
Oracle ebr что это
Обновлено: 07.07.2024
Деев Илья » Чт окт 20, 2011 9:30 pm
Новый код можно расположить в новом EDITION - некоем отдельном слое для PL/SQL кода.
Для создания нового EDITION нужно выполнить команду:
Код: Выделить всё create edition ver_01 as child of ora$base;
ora$base - EDITION по умолчанию
Пара слов о терминологии - я использую исходный термин EDITION, поскольку слово версия как-то путается с понятием версии, относящейся к объектам, например к версии пакета в разных EDITIONS.
Можно было бы перевести - "редакция", но как-то тоже не так звучит. Однако, Валерий Юринский, например, перевел этот термин именно как "версия". Может быть, стоит говорить "версия PL/SQL кода" или просто "версия кода".
Далее - дадим гранты всем пользователям, которым необходимо пользоваться новой версией
Код: Выделить всё grant use on edition ver_01 to <usr>; .
Мы работаем с базой, в основном, через PL/SQL Developer (PLSD). Для работы с новой редакцией кода во всех окнах
в меню выбираем Tools -> Preferences -> Connection -> Session Mode: Single session. Сохраняем настройку.
После этого запускаем новый инстанс PL/SQL Developer.
Далее задаем EDITION:
Код: Выделить всё alter session set edition = <ver_01>;
В режиме dual и multi session только текущая сессия будет в этом случае работать с заданным EDITION, остальные будут брать EDITION по умолчанию, который можно узнать через запрос:
Код: Выделить всё select property_value from database_properties where property_name = 'DEFAULT_EDITION'
Т.е. при открытии пакета, например, через название и контекстное меню, либо через окно браузера PL/SQL Developer'а будет открываться версия пакета, соответствующая EDITION по умолчанию.
То же самое касается не только браузера объектов, но и других окон, например, окна компиляции объектов, помеченных как INVALID.
В качестве варианта, можно прописать команду по выбору EDITION в скрипте AfterConnect.sql в каталоге PLSD. После этого нужно не забыть перезапустить PLSD.
В этом случае необязательно работать в режиме single session, т.к. нужный EDITION установится при открытии каждой сессии. Но потом нужно не забыть убрать эту команду и перезапустить PLSD (если переключение на заданный EDITION уже не требуется).
Нужно внимательно следить за тем, какой EDITION используется. Было бы классно внедрить в PLSD поддержку EBR (попросил об этом на форуме AllroundAutomations). А пока приходится изощряться.
Проследить за версией в текущей сессией можно запросами:
Код: Выделить всё select sys_context('userenv','current_edition_name') from dual; -- текущая выбранная (возможно, вручную) редакция сессии
select sys_context('userenv','session_edition_name') from dual; -- редакция, установленная в начале работы сессии
Далее применяем скрипты и создаем пакеты в новом EDITION.
Стоит заметить, что в случае существенных изменений структцры данных могут понадобиться т.н. crossedition-triggers, которые помогают заполнять данные в нужном виде при изменениях, выполняемых в разных EDITION'ах. Мы такие триггеры пока не использовали.
Здесь нужно соблюдать большую осторожность, т.к. некоторые простые привычные вещи перестают работать.
Например, снятие и установка у колонки таблицы свойства NOT NULL приводит к пометке EDITIONING VIEW как INVALID и соответствующей пометке INVALID у пакетов, зависящих от него. Как следствие - потеря состояния пакетов.
Казалось бы - EDITIONING VIEW сделан для того, чтобы защититься от влияние изменений таблиц, однако, в этом случае происходит все наоборот! То, что не вызывает никаких проблем при изменении свойств колонки в обычном случае, в нашем приводит к проблемам.
Думаю, нужно оформить запрос в техподдержке Oracle.
Далее, компилируем все INVALID-пакеты:
Код: Выделить всё -- Данные с установленным в сессии EDITION
-- спецификации
select 'alter package '||owner||'.'||object_name||' compile reuse settings;'
from dba_objects o
where o.object_type = 'PACKAGE' and STATUS = 'INVALID';
-- выполнить полученный скрипт.
-- тела
select 'alter package '||owner||'.'||object_name||' compile body reuse settings;'
from dba_objects o
where o.object_type = 'PACKAGE BODY' and STATUS = 'INVALID';
-- выполнить полученный скрипт.
Другая важная проблема - зависимости между пакетами. При использовании EbR нужно обязательно выполнить какой-то метод каждого пакета, чтобы для каждого из пакетов, при необходимости, создалась его версия в новом EDITION.
Дело в том, что если один пакет зависит от другого, имеющего версию в новом EDITION и при этот пакет (который зависит) еще не выполнялся, его версия не появляется до первого обращения к нему.
В принципе, можно вычислить зависимости и скомпилировать нужные пакеты вручную. Но у нас у каждого пакета есть служебная функция, возвращающая его внутреннюю версию, поэтому нам достаточно выполнить скрипт, который просто запрашивает эти версии.
Формирование такого скрипта происходит запросом:
Код: Выделить всё select 'select '||a.owner||'.'||package_name||'.get_ver from dual;' from dba_arguments a where a.object_name = 'GET_VER';
Если не сделать такой предварительной операции, пакеты начнут появляться в новом EDITION при работе системы, что может привести к множеству проблем с блокировками и перекомпиляцией пакетов по ходу работы.
Проводя запрос версии нашим скриптом, мы получаем все нужные пакеты в новом EDITION автоматически. Таким образом, в новом EDITION появляются даже те пакеты, текст которых не менялся! Остальные "наследуются" из предыдущего EDITION'а, т.е. их код берется из предыдущего EDITION.
Таким образом, в конце концов мы становимся готовы в любой момент переключиться на новый код.
Предварительно можно убедиться в его работоспособности, потестировать, если есть такая возможность. В нашем случае, например, есть тестовые лицевые счета, операции по которым не учитываются в системе.
Следующим этапом нужно переключиться на новый EDITION.
Деев Илья » Ср окт 26, 2011 8:38 pm
Переключение.
Итак, код задеплоен, оттестирован, ждем момента переколючения.
Когда наступает час X, остается выполнить команду переключения на новый EDITION:
Код: Выделить всё alter database default edition = VER_2011_19;
В нашем случае задача переключения на новую версию кода облегчается тем, что у нас довольно легко рестартовать пулы сессий. Т.е. мы обычно не закладываемся на продолжительную работу сессий в разных EDITIONS.
После выполнения переключения в базе все пулы рестартуют и используют код нового EDITION.
В принципе, можно добиться такого эффекта и без рестарта сессий, однако, для этого нужно в какие-то часто используемые участки кода внедрить вызов проверки необходимости переключения. Мы решили обойтись без этого.
Что интересно отметить, возможно, в силу каких-то соображений по оптимизации, не все запросы начинают использоваться из нового кода.
Если запросы не менялись, они зачастую берутся из старого кода. Причем, что особенно интересно, это происходит даже после перезагрузки сервера. Т.е. дело не только в том, что в памяти уже загружен код пакетов предыдущего EDITION.
Посмотреть, запросы из каких EDITIONS находятся в v$sql, можно так:
Код: Выделить всё -- запросы в коде разных версий
select o.edition_name, count(*)
from v$sql s
, dba_objects_ae o
where s.parsing_schema_name in (<schema list>)
and o.object_id = s.program_id
group by o.edition_name;
Запросы, которые относятся к объектам, версии которых есть в новом EDITION:
Код: Выделить всё select o.edition_name, count(*)
from v$sql s
, dba_objects_ae o
where s.parsing_schema_name in (<schema list>)
and o.object_id = s.program_id
and o.edition_name = '<OLD EDITION>'
and exists (select 1
from dba_objects_ae o2
where o2.owner = o.owner
and o2.object_name = o.object_name
and o2.object_type = o.object_type
and o2.edition_name = '<NEW EDITION>')
group by o.edition_name;
В нашем случае, после вчерашнего деплоя нового кода, получается, что работает 283 запроса из _позапрошлого_ EDITION!
К чему это может привести, например, в случае добавления колонки к таблице и соответствующему editioning view?
Каждый раз при выполнении запроса появляется еще одна версия запроса в библиотечном кеше.
В v$sql_shared_cursor в поле SQL_TYPE_MISMATCH прописывается 'Y'.
В конце концов появляются MUTEX'ы, которые поднимают потребление CPU до очень высоких значений, база зависает.
Боролись очисткой запросов в кеше с помощью
Код: Выделить всё sys.dbms_shared_pool.purge(to_char(v$sql.address)||', '||to_char(v$sql.hash_value),'c')
для запросов с большим кол-вом дублей
Однако, после неудачных попыток воспроизвести эту ситуацию, нужно признать, что такое странное поведение возникает не во всех случаях.
В тестах получалось, что возникала еще одна версия запроса (из версии пакета, принадлежащего предыдущему EDITION ), однако, она не дублировалась при каждом вызове.
Вероятно, причина в каком-то баге, проявляющемся только при определенных условиях.
Деев Илья » Чт окт 27, 2011 8:01 pm
Интересна схема перехода с заданием сервиса базы данных, у которого по умолчанию будет устанавливаться новый EDITION.
Например, новый EDITION называется VER_2011_19. Создадим и запустим сервис с одноименным названием:
Код: Выделить всё begin
dbms_service.create_service
( service_name => 'VER_2011_19',
network_name => 'VER_2011_19',
edition => 'VER_2011_19'
);
dbms_service.start_service('VER_2011_19');
end;
Теперь мы можем подключаться к базе с новым EDITION, не устанавливая его по умолчанию для всей базы, не переключаясь на него по триггеру, не вызывая явно команду alter session, а просто подключаясь через новый сервис. Очень удобный вариант!
Попробовали подключиться через JDBC к сервису, строка соединения должна выглядеть при этом примерно как "jdbc:oracle:thin:@//myhost:1521/service_name" - т.е. на конце указывается имя сервиса через "/". Почему-то во многих местах в документации фигурирует формат строки соединения через двоеточие в конце с ошибочным указанием, что это имя сервиса, в то время, как на самом деле через двоеточие указывается SID базы ("jdbc:oracle:thin:scott/tiger@<host>:<port>:<service>").
При обновлении софта на сайте можно в конфигурационных файлах задавать имя нового сервиса и все сессии будут использовать заданный EDITION.
Здесь нужно сказать, что обновление базы - это только одна сторона "блина". Вторая сторона - обновление софта на сайтах.
Безостановочным полное обновление всего софта может быть, если только каждый сайт расположен физически на нескольких машинах (работающих в одном кластере или ферме), при этом в процессе обновления сама машина должна быть временно недоступна для обычных пользователей.
После обновления софта и подключения к базе с использованием нового EDITION можно переходить на обновление следующей машины, и так по очереди. Таким образом будет достигаться синхронность начала использования новой версии софта на сайте и в базе.
Более всего интересен режим, при котором запросы из одной подсети идут на одну машину, а с других IP - на другие машины. В этом случае можно организовать тестирование нового софта на живой системе в то время, когда обычные пользователи продолжают работать.
Деев Илья » Чт ноя 03, 2011 4:52 pm
Что еще не работает с Edition-based Redefinition:
- GoldenGate пока не поддерживает EbR
- Пакет DBMS_ADVANCED_REWRITE (выдается ошибка о том, что объекты в запросе имеют версии). Вроде бы подобные проблемы есть и в VPD. Надо проверить.
- Пакет DBMS_SHARED_POOL может выдавать ошибку, когда при попытке закрепить пакет не находится его спецификация, которая находится в предыдущем EDITION.
.
Деев Илья » Пт дек 09, 2011 4:06 pm
Вылез страшный баг.
При выдаче грантов на editioning view разваливаются пакеты, которые зависят от него в этом же EDITION.
Буду оформлять SR.
Небольшие баги поменьше, но тоже неприятные - по странной причине при каждом выполнении некоторых запросов появляются новые child. Пока делаем purge по заданию.
Раньше такое вылезало, когда были добавления колонок, сейчас совершенно на ровном месте после перезагрузки сервера. ЧуднО.
Деев Илья » Сб апр 28, 2012 6:08 pm
Кстати, реально оказалось, что ситуация с грантами не баг, а баго-фича.
При выдаче гранта на editioning view версия этого view актуализируется, т.е. появляется в текущем edition, и, как следствие, все зависящие от него пакеты должны будут перекомпилироваться. Это описано в white paper по EBR Брином.
Выход видится в том, чтобы давать гранты в версии, соотвествующей последнему edition. Для этого у той схемы, которой выдается грант, должно быть право на использовании соответствующего edition.
Неудобно, однако!
В этом году бренду QIWI исполнилось 10 лет. За это время в нашей основной транзакционной базе накопилось более чем 130 тысяч строк хранимого PL/SQL кода. На Хабре регулярно встречаются статьи о том, как различные команды разработчиков категорически не используют хранимый код в БД, стараясь убрать излишнюю нагрузку с БД и таким образом удешевить систему. По этой теме можно долго дискутировать, и такая точка зрения опровергается, например, вот в этом видео.
Что бесспорно — хранимый PL/SQL код традиционно имел один существенный минус: релиз PL/SQL программы требовал остановки сервиса, поскольку процесс компиляции этого кода должен был получить эксклюзивную блокировку в словаре БД (так называемый library cache pin). Не вовремя запущенная случайная рекомпиляция могла подвесить всю систему. Приходилось регулярно выделять технические окна для релиза PL/SQL кода. Заверенные скриншоты жалоб наших возмущённых клиентов, попавших в такие окна, бережно хранятся в наших архивах. Однако не прошло и 20 лет от создания PL/SQL, как Oracle этот недостаток если не устранил полностью, то существенно смягчил.
Welcome to Oracle Edition-Based Redefinition
Мы не будем приводить детальные примеры кода с использованием Edition-Based Redefinition, а опишем несколько ключевых пунктов проекта по его внедрению. С некоторой натяжкой этот механизм, который принято сокращать до EBR, можно считать системой контроля версий объектов БД внутри самой БД. Теперь приложения способны работать с разными версиями одних и тех же процедур, пакетов и представлений. Однако в БД, кроме кода, есть еще и структуры данных в виде таблиц, и Oracle пришлось придумать способ межверсионной трансформации как самих таблиц, так и данных в них.
Сразу оговоримся, что наши разработчики используют EBR только для представлений (view) и PL/SQL кода, и не используют для таблиц. Предметная область хорошо изучена и структуры данных вполне стабильны. В течение года столбцы в горячих таблицах менялись или добавлялись от силы раз пять, при этом изменений кода было в десятки раз больше.
Приложение
Наше Java-приложение умеет само переключаться на использование новой версии PL/SQL кода. Текущий edition можно извлечь из базы таким нехитрым запросом:
Приложение хранит это значение и регулярно опрашивает базу, не изменилось ли оно.
Успешный релиз новой версии PL/SQL кода выполняет команду вида
а приложение, узнав, что edition изменился, в подходящий момент выполняет команду вида
и тем самым переключается на использование новой версии хранимого кода.
Теоретически возможен и откат PL/SQL кода на предыдущую версию – для этого надо выполнить команду alter database с установкой предыдущего edition, а приложение должно на него переключиться.
СУБД Oracle внутри крайне сложна, в её оптимизацию и развитие вложено столько человеко-лет, что любые новые возможности в её ядре не проходят безболезненно для остального функционала. Речь конечно же идёт о багах и устраняющих их патчах. EBR был вовсе не исключением, а, наоборот, существенным возмутителем спокойствия. Скажем так: без техподдержки обойтись невозможно.
К сожалению, отдельного списка патчей, устраняющих связанные с EBR баги, Oracle не ведёт. Однако Oracle активно использует EBR в одной из своих популярных ERP-систем – Oracle E-Business Suite (OEBS). Поэтому можно взять набор патчей, который Oracle рекомендует к установке на базу OEBS, и установить на вашу базу те из них, которые потенциально наиболее вероятны для вашего приложения. Найти его можно на сайте поддержки Oracle в Section 3 документа Oracle E-Business Suite Release 12.2: Consolidated List of Patches and Technology Bug Fixes (Doc ID 1594274.1)
Подводные камни
При работе с Oracle Edition-Based Redefinition мы нашли четыре недостатка:
- Ограничение на число editions, равное 2000. Со скоростью 2 релиза в неделю мы исчерпаем их за 20 лет. Надеемся, к тому времени Oracle сподобится-таки убрать это ограничение.
- Плоская, а не древовидная структура editions, 1 parent <–> 1 child. Нам это пока что никак не мешает.
- Не-версионируемые (non-editioned) объекты не могут ссылаться на версионируемые (например, в версии 11g такие объекты, как materialized view, являются non-editioned и не могут ссылаться на editioned view).
- Специфика в раздаче прав на версионируемый код.
Дело в том, что выдача прав на версионируемый объект, последний раз изменявшийся в каком-либо предыдущем edition, копирует этот объект в текущий edition, со всеми уже знакомыми нам симптомами перекомпиляции и, если не повезет, зависаниями на словарной блокировке library cache pin. По всей видимости, это связано с внутренней реализацией editioned схем в БД.
Поэтому процедуру раздачи прав пришлось слегка изменить: сначала мы находим edition, в котором искомый объект был изменен последний раз, устанавливаем этот edition в нашей сессии с помощью вышеописанной команды alter session, и лишь после этого выдаем нужные права.
Как говорится, не баг 26654363, а expected behavior. Что ж, обходной путь не слишком трудозатратен и с ним в подавляющем большинстве случаев можно ужиться.
Описание этих возможностей дано в самом конце документа
Oracle® Database. Advanced Application Developer's Guide. 11g Release 2 (11.2).
19. Edition-Based Redefinition
Вопрос:
Почему в нашем форуме практически нет вопросов, касающихся Edition-based Redefinition?
Мой ответ:
Это так потому, что данные возможности никем не используются (пока?).
Почему же они не используются?
- Разработчики и заказчики не знают об этих новых функциональных возможностях Oracle11g R2?
- Мало систем переведено на Oracle Database 11g R2?
- Критичная для бизнеса необходимость высокой доступности информационных систем – это миф, выгодно поддерживаемый продавцами компьютерного оборудования и программного обеспечения?
Предлагаю вашему вниманию их перевод, в том числе, с помощью слов, не существовавших ранее в языке русском. :-)
Если по существу, ответы на вопросы:
1. - Да
2. - Да
3. А зачем вообще здесь это вопрос?
1. Переименовать таблицы
2. Создать версионирующие представления этих таблиц в рамках "старой" версии
3. Перекомпилировать объекты, зависившие от таблиц
4. Перенести DML-триггеры с таблиц на соответствующие версионирующие представления
1. Переименовать таблицы
2. Создать версионирующие представления этих таблиц в рамках "старой" версии
3. Перекомпилировать объекты, зависившие от таблиц
4. Перенести DML-триггеры с таблиц на соответствующие версионирующие представления
Плюс, не забываем, что приложения не только самописные, но и разработанные сторонним производителем. А там все просто -- есть четкий регламент апгрейда, не соблюдаем (а приложите, пожалуйста, лог) -- о какой поддержке тогда может идти речь?
| Rules for Editioned Objects |
|---|
| A materialized view cannot depend on an editioned view |
(Именно это вы и так делаете сейчас)
| Rules for Editioned Objects |
|---|
| A table cannot have a column of a user-defined data type (collection or ADT) whose owner is editions-enabled |
определенный в другой схеме, принадлежащей пользователю,
который не имеет версионных полномочий.
Фича официально появилась почти 2 года назад в Oracle 11.2, то есть не такая уж она новая.
- Разработчики и заказчики не знают об этих новых функциональных возможностях Oracle11g R2?
- Мало систем переведено на Oracle Database 11g R2?
- Критичная для бизнеса необходимость высокой доступности информационных систем – это миф, выгодно поддерживаемый продавцами компьютерного оборудования и программного обеспечения?

В эпоху дешевого дискового хранилища, высокоскоростного интернет-соединения и огромного увеличения вычислительной мощности сбор даже больших объемов данных стал настолько невероятно простым. Однако простые данные сбора не раскрывают его бизнес-ценность. Чтобы превратиться в значимую информацию, данные должны обрабатываться и анализироваться.
Ключевые слова: Oracle, прокси-объекты, Oracle Enterprise R, базы данных, Oracle Advanced Analytics, SQL.
Известная своей способностью эффективно работать с большими объемами данных, база данных (БД) Oracle идеально подходит для размещения тех магических, но ресурсоемких процедур, которые могут получать значимую ценность из необработанных данных, тем самым реализуя концепцию перемещения обработки данных ближе к данным. Oracle Enterprise R, являющийся компонентом опции Oracle Advanced Analytics для БД Oracle, превращает эту концепцию в реальность, предоставляя основу для интеграции R — языка статистического программирования с открытым исходным кодом, который лучше всего подходит для анализа данных — с БД Oracle, производительность в исполнении в базе данных команд и скриптов R.
Знакомство с Oracle Enterprise R требует, чтобы вы поняли, как это работает и как вы можете эффективно использовать его. Хорошая структура, которой следует следовать при обучении Oracle Enterprise R, включает:
- Уровень прозрачности, который позволяет пользователям:
‒ Использовать прокси-объекты — данные остаются в базе данных.
‒ Использовать перегруженные функции R, которые переводят функциональность в SQL
‒ Использовать стандартный синтаксис R для управления данными базы данных
- Параллельные распределенные алгоритмы, которые позволяют пользователям:
‒ Улучшение масштабируемости и производительности
‒ Использовать в базе данных алгоритмы из ODM
‒ Использовать дополнительные алгоритмы на основе R, выполняемые на сервере базы данных
- Выполнение Embedded R, которое позволяет пользователям:
‒ Хранить и вызывать скрипты R в базе данных Oracle
‒ Выполнять параллельное и непараллельное выполнение данных
‒ Использовать пакеты CRAN с открытым исходным кодом
Будучи языком статистического программирования, R предсказуемо предлагает богатый набор инструментов для анализа данных. Oracle Enterprise R расширяет эту функциональность, введя набор объектов и функций для эффективной работы с данными, хранящимися в базе данных Oracle [1, с. 285].
Oracle Enterprise R предоставляет возможность доступа к таблицам базы данных в виде R data.frames и подталкивать R data.frames к базе данных в виде таблиц, создавая соответствующие прокси-объекты Oracle R Enterprise, которые нужно манипулировать в языке R. Использование прокси-объектов для таблиц позволяет преодолеть память ограничения сеанса клиента R и использование мощности обработки сервера базы данных при выполнении операций анализа данных. Фактически, Oracle Enterprise R перегружает множество стандартных функций R, чтобы они трансформировали операции R в SQL, которые выполняются в базе данных.
Схематически это может выглядеть так [2, с. 1024], как показано на рис. 1.
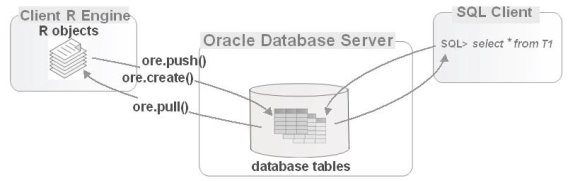
Рис. 1. Oracle Enterprise R позволяет придвигать объекты R в базу данных в виде таблиц, вытаскивать данные обратно в R (при желании) и перегружать функции R, чтобы неявно переводить операции R в SQL для взаимодействия с этими таблицами
Когда сеанс клиента R отключается от базы данных, все несохраненные временные таблицы, созданные для объектов R, перемещаемых во время сеанса, автоматически удаляются. Если вы хотите создать объекты proxy ore.frame для постоянных таблиц базы данных, вы можете использовать функцию ore.create. Такой подход может быть очень полезен для случаев, когда вы хотите получать доступ к своим данным не только с помощью R, но также и с SQL и выполнять вычисления в базе данных.
Важным ограничением извлечения данных в R является то, что вы можете вытащить таблицу базы данных или просмотреть в R-кадр данных только в том случае, если данные могут вписаться в локальную память сеанса R. Это может быть проблемой, когда дело доходит до больших наборов данных. Более того, нет причин для вытягивания, если вы планируете подавать набор данных в одну или несколько функций ORE [3, с. 588]. Oracle R Enterprise (ORE) входит в опцию Oracle Advanced Analytics. Oracle R Enterprise позволяет использовать язык R для бесшовной интеграции с Oracle Database, позволяя использовать мощь и масштабируемость базы данных Oracle. С помощью Oracle R Enterprise вы можете быстро и легко перенести свою расширенную аналитику R для использования базы данных Oracle с минимальными изменениями кода в своих R-сценариях. Наличие языка R в качестве элемента кода Oracle Database значительно расширяет статистические, аналитические и графические возможности Oracle Database.
Oracle предлагает 4 основных решения, основанных на языке R:
‒ Oracle R Enterprise: это версия языка R, которая была создана для работы в составе базы данных Oracle. Это позволяет запускать ваш R-код и скрипты в Oracle Database, используя производительность и масштабируемость сервера Oracle Database.
‒ R Oracle: пакет R, который позволяет вам подключаться к базе данных Oracle. Этот пакет специально настроен для использования Oracle Net для обеспечения эффективной связи с Oracle Database и для сверхбыстрого перемещения данных между клиентской машиной и Oracle Database.
‒ Oracle R Distribution: это настраиваемая версия языка R с открытым исходным кодом, которая предоставляется бесплатно Oracle. С Oracle R Distribution Oracle настроила определенные пакеты и функции для эффективной работы с Oracle Database.
‒ Oracle R Advanced Analytics для Hadoop: это позволяет запускать ваш R-код для доступа и запуска на Hadoop с использованием рамок программирования MapReduce для пользователей R. Этот пакет является частью программного пакета Oracle Big Data Connectors Software Suite [4, с. 98].
Когда вы работаете над вашими научными проектами, вы, как правило, создаете несколько временных объектов. При работе с R они сохраняются в вашей локальной среде. Но когда вы работаете с вашими данными (большими или малыми) и используя Oracle R Enterprise для работы с данными в базе данных, вы можете открыть для вас три основных варианта для сохранения этих временных объектов. Первый вариант — сохранить их на локальном компьютере. Но по мере роста объемов данных это может стать проблемой. Кроме того, это также проблема безопасности данных, так как в конечном итоге вы будете обрабатывать различные части данных вашего предприятия, расположенные на локальных машинах. Это может не быть проблемой для небольшой команды, но если это средние и большие, то это может стать проблемой. Второй вариант — хранить временные объекты в таблицах в базе данных. Это может быть не идеальным, поскольку вы будете смешивать основные данные с временными рабочими наборами данных. Опять же, как растет ваша научная команда, это может стать проблемой, поскольку вы не будете знать, что является основным, а что нет. Третий вариант — использовать и ORE Data Store. Это позволяет хранить эти временные объекты вместе в базе данных, но отдельно от основных данных, над которыми вы работаете. В дополнение к различным подсистемам данных вы также можете использовать хранилище данных ORE для хранения множества других объектов R.
При работе с временными объектами ORE они будут существовать только на время ваших соединений. Поэтому, когда вы отключите сеанс ORE, все временные объекты, созданные в базе данных, также будут удалены и удалены из базы данных. Было бы полезно, если бы мы могли сохранить эти временные объекты для последующего использования без необходимости выполнять дополнительные шаги по созданию таблиц для хранения данных. Кроме того, с использованием ORE вы можете создавать другие типы объектов, такие как модели интеллектуального анализа данных, которые мы хотим использовать позже. То, что мы не хотим делать, — это повторить шаги по созданию этих объектов снова и снова [5, с. 79].
С помощью Oracle R Enterprise мы можем создать и ORE Data Store в нашей базе данных. В этом хранилище данных ORE мы можем хранить все эти объекты ORE, которые мы создали. Мы можем совместно использовать хранилище данных ORE с другими аналитиками и учеными-аналитиками данных, но, возможно, самой важной особенностью хранилища данных ORE является то, что мы можем использовать его, когда мы выполняем встроенное выполнение ORE в SQL.
Примеры, приведенные в этой статье, касаются создания хранилища данных ORE, сохранения объектов в нем, поиска объектов, получения информации о хранилище данных ORE, удаления объектов и, наконец, удаления хранилища данных ORE.
Идея состоит в том, что пользователь R сохраняет свой знакомый набор инструментов, как правило, что-то вроде RStudio, но теперь может использовать аналитическую и вычислительную мощь масштабирования базы данных для больших наборов данных и использовать встроенный параллелизм оптимизатора базы данных. ORE на самом деле также включает разъемы hadoop, но в этой статье я сосредоточусь только на функциях базы данных.
Ключевыми особенностями ORE являются:
‒ Вызов базы данных, встроенный R из R
‒ Вызов базы данных, встроенный R из SQL
‒ Легкая визуализация анализа
Эта статья намеревается показать два варианта для начала работы с ORE. Большая виртуальная машина BigDataLite, которая на сегодняшний день является самой простой, и выполняет «обычную» установку, которая дает больше информации о внутренней работе ORE [6, с. 24].
R-дистрибутив и ORE, установленные таким образом, попытаются подключиться к архиву CRAN или одному из его зеркал. При установке пакетов с использованием «install.packages» система запустит GCC, скомпилировав все его зависимости и установив их на ОС хоста базы данных. Это отлично подходит для быстрых экспериментов, но если ORE предназначен для использования в качестве «производства», убедитесь, что эта настройка совместима и что системные администраторы знают и способны управлять пакетами. В худшем случае вам может понадобиться локальное проверенное зеркало CRAN, из которого вам разрешено устанавливать пакеты.
Часть R в базе данных порождает процессы R, используя EXTPROC на узлах (узлах) базы данных. В большой степени это замечательно, так как позволяет этим пакетам CRAN работать независимо от конкретной доступности объектов и алгоритмов в самой базе данных, тем самым расширяя аналитические возможности. Однако это также означает, что сам механизм базы данных не имеет «реального» контроля над этими процессами и их многопоточности или параллелизма (или их отсутствия). Преимущества параллелизма базы данных связаны с преобразованием объектов R в объекты ORE, что позволяет оптимизатору базы данных работать со своей магией.
Выполнение встроенного R, либо через R, либо SQL, позволяет разделить данные и управлять количеством процессов R, начатых для обработки этих разделов. Таким образом, достигается большая степень параллелизма в сочетании с параллельным вариантом в самой базе данных. Вся обработка выполняется на узлах базы данных, чтобы они могли мешать друг другу. Относительная простота импорта данных и перенос их в базу данных потенциально могут стать альтернативным инструментом ETL. Будьте осторожны, хотя происходит некоторое неявное преобразование типов. Преимущества производительности с использованием ORE непосредственно на данных оракула по-прежнему в значительной степени зависят от тщательного моделирования. Если ORE применяется к плохой модели данных, мы получаем плохие результаты, даже при использовании встроенного механизма R. Потенциал заключается в том, что промежуточные результаты обычно не нужно возвращать в рабочее пространство R для дальнейшей обработки, что ограничивает стоимость транспортировки данных [6, с. 214].
В этой статье вы рассмотрели, что такое Oracle Enterprise R — это надстройка над языком, которая позволяет использовать мощь СУБД Oracle для анализа на языке R больших объемов данных. Кроме того, Oracle Enterprise R делает возможным не выносить данные из базы данных для анализа, что очень важно для больших промышленных СУБД, как Oracle R Enterprise соединяет R с базой данных Oracle, обеспечивая возможность переноса большой обработки данных, выполняемой функциями R на сервер базы данных. Вы узнали, что Oracle Enterprise R перегружает многие функции R, так что построенная модель в R может использовать преимущества и возможности обработки сервера баз данных, такие как параллелизм.
В этой статье вы рассмотрели, что такое Oracle Enterprise R — это надстройка над языком, которая позволяет использовать мощь СУБД Oracle для анализа на языке R больших объемов данных. Кроме того, Oracle Enterprise R делает возможным не выносить данные из базы данных для анализа, что очень важно для больших промышленных СУБД, как Oracle R Enterprise соединяет R с базой данных Oracle, обеспечивая возможность переноса большой обработки данных, выполняемой функциями R на сервер базы данных. Вы узнали, что Oracle Enterprise R перегружает многие функции R, так что построенная модель в R может использовать преимущества и возможности обработки сервера баз данных, такие как параллелизм.
Читайте также: