
Oracle data modeler как установить
Обновлено: 05.07.2024
Я работаю над созданием среды разработки oracle на своей рабочей станции Ubuntu 16.04. Установка Oracle 12c была сложной задачей, но было несколько очень полезных уроков, которые поставили меня на правильный путь. Следуя инструкциям Дизуэлла, разработчик SQL был частью торта, чтобы настроить.
Первоначально я смог конвертировать пакет оракул rpm в deb и установить его успешно. Когда я впервые запустил datamodeler, он работал правильно. Во всех последующих запусках я получаю следующую последовательность ошибок:
Я очистил и повторно установил пакет.deb несколько раз, и я больше не могу его запускать. Любые предложения о том, как действовать, будут оценены.
Чтобы установить DM, я выполнил инструкции Oracle Noob, как показано ниже:
Я добавил эту строку в сценарий запуска datamodeler:Сегодня мне нужно тщательно изучить установку Oracle Data Modeler (ODM) на моем Ubuntu 16.04, и я сделал это с успехом с нижеследующими шагами.
Info: Выполнено как пользователь, не являющийся пользователем sudo
Установить Java
Установите версию Java ( java , javac ):
Затем проверьте правильность версии
и вы должны увидеть что-то вроде:
Установка Oracle Data Modeler
Я использую самую обновленную, стабильную версию ODM за день написания этого ответа (v4.1.5).
Перед запуском нам нужен alien конвертер, поэтому мы делаем:
Использовать чужой, чтобы преобразовать пакет *.rpm в *.deb
Небольшое примечание об использовании флага --scripts (ref: руководство для инопланетян)
-c, --scripts
Попробуйте преобразовать сценарии, предназначенные для запуска, когда пакет установлен и удален. Используйте это с осторожностью, потому что эти сценарии могут быть разработаны для работы в системе в отличие от ваших собственных и могут вызвать проблемы. Рекомендуется изучить скрипты вручную и проверить, что они делают до использования этой опции.
После этого шага вы можете запустить его из консоли:
Примечание. Если вы хотите запустить Data Modeler с момента запуска, вам нужно добавить новую запись в /usr/share/applications (для всех пользователей) или
/.local/share/applications/ (только для текущего пользователя), например, пример ниже.
Небольшое примечание об использовании флага --scripts (ref: руководство для инопланетян)
Просто примечание, чтобы помочь другим. Вышеприведенная строка может не потребоваться для некоторых версий. Для тех, кто использует Ubuntu, проверьте Ubuntu Software перед тем, как следовать инструкциям, потому что Oracle SQL Developer доступен как стандартная версия в некоторых версиях Ubuntu (я не проверял все версии, но 16.04LTS). Также обратите внимание, что большинство версий LTS имеют несколько базовых версий программного обеспечения, которые, скорее всего, будут хорошо работать для ваших требований.
Продолжаем осваивать СУБД от Oracle и сейчас давайте рассмотрим инструмент разработки и администрирования баз данных SQL Developer, мы узнаем, для чего нужен данный инструмент, затем установим его и настроим на работу с базой данных.
Как помните, в прошлом материале мы рассмотрели бесплатную СУБД от Oracle, а именно Oracle Database Express Edition 11g Release 2. И теперь для того чтобы разрабатывать базы данных и приложения на PL/SQL, необходимо установить соответствующий инструмент, и я, конечно же, для этих целей предлагаю использовать, также бесплатную программу SQL Developer, которую компания Oracle выпускает специально для разработки и управления баз данных на СУБД Oracle Database.
Для чего нужен SQL Developer?

Данная среда написана на языке программирование Java и она работает на всех платформах где есть Java SE.
SQL Developer, позволяет просматривать объекты базы данных, запускать различные SQL инструкции, создавать и редактировать объекты базы данных, импортировать и экспортировать данные, а также создавать всевозможные отчеты.
Oracle SQL Developer помимо Oracle Database может подключаться и к другим базам данных, например, Microsoft SQL Server, MySQL и другим, но для этого необходимы специальные плагины, хотя возможность подключения к базе Access (mdb файл) есть по умолчанию.
На момент написания статьи доступна версия Oracle SQL Developer 4.0.3 (4.0.3.16.84) поэтому именно ее мы и будем устанавливать.
Где скачать Oracle SQL Developer?
Так как это продукт компании Oracle соответственно его можно скачать на официальном сайте компании, на данный момент доступна страница
После перехода на страницу мы соглашаемся с лицензионным соглашением путем выбора переключателя Accept License Agreement, затем выбираем платформу, на которую мы будем устанавливать, я хочу устанавливать на Windows 7 x32, соответственно выбираю:
Жму Download, потом, как и при скачивании Oracle Database Express Edition необходимо указать учетные данные от Oracle если они есть, а если нет, то соответственно необходимо завести учетную запись на Oracle (нажать «Создать учетную запись»). После чего загрузится файл sqldeveloper-4.0.3.16.84-no-jre.zip размером почти 226 мегабайт (это архив его можно разархивировать, например программой 7-zip).
Установка SQL Developer
Как было сказано, для работы среды SQL Developer требуется Java SE, поэтому у Вас на компьютере должен быть установлен Java Development Kit (JDK) это разработанный компанией Oracle, бесплатный комплект разработчика на языке Java, который включает стандартный компилятор, библиотеки классов Java и исполнительную среду JRE.
Поэтому нам сначала необходимо скачать и установить JDK, скачать его можно также на официальном сайте. Например, я буду скачивать, и устанавливать 7 версию JDK (кстати, доступна уже 8 версия, но я захотел именно эту). 7 версия JDK на сегодняшний день доступна на странице
я перехожу на эту страницу, и у пункта Java SE Development Kit 7u72 снова соглашаюсь с лицензионным соглашением, путем выбора переключателя Accept License Agreement и выбираю файл для 32 разрядных операционных систем Windows, а конкретно jdk-7u72-windows-i586.exe.
Установка Java SE Development Kit 7u72 (JDK)
У нас загрузился файл jdk-7u72-windows-i586.exe мы соответственно его и запускаем.
После запуска появится стартовое окно установщика JDK, мы жмем «Next»
Затем советую оставить все по умолчанию, жмем «Next»
И в процессе установке появится окно для запроса на установку JRE, жмем «Next»
Далее соответственно будет производиться установка JRE

После появления следующего окна установка будет завершена, жмем «Close»
Запуск SQL Developer 4.0.3
После распаковки архива sqldeveloper-4.0.3.16.84-no-jre.zip и установки JDK, переходим в распакованный каталог, открываем папку sqldeveloper и запускаем программу sqldeveloper.exe.
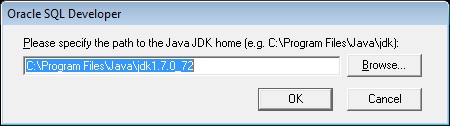
И при первом запуске SQL Developer попросит указать путь к комплекту JDK, и если Вы не меняли путь при установке JDK, то программа сама его подставит, нам останется нажать «OK», а если все же Вы изменили путь, то его необходимо будет указать.
И вот сейчас мы сможем наблюдать, как у нас будет открываться программа SQL Developer

После чего она соответственно откроется, и мы увидим стартовую страницу
Настраиваем подключение с сервером и базой данных
Так как в прошлом материале мы установили Oracle Database Express Edition, соответственно именно с этим сервером мы и будем соединяться.
Для этого жмем плюсик «New Connection»
После чего у Вас откроется окно настройки подключения, Вы соответственно вводите название Вашего подключения (Connection Name), имя пользователя (Username) и пароль (Password), если Oracle Database установлен на этом же компьютере, то в поле Hostname так и оставляем Localhost, порт 1521 (Port), SID, т.е. название базы данных, в случае с Express Edition это XE. (Если помните, я говорил что sql developer можно настроить на работу с базой Access mdb, для этого перейдите на вкладку Access). После ввода советую сначала нажать Test и если Вы получили ответ в строке состояния «Успех», т.е. Status: Success
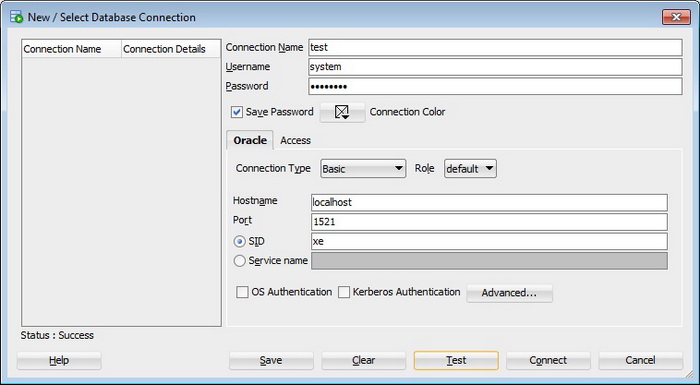
То это означает что все хорошо, можем нажимать «Connect»
В случае если Вы получили в ответ следующую ошибку:
в конец добавить две строки
затем перезапустить SQL Developer
После подключения к базе Вы увидите название своего подключения в списке подключений
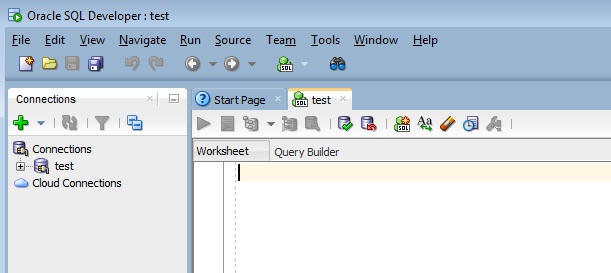
Если плюсиком открыть подключение мы увидим все типы объектов в базе данных
Заметка! Начинающим программистам рекомендую почитать мою книгу «SQL код», которая поможет Вам изучить язык SQL как стандарт, в ней рассматриваются все базовые конструкции языка SQL, приводится много примеров и скриншотов.
Вот и все теперь можно писать запросы, разрабатывать функции, процедуры на языке PL/SQL, но об этом в следующем материале. Удачи!
Эта статья и её продолжение появились благодаря вопросам студентов на семинарах по СУБД. Каждый студент должен был выбрать тему для проектирования базы данных, реализовать полный цикл проектирования от логической и физической диаграммы в Oracle SQL Developer Data Modeler ( SDDM ) до работающей базы данных в СУБД Oracle с использованием APEX. Затем стать пользователем своей разработки: заполнить схему данными и написать аналитические запросы. Некоторые возможности SDDM оказались неочевидными и мы потратили полтора занятия, что бы рассмотреть самое необходимое.
Некоторым студентам, имеющим некоторый стихийно накопленный опыт разработки приложений с использованием СУБД, тяжело перестраиваться на анализ предметной области, трудно понять важность методик проектирования реляционной модели. Потому статья начнется с напоминания порядка разработки.
Не надо сразу делать таблицы. Порядок разработки следующий:
- анализ данных, процессов обработки информации и бизнес-правил, документирование собранной информации
- выявление и определение сущностей
- выявление, описание атрибутов сущностей, определение типов атрибутов
- выявление, описание и определение типов связей между сущностями
- создание матрицы связей и проверка идеи на прочность анализом матрицы связей, документирование бизнес-правил и ограничений
- создание логической диаграммы сущность-связь (ERD) в SDDM, в свойствах атрибутов и связей в том числе отражаются бизнес-правила и ограничения, те что не могут быть реализованы в СУБД описываются отдельным документом и реализуются на прикладном уровне триггерами
Статью готовил я, Присада Сергей Анатольевич, сейчас работаю в Финансовом университете при Правительстве РФ, почта sergey.prisada на яндексе.
Рассмотрим на некоторых абстрактных отношениях следующие возможности:
- Домены атрибутов.
- Глоссарий имен.
- Суррогатные (искусственные) первичные ключи.
- Комментарии к атрибутам. Комментарии к сущностям.
Задачи
- Создать домен атрибутов содержащий 4 значения (Value List).
- Создать 3 сущности, каждая с 4 атрибутами. В каждой сущности 1 атрибут использует домен значений. 2 атрибута обязательные, два не обязательные, один атрибут уникальный, но не первичный UID. Сущности используют суррогатные (искусственные) ключи, первичные ключи вручную не устанавливаем. Каждому атрибуту и сущности сделать комментарий для RDBMS.
- Создать связи между сущностями 1:N и в свойствах связей установить использование суррогатных ключей.
- Создать и применить глоссарий имен.
- Преобразовать в реляционную, затем в физическую модель. Изучить код, при наличии ошибок выяснить причину и устранить.
- Отобразить комментарии на диаграмме для улучшения читаемости.
1. Создать домен атрибутов с 4 значениями (Value List). Указать строковый тип и параметры типа.
Меню “Tools” – “Domains Administrator”

Домен атрибутов будет использоваться для создания ограничений значений стрибутов на уровне таблицы. Ограничения могут быть не только списком значений, но также ограничивать диапазоны численных данных, можно указать конкретные значения диапазона.
Создать список допустимых значений домена.

Домены атрибутов сохраняются в файл defaultdomains.xml в каталоге с настройками Oracle Data Modeler профиля пользователя, или в каталоге с установленной программой – зависит от операционной системы.
Файл с доменами атрибутов необходимо сохранить в каталоге с моделью с новым именем, подключить его в настройках и сохранить модель. Для этого открыть настройки доменов:
Меню “Tools” – “Domains Administrator”, выбрать файл


- домен это совокупность всех значений, которые может принимать атрибут сущности
- каждый атрибут может быть определен только одним доменом атрибутов
- каждый домен может определять множество атрибутов
- в понятие домен входит не только область значений домена, но и тип данных, диапазон значений
- домен «Имя» определен, тип строковые данные, перечень атрибутов «Иванов», «Петров», «Сидоров» как принадлежащие этому домену
- домен «Почтовый индекс», тип данных NUMBER длиной 6 символов
- домен «SMS to client», тип строковые данные длинной 100 символов
2. Создать 3 сущности, каждая с 4 атрибутами. В каждой сущности 1 атрибут использует домен значений. 2 атрибута обязательные, два не обязательные, один атрибут уникальный, но не первичный UID. Сущности используют суррогатные ключи, первичные ключи не устанавливаем. Каждому атрибуту и сущности сделать комментарий для RDBMS.
Первичные ключи указывать не нужно, только уникальные атрибуты в разделе “Uniaue Identifiers”.
Использование суррогатных ключей для сущности.

Домен атрибутов и комментарий к атрибуту, параметр Mandatory (обязательности) устанаваливаем у двух из четырех.

Комментарий в свойствах сущности. Он появится на логической диаграмме, отобразится в свойствах таблицы и будет создан в физической модели.

Первичных и уникальных ключей сами не создаем (пусто на вкладке)

Создать связи между сущностями 1:N и в свойствах связей установить использование суррогатных (Искусственных) ключей “Use surrogate keys”. Свойства связи: переносимость Transferable, обязательность Optional и кардинальность Cardinality выбираем какие угодно, это же пример.

3. Создать и применить глоссарий имён.
Использование глоссария облечает работу с правилами именования в модели данных. Имя сущности должно быть в единственном числе, производная из неё таблица во множественном. Имя атрибута может быть длинным и понятным при разработке, но имя производного столбца должно быть кратким для уменьшения кода и удобства работы с запросами. Как правило, для имени столбца используют аббревиатуру имени атрибута. Имя атрибута сущности для автоматически создаваемого первичного ключа будет состоять из имени сущности с добавлением “_id”. Также в Oracle Data Modelerотдельно есть настройки правил для формирования имён внешних ключей, составных первичных ключей, индексов, ограничений уникальности.
Глоссарий имён можно создать новый, но также можно создать шаблон из уже разработанной логической
Предварительно необходимо сделать настройки имён в свойствах Oracle Data Modeler.
В настройках в Oracle Data Modeler, убрать чек-бокс.

Создать глоссарий имен из готовой логической диаграммы. Сохранить его как файл в каталоге с моделью.

Глоссарий обязательно должен содержать множественную форму для имени каждой сущности и аббревиатуру для каждого атрибута. Большие глоссарии можно редактировать выгрузив их в таблицу Excel. Меню редактирования глоссария находится в меню “Tools” – “Glossary Editor”. Используйте глоссарий во множестве проектов, нарабатывайте его в своей практике.
Меню сохранения глоссария

В настройках модели подключить глоссарий.


И примените правила именования к логической модели.

Преобразовать в реляционную.

Результат преобразования будет содержать имена из глоссария, комментарии.

Преобразовать реляционную модель в физическую.

В диалоговом окне можно выбрать не только сохранение, но также вид конкретной СУБД в которой будет использоваться готовая модель. Напомню, что проектирование не зависит от физической реализации СУБД. Мы выберем СУБД Oracle последней доступной в планировщике версии.

В настройках генерации физической модели можно указать множество параметров, например выбрать только определенные объекты модели (например вы разработали только представления View). Обязательно установить чек-боксы как на картинке. Все подробности в документации.

Результат – DDL файл с инструкциями для создания схемы в базе данных. Внимательно изучите его, найдите все элементы, которые были созданы в логической диаграмме, при наличии ошибок выяснить причину и устранить. Например домены атрибутов, каким образом создаются ограничения и т.п.

Этот скрипт готов для импорта в базу данных.
4. Отображение комментариев.
Отображение комментариев в логической и реляционной моделях делает диаграммы более читаемыми во время работы.

При открытой логической диаграмме в меню Oracle Data Modeler включить в меню отображение комментариев.

5.Скачайте пример
Изучите её как пример, создайте аналог, прочтите дополнительно документацию и примените знания в своём проекте.
Начало
Представьте что программа - это буйный пациент, а вы - медбрат, которого доктор попросил надеть смирительную рубашку на больного. Больной брыкается и цепляется своими ручонками за всё что не попадя. Нужно аккуратно отцепить пациента от окружающего мира и нежно спеленать его аки куколку.
Более подробно как паковать программы в snap будет разжёвано в поздних статьях на примере GTK программы DeaDBeeF. Упаковка там сложнее в том плане, что программа собирается из исходников, юзает графический тулкит GTK, который цепляет +100500 компонентов. Искренне хотел, чтобы автор проекта сам выставлял проект в Ubuntu Store. Поделился с ним наработками и дал время, но, не зная окончательного решения upstream, не удержался и выложил программу сам под именем deadbeef-vs.

Сегодня опять Java программа и базовые приёмы при упаковке софта в snap. Нам нужен пустой каталог и в нём создаётся пустой файл snapcraft.yaml. Пишем в нём базовые поля: name, version, summary, description, confinement, architectures.
На примере Oracle SQL Developer Data Modeler.
Поля имеют самоговорящие названия, но позволю их ещё разжевать:
В моём случае (одна архитектура в лице 64 бит) итоговое имя файла будет osddm_4.1.3.901-snap1_amd64.snap.
Следующим шагом в snapcraft.yaml добавляем раздел apps и в него свои "программы".
Заметьте что имя "бинарника" osddm совпадает с именем пакета, что позволит пользователю вызывать программу по имени osddm, что неявно вызовет osddm.osddm. Некоторых коробит такой вид программы в стиле $имя_снап.$имя_программы, но вы должны понять, что внутри snap пакета могут идти несколько "программ", должен быть способ вызвать их и нужно решить вопрос с возможным совпадением одинаковых имён программ из разных пакетов. Ведь вы можете представить в системе программу music-player и другой снапкрафтер в своём пакете ненамеренно представить плеер с таким же именем.
Чтобы окончательно прояснить вопрос со множеством "бинарников" в снап пакете, представлю вам эталонный hello-world пакет.
sudo snap install hello-world ; cd /snap/hello-world/current/ ; tree .
В его snapcraft.yaml (в пакете он лежит как meta/snap.yaml) раздел apps выглядит так
Свой враппер
Но возвращаемся к Oracle SQL Developer Data Modeler и к строкам
Почему run.sh намекает на bash скрипт и там не указан бинарник программы? Дело в том, что snapcraft автоматически предоставляет очень куцый, по крайней мере пока, скрипт-враппер command-osddm.wrapper, который будет лежать в корне snap пакета и в нём строки:
Как вы видите там реально базовые вещи в лице переменных PATH и LD_LIBRARY_PATH. Этого, к сожалению, не достаточно. По опыту скажу, что между стандартным враппером и запуском программы очень нужен ещё один ваш враппер-скрипт, которые подрихтует напильником нужное. Обратите внимание, что путь к программе (стартовому скрипту) в snapcraft.yaml указан в "относительном" стиле без / впереди - usr/bin/run.sh. usr/bin/ намекает, что это не системный /usr/, а usr/ внутри snap пакета. Обратите внимание, что в стандартном враппере наш путь был преобразован в exec $SNAP/usr/bin/run.sh. Переменная $SNAP хранит значение пути, куда будет установлен snap пакет. Обычно это /snap/$SNAP_NAME/$SNAP_REVISION/, то есть $SNAP = /snap/$SNAP_NAME/$SNAP_REVISION/. Содержимое run.sh будет ниже.
Plugs
Что такое plugs и с чем его едят? Snap пакет самодостаточен и в нём нет понятия зависимости из мира deb как класс. Но будучи изолированным, софту нужно получать доступ к вещам за пределами тюрьмы-снап-пакета. По умолчанию, система (снап пакет ubuntu-core) предоставляет следующие слоты: camera, cups-control, firewall-control, gsettings, hardware-observe, home, locale-control, log-observe, modem-manager, mount-observe, network, network-bind, network-control, network-manager, network-observe, opengl, optical-drive, ppp, pulseaudio, snapd-control, system-observe, timeserver-control, timezone-control, unity7, x11. К нужным для вас слотам можно сделать connect и получить требуемое.
Заранее из snapcraft.yaml connect'ы просятся именно так - plugs: [network, network-bind, x11, home, unity7, gsettings]
В данном примере просим дать сетевой доступ network, возможность bind на сетевой интерфейс аля сервис - network-bind, возможность графической программе через свои тулкиты отобразить в X11, доступ к домашней папке home, доступ к технологиям Unity типа глобального меню и т.д., доступ к gsettings даст так же возможность общения по шине DBus.
Пользователь в дальнейшем может добавить коннекты или разорвать существующие. Пока это возможно только в консоли через snap connect/disconnect, но разработчиками планируется создание графической утилиты. Естественно, что разрыв соединения точно приведёт в потери части функционала программы и даже к её неработоспособности в ряде случаев. Например, в почтовой рассылке разработчиков читал что текущая реализация дисконнекта слота network очень груба и многие сетевые программы справедливо ругаются и падают, когда им отсекают их сетевые возможности. Разрабы хотят сделать реализацию отъёма слота network в стиле - "нет провода". То есть, отняв у сетевой программы коннект к слоту network, мы как бы говорим программе, что внутри её тюрьмы есть сетевая карта, но из неё "вынули провод".
Кусочки
Кусочек dm-files
Parts - это ваши кусочки с произвольными именами, которые делают полезные для вас вещи. Snapcraft расширяется через систему плагинов и команда snapcraft list-plugins выводит на данный момент:
Добавляю раздел parts и первый кусочек dm-files, который использует плагин copy для размещения нужных файлов и каталогов в нужных местах.
- run.sh: usr/bin/run.sh
Мой враппер, чей код рассмотрим ниже, лежит в папке рядом со snapcraft.yaml и прошу разместить его usr/bin/run.sh, так как usr/bin/ находится в переменной PATH. - ddm/* : /
Скачанный с официального сайта Oracle SQL Developer Data Modeler в виде rpm был распакован в ddm/ и представлен в виде дерева каталогов.
Кусочек integration
Кусочек по имени integration использует ничего не делающий плагин nil, чтобы с помощью stage-packages можно было указать какие пакеты из стандартных репозиториев Ubuntu snapcraft должен скачать и добавить их содержимое в будущий snap пакет. Вы ещё не забыли что снап пакет должен быть самодостаточным? "Всё своё ношу с собой".
Баги, портящие кровь
Здесь нужно сделать перерыв и объяснить один момент. Инструмент упаковки snapcraft находится под активной разработкой, как и вся новая технология пакетов snap. Вся эта братия находится на переднем фронте разработки и не может не содержать багов и шероховатостей. В моём случае из ТРЁХ плагинов (ant, maven, jdk), занимающиеся Java программами, в идеале нужно было взять jdk, который помогает в упаковке Java программ в готовых jar файлах. Ant и maven помогают в сборке Java программ из исходников.
Если сделать дополнительный кусочек java-files вот так
то Snapcraft "увидит" Java природу упаковываемой программы и :
- модифицирует свой стандартный враппер, добавив нужное для Джава.
- сам добавит актуальный пакет openjdk.
К этому моменту разработчики облегчили жизнь снапкрафтерам и представили облачные кусочки (cloud parts), которые легко использовать, добавив к любому своему кусочку строку
after: [desktop/xxx]
где xxx - gtk2, gtk3, qt4, qt5, glib-only.
Облачные кусочки - это эталонный набор пакетов в раздел stage-packages и эталонный враппер desktop-launch.
Нашёл открытый отчёт о баге Same packages pulled twice with different timestamps cause clash и подтвердил, добавив комментарий. Баг на дату написания статьи остаётся не закрытым и в состоянии High. Ну что можно сказать, кроме слова б%№ть? Сидеть ждать от моря погоды?
Решил:
Это легко сказать и трудно сделать. Выбросив помощь разработчиков в лице их cloud parts, лишился ещё и их эталонного враппера desktop-launch, которые делает такие вещи, до которых мне своим умом просто не дойти. Спёр эталонный desktop-launch и под видом run.sh с моими дополнениями он будет рассмотрен ниже. Так же спёр эталонный набор пакетов, просто добавив их в свой кусочек integration. Давайте вернёмся к нашим баранам.
Работаем напильником
Программа вместе со своей свитой внутри снап пакета будет сжата squashfs и доступна ТОЛЬКО-ДЛЯ-ЧТЕНИЯ по пути в переменной $SNAP. Для ЗАПИСИ чего-либо у вас будет путь $SNAP_USER_DATA.
Всё, игра началась! Так как упаковка даже готовой программы в jar файлах долгий процесс и исследование неизвестной программы без исходников чревато множеством итераций упаковки, то делаем ход конём. Копируем программу со сборочного сервера в свою основную систему в системный путь /opt/datamodeler/ и делаем 99% имитацию будущего положения: каталог для чтения, где обитает программа, и каталог для записи в лице
/. Каталог /opt/datamodeler/ имитирует $SNAP, а
Делаем для чистоты эксперимента владельцем каталога пользователя root и добавляем, чтобы файлы на чтение точно были доступны всем (a+r).
sudo chown -R root:root /opt/datamodeler/
sudo chmod -R a+r /opt/datamodeler/
Теперь осталось за малым . Нужно, чтобы запущенный из под обычного пользователя, Oracle SQL Developer Data Modeler корректно работал. Он может создавать в моей домашней папке
Начнём исследование!
Стартовый для Linux систем скрипт opt/datamodeler/datamodeler.sh содержит cd "`dirname $0`"/datamodeler/bin && bash datamodeler
М-м-м, определяется где находится программа в данный момент и осуществляется переход в datamodeler/bin и запуск "bash datamodeler". Так и запишем в stage-packages, что требуется одноименный пакет bash, который хранит оболочку bash.
Анализируем вызываемый bash скрипт opt/datamodeler/datamodeler/bin/datamodeler. Ищём намёки на абсолютные пути. Вроде нет их. Шапка скрипта
и всякие dirname и basename укрепляют нас в вере, что разработчики продумали тот момент, что их детище будет запущено из различных мест в файловой системе. Нам это на руку. Строка
и вот мы двигаемся к другому скрипту launcher.sh, лежащему в opt/datamodeler/ide/bin/.
Мы можем через OIDE_JAVA_HOME или JAVA_HOME указать путь к Джава машине. В своём враппере run.sh делаю первые наброски: указываю путь к Java через JAVA_HOME и этот путь добавляю в PATH. Полный run.sh будет ниже.
и попробовал в opt/datamodeler/datamodeler.sh добавить cd "`dirname $0`"/datamodeler/bin && bash datamodeler --setskipj2sdkcheck Но номер у меня не удался. Помог другой способ. Если строка SetSkipJ2SDKCheck true есть в файле .data_modeler/1.0.0.0.0/product.conf, то osddm перестаёт ругаться. В run.sh нужно добавить строки ДО вызова программы
На этом этапе osddm стартовал, быстро мелькал сплэш экран и всё - программа завершалась. Добавил --verbose в opt/datamodeler/datamodeler.sh - cd "`dirname $0`"/datamodeler/bin && bash datamodeler --verbose . В launcher.sh заработали строки EchoIfVerbose, которые стали выводить не лишнюю для меня информацию, но понимание ситуации не улучшили. В данном месте стало грустно. У меня на руках Java программа, а я не разбираюсь ни в Джава, ни в данной программе. Отлаживать программы никогда не умел. Взгляд упал на файл opt/datamodeler/datamodeler/bin/logging.conf, чьё название намекает на конфигурирование уровня журналирования. Нужно поднять уровень журналирования! На просторах Интернет нашёл советы от профи - как повысить уровень информирования в консоль о ходе работы джава программы.
Внёс строки
И? Строк стало так много, что старт программы замедлился в разы ! Но теперь хотя бы можно найти проблему. Оказалось, что такой сложный комплекс как Oracle SQL Developer Data Modeler состоит из различных компонент и один из них обнаружил, что его каталог opt/datamodeler/netbeans/platform/ находится на разделе со свободным местом в 0 байт. То есть он ругается не на то, что каталог не доступен для записи, а именно что каталог находится там где свободного места = 0 байт.
"Нам нужна собака для полётов в космос!" - сказал К.Э. Циолковский."Вот сука!" - сказал И.П. Павлов.
И? На тебе под дых, чтобы не расслаблялся. Oracle SQL Developer Data Modeler стал ругаться, что его домашняя папка, которая расположена в $SNAP_USER_DATA совпадает с путём к platform. Нуёптвоюмать! Нужна срочно ещё папка для записи. Недавно введена папка, которая не поддерживает версионность, и доступна через переменную $SNAP_USER_COMMON = /home/$user/snap/$app-name/common/. Но вызов в скрипте run.sh
mkdir -p "$SNAP_USER_COMMON"
вызывал отказ в доступе. Кинулся к разрабам в почтовой рассылке - ответ просто убил. Это типа бага, пока вызывайте snap run ossdm; ossdm . Хорошо что я плохо выражаю свои мысли на английском и тем более отборные маты. Ну как так-то? Вместо красивого вызова программы osddm, просить пользователя однократно вызывать snap run ossdm; ossdm ? И где мне это просить? Быть в шаге от победы и отложить на неопределённый срок упаковку программы, которая готова на 99,99%. Р-р-р.
Так просто не сдамся, вдумчиво старался понять последний вызов мне. Что точно не нравится Oracle SQL Developer Data Modeler? Осенило, что ему не нравится тот факт, что папка $SNAP_USER_DATA/platform/ НА ОДНОМ УРОВНЕ иерархии с папкой $SNAP_USER_DATA/.oraclesqldeveloperdatamodeler/. Окей, бэби! Сдвигаю папку platform вглубь - $/deep/platform/. Бинго! Oracle SQL Developer Data Modeler милостиво дал добро и запустился во всей красе. Прошёл эту игру, замочил босса на уровне.
В процессе тестирования работы программы в ограниченной профилями AppArmor среде вырисовалась маленькая шероховатость. Oracle SQL Developer Data Modeler при сохранении вашей работы, пытается осуществлять частичную запись в каталог, откуда он стартовал и естественно в этом ему отказано. Оказалось есть переменные в конфигурационном файле, которые помогут переопределить нужные папки. Это переменная def_sys_types_path. Создал дефолтный прообраз будущего конфигурационного файла ddm/opt/datamodeler/userfiles/product-preferences.xml и значения заполнил метками, которые заменит sed при первом старте программы.
В run.sh есть строки
Манипуляции с параметром instanceGuid нужны, чтобы у разных пользователей был различный UUID, что важно в определённых местах. Хотелось сделать всем красиво. Разные UUID - это правильно.
Всё ли сделано? Из задуманного - всё. Программа корректно стартует и работает, сохраняя результаты пользователя. В данный момент можно получить через процедуру Update много вкусняшек к программе (
1,5 Гб), но корректно установить нельзя, так как каталог программы доступен только на чтение. Поэтому временно отключил проверку обновлений на старте. Такой серьёзный вызов требует серьёзного подхода и оставлен на вторую битву с Oracle SQL Developer Data Modeler. Нужно разместить скачанное в $SNAP_USER_DATA и подключить к программе. Постараюсь реализовать, но не обещаю, что справлюсь с таким вызовом.
Читайте также: