
Oracle sharding что это
Обновлено: 03.07.2024
Шардинг, перебалансировка и распределенные транзакции в реляционных базах данных
При разработке нового проекта в качестве основной СУБД нередко выбираются реляционные базы данных, такие, как PostgreSQL или MySQL. В этом действительно есть смысл. Первое время у проекта мало пользователей, и потому все данные помещаются в один сервер. При этом проект активно развивается. Нельзя заранее сказать, какой функционал в нем станет основным, а какой будет выкинут. Есть много историй о том, как мобильный дейтинг в итоге превращался в криптомессанджер, и подобного рода. РСУБД удобны на ранних этапах, потому что они универсальны. Так, PostgreSQL из коробки имеет встроенный полнотекстовый поиск, умеет эффективно работать с геоданными, а также подходит для хранения очередей и рассылки уведомлений. По мере развития проекта и роста нагрузки часть данных может быть перенесена в специализированные NoSQL решения. Также нагрузку можно распределить, поделив базу на несколько совершенно не связанных между собой баз, а также при помощи потоковой репликации. Но что делать в случае, если все это не помогло? В этом посте я постараюсь ответить на данный вопрос.
Примечание: Хочу поблагодарить gridem, sum3rman и gliush за активное участие в обсуждении поднятых в данном посте вопросов. Многие из озвученных ниже идей были позаимствованы у этих ребят.
Декомпозиция проблемы
Задачу построения горизонтально масштабируемого РСУБД-кластера можно разделить на следующие сравнительно независимые задачи:
Попробуем рассмотреть озвученные проблемы по отдельности.
Шардинг
Существует много схем шардирования. С довольно полным списком можно ознакомиться, например, здесь. Насколько мне известно, наиболее практичной и часто используемой схемой (в частности, она используется в Riak и Couchbase) является следующая.
<"format_version": 1,
"vbuckets": [
"cluster1",
"cluster2",
.
"clusterN"
]
>
Перебалансировка
Что делать в случае, если мы хотим переместить vbucket с одного репликасета на другой?
Итак, все клиенты знают о начале перебалансировки. Далее возможны варианты.
Дополнение: Вместо pglogical вы, вероятно, захотите использовать логическую репликацию, которая начиная с PostgreSQL 10 теперь есть из коробки.
В случаях (1) и (2) данные можно переносить обычным pg_dump или воспользоваться COPY:
Следует также отметить, что вместо логической репликации можно использовать обычную потоковую. Для этого нужно, чтобы каждый vbucket жил на отдельном инстансе СУБД. В частности, PostgreSQL позволяет легко запускать много инстансов на одной физической машине безо всякой виртуализации. В этом случае вы, вероятно, захотите выбрать несколько меньшее число vbuckets, чем предложенные ранее 1024. Еще, как альтернативный вариант, можно реплицировать вообще все данные, а потом удалять лишние. Но это дорого и будет работать только при введении в строй совершенного нового репликасета.
На мой взгляд, наиболее правдоподобным и универсальным вариантом на сегодняшний день является использование потоковой репликации с удалением лишних данных по окончании репликации по сценарию (3). Это работает только при добавлении совершенно нового, пустого репликасета. В случае, если данные нужно слить с нескольких репликасетов в один, следует использовать pg_dump по сценарию (1).
Решардинг
// былоvbucket_num = hash(key) % 1024 [ = hash(key) & 0x3FF ]
// стало
vbucket_num = hash(key) % 2048 [ = hash(key) & 0x7FF ] // оператор ++ означает операцию append, присоединение массива с конца
dict.vbuckets = dict.vbuckets ++ dict.vbuckets
Распределенные транзакции
Поскольку бакеты могут быть логически связанными и храниться на разных репликасетах, иногда приходится делать транзакции между репликасетами. При правильно выбранной схеме шардирования распределенные транзакции должны выполняться редко, поскольку они всегда недешевы. Если в вашем проекте распределенные транзакции не нужно делать никогда, вам сильно повезло.
Как всегда, в зависимости от ситуации задачу можно решить разными способами. Допустим, вы решили воспользоваться описанной выше идеей с неизменяемыми данными, и каждый пользователь в вашем проекте читает данные только из своего бакета. В этом случае «транзакцию» между бакетами А и Б можно выполнить по предельно простому алгоритму:
- Создайте объект «транзакция», хранящий все, что вы хотите записать в бакеты А и Б.
- Произведите запись в бакет А. Запись должна производиться в одну локальную транзакцию, а у записанных объектов должна быть метка, к какой транзакции они относятся. Если объекты с соответствующей меткой уже записаны, ничего не делать.
- Аналогичным образом произведите запись в бакет Б.
- Удалите объект «транзакция»;
Само собой разумеется, это не настоящие транзакции, но для многих проектов их будет более, чем достаточно. При определенных условиях этот подход можно применить даже в случае, если данные в бакетах изменяемые.
Описание более универсального подхода можно найти в блоге Дениса Рысцова. Также этот прием описан как минимум в документации к MongoDB и блоге CockroachDB. В общих чертах алгоритм примерно такой:
Важно! Приведенное описание предполагает, что каждая операция чтения или записи выполняется в отдельной транзакции при уровне изоляции serializable. Или, в более общем случае, если СУБД не поддерживает транзакций, в одну CAS-операцию. Однако выполнение нескольких операций в одной транзакции не влияет на корректность алгоритма.
Этот алгоритм довольно неприятно применять по той причине, что абсолютно все транзакции, включая локальные, должны понимать, как трактовать локальные изменения. Алгоритм обеспечивает уровень изоляции repeatable read. Это уровень изоляции менее строгий, чем snapshot isolation и serializable, и на нем возможны некоторые аномалии (phantom read, write skew). Тем не менее, он подходит для многих приложений, если знать об его ограничениях.
Хочу еще раз подчеркнуть важность проставления метки транзакции на шаге (2) не только при записи, но и при чтении. Если этого не делать, другая транзакция может изменить объект, который вы читаете, и при повторном его прочтении вы увидите что-то другое. Если вы точно знаете, что не станете ничего писать в него, то можете просто закэшировать объект в памяти.
Заключение
Как вы могли убедиться, тут довольно сложно представить универсальное решение, подходящее абсолютно всем и всегда. И это мы еще упустили из виду, например, такие важные вопросы, как репликация между несколькими ДЦ и снятие консистентных бэкапов с множества репликасетов! Именно ввиду существования огромного количества возможных решений мы не рассматривали вопрос автоматизации всего описанного выше.
Надеюсь, что вы нашли представленный выше материал интересным. Как обычно, если у вас есть вопросы или дополнения, не стесняйтесь оставлять их в комментариях!
Дополнение: В этом контексте вас также может заинтересовать статья Поднимаем кластер CockroachDB из трех нод.
Когда ваша база данных небольшая (10 ГБ), вы можете легко добавить больше ресурсов и таким образом масштабировать ее. Однако, поскольку таблицы растут, нужно подумать и о других способах масштабирования базы данных.
С одной стороны шардинг — лучший способ масштабирования. Он позволяет линейно масштабировать ресурсы базы данных, памяти и диска, дробя базу данных на более мелкие части. С другой стороны целесообразность использования шаринга — спорная тема. Интернет полон советов по шардингу, от «масштабирования инфраструктуры базы данных» до «почему вы никогда не используете шардинг». Итак, вопрос в том, какую сторону принять.
Всегда, когда возникал вопрос шардинга, ответ был «раз на раз не приходится». Теория шардинга проста: выберите один ключ (столбец), который равномерно распределяет данные. Убедитесь, что большинство запросов могут быть решены с помощью этого ключа. Эта теория проста, но только до того момента, пока вы не приступите к практике.
В Citus мы помогли сотням команд, когда они обращались к шардингу баз данных. С получением опыта мы обнаружили, что имеются ключевые шаблоны.
В этой статье мы сначала рассмотрим ключевые параметры, которые влияют на успех шардинга, а затем раскроем основную причину, по которой мнения о шардинге столь разные. Когда дело доходит до шардинга базы данных, на успех в большей степени влияет тип приложения, которое вы создаете.
На успех шардинга базы данных влияют 3 ключевых параметра. На диаграмме они показаны на трех осях, а также приведены примеры известных компаний.

Ось X на диаграмме показывает тип рабочей нагрузки. Эта ось начинается с транзакционных нагрузок слева и продолжается организацией хранилищ данных. Изменения этой оси более заметны при шардинге.
Ось Z демонстрирует еще один важный параметр — нахождение в жизненном цикле приложения. Сколько таблиц у вас есть в базе данных (10, 100, 1000) или как долго приложение находится в производстве? Приложение, запущенное на PostgreSQL в течение нескольких месяцев, будет легче шардироваться, чем приложение, которое было в производстве в течение многих лет.
В Citus мы обнаружили, что большинство пользователей имеют достаточно развитые приложения. Когда приложение развито, ось У становится критической. К сожалению, изменения этой оси не так заметны, как изменения остальных осей. Фактически большинство статей, которые противоречат выводам о фрагментации, предоставляют свои рекомендации в контексте одного типа приложения.
Ось У на диаграмме показывает наиболее важный параметр при шардинге баз данных — тип приложения. В верхней части этой оси находятся приложения B2B, модели данных которых более удобны для фрагментации. В нижней части этой оси — приложения B2C, такие как Amazon и Facebook, которые требуют больше работы. Далее мы расскажем о различиях трех известных компаний.
Хорошим примером приложения для B2B является программное обеспечение CRM. Когда вы создаете CRM-приложение, такое как Salesforce, ваше приложение будет обслуживать других клиентов. Например, компания GE Aviation будет одним из ваших клиентов, использующих Salesforce.
В GE Aviation есть пользователи, которые входят в свою панель мониторинга компании. GE также фиксирует:
потенциальных клиентов, с которыми они могут вести бизнес,
контакты/людей, которые уже известны и с которыми установлены деловые отношения,
счета, которые представляют бизнес-единицы и у которых есть работающие на них контакты,
возможности, которые являются событиями продаж, связанными с учетной записью и одного или нескольких контактов.
Сопоставление этих сложных соотношений выглядит следующим образом:

График выглядит сложным. Но изучив график, можно заметить, что большинство таблиц происходит из таблицы клиентов. Графы можно преобразовать, добавив столбец customer_id ко всем таблицам.

С помощью этого простого преобразования у базы данных теперь есть хороший ключ оглавления: customer_id. Он равномерно распределяет данные, и большинство запросов к базе данных будут включать ключ клиента. Кроме того, вы можете размещать таблицы в client_id и продолжать использовать ключевые функции реляционной базы данных, такие как транзакция, объединение таблиц и ограничение внешнего ключа.
Другими словами, если у вас есть приложение B2B, характер ваших данных дает вам фундаментальное преимущество при шардинге.

Интернет полон мнений о шардинге. Мы обнаружили, что большинство этих мнений формируются с учетом одного типа приложения. Фактически тип приложения (B2B или B2C) влияет на успех более всего. В частности, если у вас приложение для B2B, то вам будет легче шардировать реляционную базу данных.
При планировании масштабирования базы данных нужно иметь полное представление об этом процесcе и оценить все параметры с учетом требований проекта.

Корпорация Oracle любит инновации, лелеет инновации, взращивает их и удобряет, поэтому инновации в этой компании цветут пышным цветом. Соответственно, в новой СУБД Oracle Database 12.2 - полно новинок. О них в ходе технологического форума Oracle Database and Cloud рассказал Сергей Томин, ведущий консультант департамента технологического консалтинга компании Oracle СНГ.
Прежде всего, была улучшена производительность Oracle Database In-Memory, которая предоставляет возможность размещения данных в оперативной памяти в двух форматах: стандартном - строчном, и колоночном. Данные в колоночном формате размещаются в сжатом виде в отдельном кэше, In-Memory Column Store. В результате такой ценный ресурс, как память, экономится, данные сжимаются в среднем в 5-6 раз. Буферный и колоночный кэши активны одновременно, колоночный кэш автоматически синхронизируются с буферным кэшем. В ходе работы происходит динамический выбор - использовать буферный кэш или колоночный.
Казалось бы, эка невидаль, новый кэш! Тем не менее, второй кэш заметно повышает производительность аналитических запросов, так как колоночная структура хранения данных идеально подходит для них. Но, если использовать только колоночное хранение данных, то производительность будет "проседать" на OLTP-нагрузке. Например, если нужно вписать в таблицу базы данных Oracle строку то, казалось бы, это одна операция. Но когда данные разбиты по столбцам, то вместо одной операции необходимо провести несколько операций равное числу столбцов таблицы. Поэтому Oracle и предлагает двойной формат хранения данных, позволяющий ускорить не только аналитические запросы но и DML-операции за счет отказа от дополнительных индексов.
В использовании кэша In-Memory есть и маленькие хитрости. Так, в настоящее время процессоры не могут поддерживать все типы данных Oracle. Чтобы использовать векторные операции процессоров, данные кодируются. При этом возникает проблема: например, есть две таблицы, и у них один общий столбец, по которому делается соединение. Но этот столбец может кодироваться различным образом у разных таблиц. В Oracle Database 12.1 необходимо восстанавливать исходные значения столбца, что требует дополнительных затрат CPU. А в Oracle Database 12.2 можно указать, что столбцы связаны, создать Join Group, в результате столбцы будут закодированы одинаково.
Появилось и еще одно нововведение: материализация выражений в оперативной памяти. В случае, если нужно миллион раз вычислить какое-то выражение для аналитического запроса, можно объявить выражение виртуальным столбцом и разместить его в In-Memory кэше, где значения выражения будут заранее просчитаны.
На повышение производительности работает и функция автоматической оптимизации данных, которая теперь распространилась и на Oracle Database In-Memory. Когда в последний раз пользовались конкретными данными? Если больше 120 дней назад - данные выгружаются из колоночного кэша.
Есть нововведения и в деле первоначальной загрузки данных в колоночный кэш. Как быстро загрузить с диска в оперативную память несколько терабайт данных? Сложно, долго и дорого? Вовсе нет. С функцией In-Memory Fast Start, которая позволяет хранить копию колоночного кэша на диске, первоначальная загрузка ускоряется примерно в пять раз.
В СУБД Oracle Database 12.2 появился и новый механизм сжатия индексов Advanced Index Compression HIGH, схожий с существующими алгоритмами Advanced Row Compression и Hybrid Columnar Compression для таблиц. Этот новый алгоритм позволяет сжать индексы в 4,6 раза. Да, производительность немного теряется, но существенно экономится дисковое пространство.
Веское слово было сказано и в области безопасности. Теперь применяется шифрование табличных пространств "на лету". Ранее, чтобы поменять ключ шифрования, нужно было ограничивать доступ пользователей, это делалось офлайн. Теперь все на ходу. Кроме того, у опции Database Vault появился режим эмуляции. В этом режиме не ограничивается доступ к данным, но регистрируются нарушения правил доступа к данным, заданных в Database Vault. Это позволяет настроить правила доступа к данным во время разработки и тестирования приложения и избежать проблем при вводе Database Vault в промышленную эксплуатацию.
Появились и новые функции для разработчиков. Например, одно маленькое, но приятное улучшение: длинные идентификаторы. Максимальная длина имени большинства типов объектов базы данных теперь не 30 байт, а 128. Можно присваивать более понятные имена.
Существенно доработана опция Oracle Multitenant, хорошо подходящая для SaaS-приложений. Oracle Multitenant позволяет значительно сэкономить на административных расходах повысить эффективность использования аппаратных ресурсов благодаря консолидации большого количества мелких баз данных в одну конейнерную. В Oracle Database 12.2 максимальное количество подключаемых баз данных в контейнерной базе данных увеличено с 252 до 4096.
Опция Multitenant в сочетании с технологией тонкого клонирования позволяет быстро создавать клоны продакшн-системы, что отлично подходит для разработки и тестирования. Если раньше надо было перед клонированием переводить подключаемую БД в режим read only, то теперь можно сделать клон подключаемой БД на лету без остановки работы пользователей. Можно также в режиме online перенести подключаемую БД в облако.

Есть в СУБД Oracle 12.2 и кое-что принципиально новое. Это Oracle Sharding - разбиение таблиц по разным базам данных. Эта технология повышает отказоустойчивость БД и предоставляет возможности для масштабирования. Инициатором нововведения стали крупные пользователи, в частности, сеть LinkedIn. В результате "шардинга" вместо одной физической БД появляется несколько с одинаковой логической схемой, называемые "шардами". Максимальное количество "шардов" - до 1 тысячи, причем у каждой таблицы должен быть единый ключ шардирования. Пользователя автоматически направляют туда, где хранится его информация, в зависимости от значения ключа шардирования, указываемого в строке соединения. Соединение таблиц в таких базах работает только в рамках отдельного шарда, но можно сделать агрегацию данных по нескольким шардам.
Есть новые функции и среди аналитики. Так, к появившейся в Oracle Database 12.1 функции приблизительного вычисления количества различных значений столбца добавилась функция приблизительного вычисления перцентиля. Дополнительно эти функции могут возвращать стандартную ошибку и доверительную вероятность. Обладая точностью порядка 97%, эти функции работают в разы быстрее и потребляют меньше CPU и памяти.
Еще один интересный доклад на мероприятии был посвящен вопросами аппаратного ускорения. Как пояснил Игорь Мельников, ведущий консультант департамента технологического консалтинга компании Oracle СНГ, когда выходит новый процессор, то выигрыш производительности составляет 10-15%, резко роста не наблюдается. Он отметил, что нельзя сказать, что индустрия топчется на месте, но развитие очевидно замедлилось. Что же делать? Выполнять часть задач на аппаратном уровне. Такая технология носит название "Software in Silicon".
Так, существуют специальные криптоакселераторы, встроенные в процессор SPARC M7. Полтора десятка алгоритмов шифрования доступны в качестве низкоуровневых команд процессора, необходимость тратить дорогостоящие вычислительные ресурсы пропадает. Те же криптоакселераторы применяются и для шифрования бэкапов. К слову, эту функциональность могут использовать любые другие Java-приложения, а не только СУБД Oracle.
Кроме защиты данных, есть и функции защиты памяти Silicon Secured Memory. На низком уровне реализуется защита от некорректных указателей, отсеиваются программные ошибки, определяется выход обращений за пределы массивов, а также операции чтения памяти, которая еще не была выделена, или уже была освобождена. Кроме криптозащиты и анализа использования памяти, в процессор SPARC M7 встроены функции SQL in Silicon.
Также для ускорения работы применяется технология DAX (Data Analytics Accelerator). Она добавляет средства обработки, позволяющие выполнять такие функции, как Scan, Extract, Select и Translate, на выделенном физическом сопроцессоре. DAX выполняет наиболее тяжелую и "грязную" работу, например, декомпрессию. Так, заказчики Oracle часто с некоторым напряжением относятся к компрессии, ибо она нагружает процессор. Но DAX делает автоматическую запаковку и распаковку, эта операция выполняется на аппаратном уровне. Предлагается и открытый API для разработчиков Oracle Open DAX API.
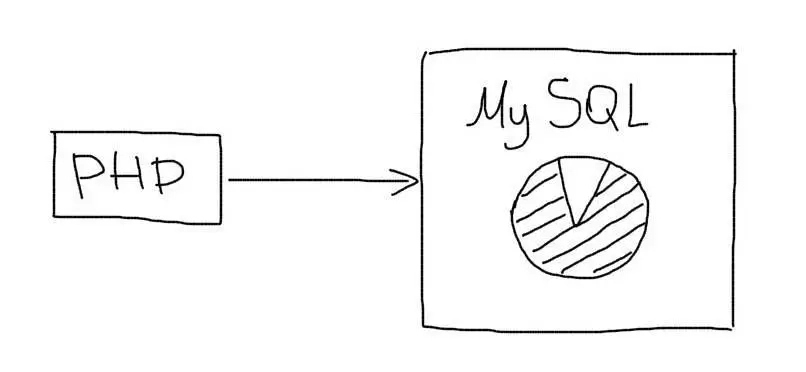
Масштабирование баз данных — самая сложная задача во время роста проекта. 90% всех усилий обычно приходится как раз на работу, связанную с ростом объема данных и операций с ними. Классическая схема работы приложения с базой данных выглядит так:
Один сервер базы данных в какой-то момент перестает справляться с нагрузкой. В этот момент и следует применять описанные тут техники масштабирования.
Перед тем, как приступать к масштабированию, необходимо провести анализ медленных запросов и убедиться, что сервер MySQL настроен оптимально.
Стратегии
В основе масштабирования данных лежит тот же принцип, что и в основе масштабирования Web приложений. Это разделение данных на группы и выделение их на отдельные сервера. Существует две основные стратегии — репликация и шардинг.
Репликация
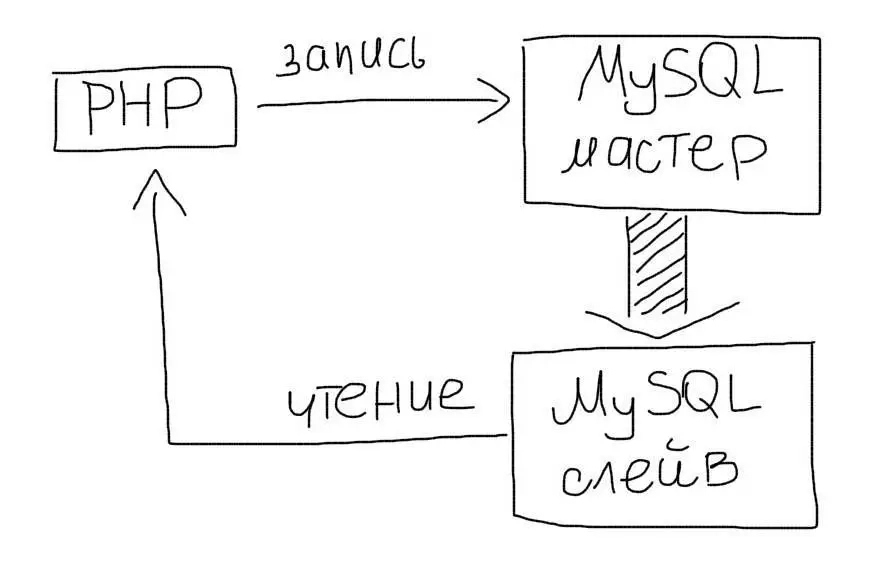
Репликация позволяет создать полный дубликат базы данных. Так, вместо одного сервера у Вас их будет несколько:
Master-slave
Чаще всего используют схему master-slave:
- Master — это основной сервер БД, куда поступают все данные. Все изменения в данных (добавление, обновление, удаление) должны происходить на этом сервере.
- Slave — это вспомогательный сервер БД, который копирует все данные с мастера. С этого сервера следует читать данные. Таких серверов может быть несколько.
Репликация позволяет использовать два или больше одинаковых серверов вместо одного. Операций чтения (SELECT) данных часто намного больше, чем операций изменения данных (INSERT/UPDATE). Поэтому, репликация позволяет разгрузить основной сервер за счет переноса операций чтения на слейв.
Работа из приложения
В приложении у Вас будет два соединения с базой данных. Одно — для мастера и одно для слейва:
При выполнении запросов необходимо использовать соответствующее соединение
Репликация обычно поддерживается самой СУБД (например, MySQL) и настраивается независимо от приложения.
Читайте детальнее про настройку, использование и типы репликации данных на примере MySQL.
Следует отметить, что репликация сама по себе не очень удобный механизм масштабирования. Причиной тому — рассинхронизация данных и задержки в копировании с мастера на слейв. Зато это отличное средство для обеспечения отказоустойчивости. Вы всегда можете переключиться на слейв, если мастер ломается и наоборот. Чаще всего репликация используется совместно с шардингом именно из соображений надежности.
Шардинг (sharding)
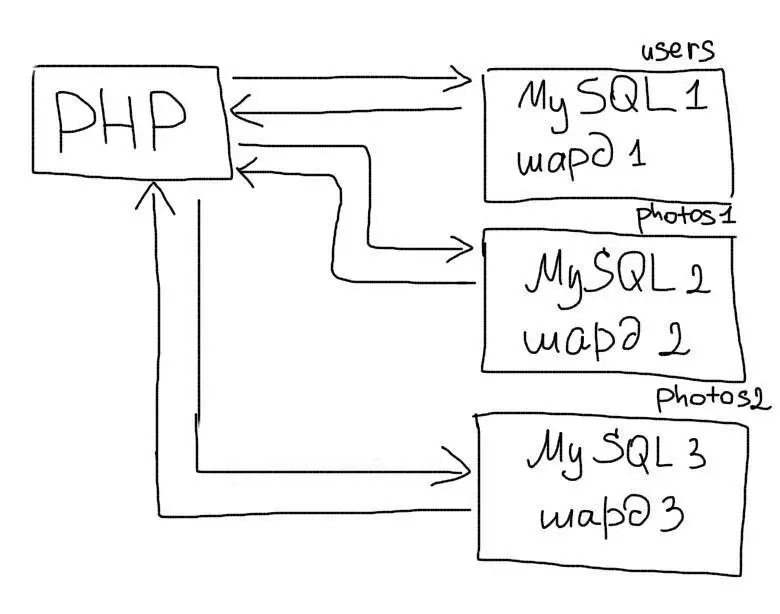
Шардинг (иногда шардирование) — это другая техника масштабирования работы с данными. Суть его в разделении (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер. Этот процесс зависит от структуры Вашей базы данных и выполняется прямо в приложении в отличие от репликации:
Вертикальный шардинг
Вертикальный шардинг — это выделение таблицы или группы таблиц на отдельный сервер. Например, в приложении есть такие таблицы:
- users — данные пользователей
- photos — фотографии пользователей
- albums — альбомы пользователей
Таблицу users Вы оставляете на одном сервере, а таблицы photos и albums переносите на другой. В таком случае в приложении Вам необходимо будет использовать соответствующее соединение для работы с каждой таблицей:
Для каждой таблицы или группы таблиц будет отдельное соединение
В отличие от репликации, мы используем разные соединения для любых операций, но с определенными таблицами. Читайте подробнее об использовании вертикального шардинга на практике.
Горизонтальный шардинг
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере. Разделение таблицы на куски делается по такому принципу:
- На нескольких серверах создается одна и та же таблица (только структура, без данных).
- В приложении выбирается условие, по которому будет определяться нужное соединение (например, четные на один сервер, а нечетные — на другой).
- Перед каждым обращением к таблице происходит выбор нужного соединения.
Допустим, наше приложение работает с огромной таблицей, которая хранит фотографии пользователей. Мы подготовили два сервера (обычно они называются шардами) для этой таблицы. Для нечетных пользователей мы будем работать с первыми сервером, а для четных — со вторым. Таким образом, на каждом из серверов будет только часть всех данных о фотках пользователей. Это будет выглядеть так:
Перед обращением к таблице, мы выбираем нужное нам соединение
Результат вот этой операции $user_id % 2 будет остатком от деления на 2. Т.е. для четных чисел — 0, а для нечетных — 1.
Любая работа с таблицей photos теперь будет происходить только после получения нужного соединения на основе $user_id .
Горизонтальный шардинг — это очень мощный инструмент масштабирования данных. Но в то же время и очень нетривиальный. Читайте детально об использовании горизонтального шардинга на практике.
Не следует применять технику шардинга ко всем таблицам. Правильный подход — это поэтапный процесс разделения растущих таблиц. Следует задумываться о горизонтальном шардинге, когда количество записей в одной таблице переходит за пределы от нескольких десятков миллионов до сотен миллионов.
Совместное использование
Шардинг и репликация часто используются совместно. В нашем примере, мы могли бы использовать по два сервера на каждый шард таблицы:
- photos_master_1 — мастер первой половины таблицы.
- photos_slave_1 — слейв первой половины таблицы.
- photos_master_2 — мастер второй половины таблицы.
- photos_slave_2 — слейв второй половины таблицы.
Тогда в приложении работа с этой табличкой может выглядеть так:
Читаем данные со слейвов, а записываем на мастер-сервера
Такая схема часто используется не для масштабирования, а для обеспечения отказоустойчивости. Так, при выходе из строя одного из серверов шарда, всегда будет запасной.
Key-value базы данных
Следует отметить, что большинство [p165 Key-value баз данных] поддерживает шардинг на уровне платформы. Например, Memcache. В таком случае, Вы просто указываете набор серверов для соединения, а платформа сделает все остальное:
Мемкеш сам умеет определять нужный сервер для каждого ключа
Самое важное
Шардинг и репликация — это популярные и мощные техники масштабирования систем работы с данными. Несмотря на примеры для MySQL, эти подходы универсальны и могут применяться для любой технологии.
Помните, процесс масштабирования данных — это архитектурное решение, оно не связано с конкретной технологией. Не делайте ошибок наших отцов — не переезжайте с известной Вам технологии на новую из-за поддержки или не поддержки шардинга. Проблемы обычно связаны с архитектурой, а не конкретной базой данных.
Этот текст был написан несколько лет назад. С тех пор упомянутые здесь инструменты и софт могли получить обновления. Пожалуйста, проверяйте их актуальность.
Highload нужны авторы технических текстов. Вы наш человек, если разбираетесь в разработке, знаете языки программирования и умеете просто писать о сложном!
Откликнуться на вакансию можно здесь .
Что такое индексы в Mysql и как их использовать для оптимизации запросов
Примеры ad-hoc запросов и технологии для их исполнения
Настройка Master-Master репликации на MySQL за 6 шагов
Как создать и использовать составной индекс в Mysql
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Синтаксис и оптимизация Mysql LIMIT
Check-unused-keys для определения неиспользуемых индексов в базе данных
Настройка Master-Slave репликации на MySQL за 6 простых шагов
Типы и способы применения репликации на примере MySQL
Запрос для определения версии Mysql: SELECT version()
Правильная настройка Mysql под нагрузки и не только. Обновлено.
3 примера установки индексов в JOIN запросах
Быстрый подсчет уникальных значений за разные периоды времени
И как правильно работать с длительными соединениями в MySQL
Анализ медленных запросов с помощью EXPLAIN
Описание, рекомендации и значение параметра query_cache_size
Что значит и как это починить
Правила выбора типов данных для максимальной производительности в Mysql
Использование партиций для ускорения сложных удалений
Просмотр профиля запросов в Mysql
Включение и использование логов ошибок, запросов и медленных запросов, бинарного лога для проверки работы MySQL
Читайте также: