
Oracle разбить выборку на части
Обновлено: 06.07.2024
1. зависимый подзапрос
2. join + group by
Этот способ часто рекомендуют в интернете в качестве решения задачи (встречаются вариации с left join). Однако его производительность не самая оптимальная в сравнении с другими методами, рассмотренными в этой статье. Вероятно, причина популярности этого решения в том, что join многим интуитивно представляется более простым решением.
Обратите внимание: в режиме ONLY_FULL_GROUP_BY придется усложнять запрос: сначала выбрать нужные post_id, затем по ним дополнительным join извлечь остальные поля (подробнее см статью Группировка в MySQL). Простое перечисление всех полей в части group by в разы увеличивает время выполнения запроса.
- в старых версиях они действительно не применимы :)
- в новых их производительность будет существенно хуже по сравнению с иными доступными вариантами решений (см способы 4 и 6)
3. group_concat()
- сколько строк из группы нужно выбрать
- есть ли возможность использовать with (доступны с MariaDB 10.2 / MySQL 8). Если в явном виде дублировать from-подзапрос, то каждый из них будет материализован в отдельную временную таблицу.
4. оконные функции
Производительность - двойное сканирование таблицы: сначала для нумерации (нет возможности ограничиться нумерацией только нескольких строк из группы), потом отбросить не удовлетворяющие условию where i <= 3 .
5. пользовательские переменные
Та же идея, что и в предыдущем варианте, только реализована с помощью пользовательских переменных (user variables). Актуально для версий, в которых нет оконных функций.
Обратите внимание на добавление ещё одной переменной @z:=1, которая более нигде не применяется. С некоторых пор оптимизатор научился упрощать тривиальные с его точки зрения from-подзапросы, перенося условия из них во внешний запрос. Однако, если в подзапросе используются переменные, то пока оптимизатор материализует такие подзапросы.
В общем, пользовательские переменные - мощный инструмент написания и оптимизации запросов, но нужно быть очень внимательными при работе с ними, понимать на каком эффекте основан, используемый вами трюк, и проверять работоспособность в новых версиях. Подробнее см Оптимизация запросов MySQL с использованием пользовательских переменных
6. подзапросы lateral
В MySQL 8.0.14 добавлена поддержка зависимых подзапросов в части FROM, с помощью которых наша задача решается оптимальным образом. Сначала формируется список идентификаторов пользователей (производная таблица t1) и для каждого из выбираются нужные строки (коррелированный from-подзапрос t2).
К удивлению, при выборе строк в подзапросе t2 сервер читает все строки группы и делает файловую сортировку вместо нахождения 3 нужных строк по уникальному индексу (user_id, date_added). Возможно в будущих версиях это поведение будет исправлено.
На сегодняшний день можно применить следующий трюк, благодаря которому MySQL будет использовать индекс - расширить выражение сортировки следующим образом:
Для выборки случайных строк из группы достаточно в lateral подзапросе заменить сортировку на случайную - order by rand().
Заключение
| время, с | ||
| 3 последних | 3 случайных | |
| 1. зависимый подзапрос | 10.8 | - |
| 2. join + group by | 11 | - |
| 3. group_concat() | 0.06 | 0.03 |
| 3. модифицированный вариант + WITH | 0.03 | 0.016 |
| 3. модифицированный вариант без WITH | 0.08 | - |
| 4. row_number() | 0.15 | 0.17 |
| 5. пользовательские переменные | 0.13 | 0.14 |
| 6. LATERAL | 0.005 | 0.03 |
Если ваша СУБД поддерживает подзапросы lateral, то используйте их. Вообще, каждый раз, когда есть необходимость "для каждого значения выбрать . " - возможно вы сможете эффективно решить задачу, используя LATERAL производные таблицы. Подробнее об этой функциональности можно прочитать в статье В MySQL 8.0.14 добавлена поддержка производных таблиц типа LATERAL.
Неожиданно высокую эффективность показал третий способ, особенно для выборки случайных строк из группы. Неожиданно, потому что как правило рекомендуют использовать второй и четвертый (для MySQL до недавнего времени его реализацию через переменные, т.е. пятый) способы.
Также не забывайте про вариант реализации lateral во внешнем приложении: сначала выбираем список идентификаторов групп, потом в цикле отдельными запросами находим нужные строки для каждой группы. Порой встречается ошибочное мнение, что это ламерский подход и правильно решать задачу в один запрос к базе. По эффективности множество "простых" запросов, выбирающих по индексу нужные строки, лучше одного "сложного", который многократно сканирует всю таблицу. Разумеется это справедливо, когда в группах много элементов, и нужно вернуть лишь малую часть, иначе накладные расходы могут превысить выигрыш от снижения количества прочитанных строк.
Привет, Хабр! В компании, где я работаю, часто проходят (за мат извините) митапы. На одном из них выступал мой коллега с докладом об оконных функциях и группировках Oracle. Эта тема показалась мне стоящей того, чтобы сделать о ней пост.

С самого начала хотелось бы уточнить, что в данном случае Oracle представлен как собирательный язык SQL. Группировки и методы их применения подходят ко всему семейству SQL (который понимается здесь как структурированный язык запросов) и применимы ко всем запросам с поправками на синтаксис каждого языка.
Всю необходимую информацию я постараюсь кратко и доступно объяснить в двух частях. Пост скорее будет полезен начинающим разработчикам. Кому интересно — добро пожаловать под кат.
Часть 1: предложения Order by, Group by, Having
Здесь мы поговорим о сортировке — Order by, группировке — Group by, фильтрации — Having и о плане запроса. Но обо всем по-порядку.
Order by
Оператор Order by выполняет сортировку выходных значений, т.е. сортирует извлекаемое значение по определенному столбцу. Сортировку также можно применять по псевдониму столбца, который определяется с помощью оператора.
Преимущество Order by в том, что его можно применять и к числовым, и к строковым столбцам. Строковые столбцы обычно сортируются по алфавиту.
Сортировка по возрастанию применяется по умолчанию. Если хотите отсортировать столбцы по убыванию — используйте дополнительный оператор DESC.
SELECT column1, column2, … (указывает на название)
FROM table_name
ORDER BY column1, column2… ASC|DESC;

Давайте все рассмотрим на примерах:
В первой таблице мы получаем все данные и сортируем их по возрастанию по столбцу ID.
Во второй мы также получаем все данные. Сортируем по столбцу ID по убыванию, используя ключевое слово DESC.
В третьей таблице используется несколько полей для сортировки. Сначала идет сортировка по отделу. При равенстве первого оператора для полей с одинаковым отделом применяется второе условие сортировки; в нашем случае — это зарплата.
Все довольно просто. Мы можем задать более одного условия сортировки, что позволяет более грамотно сортировать выходные списки.
Group by
В SQL оператор Group by собирает данные, полученные из базы данных в определенных группах. Группировка разделяет все данные на логические наборы, что дает возможность выполнять статистические вычисления отдельно в каждой группе.
Этот оператор используется для объединения результатов выборки по одному или нескольким столбцам. После группировки будет только одна запись для каждого значения, использованного в столбце.
С использованием оператора SQL Group by тесно связано использование агрегатных функций и оператор SQL Having. Агрегатная функция в SQL — это функция, возвращающая какое-либо одно значение по набору значений столбца. Например: COUNT(), MIN(), MAX(), AVG(), SUM()
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);
Group by стоит после условного оператора WHERE в запросе SELECT. По желанию можно использовать ORDER BY, чтобы отсортировать выходные значения.
Итак, опираясь на таблицу из предыдущего примера, нам нужно найти максимальную зарплату сотрудников каждого отдела. В итоговой выборке должно получиться название отдела и максимальная зарплата.
Решение 1 (без использования группировки):
Решение 2 (с использованием группировки):
В первом примере решаем задачу без использования группировки, но с использованием подселекта, т.е. в один селект вкладываем второй. Во втором решении используем группировку.
Второй пример вышел короче и читабельнее, хотя выполняет такие же функции, что и первый.
Как у нас работает Group by: сначала разбивает два отдела на группы qa и dev. Потом для каждого из них ищет максимальную зарплату.
Having
Having это инструмент фильтрации. Он указывает на результат выполнения агрегатных функций. Предложение Having используется в SQL там, где нельзя применить WHERE.
Если предложение WHERE определяет предикат для фильтрации строк, то Having используется после группировки для определения логичного предиката, фильтрующего группу по значениям агрегатных функций. Предложение необходимо для проверки значений, полученных при помощи агрегатных функций из групп строк.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
Сначала мы выводим отделы со средней зарплатой больше 4000. Затем выводим максимальную зарплату с применением фильтрации.
Решение 1 (без использования GROUP BY и HAVING):
Решение 2 (с использованием GROUP BY и HAVING):
В первом примере используется два подселекта: один для нахождения максимальной зарплаты, другой для фильтрации средней зарплаты. Второй пример, опять же, вышел намного проще и лаконичнее.
План запроса
Нередко бывают ситуации, когда запрос работает долго, потребляя значительные ресурсы памяти и дисков. Чтобы понять, почему запрос работает долго и неэффективно, мы можем посмотреть план запроса.
План запроса — это предполагаемый план выполнения запроса, т.е. как СУБД будет его выполнять. СУБД распишет все операции, которые будут выполняться в рамках подзапроса. Проанализировав все, мы сможем понять, где в запросе слабые места и с помощью плана запроса сможем оптимизировать их.
Исполнение любого SQL предложения в Oracle извлекает так называемый “план исполнения”. Этот план исполнения запроса является описанием того, как Oracle будет осуществлять выборку данных, согласно исполняемому SQL предложению. План представляет собой дерево, которое содержит порядок шагов и связь между ними.
К средствам, позволяющим получить предполагаемый план выполнения запроса, относятся Toad, SQL Navigator, PL/SQL Developer и др. Они выдают ряд показателей ресурсоемкости запроса, среди которых основными являются: cost — стоимость выполнения и cardinality (или rows) — кардинальность (или количество строк).
Чем больше значение этих показателей, тем менее эффективен запрос.
Ниже можно увидеть анализ плана запроса. В первом решении используется подселект, во втором — группировка. Обратите внимание, что в первом решении обработано 22 строки, во втором — 15.
Анализ плана запроса:


Ещё один анализ плана запроса, в котором применяется два подселекта:
Этот пример приведен как вариант нерационального использования средств SQL и я не рекомендую вам его использовать в своих запросах.
Все перечисленные выше функции упростят вам жизнь при написании запросов и повысят качество и читабельность вашего кода.
Часть 2: Оконные функции
Оконные функции появились ещё в Microsoft SQL Server 2005. Они осуществляют вычисления в заданном диапазоне строк внутри предложения Select. Если говорить кратко, то “окно” — это набор строк, в рамках которого происходит вычисление. “Окно” позволяет уменьшить данные и более качественно их обработать. Такая функция позволяет разбивать весь набор данных на окна.
Оконные функции обладают огромным преимуществом. Нет необходимости формировать набор данных для расчетов, что позволяет сохранить все строки набора с их уникальными ID. Результат работы оконных функций добавляется к результатирующей выборке в еще одно поле.
SELECT column_name(s)
Агрегирующая функция (столбец для вычислений)
OVER ([PARTITION BY столбец для группировки]
FROM table_name
[ORDER BY столбец для сортировки]
[ROWS или RANGE выражение для ограничения строк в пределах группы])
OVER PARTITION BY — это свойство для задания размеров окна. Здесь можно указывать дополнительную информацию, давать служебные команды, например добавить номер строки. Синтаксис оконной функции вписывается прямо в выборку столбцов.
Давайте рассмотрим все на примере: в нашу таблицу добавился еще один отдел, теперь в таблице 15 строк. Мы попытаемся вывести работников, их з/п, а также максимальную з/п организации.
В первом поле мы берем имя, во втором — зарплату. Дальше мы применяем оконную функцию over(). Используем её для получения максимальной зарплаты по всей организации, так как не указаны размеры “окна”. Over() с пустыми скобками применяется для всей выборки. Поэтому везде максимальная зарплата — 10 000. Результат действия оконной функции добавляется к каждой строчке.
Если убрать из четвертой строки запроса упоминание оконной функции, т.е. остается только max (salary), то запрос не сработает. Максимальную зарплату просто не удалось бы посчитать. Так как данные обрабатывались бы построчно, и на момент вызова max (salary) было бы только одно число текущей строки, т.е. текущего работника. Вот тут и можно заметить преимущество оконной функции. В момент вызова она работает со всем окном и со всеми доступными данными.
Давайте рассмотрим еще один пример, где нужно вывести максимальную з/п каждого отдела:

Фактически мы задаем рамки для “окна”, разбивая его на отделы. В качестве ранжирующего примера мы указываем department. У нас есть три отдела: dev, qa и sales.
“Окно” находит максимальную зарплату для каждого отдела. В результате выборки мы видим, что оно нашло максимальную зарплату сначала для dev, затем для qa, потом для sales. Как уже упоминалось выше, результат оконной функции записывается в результат выборки каждой строки.
В предыдущем примере в скобках после over не было указано. Здесь мы использовали PARTITION BY, которое позволило задать размеры нашего окна. Здесь можно указывать какую-то доп информацию, передавать служебные команды, например, номер строки.
Заключение
SQL не так прост, как кажется на первый взгляд. Все описанное выше — это базовые возможности оконных функций. С их помощью можно “упростить” наши запросы. Но в них скрыто намного больше потенциала: есть служебные операторы (например ROWS или RANGE), которые можно комбинировать, добавляя больше функциональности запросам.
Выбор данных выполняется командой SELECT.
Ниже приведен примерный список используемых ею конструкций и ключевых слов, полный же список зависит от реализации СУБД:
Это наверно самая сложная команда, поэтому ее изучение лучше разбить на несколько частей. Здесь рассмотрим эту команду в общем, а соединения, группировку данных и подобное более детально чуть позже. Пусть имеется следующая таблица с указанными данными.
выборка констант
Для выбора констант может указываться любой источник. Однако, если мы хотим просто
подсчитать значение какого-то выражения, то указывать источник имеющий сотню тысяч записей затратно по ресурсам. Поэтому многие СУБД позволяют выбрать константы без указания источника. Oracle не поддерживает синтаксис SELECT без FROM, а для выбора констант используется специальная системная таблица dual.
выборка по столбцам таблиц
Если источники данных указаны, то кроме констант можно выбирать столбцы или строить выражения с их использованием. Столбец определяется как имя_источника.имя_столбца. Если источник данных один, то его имя можно опустить. Для выбора всех столбцов всех источников используется символ *. Аналогично можно выбрать все столбцы указанного источника: имя_источника.*. Ниже приведен пример выборки всех записей нашей таблицы.
синонимы (алиасы)
При выборе данных можно назначать временные синонимы источникам данных и используемым столбцам. А в некоторых случаях необходимо. Например, когда источник подзапрос соединяется с другим источником, именование подзапроса обязательно. Другой пример, это объединение нескольких выборок, имена столбцов которых должны совпадать. Ключевое слово AS как правило необязательно, а в Oracle разрешено только для столбцов.
уникальные записи
Записи выборки считаются одинаковыми, если значения соответствующих полей одинаковы. Поэтому для демонстрации distinct на нашей таблице нужно исключить первичный ключ (поле id) из выборки.
Конструкция ORDER BY позволяет последовательно отсортировать сразу по нескольким столбцам. Столбцы, по которым происходит сортировка, желательно проиндексировать.
выборка по условию
Конструкция WHERE позволяет ограничить множество выбираемых записей. Ниже приведено несколько примеров.
выборка по группам
И напоследок пару примеров группировки данных.
Соединения (Join)
Этот раздел написан на основе материалов сайта Javenue.
Ключевое слово join в SQL используется при построении select выражений. Инструкция Join позволяет объединить колонки из нескольких таблиц в одну. Объединение происходит временное и целостность таблиц не нарушается. Существует три типа join-выражений:
- inner join;
- outer join;
- cross join;
В свою очередь, outer join может быть left, right и full (слово outer обычно опускается).
В качестве примера (DBMS Oracle) создадим две простые таблицы и сконструируем для них SQL-выражения с использованием join .
Содержимое таблиц пусть будет таким:
Конструкция join выглядит так:
. join_type join table_name on condition .
Кострукция join располагается сразу после select-выражения. Можно использовать несколько таких конструкций подряд для объединения соответствующего кол-ва таблиц. Логичнее всего использовать join в том случае, когда таблица имеет внешний ключ ( foreign key ).
Inner join необходим для получения только тех строк, для которых существует соответствие записей главной таблицы и присоединяемой. Иными словами условие condition должно выполняться всегда. Пример:
Результат будет таким:
В случае с left join из главной таблицы будут выбраны все записи, даже если в присоединяемой таблице нет совпадений, то есть условие condition не учитывает присоединяемую (правую) таблицу. Пример:
Результат выполнения запроса:
Результат показывает все ресурсы и их администраторов, вне зависимотсти от того есть они или нет.
Right join отображает все строки удовлетворяющие правой части условия condition , даже если они не имеют соответствия в главной (левой) таблице:
А результат будет следующим:
Результирующая таблица показывает ресурсы и их администраторов. Если адмнистратор не задействован, эта запись тоже будет отображена. Такое может случиться, например, если ресурс был удален.
Full outer join (ключевое слово outer можно опустить) необходим для отображения всех возможных комбинаций строк из нескольких таблиц. Иными словами, это объединение результатов left и right join .
А результат будет таким:
Некоторые СУБД не поддерживают такую функциональность (например, MySQL), в таких случаях обычно используют объединение двух запросов:
Агрегатные функции, группировка данных
Для группировки данных в запросе select используется конструкция group by,
в которой должны быть перечислены те же столбцы, что и после select. Ниже приведен
пример вывода данных по группам для таблицы bills.
Сами по себе группы редко используются, и предыдущий пример выборки можно заменить
сортировкой. Другое дело, если необходимо воспользоваться одной из групповых функций,
называемых агрегатными:
Ключевое слово DISTINCT позволяет игнорировать повторные значения в столбце, ALL
обрабатывает все значения в столбце (по умолчанию), * позволяет включить в обработку поля с null значением.
В MySQL между именем функции и скобкой не должно быть пробелов.
Ниже приведен пример использования агрегатных функций в качестве выбираемых данных. Если
агрегатная функция используется в выборке без group by, то она применяется ко всем записям
выборки, иначе для каждой группы в отдельности. И в любом случае в перечислении select нельзя
смешивать групповые столбцы с не групповыми.
Агрегатные функции можно использовать в выражениях условия в конструкции having для
отбора группы.
Операции над выборками
Так как выборка по сути является множеством, то и доступные операции над ними
соответствующие:
Запросы участвующие в таких операциях должны следовать нескольким условиям.
Иметь одинаковое число столбцов, соответствующие столбцы должны быть одного типа.
Тип данных столбца должен быть простым, т.е. не разрешаются типы подобные blob.
MySQL 5 поддерживает только UNION, в Oracle EXCEPT для других целей,
а для исключения используется MINUS.
По умолчанию в результирующую выборку попадают только уникальные записи.
Для включения всех записей используется ключевое слово ALL после имени операции.
Например, в следующем примере будет две записи со значением 2.
Добавление итогов в SQL
Еще раз рассмотрим таблицу bills созданную в пункте об агрегатных функциях.
Предположим мы хотим вывести все суммы, а в конце выборки добавить итоговую сумму.
Наиболее универсальным способом является объединение двух запросов.
Для решения подобных задач в стандарте введена конструкция ROLLUP генерирующая
дополнительную строку. Если в определении столбца агрегатная функция не используется,
то соответствующее поле в этой строке заполняется значением null. В противном случае
заполняется значением выражения столбца, причем агрегатная функция выполняется ко
всем записям основной выборки.
А теперь предположим мы хотим вывести все суммы с итогами по каждой группе и в конце выборки
общий итог. Ниже приведен пример с использованием объединений. Чтобы общий итог был точно в
конце выборки, задаем в поле d максимальню дату. В Oracle и Postgre можно оставить значение
null.
Подобную задачу можно решить с помощью стандартной конструкции CUBE, если она уже
реализована в СУБД. Куб генерирует не только общий итог, но и все возможные под итоги.
Ниже приведен пример использования куба. Для упрощения кода пустые значения не заменяются.
Нумерация записей
В стандарт SQL2003 уже добавлена функция row_number(), если она еще не реализована
в вашей версии БД, используйте следующие методы.
Oracle
В Oracle для нумерации записей введен псевдостолбец rownum.
MySQL
В MySQL для этого надо воспользоваться переменной. Чтобы увидеть результат следующего
примера в MySQLQueryBrowser, необходимо начать транзакцию (на панели кнопка после слова
Transaction). Далее выполняем приведенные в примере команды и затем завершаем транзакцию
(соседняя кнопка с галочкой).
PostgreSQL
В PostgreSQL для этих целей можно выделить последовательность и сбрасывать ее перед новой
выборкой.

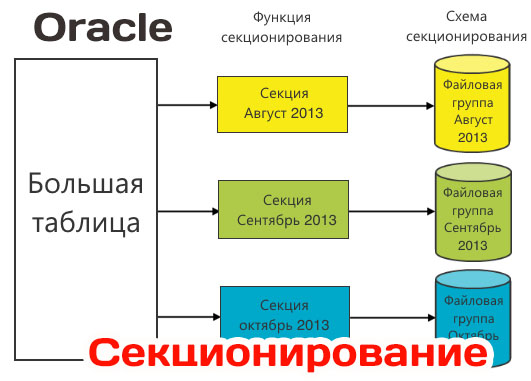
В этой части статьи рассматриваются особенности создания секционированных таблиц, в следующей речь пойдет об особенностях перевода существующих больших несекционированчых таблиц в секционированные таблицы, а также особенности секционирования индексов и работа с секциями.
Задачи, решаемые секционированием
Прежде чем приступить к секционированию, надо четко определить задачи, которые предполагается решить
- Первой и наиболее часто решаемой задачей при секционировании является повышение производительности работы SQL-запросов и DML-операций по модификации строк таблицы. Это достигается за счет того, что поиск и модификация строк в таблице идут не по всей таблице, а только в ее части (в одной или нескольких секциях). Кроме того, разбиение таблицы на секции позволяет увеличит скорость обработки таблицы за счет использования параллелизма.
- Вторая задача, которая нашла широкое применение в нашей организации, - это быстрое удаление значительного числа строк в больших таблицах за счет выполнения операции truncate секций. Другим широким применением секционирования является освобождение табличного пространства, занимаемого таблицей, после удаления строк из таблицы командой delete. Использование команд Shrink (сжатие таблицы) или Move (перемещение в табличное пространство) для освобождения табличного пространства в большой несекционированной таблице может занимать значительное время. В секционированных таблицах выполнение таких команд в пределах секции будет выполниться существенно быстрее.
- Третьей задачей секционирования является разбиение большой таблицы на оперативную и архивную части. Особенно это эффективно, если оперативная часть в виде секции интенсивно пополняется и модифицируется, а архивная часть (секции) менее подвержена изменениям, и существенно реже из нее извлекается информация. Строки таблицы из оперативной секции со временем могут быть переведены в архивные секции, при этом архивные секции могут периодически очищаться.
- Четвертой задачей является существенное снижение конкуренции за строки и индексы таблицы, в том числе уменьшения вероятности блокировок. Так в результате секционирования одной из таблиц по HASH-методу полностью была решена задача множественных блокировок, возникающих в таблице.
- Пятой задачей является обеспечение устойчивости функционирования таблиц. Поскольку секция - это поименованный самостоятельный фрагмент памяти на дисках, то при возникновении проблем в одних секциях другие продолжают успешно функционировать. Устойчивости функционирования способствует также хранение секций в различных табличных пространствах и на различных физических носителях. Это особенно важно для таблиц, которые обеспечивают работу множества других таблиц (например. справочники, к которым идет интенсивное обращение). Кроме того, секционирование позволяет осуществлять независимое копирование и резервирование секций, оперативное восстановление секций, а также возможности более быстрой и более частой перестройки индексов наиболее активной секции, не затрагивая индексы пассивных секций.
Ключ секционирования
Следующим важным шагом в создании секционированной таблицы является определение ключа секционирования. В качестве ключа секционирования может выступить столбец или несколько столбцов, относительно значений которых будет делаться разнесение таблицы на секции. К потенциальным столбцам для создания ключа секционирования относятся столбцы типа date (например, столбец created - дата создания строки или updated - дата изменения строки) для секционирования по методам Range и List . Столбцы типа number с высокой степенью уникальности значений хорошо подходят для секционирования по методам Range и Hash . Столбцы, имеющие список фиксированных значений, подходят для секционирования по списку List .
В Oracle 11g появилась возможность в качестве ключа секционирования использовать виртуальный столбец (virtual column), построенный на функции к реальному столбцу таблицы. Виртуальный столбец в действительности не хранится в таблице, а каждый раз вычисляется при обращении к нему во время ввода данных в таблицу. Для создания виртуального столбца используется фраза generated always as. после которой идет функция, выполняемая над реальным столбцом таблицы, а далее идет обязательная фраза virtual. Например, PARTID generated always AS (to_char(UPDATED,'MM')) virtual . Возможен вариант создания виртуального столбца более короткой фразой PARTID AS (to_char(UPDATED,'MM')) .
Увидеть, какой столбец в таблице виртуальный позволяет запрос:
Замечание. При вводе данных в таблицу с виртуальным столбцом следует указать в insert и values перечень столбцов, иначе будет ошибка ORA-00947: not enough value .
Методы секционирования таблиц
Секционирование повышает эффективность работы с таблицами и индексами
Выбранный ключ секционирования, как правило, определяет методы секционирования. В настоящее время имеются следующие методы секционирования таблиц:
- Range -секционирование по диапазону ключа,
- List - секционирование по списку ключа.
- Hash - хеш-секционирование,
- составное секционирование.
- интервальное секционирование.
- ссылочное секционирование,
- системное секционирование
Последние три появились в Oracle 11g. вместе с тем последние два у нас пока не нашли большого применения.
Секционирование методом Range по диапазону ключа
В практике секционирования по методу Range используем два вида секционирования: по диапазону дат и по диапазону значений.
Секционирование методом Range по диапазону дат
При секционировании этим методом нами используются секционирование по дням, месяцам и по годам. Секционирование этим методом покажем на примере таблицы HISTLG в схеме AIF. Ключом секционирования выступает столбец updated (дата корректировки строки), при этом секции создаются с шагом секций в один месяц. Команда создания секционированной таблицы create имеет вид:
В команде CREATE указаны табличное пространство TABLESPACE HSTDATA, в котором будет находиться таблица, метод секционирования и ключ секционирования PARTITION BY RANGE (UPDATED) , имена секций и максимальное значение диапазона ключевого столбца этой секции. Например, первая секция PARTITION PARTMM_2015_01 VALUES LESS THAN TO_DATE('01.01.20157DD.MM.YYYY') говорит о том, что все значения столбца update меньше 01.01.2015 попадут в первую секцию, а значения update меньше 01.02.2015 попадут во вторую секцию и т.д. В таблице создана последняя секция PARTITION PARTMM_MAX VALUES LESS THAN (MAXVALUE) , позволяющая при превышении значения ключа значения диапазона предпоследней секции размещать строки таблицы в эту последнюю секцию (это подстраховка на случай, если забыли создать новую секцию). Фраза COMPRESS определяет, что первая секция будет сжата.
Следует обратить особое внимание на последнюю фразу ENABLE ROW MOVEMENT , которая позволяет переходить строкам таблицы из секции в секцию. В отсутствии этой фразы Oracle выдаст ошибку. Переход строк по секциям может происходить автоматически при изменении значения ключа (например, столбец updated в результате операции update изменит значение на то. при котором он должен уже принадлежать другой секции) или может происходить специально, например, для перевода строк из оперативной секции в архивную секцию путем изменения значения ключевого столбца. Если не указали эту фразу при создании таблицы, то, чтобы избежать ошибки, следует выполнить команду ALTER TABLE ИМЯ ТАБЛИЦЫ ENABLE ROW MOVEMENT .
Увидеть секции таблицы можно по запросу:
А содержимое секции по запросу:
Секционирование методом RANG по диапазону значений
Секционирование по диапазону значений похоже на секционирование по диапазону дат, только вместо ключа по дате используется ключ по столбцу, принимающему числовое значение (желательно имеющее равномерное распределение по всему диапазону значений). Для этого хорошо подходит столбец с уникальным значением. Рассмотрим на примере той же таблицы AIF.HISTLG, секционированной выше по диапазону дат. В качестве ключа секционирования используется столбец ISN с уникальными значениями. Команда создания таблицы имеет вид:
где PARTITION BY RANGE (ISN) говорит о секционировании no RANGE при ключе секционирования ISN, интервал создания секции через 1000 значений.
Создание новой секции в секционированной таблице по методу Range
Каждый раз при создании секционированной таблицы возникает непростой вопрос: как создавать новые секции. До Oracle 11g было три варианта создания новой секции.
Первый вариант - это в команде create таблицы вручную создается множество секций (например, на несколько лет вперед). Однако, как показала практика, этот метод приводит к тому, что через несколько лет о том, что таблица была секционирована, могут забыть. Когда об этом вспоминают, то оказывается, что информация длительное время пишется в одну и ту же последнюю секцию THAN (MAXVALUE) . В результате секционированная таблица практически превратилась в обычную таблицу. В этой ситуации надо либо снова создавать новую секционированную таблицу, либо по команде Split разбивают последнюю секцию на несколько секций. Например, для таблицы AIF.HISTLG (секционированной по дате) команда Split по созданию новой секции PARTMM_2016_01 на основе расщепления последней PARTMM.MAX секции имеет вид:
Фраза UPDATE GLOBAL INDEXES обеспечивает исправность индексов после команды Split.
Второй вариант - создать процедуру, которая автоматически образует новую секцию. Такая универсальная процедура для секционирования по дням и месяцам была нами разработана. Данная процедура запускается Job Sheduler ежедневно для секционирования по дням или ежемесячно для секционирования по месяцам.
Данные процедуры успешно работают уже несколько лет, своевременно создавая новые секции. Основой процедуры являются представление ALL_TAB_PARTITIONS ДЛЯ поиска последней секции таблицы и команда Split для расщепления этой секции по команде ALTER , указанной выше.
Третий вариант (разработан нашими специалистами и успешно применяется в течение несколько лет) - это создание секционированной таблицы с секциями, используемыми по циклу. Под секционированием таблиц по циклу понимаются секционирование, выполненное в соответствии с двумя правилами. Первое правило - таблица должна содержать фиксированное количество секций, равное либо максимальному числу дней в месяце (31 секция), либо максимальному число дней в году (366 секций), либо числу месяцев в году (12 секций). Второе правило: данные в одну и ту же секцию попадают с определенной периодичностью (цикличностью).
Например, в следующем году информация за январь пишется снова в ту же секцию января, что и в прошедшем году. При этом секции чистятся от прошлогодней информации. Преимущество этого метода в том, что не надо создавать новые секции.
В Oracle 11g появилась новая замечательная возможность автоматического создания секций с использованием при создании таблицы фразы INTERVAL (такой подход называется интервальное секционирование Interval Partitioning). Тогда при создании секций методом Range по интервалу дат с использованием фразы Interval команда создания секционированной таблицы примет вид:
где фраза INTERVAL (INTERVAL '1' MONTH) указывает, что секции будут автоматически создаваться каждый месяц (та же фраза может иметь вид INTERVAL (NUMTOYMINTERVAL (1. 'MONTH') . Для секционирования по дням используется фраза INTERVAL (INTERVAL '1' DAY) , а по годам - INTERVAL (INTERVAL '1' YEAR) . При автоматическом создании секций методом Range по интервалу значений с использованием фразы Interval команда создания таблицы примет вид:
где фраза INTERVAL(1000) задает режим автоматического создания секции через 1000 значений ISN.
Следует учесть, что новые секции создаются в процессе ввода данных. Следует также иметь в виду, что имя новой автоматически создаваемой секции будет иметь вид SYS_PNNNNN, например, SYS_P28981. При этом при интервальном секционировании не нужно создавать последнюю секцию VALUES LESS THAN (MAXVALUE) . иначе появится ошибка ORA-14761.
Таким образом, в Oracle 11g у команды create создания секционированной таблицы существенно меньшее число строк, а о создании новой секции своевременно позаботится Oracle.
Секционирование по списку ключей LIST
Секционирование по списку применяется, если есть возможность указать конкретный перечень дискретных значений столбца, по которому происходит разбиение на секции. При секционировании по LIST в команде create указываются метод секционирования LIST (PARTITION BY LIST) , ключ секционирования и имена секций, в которых указывается одно или несколько дискретных значений.
В качестве примера проведем секционирование таблицы AIF.AGREEM. используя в качестве ключа виртуальный столбец partid. При каждом вводе строки в таблицу в виртуальном столбце формируется числовой номер месяца по функции to_number(to_char(updated,'MM')) . Таблицу разбиваем на 12 секций, кроме того, используем подход секционирования по циклу, когда в следующем году строки января вводятся в ту же секцию января, а перед этим секция за январь чистится от старых данных по delete или по truncate. Команда создания секции примет вид:
Вместо виртуального столбца может быть введен реальный столбец partid (тип number) , заполняемый при вводе строки в таблицу. Указанный выше вариант эффективно использовался в таблицах как с 366 секциями, так и с 12 с очисткой последних по truncate, поскольку информация в таблицах хранится меньше года. Достоинство этого подхода в том, что создавать новые секции не приходится, а табличное пространство старых секций ежемесячно быстро освобождается по truncate .
Замечание. Если необходимо очистить табличное пространство секции, то используются либо команды сжатия SHRINK , либо MOVE (перемещения в табличное пространство):
Другие стандартные варианты секционирования по методу LIST изложены в различных источниках.
Хеш-секционирование HASH
Как правило, если не получается секционировать по диапазону RANGE или LIST , то применяется хешсекционирование, основанное на хеш-функции. В этом случае строки таблицы равномерно распределяются между секциями на основании внутренних алгоритмов хеширования Oracle. При этом чем уникальнее значения столбца в таблице, по которому идет секционирование, тем лучше будет распределение данных по разделам. Первичный ключ или уникальный столбец (столбцы) является самым хорошим хеш- ключом. Oracle рекомендует число секций N как степень 2, т.е. N=2,4,8,16,32 и т.д. При этом добавление или удаление какой-то хеш-секции вызывает перезапись всех данных в другие секции. Рассмотрим HASH секционирование на примере индексноорганизованной таблицы LISTIN. Целью HASH секционирования таблицы было добиться существенного снижение числа блокировок, возникающих в этой таблице. Эта цель была успешно реализована за счет секционирования таблицы по 16 секциям (фраза PARTITIONS 16 ), где ключом секционирования выступал столбец TASKISN. Команда создания таблицы имеет вид:
Следует заметить, что если в качестве ключа секционирования используется столбец, в котором имеем очень неравномерное распределение значения столбца (малая уникальность), то применение хеш-секционирования не целесообразно. При этом число секций не имеет особого значения, поскольку все значения ключевого столбца «свалятся» в одну-две секции.
Замечание. Увидеть размер секций в mb по всем указанным выше методам можно по запросу:
Составное секционирование
При составном секционировании внутри секции создаются подсекции Однако в версиях до Oracle 11g смешанное секционирование разрешалось только по RANGE методу для секции и методам HASH или LIST для подсекции. В Oracle 11g варианты методов секций-подсекций были существенно расширены, и в настоящее время можно осуществлять составное секционирование в следующих комбинациях: Range-Range, Range-Hash , Range-List, List-Range, List-Hash или Ust-List. Надо отметить, что при составном секционировании данные физически хранятся в подсекциях, а секции высту-пают только в роли логических контейнеров.
Рассмотрим смешанное секционирование на примере таблицы платежей AIF.PAY_ORD_RECORD с делением таблицы на секции по методу RANGE , а на подсекции по методу LIST . Ключом секционирования по секциям выступает столбец PAY_DATA (тип date), а ключом секционирования подсекции выступает столбец STATUS (тип number), принимающий три значения: 0. 1,2. Команда создания секционированной таблицы в Oracle 11g с секционированием по месяцам примет вид:
где разбиение по секциям задает фраза PARTITION BY RANGE (PAY_DATA) , а по подсекциям фраза SUBPARTITION BY LIST (STATUS) . Далее идет список подсекций со своими значениями: STATUS_0 VALUES (0) . STATUSJ VALUES (1) . STATUSJ? VALUES (2) . Для каждой подсекции может быть задано свое табличное пространства, которое может отличаться от табличного пространства таблицы HSTDATA. С гомощью предложения SUBPARTITION TEMPLATE один и тот же набор подсекций будет автоматически использоваться во всех секциях. Однако создание подсекций можно сделать вручную, указав все подсекции для каждого секции. Просмотреть созданные подсекции по имени таблицы можно по запросу:
Системное секционирование (system partitioning)
Появилось в Oracle 11 g и применяется, как правило, для таблиц, которые не могут быть секционированы никакими другими методами. В этом методе Oracle сам управляет, какую строку таблицы в какую секцию помещать. Для этого метода необходимо просто написать название секций, например, секции Р1, Р2, РЗ:
Увидеть разбиение таблицы на секции можно по запросу:
Увидеть метод секционирования, что он именно SYSTEM , можно по запросу:
Следует заметить, что для правильного ввода данных в таблицу надо, помимо имени таблицы, указать еще имя сегмента, иначе будет ошибка ORA-14701 . Тоже для ускоренной выборки данных по запросу следует указать имя сегмента.
Замечание. В таблице подвергнуться секционированию может не только сама таблица, но и индексы таблицы. В силу объемности и важности материала о секционировании индексов пойдет речь во второй части. Там же будет рассказано об особенностях перехода от несекционированных больших по объему таблиц к секционированным таблицам, в том числе о возникающих в этих случаях особенностях поведения индексов, триггеров, синонимов и т.д. этих таблиц.
Читайте также: