
Oracle etl что это
Обновлено: 03.07.2024
ETL-разработчик — это одно из направлений работы в IT - сфере. Данный специалист занимается управлением хранилищами данных: он отвечает за консолидацию, федерализацию и обмен данными.
ETL происходит из английских слов : «to Extract», «to Transform», «to Load», то есть « И звлекать», « П реобразо вы вать», « З агружать».
ETL - разработчик в действии
- Нужно извлекать данные из внешних источников.
- Преобразовывать эти данные согласно имеющейся бизнес-модели.
- Загружать преобразованные данные в собственное хранилище данных.
- Часто источниками данных являются очень разносторонние системы хранилищ данных с разными форматами самих данных. А это влечет за собой знание различных процедур извлечения этих данных. Иногда бывает, что внутри одной информационной системы данные извлекаются разными путями.
- Данные с разных источников и разных форматов должны быть приведены в единый вид, который регламентируется собственными бизнес-правилами, единством применяемых систем кодирования, используемыми классификаторами и справочниками.
- При извлечении и преобразовании данных всегда нужно учитывать особенности компании, где работает ETL - разработчик, зачастую это добавляет дополнительные сложности в и т ак непростую работу.
ETL - разработка в действии
- Облачные хранилища. В данном случае ETL - разработчик работает с облачными хранилищами, которые удешевляют процесс хранения данных и позволяют легко масштабировать и защищать облачный продукт. Часто такой процесс завязан с каким-нибудь приложением.
- Базы данных. Работа с обычными базами данных, где ETL - developer — это тот , кто отвечает за перемещение данных в хранилища.
- Машинное обучение. При машинном обучении приходится часто работать с большими объемами данных. ETL применяется для миграции данных из разных источников в одно хранилище, которым пользуются для машинного обучения.
- Маркетинговые данные. Часто крупным компаниям необходимо провести маркетинговое исследование , и поэтому им необходимо переместить в одно хранилище данные из разных источников: веб-аналитика, со цс ети, данные о клиентах, о продажах и т. д.
- Данные от IoT. Если в системе IoT подключено очень много датчиков, собирающих данные, то часто для их анализа такие данные собираются в одном месте. За этот «сбор» данных отвечает ETL - разработчик.
- Синхронизация данных. К примеру , данные из обычных баз копируются в облачные хранилища. При обновлении данных в обычных хранилищах их нужно обновлять и в облаке. За этот процесс синхронизации тоже может отвечать ETL - разработчик.
- Аналитика бизнеса. Часто топ -менеджменту больших компаний нужно проводить анализ показателей собственного бизнеса. В больших бизнес-организациях очень много источников таких данных. За сбор информации в одном месте из разносторонних областей бизнеса отвечает ETL - разработка.
Системный инструмент ETL
- Cloud BigData.
- IBM InfoSphere.
- Power Center.
- MicrosoftSQLServer.
- Open Text.
- OracleGoldenGate.
- PervasiveDataIntegrator.
- PitneyBowes.
- SAPBusinessObjects.
- Sybase.
- И др.
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
- Как случайные ошибки, возникшие на уровне ввода, переноса данных, или из-за багов;
- Как различия в справочниках и детализации данных между смежными ИТ-системами.
- Привести все данные к единой системе значений и детализации, попутно обеспечив их качество и надежность;
- Обеспечить аудиторский след при преобразовании (Transform) данных, чтобы после преобразования можно было понять, из каких именно исходных данных и сумм собралась каждая строчка преобразованных данных.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
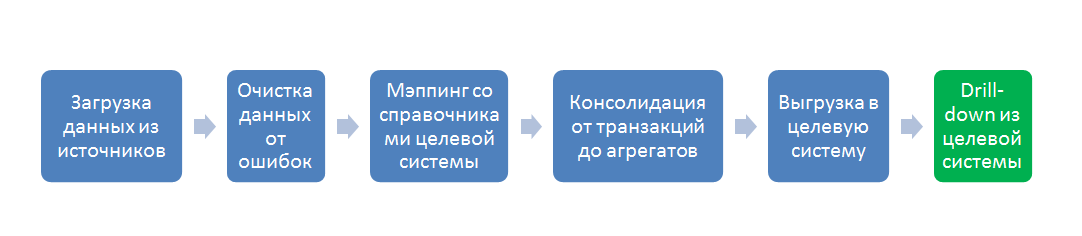
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
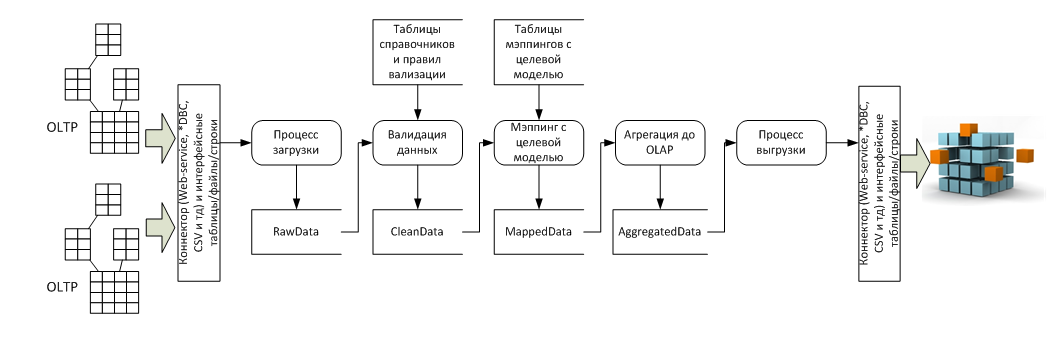
- Процесс загрузки – Его задача затянуть в ETL данные произвольного качества для дальнейшей обработки, на этом этапе важно сверить суммы пришедших строк, если в исходной системе больше строк, чем в RawData то значит — загрузка прошла с ошибкой;
- Процесс валидации данных – на этом этапе данные последовательно проверяются на корректность и полноту, составляется отчет об ошибках для исправления;
- Процесс мэппинга данных с целевой моделью – на этом этапе к валидированной таблице пристраивается еще n-столбцов по количеству справочников целевой модели данных, а потом по таблицам мэппингов в каждой пристроенной ячейке, в каждой строке проставляются значения целевых справочников. Значения могут проставляться как 1:1, так и *:1, так и 1:* и *:*, для настройки последних двух вариантов используют формулы и скрипты мэппинга, реализованные в ETL-инструменте;
- Процесс агрегации данных – этот процесс нужен из-за разности детализации данных в OLTP и OLAP системах. OLAP-системы — это, по сути, полностью денормализованная таблица фактов и окружающие ее таблицы справочников (звездочка/снежинка), максимальная детализация сумм OLAP – это количество перестановок всех элементов всех справочников. А OLTP система может содержать несколько сумм для одного и того же набора элементов справочников. Можно было-бы убивать OLTP-детализацию еще на входе в ETL, но тогда мы потеряли бы «аудиторский след». Этот след нужен для построения Drill-down отчета, который показывает — из каких строк OLTP, сформировалась сумма в ячейке OLAP-системы. Поэтому сначала делается мэппинг на детализации OLTP, а потом в отдельной таблице данные «схлопывают» для загрузки в OLAP;
- Выгрузка в целевую систему — это технический процесс использования коннектора и передачи данных в целевую систему.
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
- Надо учитывать требования бизнеса по длительности всего процесса. Например: Если данные должны быть загружены в течение недели с момента готовности в исходных системах, и происходит 40 итераций загрузки до получения нормального качества, то длительность загрузки пакета не может быть больше 1-го часа. (При этом если в среднем происходит не более 40 загрузок, то процесс загрузки не может быть больше 30 минут, потому что в половине случаев будет больше 40 итераций, ну или точнее надо считать вероятности:) ) Главное если вы не укладываетесь в свой расчет, то не надейтесь на чудо — сносите и все, делать заново т.к. вы не впишитесь;
- Данные могут загружаться набегающей волной – с последовательным обновлением данных одного и того-же периода в будущем в течение нескольких последовательных периодов. (например: обновление прогноза окончания года каждый месяц). Поэтому кроме справочника «Период», должен быть предусмотрен технический справочник «Период загрузки», который позволит изолировать процессы загрузки данных в разных периодах и не потерять историю изменения цифр;
- Данные имеют обыкновение быть перегружаемыми много раз, и хорошо если будет технический справочник «Версия» как минимум с двумя элементами «Рабочая» и «Финальная», для отделения вычищенных данных. Кроме-того создание персональных версий, одной суммарной и одной финальной позволяет хорошо контролировать загрузку в несколько потоков;
- Данные всегда содержат ошибки: Перезагружать весь пакет в [50GB -> +8] это очень не экономно по ресурсам и вы, скорее всего, не впишитесь в регламент, следовательно, надо грамотно делить загружаемый пакет файлов и так проектировать систему, чтобы она позволяла обновлять пакет по маленьким частям. По моему опыту лучший способ – техническая аналитика «файл-источник», и интерфейс, который позволяет снести все данные только из одного файла, и вставить вместо него обновленные. А сам пакет разумно делить на файлы по количеству исполнителей, ответственных за их заполнение (либо админы систем готовящие выгрузки, либо пользователи заполняющие вручную);
- При проектировании разделения пакета на части надо еще учитывать возможность так-называемого «обогащения» данных (например: Когда 12 января считают налоги прошлого года по правилам управленческого учета, а в марте-апреле перегружают суммы на посчитанные по бухгалтерскому), это решается с одной стороны правильным проектированием деления пакета данных на части так, чтобы для обогащения надо было перегрузить целое количество файлов (не 2,345 файла), а с другой стороны введением еще одного технического справочника с периодами обогащения, чтобы не потерять историю изменений по этим причинам).
Процесс валидации
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
- Не из списка разрешенных значений
- Отсутствие обязательных значений
- Не соответствие формату (Все договора должны нумероваться «ДГВxxxx..»)
- Не из списка разрешенных значений для связанного элемента
- Отсутствие обязательных элементов для связанного элемента
- Не соответствие формату для связанного элемента(например: для продукта «АИС» все договора должны нумероваться «АИСxxxx..»)
- Символы допустимые в одном формате, недопустимы в другом
- Кодировка
- Обратная совместимость (Элемент справочника был изменен в целевой системе без добавления мэппинга)
- Новые значения (нет мэппинга)
- Устаревшие значения (не из списка разрешенных в целевой системе)
- Не число
- Не в границах разрешенного интервала значений
- Пропущено порядковое значение (например: данные не дошли)
- Не выполняется отношение y=ax+b (например: НДС и Выручка, или Встречные суммы равны)
- Элементу «А» присвоен неправильный порядковый номер
- Разницы за счет разных правил округления значений (например: в 1С и SAP никогда не сходится рассчитанный НДС)
- Переполнение
- Потеря точности и знаков
- Несовместимость форматов при конвертации в не число
- День недели не соответствует дате
- Сумма единиц времени не соответствует из-за разницы рабочие/не рабочие/праздничные/сокращенные дни
- Несовместимость формата даты при передаче текстом (например: ISO 8601 в UnixTime, или разные форматы в ISO 8601)
- Ошибка точки отсчета и точности при передаче числом (например: TimeStamp в DateTime)
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
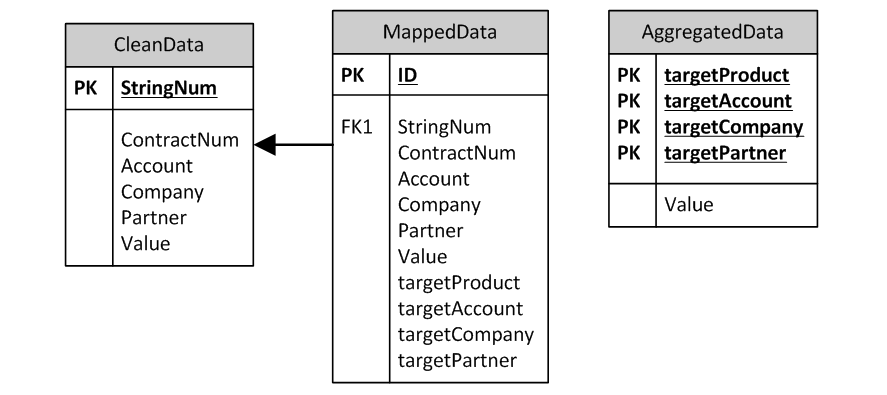
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
-
Таблица замэпленных данных должна включать одновременно два набора полей – старых и новых аналитик, чтобы можно был сделать select по исходным аналитикам и посмотреть, какие целевые аналитики им присвоены, и наоборот:
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
Ниже приведен отобранный список инструментов ETL с их популярными функциями и ссылками на веб-сайты. Список содержит как открытое (бесплатное), так и коммерческое (платное) программное обеспечение.
1) Клей AWS

Особенности:
- Автоматическое обнаружение схемы
- Этот инструмент ETL автоматически генерирует код для извлечения, преобразования и загрузки ваших данных.
- Задания AWS Glue позволяют запускать по расписанию, по запросу или на основе определенного события.
2) Алуома

Особенности:
- Обеспечить современный подход к миграции данных
- Инфраструктура Alooma соответствует вашим потребностям.
- Это поможет вам решить ваши проблемы с конвейером данных.
- Создавайте коллажи для анализа транзакционных или пользовательских данных с любым другим источником данных.
- Объедините хранилища данных в одном месте, независимо от того, находятся они в облаке или локально.
- Легко помогает захватить все взаимодействия.
3) Стежка

Особенности:
- Он предлагает вам возможность защищать, анализировать и управлять вашими данными, централизуя их в вашей инфраструктуре данных.
- Обеспечить прозрачность и контроль вашего конвейера данных
- Добавить несколько пользователей в вашей организации
4) Fivetran

Особенности:
- Помогает создавать надежные автоматизированные конвейеры со стандартизированными схемами.
- Добавление новых источников данных так быстро, как вам нужно
- Не требуется обучение или пользовательское кодирование
- Поддержка BigQuery, Snowflake, Azure, Redshift и т. Д.
- Доступ ко всем вашим данным в SQL
- Полная репликация по умолчанию
5) Матиллион

Особенности:
- ETL-решения, которые помогут вам эффективно управлять своим бизнесом
- Программное обеспечение поможет вам разблокировать скрытые значения ваших данных.
- Достигайте результатов своего бизнеса быстрее с помощью решений ETL
- Помогает вам подготовить ваши данные для аналитики данных и инструментов визуализации
6) Streamsets
Программное обеспечение StreamSets ETL, которое позволяет доставлять непрерывные данные в каждую часть вашего бизнеса. Он также обрабатывает смещение данных с помощью современного подхода к проектированию и интеграции данных.

Особенности:
- Превратите большие данные в идеи всей организации с помощью Apache Spark.
- Позволяет выполнять массовую обработку ETL и машинного обучения без необходимости использования языка Scala или Python.
- Работайте быстро с единым интерфейсом, который позволяет проектировать, тестировать и развертывать приложения Spark
- Он предлагает лучшую видимость исполнения Spark с помощью дрейфа и обработки ошибок.
7) Таленд

Особенности:
- Поддерживает обширные преобразования интеграции данных и сложные рабочие процессы
- Обеспечивает бесперебойную связь для более чем 900 различных баз данных, файлов и приложений.
- Он может управлять проектированием, созданием, тестированием, развертыванием и т. Д. Интеграционных процессов.
- Синхронизировать метаданные между платформами баз данных
- Инструменты управления и мониторинга для развертывания и контроля работ
8) Информатика PowerCenter

Особенности:
- Он имеет централизованную систему регистрации ошибок, которая облегчает регистрацию ошибок и отклонение данных в реляционные таблицы.
- Встроенный интеллект для повышения производительности
- Ограничить журнал сеанса
- Возможность расширения интеграции данных
- Фонд модернизации архитектуры данных
- Лучшие проекты с применением передовых методов разработки кода
- Интеграция кода с внешними инструментами настройки программного обеспечения
- Синхронизация среди географически распределенных членов команды.
9) Блендо
Blendo синхронизирует готовые аналитические данные в вашем хранилище данных с помощью нескольких щелчков мыши. Этот инструмент поможет вам сэкономить значительное время внедрения. Инструмент предлагает полнофункциональные 14-дневные бесплатные пробные версии.
Oracle Data Integration, Cloud, Spatial and Analytics (GoldenGate, ODI, Cloud, Spatial, Exadata)
Поскольку многие компании вложились в Oracle Warehouse Builder, было принято решение не бросать его разработку, а произвести постепенное слияние продуктов. Об этом достаточно подробно написано в блоге Андрея Пивоварова.
E-LT и ETL. Меняется ли смысл от перестановки букв?
Об этих двух подходах написано много. Каждый из них имеет свои плюсы и минусы.
Подход ETL подразумевает порядок выгрузку данных в stage область, преобразование там этих данных, а затем загрузку данных в хранилище. Этот подход стар как мир и имеет большое количество инструментов, которые его поддерживают. Разработка концепции ETL подразумевала, что ни источники данных, ни хранилище данных неспособные самостоятельно преобразовать данные к нужному виду.
Подход E-LT также основан на том, что данные сначала загружаются stage область, но в отличие от предыдущего подхода хранилище данных и stage область совмещены. Т.е. мы имеем в хранилище сырые данные, которые затем могут быть трансформированы в любой нужный нам вид и сохранены в том же хранилище.
E-LT подход хорош тем, что в хранилище данных мы можем отследить, откуда появились данные, т.е. имеем как преобразованные (агрегированные, отобранные, трансформированные) данные, так и исходные. Кроме того, мы можем допускать пользователя к исходным данные с минимальной агрегацией, что дает нам возможность строить операционные витрины данных и операционный BI. Делается это за счет применения CDC технологий (GoldenGate, Streams, triggers). Подробнее о построении операционных BI можно посмотреть в моей презентации.
Если краткое, то отличие операционного BI от стратегического можно выразить следующей таблицей:
Если подвести итог, то у E-LT подхода есть следующие плюсы:
- совмещение промежуточной stage области и хранилища не замедляет передачу данных для анализа, давая проводить анализ в реальном времени
- для получения доступа к нижнему уровню детализации не требует подключения к исходным системам
- E-LT системы позволяют использовать знания администраторов, т.е. не требуется изучать отдельный сложный продукт, который управляет stage областью.
Наличие плюсов, подразумевает наличие минусов:
- E-LT подход относительно нов и не все ETL инструменты поддерживают его;
- E-LT подход опирается на функциональность СУБД, поэтому не является независимым и самодостаточным.
Вот почему, многие разработчики ETL средств пытаются научить свои средства работать с базой данных более эффективно нежели просто вытаскивать сырые данные.
Подход компании Oracle был изначально направлен именно на использование возможностей базы данных. По сути с приобретением компании Sunopsis у Oracle появился инструмент TETLT, т.е. инструмент, который трансформирует данные в том месте, где это наиболее эффективно.
Архитектура ODI
Для того, чтобы эффективно использовать ODI необходимо понимать архитектуру комплекса.


Комбинация этих модулей и позволяет задать процесс переноса данных в хранилище.
Заключение
Продукт изначально был разработан так, чтобы максимально задействовать средства базы данных, поэтому, в частности, он дает возможность обойтись без выделенного центра для ETL-преобразования.
Для ODI разработан целый ряд knowledge-модулей, которые позволяют извлекать и загружать данные практически в любую базу данных и информационную систему.
В следующих постах я более подробно расскажу об использовании Oracle Data Inetegrator для построения ETL-решений.

Сложные ETL-процессы, как правило, разбиваются на цепочку более простых.
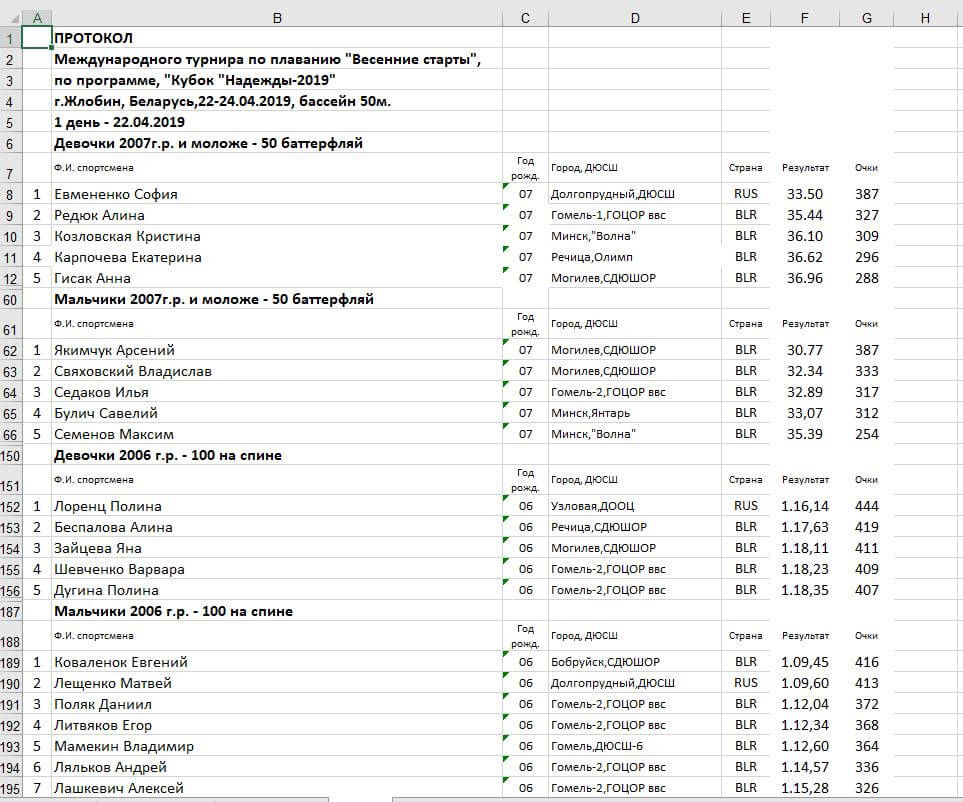
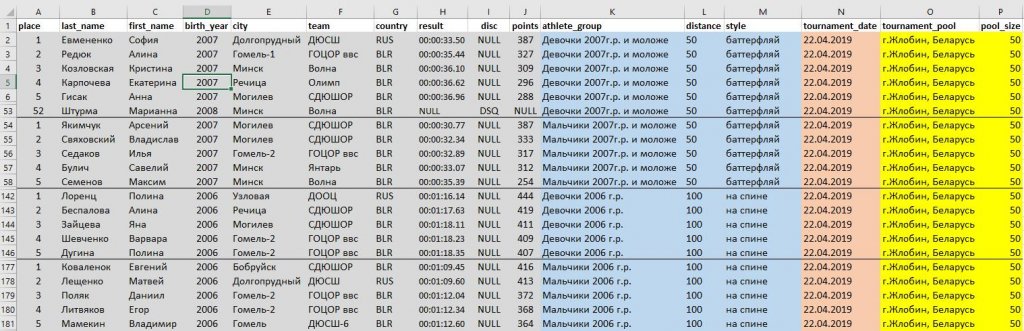
Рассмотрим частный случай импорта данных из внешнего файла. Например, из Excel или csv.
Образец файла с исходными данными (протокол проведенных соревнований по плаванию):
Модель данных в целевой БД:
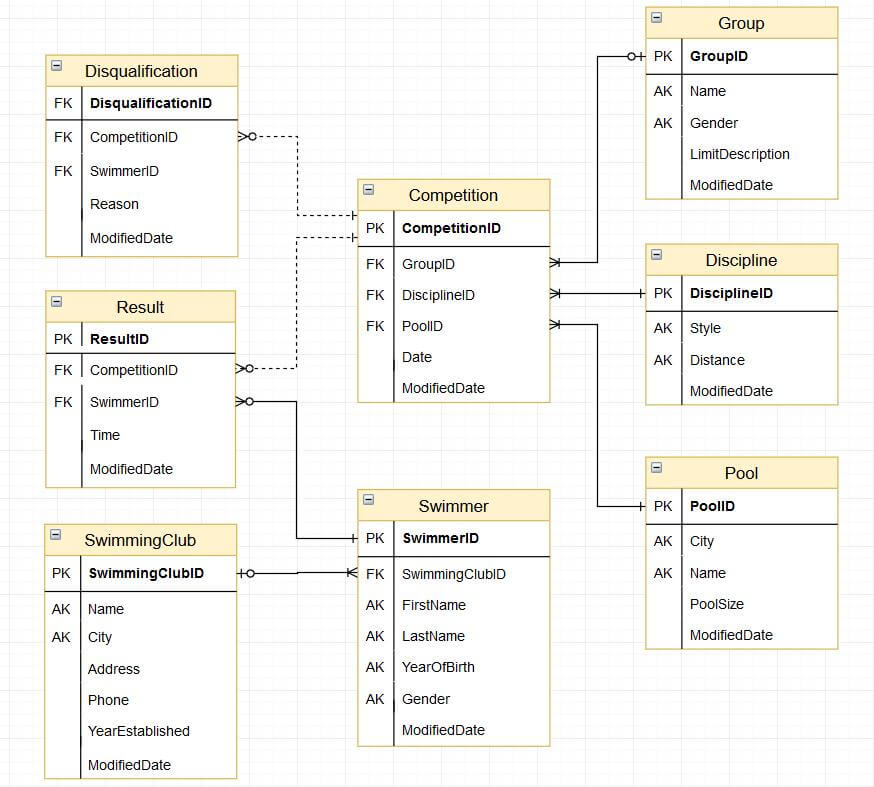
Загрузка данных в модель выше довольно сложная задача, учитывая, что исходные данные находятся в неструктурированном виде. В данной статье мы ограничимся подготовкой последних для загрузки в стейджинговую (т.е. промежуточную с точки зрения целевой модели) таблицу.
Промежуточная таблица в данном случае позволяет сконцентрироваться на процессе первоначальной подготовки данных и переносе их из внешнего неструктурированного источника (см. скриншот выше) во внутренний, очищенный и удобный с точки зрения БД для последующей работы формат.
Архитектура ETL (мы концентрируемся на ETL 1):
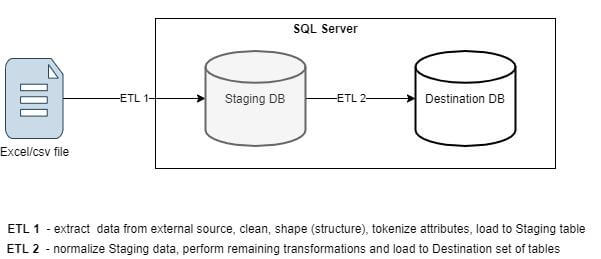
Для определения возможной схемы стейджинговой таблицы проведем первичный data profiling, определив:
- метрики исходных данных (список атрибутов, их типы, длину строковых полей, null/not null, потенциальный ключ, степень соответствия целевым атрибутам и пр);
- аномалии (грязные или отсутствующие данные, множественные значения и пр);
- возможный способ осуществления парсинга.
Требования к Staging-ETL (v1.0):

Глядя на исходные данные, приходим к выводу что в них присутствуют множественные значения. Мы не будем готовы загрузить такие данные в целевые таблицы (например, строки Фамилия+Имя, Клуб+Город, Группа+Длина дистанции+Стиль плавания).
Нужно детальное сравнение исходных данных с целевыми атрибутами и уточнение требований.
Уточненные требования:
Создадим рабочую таблицу для загрузки “сырых” исходных данных.
Фактически, мы будем создавать ELT (Extract-Load-Transform) а не ETL (Extract-Transform-Load) код. Другими словами, все трансформации и очистку данных мы будем делать ПОСЛЕ загрузки сырых данных в БД.
Будем полагать исходные данные находятся в текстовом файле формата csv.
Если, изначально данные находятся в Excel, конверсию в csv можно предварительно сделать программно или средствами самого Excel.
Грузим данные в рабочую таблицу:
Commands completed successfully.
(1470 rows affected)
(5 rows affected)

Альтернативно, ту же задачу можно было сделать с помощью мастера импорта данных или с помощью
Попробуем решить задачу одним запросом SELECT, разбив его на ряд CTE-модулей
(30 rows affected)

Внимательно проанализировав полученный результат, мы находим признак грязных данных (Будник Виктория в названии группы).

Нужна доработка кода выше под эту особенность и строго продуманный подход к тому, как мы будем парсить исходные данные. Попытка выработать этот самый строгий подход дана в размеченном скриншоте ниже.
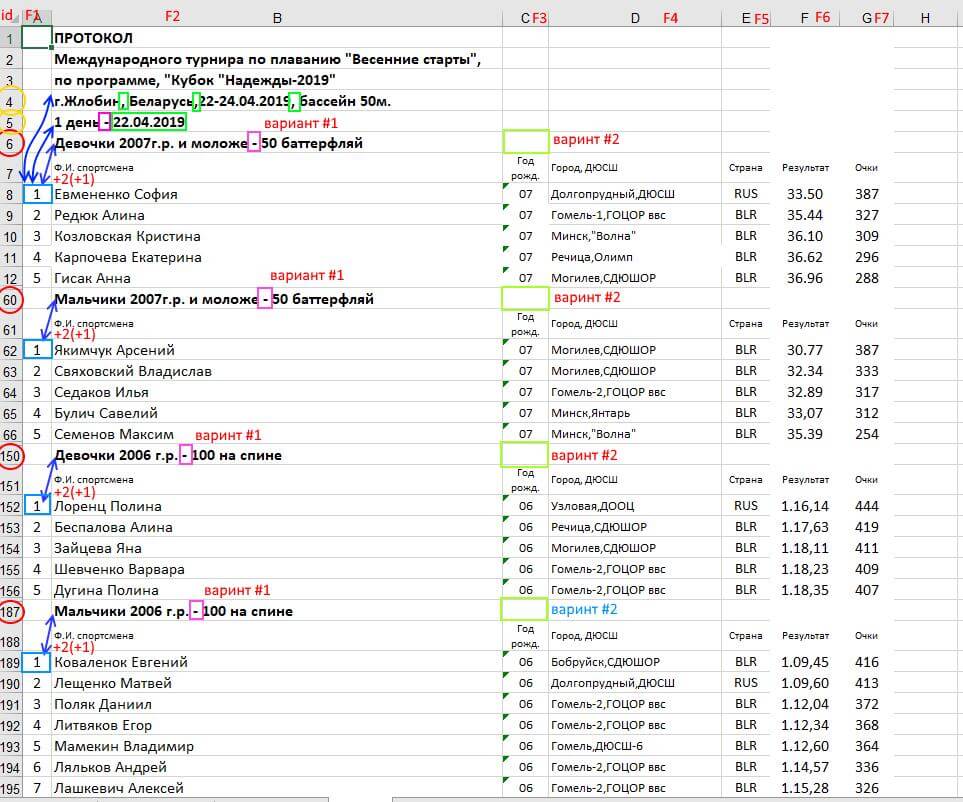
(30 rows affected)

Определение списка соревновательных дней:
(2 rows affected)

Определение места проведения соревнования:

(100 rows affected)
Мы приблизились к выполнению требований.
Теперь сконцентрируемся на разбиении множественных атрибутов на атомарные значения.
Попробуем разбить Фамилию Имя:

Проверим корректно ли происходит разбиение на всем множестве записей (у всех таких записей значение в колонке F1 не пусто):
(324 rows affected)
(106 rows affected)


Время на data profiling было потрачено не зря! Порой имя спортсмена содержит символы (в/к), что, вероятнее всего, означает что он участвовал в соревновании вне конкурса.

Для того чтобы загрузить лишь имя спортсмена, в поле first_name нужно взять первое слово (в случае если их несколько):
(99 rows affected)

Сделаем подобные проверки для каждого поля. Подкорректируем формулы извлечения атрибутов для всех имеющихся проблем.
Заметим, помимо прочего, что у всех атрибутов могут быть пробелы как До, так и После их значения. Для их удаления будем применять ltrim(rtrim(value)).
Высокий процент грязных данных после работы парсера говорит как о плохом качестве исходных данных, так и о плохой работе ETL-специалиста в части его подготовительной (исследовательской) работы перед написанием ETL.
Еще одна проблема – результаты заплывов (время). Строки не находятся в едином формате и, соответственно, не конвертируются в тип time(2).
Среди значений времени присутствуют строки, дробная часть может отсутствовать, а может быть отделена от целой как точкой, так и запятой.
Будем разбивать значения этого исходного поля на два новых: результат-время и результат-дисквалификация. При этом само поле результат-время разложим на компоненты hh-mm-ss-ms с намерением впоследствии применить функцию timefromparts(hh, mm, ss, ms, precision) и тем самым сконвертировать результат из типа varchar к типу time(2).
(12 rows affected)

Теперь соберем все вместе.
Окончательный вариант:
(2 rows affected)

Используя язык SQL, мы создали основу ELT-процесса парсинга полуструктурированных данных.
Заметим, что код выше не является идеальным. Это скорее R&D-решение, полученное дата-аналитиком в процессе исследования исходных данных. Вопрос оптимизации будет решен дата-инженером во время создания полноценного ETL-процесса.
* Материалы, использованные в статье (код, исходный Excel-файл, результаты работы парсера, выгруженные в csv-файл) можно получить по этой ссылке.
Автор материала – Тимофей Гавриленко, преподаватель Тренинг-центра ISsoft.

Образование: окончил с отличием математический факультет Гомельского Государственного Университета им. Франциска Скорины.
Microsoft Certified Professional (70-464, 70-465).
Работа: c 2011 года работает в компании ISsoft (ETL/BI Developer, Release Manager, Data Analyst/Architect, SQL Training Manager), на протяжении 10 лет до этого выступал как Sysadmin, DBA, Software Engineer.
В свободное время ведет бесплатные образовательные курсы для детей и взрослых, желающих повысить свой уровень компьютерной грамотности и переквалифицироваться в IT-специалиста.
Читайте также: