
Нужен кэш и ничего не сможет его заменить
Обновлено: 05.07.2024
Когда вы открываете любые сайты, открытки, картинки, видео, их копии остаются в памяти браузера. Это происходит, даже если вы не скачиваете контент, а просто просматриваете. Как раз эти копии и называются кэшем. Он нужен для того, чтобы сократить количество запросов к сайтам. Например, через некоторое время вы вновь решите посмотреть страницу, которую открывали раньше. Кэш моментально загрузит ее с жесткого диска.
Кэширование работает практически во всех программах и приложениях. Некоторые данные очищаются автоматически, а другие копятся на жестком диске. Это создает дополнительную нагрузку на память устройства. Замедляется работа смартфона, ноутбука, компьютера. Интернет «зависает». Некоторые уверены: дело — в провайдере. Но даже если вы подключите самую высокую скорость (например, 1 Гб/с от МТС ), сайты все равно не будут грузиться быстрее, пока вы не очистите кэш.
Как чистить кэш, сколько раз в месяц это нужно делать
Самый простой способ очистить кэш — перезагрузить устройство. Речь идет не только о компьютерах и смартфонах, но и о wi-fi роутерах, и его модель не имеет значения. Даже самые современные и мощные маршрутизаторы от Ростелеком или Билайн нуждаются в регулярной перезагрузке (примерно, раз в месяц).
Рассказываем, как чистить кэш на Android:
- Откройте настройки смартфона.
- Перейдите в раздел «Устройство».
- Выберите вкладку «память» или «хранилище» (в зависимости от модели смартфона).
- Кликните на «данные кэша» или «cache».
- Нажмите «Очистить» либо «clear cache».
- Подтвердите действие.
Как очистить кэш на iOS:
- Откройте настройки.
- Найдите вкладку браузера Safari.
- Нажмите на вкладку и выберите «Очистить историю и данные».
- Подтвердите действие.
Имейте в виду: вместе с кэшем в айфоне удалится вся история посещений.
Как очистить кэш на компьютере или ноутбуке
Кэш на компьютере обычно чистят через данные локального диска:
- Откройте системный диск (как правило это локальный диск C).
- Кликните по нему правой кнопкой мышки и выберите вкладку «Свойства».
- В разделе «Общие» есть пункт «Очистка диска». Нажмите на эту кнопку.
- Выберите «Очистить системные файлы». Поставьте галочки напротив основных разделов, где хранится кэш:
— временные файлы интернета;
— файлы для отчетов об ошибках;
- Нажмите «Ок» и дождитесь, пока система удалит ненужные данные.
Процесс может занять некоторое время.
Есть еще один вариант: очистить кэш не в самом устройстве, а в браузере. Зайдите в тот, которым обычно пользуетесь (Mozilla Firefox, Google Chrome, Opera). Нажмите в правом верхнем углу на три точки или три горизонтальные полоски (в разных браузерах разные значки). Откроются настройки. Найдите вкладку «История» и нажмите «Очистить». Хотите, чтобы некоторые сайты сохранились в памяти? Добавьте их в закладки (для этого зайдите на страницу и нажмите комбинацию клавиш Ctrl+D).
Если статья оказалась полезной, не забывайте ставить лайк. Подписывайтесь на наш канал и узнавайте еще больше полезного о домашнем и мобильном интернете.
[Вступление]
Эй! Cash, cash (ха), cash
Cash (cash, cash, cash)
Cash (cash), cash (cash)
Cash (cash), cash (cash)
Эй, тр-р-р, эй (ca-a-ash), эй!
[Припев]
Нужен cash, и ничего сейчас
Уже не сможет его заменить
Нужен cash, и ничего сейчас
Уже не сможет его заменить
Нужен cash, и ничего сейчас
Уже не сможет его заменить
Нужен cash, и ничего сейчас
Уже (э-э, ху, тр-р-р, да-а)
[Куплет]
Прежде чем его достать (а)
Хоботов целый каскад
Это конечно не звёзды (эй), м
Пристегнись и не ёрзай (ху-у)
Не раздувай свои ноздри, кореш
Не разгоняйся, вижу, ты гонишь
Вижу, ты гонишь по встречной
Ты берёшь много на плечи (тррр)
О, эти речи, лёгкие деньги из лавэ веер
Ты на измене, не ветки (ху-у) —
Ты не уверен
Скоро ты будешь сидеть на замене
Нужны схемы конкретней
Сажу мясо на вертел (ху-у)
Здесь важны коннекты
Хватит гулять в Интернете (ху-у)
Уральские пельмени (трр)
С юмором в этой манере (ху)
В этом самом моменте: жирные рифмы
Да, они в теле (м-м)
Медленно далеко едем (хоу!)
Будто совсем еле-еле (у!)
Едем забирать зелень (трррь)
Детка садись на колени, эй
[Припев]
Нужен cash, и ничего сейчас
Уже не сможет его заменить
Нужен cash, и ничего сейчас
Уже не сможет его заменить
Нужен cash, и ничего сейчас
Уже не сможет его заменить
Нужен cash, и ничего сейчас
Уже (не сможет его заменить)
Нужен cash (тррь), и ничего сейчас
Уже не сможет его заменить
Нужен cash, и ничего сейчас
Уже (не сможет его заменить)
Нужен cash, и ничего сейчас
Уже не сможет его заменить
Нужен cash, и ничего сейчас
Уже, трррь, не сможет его заменить
[Финал]
Не сможет его заменить
Не сможет его заменить (нет)
Не сможет его заменить (яу!)
Не сможет его заменить (дэ!)
Не сможет его заменить (эй)
Не сможет его заменить (тсс!)
Не сможет его заменить
Не сможет его заменить (ы, да!)
Наверное, все хотя бы раз задавались вопросом, а не пришла ли пора почистить кэш смартфона. Он не приходил в голову только тем, кто делает это на постоянной основе, исправно удаляя данные, которые накопила система и приложения. Зачем? Одни таким образом стараются просто держать свой аппарат в чистоте, другие искренне верят, что удаление кэша позволит повысить быстродействие системы, а третьи делают это просто потому, что так делают все. Я, как приверженец рационального подхода во всём, кэш не удаляю от слова совсем. Объясняю на пальцах, почему.

Кэш не вредит, а помогает. Так что не удаляйте его
Я совру, если скажу, что никогда не чистил кэш сам. Я хорошо помню те смутные времена, когда 4 и 8 ГБ памяти были нормой, а Android-смартфоны – даже флагманские – начинали тормозить сразу после того, как их доставали из коробки. Тогда чистка кэша казалось логичным и вполне эффективным способом по недопущению переполнения встроенного хранилища и замедления операционной системы. Поэтому категория приложений-клинеров, или, по-простому, чистильщиков, была в Google Play одной из самых популярных. Но сегодня в них нет никакого смысла.
Что такое кэш и зачем он нужен
Кэш – это небольшие объёмы ключевых данных, которые приложения, сайты и онлайн-сервисы сохраняют на устройстве для быстрого доступа при последующих запусках. Дело в том, что все современные программы устроены таким образом, что получение данных из кэша у них происходит быстрее, чем выборка исходных данных из удалённого источника. В этом смысле кэш является технологическим аналогом привычек, которые приложение изучает и запоминает, а потом выстраивает модель взаимодействия с вами, основываясь на этих привычках.
Подпишись на нас в "Google Новостях". Так удобнее следить за обновлениями сайта.
Многие думают, что файлы кэша как-то засоряют систему и заставляют смартфон работать медленнее, но это не так. Напротив, они позволяют ему работать быстрее, поскольку не вынуждают обрабатывать данные заново, а просто берут их из специального раздела хранилища. Браузеры сохраняют информацию о часто посещаемых ресурсах, чтобы тратить меньше времени на их загрузку при последующих обращениях. Удалите их и сайты начнут обрабатываться медленнее. То же самое касается и других приложений – от видеохостингов вроде YouTube и социальных сетей вроде «ВКонтакте» или Facebook.
Нужно ли удалять кэш на Android
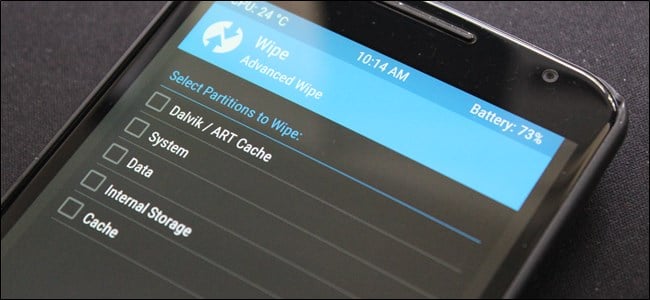
Из Android Nougat вообще пропал инструмент удаления системного кэша. Даже Google считает, что в этом нет смысла
Нет никакого смысла в том, чтобы удалять файлы кэша.
- Во-первых, потому что с ними все приложения и сервисы, которые установлены на вашем смартфоне, начинают работать быстрее.
- Во-вторых, потому что они занимают настолько мало места, что вы даже не заметите их.
- В-третьих, файлы кэша имеют свойство повторно накапливаться ровно в том виде, в котором они были изначально.
Google уже давно научила Android грамотно работать с файлами кэша – хоть с системными, хоть в приложениях. Серьёзный переворот в этой области случился в 2016 году, когда вышла Android 7.0 Nougat. Если до того момента в меню восстановления операционной системы была возможность сброса системного кэша, то после – он исчез. В результате вышло даже лучше, чем на iOS.
Почему приложения так много весят со временем
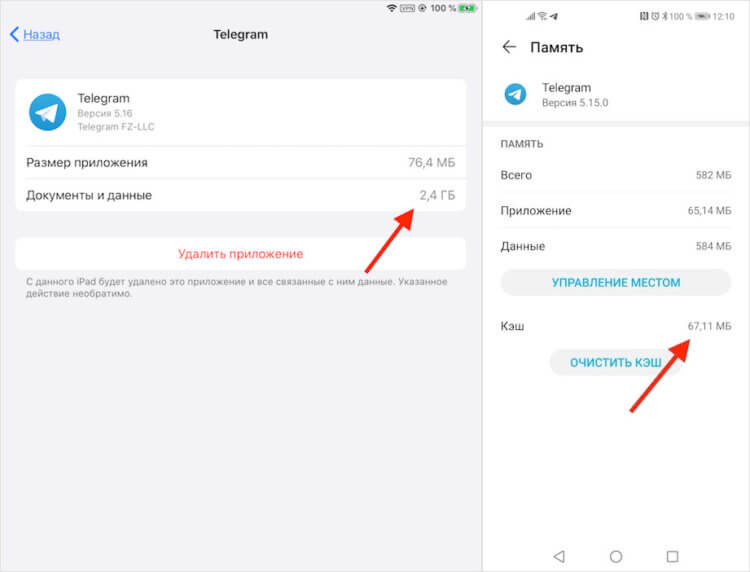
Посмотрите на Telegram на моём iPad. Чаще всего я пользуюсь мессенджером именно на Android-смартфоне, где файлы кэша занимают меньше 70 МБ, тогда как на планшете с iOS их больше по объёму примерно в 30 раз. Всё дело в том, что iOS кэширует почти всю информацию, которую получает. Из-за этого фотографии, видеозаписи и другие медиавложения проходят через память устройства и остаются там. Это не плохо, просто эта такая особенность системы. Android ведёт себя более рационально, загружая только ключевые данные, но не скачивает все файлы без разбора.
Я уже несколько лет не удаляю кэш и прекрасно себя чувствую. У меня не было проблем ни со старым LG G3, ни с LeEco Le 2, ни с Galaxy A51, ни с Honor View 20. Да, я, как, наверное, и все, сталкивался с замедлением работоспособности старых смартфонов. Но тут не нужно искать второго дна и сваливать всю вину на кэш, который якобы тормозит систему. На самом деле ничего такого не происходит и, даже стерев весь кэш, вы не вернёте аппарату былое быстродействие, просто потому что он устарел и банально перестал тянуть все функциональные обновления, которые на него свалились. Поэтому не порите горячку.
Свободное общение и обсуждение материалов

Android-смартфоны устроены намного сложнее, чем нам кажется. Это производители сделали так, чтобы мы могли без особого труда пользоваться своими аппаратами. Для этого они создали удобный и понятный интерфейс, который позволяет нам обращаться к тем или иным компонентам Android, отдавать смартфону команды и реагировать на его предложения. В общем, ничего сложного. Однако, помимо рядовых пользователей, Android используют ещё и продвинутые, которых хлебом не корми, дай что-нибудь изменить, настроить или кастомизировать. Для них и существуют такие режимы, как FastBoot.

Что не так с Android? Да по большому счёту, в общем-то, всё так. И по части функциональности, и по части безопасности, и по части быстродействия. Единственная претензия, которую зачастую предъявляют операционной системе Google, состоит разве что в том, что она – не iOS. Нет, ну правда. Android почему-то всегда пытаются сопоставлять с мобильной платформой Apple, причём почему-то всегда не в её пользу. А, между тем, с точки зрения пользовательского опыта Android весьма и весьма хороша. Другое дело, когда о недостатках начинают говорить сами разработчики.

Вчера я впервые за много лет пересел на iPhone. О своём опыте использования этого смартфона я ещё расскажу, а пока сосредоточусь на первых шагах, которые мне предстояло сделать на iOS. Несмотря на то что я с 2011 года не изменяю iPad и использую Mac в качестве единственного компьютера, за которым я решаю рабочие и бытовые задачи, айфона у меня не было. Я предпочитал ему аппараты на Android, которые менял раз в 1,5-2 года и, в общем, горя не знал. Благо переход с Android на Android всегда был лёгким и непринуждённым. А вот каково это - перейти с Android на iOS?
К сожалению, при аварийном выключении телефона или аварийной перезагрузке временные файлы иногда могут не состыковаться с программой, их породившей и тогда программа формирует эти файлы заново. При этом старые, уже не нужные временные файлы так и остаются в памяти телефона, занимают в нем место, а то и ухудшают работу смартфона.
Просто так чистить кэш смысла особого нет, как, впрочем, и вреда от этого. Вообще все зависит от программы, некоторые без очистки кэша живут не долго, и их лучше просто не использовать.
Полный бред, все приложения зависают и за переполненного кеша. Объясняю:- Абсолютно все приложения обновляются минимум раз в месяц и старые параметры не соответствует требованиям параметрам после обновления. Как и на вашем сайте wp обновляется регулярно и после обнов функционал сайта не работает корректно. Совет горе писателю? Доступен WordPress 5.3.2! Пожалуйста, сообщите администратору сайта. И возьмите учебники и выучите мат.часть работы и функционал приложений.
Меня зовут Виктор Пряжников, я работаю в SRV-команде Badoo. Наша команда занимается разработкой и поддержкой внутреннего API для наших клиентов со стороны сервера, и кэширование данных — это то, с чем мы сталкиваемся каждый день.
Существует мнение, что в программировании есть только две по-настоящему сложные задачи: придумывание названий и инвалидация кэша. Я не буду спорить с тем, что инвалидация — это сложно, но мне кажется, что кэширование — довольно хитрая вещь даже без учёта инвалидации. Есть много вещей, о которых следует подумать, прежде чем начинать использовать кэш. В этой статье я попробую сформулировать некоторые проблемы, с которыми можно столкнуться при работе с кэшем в большой системе.

Я расскажу о проблемах разделения кэшируемых данных между серверами, параллельных обновлениях данных, «холодном старте» и работе системы со сбоями. Также я опишу возможные способы решения этих проблем и приведу ссылки на материалы, где эти темы освещены более подробно. Я не буду рассказывать, что такое кэш в принципе и касаться деталей реализации конкретных систем.
При работе я исхожу из того, что рассматриваемая система состоит из приложения, базы данных и кэша для данных. Вместо базы данных может использоваться любой другой источник (например, какой-то микросервис или внешний API).
Деление данных между кэширующими серверами
Если вы хотите использовать кэширование в достаточно большой системе, нужно позаботиться о том, чтобы можно было поделить кэшируемые данные между доступными серверами. Это необходимо по нескольким причинам:
- данных может быть очень много, и они физически не поместятся в память одного сервера;
- данные могут запрашиваться очень часто, и один сервер не в состоянии обработать все эти запросы;
- вы хотите сделать кэширование более надёжным. Если у вас только один кэширующий сервер, то при его падении вся система останется без кэша, что может резко увеличить нагрузку на базу данных.
Есть разные алгоритмы для реализации этого. Самый простой — вычисление номера сервера как остатка от целочисленного деления численного представления ключа (например, CRC32) на количество кэширующих серверов:
Такой алгоритм называется хешированием по модулю (англ. modulo hashing). CRC32 здесь использован в качестве примера. Вместо него можно взять любую другую хеширующую функцию, из результатов которой можно получить число, большее или равное количеству серверов, с более-менее равномерно распределённым результатом.
Этот способ легко понять и реализовать, он достаточно равномерно распределяет данные между серверами, но у него есть серьёзный недостаток: при изменении количества серверов (из-за технических проблем или при добавлении новых) значительная часть кэша теряется, поскольку для ключей меняется остаток от деления.
Я написал небольшой скрипт, который продемонстрирует эту проблему.
В нём генерируется 1 млн уникальных ключей, распределённых по пяти серверам с помощью хеширования по модулю и CRC32. Я эмулирую выход из строя одного из серверов и перераспределение данных по четырём оставшимся.
В результате этого «сбоя» примерно 80% ключей изменят своё местоположение, то есть окажутся недоступными для последующего чтения:
Total keys count: 1000000
Shards count range: 4, 5
| ShardsBefore | ShardsAfter | LostKeysPercent | LostKeys |
|---|---|---|---|
| 5 | 4 | 80.03% | 800345 |
Самое неприятное тут то, что 80% — это далеко не предел. С увеличением количества серверов процент потери кэша будет расти и дальше. Единственное исключение — это кратные изменения (с двух до четырёх, с девяти до трёх и т. п.), при которых потери будут меньше обычного, но в любом случае не менее половины от имеющегося кэша:

Я выложил на GitHub скрипт, с помощью которого я собрал данные, а также ipynb-файл, рисующий данную таблицу, и файлы с данными.
Для решения этой проблемы есть другой алгоритм разбивки — согласованное хеширование (англ. consistent hashing). Основная идея этого механизма очень простая: здесь добавляется дополнительное отображение ключей на слоты, количество которых заметно превышает количество серверов (их могут быть тысячи и даже больше). Сами слоты, в свою очередь, каким-то образом распределяются по серверам.
При изменении количества серверов количество слотов не меняется, но меняется распределение слотов между этими серверами:
- если один из серверов выходит из строя, то все слоты, которые к нему относились, распределяются между оставшимися;
- если добавляется новый сервер, то ему передаётся часть слотов от уже имеющихся серверов.

На картинке начального разбиения все слоты одного сервера расположены подряд, но в реальности это не обязательное условие — они могут быть расположены как угодно.
Основное преимущество этого способа перед предыдущим заключается в том, что здесь каждому серверу соответствует не одно значение, а целый диапазон, и при изменении количества серверов между ними перераспределяется гораздо меньшая часть ключей ( k / N , где k — общее количество ключей, а N — количество серверов).
Если вернуться к сценарию, который я использовал для демонстрации недостатка хеширования по модулю, то при той же ситуации с падением одного из пяти серверов (с одинаковым весом) и перераспределением ключей с него между оставшимися мы потерям не 80% кэша, а только 20%. Если считать, что изначально все данные находятся в кэше и все они будут запрошены, то эта разница означает, что при согласованном хешировании мы получим в четыре раза меньше запросов к базе данных.
Код, реализующий этот алгоритм, будет сложнее, чем код предыдущего, поэтому я не буду его приводить в статье. При желании его легко можно найти — на GitHub есть rendezvous hashing), но они гораздо менее распространены.
Вне зависимости от выбранного алгоритма выбор сервера на основе хеша ключа может работать плохо. Обычно в кэше находится не набор однотипных данных, а большое количество разнородных: кэшированные значения занимают разное место в памяти, запрашиваются с разной частотой, имеют разное время генерации, разную частоту обновлений и разное время жизни. При использовании хеширования вы не можете управлять тем, куда именно попадёт ключ, и в результате может получиться «перекос» как в объёме хранимых данных, так и в количестве запросов к ним, из-за чего поведение разных кэширующих серверов будет сильно различаться.
Чтобы решить эту проблему, необходимо «размазать» ключи так, чтобы разнородные данные были распределены между серверами более-менее однородно. Для этого для выбора сервера нужно использовать не ключ, а какой-то другой параметр, к которому нужно будет применить один из описанных подходов. Нельзя сказать, что это будет за параметр, поскольку это зависит от вашей модели данных.
В нашем случае почти все кэшируемые данные относятся к одному пользователю, поэтому мы используем User ID в качестве параметра шардирования данных в кэше. Благодаря этому у нас получается распределить данные более-менее равномерно. Кроме того, мы получаем бонус — возможность использования multi_get для загрузки сразу нескольких разных ключей с информацией о юзере (что мы используем в предзагрузке часто используемых данных для текущего пользователя). Если бы положение каждого ключа определялось динамически, то невозможно было бы использовать multi_get при таком сценарии, так как не было бы гарантии, что все запрашиваемые ключи относятся к одному серверу.
Параллельные запросы на обновление данных
Посмотрите на такой простой кусочек кода:
Что произойдёт при отсутствии запрашиваемых данных в кэше? Судя по коду, должен запуститься механизм, который достанет эти данные. Если код выполняется только в один поток, то всё будет хорошо: данные будут загружены, помещены в кэш и при следующем запросе взяты уже оттуда. А вот при работе в несколько параллельных потоков всё будет иначе: загрузка данных будет происходить не один раз, а несколько.
Выглядеть это будет примерно так:

На момент начала обработки запроса в процессе №2 данных в кэше ещё нет, но они уже читаются из базы данных в процессе №1. В этом примере проблема не такая существенная, ведь запроса всего два, но их может быть гораздо больше.
Количество параллельных загрузок зависит от количества параллельных пользователей и времени, которое требуется на загрузку необходимых данных.
Предположим, у вас есть какой-то функционал, использующий кэш с нагрузкой 200 запросов в секунду. Если на на загрузку данных нужно 50 мс, то за это время вы получите 50 / (1000 / 200) = 10 запросов.
То есть при отсутствии кэша один процесс начнёт загружать данные, и за время загрузки придут ещё девять запросов, которые не увидят данные в кэше и тоже станут их загружать.
Эта проблема называется cache stampede (русского аналога этого термина я не нашёл, дословно это можно перевести как «паническое бегство кэша», и картинка в начале статьи показывает пример этого действия в дикой природе), hit miss storm («шторм непопаданий в кэш») или dog-pile effect («эффект собачьей стаи»). Есть несколько способов её решения:
Блокировка перед началом выполнения операции пересчёта/ загрузки данных
Суть этого метода состоит в том, что при отсутствии данных в кэше процесс, который хочет их загрузить, должен захватить лок, который не даст сделать то же самое другим параллельно выполняющимся процессам. В случае memcached простейший способ блокировки — добавление ключа в тот же кэширующий сервер, в котором должны храниться сами закэшированные данные.
При этом варианте данные обновляются только в одном процессе, но нужно решить, что делать с процессами, которые попали в ситуацию с отсутствующим кэшем, но не смогли получить блокировку. Они могут отдавать ошибку или какое-то значение по умолчанию, ждать какое-то время, после чего пытаться получить данные ещё раз.
Кроме того, нужно тщательно выбирать время самой блокировки — его гарантированно должно хватить на то, чтобы загрузить данные из источника и положить в кэш. Если не хватит, то повторную загрузку данных может начать другой параллельный процесс. С другой стороны, если этот временной промежуток будет слишком большим и процесс, получивший блокировку, умрёт, не записав данные в кэш и не освободив блокировку, то другие процессы также не смогут получить эти данные до окончания времени блокировки.
Вынос обновлений в фон
Основная идея этого способа — разделение по разным процессам чтения данных из кэша и записи в него. В онлайн-процессах происходит только чтение данных из кэша, но не их загрузка, которая идёт только в отдельном фоновом процессе. Данный вариант делает невозможными параллельные обновления данных.
Этот способ требует дополнительных «расходов» на создание и мониторинг отдельного скрипта, пишущего данные в кэш, и синхронизации времени жизни записанного кэша и времени следующего запуска обновляющего его скрипта.
Этот вариант мы в Badoo используем, например, для счётчика общего количества пользователей, про который ещё пойдёт речь дальше.
Вероятностные методы обновления
Суть этих методов заключается в том, что данные в кэше обновляются не только при отсутствии, но и с какой-то вероятностью при их наличии. Это позволит обновлять их до того, как закэшированные данные «протухнут» и потребуются сразу всем процессам.
Для корректной работы такого механизма нужно, чтобы в начале срока жизни закэшированных данных вероятность пересчёта была небольшой, но постепенно увеличивалась. Добиться этого можно с помощью алгоритма XFetch, который использует экспоненциальное распределение. Его реализация выглядит примерно так:
В данном примере $ttl — это время жизни значения в кэше, $delta — время, которое потребовалось для генерации кэшируемого значения, $expiry — время, до которого значение в кэше будет валидным, $beta — параметр настройки алгоритма, изменяя который, можно влиять на вероятность пересчёта (чем он больше, тем более вероятен пересчёт при каждом запросе). Подробное описание этого алгоритма можно прочитать в white paper «Optimal Probabilistic Cache Stampede Prevention», ссылку на который вы найдёте в конце этого раздела.
Нужно понимать, что при использовании подобных вероятностных механизмов вы не исключаете параллельные обновления, а только снижаете их вероятность. Чтобы исключить их, можно «скрестить» несколько способов сразу (например, добавив блокировку перед обновлением).
«Холодный» старт и «прогревание» кэша
Нужно отметить, что проблема массового обновления данных из-за их отсутствия в кэше может быть вызвана не только большим количеством обновлений одного и того же ключа, но и большим количеством одновременных обновлений разных ключей. Например, такое может произойти, когда вы выкатываете новый «популярный» функционал с применением кэширования и фиксированным сроком жизни кэша.
В этом случае сразу после выкатки данные начнут загружаться (первое проявление проблемы), после чего попадут в кэш — и какое-то время всё будет хорошо, а после истечения срока жизни кэша все данные снова начнут загружаться и создавать повышенную нагрузку на базу данных.
От такой проблемы нельзя полностью избавиться, но можно «размазать» загрузки данных по времени, исключив тем самым резкое количество параллельных запросов к базе. Добиться этого можно несколькими способами:
- плавным включением нового функционала. Для этого необходим механизм, который позволит это сделать. Простейший вариант реализации — выкатывать новый функционал включённым на небольшую часть пользователей и постепенно её увеличивать. При таком сценарии не должно быть сразу большого вала обновлений, так как сначала функционал будет доступен только части пользователей, а по мере её увеличения кэш уже будет «прогрет».
- разным временем жизни разных элементов набора данных. Данный механизм можно использовать, только если система в состоянии выдержать пик, который наступит при выкатке всего функционала. Его особенность заключается в том, что при записи данных в кэш у каждого элемента будет своё время жизни, и благодаря этому вал обновлений сгладится гораздо быстрее за счёт распределения последующих обновления во времени. Простейший способ реализовать такой механизм — умножить время жизни кэша на какой-то случайный множитель:
Если по какой-то причине не хочется использовать случайное число, можно заменить его псевдослучайным значением, полученным с помощью хеш-функции на базе каких-нибудь данных (например, User ID).
Пример
Я написал небольшой скрипт, который эмулирует ситуацию «непрогретого» кэша.
В нём я воспроизвожу ситуацию, при которой пользователь при запросе загружает данные о себе (если их нет в кэше). Конечно, пример синтетический, но даже на нём можно увидеть разницу в поведении системы.
Вот как выглядит график количества hit miss-ов в ситуации с фиксированным (fixed_cache_misses_count) и различным (random_cache_misses_count) сроками жизни кэша:

Видно, что в начале работы в обоих случаях пики нагрузки очень заметны, но при использовании псевдослучайного времени жизни они сглаживаются гораздо быстрее.
«Горячие» ключи
Данные в кэше разнородные, некоторые из них могут запрашиваться очень часто. В этом случае проблемы могут создавать даже не параллельные обновления, а само количество чтений. Примером подобного ключа у нас является счётчик общего количества пользователей:

Этот счётчик — один из самых популярных ключей, и при использовании обычного подхода все запросы к нему будут идти на один сервер (поскольку это всего один ключ, а не множество однотипных), поведение которого может измениться и замедлить работу с другими ключами, хранящимися там же.

Чтобы решить эту проблему, нужно писать данные не в один кэширующий сервер, а сразу в несколько. В этом случае мы кратно снизим количество чтений этого ключа, но усложним его обновления и код выбора сервера — ведь нам нужно будет использовать отдельный механизм.
Мы в Badoo решаем эту проблему тем, что пишем данные во все кэширующие серверы сразу. Благодаря этому при чтении мы можем использовать общий механизм выбора сервера — в коде можно использовать обычный механизм шардирования по User ID, и при чтении не нужно ничего знать про специфику этого «горячего» ключа. В нашем случае это работает, поскольку у нас сравнительно немного серверов (примерно десять на площадку).
Если бы кэширующих серверов было намного больше, то этот способ мог бы быть не самым удобным — просто нет смысла дублировать сотни раз одни и те же данные. В таком случае можно было бы дублировать ключ не на все серверы, а только на их часть, но такой вариант требует чуть больше усилий.
Если вы используете определение сервера по ключу кэша, то можно добавить к нему ограниченное количество псевдослучайных значений (сделав из total_users_count что-то вроде t otal_users_count_1 , total_users_count_2 и т. д.). Подобный подход используется, например, в Etsy.
Если вы используете явные указания параметра шардирования, то просто передавайте туда разные псевдослучайные значения.
Главная проблема с обоими способами — убедиться, что разные значения действительно попадают на разные кэширующие серверы.
Сбои в работе
Система не может быть надёжной на 100%, поэтому нужно предусмотреть, как она будет вести себя при сбоях. Сбои могут быть как в работе самого кэша, так и в работе базы данных.
При сбоях в работе базы данных и отсутствии кэша мы можем попасть в ситуацию cache stampede, про которую я тоже уже рассказывал раньше. Выйти из неё можно уже описанными способами, а можно записать в кэш заведомо некорректное значение с небольшим сроком жизни. В этом случае система сможет определить, что источник недоступен, и на какое-то время перестанет пытаться запрашивать данные.
Читайте также: