
Ndf sql server что за файл
Обновлено: 03.07.2024
Файлы и файловые группы
На физическом уровне база данных в Microsoft SQL Server 2008 представляется набором файлов операционной системы. Данные и сведения журналов транзакций всегда размещаются в разных файлах. Отдельные файлы используются только одной базой данных. Файловые группы представляют собой именованные коллекции файлов и используются для упрощения размещения данных и выполнения задач администрирования, например резервного копирования и восстановления.
Базы данных SQL Server содержат файлы трех типов:
Первичный файл данных является отправной точкой базы данных. Он указывает на остальные файлы базы данных. В каждой базе данных имеется один первичный файл данных. Для имени первичного файла данных рекомендуется использовать расширение MDF.
Ко вторичным файлам данных относятся все файлы данных, за исключением первичного файла данных. Базы данных могут вообще не содержать вторичных файлов данных, или содержать один или несколько вторичных файлов данных. Для имени вторичного файла данных рекомендуется использовать расширение NDF.
Файлы журналов содержат все сведения журналов, используемые для восстановления базы данных. В каждой базе данных должен быть по меньшей мере один файл журнала, но их может быть и больше. Для имен файлов журналов рекомендуется использовать расширение MDF, NDF и LDF. Однако эти расширения помогают пользователю идентифицировать различные виды файлов и правильно их использовать.
В SQL Server расположение всех файлов базы данных записывается в первичный файл базы данных и в специальную служебную структуру СУБД SQL Server, называемую базой данных master. В большинстве случаев при работе с базой данных компонент СУБД (SQL Server Database Engine ) использует сведения о размещении файлов, хранимые в базе данных master. Однако в некоторых случаях (например, при восстановлении базы данных master из копии, при определенным образом проводимом присоединении базы данных) компонент Database Engine использует сведения о расположении файлов из первичного файла, чтобы инициализировать записи о расположении файлов в базе данных master.
Файлы SQL Server имеют два имени:
- logical_file_name — имя, используемое для ссылки на физический файл во всех инструкциях Transact-SQL. Логическое имя файла должно соответствовать правилам для идентификаторов SQL Server и быть уникальным среди логических имен файлов в соответствующей базе данных.
- os_file_name — это имя физического файла, включая путь к каталогу. Оно должно соответствовать правилам для имен файлов операционной системы.
Изначально можно указать максимальный размер каждого файла. Если максимальный размер файла не указан, файлы SQL Server могут автоматически увеличиваться в размерах, превосходя первоначально заданные показатели, пока не займут все доступное место на диске. При определении файла пользователь может указывать требуемый шаг роста. Каждый раз при заполнении файла его размер увеличивается на указанный шаг роста. Если в файловой группе имеется несколько файлов, их автоматический рост начинается лишь по заполнении всех файлов. Затем файлы увеличиваются в размерах по кольцевому списку. Эта функция особенно полезна в случаях, когда SQL Server используется в качестве базы данных, внедренной в приложение, где пользователь не имеет удобного доступа к системному администратору. По мере необходимости пользователь может предоставить файлам возможность увеличиваться в размерах автоматически, тем самым снимая с администратора часть забот по наблюдению за свободным пространством базы данных и по распределению дополнительного пространства вручную.
Из объектов баз данных и файлов можно формировать файловые группы, используемые для решения задач распределения и административного управления. Файлы журналов не могут входить в состав файловых групп. Управление пространством журнала отделено от управления пространством данных. Файл не может входить в состав нескольких файловых групп. Таблицы, индексы и данные больших объектов могут быть ассоциированы с указанной файловой группой. В этом случае все их страницы будут размещены внутри файловой группы; либо таблицы и индексы могут быть секционированы. Данные секционированных таблиц и индексов разделяются на блоки, каждый из которых может быть помещен в отдельную файловую группу базы данных. В каждой базе данных одна файловая группа назначается файловой группой по умолчанию. Если при создании таблицы или индекса файловая группа не указывается, предполагается, что все страницы будут распределяться из файловой группы по умолчанию. В каждый момент времени лишь одна файловая группа может быть файловой группой по умолчанию.
Основной единицей хранилища данных и обмена информацией между внешней и оперативной памятью в SQL Server является страница. Место на диске, предоставляемое для размещения файла данных (MDF- или NDF-файл) в базе данных, логически разделяется на страницы с непрерывным перечислением от 0 до n. Дисковые операции ввода-вывода выполняются на уровне страницы. А именно, SQL Server считывает или записывает целые страницы данных. В SQL Server размер страницы составляет 8 КБ. Это значит, что в одном мегабайте базы данных SQL Server содержится 128 страниц. Каждая страница начинается с 96-байтового заголовка, который используется для хранения системных данных о странице. Эти данные включают номер страницы, тип страницы, объем свободного места на странице и идентификатор единицы распределения объекта, которому принадлежит страница. В файлах данных базы данных SQL Server используется 8 типов страниц (данные с типами данных небольших размеров, данные с типами данных больших размеров, записи индекса, сведения о размещении экстентов, сведения о размещении страниц и доступном на них свободном месте и т. д.).
Для эффективного управления памятью страницы объединяются в экстенты , которые являются основными единицами организации пространства.
Экстент — это коллекция, состоящая из восьми физически непрерывных страниц или 64 Кб; они используются для эффективного управления страницами. Все страницы хранятся в экстентах. Таким образом, в одном мегабайте базы данных SQL Server содержится 16 экстентов.
Чтобы сделать распределение места эффективным, SQL Server не выделяет целые экстенты для таблиц с небольшим объемом данных. SQL Server имеет два типа экстентов:
- Однородные экстенты принадлежат одному объекту (определенной таблице, индексу и т. д.); все восемь страниц могут быть использованы только этим владеющим объектом.
- Смешанные экстенты могут находиться в общем пользовании у не более восьми объектов. Каждая из восьми страниц в экстенте может находиться во владении разных объектов.
Новая таблица или индекс — это обычно страницы, выделенные из смешанных экстентов. При увеличении размера таблицы или индекса до восьми страниц эти таблица или индекс переходят на использование однородных экстентов для последовательных единиц распределения. При создании индекса для существующей таблицы, в которой содержится достаточно строк, чтобы сформировать восемь страниц в индексе, все единицы распределения для индекса находятся в однородных экстентах. Пример размещения объектов в смешанном и однородном экстентах приводится на рис. 10.2.
Рис. 10.2. Размещение объектов в смешанном и однородном экстентах
Рис. 10.3. Пример нумерации страниц файлов базы данных
SQL Server использует MDF для файлов данных и LDF для файлов журналов, но что такое файлы NDF?
в чем преимущества этих файлов?
с архитектура файлов и файловых групп
вторичные файлы данных
вторичные файлы данных составляют все файлы данных, кроме первичного файла данных. Некоторые базы данных могут не иметь дополнительных файлов данных, в то время как другие имеют несколько дополнительных файлов данных. рекомендуемое расширение имени файла для вторичных файлов данных .НДФЛ.
и с расширение файла NDF-Microsoft SQL Server secondary файл данных
посмотреть понимание файлов и файловых групп
дополнительные файлы данных являются необязательными, определяемые пользователем, и сохранять пользовательские данные. Вторичные файлы могут быть использованы для распространения данные на несколько дисков, каждый файл на другом диске. Кроме того, если база данных превышает максимальный размер для одного окна файл, вы можете использовать вторичные файлы данных таким образом, база данных может продолжать расти.
в рекомендуемое расширение имени файла для вторичных файлов данных .НДФЛ.
например, три файла, Data1.ndf, Данных2.ndf, и Data3.НДФ, может быть создано на трех дисках, соответственно, и присваивается файловая fgroup1. Таблица может тогда быть создан специально для файловой группы fgroup1. Запросы на получение данных из стол будет разбросан по всей тройке диски; это позволит повысить производительность. Такое же улучшение производительности мочь быть выполнено с помощью одного файла созданный на RAID (избыточный массив независимые диски) набор полосок. Однако, файлы и файловые группы позволяют легко добавлять новые файлы на новые диски.
вторичные файлы данных являются необязательными, определяются пользователем и хранят пользовательские данные. Вторичные файлы можно использовать для распространения данных по нескольким дискам, помещая каждый файл на другой диск. Кроме того, если база данных превышает максимальный размер для одного файла Windows, можно использовать вторичные файлы данных, чтобы база данных могла продолжать расти.
рекомендуемое имя файла расширение для вторичных файлов данных .ndf , но это не является обязательным.
файл NDF-это определяемый пользователем файл базы данных-получателя Microsoft SQL Server с расширением .ndf, которые хранят пользовательские данные. Кроме того, когда размер файла базы данных растет автоматически от его указанного размера, вы можете использовать .файл ndf для дополнительного хранения и т. д.файл ndf может храниться на отдельном диске. Каждый файл NDF использует то же имя файла, что и соответствующий файл MDF. Мы не можем открыть .файл ndf в SQL Server без прикрепления его связанного .файл МДФ.
Логическая структура хранения SQL Server - это группа файлов, экстент и страница данных.
SQL Server отображает базу данных как набор файлов операционной системы. Данные и информация журнала никогда не смешиваются в одном файле, иФайл используется только одной базой данных, Файловая группа - это именованная коллекция файлов, используемая для упрощения задач хранения и управления данными (например, операций резервного копирования и восстановления).
Файл базы данных
Базы данных SQL Server имеют три типа файлов:
- Файл основных данных
Основной файл данных является отправной точкой базы данных. Помимо системы хранения и пользовательских данных, в файле основных данных также хранится такая информация, как путь, имя и размер всех файлов вспомогательных данных в базе данных и файл журнала повторов. SQL Server получает информацию о других файлах данных и восстанавливает файлы журналов, читая основной файл данных. Эта функция аналогична управляющему файлу Oracle. Каждая база данных имеет файл основных данных. Рекомендуемое расширение файла для файла основных данных .mdf. - Вторичный файл данных
Все остальные файлы данных, кроме основного файла данных, являются вторичными файлами данных, которые обычно хранят только пользовательские данные. Некоторые базы данных могут не содержать никаких вторичных файлов данных, в то время как некоторые базы данных содержат несколько вторичных файлов данных. Рекомендуемое расширение файла для вторичных файлов данных .ndf. - Лог-файл
Файл журнала содержит всю информацию журнала, используемую для восстановления базы данных. В каждой базе данных должен быть хотя бы один файл журнала, разумеется, их может быть несколько. Рекомендуемое расширение файла для файлов журнала .ldf.
SQL Server не требует использования расширений файлов .mdf, .ndf и .ldf, но их использование может помочь идентифицировать различные типы и использование файлов.
В SQL Server местоположения всех файлов в базе данных записываются в главном файле и главной базе данных базы данных. В большинстве случаев ядро базы данных SQL Server использует информацию о расположении файлов в базе данных master. Однако в следующих случаях ядро базы данных использует информацию о расположении файла главного файла для инициализации элемента местоположения файла в главной базе данных:
- При использовании оператора CREATE DATABASE с опцией FOR ATTACH или FOR ATTACH_REBUILD_LOG для присоединения базы данных.
- При обновлении с SQL Server 2000 или 7.0.
- При восстановлении основной базы данных.
Группа файлов базы данных
Для облегчения распространения и управления объекты базы данных и файлы могут быть разделены на группы файлов вместе. Файловая группа SQL Server состоит из несколькихДата файлысочинение.
Файловая группа SQL Server - это основная файловая группа и пользовательская файловая группа, которые соответствуют системному табличному пространству и пользовательскому табличному пространству в базе данных Oracle соответственно.
- основная группа файлов
Основная группа файлов содержит основной файл данных и любые другие файлы, которые явно не назначены другим группам файлов. Все страницы системных таблиц размещены в основной файловой группе. Подобно системному табличному пространству базы данных Oracle, первичная файловая группа не может быть удалена, и ее имя первичное также является фиксированным и не может быть изменено. - Пользовательская группа файлов
Пользовательская файловая группа - это любая файловая группа, указанная с помощью ключевого слова FILEGROUP в операторе CREATE DATABASE или ALTER DATABASE.
Файлы журнала не входят в файловую группу. Пространство журнала управляется отдельно от пространства данных.
В базе данных SQL Server нет группы файлов, соответствующей временному табличному пространству Oracle. Многоверсионные данные (отмена) SQL Server и временные данные, сгенерированные с помощью операций сортировки или хеширования, хранятся в системе tempdb. В базе данных несколько баз данных совместно используют базу данных tempdb.
Файл не может быть членом нескольких групп файлов. Таблицы, индексы и данные больших объектов могут быть связаны с указанными группами файлов. В этом случае все их страницы будут выделены для группы файлов, или таблица и индекс будут разделены. Данные секционированных таблиц и индексов делятся на блоки, и каждый блок может быть помещен в отдельную файловую группу в базе данных.
В базе данных SQL Server запрещается удалять группу файлов, содержащую таблицу или индекс. Это отличается от Oracle. В Oracle, если табличное пространство содержит данные, когда табличное пространство удаляется с помощью отбрасывания табличного пространства , Вы можете добавить пункт включения содержимого.
Файловая группа в каждой базе данных назначается файловой группой по умолчанию. Если при создании таблицы или индекса файловая группа не указана, предполагается, что все страницы выделены из файловой группы по умолчанию. Только одна файловая группа может быть файловой группой по умолчанию одновременно. Если файловая группа по умолчанию не указана, основная файловая группа используется в качестве файловой группы по умолчанию. Члены предопределенной роли базы данных db_owner могут переключать файловую группу по умолчанию из одной файловой группы в другую.
Правила разработки для файлов и групп файлов
Следующие правила применяются к файлам и группам файлов:
- Файл или файловая группа не могут использоваться несколькими базами данных. Например, никакая другая база данных не может использовать файлы sales.mdf и sales.ndf, которые содержат данные и объекты в базе данных продаж.
- Файл может быть членом только одной группы файлов.
- Файлы журнала транзакций не могут принадлежать какой-либо файловой группе.
Площадь (протяженность)
Экстент - это единица, которая выделяет место для хранения таблицы или индекса, а также является основной единицей управления пространством.
В SQL Server размер экстента представляет собой фиксированные 8 последовательных страниц данных, 64 КБ, что означает, что в базе данных SQL Server имеется 16 областей на МБ. При создании файловой группы нельзя указывать размер экстента, аналогичный условиям автоматического выделения или единообразного размера в Oracle, поэтому SQL Server менее гибок.

SQL Server выделяет экстенты для таблиц не так, как в Oracle. Чтобы сделать выделение пространства эффективным, SQL Server не будет выделять все области таблицам, которые содержат небольшой объем данных, поэтому SQL Server не будет выделять экстенты для пустых таблиц, и выделение расширений будет отложено до тех пор, пока записи не будут добавлены в таблицу.
SQL Server имеет два типа зон:
- Смешанная область (смешанный экстент): смешанная область используется несколькими таблицами или индексами и может использоваться несколькими объектами. Каждая из восьми страниц в зоне может принадлежать другому объекту.
- Единая степень: Единая степень принадлежит одному объекту. Все 8 страниц в зоне могут быть предназначены только для одной таблицы или индекса.
Обычно первые 8 страниц данных, выделенных для таблицы или индекса, размещаются в смешанной зоне, а последующие страницы данных - в объединенной зоне. Этот метод отличается от Oracle. Зона Oracle может быть назначена только одной таблице или индексу. Несколько объектов не могут быть общими, или можно сказать, что Oracle имеет только один тип объединенной зоны в SQL Server.

Управление файловыми группами и файловыми группами SQL Server
- <add_or_modify_files> :: = </ add_or_modify_files>: укажите файлы, которые будут добавлены, удалены или изменены.
- имя_базы_данных: имя базы данных, которую нужно изменить.
- ДОБАВИТЬ ФАЙЛ: Добавить файл в базу данных.
- TO FILEGROUP : укажите группу файлов, в которую нужно добавить указанный файл.
- ADD LOG FILE: Добавьте файл журнала, который будет добавлен в указанную базу данных.
- УДАЛИТЬ ФАЙЛ логическое_файл_имя: удалите описание логического файла и удалите физический файл из экземпляра SQL Server. Если файл не пуст, файл не может быть удален.
- логическое_файл_имя: логическое имя, используемое при обращении к файлу в SQL Server.
- MODIFY FILE: укажите файл, который необходимо изменить. Если указан SIZE, новый размер должен быть больше текущего размера файла.
Чтобы изменить логическое имя файла данных или файла журнала, укажите имя логического файла для переименования в предложении NAME и укажите новое логическое имя файла в предложении NEWNAME. Например:
Чтобы переместить файлы данных или файлы журналов в новое место, укажите текущее логическое имя файла в предложении NAME и укажите новый путь и имя файла операционной системы (физическое) в предложении FILENAME. Например:
- os_file_name: для стандартных (ROWS) групп файлов это путь и имя файла, используемые операционной системой при создании файла.
- 'filestream_path': для группы файлов FILESTREAM FILENAME указывает путь, в котором будут храниться данные FILESTREAM.
- memory_optimized_data_path: Для групп файлов, оптимизированных для памяти, FILENAME будет указывать путь, где будут храниться данные, оптимизированные для памяти. Атрибуты SIZE, MAXSIZE и FILEGROWTH не применяются к оптимизированным для памяти группам файлов.
- FILEGROWTH: используется для указания размера каждого файла. Если определенное значение не указано, по умолчанию используется значение 1 МБ. Если указано значение 0, файл данных не может автоматически увеличиваться. В качестве единицы измерения можно использовать МБ, КБ, ГБ, ТБ или процент (%). Значение по умолчанию - МБ. Если указан%, то размер приращения - это определенный процент от размера файла при росте. Указанный размер округляется до ближайшего кратного 64 КБ.
- OFFLINE: отключить файл и сделать все объекты в группе файлов недоступными.
- <add_or_modify_filegroups> :: = </ add_or_modify_filegroups>: добавление, изменение или удаление файловых групп в базе данных.
- СОДЕРЖИТ FILESTREAM: указывает, что файловая группа хранит большие двоичные объекты FILESTREAM (BLOB) в файловой системе.
- CONTAINS MEMORY_OPTIMIZED_DATA: укажите группу файлов для хранения данных оптимизации памяти в файловой системе. В каждой базе данных может быть только одна группа файлов MEMORY_OPTIMIZED_DATA. При создании таблицы, оптимизированной для памяти, файловая группа не может быть пустой, и она должна содержать хотя бы один файл.
- REMOVE FILEGROUP filegroup_name: удалите файловую группу filegroup_name, чтобы удалить файловую группу из базы данных. Если файловая группа не пуста, ее нельзя удалить. Сначала удалите все файлы из группы файлов.
- MODIFY FILEGROUP filegroup_name: Изменить файловую группу.
- ПО УМОЛЧАНИЮ: Измените группу файлов базы данных по умолчанию на имя_группы файлов. В качестве файловой группы по умолчанию может быть только одна файловая группа в базе данных.
- AUTOGROW_SINGLE_FILE: Когда файлы в файловой группе соответствуют порогу автоматического роста, увеличивается только файл. Это значение по умолчанию.
- AUTOGROW_ALL_FILES: если файлы в файловой группе достигают порога автоматического роста, все файлы в файловой группе растут.
- <filegroup_updatability_option>: установить атрибуты только для чтения или чтения / записи для файловой группы.
- READ_ONLY | READONLY: указанная группа файлов доступна только для чтения. Объекты в нем не могут быть обновлены. Основная группа файлов не может быть установлена только для чтения. Чтобы изменить этот статус, вы должны иметь эксклюзивный доступ к базе данных.
- Поскольку базы данных только для чтения не позволяют изменять данные, произойдет следующее:
При запуске системы автоматическое восстановление будет пропущено.
Невозможно сжать базу данных.
не будет заблокирован в базе данных только для чтения. Это может ускорить запрос.
A. Добавить группу файлов, состоящую из двух файлов, в базу данных
В следующем примере создается группа файлов Test1FG1 в базе данных AdventureWorks2012, а затем добавляются два файла по 5 МБ в группу файлов.
Б. Добавьте два файла журнала в базу данных.
C. Удалить файлы из базы данных
D. Изменить файлы
Размер файла, добавленного в следующем примере. Команда ALTER DATABASE MODIFY FILE может увеличить размер файла, поэтому, если вам нужно уменьшить размер файла, вам нужно использовать DBCC SHRINKFILE.
В этом примере размер файла сжатых данных составляет 100 МБ, а затем укажите размер в этом размере.
E. переместить файл в новое место
Далее в качестве примера используется файл данных E: \ t1dat2.ndf в данных AdventureWorks в C: \ t1dat2.ndf, чтобы проиллюстрировать процесс перемещения файла данных.
Сначала переведите базу данных в автономный режим:
Переместите E: \ t1dat2.ndf в C: \ t1dat2.ndf в операционной системе:
Измените запись этого пути к файлу в базе данных:
Наконец, верните базу данных в оперативный режим:
Затем запросите физический путь к файлу t1dat2:
F. Сделать файловую группу файловой группой по умолчанию
В следующем примере Test1FG1 становится файловой группой по умолчанию. Затем группа файлов по умолчанию сбрасывается в группу файлов PRIMARY. Обратите внимание, что PRIMARY должен быть разделен скобками или кавычками.
Запрос информации назначенного экстента указанной таблицы
В SQL Server вы можете использовать команду dbcc exteninfo для запроса информации о выделенном экстенте таблицы.
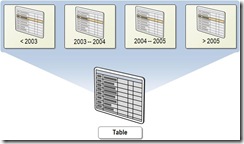
Секционирование (partitions) - один из основных инструментов для обеспечения оптимальной работы с большим объёмом данных за счёт горизонтального масштабирования. Повышается управляемость и производительность, как модификации данных, так и запросы на выборку.
Кроме того, можно повысить производительность, применяя блокировки на уровне секций, а не всей таблицы. Это может уменьшить количество конфликтов блокировок для таблицы.
Но не все обращают внимание на ещё одну уникальную возможность, которую предоставляет секционирование, а именно: обеспечение высокой доступности данных. Сокращает время восстановления после сбоев.

Для демонстрации создадим тестовую БД: Теперь к нашей новой БД добавим несколько файловых групп, каждая из которых будет состоять из одного вторичного файла данных (*.ndf): Теперь наша БД состоит из 13 файловых группы: первичной и 12 вторичных

Файлы:
Все эти подготовки были сделаны не случайно, теперь мы создадим функцию и схему секционирования. При этом мы будем секционировать нашу будущую "важную" таблицу с данными за 2012 год по месяцу. Каждая отдельная секция будет располагаться в своей выделенной файловой группе. Обратите ваше внимание, что все данные, которые будут с датой 2012 года расположатся в файловой группе primary.

Ну, а теперь создадим нашу наиважнейшую таблицу, которая будет содержать информацию о продажах за 2012 год. При этом к этим данным выдвигаются очень серьёзные бизнес-требования в плане доступности. В результате у нас таблица с 14 секциями, 12 из которых содержат данные. в нашем случаи по 10000 строк:
Т.к. у нас каждая секция хранится в отдельной файловой группе, то мы можем создавать резервные копии не только всей БД, но и отдельно для каждой файловой группы.
Следующим скриптом мы создадим 12 резервных копий файловых групп: Теперь сэмулируем аварию, для этого внесем изменения в одну из файловых групп через любой текстовый редактор. Но прежде необходимо отключить нашу БД (sp_detach_db) или остановить SQL Server, т.к. иначе файлы БД нельзя отредактировать. Теперь внесём изменения в один из файлов БД, например в файл C:\temp\fg7.ndf. В качестве редактора я использую Far Manager.

Теперь подключим нашу базу: После подключения БД, попытаемся считать данные из файловой группы, которую мы отредактировали. В результате мы получим ошибку:
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x95830087; actual: 0x959e8087). It occurred during a read of page (9:8) in database ID 5 at offset 0x00000000010000 in file 'C:\temp\fg7.ndf'. Additional messages in the SQL Server error log or system event log may provide more detail. This is a severe error condition that threatens database integrity and must be corrected immediately. Complete a full database consistency check (DBCC CHECKDB). This error can be caused by many factors; for more information, see SQL Server Books Online.

При этом данные из других файловых групп доступны для работы Т.е., не смотря на битые данные в одной из секций, мы продолжаем работать с остальными данными в обычном режиме. Теперь попытаемся восстановить нашу "битую" файловую группу в режиме ONLINE, т.е. без остановки работы с другими данными.
Начинаем всё с переключения нашей ФГ (файловой группы) в режим OFFLINE Теперь посмотрим статусы файловых групп:
Теперь, при обращении к нашей ФГ, мы получим уже другую ошибку One of the partitions of index '' for table 'dbo.sales'(partition ID 72057594039500800) resides on a filegroup ("FG7") that cannot be accessed because it is offline, restoring, or defunct. This may limit the query result.

Далее выполним само восстановление FG7
Статус нашей ФГ изменился с OFFLINE на RESTORING.

Но теперь мы проведём более серьёзный тест и удалим одну из файловых групп, но прежде сделаем новую резервную копию нашей файловой группы, которую будем удалять: Теперь остановим службу SQL Server, удалим файл C:\temp\fg7.ndf и вновь запустим службу SQL Server.

Обратимся за подробностями к логу

И так: наша база данных повреждена т.к. нет доступа к одному из файлов. Первым делом нужно вернуть БД в оперативный доступ. Для этого необходимо перевести в OFFLINE одну ФГ, файл которой "пропал", а всю базу перевести в ONLINE-режим.
Читайте также: