
Oracle ash что это
Обновлено: 06.07.2024
Детальный анализ реального боя ASH, анализ оптимизации диагностики производительности ORACLE 11G
1、ASH (Active SessionHistory)
ASH основан на V $ SESSION, выборке один раз в секунду для записи событий, ожидающих активных сеансов. Выборка из неактивных сеансов не производится, и выборка выполняется с помощью недавно введенного фонового процесса MMNL.
Представление v $ active_session_history обеспечивает извлечение информации об активности сеанса на уровне экземпляра. Активные сеансы будут отбираться каждую минуту и сохраняться в кольцевом буфере в sga. Любой сеанс, подключенный к базе данных и ожидающий неактивного ожидающего события, будет считаться активным сеансом. Каждая выборка сеанса представляет собой набор данных строки, и данные строки каждого выбранного активного сеанса возвращаются через представление v $ active_session_history, и возвращается первая строка данных последнего сеанса с выборкой. Поскольку образцы активного сеанса хранятся в кольцевом буфере в sga, чем выше активность системы, тем менее активный сеанс может храниться в кольцевом буфере. Это означает, что каждый сеанс, выбранный в течение этого периода, будет отображаться в представлении v $ или время активности сеанса будет отображаться в представлении v $, которое полностью зависит от активности базы данных.
Минимальное значение буферов ASH составляет 1 МБ, а максимальное значение не превышает 30 МБ. Данные записываются в память. Ожидаемое значение - запись одного часа контента, поэтому данные записи в памяти ASH всегда ограничены.
Как правило, проблемы с производительностью базы данных можно диагностировать онлайн в режиме реального времени, особенно когда нагрузка высока, а ЦП загружен на 100% после 100%. В это время использование золы для создания отчетов журнала в реальном времени может в значительной степени точно определить местонахождение проблемы.
2. Основные элементы ASH
После выполнения команды SQL> @? / Rdbms / admin / ashrpt.sql следующие параметры необходимо будет заполнить вручную:
(1) Тип отчета журнала
Enter value for report_type: text
- Выберите тип создаваемого отчета ASH, будь то текст или HTML.
(2) Время начала отчета журнала
Enter value for begin_time: 08/31/1620:00:00
- Введите время начала ASH. Формат времени объяснен в примере выше. Например, здесь я начинаю в 20:00:00 31 августа 2016 г.
(3) Время окончания отчета журнала
Enter value for duration:7200
- Введите время окончания золы, по умолчанию - SYSDATE-begin_time, общее время ввода общей статистики анализа, обычно по умолчанию - секунды, например, 7200 здесь составляет 2 часа, и 2 часа журналов анализа золы извлекаются.
(4) Имя файла отчета
Enter value for report_name: /home/oracle/ash_20160831_3.html
- Введите имя отчета ASH, вы можете указать сгенерированный каталог, по умолчанию это каталог, в который в настоящее время выполнен вход в sqlplus. Лучше всего добавить расширение здесь. Если расширение не добавлено, расширение станет lst. Это не влияет на данные, но влияет на эффективность чтения.
3. Фактический боевой рекорд операции АШ
DB Id DB Name Inst Num Instance
3391761643 POWERDES 1 powerdes
Specify the Report Type
Enter 'html' for an HTML report, or 'text' for plain text
Defaults to 'html'
Enter value for report_type: html
Type Specified: html
Instances in this Workload Repository schema
DB Id Inst Num DB Name Instance Host
* 3391761643 1 POWERDES powerdes pldb1
* 3391761643 1 POWERDES powerdes localhost.lo
Defaults to current database
Using database id: 3391761643
Enter instance numbers. Enter 'ALL' for all instances in a
RAC cluster or explicitly specify list of instances (e.g., 1,2,3).
Defaults to current instance.
Using instance number(s): 1
ASH Samples in this Workload Repository schema
Oldest ASH sample available: 23-Aug-16 08:00:17 [ 12265 mins in the past]
Latest ASH sample available: 31-Aug-16 20:25:19 [ 0 mins in the past]
Specify the timeframe to generate the ASH report
Enter begin time for report:
-- Valid input formats:
-- To specify absolute begin time:
-- Examples: 02/23/03 14:30:15
-- To specify relative begin time: (start with '-' sign)
-- Examples: -1:15 (SYSDATE - 1 Hr 15 Mins)
-- -25 (SYSDATE - 25 Mins)
Defaults to -15 mins
Enter value for begin_time: 08/31/16 20:00:00
Report begin time specified: 08/31/16 20:00:00
Enter duration in minutes starting from begin time:
Defaults to SYSDATE - begin_time
Press Enter to analyze till current time
Enter value for duration: 7200
Using 31-Aug-16 20:00:00 as report begin time
Using 31-Aug-16 20:26:30 as report end time
Specify Slot Width (using ashrpti.sql) for 'Activity Over Time' section
Enter value for report_name: ash_20160831_3.html
Using the report name ash_20160831_3.html
Summary of All User Input
DB Id : 3391761643
Begin time : 31-Aug-16 20:00:00
End time : 31-Aug-16 20:26:30
Slot width : Default
Report targets : 0
Report name : ash_20160831_3.html
Report written to ash_20160831_3.html
4. Подробное объяснение отчета журнала ASH.
4.1 Отчет ASH
Используя отчет по золе, после создания отчета по золе вы можете получить информацию, которая определена как краткосрочная проблема производительности.
Отчет по золе разделен на следующие части:
activity over time

4.2 Top Evnets
В разделе событий ожидания верхнего уровня описаны события ожидания верхнего уровня, созданные пользователями, фоном и т. Д. В выбранных действиях сеанса. Эта информация может использоваться для определения того, какие события ожидания вызвали краткосрочные проблемы с производительностью. События ожидания верхнего уровня включают в себя следующие части:
(1) Самые популярные пользовательские события Самые популярные пользовательские события
Эта часть информации показывает, что пользовательский процесс ожидает большой процент выбранной активности сеанса.
(2) Основные фоновые события
В этой части информации показан фоновый процесс, ожидающий большого процента выбранной активности сеанса.
(3) Значения верхнего события P1 / P2 / P3 Параметры верхнего ожидающего события P1 / P2 / P3
В этой части информации показаны значения параметров ожидающих событий, на которые приходится высокий процент отобранной активности сеанса. Они сортируются по проценту от общего времени ожидания (% событий) и отображаются. Для каждого ожидающего события значения p1, p2 и p3 Подождите, пока не будут связаны параметры события: параметр 1, параметр 2 и параметр 3.
Случай показан на Рисунке 42.jpg ниже:

4.3 Load Profile
Часть профиля нагрузки описывает анализ нагрузки в выбранной активности сеанса. Используйте эту часть информации для определения служб, клиентов или типов команд sql, которые вызывают краткосрочные проблемы с производительностью. Часть профиля нагрузки содержит следующую информацию:
Эта часть информации показывает информацию о сервисе и модуле, на которые приходится высокий процент активности сеанса выборки.
(2)top client ids
В этой части информации отображается информация об идентификаторе клиента, на который приходится высокий процент активности сеанса выборки. Это конкретный идентификатор приложения в сеансе базы данных.
(3)top sql command types
В этой части информации показаны типы команд SQL, на которые приходится высокий процент активности сеанса выборки, например выбор или обновление.
(4)top phases of execution
В этой части информации показаны этапы выполнения, на которые приходится высокий процент выбранной активности сеанса, например компиляция и выполнение SQL, Pl / SQL и Java.
Случай показан на Рисунке 43.jpg ниже:

4.4 Top Sql
В разделе SQL верхнего уровня описываются операторы SQL верхнего уровня в выбранной активности сеанса. Использование этой информации может определить операторы SQL с высокой нагрузкой, которые вызывают краткосрочные проблемы с производительностью.
Раздел sql верхнего уровня содержит следующую информацию:
top sql with top events
top sql with top row sources
top sql using literals
top parsing module/action
complete list of sql text
(1)top sql with top events
В этой части информации показаны операторы SQL, на которые приходится высокий процент от общего числа ожидающих событий в выбранной активности сеанса.
(2)top sql with top row sources
В этой части информации показаны операторы SQL, на которые приходится высокий процент выбранной активности сеанса, и подробная информация об их плане выполнения. Эта часть информации может использоваться для определения того, какая часть выполнения SQL потребляет много времени выполнения SQL.
(3)top sql using literals
Эта часть информации показывает высокий процент операторов SQL, которые используют буквальные значения в выборочных действиях сеанса. Вы можете повторно проверить эту часть операторов SQL, чтобы увидеть, можно ли использовать переменные связывания вместо буквальных значений.
(4)top parsing module/action
В этой части информации показаны модули и операции, на которые приходится высокий процент выполнения проанализированных операторов SQL в выбранных действиях сеанса.
(5)complete list of sql text
Эта часть информации показывает полное текстовое содержание оператора SQL верхнего уровня.
В этой части информации показан процесс pl / sql, на который приходится высокий процент активности сеанса выборки.
В этой части информации показаны java-программы, на которые приходится высокий процент активности сеанса выборки.
4.5 top sessions
Эта часть информации описывает конкретное ожидающее событие, которого ожидает сеанс. Используйте эту информацию, чтобы определить сеансы, на которые приходится высокий процент активности сеанса выборки. Они могут быть причиной временных проблем с производительностью. Раздел основных сеансов содержит следующую информацию:
В этом разделе информации показаны ожидающие сеансы, на которые приходится высокий процент активности сеанса выборки.
(2)top blocking sessions
Эта часть информации показывает высокий процент заблокированных сеансов в выбранной активности сеанса.
(3)top sessions running pqs
Эта часть информации показывает, какие параллельные запросы ожидают большого процента активности сеанса выборки.
4.6、top objects/files/latches
Эта часть информации показывает, что информация, которая обычно потребляет больше всего ресурсов базы данных, включает следующие части:
(1)top db objects
В этой части информации показаны объекты базы данных (такие как таблицы и индексы), на которые приходится высокий процент всех объектов, на которые имеются ссылки в выбранной активности сеанса.
В этой части информации показаны файлы базы данных, на которые приходится высокий процент посещений в выбранной активности сеанса.
В этой части информации отображается информация о защелках, на которую приходится высокий процент активности сеанса выборки.
Защелка - это простой механизм низкоуровневой сериализации, используемый для защиты общих структур данных в sga. Например, защелка защищает список пользователей, которые в настоящее время обращаются к структуре блока данных в базе данных и буферном кеше. При обслуживании или поиске этих структур сервер или Время, в течение которого фоновый процесс запрашивает удержание защелки, очень мало.Реализация защелки зависит от операционной системы, особенно от того, как долго процесс ожидает получения защелки.
(4)Activity over time
Эта часть представляет собой наиболее обширную часть информации отчета по золе. Эта часть информации предназначена для долгосрочных отчетов по золе, поскольку она предоставляет подробную подробную информацию о деятельности и сводку рабочей нагрузки во время анализа. Активность во времени будет разделена на 10 Периоды времени. Размер каждого периода времени зависит от продолжительности анализа. Первый и последний периоды времени выглядят странно. Все внутренние периоды времени равны по размеру, и их можно сравнивать друг с другом. Например, если время анализа длится 10 минут, тогда все периоды времени будут Это одна минута каждый. Затем, если время анализа длится 9 минут 30 секунд, то внешний период может быть каждые 15 секунд, внутренний период может составлять 1 минуту каждый.
Информация, содержащаяся в каждом периоде определенного периода, выглядит следующим образом:
время (продолжительность) Продолжительность временного интервала
solt count Количество выбранных сеансов во временном интервале.
событие Три самых ожидаемых события за период
event count ash Количество ожидающих событий, выбранных и ожидающих
% event Процент ожидающих событий, отобранных пеплом в течение всего периода анализа.
При сравнении внутренних периодов времени выполните анализ перекоса, определив столбцы количества аномальных событий и количества слотов. Исключение в столбце количества событий указывает на то, что количество ожидающих событий, ожидающих в сеансе выборки, увеличилось. Исключение в столбце количества слотов указывает на то, что активность будет достойной Смысл увеличился, потому что данные пепла отбираются только из активных сеансов для иллюстрации базы данных.
Нагрузка увеличивается. Вообще говоря, когда количество активных сеансов выборки и ожидающих событий, связанных с этими сеансами, увеличивается, тогда этот период может вызвать краткосрочные проблемы с производительностью, как показано в 44.jpg ниже:

5. Проанализируйте отчет журнала ASH.
Скопируйте сгенерированный ash_20160831_3.html, откройте его в браузере, вы увидите, что проблема находится на курсоре. Mutex S, как показано ниже:

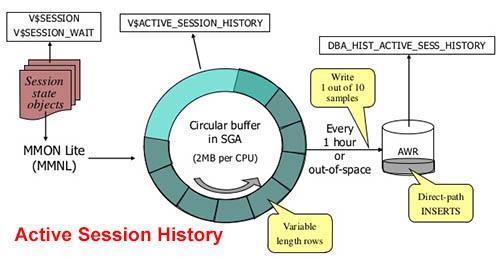
AWR snapshots (снимки) очень полезны, но Oracle по умолчанию делает их каждые 60 минут. Если вы заинтересованы в анализе проблем с производительностью, которая случилась 10 минут назад, то снимки AWR ничем не помогут. Однако все-таки способ получить эту информацию имеется. Oracle Database собирает статистику Active Session History (состоящую в основном из статистики ожидания для различных событий) для всех активных сеансов каждую секунду, и сохраняет ее в циклическом буфере в SGA. Таким образом, ASH записывает самую свежую активность сеанса (за последние пять или десять минут).
Процесс MMNL (в Oracle его называют manageability monitor light — облегченный монитор управляемости, хотя этот процесс отображается как “manageability monitor process 2”, когда запрашивается представление V$BGPROCESS) выполняет легковесные задачи управляемости, включая метрики и захват хронологической информации сеансов для средства ASH при некоторых обстоятельствах. Например, MMNL сбросит данные ASH на диск, если буфер памяти ASH заполнится до истечения часового интервала, что обычно заставляет MMON выталкивать его.
Анализ ASH предоставляет эффективные данные по производительности, поскольку сосредоточен только на активных сеансах. Анализ текущих активных сеансов выполняется с использованием представления V$ACTIVE_SESSION_HISTORY, а анализ хронологии более старых сеансов — с помощью представления DBA_HIST_ACTIVE_SESSION_HISTORY.
На заметку! Дополнительная статистика в Oracle Database не оказывает заметного влияния на производительность, поскольку поступает в основном прямо из SGA через фоновые процессы. Средство ASH использует около 2 Мбайт памяти в SGA на каждый процессор.
Данные текущего активного сеанса
Как должно быть известно, представление V$SESSION хранит данные обо всех текущих сеансах. Оно содержит 72 столбца информации, и потому слишком громоздко для анализа данных сеанса. Вот почему ASH упрощает представление V$SESSION и получает из него наиболее важную информацию ожидания. Oracle предлагает новое представление V$ACTIVE_SESSION_HISTORY, которое содержит по одной строке для каждого активного сеанса, откуда ASH делало выборку, и возвращает строку самого последнего сеанса первой.
Представление V$ACTIVE_SESSION_HISTORY — это место, где база данных хранит пример данных всех активных сеансов. В этом представлении имеется столбец по имени SESSION_STATE, который показывает, активен ли сеанс. Столбец SESSION_STATE принимает два значения: ON CPU или WAITING. Сеанс считается активным в следующих случаях:
- состояние сеанса ON CPU, что означает активное использование сеансом процессора для выполнения работы с базой данных;
- состояние сеанса WAITING, но столбец EVENT указывает, что сеанс не ожидает никаких событий в классе IDLE.
Обратите внимание, что ASH — скользящий буфер в SGA; это находящаяся в памяти хронология активного сеанса. Таким образом, в загруженной базе данных старая информация часто перезаписывается, поскольку ASH собирает данные из представления V$SESSION каждую секунду.
На заметку! Использование статистики ASH для настройки производительности экземпляра рассматривается в главе 20.
Хронологические данные более старых сеансов
Представление словаря данных DBA_HIST_ACTIVE_SESSION_HISTORY хранит хронологическую информацию о последнем активном сеансе. Другими словами, это представление — не что иное, как коллекция снимков представления V$ACTIVE_SESSION_HISTORY, которое само по себе является образом данных активного сеанса.
Существуют два способа заполнения DBA_HIST_ACTIVE_SESSION_HISTORY.
- В процессе получения регулярных (по умолчанию — ежечасных) снимков, выполняемых AWR, фоновый процесс MMON передает AWR данные ASH.
- Oracle может понадобиться передать данные в представление DBA_HIST_ACTIVE_SESSION_HISTORY между моментами получения регулярных снимков, если буфер памяти окажется заполненным, и база данных не сможет записать в него данные об активности сеанса. В этом случае новый фоновый процесс MMNL выполнит выталкивание данных из буфера памяти в представление словаря данных.
Генерация отчета ASH
Для получения отчета ASH можно воспользоваться сценарием ashrpt.sql, находящимся в каталоге $ORACLE_HOME/rdbms/admin. Применение этого сценария аналогично использованию сценария awrrpt.sql, описанного ранее в этой главе. Этот сценарий генерирует информацию об операторах SQL, которые выполнялись в указанный период времени, и включает детали о блокировках и ожидании. Вот как можно запустить сценарий ashrpt.sql для получения отчета ASH:
Вам будет предложено ввести временные рамки для сбора информации ASH, кроме того, формат вывода отчета — HTML или текстовый, а также имя отчета. В листинге 1 ниже показана часть отчета ASH.
Первый раздел отчета ASH, Top User Events, предоставляет информацию о верхних пользовательских событиях, как показано в листинге 2:
Раздел Top Background Events (Верхние фоновые события), показанный в листинге 3 ниже, демонстрирует события ожидания в базе данных.
Раздел Top Service/Module (Верхняя служба/модуль), показанный в листинге 4, отображает активность, разделенную в соответствии со службами и модулями экземпляра.
В листинге 5 ниже показана информация о важнейших типах команд SQL (раздел Top SQL Command Types), выполненных в базе данных за последний час.
В листинге 6 ниже идентифицируются верхние операторы SQL (раздел Top SQL Statements), выполненные за анализируемый период ASH.
После этого следует раздел под названием Top SQL Using Literals (Верхние операторы SQL, использующие литералы), который поможет идентифицировать SQL-операторы, не использующие переменные привязки.
Следующие два сегмента, показанные в листинге 7, относятся Top Sessions (Ведущие сеансы) и Top Blocking Sessions (Ведущие блокирующие сеансы), основанные на ожиданиях в очереди и статистике ожидания занятого буфера.
Следующие три сегмента подводят итог по ведущим объектам базы данных, ведущим файлам и ведущим защелкам в экземпляре. В конце отчет ASH содержит итоговую информацию о событиях ожидания в базе данных, распределенных по меньшим временным слотам, чем общий период анализа, как показано в листинге 8.
В этом примере часовой период времени разбит на десять шестиминутных интервалов. Данный пример поможет более точно выявить моменты ухудшения производительности.

У каждого, кто работает с Бд Oracle есть набор любимых запросов для ее диагностики.
В этой статье хотел бы описать мои, которые запускаются из Oracle Sql developer.
Выгрузка всех отчетов находится по ссылке github
Для работы необходимо наличие лицензии "Diagnostic and Tuning Pack"
Полный список всех отчетов можно видеть на картинке слева.
Большинство из них вспомогательные и нужны для определения параметров запуска отчета "ash" с более детальными параметрами
Вспомогательные отчеты
- Buffer Cache hit ratio - строит график с этим показателем.
Необходим для определения периода времени на котором были провалы по % буферных чтений. - Graph top - топ sql запросов по продолжительности в разрезе времени.
Может быть использован для наглядного определения наиболее долгих запросов в промежуток времени. - Reads per sec - график логических или физических чтений в разрезе времени
Используется для определения проблемного промежутка времени в который было повышенное число чтений - Table top reads - гистограмма со списком топовых таблица по чтениям в указанный период
Используется как детализация отчета "Reads per sec" за указанный период, чтобы узнать какая именно таблица вызвала повышенные чтения. - Нагрузка ash - график числа sample ash в разрезе времени
Наглядное определение периода времени, в который была наибольшая активность запросов. По проблемному периоду дальше строится детализирующий отчета "ash" - Нагрузка по неделям - график числа sample ash в разрезе дня недели и номера недели
Удобно для анализа динамики нагрузки на бд. - Obj top read - топ запросов по чтениям на заданной таблице.
Используется как детализация отчетов "Reads per sec" -> "Table top reads", чтобы узнать какие именно запросы вызвали повышенные чтения на указанной таблице. - Query on obj - топ запросов по времени на заданной таблице.
Схож с отчетом "Obj top read", но запросы отсортированы по времени работы. Отчет удобен для определения проблемных по времени работы запросов на таблице. - Таблицы в кэше - таблицы, которые сейчас в буферном кэше находятся в представлении v$bh
Чтобы иметь историю представление материализуется в таблицу каждый час запросом, а потом строится график: Постоянный большой объем таблицы в кэше говорит о неоптимальности запросов на ней, т.к. вычитывается большой объем данных.
По dirty_blocks можно косвенно оценить объем изменений. - Query ash now - список сейчас работающих запросов.
Есть возможность наложить фильтр по клиенту, программе, sql_id, id сессии, тексту запроса. - Plan diff date - поиск изменившихся планов между 2 датами.
Удобно при анализе изменившихся планов после установки патчей на бд. - SQL id plans, Table plans - устаревшие отчеты, которые стали частью других: "ash" и "Query on obj" соответственно.
Основной детализирующий отчет ASH
Кроме столбцов, которые известы из параметров отчета, добавляются:
* st_dt/ed_dt - период, на котором наблюдался запрос
* execs - число выполнений
* gb - объем считанных данных в ГБ
* av_sec - среднее время работы
* sec - суммарное время работы
* smpl - суммарное число sample в ash
* dop - степень параллелизма, с которой работал запрос
* rws - числ отбираемых/изменяемых строк
* prc - % времени запроса от общей
* txt - текст запроса
Если поставить фокус на определенной строчке отчета, то активируются детализирующие отчеты:

* sql_id plans - список планов на этом запросе за все время существования.
+ Характеристики каждого плана: когда он выполнялся, число выполнений, объем физических и логических чтений, число строк, среднее время и отклонение времени работы от среднего.
Данный детализирующий отчет удобен для выбора плана для последующей фиксации по средствам baseline.

* ash now - сейчас исполняющиеся запросы:

* plan - максимально детальный план запроса:
* binds - историй биндов запроса

* v$sql - информация о запросе из v$sql:
Список child планов, наличие профиля или baseline и все количественные характеристики child планов:

* awr - количественные характеристики плана в разрезе снапшотом без агрегации

* text - полный текст запроса:

* plan real - детализация плана запроса:
** план запроса
** предикаты доступа к объекту (если план сейчас в кэше)
** полный список колонок используемого индекса (для анализа эффективности индекса на месте)
** event - список событий этой строчки плана с процентным распределением от общего времени запроса
** prc - % времени работы этой строчки плана.
Удобно для быстрого определения неоптимальной части запроса, которую требуется оптимизировать в первую очередь.

* graph - график суммарного времени работы запроса в разрезе часов.

* awr wk - аналог отчета awr, но с группировкой до недели.
Удобно для определения тренда времени запроса и определения времени, когда сменился план.

* objects - топ таблиц по времени обращения к ним от этого запроса
* v$bh - история объема таблиц запроса в буферном кэше (источник: отчет "Таблицы в кэше")
* module - топ программ, которые взывают этот запрос
* graph_exe - график, аналогично отчету "graph", но по числу выполнений запроса.
Удобно сравнивать graph и graph_exe между собой, чтобы визуально видеть, растет ли число выполнений запроса вместе с общим временем.
Если число выполнений не растет, а общее время растет, то вероятная причина - рост среднего времени запроса.

* список сессий, которые блокировки работу выделенного запроса
** Событие блокировки
** клиент, который блокировал работу
** id сессии блокировки
** current_* - блок и строка в блоке, на которой происходила блокировка.
** obj_name - Объект, на котором блокировка
** cnt - количество sample во время которых длилась блокировка.
** sql_text - текст запроса, для определения строчки, на которой висела блокировка (на основании current_* столбцов)
Данный отчет удобно использовать для определения горячих строк, к которым пытаются получить блокировку несколько процессов.

* plan real tbs - на каком tablespace были основные чтения у строк плана запроса.
Данный отчет удобен для понимания причин замедления запроса, у которого не поменялся план
Скорей всего замедление связано с ростом числа чтений сегментом отката UNDO из-за интенсивной вставки/обновления одной из таблиц запроса ранее.

* text_bnd - Запрос с подставленным параметрами на место биндов.
Удобно для проверки влияния биндов на план запроса. Если с подставленными значениями получается хороший план, то вероятная причина в перекосе данных или отсутствующих гистограммах.

Привет! Меня зовут Александра, я работаю в команде тестирования производительности. В этой статье расскажу базовые сведения об OEM от Oracle. Статья будет полезна для тех, кто только знакомится с платформой, но и не только для них. Основная цель статьи — помочь провести быстрый анализ производительности БД и поиск отправных точек для более глубокого анализа.
OEM (Oracle Enterprise Manager) — платформа для управления БД. OEM предоставляет графический интерфейс для выполнения большого количества операций с базами данных: резервное копирование, просмотр аварийных журналов, графиков производительности.
Performance Home
На вкладке Performance Home можно увидеть основные графики утилизации БД.
Average Runnable Process

Этот график дает общее понимание использования CPU.
| № | Показатель | Описание |
|---|---|---|
| 1 | Instance Foreground CPU | Отображает утилизацию CPU процессами текущего инстанса, напрямую запущенными клиентом, например выполнение запросов. Список событий ожидания текущего инстанса можно посмотреть в AWR-отчете |
| 2 | Instance Background CPU | Отображает утилизацию CPU фоновыми процессами текущего инстанса, например LGWR. Список событий фонового процесса текущего инстанса можно посмотреть в AWR-отчете или в официальной документации Oracle |
| 3 | Non-database Host CPU | Отображает утилизацию CPU процессами, не относящимися к текущему инстансу |
| 4 | Load Average | Отображает среднюю длину очереди процессов, ожидающих выполнения |
| 5 | CPU Treads/CPU Cores | Отображает лимит максимально возможного использования CPU |
Average Active Sessions
- Если зафиксирован рост активных сессий, то должна расти пропускная способность (график Throughput).
- Если Active Sessions превышает CPU Cores/CPU Threads, это свидетельствует о проблемах производительности.
- Если зафиксирован рост времени отклика операций, но при этом активные сессии не превышают CPU, это значит, что узкое место не в CPU и нужно более детально смотреть, по каким классам события ожидания фиксируется рост, после чего можно на графике нажать на соответствующий класс и провалиться глубже в детализацию (откроется отчет ASH — Active Session History).
Throughput

Раздел Throughput отображает пропускную способность. Пропускная способность базы данных измеряет объем работы, которую база данных выполняет за единицу времени.
Пики на графике Throughput должны соответствовать пикам на графике Average Active Sessions. Если заметен рост времени ожидания, необходимо убедиться, что увеличивается пропускная способность. Если пропускная способность низкая, а время ожидания растет — необходимо изменить настройки БД.

Latency показывает задержку чтения блоков. Это разница между временем выполнения чтения и временем обработки чтения БД. Показатель должен стремиться к нулю.
Оптимальным считается значение до 10 мс. Этот график — основной показатель производительности в этом блоке. Если зафиксирован рост времени задержки, нужно посмотреть, не растет ли количество I/O операций и их вес, также на рост Latency может влиять утилизация CPU.
Статистику по I/O можно смотреть в разрезе функций, в разрезе типов и в разрезе групп потребителей ресурсов (группы пользователей). Для этого на графике необходимо выбрать соответствующий Breakdown. Графики показывают количество I/O-операций в секунду и их вес в разрезе выбранного значения Breakdown. Для большей детализации можно провалиться глубже в статистику, выбрав соответствующее значение на графике или в легенде, и посмотреть статистику именно по выбранному значению.
I/O Function

График дает представление об уровне утилизации диска приложениями или джобами. То есть на графике можно увидеть, какие процессы больше всего читали и писали за определенный период.
Можно выделить следующие категории:
| № | Категория | Описание |
|---|---|---|
| 1 | Фоновые процессы | Включают в себя ARCH, LGWR, DBWR (полный список фоновых процессов есть в документации) |
| 2 | Активность | XML DB, Streams AQ, Data Pump, Recovery, RMAN |
| 3 | Тип I/O | Включает прямую запись и чтение (в том числе чтение из кэша) |
| 4 | Другое | Включает операции ввода/вывода управляющих файлов |
I/O Type

Выводит статистику по тяжести операций ввода-вывода. Маленькими считаются операции, которые обрабатывают до 128 КБ. К большим операциям ввода-вывода относятся: сканирование таблиц и индексов, прямая загрузка данных, резервное копирование, восстановление и архивирование.
Consumer group
Дает представление об утилизации диска в разрезе групп пользователей: показывает, какая группа пользователей выполняет операции чтения и записи в определенный период. Включает в себя фоновые процессы.
Parallel Executions
Раздел дает представление о показателях, связанных с параллельным выполнением запросов. Параллельный запрос делится на несколько процессов для ускорения выполнения запроса. Параллельное выполнение полезно при выполнении тяжелых запросов. Подробнее можно прочесть в официальной документации Oracle.
Services

Службы на этом графике представляют собой группы приложений. Отображаются только сессии активных служб, находящиеся в ожидании в определенный момент времени. Например, служба SYS$USERS — это установка пользовательского сеанса.
ASH Report

ASH Report (Active Session History) дает более подробную информацию по потреблению ресурсов. Чтобы перейти к графику, в меню Performance нужно выбрать пункт Performance Hub/ASH Report. Также перейти к ASH Report можно при выборе класса события ожидания на графике Average Active Session.
- События ожидания и группы событий ожидания.
- Группы пользователей, пользователи, сервисы, инстансы.
- SQL-запросы.
AWR (Automatic Workload Repository) дает подробную информацию о процессах, происходящих с БД в определенный период. Для построения AWR-отчета нужно выбрать пункт меню Performance/AWR/AWR Report. Также есть возможность сравнивать два временных промежутка. Для этого нужно выбрать пункт меню Performance/AWR/Compare Period Report.
Ниже будут описаны наиболее показательные разделы AWR-отчета, описание остальных разделов можно поискать в официальной документации.
Load Profile

Здесь отображается общая информация по тому, как была загружена БД за выбранный период.
| № | Параметр | Описание |
|---|---|---|
| 1 | DB Time(s) | Сумма времени утилизации процессора и время ожидания (без простоя) |
| 2 | DB CPU(s) | Нагрузка на процессор |
| 3 | Background CPU(s) | Загрузка процессора фоновыми задачами |
| 4 | Redo size | Объем чтения |
| 5 | Logical reads | Среднее количество логических чтений блоков |
| 6 | Block changes | Среднее значение измененных блоков |
| 7 | Physical reads | Физическое чтение в блоках |
| 8 | Physical writes | Количество записей в блоках |
| 9 | Read I/O requests | Количество чтений |
| 10 | Write I/O requests | Количество записей |
| 11 | Read I/O (MB) | Объем чтения |
| 12 | Write I/O (MB) | Объем записей |
| 13 | IM scan rows | Количество строк в In-Memory Compression Units (IMCU), которые были доступны |
| 14 | Session Logical Read IM | Чтения в In-Memory |
| 15 | User calls | Пользовательские вызовы |
| 16 | Parses | Разборы |
| 17 | Logons | Количество входов |
| 18 | Excecutes | Количество вызовов |
| 19 | Rollback | Количество откатов данных |
| 20 | Transacions | Количество транзакций |
Instance Efficiency Percentages

| № | Показатель | Критерии |
|---|---|---|
| 1 | Buffer nowait | Если показатель меньше 95%, значит, буферы data block buffer используются неправильно. Возможно, нужно увеличить data block buffer size |
| 2 | Buffer Hit | Если показатель меньше 95%, значит, буферы data block buffer используются неправильно. Возможно, нужно увеличить data block buffer size |
| 3 | Library cache hit | Если показатель меньше 95% — нужно расширять shared pool (либо причина в bind-переменных) |
| 4 | Redo NOWAIT | Если показатель меньше 95%, это говорит о проблеме в redo log buffer или redo log |
| 5 | Parse CPU to Parse Elapsd | Показатель должен быть больше или равен 90%, тогда большинство процессов не ожидает ресурсов, что говорит о правильной работе базы данных |
| 6 | Non-Parse CPU | Показатель должен приближаться к 100%, это значит, что большинство ресурсов CP используется в различных операциях, кроме parsing, что говорит о правильной работе базы данных. Если Non-Parse CPU низкий, значит, база много времени тратит на разбор запроса вместо реальной работы |
| 7 | In-memory sort | Значение меньше 100 говорит о том, что сортировка идет через диск, а также есть потенциальные проблемы с PGA_AGGREGATE_TARGET,SORT_AREA_SIZE,HASH_AREA_SIZE и bitmap setting |
| 8 | Soft Parse | Чем он выше, тем меньше у нас Hard Parse |
| 9 | Latch Hit | Чем он выше, тем меньше мы ждем Latches (если он низкий — у нас проблемы с CPU-Bound и Latches) |
Top 10 Foreground Events by Total Wait Time
В разделе находится топ-10 событий, которые ожидали ресурсов дольше остальных.
При анализе необходимо обратить внимание на класс события ожидания. Если wait class System I/O, User I/O или Other, это нормально для БД. Если класс события ожидания Concurrency, это может свидетельствовать о проблемах.
Классы события ожидания можно посмотреть в разделе Wait Classes by Total Wait Time. В разделе находится статистика по классам события ожидания с сортировкой по времени ожидания.
Описание некоторых событий ожидания:
| № | Событие ожидания | Описание |
|---|---|---|
| 1 | DB CPU | Отображает процессорное время, затраченное на пользовательские операции над БД. Это событие должно находиться на первом месте списка |
| 2 | db file sequential read | Метрика сигнализирует, что пользовательский процесс не находит нужный блок в buffer cache, загружает его с диска в SGA и ждет физического ввода/вывода |
| 3 | db file scattered read | Указывает на проблему с фулл-сканами, возможно, нужны индексы |
| 4 | read by other session | Может говорить о том, что размер блока слишком большой или задержка (latency) слишком большая |
| 5 | enq TX – row lock contention | Событие возникает при ожидании блокировки строки для дальнейшей ее модификации DML-запросом. Если показатель больше 10%, необходимо разбираться в причинах. Более детальную информацию можно посмотреть в разделе Segments by Row Lock Waits, в котором есть сведения о том, какие таблицы были заблокированы и какими запросами |
| 6 | DB FILE SEQUENTIAL READ | Если среднее значение параметра больше 100 мс, это может свидетельствовать о том, что диск работает медленно |
| 7 | LOG FILE SYNC | Значение AVG WAIT более 20 мс может свидетельствовать о проблемах |
| 8 | DB FILE SCATTERED READ | Если это событие выполняется — возможно, имеет смысл создать дополнительные индексы. Для более подробной информации нужно перейти к разделу Segments By Physical Read, в котором находится информация по таблицам и индексам, в которых происходит физическое чтение |
| 9 | direct path read temp ИЛИ direct path write temp | Эти события дают информацию по использованию временных файлов |
| 10 | Buffer Busy Wait | Событие указывает на то, что несколько процессов пытаются обратиться к одному блоку памяти, то есть пока первый процесс работает с конкретным блоком памяти, остальные процессы находятся в статусе ожидания |
Host CPU и Instance CPU
Здесь стоит обратить внимание на %Idle и %Total CPU. Если показатель %Idle низкий, а %Total CPU высокий, это может свидетельствовать о том, что процессор является узким местом.
Foreground Wait Class, Foreground Wait events и Background Wait Events
Показывают классы и события, которые провели в ожидании большего всего. Foreground Wait events дополняет информацию раздела Top 10 Foreground Events By Total Wait Time. Background Wait Events показывает детализацию по событиям ожидания фоновых процессов.
SQL statistics

Раздел содержит несколько таблиц со статистикой по SQL-запросам, отсортированным по определенному критерию.
Подробнее про оптимизацию запросов и примеры типичных проблем в запросах можно почитать в статье Проактивная оптимизация производительности БД Oracle.
| № | Параметр | Описание |
|---|---|---|
| 1 | SQL ordered by Elapsed Time | Топ SQL-запросов по затраченному времени на их выполнение |
| 2 | SQL ordered by CPU Time | Топ SQL-запросов по процессорному времени |
| 3 | SQL ordered by User I/O Wait Time | Топ SQL-запросов по времени ожидания ввода/вывода для пользователя |
| 4 | SQL ordered by Gets | Запросы к БД, упорядоченные по убыванию логических операций ввода/вывода. При анализе стоит учитывать, что для PL/SQL-процедур их количество прочитанных Buffer Gets будет состоять из суммы всех запросов в рамках этой процедуры |
| 5 | SQL ordered by Reads | Этот раздел схож с предыдущим: в нем указываются все операции ввода/вывода, наиболее активно физически считывающие данные с жесткого диска. Именно на эти запросы и процессы надо обратить внимание, если система не справляется с объемом ввода/вывода |
| 6 | SQL ordered by Physical Reads (UnOptimized) | В этом разделе выводятся неоптимизированные запросы. В Oracle неоптимизированными считаются все запросы, которые не обслуживаются DSFC или Exadata Cell Smart Flash Cache (ECSFC) |
| 7 | SQL ordered by Executions | Наиболее часто выполняемые запросы |
| 8 | SQL ordered by Parse Calls | Отображает количество попыток разбора SQL-запросов до его выполнения |
| 9 | SQL ordered by Sharable Memory | Запросы, занимающие больший объем памяти общего пула SGA |
| 10 | SQL ordered by Version Count | Здесь показано количество SQL-операторов экземпляров одного и того же оператора в разделяемом пуле |
| 11 | Complete List of SQL Text | Показывает полный SQL-запрос, не только его хэш. В этой таблице можно найти неоптимальные запросы (например, запросы по всем столбцам таблицы «select * from. », запросы с большим количеством «like» и т. п.) |
Active Session History (ASH) Report
В данной таблице находятся самые тяжелые SQL запросы, на которые приходится наибольший процент активности и наибольшее время ожидания.
В таблице содержится статистика по запросам, на которые приходится наибольший процент выборочной активности и подробная информация о их плане выполнения. Вы можете использовать эту информацию, чтобы определить, какая часть выполнения SQL операторов значительно повлияла на затраченное время SQL оператора.
Читайте также: