
Можно ли в будущем научить компьютер воспринимать мимику тембр и громкость голоса человека
Обновлено: 07.07.2024

На лице человека отображаются любые эмоции, как бы человек ни старался их скрыть. Обычные эмоции может распознать как человек, так и машина, но сейчас речь идет о микровыражениях, мимике лица, которая практически незаметна для окружающих. Сейчас разработан алгоритм, выявляющих эти мини-эмоции, и распознающий их.
Ранее это умели делать (и то не слишком хорошо) только тренированные профессионалы — полицейские, работники спецслужб, психологи. Теперь это же могут делать и машины, причем с большей точностью, чем люди. Автором проекта по изучению микровыражений и обучению компьютеров идентификации таких эмоций является Сяобаи Ли (Xiaobai Li) из Университета Оулу, Финляндия и несколько его коллег.
Команда смогла создать и проверить в работе первую систему, способную обнаружить и идентифицировать микровыражение, минимальную мимику лица человека. Причем машина выполняет эту задачу лучше, чем люди. Разработка подобной технологии стала возможной благодаря прогрессу в сфере искусственного интеллекта и когнитивного обучения. Сам алгоритм был бы бесполезен без большой базы данных, которая используется для обучения машин.
Так, первой задачей Ли и коллег была разработка базы данных видео с демонстрацией микровыражений лица человека в реальных условиях. Это сделать сложнее, чем сказать. Желание скрыть свои эмоции появляется у человека не так часто, а на камеру это сделать еще тяжелее. Но базу составлять нужно, поскольку микроэмоции значительно отличаются от обычной мимики.
Ли с коллегами решили попробовать такой метод: группу из 20 добровольцев попросили просмотреть несколько видео, которые обычно вызывают сильные эмоции у человека. При этом людям сказали, что они будут должны заполнить очень большой опросник, детально описывая каждую проявленную эмоцию. И большинство добровольцев скрывали свои чувства под маской безразличия.
Так поступили 16 из 20 человек, принявших участие в исследовании. Всего было зафиксировано 164 проявления микроэмоций, все это фиксировалось на камеру, сьемка велась со скоростью около 100 fps. Затем команда связала эмоции каждого человека с эмоциональным содержанием видео, разработав базу, которая и использовалась для обучения машин.
Для компьютерной системы задача распознавания микроэмоций делится на две части. Первая — определить изменение выражение лица человека и описать его, как микроэмоцию. Второе — идентифицировать микроэмоцию. Первая задача решилась путем сопоставления действительно безэмоционального выражения лица человека с изображениями микромимики. Любое изменение выражения лица определялось как микроэмоция.
Вторая задача, распознавание эмоций, была еще более сложной. Команда решила усилить микромимику путем фиксации движения частей лица во время изменения выражения. Основное внимание уделялось именно тем частям лица, которые определяют выражение эмоции, а не просто движутся. Затем алгоритм научили определять эмоции как позитивные, негативные или выражение удивления.
После того, как все было готово, разработчики решили сравнить, насколько хорошо люди справляются с задачей выявления и идентификации микроэмоций. После проведения ряда тестов разработчики убедились, что машины справляются с этим лучше, чем люди. Речь идет о превосходстве компьютеров как в выявлении микроэмоций, так и в их идентификации.
Где можно применить разработку? Здесь как раз особых вопросов нет — технология может использоваться в качестве детектора лжи, в правоохранительных органах, психотерапии, собеседованиях. Если уже фантазировать, то можно представить себе работу с таким алгоритмом, используя гаджет типа Google Glass.

Современные «устройства ввода» — именно так называются компьютерная клавиатура, мышь, джойстик — прочно вошли в нашу жизнь и даже стали для многих пользователей компьютеров вторыми «руками». Действительно, управление мышью тривиальное, возможность печатать «вслепую», то есть глядя на экран, а не на клавиатуру, доводит почти до автоматизма обращение к компьютеру.
Однако тактильный, осязательный метод передачи информации, в принципе, не свойственен Homo Sapiens: в докомпьютерную эру люди использовали для этого взгляд, голос, частично жесты.
Ученые полагают, что общение с «компьютерами будущего» станет возможным именно при помощи традиционных человеческих «средств связи».
Лиджун Инь, профессор Бингемтонского университета и директор Лаборатории компьютерной графики и обработки изображений, занимается обучением компьютеров человеческому языку.
Инь и его коллеги разработали метод передачи информации от компьютера к человеку посредством взглядов, жестов или речи.

Чтобы машина могла воспринимать информацию, была разработана специальная технология «компьютерного зрения» — простая веб-камера становилась для компьютера человеческим глазом, отчасти обладая способностью интерпретировать объекты и явления реального мира и «понимать» желания пользователя.
«Наши исследования в области компьютерной графики и компьютерного зрения нацелены на то, чтобы сделать использование компьютеров проще. В идеале с компьютером можно взаимодействовать в формате «дружеской беседы». Такие машины смогут использовать и люди с ограниченными возможностями», — считает профессор Инь.
Разработка специального математического аппарата для анализа данных, получаемых веб-камерой, отчасти позволила компьютерам «видеть».
Один из аспирантов из лаборатории Иня сделал перед экспертами Военно-воздушных сил США презентацию с использованием Microsoft Power Point, управляя программой с помощью взгляда.

Из оборудования в его распоряжении были только ноутбук и веб-камера, и этого было достаточно, чтоб взглядом сообщить компьютеру, какой участок слайда в презентации нужно подчеркнуть или выделить.
Следующая стадия сверхточной обработки изображения с веб-камеры — научить компьютер оценивать настроение и психологическое состояние хозяина. Для облегчения задачи исследователи разбили всю гамму эмоций на шесть базовых состояний:
злость, отвращение, страх, радость, грусть и удивление;
и начали экспериментировать с автоматическим распознаванием этих эмоций. Они изучают важность анализа состояния отдельных частей лица — глаз, рта, лба — для выражения эмоций, а также оценивают точность оценки, если лицо видно лишь частично, например, в профиль.
«Компьютеры понимают только нули и единицы, вся задача стоит в путях кодировки»,

Компьютерное распознавание эмоций может оказать существенную помощь людям, которые лишены способностей либо понять их, либо, наоборот, выразить свое собственное состояние. Например, люди, страдающие аутизмом, часто не могут правильно интерпретировать эмоции окружающих, поэтому испытывают трудности в общении. Компьютер смог бы «переводить» для них внешний мир. Маленькие дети, наоборот, еще не обладают достаточным речевым аппаратом, чтобы передать свои собственные эмоции. Так, взрослый человек может пойти к врачу, если испытывает боль, а также точно указать ее место и характер. Младенцы способны лишь плакать, испытывая дискомфорт. Дать более точные данные они не могут, меж тем плач сам по себе не всегда означает боль. Анализ мимики с помощью компьютерной программы, возможно, поможет отличить, действительно больного ребенка от просто капризничающего или уставшего.
Как научить компьютер узнавать знакомых и незнакомых
У каждого человека есть свои вокальные характеристики — темп, громкость и интонация голоса,— обусловленные индивидуальной структурой его голосового аппарата. Прислушиваясь к разговору, человек может на уровне подсознания идентифицировать голоса. Но можно ли научить этому компьютер?

Фото: Юрий Мартьянов, Коммерсантъ / купить фото
Фото: Юрий Мартьянов, Коммерсантъ / купить фото
При разработке алгоритма идентификации личности по голосу решаются две подзадачи: распознавание говорящего и проверка. Распознавая говорящего человека, компьютер сравнивает образец речи с шаблоном из базы данных и ищет соответствия.
Сами системы распознавания могут быть разделены на текстозависимые и текстонезависимые: известен ли системе текст, который должен быть произнесен пользователем, и использует ли система данную информацию. При текстозависимом распознавании могут использоваться как фиксированные фразы, так и фразы, сгенерированные системой и предложенные пользователю. Текстонезависимые системы предназначены обрабатывать произвольную речь.
Сейчас используются несколько алгоритмов создания таких систем.
Например, алгоритм динамического преобразования времени (Dynamic Time Warping) используется для текстозависимых систем. Этот алгоритм используется для распознавания речи в том случае, когда два разных человека произнесли какую-либо одну фразу и надо узнать, кто именно. Для этого компьютер сравнивает две «карты» голоса, отображенные на синусоидных графиках (рис. 1, а). Для сравнения достаточно всего два-три слова.
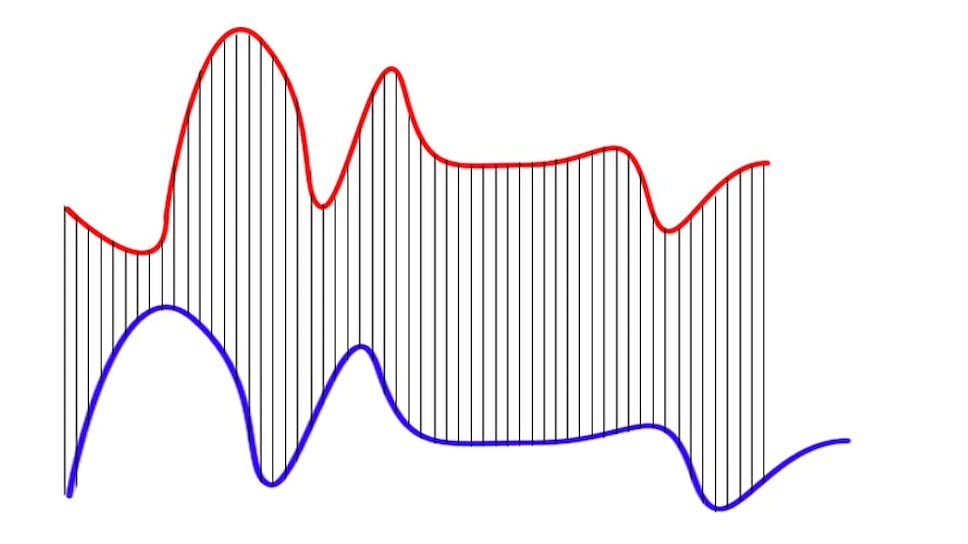
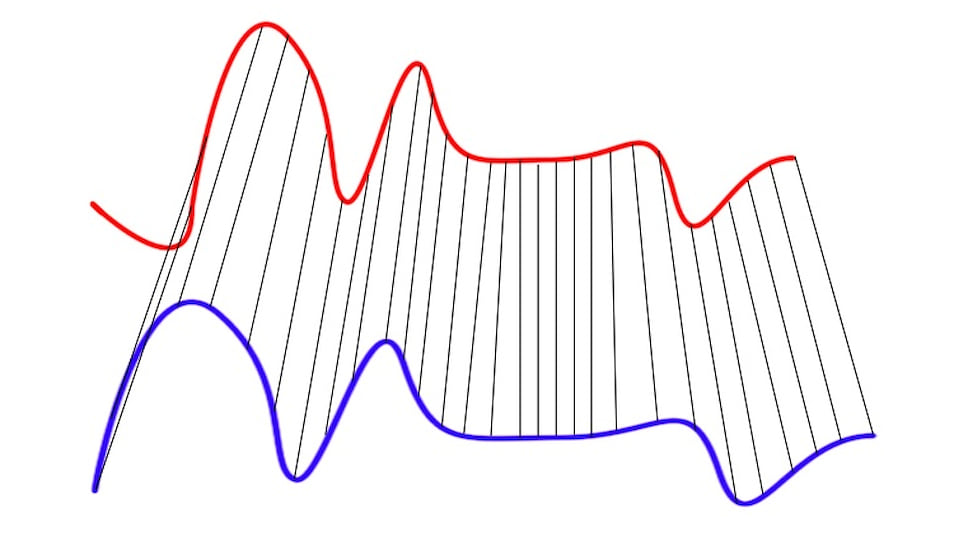
Но бывает так, что эти графики у людей очень похожи. Чтобы сравнить такие голоса, компьютер будет «деформировать» ось времени одного или обоих графиков, чтобы достигнуть лучшего выравнивания (рис. 1, б). Ошибки возникают из-за того, что сравниваемые последовательности имеют разную длину и точка одного ряда будет расположена немного выше или немного ниже соответствующей точки в другом ряду. Поэтому алгоритму трудно найти видимое выравнивание двух строк. Тем не менее он хорошо справляется с распознаванием отдельных слов в ограниченном словаре. Это простой и открытый для улучшения алгоритм, подходящий для приложений в телефонах, автомобильных компьютерах или системах безопасности.
Другой алгоритм — метод опорных векторов, или SVM (от англ. Support Vector Machines), удобно применять, когда требуется идентифицировать каждого человека в большой группе говорящих людей. Этот алгоритм создает линию или гиперплоскость, которая делит данные на классы. Как в детской задаче, где надо одной линией разделить красные и синие кружочки, алгоритм должен найти наиболее правильную линию (рис. 2). Но таких линий может быть очень много. Как же алгоритм находит «ту самую»? Компьютер ищет такие точки на графике, которые расположены ближе всего к линии разделения. Эти точки называются опорными векторами. Затем алгоритм вычисляет расстояние между опорными векторами и разделяющей плоскостью. Основная цель алгоритма — найти такое место, где это расстояние будет максимально большим. Алгоритм может работать и с трехмерной моделью.
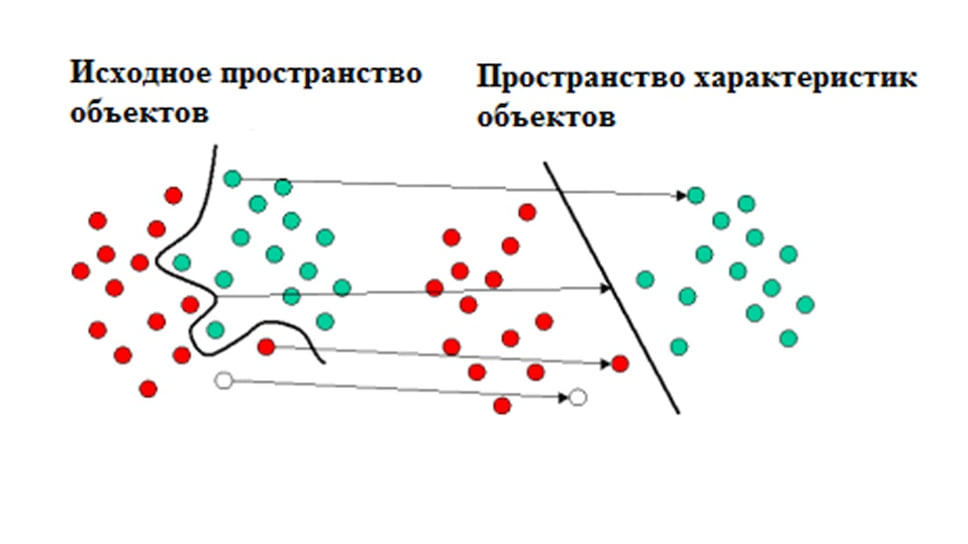
Это позволяет использовать его в анализе и классификации больших объемов данных или разрозненных данных из разных источников. Алгоритм может быть использован для выявления закономерностей в данных и создания структуры, которая потом используется для классификации. Для этого нужно ввести набор входных данных и соответствующих им выходных данных, которые используются для анализа и извлечения паттерна. При этом нам не нужно понимать поведение данных, алгоритм сам будет наблюдать за данными и связями внутри них. Кроме того, этот алгоритм хорошо умеет фильтровать шумы и ошибки данных, что часто нужно при распознавании голоса.
Оба этих алгоритма используются в современных устройствах — телефонах, роботах, системе «умный дом», компьютерах и автомобилях. И алгоритм динамического преобразования временной шкалы, и метод опорных векторов могут помочь организовать регламентированный доступ пользователей по заданной парольной фразе к ресурсам предприятия, телефонным и интернет-сервисам. Эти технологии могут упростить процесс идентификации пользователя без ущерба для информационной безопасности устройства.
Системы могут и будут улучшаться. Сегодня ученые пробуют дополнить алгоритмы языковыми моделями, которые будут описывать структуру языка — например, последовательность слов. Применение нейронных связей — это еще один этап. При этом каждое новое распознавание будет улучшать каждое новое распознавание в будущем. Таким образом, система станет самообучаемой.

Когда-то для подделки лиц на фотографиях требовались высокий уровень мастерства и таланта, а также большое количество времени. Но более 15 лет назад у человечества появился такой инструмент, как Photoshop и изготовить фальшивку из исходника стало значительно проще. Казалось, что провернуть подобную махинацию на видео невозможно, но команда инженеров из США и Германии разработала программу «замены лиц» Face2Face, которая позволяет в режиме реального времени менять мимику и речь выступающего на желаемую.
Как заверяют разработчики, для мистификации требуется актёр (или кто-то иной), мимика которого будет накладываться на лицо "жертвы", стандартная RGB-камера, компьютер с процессором не хуже Intel Core i7 и видеокартой Nvidia GTX980. С помощью датчика глубины изображения программа создаёт по каждому участнику маску, в которой есть привязки к определённым мимическим точкам на лицах. После этого система на лету создаёт реалистичную видеоверсию лица и накладывает её поверх реального лица выступающего, при этом положение его головы в данный момент не играет роль. Возможности Face2Face можно оценить в прилагаемом видео, в нём разработчики воспользовались выступлениями известных мировых фигур (Джорджа Буша, Владимира Путина, Дональда Трампа и Барака Обама).
Данная технология не доступна за пределами исследовательской лаборатории, но только пока. Как видно из видеоролика, местами наложение выдаёт себя искусственной и "натянутой" мимикой. Программа находится на доработке, но создатели надеются на её коммерциализацию в недалёком будущем. Face2Face может найти применение при создании фильмов и реалистичных компьютерных игр, при дубляже видео на разные языки и так далее. Хотелось бы верить, что до политических подделок и профанаций дело не дойдёт.


Изобретатель из Одинцова создал робота‐психолога
В Саратовском государственном техническом университете имени Гагарина Ю.А. разработали приложение для ПК, которое может уловить психоэмоциональное состояние человека за 10 секунд. В программу внесено 20 психотипов, которые оцениваются по шести показателям: темп, мелодика, громкость, интонационная составляющая, паузы и модуляция голоса. Алгоритм понимает эмоции радости, тревоги, возбуждения, скуки и многие другие.
По словам специалистов СГТУ, программа анализирует физические характеристики звукового сигнала как в режиме реального времени, так и в записи. После получения данных алгоритм сравнивает контрольные показатели речи с параметрами из базы и выдает свое заключение о состоянии говорящего и о том, какие эмоции он сейчас испытывает.

Вслед за Китаем: российские банки научатся узнавать клиента в лицо и читать мимику
Работа нового алгоритма базируется на данных о характере речи, полученных в СГМУ им. В. И. Разумовского, по сферической модели эмоций, разработанной в МГУ. Программа оценивает только звук и его характерные особенности — сами слова и их значение не учитываются в приложении.
На данный момент специалисты готовят свое решение к масштабным тестированиям. Это поможет понять плюсы и минусы использования разработки СГТУ, а также оценить ее эффективность.
Ученые давно работают над задачей распознавания программами и «умными» устройствами не просто речи, но и ее психоэмоциональной окраски. Ценность данной способности в том, что с ее помощью алгоритмы помогут персонализировать использование гаджетов. Кроме того, подобные интеллектуальные системы имеют большое значение для помощи специалистам в ведении переговоров, оказании психологической помощи, собеседованиях, на судебных процессах и в других сферах.
Ранее решения по пониманию компьютером эмоций говорящего уже представили в Microsoft с онлайн-сервисом Text Analytics API, который определяет тональность, ключевые фразы, темы и язык текста; в Amazon, запатентовавшей нейросеть, определяющую самочувствие по голосу; в Плимутском университете, где робота NAO научили понимать эмоции детей с аутизмом; в Neurodata Lab, которая дала российскому сервисному роботу Promobot возможность сопереживать; а также в ВШЭ, где алгоритм научили в 70% случаев правильно распознавать эмоциональный окрас речи.
Читайте также:
- 2 что может видеть commview которая инсталлирована на компьютер с локальной сетью
- Как выглядит текстовый файл на компьютере
- Wi fi адаптер tp link tl wn781nd установка
- Подготовьте к изданию рукописные или компьютерные иллюстрированные сборники загадки народов мира
- Vmware virtual disk scsi disk device что это