
Oracle как узнать дату создания внешнего файла
Обновлено: 06.07.2024
Я должен найти время создания файла, когда я прочитал некоторые статьи об этой проблеме, все упомянули, что нет никакого решения (как Site1, Site2).
Когда я попробовал stat команда, указывает это Birth: - .
Таким образом, как я могу найти время создания файла?
Есть способ узнать дату создания каталога, просто выполните следующие действия:
Узнайте inode каталога с помощью ls -i команда (скажем, ее X )
Узнайте, на каком разделе сохранен ваш каталог, с помощью команды df -T / path (скажем, это на / dev / sda1 )
Теперь используйте эту команду: sudo debugfs -R 'stat ' / dev / sda1
В выводе вы увидите:
crtime - дата создания вашего файла.
Что я тестировал :
- Создал каталог в определенное время.
- Получил доступ к нему.
Изменил его, создав файл.
Я попробовал команда, и она дала точное время.
@Nux нашел отличное решение для этого, которое вы все должны проголосовать. Я решил написать небольшую функцию, которую можно было бы использовать для прямого запуска всего. Просто добавьте это в свой
Теперь вы можете запустить get_crtime , чтобы распечатать даты создания любого количества файлов или каталогов:
TL; DR: Просто беги: sudo debugfs -R 'stat / path / to / your / file' / dev /
(Чтобы определить вашу fs, запустите df -T / path / to / your / file , скорее всего, это будет / dev / sda1 ).
Длинная версия:
Мы собираемся запустить две команды:
Узнать имя раздела для ваш файл.
Вывод будет выглядеть следующим образом (сначала имя раздела):
Узнать время создания этого файла.
В выходных данных найдите ctime .
Неспособность stat показать время создания связана с ограничением системного вызова stat (2) , структура возврата которого не включает поле для времени создания. Однако, начиная с Linux 4.11 (т.е. 17.10 и новее *), доступен новый системный вызов statx (2) , который включает время создания в его возвращаемую структуру.
* И, возможно, в более старых версиях LTS, использующих ядра аппаратного стека (HWE). Проверьте uname -r , чтобы убедиться, что вы используете ядро версии не ниже 4.11 для подтверждения.
К сожалению, вызывать системные вызовы непосредственно в программе на языке C непросто. Обычно glibc предоставляет оболочку, которая упрощает работу, но glibc добавила оболочку только для statx (2) в августе 2018 г. (версия 2.28 , доступна в 18.10). Сама команда stat получила поддержку statx (2) только в GNU coreutils 8.31 (выпущена в марте 2019 г.) , однако даже только Ubuntu 20.04 имеет coreutils 8.30 .
Но я не думаю, что это будет перенесено на выпуски LTS, даже если они получат или уже используют новые ядра или glibcs. Поэтому я не ожидаю, что stat в любой текущей версии LTS (16.04, 18.04 или 20.04) когда-либо напечатает время создания без ручного вмешательства.
В 18.10 и новее, вы можете напрямую использовать функцию statx , как описано в man 2 statx (обратите внимание, что на странице руководства 18.10 неверно указано, что glibc еще не добавил оболочку).
в Ubuntu 20.10 вы сможете использовать stat напрямую:
К счастью, для старых систем @whotwagner написал пример программы на C , в которой показано, как использовать Системный вызов statx (2) в системах x86 и x86-64. Его вывод имеет тот же формат, что и stat по умолчанию, без каких-либо параметров форматирования, но его просто изменить, чтобы печатать только время рождения.
Сначала клонируйте его:
Вы можете скомпилировать код statx.c или, если вам просто нужно время рождения, создайте Birth.c в клонированном каталоге со следующим кодом (который является минимальной версией ] statx.c печатает только временную метку создания, включая точность наносекунды):
Теоретически это должно сделать время создания более доступным:
- должно поддерживаться больше файловых систем, чем только ext * ( debugfs - это инструмент для файловых систем ext2 / 3/4, который нельзя использовать в других)
- вам не нужен root, чтобы использовать это (за исключением установки некоторых необходимых пакетов, таких как make и linux-libc-dev ).
Тестирование системы xfs, например:
Однако это не сработало для NTFS и exfat. Я полагаю, что файловые системы FUSE для них не учитывали время создания.
У меня есть файл CSV с именем inventory.csv, расположенный на сервере базы данных Oracle (2008 R2 Enterprise Edition Windows Server). Этот файл CSV используется в качестве внешней таблицы Oracle.
Каждый час запланированная задача (планировщик задач Windows) выполняет файл .bat, который копирует обновленную версию inventory.csv, перезаписывая оригинал.
Затем эти данные используются приложением отчетности.
Проблема
Приложение, которое использует данные в inventory.csv, не имеет возможности узнать, когда эти данные были обновлены в последний раз.
В идеале я хотел бы, чтобы "last updated date" был доступен как столбец в таблице.
Одно из возможных решений состоит в том, чтобы инициировать протоколирование текущей даты/времени в отдельном файле, а затем ссылаться на него также как на внешнюю таблицу. Однако в этом решении слишком много движущихся частей, и я бы предпочел что-то более простое, если это возможно.
Я знаю, что сам файл CSV знает, когда он был created. I'm интересно, есть ли какой-нибудь способ для внешней таблицы Oracle прочитать дату "Created" из свойств файла CSV?
Или еще какие-нибудь идеи?
1 ответ
SQL*Loader: Oracle использует эту функцию через драйвер доступа ORACLE_LOADER для перемещения данных из плоского файла в базу данных; Data Pump: он использует драйвер доступа Data Pump для перемещения данных из базы данных в файл в собственном формате Oracle и обратно в базу данных из файлов этого.
Мы используем в выпуске Oracle 11g Release 2 внешнюю таблицу типа ORACLE_LOADER для импорта данных из файла CSV в таблицу. Внешняя таблица имеет фиктивное имя файла, заданное для значения LOCATION, так как пользователи будут вводить правильное имя файла в качестве параметра при запуске пакета.
Какая версия Oracle?
Если вы используете 11.2 или более позднюю версию, вы можете использовать функцию препроцессора внешних таблиц для запуска shell script/ batch file в файле перед его загрузкой. Мой уклон состоял бы в том, чтобы пойти на простоту-заставить сценарий предварительной обработки захватить дату, сохранить ее в отдельном файле и иметь отдельную внешнюю таблицу, которая загружает и предоставляет эти данные. Это, вероятно, проще, чем добавлять дату в каждую строку.
Похожие вопросы:
У меня есть следующий запрос для создания таблицы, однако имя файла находится на моей локальной машине (так как у меня нет доступа к окну Oracle), как я могу использовать локальный файл для создания.
Я использую надстройку, чтобы упростить создание отчета из необработанных данных, доступных в электронной таблице. Необработанные данные, которые должны быть доступны, - это файл .xlsx, где теперь.
Я только что узнал одну из функций Oracle: внешняя таблица. Но когда я использую эту внешнюю таблицу в своем приложении, я получаю проблему и задаюсь вопросом, как ее решить. Проблема заключается в.
SQL*Loader: Oracle использует эту функцию через драйвер доступа ORACLE_LOADER для перемещения данных из плоского файла в базу данных; Data Pump: он использует драйвер доступа Data Pump для.
Мы используем в выпуске Oracle 11g Release 2 внешнюю таблицу типа ORACLE_LOADER для импорта данных из файла CSV в таблицу. Внешняя таблица имеет фиктивное имя файла, заданное для значения LOCATION.
Я знаю, что могу получить доступ к внешней переменной в объекте функции, но вот с чем я застрял. zero = function (one) < this.one = one; this.two = < three: < four: function() < one.test(); >> > >.
Я хочу загрузить csv в oracle с помощью внешней таблицы. есть 1 столбец, который нужно превратить в отдельную таблицу с помощью FK. csv.
У меня есть 150 нечетных файлов csv, но там имя файла может отличаться. поэтому я хочу знать, можем ли мы использовать в Концепции внешней таблицы *.csv, где мы предоставляем список имен файлов.
В postgres есть системная таблица, которая хранит сопоставление между внешней (внешней) таблицей и соответствующим ей файлом на диске. Аналогично сопоставлению location и table_name в таблице.
Я создал внешнюю таблицу в Oracle 11g. Иногда он выдает ошибку file not found. Файл находится в каталоге внешней таблицы oracle со всеми разрешениями, предоставленными для folder/file. Самое.
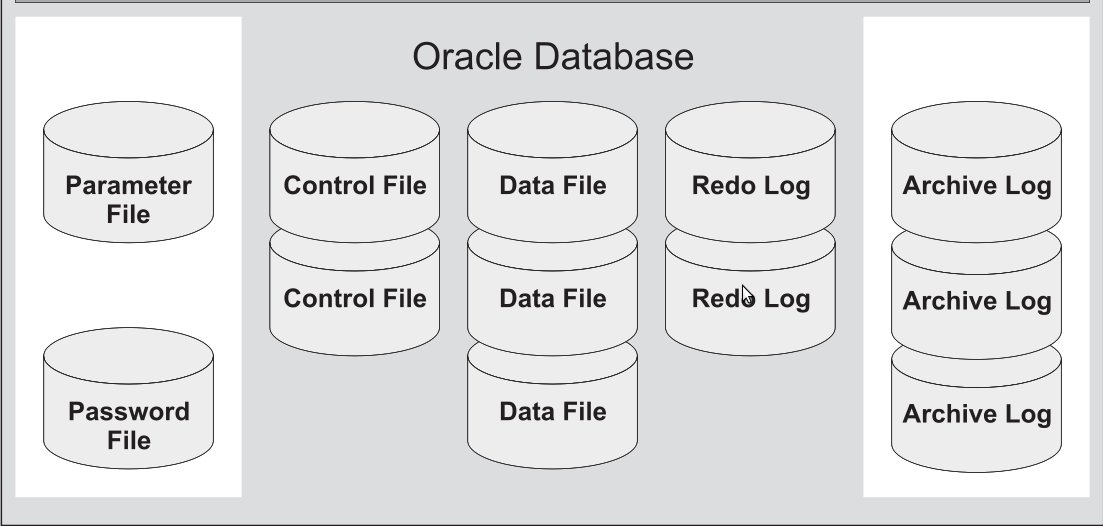
Предполагается, что вы инсталлировали базу данных, согласно документа.
Обязательные файлы:
Необязательные файлы:
-
(необязательные в том смысле, что база может быть настроена для работы без данных файлов) (Alertlog - если нет необходимости в изучении данных по ошибкам, можно удалить. Трассировочные файлы по умолчанию не создаются. Чтобы создавались, нужно включать трассировку и потом не забыть отключить) (По умолчанию не используются. Нужно специально создавать специальными командами.)
Файлы данных (Data Files)
Все данные в базе данных Oracle сохраняются в файлах данных. Все таблицы, индексы, триггеры, последовательности, программы на PL/SQL, представления - все это находится в файлах данных. И хотя эти и другие объекты базы данных логически содержатся в табличных пространствах, в действительности они сохраняются в файлах на жестком диске компьютера.
В каждой базе данных Oracle имеется по крайней мере один файл данных (но обычно их бывает больше). Если вы создаете в Oracle таблицу и заполняете ее строками, Oracle помещает эту таблицу и строки в файл данных. Каждый файл данных может быть связан только с одной базой данных.
У каждого файла данных имеется специальный формат, внутренний для программного обеспечения Oracle. Важно отдавать себе отчет в том, что файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных Oracle содержит несколько структур, в том числе и идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла.
Данные в файлы вносятся исключительно средствами Oracle.
Следующий запрос, покажет, где находятся файлы данных.
Оперативные файлы журналов повтора (Online Redo Log Files)
Оперативные файлы журналов повтора - предназначены для записи всех изменений, выполненных над данными базы данных Oracle. Используется для хранения на диске информации для повторного выполнения операций.
Для компьютера выполнить задачи повторно - означает выполнить ее точно так, как она выполнялась в предыдущий раз. Поэтому назначение оперативного файла журнала повтора заключается в сохранении информации об изменениях в базе данных таким, образом, чтобы позже их можно было повторить.
Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, после его заполнения (или переключения некоторыми командами), база данных приступает к записи в следующий файл. Эта операция называется переключением журналов.
Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
Управляющие файлы (Control Files)
Поскольку база данных Oracle является физическим набором связанных файлов данных, то для их синхронизации и контроля требуется особые методы. Для этих целей используются управляющие файлы.
База данных Oracle может иметь один или несколько управляющих файлов. Если имеется несколько управляющих файлов, все они должны быть абсолютно идентичными. При каждом запуске базы данных Oracle читает информацию управляющего файла, а при каждом изменении размещения или добавления новых файлов данных и журналов базы данных обновляет управляющий файл.
Файлы параметров pfile, spfie (Parameter Files)
Файлы параметров используются для конфигурирования действий Oracle предже всего при старте. Для того, чтобы запустить экземпляр базы данных, Oracle должен прочесть файл параметров и определить, какие параметры инициализации установлены для этого экземпляра. В файле параметров содержатся многочисленные параметры и их установленные значения. Oracle считывает файл параметров при запуске базы данных. Можно создать несколько файлов параметров, каждый будет соответствовать различным конфигурациям экземпляра.
- spfile - бинарный файл, который используется сервером Oracle при старте.
- pfile - текстовый файл с параметрами, будет использоваться при старте, если не будет найден spfile.
При старте, Oracle считает файл spfileora112.ora. (файл серверных параметров). Преимущество spfile заключается в том, что при работе с базой данных, любые изменения в базе касающиеся изменения параметра системы, автоматически записываются в данный файл.
Если используется pfile, для сохранения изменений, необходимо либо “руками вносить эти изменения” в текстовый файл, либо в консоли выполнять команды для создания данных файлов Ораклом.
Как я могу узнать, что моя база данных использует PFILE или SPFILE?
Выполните следующий запрос, чтобы увидеть какой файл параметров был использован:
Архивные файлы журналов повтора (Archive Log Files)
Как только оперативный файл журнала повтора (Redolog) оказывается заполнен, программное обеспечение сервера Oracle начинает запись в следующий файл. Эта операция повторяется, как следствие информация в оперативных файлах журнала (Redolog) многократно перезаписывается.
Если необходимо сохранить историю изменений, нужно, чтобы после переключения журналов сохранялась их копия. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повтора жизненно важны при восстановлении. Если часть базы данных потеряна или повреждена, то для устранения повреждений обычно требуется несколько архивных журналов или туева хуча этих журналов. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут использоваться. Храните все свои архивные файлы журналов повтора с момента выполнения последней резервной копии. Файлы журналов постепенно накапливаются и разрастаются. Иногда необходимо их удалять. Все операции с данными файлами по применению их к базе выполняются исключительно средствами базы данных. А копировать и переносить их при желании можно как угодно. Бездумно удалять их руками не рекомендуется.
Alert log и трассировочные файлы (trace file)
При работе базы данных события и ошибки регистрируются в текстовых файлах на сервере базы данных. Файл журнала предупреждений (alert log) нужен администратору базы данных для отслеживания важнейших действий с базой данных - наподобие открытия и закрытия базы данных, установления параметров загрузки базы данных и переключения оперативных журналов повтора. Также в эти файлы записываются многие ошибки базы данных для последующего расследования их причин. Любые структурные изменения базы данных также регистрируются в файле журнала предупреждений.
Когда возникает ошибка базы данных, может генерироваться файл трассировки (trace file). Они содержит подробную информацию о возникновении ошибки.
Файлы паролей (Password File)
Необязательный файл, используется для защиты информации о подключениях привилегированных пользователей. Если отсутствует, то вы можете выполнять администрирование своей базы данных, только локально. Кроме того, с его помощью контролируется количество привилегированных подключений для управления в одно и то же время.
Tags: Oracle Database, Файлы базы данных Oracle,
Oracle DBA
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.
Зачастую для тех или иных нужд возникает необходимость выполнить команду OS из pl/sql или даже sql внутри Oracle Database.
Ниже описывается один из способов и его применение в задаче определения доступного дискового пространства.
Предлагаемый способ заключается в использование добавленного в 11.2 функционала «Препроцессинг данных внешних таблиц».
- Directory — в ней будет располагаться наш скрипт препроцессинга и на неё будет ссылаться таблица
- external organization table — обращение к которой будет вызывать выполнение скрипта
- script — собственно сам файл который будет выполнять требуемое нам действие в OS
Пример создания требуемых объектов:
Лучше всего иметь отдельную directory для наших целей ввиду того что нам потребуется одновременно и права на запись в ней и права на выполнение, а такую комбинацию лучше никому не выдавать.
Оптимальное использование это создание пакета (хоть и в схеме SYS) в спецификации которого описаны процедуры, которым необходимо обращение к OS, а саму реализацию оставить внутри пакета и никого к ней не подпускать.
Далее подразумевается что права на чтение, запись и выполнение к UTIL_DIR у нас имеются, также как и права на select из T_OS_COMMAND.
Для создания файла который будет выполнятся достаточно выполнить в OS (да придется хоть раз выполнить действия в OS прибегнув к более тривиальным методам — например ssh):
Данные команды должны быть выполнены от пользователя (либо члена группы) от которых запускается экземпляр БД.
Всё готово к использованию. Для выполнения произвольной команды OS нам следует записать её в файл os_command.sh и обратиться с запросом к таблице T_OS_COMMAND.
Теперь для получения результата работы нашего скрипт достаточно выполнить запрос к таблице T_OS_COMMAND
Далее можно приступать к реализации непосредственно методов которым необходим вызов команд OS.
Примером такой реализации может выступать пакет P_SYS_UTILITY. Пожелания по его развитию и участие в оном приветствуются.
Метод Get_Disk_Usage
p_file_name — имя файла или папки для месторасположения которого(-ой) будет произведен расчет. Позволяет передавать имена относящиеся к ASM disk groups.
o_mount_dev — имя устройства в системе на которое смонтировано указанное месторасположение, определяется из вывода команды df. Для ASM будет возвращено имя disk group.
o_used_space — количество байт занятых на устройстве/diskgroup
o_free_space — количество байт доступных на устройстве/diskgroup
Осуществляет вызов df с передачей в качестве параметра имени файла, или обращение к v$asm_diskgroup в случае если имя файла начинается на "+".
Метод Collect_Usage
Осуществляет сбор информации об использовании пространства внутри БД. Группирует по табличным пространствам, владельцам и типам сегментов. Не берет в учет сегменты типа undo и temp. Сохраняет полученную информацию в таблицу T_SPACE_USAGE. Рекомендуется к ежедневному выполнению.
Метод Get_Forecast
pDT — дата на которую надо спрогнозировать размер
pBASE — количество дней, данные за которые войдут в базу по которой будет строиться прогноз
pTYPE_F — способ прогнозирования — либо на основе ковариация (генеральной) совокупности, либо на основе среднего изменения
pTABLESPACE — табличное пространство по которому производится прогнозирование, если не передавать то по всем
pOWNER — владелец схемы по которому производится прогнозирование, если не передавать то по всем
pTYPE — тип сегментов данных по которому производится прогнозирование, если не передавать то по всем
Выполняет расчет прогнозируемого занимаемого места сегментов согласно указанным критериям. Результат в байтах.
Метод Get_Space_Status
pFOREDAYS — количество дней для прогноза
pFREE_PRCNT — процент доступного пространства (считается от прогнозируемого занятого)
Производит оценку по шкале от 0 до 100 доступного для роста БД пространства.
Также учитывает ограничения на рост файлов внутри БД.
Простой результат позволяет интегрировать вызов функции в системы мониторинга с настройкой порогов критичности.
ps.и да, учитываем, что выдавая права на выполнение и запись мы прокладываем брешь в безопасности.
Читайте также: