Метода коррекции ошибок ecc 200
Обновлено: 02.07.2024
Конечно, вы слышали (или читали) говорить о Код исправления ошибок ECC во многих аппаратных компонентах, связанных с памятью (либо Оперативная память или хранилище), хотя очень немногие понимают его важность. По этой причине в этой статье мы собираемся объяснить, как работает ECC в SSD контроллер и как благодаря этому можно увеличить продолжительность жизни и сделать большую разницу в срок службы твердотельных накопителей .
Каждому устройству, использующему флэш-память NAND, необходим код с исправлением случайных битов (известный как «мягкая» ошибка). Это потому что много электрический шум производится внутри чипа NAND, а уровни сигналов битов, проходящих через цепочку чипов NAND, очень слабые.
Один из способов, которым NAND память стали самый дешевый всего, потому что это требует, чтобы исправление ошибок было выполнено от элемента вне самого чипа NAND; В случае SSD, ECC выполняется на контроллере .
Как ECC работает на контроллере SSD
Хотя это понятие не является слишком широким, сопротивление флэш-памяти является мерой того, сколько циклов стирания / записи может выдержать блок флэш-памяти, прежде чем начнут появляться «серьезные» ошибки. Очень часто эти сбои происходят только в отдельных битах, и очень редко происходит сбой всего блока. При достаточно высоком числе стирания / записи «мягкая» частота ошибок также увеличивается из-за ряда других механизмов в самом SSD.
Давайте рассмотрим пример: допустим, что неиспользуемый чип NAND имеет достаточно «мягких» ошибок, чтобы требовать 8 бит ECC, то есть при каждом считывании страницы может быть до 8 бит, которые были случайно повреждены (обычно из-за электрических помех, которые мы говорили о). вначале). ECC, используемый в этом чипе, может исправлять 12-битные ошибки, так что ECC не может решить эту проблему мы должны найти 8 «мягких» ошибок, связанных с электрическим шумом, плюс еще 5 «мягких» из-за износа.
Теперь производители флэш-памяти гарантируют, что первый из этих 5 сбоев произойдет через некоторое время после спецификации прочности SSD. Это означает, что ни один бит не выйдет из строя из-за износа, пока не будут превышены циклы стирания / записи, указанные производителем. Теперь имейте в виду, что спецификации не достаточно точны, чтобы предсказать, когда следующий бит выйдет из строя, и на самом деле это может занять несколько тысяч циклов стирания / записи выше спецификации, чтобы это произошло; помните, что производитель гарантирует, что это не произойдет до X циклов, но не тогда, когда это произойдет после их превышения.

Это означает, что это может занять много времени, прежде чем блок становится настолько коррумпированным что его необходимо удалить из службы (а также для этого на SSD обычно есть «дополнительные» блоки для замены поврежденных), что, в свою очередь, означает, что сопротивление исправлен от ошибок блок может быть во много раз больше указанного сопротивления, в зависимости от количества избыточных ошибок, которые ECC предназначен для исправления.
Какое влияние оказывает код исправления ошибок на SSD?
Как мы объясняли ранее, флэш-память настолько дешева, потому что она не включает в себя ECC в самих чипах, но интегрирована в другое внешнее оборудование, и, как вы предположите, это имеет свою цену. Более сложный ECC требует большей вычислительной мощности на контроллере и может быть медленнее, если алгоритмы не очень современные. Кроме того, количество ошибок, которые могут быть исправлены, будет зависеть от того, насколько большой сектор памяти исправляется, поэтому контроллер SSD со сложным алгоритмом ECC, вероятно, будет использовать много ресурсов, снижение общий SSD производительность , Эти улучшения также делают контроллер дороже .

Алгоритмы ECC имеют свое собственное математическое состояние в зависимости от контроллера (другими словами, нет никакого стандарта), и даже самые базовые кодировки ECC (Рида-Соломона и LDPC) довольно сложны для понимания. Когда кто-то говорит о пределе Шеннона (максимальное количество битов, которое может быть исправлено), это величина, которую, как вы не знаете от производителя в технических характеристиках, чрезвычайно сложно вычислить.
Просто придерживайтесь этого: большее количество корректирующих битов увеличивает срок службы SSD, но также оказывает некоторое влияние на производительность или даже цену продукта, так как требует более мощный контроллер.
ГОСТ Р ИСО/МЭК 16022-2008
НАЦИОНАЛЬНЫЙ СТАНДАРТ РОССИЙСКОЙ ФЕДЕРАЦИИ
Спецификация символики Data Matrix
Automatic identification. Bar coding. Data Matrix symbology specification
Дата введения 2010-01-01
Цели и принципы стандартизации в Российской Федерации установлены Федеральным законом от 27 декабря 2002 г. N 184-ФЗ "О техническом регулировании", а правила применения национальных стандартов Российской Федерации - ГОСТ Р 1.0-2004 "Стандартизация в Российской Федерации. Основные положения"*
* На территории Российской Федерации документ не действует. Действует ГОСТ Р 1.0-2012. - Примечание изготовителя базы данных.
Сведения о стандарте
1 ПОДГОТОВЛЕН Ассоциацией автоматической идентификации "ЮНИСКАН/ГС1 РУС" совместно с Обществом с ограниченной ответственностью (ООО) НПЦ "Интелком" на основе аутентичного перевода стандарта, указанного в пункте 4, выполненного ООО НПЦ "Интелком"
2 ВНЕСЕН Техническим комитетом по стандартизации ТК 355 "Автоматическая идентификация"
3 УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Приказом Федерального агентства по техническому регулированию и метрологии от 18 декабря 2008 г. N 509-ст
4 Настоящий стандарт идентичен международному стандарту ИСО/МЭК 16022:2006* "Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация символики штрихового кода Data Matrix" (ISO/IEC 16022:2006 "Information technology - Automatic identification and data capture techniques - Data Matrix bar code symbology specification"), за исключением приложения U, содержащего сведения о соответствии терминов на русском и английском языках, приложения V, включающего в себя сведения о наборах знаков по ИСО/МЭК 646, ИСО/МЭК 8859-1 и ИСО/МЭК 8859-5. В приложении М приведены исправления в соответствии со списком технических опечаток 1 (Technical Corrigendum 1) к ISO/IEC 16022.1:2006.
* Доступ к международным и зарубежным документам, упомянутым в тексте, можно получить, обратившись в Службу поддержки пользователей. - Примечание изготовителя базы данных.
Наименование национального стандарта изменено относительно наименования указанного международного стандарта для приведения в соответствие с ГОСТ Р 1.5-2004* (подраздел 3.5) и учета его принадлежности к группе стандартов "Автоматическая идентификация".
_______________
* На территории Российской Федерации документ не действует. Действует ГОСТ Р 1.5-2012. - Примечание изготовителя базы данных.
При применении настоящего стандарта рекомендуется использовать вместо ссылочных международных (региональных) стандартов соответствующие им национальные стандарты, сведения о которых приведены в дополнительном приложении W
5 ВВЕДЕН ВПЕРВЫЕ
Изменение N 1 внесено изготовителем базы данных по тексту ИУС N 1, 2014 год
Информация об изменениях к настоящему стандарту публикуется в ежегодно издаваемом информационном указателе "Национальные стандарты", а текст изменений и поправок - в ежемесячно издаваемых информационных указателях "Национальные стандарты". В случае пересмотра (замены) или отмены настоящего стандарта соответствующее уведомление будет опубликовано в ежемесячно издаваемом информационном указателе "Национальные стандарты". Соответствующая информация, уведомления и тексты размещаются также в информационной системе общего пользования - на официальном сайте Федерального агентства по техническому регулированию и метрологии в сети Интернет
Data Matrix - двухмерная матричная символика, состоящая из квадратных модулей, упорядоченных внутри периметра шаблона поиска. В настоящем документе представление символа и его описание приведено, главным образом, для темных модулей на светлом фоне. Тем не менее, символы Data Matrix также могут быть напечатаны в виде светлых модулей на темном фоне.
Производителям оборудования и пользователям технологии штрихового кодирования необходима общедоступная стандартная спецификация символики, на которую они могли бы ссылаться при разработке оборудования и стандартов по применению. С этой целью и был разработан настоящий стандарт.
Следует обратить внимание на возможность того, что некоторые элементы, включенные в настоящий стандарт, могут быть объектом патентного права, и организации ИСО и МЭК не берут на себя ответственность за определение некоторых или всех подобных патентных прав.
Сноски в тексте стандарта, выделенные курсивом, приведены для пояснения текста стандарта.
1 Область применения
Настоящий стандарт устанавливает требования к символике Data Matrix*, а также параметры символики, кодирование знаков данных, форматы символов, требования к размерам и качеству печати, правила исправления ошибок, алгоритм декодирования и прикладные параметры, выбираемые пользователем.
* Название символики произносится как Дата Матрикс, что в переводе на русский язык - "матрица данных".
Настоящий стандарт распространяется на все символы символики Data Matrix, напечатанные или нанесенные каким-либо другим способом.
2 Нормативные ссылки
В настоящем стандарте использованы нормативные ссылки на следующие стандарты и другие нормативные документы*, которые необходимо учитывать при использовании настоящего стандарта. В случае ссылок на документы, у которых указана дата утверждения, необходимо пользоваться только указанной редакцией. В случае, когда дата утверждения не приведена, следует пользоваться последней редакцией ссылочных документов, включая любые поправки и изменения к ним:
* Таблицу соответствия национальных стандартов международным см. по ссылке. - Примечание изготовителя базы данных.
ИСО/МЭК 15424 Информационные технологии. Технологии автоматической идентификации и сбора данных. Идентификаторы носителей данных (включая идентификаторы символик) (Information technology - Automatic identification and data capture techniques - Data Carrier Identifiers (including Symbology Identifiers)
ИСО/МЭК 19762-1 Информационные технологии. Технологии автоматической идентификации и сбора данных. Гармонизированный словарь. Часть 1. Общие термины, связанные с автоматической идентификацией и сбором данных (Information technology - Automatic identification and data capture (AIDC) techniques - Harmonized vocabulary - Part 1: General terms relating to AIDC)
ИСО/МЭК 19762-2 Информационные технологии. Технологии автоматической идентификации и сбора данных. Гармонизированный словарь. Часть 2. Средства для оптического считывания (Information technology - Automatic identification and data capture (AIDC) techniques - Harmonized vocabulary - Part 2: Optically readable media (ORM))
ИСО/МЭК 15415 Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация испытаний качества печати символов штрихового кода. Двумерные символы (Information technology - Automatic identification and data capture techniques - Bar code print quality test specification - Two-dimensional symbols)
ИСО/МЭК 15416 Информационные технологии. Технологии автоматической идентификации и сбора данных. Спецификация испытаний качества печати символов штрихового кода. Линейные символы (Information technology - Automatic identification and data capture techniques - Bar code print quality test specification - Linear symbols)
ИСО/МЭК 646:1991 Информационные технологии. Набор 7-битовых кодированных знаков ИСО для обмена информацией (Information technology - ISO 7-bit coded character set for information interchange)
AIM Inc. ITS/04-001 Международный технический стандарт. Интерпретации в расширенном канале. Часть 1. Схемы идентификации и протокол (AIM Inc. ITS/04-001 International Technical Standard: Extended Channel Interpretations - Part 1: Identification Schemes and Protocol)
3 Термины, определения, символы и математические/логические обозначения
3.1 Термины и определения
В данном документе используются термины, определенные в ИСО/МЭК 19762-1, ИСО/МЭК 19762-2, а также следующие:
3.1.1 кодовое слово (codeword): Значение знака символа, формируемое на промежуточном уровне кодирования в процессе преобразования исходных данных в их графическое представление в символе.
3.1.2 модуль (module): Отдельная ячейка матричной символики, используемая для кодирования одного бита информации и имеющая номинально квадратную форму в символах Data Matrix.
3.1.3 сверточное кодирование (convolutional coding): Алгоритм контроля и исправления ошибок, преобразующий множество битов на входе во множество битов на выходе, которое может быть восстановлено после повреждения, путем кодирования с разделением множества входящих битов на блоки с последующим проведением операции свертки каждого входящего блока с регистром сдвига со множеством состояний для получения защищенных на выходе блоков.
Примечание - Такие алгоритмы кодирования могут быть реализованы с помощью аппаратных средств путем использования входных и выходных коммутаторов, регистров сдвига и вентилей исключающих ИЛИ*.
* Международное обозначение операции исключающее ИЛИ: exclusive-or - XOR.
3.1.4 шаблонная рандомизация (pattern randomising): Процедура, с помощью которой исходный набор битов превращают в другой набор битов путем инвертирования отдельных битов с целью уменьшения вероятности повторения в символе одинаковых наборов.
3.2 Символы
В данном документе, если иное не предусмотрено в особых случаях, применяют следующие математические символы:
- число кодовых слов исправления ошибок;
- (для версии ЕСС 000-140) число битов в полном сегменте на входе в конечный автомат для генерирования сверточного кода;
(для версии ЕСС 200) общее число кодовых слов исправления ошибок;
- порядок памяти сверточного кода;
- (для версии ЕСС 000-140) число битов в полном сегменте, сгенерированных конечным автоматом, порождающим сверточный код;
(для версии ЕСС 200) общее число кодовых слов данных;
- числовое основание в схеме кодирования;
- число кодовых слов, зарезервированных для обнаружения ошибок;
- сегмент битов на входе в конечный автомат, принимающий битов за единицу времени;
- сегмент битов на выходе из конечного автомата, генерирующего битов за единицу времени;
- горизонтальный и вертикальный размеры модуля;
- кодовое слово исправления ошибок.
3.3 Математические обозначения
В настоящем стандарте используются следующие обозначения и математические операции:
- оператор деления на целое число;
- остаток при делении на целое число;
- исключающее ИЛИ (exclusive-or) - логическая функция или операция, результатом которой является единица только в случае неэквивалентности двух входов;
На сегодняшний день на просторах Рунета можно встретить открытые темы на форумах с вопросами – стоит ли брать рабочую станцию с ECC-памятью или можно обойтись обычной? В данных ветках можно прочесть множество противоречивых утверждений, и часть из них говорит о том, что коррекция ошибок сильно замедляет память, а следовательно и ЦП. Но мало кто это проверял на деле на современных процессорах.
реклама
Сегодня мы разберемся в этом вопросе и сравним производительность серверного процессора с обоими типами памяти. Но для начала небольшой экскурс.
Коррекция ошибок
Для чего необходима коррекция? И почему в работе памяти возникают ошибки? Перед ответом на эти вопросы следует разделить ошибки на два типа:
Причиной появления аппаратных ошибок является дефектная микросхема DRAM, а случайные ошибки возникают под воздействием излучения, альфа-частиц, элементарных частиц и прочего. Соответственно, первые в принципе неисправимы – если чип дефектный, то поможет только его замена; а вот вторые могут быть исправлены.
Почему же так необходима коррекция ошибок в рабочих станциях и серверах? Однобитовая ошибка в 64-битном слове меняет содержимое ячейки памяти, а в конечном итоге на жесткий диск может быть записано другое число, другие данные, при этом компьютер не зафиксирует эту подмену. А изменение бита в оперативной памяти может вызвать сбой программы, что для рабочей станции и сервера недопустимо.
MSI RTX 3070 сливают дешевле любой другой, это за копейки Дешевая 3070 Gigabyte Gaming - успей пока не началосьДля обнаружения изменения битов памяти можно использовать метод подсчета контрольной суммы, но он позволяет лишь обнаруживать ошибки без их исправления.
В свое время было предложено много различных способов решения данной проблемы, но на сегодняшний день наибольшее распространение получил метод коррекции ошибок или ECC (Error-Correcting Code). Данный метод позволяет автоматически исправлять однобитовые ошибки в 64-битном слове – SEC (Single Error Correction) и детектировать двухбитовые – DED (Double Error Detection).
Физическая реализация ECC заключается в размещении дополнительной микросхемы памяти на модуле ОЗУ – соответственно, при одностороннем дизайне модуля памяти вместо восьми чипов располагается девять, а при двустороннем вместо шестнадцати – восемнадцать. Таким образом, ширина модуля становится не 64 бита, а 72 бита.
Метод коррекции ошибок работает следующим образом: при записи 64 бит данных в ячейку памяти происходит подсчет контрольной суммы, составляющей 8 бит. Когда процессор обращается к этим данным и производит считывание, проводится повторный подсчет контрольной суммы и сравнение с исходной. Если суммы не совпадают – произошла ошибка. Если она однобитовая, то неправильный бит исправляется автоматически, если двухбитовая – детектируется и сообщается ОС.
Финансовая сторона
реклама
Прежде чем приступить к тестированию, необходимо затронуть финансовый вопрос.
Стоимость обычного модуля памяти DDR3-1600 с напряжением 1.35 В и объемом 8 Гбайт составляет около 3600 рублей, а с коррекцией ошибок – 4800 рублей. На первый взгляд ECC-память выходит на 30-35% дороже, что, в целом, не позволяет их сравнивать в силу существенно большей стоимости последней. Но почему же тогда такой вопрос возникает при сборке рабочей станции? Все просто – необходимо смотреть на данный вопрос шире, а именно – смотреть на общую стоимость рабочей станции.
Ценник однопроцессорной станции на базе четырехъядерного восьмипоточного Xeon (настольные процессоры серий i5 и i7 не поддерживают ECC-память) с 32 Гбайтами памяти, материнской платы с чипсетом C222/С224/С226 (десктопные наборы логики Z87/Z97 и другие также не поддерживают память с коррекцией ошибок) будет превышать 70 000 рублей (при условии, что устанавливаются серверные SSD с повышенным ресурсом). А если включить в эту стоимость и дискретную видеокарту, и прочие сопутствующие компоненты, например, ИБП, то ценник из пятизначного превратится в шестиизначный, перевалив планку в 100 000 рублей.
Покупка 32 Гбайт памяти с коррекцией ошибок потребует дополнительных 4-6 тысяч рублей, что по отношению к общей стоимости рабочей станции не превышает 5%, то есть не является критичным. Также переход от десктопного к серверному железу предоставит и другие преимущества, например: интегрированные графические карты P4600 в процессорах Intel Xeon E3-1200 третьего поколения получили оптимизированные драйверы, которые должны повышать производительность в профессиональных приложениях, например, в CAD; поддержка технологии Intel VT-d, которая позволяет пробрасывать устройства в виртуальную среду, например, видеокарты; прочие серверные технологии – Intel AMT или IPMI, WatchDog и другие, которые также могут оказаться полезными.
Таким образом, хоть и сама ECC-память стоит заметно дороже обычной, в общей стоимости рабочей станции данная статья затрат является несущественной, и переплата не превышает 5%.
Тестовый стенд
Для данного обзора использовалась следующая конфигурация:
- Материнская плата: Supermicro X10SAE (Intel C226, LGA 1150);
- Процессор: Xeon E3-1245V3 (Turbo Boost – off, EIST – off, HT – on);
- Оперативная память:
- 2x Kingston DDR3-1600 ECC 8 Гбайт (KVR16LE11/8 CL11, 1.35 В);
- 2x Kingston DDR3-1600 8 Гбайт (KVR16LN11/8 CL11, 1.35 В);
Методика тестирования
В рамках тестирования были произведены замеры производительности как при одноканальном режиме работы ИКП, так и при двухканальном. Суммарный объем ОЗУ составил 8 (один модуль) и 16 Гбайт (два модуля) соответственно.
- 3DMark 2006 1.2;
- 7Zip 9.20;
- AIDA64 Extreme 5.20.3400;
- Cinebench R15;
- CrystalMark 2004R3;
- Fritz 4.20;
- LinX 0.6.5;
- wPrime 2.10.
Результаты тестирования
Тест памяти
Перед тем, как приступить к тестированию, проведем замер пропускной способности памяти и латентности.
![550x378 31 KB. Big one: 1019x701 26 KB]()
реклама
При изучении результатов можно заключить, что производительность ECC- и non-ECC- памяти находится на одном и том же уровне в рамках погрешности.
![550x147 18 KB. Big one: 1017x273 11 KB]()
Если в предыдущем тесте от замера к замеру выигрывал то один, то другой тип памяти, то при замере латентности ECC-память постоянно показывает большие задержки. Но разница несущественна – всего лишь 1 нс.
Таким образом, замер ПС и латентности памяти не показал особых различий между ECC- и non-ECC-памятью. Посмотрим, повторится ли это в последующих тестах.
3DMark
реклама
Тестовый пакет 3DMark содержит подтесты как для процессора, так и для графической карты. Здесь и кроется самое интересное – давно известно, что встроенному видеоядру не хватает существующей ПСП в 25.6 Гбайт/с, поэтому именно в графических подтестах можно выявить негативное влияние коррекции ошибок, если оно вообще есть,…
![550x880 50 KB. Big one: 1037x1661 64 KB]()
. но разницы нет – что ECC, что non-ECC. Ни процессор, ни интегрированное ядро никак не реагируют на замену обычной памяти на DDR с коррекцией ошибок – результаты одинаковы в рамках погрешности. Среднеарифметическая разница составила 0.02% в пользу ECC-памяти для одноканального режима и 1.6% для двухканального режима.
При этом нельзя сказать, что встроенная видеокарта P4600 не зависит от скорости ОЗУ – при одноканальном доступе общий результат почти на 30% ниже, чем при двухканальном. Другими словами, скорость ОЗУ критична для графического ядра, но сами по себе «ECC-версии» не влияют ни на скорость ОЗУ, ни на видеокарту.
реклама
Архиваторы, как известно, чувствительны к памяти, поэтому, возможно, здесь получится зафиксировать влияние типа памяти на производительность.
![550x293 23 KB. Big one: 1027x548 20 KB]()
Ситуация с архивацией неоднозначная: с одной стороны – в одноканальном режиме (как при распаковке, так и при сжатии) ECC-память уверенно оказывается медленнее на 2%; с другой – в двухканальном режиме при сжатии ECC-память уверенно быстрее, а при распаковке – медленнее, а среднее арифметическое – быстрее на 0.65%.
Скорее всего, причина в следующем – пропускной способности памяти при одноканальном доступе процессору явно недостаточно, и поэтому чуть большая латентность ECC-памяти сказывается на производительности; а при двухканальном доступе ПСП полностью покрывает нужды CPU и поэтому чуть большая латентность памяти с коррекцией ошибок не сказывается на производительности. В любом случае зафиксировать существенного влияния на скорость архивации не получилось.
Cinebench
реклама
Тестовый пакет Cinebench содержит подтест как процессора, так и видеокарты.
![550x293 20 KB. Big one: 1026x547 20 KB]()
Но ни первый, ни вторая никак не отреагировали на ECC-память.
Зато налицо явная зависимость видеокарты от ПСП – при одноканальном доступе результат в OpenGL оказался на 25% ниже, чем при двухканальном. Вспоминая результаты 3DMark и смотря на нынешние, можно заключить, что производительность интегрированной видеокарты хоть и зависит от ПСП, но ECC-память не оказывает на нее негативного влияния.
![]()
В 1948 году Клод Шеннон опубликовал свою знаменитую работу о передаче информации, в которой, помимо прочего, была сформулирована теорема о передаче информации по каналу с помехами. После публикации, было разработано немало алгоритмов исправления ошибок с помощью некоторого увеличения объема передаваемых данных, но одним из часто встречающихся семейств алгоритмов, являются алгоритмы, основанные на коде с малой плотностью проверок на четность (Low-density parity-check code, LDPC-code, низкоплотностный код), получившие сейчас распространение за счет простоты реализации.![]()
LDPC был впервые представлен миру в стенах MIT Робертом Греем Галлагером (Robert Gray Gallager), выдающимся специалистом в области коммуникационных сетей. Произошло это в 1960 году, и LDPC опередил свое время. Компьютеры на вакуумных лампах, распространенные в то время, редко обладали мощностью достаточной, для эффективной работы с LDPC. Компьютер, способный обрабатывать такие данные в реальном времени, в те годы занимал площадь почти в 200 квадратных метров, и это автоматически делало все алгоритмы, основанные на LDPC экономически невыгодными. Поэтому, на протяжении почти 40 лет использовались более простые коды, а LDPC оставался скорее изящным теоретическим построением.
![]()
В середине 90-х, инженеры, работающие над алгоритмами спутниковой передачи цифрового телевидения, «стряхнули пыль» с LDPC и стали его использовать, поскольку компьютеры к тому времени стали и мощней, и меньше. К началу 2000-х годов, LDPC получает повсеместное распространение, поскольку он позволяет с большой эффективностью исправлять ошибки при высокоскоростной передаче данных в условиях высоких помех (например при сильных электромагнитных наводках). Так же распространению способствовало появление специализированных систем на чипах, использующихся в WiFi технике, жестких дисках, контроллерах SCSI и т.д., такие SoC оптимизируются под задачи, и для них вычисления, связанные с LDPC вообще не представляют проблемы. В 2003 году LDPC-код, вытеснил технологию турбо-кода, и стал частью стандарта спутниковой передачи данных для цифрового телевидения DVB-S2. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового «эфирного» телевидения.
Стоит сказать, что на базе LDPC строятся очень разные решения, нет «единственно правильной» эталонной реализации. Часто решения, основанные на LDPC несовместимы между собой и код, разработанный, например, для спутникового телевидения, не может быть портирован и использован в жестких дисках. Хотя чаще всего, объединение усилий инженеров разных областей дает массу преимуществ, и LDPC «в целом» является технологией не запатентованной, разные ноу-хау и проприетарные технологии вместе с корпоративными интересами встают на пути. Чаще всего, подобное сотрудничество возможно только в пределах одной компании. В качестве примера можно привести решение для канала чтения HDD от LSI под названием TrueStore®, которое компания предлагает на протяжении уже 3 лет. После приобретения компании SandForce, инженеры LSI стали работать над алгоритмами исправления ошибок SHIELD™ для SSD контроллеров (основанными на LDPC), не существовало портов алгоритмов для работы с SSD, но знания инженерной команды, работавшей над решениями для HDD очень помогли в разработке новых алгоритмов.
Тут, разумеется, у большинства читателей возникнет вопрос: чем алгоритмы, каждый алгоритм LDPC отличается от остальных? Большинство решений LDPC начинаются как декодеры с жестким решением, то есть такой декодер работает с жестко ограниченным набором данных (чаще всего 0 и 1) и использует код коррекции ошибок при малейших отклонениях от нормы. Такое решение, конечно, позволяет эффективно обнаруживать ошибки в передаваемых данных и исправлять их, но в случае высокого уровня ошибок, что иногда случается при работе с SSD, такие алгоритмы перестают справляться с ними. Как вы помните из наших предыдущих статей, любая флеш-память подвержена росту количества ошибок в процессе эксплуатации. Этот неизбежный процесс стоит учитыавть при разработке алгоритмов корреции ошибок для SSD накопителей. Что же делать в случае роста числа ошибок?
Тут на помощь приходят LDPC с мягким решением, являющиеся по сути «более аналоговыми». Подобные алгоритмы «смотрят» глубже, чем «жесткие», и, обладают большим набором возможностей. Примером самого простого такого решения может быть попытка прочитать данные снова, используя другое напряжение, так же как мы часто просим собеседника повторить фразу погромче. Продолжая метафоры с общением людей, можно привести пример более сложных алгоритмов коррекции. Представьте, что вы общаетесь на английском с человеком, говорящим с сильнейшим акцентом. В данном случае сильный акцент выступает в роли помехи. Ваш собеседник произнес некую длинную фразу, которую вы не поняли. В роли LDPC с мягким решением в данном случае будут выступать несколько коротких наводящих вопросов, которые вы можете задать и прояснить весь смысл фразы, которую вы изначально не поняли. Подобные мягкие решения часто используют так же сложные статистические алгоритмы, позволяющие исключить ложнопозитивные срабатывания. В общем, как вы уже поняли, такие решения заметно сложней в реализации, но они чаще всего показывают куда лучшие результаты по сравнению с «жексткими».
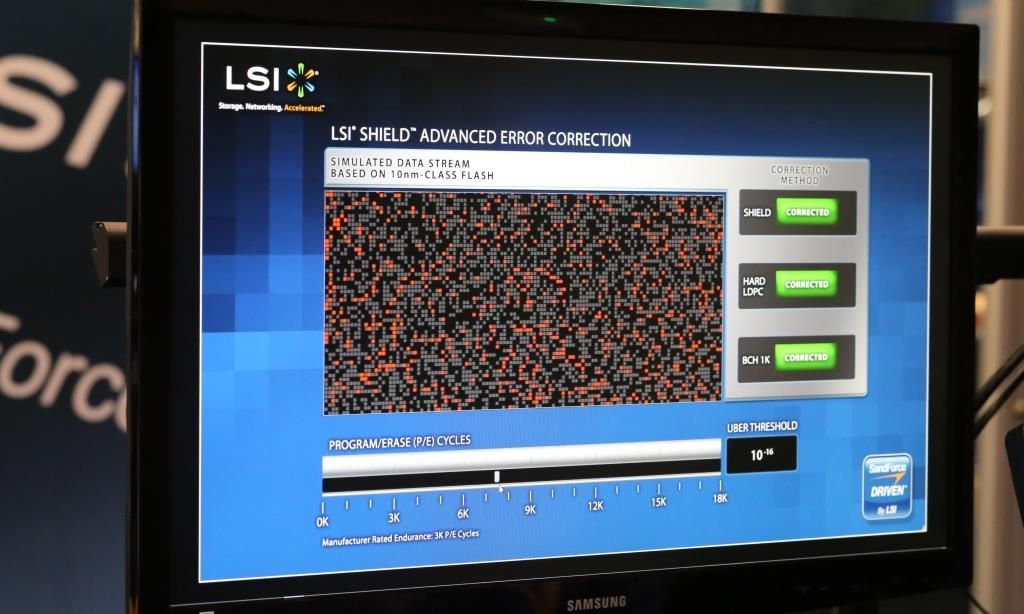
В 2013 году, на саммите, посвященном флэш-памяти, проходившем в Санта-Кларе, Калифорния, LSI представили свою технологию расширенной коррекции ошибок SHIELD. Комбинируя подходы с мягким и жестким решением, DSP SHIELD предлагает ряд уникальных оптимизаций для будущих технологий Flash-памяти. Например, технология Adaptive Code Rate, позволяет менять объем, отведенный под ECC так, чтоб он занимал как можно меньше места изначально, и динамически увеличивался по мере неизбежного роста количества ошибок, характерных для SSD.
![]()
Как видите, различные решения LDPC работают очень по-разному, и предлагают разные фунции и возможности, от которых во многом будет зависеть и качество работы финального продукта.
![]()
В 1948 году Клод Шеннон опубликовал свою знаменитую работу о передаче информации, в которой, помимо прочего, была сформулирована теорема о передаче информации по каналу с помехами. После публикации, было разработано немало алгоритмов исправления ошибок с помощью некоторого увеличения объема передаваемых данных, но одним из часто встречающихся семейств алгоритмов, являются алгоритмы, основанные на коде с малой плотностью проверок на четность (Low-density parity-check code, LDPC-code, низкоплотностный код), получившие сейчас распространение за счет простоты реализации.![]()
LDPC был впервые представлен миру в стенах MIT Робертом Греем Галлагером (Robert Gray Gallager), выдающимся специалистом в области коммуникационных сетей. Произошло это в 1960 году, и LDPC опередил свое время. Компьютеры на вакуумных лампах, распространенные в то время, редко обладали мощностью достаточной, для эффективной работы с LDPC. Компьютер, способный обрабатывать такие данные в реальном времени, в те годы занимал площадь почти в 200 квадратных метров, и это автоматически делало все алгоритмы, основанные на LDPC экономически невыгодными. Поэтому, на протяжении почти 40 лет использовались более простые коды, а LDPC оставался скорее изящным теоретическим построением.
![]()
В середине 90-х, инженеры, работающие над алгоритмами спутниковой передачи цифрового телевидения, «стряхнули пыль» с LDPC и стали его использовать, поскольку компьютеры к тому времени стали и мощней, и меньше. К началу 2000-х годов, LDPC получает повсеместное распространение, поскольку он позволяет с большой эффективностью исправлять ошибки при высокоскоростной передаче данных в условиях высоких помех (например при сильных электромагнитных наводках). Так же распространению способствовало появление специализированных систем на чипах, использующихся в WiFi технике, жестких дисках, контроллерах SCSI и т.д., такие SoC оптимизируются под задачи, и для них вычисления, связанные с LDPC вообще не представляют проблемы. В 2003 году LDPC-код, вытеснил технологию турбо-кода, и стал частью стандарта спутниковой передачи данных для цифрового телевидения DVB-S2. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового «эфирного» телевидения.
Стоит сказать, что на базе LDPC строятся очень разные решения, нет «единственно правильной» эталонной реализации. Часто решения, основанные на LDPC несовместимы между собой и код, разработанный, например, для спутникового телевидения, не может быть портирован и использован в жестких дисках. Хотя чаще всего, объединение усилий инженеров разных областей дает массу преимуществ, и LDPC «в целом» является технологией не запатентованной, разные ноу-хау и проприетарные технологии вместе с корпоративными интересами встают на пути. Чаще всего, подобное сотрудничество возможно только в пределах одной компании. В качестве примера можно привести решение для канала чтения HDD от LSI под названием TrueStore®, которое компания предлагает на протяжении уже 3 лет. После приобретения компании SandForce, инженеры LSI стали работать над алгоритмами исправления ошибок SHIELD™ для SSD контроллеров (основанными на LDPC), не существовало портов алгоритмов для работы с SSD, но знания инженерной команды, работавшей над решениями для HDD очень помогли в разработке новых алгоритмов.
Тут, разумеется, у большинства читателей возникнет вопрос: чем алгоритмы, каждый алгоритм LDPC отличается от остальных? Большинство решений LDPC начинаются как декодеры с жестким решением, то есть такой декодер работает с жестко ограниченным набором данных (чаще всего 0 и 1) и использует код коррекции ошибок при малейших отклонениях от нормы. Такое решение, конечно, позволяет эффективно обнаруживать ошибки в передаваемых данных и исправлять их, но в случае высокого уровня ошибок, что иногда случается при работе с SSD, такие алгоритмы перестают справляться с ними. Как вы помните из наших предыдущих статей, любая флеш-память подвержена росту количества ошибок в процессе эксплуатации. Этот неизбежный процесс стоит учитыавть при разработке алгоритмов корреции ошибок для SSD накопителей. Что же делать в случае роста числа ошибок?
Тут на помощь приходят LDPC с мягким решением, являющиеся по сути «более аналоговыми». Подобные алгоритмы «смотрят» глубже, чем «жесткие», и, обладают большим набором возможностей. Примером самого простого такого решения может быть попытка прочитать данные снова, используя другое напряжение, так же как мы часто просим собеседника повторить фразу погромче. Продолжая метафоры с общением людей, можно привести пример более сложных алгоритмов коррекции. Представьте, что вы общаетесь на английском с человеком, говорящим с сильнейшим акцентом. В данном случае сильный акцент выступает в роли помехи. Ваш собеседник произнес некую длинную фразу, которую вы не поняли. В роли LDPC с мягким решением в данном случае будут выступать несколько коротких наводящих вопросов, которые вы можете задать и прояснить весь смысл фразы, которую вы изначально не поняли. Подобные мягкие решения часто используют так же сложные статистические алгоритмы, позволяющие исключить ложнопозитивные срабатывания. В общем, как вы уже поняли, такие решения заметно сложней в реализации, но они чаще всего показывают куда лучшие результаты по сравнению с «жексткими».
В 2013 году, на саммите, посвященном флэш-памяти, проходившем в Санта-Кларе, Калифорния, LSI представили свою технологию расширенной коррекции ошибок SHIELD. Комбинируя подходы с мягким и жестким решением, DSP SHIELD предлагает ряд уникальных оптимизаций для будущих технологий Flash-памяти. Например, технология Adaptive Code Rate, позволяет менять объем, отведенный под ECC так, чтоб он занимал как можно меньше места изначально, и динамически увеличивался по мере неизбежного роста количества ошибок, характерных для SSD.
![]()
Как видите, различные решения LDPC работают очень по-разному, и предлагают разные фунции и возможности, от которых во многом будет зависеть и качество работы финального продукта.
Читайте также: