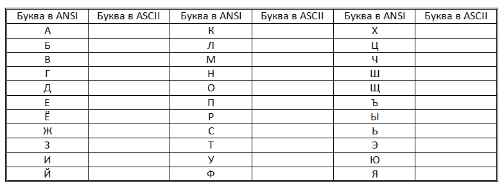
Задание 2
Закодировать текст Happy Birthday to you!! с помощью кодировочной таблицы ASCII
Записать двоичное и шестнадцатеричное представление кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера).
Задание 3
Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление).
72 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33
Задание 4
Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов.
01010000 01100101 01110010 01101101 00100000 01010101
01101110 01101001 01110110 01100101 01110010 01110011
01101001 01110100 01111001
Задание 5
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.
Задание 6
Задание 7
С помощью табличного процессора Excel построить кодировочную таблицу ASCII, в которой символы буду автоматически отображаться на экране в соответствии с их заданным десятичным номером (использовать соответствующую текстовую функцию).
Справочная информация
Алгоритм Хаффмена. Сжатием информации в памяти компьютера называют такое её преобразование, которое ведёт к сокращению объёма ханимаемой памяти при сохранении закодированного содержания. Рассмотрим один из способов сжатия текстовой информации - алгоритм Хаффмена. С помощью этого алгоритма строится двоичное дерево, которое позволяет однозначно декодировать двоичный код, состоящий из символьный кодов различной длины. Двоичным называется дерево, из каждой вершины которого выходят две ветви. На рисунке приведён пример такого дерева, построенный для алфавита английского языка с учётом частоты встречаемости его букв.
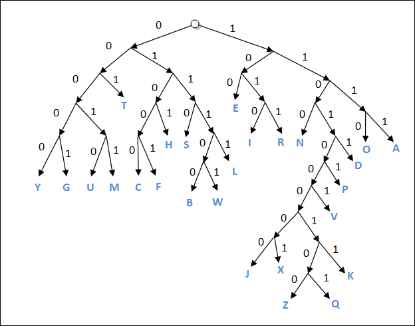
Закодируем с помощью данного дерева слово "hello":
0101 100 01111 01111 1110
При размещении этого кода в памяти побитово он примет вид:
010110001111011111110
Таким образом, текст, занимающий в кодировки ASCII 5 байтов, в кодировке Хаффмена займет 3 байта.
Задание 8
Используя метод сжатия Хаффмена, закодируйте следующие слова:
а) administrator
б) revolution
в) economy
г) department
Задание 9
Используя дерево Хаффмена, декодируйте следующие слова:
а) 01110011 11001001 10010110 10010111 100000
б) 00010110 01010110 10011001 01101101 01000100 000
1. Пользуясь таблицей кодировки ASCII и CP-1251 закодируйте следующие послания:
2. В некоторой кодировке для хранения одного символа отводится 2 байта. Определите вес слова из двадцати двух символов в данной кодировке.
3. В кодировке КОИ-8 для хранения одного символа отводится 1 байт. Определите вес (в битах) слова «дезоксирибонуклеиновая».
5. В кодировке Unicode для хранения одного символа отводится 16 бит. Дан отрывок текста, записанного в данной кодировке:
«Калининград, Ярославль, Владимир, Елабуга, Троицк, Томск, Омск, Уфа – города России».
В результате редактирования текста, одно слово и ставшие лишними пробелы и запятые удалили. Новый текст стал на 14 байт меньше. Определите удалённое слово.
6. Текст, напечатанные на компьютере занял несколько страниц. Каждая страница текста состоит из 60 строк по 30 символов в строке. Файл с данным текстом занимает в компьютере 225 Кбайт. Сколько страниц содержит данный текст, если известно, что он закодирован в Unicode.
7. В кодировке Windows-1251 каждый символ кодируется 8 бит. Вова хотел написать текст (в нём нет лишних пробелов):
«Скользя по утреннему снегу,
Друг милый, предадимся бегу
И навестим поля пустые…»
Одно из слов ученик написал два раза подряд через пробел. При этом размер написанного предложения в данной кодировке оказался на 10 байт больше, чем размер нужного предложения. Напишите в ответе лишнее слово.
9. В кодировке КОИ-8 каждый символ кодируется 8 бит. Вова хотел написать текст (в нём нет лишних пробелов):
«Скользя по утреннему снегу,
друг милый, предадимся бегу
нетерпеливого коня и навестим поля пустые…»
Одно из слов ученик написал два раза подряд через пробел. При этом размер написанного предложения в данной кодировке оказался на 14 байт больше, чем размер нужного предложения. Напишите в ответе лишнее слово.
10. Растровое изображение размером 512х720 пикселей занимает 90 Кбайт памяти. Определите количество цветов в палитре, с помощью которой было закодировано данное изображение.
11. Монитор поддерживает 16-цветовую палитру и вмещает изображение размером 480х640 пикселей. Определите объём видео памяти, необходимый для хранение полноформатного изображения исходя из особенностей данного монитора. Ответ дайте в килобайтах.
12. Определите объём видеопамяти, необходимый для хранения изображения 1024х768 пикселей с палитрой 16 777 216 цветов.
13. Чёрно-белый графический файл (без градаций серого цвета) имеет размер 100х100 пикселей. Определите его информационный объём.
15. Чёрно-белый графический файл с 32 градациями серого цвета имеет размер 64х32 пикселя. Какое максимально возможное число таких файлов можно записать на флеш-носитель ёмкостью 1024 Кбайта?
Кодирование текстовой информации
Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом. Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества - письменность и арифметика - есть не что иное, как система кодирования речи и числовой информации. Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована.
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц - машинным языком.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже (обратите особое внимание!) пробелы между словами.

Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Виды таблиц кодировок
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange - Американский стандартный код для информационного обмена), кодирующая первую половину символов с числовыми кодами от 0 до 127 ( коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Порядковый номер
Символы с номерами от 0 до 31 принято называть управляющими.
Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п.
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы.
Символ 32 - пробел, т.е. пустая позиция в тексте.
Все остальные отражаются определенными знаками.
Альтернативная часть таблицы (русская).
Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.

Обращается внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.


От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 ("CP" означает "Code Page", "кодовая страница").

Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.

Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.

Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251. Введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение.

С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode.

Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Внутреннее представление слов в памяти компьютера
с помощью таблицы ASCII
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать - на экране монитора видна какая-то "абракадабра". Это происходит оттого, что на компьютерах применяется разная кодировка символов русского языка.

Таким образом, каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Н апример, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ» (Рис. 10), тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения.
Читайте также: