Oracle scn что такое
Обновлено: 07.07.2024
Продолжение статьи про Real Application Cluster (RAC). Окончание.
Считаем, что кластер поднялся и все закрутилось.
Взаимодействие узлов. Cache-fusion.
Много экземпляров БД, много дисков. Хлынули пользовательские запросы… вот они, клиенты, которых мы так ждали. =)
Самым узким местом любой БД являются дисковый ввод-вывод. Поэтому все базы данных стараются как можно реже обращаться к дискам, используя отложенную запись. В RAC все так же, как и для single-instance БД: у каждого узла в RAM располагается область SGA (System Global Area), внутри нее находится буферный кэш (database buffer cache). Все блоки, некогда прочитанные с диска, попадают в этот буфер, и хранятся там как можно дольше. Но кэш не бесконечен, поэтому, чтобы оценить важность хранимого блока, используется TCA (Touch Count Algorithm), считающий количество обращений к блокам. При первом попадании в кэш, блок размещается в его cold-end. Чем чаще к блоку обращаются, тем ближе он к hot-end. Если же блок «залежался», он постепенно утрачивает свои позиции в кэше и рискует быть замещенным другой записью. Перезапись блоков начинается с наименее используемых. Кэш узла – крайне важен для производительности узлов, поэтому для поддержания высокой производительности в кластере кэшем нужно делиться (как завещал сами-знаете-кто). Блоки, хранимые в кэше узла кластера, могут иметь роль локальных, т.е. для его собственного пользования, но некоторые уже будут иметь пометку глобальные, которыми он, поскрипев зубами дисками, будет делится с другими узлами кластера.
Технология общего кэша в кластере называется Cache-fusion (синтез кэша). CRS на каждом узле порождает синхронные процессы LMSn, общее их название как сервиса — GCS (Global Cache Service). Эти процессы копируют прочитанные на этом экземпляре блоки (глобальные) из буферного кэша к экземпляру, который за ними обратился по сети, и также отвечают за откат неподтвержденных транзакций. На одном экземпляре их может быть до 36 штук (GCS_SERVER_PROCESSES). Обычно рекомендуется по одному LMSn на два ядра, иначе они слишком сильно расходуют ресурсы. За их координацию отвечает сервис GES (Global Enqueue Service), представленный на каждом узле процессами LMON и LMD. LMON отслеживает глобальные ресурсы всего кластера, обращается за блоками к соседним узлам, управляет восстановлением GCS. Когда узел добавляется или покидает кластер, он инициирует реконфигурацию блокировок и ресурсов. LMD управляет ресурсами узла, контролирует доступ к общим блоками и очередям, отвечает за блокировки запросов к GCS и управляет обслуживанием очереди запросов LMSn. В обязанности LMD также входит устранение глобальных взаимоблокировок в рамках нескольких узлов кластера.

Таблица GRD распределена между узлами кластера. Каждый узел принимает участие в распределении ресурсов кластера, обновляя свою часть GRD. Часть таблицы GRD относится к ресурсам – объектам: таблицы, индексы и.т.п. Она постоянно синхронизируется (обновляется) между узлами.
Когда узел прочел блок данных с диска, он становится master-ом этого ресурса и делает соответствующую отметку в своей части таблицы GRD. Блок помечается как локальный, т.к. узел пока использует его в одиночку. Если же этот блок потребовался другому узлу, то процесс GCS пометит этот блок в таблице как глобальный («опубликован» для кластера) и передаст затребовавшему узлу.
| DBA | location | mode | role | SCN | PI/XI |
| 500 | узел №3 | shared | local | 9996 | 0 |
- Data Block Address (DBA): физический адрес блока
- Location: узел на котором доступен этот блок
- Resource mode: определяется тем, кто на текущий момент является владельцем блока и какая операция к нему будет применяться
- null: узел не претендует на изменение этого блока (только select)
- shared: к блоку осуществляется защищенный множественный доступ только для чтения на нескольких узлах.
- exclusive: узел собирается изменить (или уже изменил) этот блок. Хотя одновременно в кластере могут содержаться прежние (согласованные) версии этого же блока, менять их нельзя.
- local: когда узел только прочитал блок с диска, и ни с кем им еще не делился.
- global: когда узел был изначально считан этим блоком, но после был передан запросившему его узлу в некотором режиме (mode). Теперь этот же блок может присутствовать на других узлах.
- Past Image (PI): глобальный грязный блок (старая версия, после изменения), хранящийся в кэше узла после того, как узел передал его по сети другому. Блок держится в памяти пока он или более поздняя версия не будет записана на диск, о чем оповестит GCS, когда блок будет больше не нужен.
- Current Image (XI): текущая последняя копия блока, содержащаяся в последнем узле кластера в цепочке запросов этого блока.
- как можно реже обращаться к диску, за счет активной работы с кэшем
- обеспечить consistency read (CR), согласованность по чтению, т.е. данные неподтвержденной транзакции никто никогда не увидит ни в какой (параллельной) сессии
- Read/read behavior (no transfer).
Пусть данные таблицы A первым считал узел №4. Он является master этой таблицы и отвечает за соответствующую часть в GRD. - На узел №3 пришел запрос на чтение из таблицы A. У узла №3 в кэше нет необходимого блока. Из GRD он узнает, что master таблицы A – это узел №4, и обращается к нему.
- Узел №4 просматривает GRD на наличие запрашиваемого блока. Если бы он был у него в кэше, то он просто бы передал его. Но допустим, что нужного блока не оказалось. Узел №4 отправит узлы №3 самостоятельно считать этот блок с диска.
- Узел №3 сам считывает его с диска, пока только для себя и ни с кем блоком не делится (local), но впоследствии может предоставлять к нему доступ другим узлам через посредника — master-а этой таблицы (shared).
- Узел №3 отчитывается перед master таблицы A узлом №4, и тот вносит соответствующую запись в GRD (на узле №4):
Без необходимости никаких записей на диск не происходит. Всегда копия блока хранится на узле, на котором он чаще используется. Если определенного блока пока еще нет в глобальном кэше, то при запросе master попросит соответствующий узел прочитать блок с диска и поделиться им с остальными узлами (по мере надобности).
- Участвует 2 узла: когда целевому узлу потребовался блок, который хранился в кэше master.
- Участвует 3 узла: когда master отправляет запрос промежуточному узлу, и тот передает блок востребованному в нем узлу.
Taking fire, need assistance! Workload distribution.
Описанное устройство Cache-fusion, предоставляет кластеру возможность самому (автоматически) реагировать на загрузку узлов. Вот как происходит workload distribution или resource remastering (перераспределение вычислительных ресурсов):
Если, скажем, через узел №1 1500 пользователей обращается к ресурсу A, и примерно в это же время 100 пользователей обращается к тому же ресурсу A через узел №2, то очевидно, что первый узел имеет большее количество запросов, и чаще будет читать с диска. Таким образом узел №1 будет определен как master для запросов к ресурсу A, и GRD будет создано и координироваться начиная с узла №1. Если узлу №2 потребуются те же самые ресурсы, то для получения доступа к ним он должен будет согласовать свои действия с GCS и GRD узла №1, для получения ресурсов через interconnect.
Если же распределение ресурсов поменяется в пользу узла №2, то процессы №2 и №1 скоординируются свои действия через interconnect, и master-ом ресурса A станет узел №2, т.к. теперь он будет чаще обращаться к диску.
Это называется родственность (affinity) ресурсов, т.е. ресурсы будут выделяться тому узлу, на котором происходит больше действий по получению и их блокированию. Политика родственности ресурсов скоординирует деятельность узлов, чтобы ресурсы более доступны были там, где это более необходимо. Вот, кратко, и весь workload distribution.Перераспределение (remastering) также происходит, когда какой-то узел добавляется или покидает кластер. Oracle перераспределяет ресурсы по алгоритму называемому «ленивое перераспределение» (lazy remastering), т.к. Oracle почти не принимает активных действий по перераспределению ресурсов. Если какой-то узел упал, то все, что предпримет Oracle – это перекинет ресурсы, принадлежавшие обвалившемуся узлу, на какой-то один из оставшихся (менее загруженный). После стабилизации нагрузки GCS и GES заново (автоматически) перераспределят ресурсы (workload distribution) по тем позициям, где они более востребованы. Аналогичное действие происходит при добавлении узла: примерно равное количество ресурсов отделяется от действующих узлов и назначается вновь прибывшему. Потом опять произойдет workload distribution.
Как правило, для инициализации динамического перераспределения, загруженность на определенном узле должна превышать загруженность остальных в течение более 10 минут.Вот пуля пролетела, и… ага? Recovery.
- Часть GRD таблицы с ресурсами упавшего узла «замораживается».
- Не вышедший на связь узел помечается как «пропавший», чтобы оставшиеся узлы к нему не обращались зря по interconnect.
- Узел, который первым обнаружил пропажу, начинает восстановление информации, которая обрабатывалась на исчезнувшем узле:
- Понижает темпы обслуживания собственных транзакций, бросая вычислительные ресурсы на восстановление
- Обращается к общему файловому хранилищу (datastorage), и на себе начинает применять online redo logs, принадлежавшие пропавшему узлу. С учетом порядкового номера SCN блоков, merge их с тем, что хранится в буфере, и «накатывает» (roll-forward) в своем кэше. При этом узел пропускает те устаревшие записи блоков (PI), более поздние версии которых, уже были сброшены на диск. Если у считанных блоков в кластере присутствует master соответствующего ресурса, то узел сообщает список считанных блоков, и master на этих ресурсах выставляет блокировку, чтобы узлы к ним не обращались (пока они восстанавливаются).
- После чего, вторым прочтением по redo log, учитывая уже undo записи, откатывает (roll-back) незафиксированные транзакции. Происходит это по технологии fast-recovery, т.е. откат транзакций будет производиться отдельным background процессом. Oracle вернет заблокированные незавершенными транзакциями (uncommitted) блоки в согласованное состояние (consistent), к прежним значениям, как только придет запрос на эти блоки. Либо они уже к тому времени будут восстановлены этим самым параллельным background процессом. Таким образом, уже в кластере снимаются блокировки и могут выполняться новые запросы пользователей.
- Часть таблицы GRD, принадлежавшая упавшему узлу, размораживается на восстанавливающем узле (теперь он master ресурса). Таким образом, в кластере восстанавливается состояние обрабатываемых транзакций на пропавшем узле на момент «падения».
Но пока все эти процессы происходят, нетерпеливому клиенту есть что предложить.
Пока узлы спасают друг друга… Failover.
Virtual IP (VIP) – логический сетевой адрес, назначаемый узлу на внешнем сетевом интерфейсе. Он предоставляет возможность CRS спокойно запускать, останавливать и переносить работу с этим VIP на другой узел. Listener (процесс, принимающий соединения) на каждом узле будет прослушивать свой VIP. Как только какой-то узел становится недоступным, его VIP подхватывает на себя другой узел в кластере, таким образом, временно обслуживая свои и запросы упавшего узла.
- Database VIPs: Клиент подсоединится по VIP, но уже подключится к другому узлу. Временно замещающий узел ответит “logon failed”, несмотря на то, что VIP будет active, нужный экземпляр БД за ним будет отсутствовать. И клиент тут же повторит попытку, но уже к другому экземпляру/узлу кластера из своего списка в конфигурации.
- Application VIP: то же, что и прежде. Но только теперь по этому VIP можно будет обратиться к приложению, на каком бы узле оно ни крутилось.
Если узел восстановится и выйдет в online, CRS опознает это и попросит сбросить в offline на подменяющем его узле и вернет VIP адрес обратно владельцу. VIP относится к CRS, и может не перебросится если выйдет из строя именно экземпляр БД.
Важно отметить, что при failover переносятся только запросы select, вместе и открытыми курсорами (возвращающими результат). Транзакции не переносятся (PL/SQL, temp tables, insert, update, delete), их всегда нужно будет запускать заново.
- Connect-time failover and client load-balancing
В этом случае клиент всегда случайно выбирает к какому узлу кластера подключиться из своего списка конфигурации сетевого подключения. Если узел, выполняющий запрос, выходит из строя, то по TAF клиент выбирает другой узел кластера и переподключается. - Preconnect
В этом случае, клиент всегда при установлении соединения с кластером подключается ко всем узлам, хотя запрос будет запускать только на одном экземпляре. Если же узел выходит из строя, то просто переводит запрос на другой узел. Failover происходит быстрее, но расходует ресурсы на подключение на всех узлах кластера.
Туда не ходи, сюда ходи… Load-balancing.
При выполнении любых операций, информацию, относящуюся к производительности запросов (наподобие «отладочной»), Oracle собирает в AWR (Automatic Workload Repository). Она хранится в tablespace SYSAUX. Сбор статистики запускается каждые 60 минут (default): I/O waits, wait events, CPU used per session, I/O rates on datafiles (к какому файлу чаще всего происходит обращение).
Необходимость в Load-balancing (распределении нагрузки) по узлам в кластере определяется по набору критериев: по числу физических подключений к узлу, по загрузке процессора (CPU), по трафику. Жаль что нельзя load-balance по среднему времени выполнения запроса на узлах, но, как правило, это некоторым образом связано с задействованными ресурсами на узлах, а следовательно оставшимися свободными ресурсам.
О Client load-balancing было немного сказано выше. Он просто позволяет клиенту подключаться к случайно выбранному узлу кластера из списка в конфигурации. Для осуществления же Server-side load-balancing отдельный процесс PMON (process monitor) собирает информацию о загрузке узлов кластера. Частота обновления этой информации зависит от загруженности кластера и может колебаться в пределе от приблизительно 1 минуты до 10 минут. На основании этой информации Listener на узле, к которому подключился клиент, будет перенаправлять его на наименее загруженный узел.
- Based on elapsed-time (CLB_GOAL_SHORT): по среднему времени выполнения запроса на узле
- Based on number of sessions (CLB_GOAL_LONG): по количеству подключений к узлу
![Oracle Instance]()
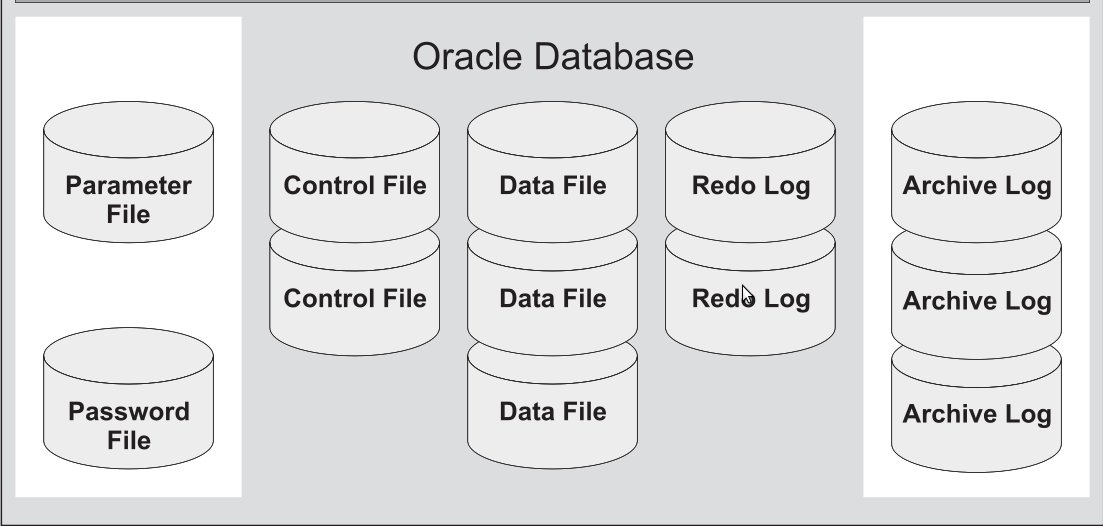
Предполагается, что вы инсталлировали базу данных, согласно документа.
Обязательные файлы:
Необязательные файлы:
-
(необязательные в том смысле, что база может быть настроена для работы без данных файлов) (Alertlog - если нет необходимости в изучении данных по ошибкам, можно удалить. Трассировочные файлы по умолчанию не создаются. Чтобы создавались, нужно включать трассировку и потом не забыть отключить) (По умолчанию не используются. Нужно специально создавать специальными командами.)
Файлы данных (Data Files)
Все данные в базе данных Oracle сохраняются в файлах данных. Все таблицы, индексы, триггеры, последовательности, программы на PL/SQL, представления - все это находится в файлах данных. И хотя эти и другие объекты базы данных логически содержатся в табличных пространствах, в действительности они сохраняются в файлах на жестком диске компьютера.
В каждой базе данных Oracle имеется по крайней мере один файл данных (но обычно их бывает больше). Если вы создаете в Oracle таблицу и заполняете ее строками, Oracle помещает эту таблицу и строки в файл данных. Каждый файл данных может быть связан только с одной базой данных.
У каждого файла данных имеется специальный формат, внутренний для программного обеспечения Oracle. Важно отдавать себе отчет в том, что файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных Oracle содержит несколько структур, в том числе и идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла.
Данные в файлы вносятся исключительно средствами Oracle.
Следующий запрос, покажет, где находятся файлы данных.
Оперативные файлы журналов повтора (Online Redo Log Files)
Оперативные файлы журналов повтора - предназначены для записи всех изменений, выполненных над данными базы данных Oracle. Используется для хранения на диске информации для повторного выполнения операций.
Для компьютера выполнить задачи повторно - означает выполнить ее точно так, как она выполнялась в предыдущий раз. Поэтому назначение оперативного файла журнала повтора заключается в сохранении информации об изменениях в базе данных таким, образом, чтобы позже их можно было повторить.
Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, после его заполнения (или переключения некоторыми командами), база данных приступает к записи в следующий файл. Эта операция называется переключением журналов.
Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
Управляющие файлы (Control Files)
Поскольку база данных Oracle является физическим набором связанных файлов данных, то для их синхронизации и контроля требуется особые методы. Для этих целей используются управляющие файлы.
База данных Oracle может иметь один или несколько управляющих файлов. Если имеется несколько управляющих файлов, все они должны быть абсолютно идентичными. При каждом запуске базы данных Oracle читает информацию управляющего файла, а при каждом изменении размещения или добавления новых файлов данных и журналов базы данных обновляет управляющий файл.
Файлы параметров pfile, spfie (Parameter Files)
Файлы параметров используются для конфигурирования действий Oracle предже всего при старте. Для того, чтобы запустить экземпляр базы данных, Oracle должен прочесть файл параметров и определить, какие параметры инициализации установлены для этого экземпляра. В файле параметров содержатся многочисленные параметры и их установленные значения. Oracle считывает файл параметров при запуске базы данных. Можно создать несколько файлов параметров, каждый будет соответствовать различным конфигурациям экземпляра.
- spfile - бинарный файл, который используется сервером Oracle при старте.
- pfile - текстовый файл с параметрами, будет использоваться при старте, если не будет найден spfile.
При старте, Oracle считает файл spfileora112.ora. (файл серверных параметров). Преимущество spfile заключается в том, что при работе с базой данных, любые изменения в базе касающиеся изменения параметра системы, автоматически записываются в данный файл.
Если используется pfile, для сохранения изменений, необходимо либо “руками вносить эти изменения” в текстовый файл, либо в консоли выполнять команды для создания данных файлов Ораклом.
Как я могу узнать, что моя база данных использует PFILE или SPFILE?
Выполните следующий запрос, чтобы увидеть какой файл параметров был использован:
Архивные файлы журналов повтора (Archive Log Files)
Как только оперативный файл журнала повтора (Redolog) оказывается заполнен, программное обеспечение сервера Oracle начинает запись в следующий файл. Эта операция повторяется, как следствие информация в оперативных файлах журнала (Redolog) многократно перезаписывается.
Если необходимо сохранить историю изменений, нужно, чтобы после переключения журналов сохранялась их копия. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повтора жизненно важны при восстановлении. Если часть базы данных потеряна или повреждена, то для устранения повреждений обычно требуется несколько архивных журналов или туева хуча этих журналов. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут использоваться. Храните все свои архивные файлы журналов повтора с момента выполнения последней резервной копии. Файлы журналов постепенно накапливаются и разрастаются. Иногда необходимо их удалять. Все операции с данными файлами по применению их к базе выполняются исключительно средствами базы данных. А копировать и переносить их при желании можно как угодно. Бездумно удалять их руками не рекомендуется.
Alert log и трассировочные файлы (trace file)
При работе базы данных события и ошибки регистрируются в текстовых файлах на сервере базы данных. Файл журнала предупреждений (alert log) нужен администратору базы данных для отслеживания важнейших действий с базой данных - наподобие открытия и закрытия базы данных, установления параметров загрузки базы данных и переключения оперативных журналов повтора. Также в эти файлы записываются многие ошибки базы данных для последующего расследования их причин. Любые структурные изменения базы данных также регистрируются в файле журнала предупреждений.
Когда возникает ошибка базы данных, может генерироваться файл трассировки (trace file). Они содержит подробную информацию о возникновении ошибки.
Файлы паролей (Password File)
Необязательный файл, используется для защиты информации о подключениях привилегированных пользователей. Если отсутствует, то вы можете выполнять администрирование своей базы данных, только локально. Кроме того, с его помощью контролируется количество привилегированных подключений для управления в одно и то же время.
Tags: Oracle Database, Файлы базы данных Oracle,
Oracle DBA
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.
A mandatory tablespace that consists of the data dictionary, including definitions of tables, views, and stored procedures needed by the database. Oracle Database automatically maintains information in this tablespace.
A mandatory, auxiliary system tablespace that is used by many Oracle Database features and products. This tablespace contains content that was previously stored in the DRSYS , CWMLITE , XDB , ODM , OEM_REPOSITORY , and SYSTEM tablespaces.
An user-created tablespace that consists of application data. As you create and enter data into tables, Oracle Database fills this space with your data.
A mandatory tablespace that contains temporary tables and indexes created during SQL statement processing. You may have to expand this tablespace if you run SQL statements that involve significant sorting, such as ANALYZE COMPUTE STATISTICS on a very large table, or the constructs GROUP BY , ORDER BY , or DISTINCT .
System-managed tablespaces that contain undo data for each instance. Each Oracle RAC instance uses a different value for n in the tablespace name. These tablespaces are used for automatic undo management.
A system tablespace that contains rollback segments. If you do not use automatic undo management, then you must configure the RBS tablespace. The RBS tablespace should only be used when needed for compatibility with earlier versions of Oracle Database.
Посмотреть, какие табличные пространства имеются в базе данных можно следующим запросом.
В каких файлах хранятся табличные пространства.
Табличное пространство system
В табличном пространстве system хранится «Словарь данных Oracle»
Каждая база данных Oracle содержит набор таблиц, доступных только для чтения и известных как словарь данных (data dictionary), который содержит метаданные (информацию о различных компонентах базы данных). Словарь данных Oracle – сердце системы управления базой данных.
Словарь данных создается при создании экземпляра базы данных выполнением инструкций в файле $ORACLE_HOME/rdbms/admin/catalog.sql
Oracle не позволяет обращаться к таблицам словаря данных напрямую. Он создает представления на базе этих таблиц и общедоступные синонины для тих представлений, к которым могут обращаться пользователи. Существует три набора представлений словаря данных: USER, ALL и DBA – каждый из которых содержит сходный набор представлений со сходным набором столбцов.
Посмотреть содержимое табличного пространства system
Табличное пространство sysaux
Табличное пространство sysaux служит вспомогательным табличным пространством по отношению к табличному пространству system.
![Как изменяются блоки данных во время транзакций отмены Undo в базе данных Oracle]()
Всякий раз, когда сеанс просматривает блок данных в СУБД Oracle, он должен гарантировать, что вы получите соответствующую версию данных. То есть, с точки зрения внешнего наблюдателя, сеанс не должен видеть неподтвержденные данные, или данные, измененные и подтвержденные после того, как ваш запрос уже начал выполнение (или инструкция DML и даже транзакция – в зависимости от уровня изоляции). Это называют чтением согласованной версии данных.
Примечание. Легко забыть, что согласованное чтение является обязательным атрибутом изменяемых данных. Если сеанс изменяет данные в блоке, он должен иметь возможность видеть их с двух разных сторон – он должен видеть текущую версию данных, потому что в данный момент является единственным, наделенным правом доступа к ней, и он должен видеть согласованную версию данных, потому что при наличии существенных различий между двумя версиями, сеансу может потребоваться подождать, перезапустить текущую инструкцию или даже прервать работу, сгенерировав ошибку (обычно ORA-08177: can’t serialize access for this transaction или на русском ORA-08177: невозможно сериализовать доступ для этой транзакции ).
В следующих нескольких разделах статьи мы пройдемся по особенностям работы механизма согласованного чтения, поэтому нам нужно подготовить данные, чтобы точно знать их исходное состояние, и затем мы будем детально рассматривать, как один сеанс изменяет их, а другой предпринимает все возможное, чтобы не увидеть неподтвержденные изменения.
Подготовка полигона
Прежде чем выполнить какие-либо действия, рассмотрим содержимое единственного пока блока для нашей таблицы. Этот дамп необходим, чтобы мы могли видеть, как изменяется внутренняя информация, когда один сеанс изменяет данные, а другой пытается получить прежнюю версию этих данных.
Среди деталей, которые будут рассматриваться в этом разделе, имеется также список заинтересованных транзакций (Interested Transaction List, ITL) – табличный раздел в начале дампа, начинающийся с последовательности меток в пятой строке и содержащий две строки информации.
Список заинтересованных транзакций
В таблице ниже перечислены все элементы в списке ITL.
Набор битовых флагов для точной идентификации состояния транзакции: ----: активная (то есть, «никогда не завершалась»).
--U-: подтверждение по верхней границе (также устанавливается при выполнении «быстрого подтверждения»).
C---: транзакция подтверждена и все блокировки сброшены (всем соответствующим байтам блокировки присвоены нулевые значения).
-B--: может относиться к рекурсивным транзакциям, вызывающим деление блоков индексов (index block splits). Мне приходилось видеть комментарии, в которых утверждалось, что когда установлен этот флаг, столбец UBA будет указывать на запись, хранящую предыдущее содержимое элемента ITL, но мне не удалось найти подтверждений этому.
---T: Мне приходилось видеть комментарии, в которых утверждалось, что этот флаг означает, что транзакция была активной на момент очистки блока, но мне не удалось найти подтверждений этому.
В дампе блока, находящегося в исходном состоянии, можно видеть, что список ITL для этого блока содержит два элемента. Это – число элементов по умолчанию, когда создается таблица или индекс в версии Oracle Database 9i или выше. При желании создать (или перестроить) объект с более длинным списком ITL в каждом блоке, чтобы, например, минимизировать вероятность конфликтов на более высоком уровне при одновременном изменении данных, можно установить требуемое значение в параметре initrans во время создания объекта. Но часто это излишне, потому что списки ITL в любых блоках могут расти динамически, если в этом есть необходимость и достаточно свободного места в блоке.
Размер списка ITL ограничивается параметром maxtrans (по крайней мере, так было в ранних версиях Oracle), который имеет синтаксический предел 255, а физический предел определяется размером блока данных объекта. К сожалению, синтаксический предел игнорируется в версиях Oracle 10g и выше; и для блоков размером 8 Кбайт физический предел составляет 169 элементов.
Примечание. Параметр initrans действует порой несколько необычно. В случае с индексами, значение initrans применяется только к листовым блокам (leaf blocks) – каждый блок ветвления (branch block) (включая и корневой блок) получает список ITL с единственным элементом, который используется только для деления блоков. Первый элемент списка ITL в листовых блоках резервируется для их деления, при этом существует один особый случай: когда новый индекс создается в пустой (или почти пустой) таблице, единственный блок индекса будет одновременно играть роль корневого блока (блок ветвления) и листового блока, поэтому он получит список ITL с двумя элементами – один, как блок ветвления, и второй, как листовой блок, необходимый для выполнения других действий, отличных от деления блока. Исторически, параметру initrans по умолчанию присваивалось значение 1 для таблиц, но в последних версиях Oracle стало присваиваться значение 2, даже при том, что словарь данных все еще сообщает о значении по умолчанию 1. (А если загрузить блоки, используя метод прямой загрузки (direct path loads), можно обнаружить, что они изначально получают списки ITL с тремя элементами.)
Список ITL предназначен для идентификации транзакций, последними изменявших блок данных, но так как он занимает место, Oracle стремится хранить как можно более короткие списки ITL. (Oracle не уменьшает размеры списков ITL, после того, как они вырастут; возможно для этой операции отсутствуют подходящие моменты, хотя, в некоторых крайних случаях вам может показаться, что они являются «очевидными» событиями, чтобы сделать это.) Кроме того, при делении листовых блоков индексов старый список ITL копируется в новый листовой блок, и эта стратегия может приводить к существенным затратам памяти.
Примечание. Существует два других числа SCN, хранимых в фиксированных местоположениях в каждом блоке данных: «номер очистки блока» (cleanout SCN, в дампе обозначается меткой csc:) – число SCN, отражающее число операций и изменяющееся операцией полной очистки блока (см. раздел «Отложенная очистка блока» ниже в этой главе), и «номер последнего изменения» (в дампе обозначается меткой scn:), который изменяется при изменении содержимого блока и связан с дополнительным байтом (с меткой seq:), где хранится число изменений блока с данным значением SCN (если байт seq: достигает значения 254, в следующий раз ему будет присвоено значение 1 и будет увеличено на единицу значение SCN в экземпляре).
Итак, в этом блоке мы видим короткий список последних транзакций. В действительности данный блок еще настолько новый, что один из элементов списка ITL пока не использовался – элемент с индексом 0x02 пока пустой. Но в элементе с индексом 0x01 можно видеть, что совсем недавно блок изменялся транзакцией 1.1.1de4 (undo-сегмент 1, слот 1, номер 7652). Она была подтверждена с номером SCN 0x01731c46, но блок еще не был очищен, потому что имеет флаг --U- подтверждения по верхней границе (ниже мы будем рассматривать разные эффекты, проявляющиеся при подтверждении транзакции), а счетчик блокировок сообщает, что заблокировано три строки. (Чуть ниже в дампе можно видеть, что все три строки в блоке имеют значение lb: 0x01 – то есть, эти строки заблокированы транзакцией в элементе 0x01 списка ITL.) Наконец, по значению uba видно, что если перейти к записи 5 в блоке 11976, в файле 6 (который должен иметь порядковый номер 0x0543), можно найти информацию, описывающую, как отменить последние изменения, выполненные транзакцией.
Я не буду приводить полный дамп соответствующей записи отмены, а только сообщу, что запись 5 из блока отмены говорит следующее: «очистить слот (строку) 0x02 в блоке таблицы и изменить uba в элементе 1 списка ITL на 0x01802ec8.0543.04 (то есть, чтобы он указывал на запись 0x04 в текущем блоке отмены)». Запись 4 говорит: «очистить слот (строку) 0x01 в блоке таблицы и изменить uba в элементе 1 списка на 0x01802ec8.0543.03». И, наконец, запись 3 говорит: «очистить слот (строку) 0x01 в блоке таблицы и изменить uba в элементе 1 списка на: ‘прежде не использовался’».
Параллельные операции
Теперь, когда у нас имеются некоторые исходные данные и блок, с одним использованным и одним неиспользованным элементом ITL, давайте запустим четыре отдельных сеанса и выполним следующие операции – именно в таком порядке:
Первый вызов в сеансе, который я обозначил как «My session» (мой сеанс) устанавливает уровень изоляции «только для чтения» (см. главу 2), фактически фиксируя состояние базы данных (с точки зрения этого сеанса), в каком она находилась в этот момент времени или, точнее говоря, для данного значения SCN.
С этого момента к сеансу «My session» будут применяться два ограничения: во-первых, ему не позволено будет видеть любые неподтвержденные изменения, производимые другими пользователями (что, впрочем, характерно также для стандартного в Oracle уровня изоляции read committed – чтение подтвержденных изменений) и, во-вторых, в этом сеансе вообще нельзя будет увидеть никакие подтвержденные изменения, выполненные после этого момента.
То есть, когда я выполняю инструкцию select, неподтвержденные изменения, выполненные в сеансе 1, и подтвержденные, выполненные в сеансе 3, должны оставаться невидимыми для меня и я должен видеть только подтвержденные изменения, выполненные в сеансе 2. Мой запрос должен вернуть множество результатов: (1,1), (2,102), (3,3). С другой стороны, из-за того, что Oracle изменяет блоки почти в реальном масштабе времени, к моменту запуска моего запроса все изменения будут выполнены в копиях блоков, находящихся в памяти. Что же происходит внутри Oracle, что позволяет мне получить правильные результаты?
Ниже приводится сокращенный до минимума дамп блока после того, как три сеанса выполнят свои изменения, непосредственно перед запуском моего запроса:
Я вынудил Oracle записать этот блок на диск вызовом alter system checkpoint перед выводом дампа, чтобы показать, что все изменения (включая неподтвержденные, выполненные в сеансе 1) находятся не только в буферизованных копиях затронутых блоков, но также могут быть сохранены на диск. Обратите внимание, что строки 0 и 1 изменили свое местоположение в блоке (0x1f7b и 0x1f71 вместо прежних смещений 0x1f97 и 0x1f8d, которые можно видеть в предыдущем дампе) – так как длины строк увеличились, их пришлось скопировать в свободное пространство в блоке, чтобы сохранить изменения. Строка 2, напротив, осталась на прежнем месте (0x1f85), потому что ее длина не изменилась и ее оказалось возможным изменить на месте.
Взгляните внимательнее на список ITL: несмотря на то, что было выполнено три транзакции с этим блоком, в списке по-прежнему имеется всего два элемента. Это объясняется тем, что Oracle стремится сохранить список ITL максимально коротким и повторно использует элементы списка ITL, описывающие уже подтвержденные транзакции. (Элементы ITL повторно используются в порядке увеличения номеров SCN.)
Элемент списка ITL с индексом 0x01 демонстрирует эффект фиксирующей очистки (commit cleanout), быстрой, но неполной очистки, которая может применяться к некоторым измененным блокам при подтверждении транзакции. Флаг получает значение --U-, но счетчик блокировок остается равным 1, а поле Scn/Fsc остается равным fsc, даже при том, что само значение подтвержденного SCN равно 0x01731c83. Если заглянуть в тело блока, можно увидеть, что строка 2 (третья) имеет значений 0x01 в байте блокировки (lb:) – строка 2 является единственной, заблокированной транзакцией 1 в списке ITL. Этот элемент списка соответствует третьей транзакции, которая присвоила столбцу n1 новое значение 99 и была подтверждена.
Элемент 0x02 списка ITL выглядит так, как если бы соответствующая ему транзакция еще не была подтверждена. По причинам, с которыми мы познакомимся ниже, такая ситуация может интерпретироваться ошибочно – вполне возможно, что транзакция была подтверждена некоторое время тому назад, но Oracle еще не успел выполнить очистку и пометить транзакцию как подтвержденную. Фактически, этот элемент ITL хранит информацию о первой, неподтвержденной транзакции и мы можем видеть, что она блокирует одну строку (Lck = 1 в элементе ITL), и что строка 0 – это строка в блоке, которая была заблокирована элементом 0x2 ITL (lb: = 0x2 в теле блока).
Сейчас хорошо было бы показать динамическую диаграмму происходящего, отображающую, как изменяются во времени связи между элементами ITL и соответствующими частями undo-сегмента, но лучшее, что я могу предложить – это рисунок ниже, где показан обобщенный пример, как ITL указывает на соответствующий слот таблицы транзакций в заголовке undo-сегмента, тогда как uba ссылается на конкретную запись в блоке отмены в этом сегменте, и – если это окажется самый последний блок в транзакции – как слот в таблице транзакций может указывать на тот же самый блок отмены.
![]()
Рис. 1. Связи между элементом ITL и соответствующим undo-сегментом
Читайте также: