
Не хватает памяти screaming frog
Обновлено: 07.07.2024
Когда вы начнете работать в SEO, вы столкнетесь с мощными инструментами, которые помогут вам найти ценные данные. Важно уметь максимально эффективно пользоваться эти инструменты и ориентироваться в них.
Screaming Frog – это сканер веб-сайтов, который сканирует URL-адреса и возвращает ценные данные, которые мы можем проанализировать для аудита технического и локального SEO.
Как настроить ваше устройство для Screaming Frog и какие настройки необходимо выполнить для сканирования сайта и выполнения сканирования. Все это поможет вам добиться успеха в использовании собственного контрольного списка технического аудита и обеспечит получение данных, необходимых для проведения вашего первого аудита.
Настройка вашего устройства
Прежде чем вы начнете сканировать сайты, было бы полезно выделить больше оперативной памяти вашей системы для Screaming Frog, что обеспечит большую скорость и гибкость для всего будущего сканирования. Это будет необходимо для сканирования сайтов с более чем 150 тыс. URL.
Конфигурация > Система > Память

Значение по умолчанию для 32-разрядных компьютеров составляет 1 ГБ ОЗУ и 2 ГБ ОЗУ для 64-разрядных компьютеров.
Рекомендую использовать 8 ГБ, что позволяет Screaming Frog сканировать до 5 миллионов URL-адресов. Screaming Frog рекомендует использовать на 2 ГБ меньше общей оперативной памяти, но будьте осторожны, если вы выделите общую оперативную память, ваша система может столкнуться с ошибкой.

Когда вы закончите выделять больше оперативной памяти для Screaming Frog, вам нужно будет перезапустить программное обеспечение, чтобы изменения вступили в силу.

Конфигурации
Как только вы начнете сканировать сайты, важно соответствующим образом настроить свои конфигурации, чтобы убедиться, что Screaming Frog сканирует максимально эффективно.
Конфигурация > Spider > Basic

Это настройки по умолчанию, которые Screaming Frog имеет для каждого сканирования.

Вот основные настройки для проведения технического аудита:
- Отслеживать внутренний «nofollow»: позволяет нам сканировать внутренние ссылки с «атрибутами nofollow», чтобы проверить, реализует ли наш сайт этот тег для отображения контента, который мы делаем / не хотим обнаруживать или индексировать.
- Сканирование канонических файлов: позволяет сканировать элементы канонических ссылок, чтобы проверить, указываем ли мы, какие страницы мы хотим ранжировать.
- Crawl Next / Prev : позволяет сканировать элементы rel = ”next” и rel = ”prev”, чтобы дать нам представление о том, четко ли наш сайт отображает связь между страницами.
- Извлечь hreflang : отображает язык hreflang, коды регионов и URL, чтобы проверить, что мы сообщаем о различных вариантах нашего сайта.
- Сканирование связанных XML- файлов Sitemap : позволяет нам находить URL-адреса в XML- файлах Sitemap.
- Автоматическое обнаружение XML-файлов Sitemap с помощью robots.txt: позволяет нам находить карты сайта, обнаруживаемые с помощью robots.txt

Если вы имеете дело с сайтом, который использует JavaScript и хотите выполнить выборочную проверку внутренней навигации, вам нужно выполнить отдельный обход с разными конфигурациями для этой конкретной страницы, а не для всего домена. Перейдите на вкладку «рендеринг», чтобы наш сканер мог найти эти экземпляры.
Конфигурация > Spider > Рендеринг

После настройки паука нам всегда нужно устанавливать пользовательские фильтры для конкретных вещей, которые мы хотим показать в нашем сканировании.
Конфигурация > Пользовательский > Поиск

Эти фильтры, чтобы включать и исключать то, за чем следить, и чтобы все страницы учитывались:
- <embed: проверяет любой важный контент
- <iframe: проверяет любой контент, загруженный в iframe

Теперь, когда у вас настроены конфигурации для начального сканирования, вы можете сохранить эти конфигурации для будущих сканирований, чтобы вам не приходилось каждый раз проходить этот процесс. Просто загрузите необходимые конфигурации перед запуском каждого сканирования.
Файл > Конфигурация > Сохранить как

Файл > Конфигурация > Загрузить

Сканирование вашего первого сайта
Теперь, когда мы настроили нашу систему и выполнили настройки, нам осталось только начать сканирование нашего сайта.
Чтобы сканировать веб-сайт, вы захотите использовать режим «Spider» Screaming Frog по умолчанию. Это позволит нам сканировать сайт и собирать ссылки на основе созданных нами конфигураций и фильтров.

Введите URL > Нажмите Старт

В дополнение к режиму «Паук» также используют режим «Список», который будет сканировать список URL-адресов, которые могут быть взяты из файла или простого копирования и вставки.
Сегодня разберем настройки программы Screaming Frog SEO Spider.
Screaming Frog - краулер ( Crawler ), сканирующий URL-адреса сайта. SEO Spider помогает получить полезную информацию для проведения технического аудита.
1. Для работы программы требуется установка JAVA;
2. При сканировании используется оперативная память, поэтому при работе с большими сайтами потребуется увеличить объем памяти, которую выделяем для ПО. (В одной из следующих статей расскажу, как увеличить объем используемой памяти для Screaming Frog)
Настройка Screaming Frog :
Configuration
1. Basic
Заходим Configuration > Spider > Basic
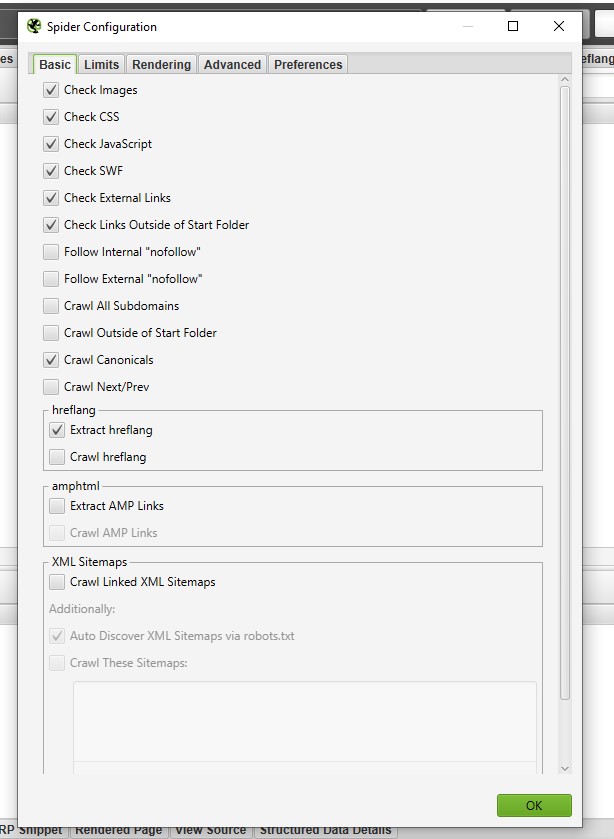
Во вкладке отмечаем файлы, которые будем сканировать: картинки, CSS, JS файлы, внешние ссылки и т.п.
Например, при нехватке оперативной памяти отключение сканирования изображений может помочь решить проблему.
Check Images - параметр, отвечающий за сканирование изображений
Check CSS - параметр, отвечающий за сканирование CSS.
Check JavaScript - параметр, отвечающий за сканирование JavaScript.
Check SWF - параметр, отвечающий за сканирование флеш-ссылки.
Check external links - параметр, отвечающий за сканирование внешних ссылок и/или ресурсов. Это могут быть изображения, CSS, JS, атрибуты hreflang и пр.
Check links outside of start folder - параметр предоставляет возможность обхода в начальной папке запуска, но все равно сканирует ссылки.
Follow internal or external «nofollow» - для сканирования ссылок в теге nofollow отметьте этот параметр.
Crawl all subdomains - для сканирования поддоменов поставьте флажок.
Crawl outside of start folder - по умолчанию SEO Spider будет сканировать только подпапку. Данная функция нужна для сканирования всего сайта при условии, что скнирование начинается с поддомена.
Crawl canonicals - параметр отвечает за сканирование canonical.
Crawl next / prev - параметр отвечает за сканирование rel = "next" и rel = "prev" параметров. Для сканирования таких страниц необходимо отметить параметр флажком.
2. Limits
Вкладка Limits отвечает за настройки лимитов на санирование URL.
Limit Crawl Total - число просканированных адресов.
Для сканирования сайта полностью рекомендую убирать данную настройку, если задать определенный лимит, то как краулер остановится достигнув заданного числа.
Limit Crawl Depth - параметр уровня вложенности сканирования.
Указав уровень вложенности 1, Screaming Frog выдаст все URL УВ от введенного документа.
Например, если указать главную страницу и в Limit Crawl Depth добавить значение 1 , то паук перейдет по всем ссылкам с главной страницы и остановится. При параметре со значением 0 будет проверен только указанный документ.
Статья пригодиться тем, чья работа не только стоит на потоке в плане сканирования проектов, но и при этом требует установить такие настройки, которые одинаково подойдут, как на средние проекты с количеством URL до 500 тыс., так и для небольших сайтов.
Начну с того, что в нашей компании, как и в любом более-менее крупном рекламном digital-агентстве, остро стоит вопрос оптимизации и автоматизации рутинных процессов, освобождая время для решения более важных стратегических задач.
Так вот: пройдя испытательный срок и проработав в агентстве примерно 2 месяца, взялся я за задачи ежемесячного сканирования по нескольким проектам. В seo я, в принципе, не новичок, но моя основная специализация – это аккаунт-менеджмент и маркетинг.
Время от времени, я как аккаунт-менеджер для собственных нужд по проекту и обсуждения деталей продвижения с клиентами провожу анализ выдачи их сайтов в выдаче в целом, в ТОП 10 поисковиков, но иной раз есть потребность в том, чтобы провести подробное сканирование сайта.
Сканирование проектов осуществляю, как и все на ПО Screaming Frog SEO Spider . Установил прогу, получил от руководства на нее лицензию и не трогал в ней ничего из настроек параметров сканирования (ибо все работало, а как известно не надо чинить то, что не сломалось).
Ну и шло все своим чередом, пока не попался мне в ведение проект довольно масштабный, особенно в рамках своей профессиональной деятельности.
Инструкция к screaming frog seo spider , естественно, более чем подробно дает понимание того, что и для чего настраивается, но конкретных рекомендаций по настройке не дает.
Далее я обратился к поиску на тему того как правильно использовать seo spider tool . Перечитав несколько статей, посвященных настройке программы, сделал вывод, что в них описано то же самое, что и в инструкции, но более кратко и попроще.
В итоге по своему вопросу решил я воспользоваться помощью наших опытных специалистов, которые (за что им действительно огромное спасибо) буквально на пальцах объясняли мне по каким принципам данное ПО работает и дали несколько очень дельных рекомендаций по настройке.
В итоге, после 3 дней путем проб, ошибок и консультаций с коллегами я пришел к следующему
Сегодня разберем настройки программы Screaming Frog SEO Spider.
Screaming Frog - краулер, сканирующий URL-адреса сайта. SEO Spider помогает получить полезную информацию для проведения технического аудита.
Особенности программы:
- Для работы программы требуется установка JAVA;
- При сканировании используется оперативная память, поэтому при работе с большими сайтами потребуется увеличить объем памяти, которую выделяем для ПО. (В одной из следующих статей расскажу, как увеличить объем используемой памяти для Screaming Frog)
Настройка Screaming Frog: Configuration
1. Базовые настройки (Basic)
Для перехода к базовым настройкам заходим Configuration > Spider > Basic:
Во вкладке отмечаем файлы, которые будем сканировать: картинки, CSS, JS файлы, внешние ссылки и т.п.
Например, при недостаточном объеме памяти необходимо отключить сканирование изображений.
Check Images — параметр, отвечающий за сканирование изображений
Check CSS — параметр, отвечающий за сканирование CSS.
Check JavaScript — параметр, отвечающий за сканирование JavaScript.
Check SWF — параметр, отвечающий за сканирование флеш-ссылки.
Check external links — параметр, отвечающий за сканирование внешних ссылок и/или ресурсов. Это могут быть изображения, CSS, JS, атрибуты hreflang и пр.
Check links outside of start folder — параметр предоставляет возможность обхода в начальной папке запуска, но все равно сканирует ссылки.
Follow internal or external «nofollow» — для сканирования ссылок в теге nofollow отметьте этот параметр.
Crawl all subdomains — для сканирования поддоменов поставьте флажок.
Crawl outside of start folder — по умолчанию SEO Spider будет сканировать только подпапку. Данная функция нужна для сканирования всего сайта при условии, что сканирование начинается с поддомена.
Crawl canonicals — параметр отвечает за сканирование canonical.
Crawl next / prev — параметр отвечает за сканирование rel = "next" и rel = "prev" параметров. Для сканирования таких страниц необходимо отметить параметр флажком.
2. Лимиты проверок (Limits)
Для перехода к настройкам лимитов сканирования заходим Configuration > Spider > Limits:
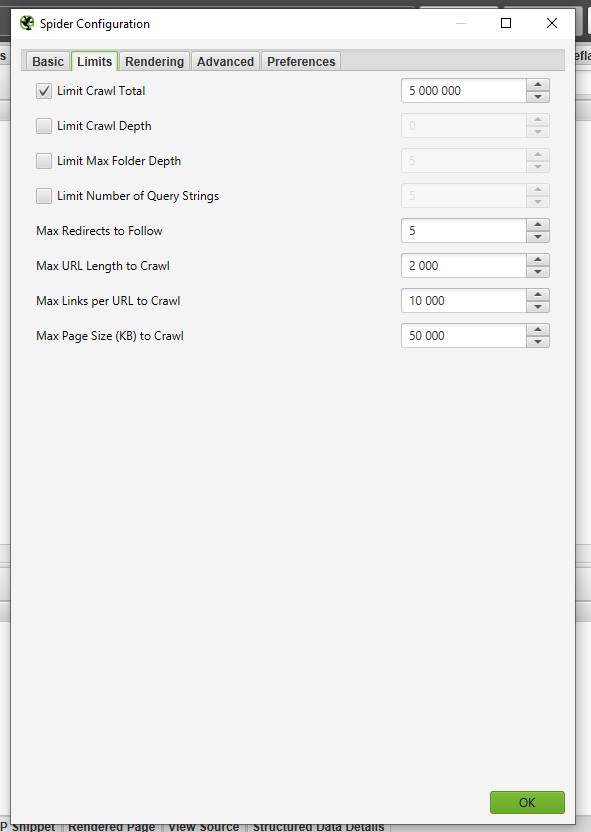
Вкладка Limits отвечает за настройки лимитов на санирование URL.
Limit Crawl Total - число просканированных адресов.
Для сканирования сайта полностью рекомендую убирать данную настройку, если задать определенный лимит, то как краулер остановится достигнув заданного числа.
Limit Crawl Depth - параметр уровня вложенности сканирования.
Указав уровень вложенности 1, Screaming Frog выдаст все URL УВ. от введенного документа.
Например, если указать главную страницу и в Limit Crawl Depth добавить значение 1 , то паук перейдет по всем ссылкам с главной страницы и остановится. При параметре со значением 0 будет проверен только указанный документ.
Limit Max Folder Depth - глубина сканирования по папкам.
3. Настройки рендеринга (Rendering)
Во вкладке Rendering настраиваем параметры сканирования JavaScript кода.
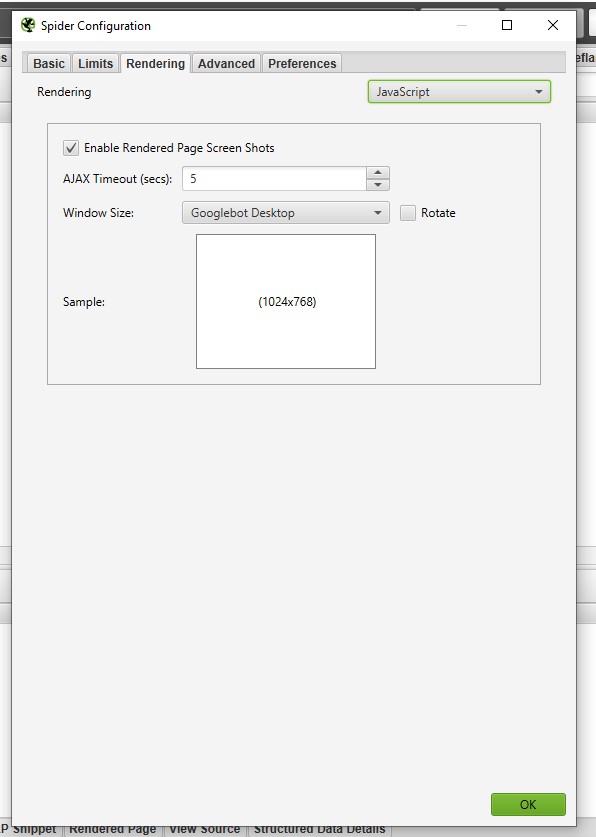
Для сканирования JS файлов выберите в настройках JavaScript.
Внимание: это увеличит время сканирования и требуемый объем оперативной памяти.
4. Расширенные настройки (Advanced)
Разберем расширенные настройки Паука.
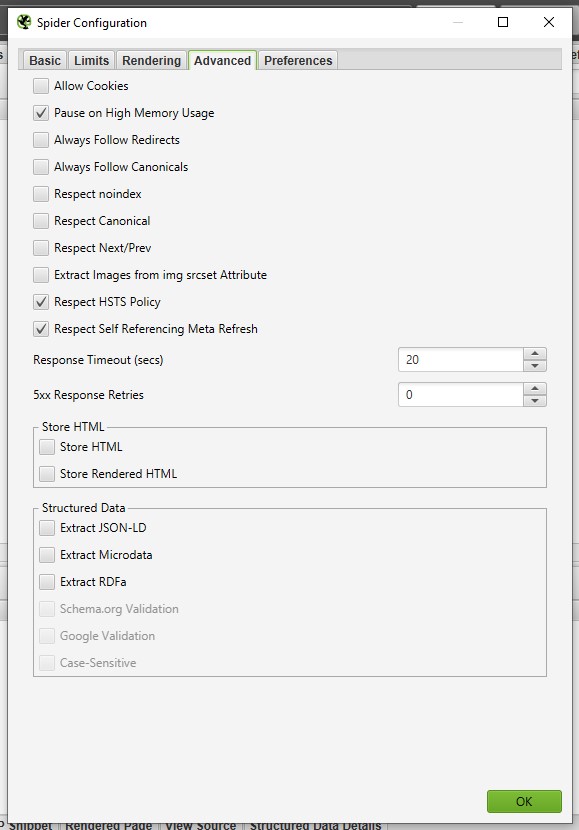
Pause on high memory usage
Always follow redirects
Эта функция указывает SEO-пауку переходить по редиректам до того момента, пока не попадет на страницу с кодом ответа 200 ОК.
Respect noindex
Этот параметр удаляет все URL-адреса с «noindex».
Respect canonical
Этот параметр удаляет все канонические страницы из отчета.
Respect Next/Prev
Этот параметр фиксирует URL-адреса с параметром rel = "prev", о которых не сообщается в SEO Spider.
Extract Images From img srcset Attribute
Если параметр включен, то будут извлекаться изображения из атрибута srcset тега <img>.
Response timeout
По умолчанию SEO Spider будет ждать 20 секунд, чтобы получить код ответа от URL-адреса. Вы можете увеличить продолжительность ожидания ответа от сайта. Увеличение времени пригодиться для очень медленных веб-сайтов.
5XX Response Retries
Этот параметр позволяет повторно проверять страницы, отдавшие 5XX код. Часто код 5ХХ может быть вызван перегрузкой сервера и повторное сканирование URL-адреса может дать ответ 2XX.
Max redirects to follow
Фиксируем максимальное число переадресаций, по которым будет переходить SEO Spider при 30Х коде ответа.
5. Персональные настройки (Preferences)
В данном блоке настроек задается диапазон размеров тегов, меты и заголовков h1, h2, которые будут считаться допустимыми.
Дополнительно на этой вкладке указывается максимально допустимый размер URL в символах, максимальный размер ALT у изображений и вес изображения.

На изображении представлены рекомендуемые настройки для тегов Title, Description, H1
Разобрав настройки паука (Configuration > Spider) переходим к следующим параметрам.
Настройка обработки файла robots.txt
Для определения параметров обработки robots заходим во вкладку Configuration > robots.txt > Settings
В данном окне всего 3 параметра:
1. Игнорирование файла robots.txt
Паук не будет сканировать сайт, если индексация запрещена в robots.txt. Эта опция позволяет игнорировать этот протокол.
2. Отображение внутренних URL, заблокированных в файле robots.txt
Внутренние URL заблокированные в robots.txt будут отображаться во вкладке " Internal " с кодом ответа "0"и статусом "Blocked by Robots.txt" заблокирован в файле robots.txt. Чтобы скрыть эти URL в интерфейсе, снимаем флажок.
3. Отображение внешних URL, заблокированных в файле robots.txt
Аналогично пункту 2, но только для внешних ссылок.
Опции Include/Exclude
Во вкладках Configuration > Include и Configuration > Exclude
Опции позволяют с помощью регулярных выражений указывать, какие URL сканировать либо исключать из анализа.
Чаще всего данные вкладки использую, когда проверить весь сайт полностью не получается из-за его размера. В этом случае проверку выполняем по разделам.
Скорость сканирования - Speed
Конфигурация Speed контролирует скорость сканирования SEO Spider.
Для настройки скорости сканирования переходим во вкладку Configuration > Speed.
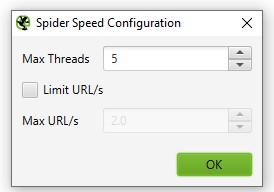
Max Threads - указываем число одновременных подключений. Чем больше значение, тем быстрее скорость сканирование. Обычно данный параметр оставляю не тронутым, а уменьшаю в том случае, если при сканировании сервер начинает отдавать 503 код.
Внимание, чем больше данный параметр, тем выше вероятность, того что сервер паук будет перегружать сервер и скорость ответа уменьшится.
Max URL - отвечает за число URL сканируемых за 1 секунду. Использую в редких случаях, когда сайт находится на слабом сервере.
User-agent
Вы можете настроить «User-Agent» в разделе « Configuration > User-Agent».
Screaming Frog имеет встроенные параметры агентов для Googlebot, Yandex, Googlebot-Mobile, и др. Дополнительно можете настраивать собственного пользовательского агента.
Данной настройкой пользуюсь при сравнении десктопной и мобильной версии сайта.
Custom > Search
Пользовательские настройки поиска, при помощи регулярных выражений, находят требуемые участки кода.
Читайте также: