
Ошибка неожиданный in в r studio
Обновлено: 07.07.2024
R-Studio как пользоваться правильно, чтобы не усложнить наверно и без того сложную ситуацию в которую вы попали. Пожалуйста прослушайте небольшой курс молодого бойца по работе с подобными программами, без этого вы можете наделать много ошибок и вместо того, что бы вернуть свои удалённые данные, вы ещё хуже затрёте их.
Программа для восстановления файлов R-Studio: как пользоваться
Первая ошибка это волнение, которое сопровождается вытекающими отсюда последствиями, например необдуманными действиями, успокойтесь, дочитайте статью до конца, спокойно всё обдумайте, а затем действуйте. Кстати, если вы случайно удалили с вашего жёсткого диска фотографии, то у нас есть очень простая статья, которая я уверен вам поможет Как восстановить удалённые фотографии. Ещё вам могут пригодиться статьи: Как восстановить удалённые файлы бесплатными программами DMDE , R.saver и Recuva и платными - Ontrack EasyRecovery Professional, GetDataBack for NTFS .
Когда мы с вами, Дорогие мои, случайно удаляем файл, без которого наше дальнейшее существование на планете Земля, будет нам не в радость, знайте, что физически с жёсткого диска он не удалился, но навсегда потерять его можно, записав любую информацию поверх него. Поэтому, даже если вы читали как пользоваться R-Studio, но опыта как такового у вас нет, сразу выключаем компьютер и лучше в аварийном порядке. Больше никаких действий с вашим жёстким диском не производим, тогда наши шансы на благополучный успех увеличиваются.
- Примечание: много раз ко мне обращались люди с подобными проблемами и не могли вспомнить, какие действия они предпринимали до того, как обратиться в технический сервис. Они даже толком не могли назвать точное название программы, которой пытались спасти свои данные, а самое главное, после удаления своих файлов, например мимо корзины, они активно пользовались компьютером (иногда несколько дней), что категорически делать нельзя, только потом всё-таки шли в сервис и требовали чуда.
После того как мы выключили компьютер, берём системный блок и идём к профессионалам, ваши данные 90% будут спасены, естественно с вас возьмут немного денежки, сколько, лучше узнать сразу, но если денежки попросят очень много, читаем дальше.
Сейчас я пишу эту статью, а передо мной стоит системный блок, в нём находится жёсткий диск, его случайно форматировали, то есть удалили всё что на нём находилось, давайте попробуем восстановить потерянные файлы с помощью R-Studio , а заодно научимся пользоваться этой хорошей программой.
В первую очередь нам с вами нужно эвакуировать пострадавшего, другими словами снять форматированный винчестер и подсоединить к моему компьютеру, я делаю так всегда, потому что нельзя сохранять восстанавливаемую информацию на тот же носитель, с которого были удалены файлы.

Если для вас это трудно, тогда хотя бы не восстанавливайте файлы на тот раздел жёсткого диска с которого они были удалены.
Примечание: Друзья, самое главное правило при восстановлении информации звучит так: число обращений к жёсткому диску с удалёнными данными должно быть сведено к минимуму. А значит, перед работой с R-Studio желательно сделать образ жёсткого диска с потерянными данными и восстанавливать информацию уже с образа. Как сделать посекторный образ жёсткого диска и восстановить с него информацию написано в этой нашей статье.
Итак начнём, на нашем пострадавшем от форматирования винчестере пропало очень много папок с семейными фотографиями и видео, нам нужно их вернуть.
Запускаем R-Studio , у программы интуитивно понятный англоязычный интерфейс, но нам не привыкать, я уверен, что, попользовавшись ей один раз, вы запомните её навсегда.
Главное окно программы Device View "Просмотр дисков" в левой его части показаны практически все накопители находящиеся в системе: жёсткие диски, разбитые на логические разделы, USB-накопители, DVD-диски, флеш-карты, правое окно предоставляет полнейшую информацию о выбранном нам накопителе, начиная с названия и заканчивая размером кластеров.
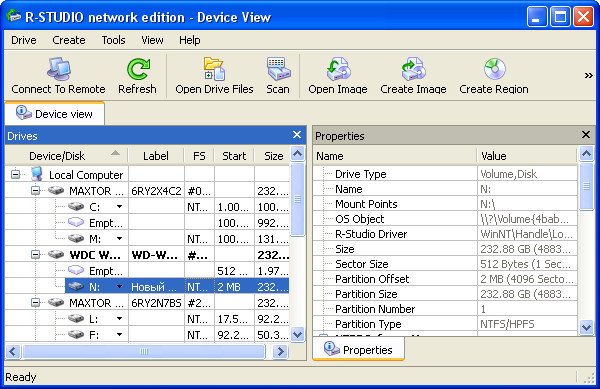
Выбираем наш диск (N:) и жмём Open Drive Files (Открыть файлы диска),
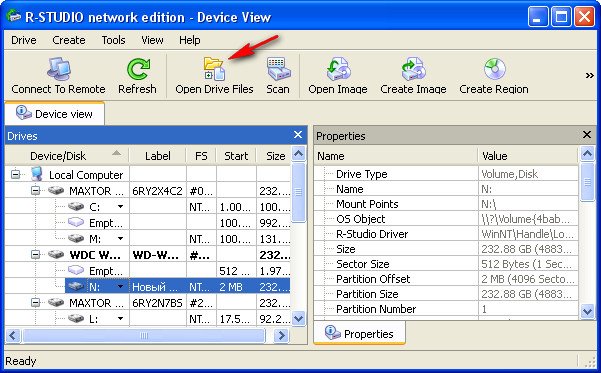
сейчас мы с вами используем самый простой способ восстановления удалённых файлов, перед нами открывается несколько папок имеющих древовидную структуру, раскрываем все начиная с первой, предупреждаю, не ждите обычных названий ваших файлов, в нашем случае Фото сынишки и т.д. Можно сказать нам повезло, в окне присутствуют папки перечёркнутые
красным крестиком, это значит они были удалены, смотрим названия: Глава 01, 02 и т.д, это нужные нам папки с лекциями Университетского профессора, дело в том что перед подобными операциями восстановления, я внимательно расспрашиваю людей о названиях удалённых файлов и их расширениях, это нужно в особых запущенных случаях для поиска по маске и т.д. Вы можете не забивать себе голову на первый раз, в конце статьи мы воспользуемся методом расширенного сканирования ( Scan ) и восстановим всё что было на винчестере, это конечно займёт времени по сравнению с простым способом в десять раз больше. А сейчас ставим везде галочки и далее Recover ,
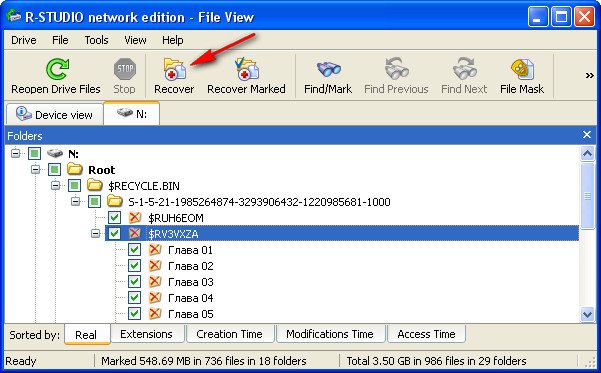
выбираем куда восстанавливать, по умолчанию в личную папку R-Studio в Моих документах и предложение изменить настройки восстановления по умолчанию, оставляем всё как есть нажимаем ОК .
Я пытаюсь скомпилировать простой пример Rcpp с веб-страницы Rcpp с inline : Rcpp::NumericVector orig(vector); Rcpp::NumericVector vec(orig.size()); std::transform(orig.begin(),orig.end(),vec.begin(),sqrt); return Rcpp::List::create(Rcpp::Named(result)=vec,Rcpp::Named(original) =orig); Однако я.
В настоящее время я кодирую алгоритм имитационного отжига для задания класса ('solving' проблема рюкзака) и хотел сделать это в Rcpp (я должен использовать R, а Rcpp быстрее). Rcpp выдает мне следующую ошибку invalid static_cast from type 'Rcpp::Vector<13, Rcpp::PreserveStorage>' to type.
Если файл сохранить как файл с расширением .cpp , RStudio вызовет правильную функцию: sourceCpp() .
Похожие вопросы:
Ошибка синтаксического анализа: синтаксическая ошибка, неожиданный ' ['в $results = []; function class_uses_recursive($class) < $results = []; foreach (array_merge([$class => $class].
Я получаю следующую ошибку, когда пытаюсь установить пакет plyr, я пробовал некоторые решения, предложенные в других потоках, но они, похоже, не работают. Недавно я обновил версию R и R studio на.
Я пытаюсь запустить тестовую функцию, но получаю ошибку компиляции: library(Rcpp) library(inline) testfun = cxxfunction( signature(x=numeric, i=integer), body = ' NumericVector xx(x); int ii =.
Я пытаюсь скомпилировать простой пример Rcpp с веб-страницы Rcpp с inline : Rcpp::NumericVector orig(vector); Rcpp::NumericVector vec(orig.size());.
В настоящее время я кодирую алгоритм имитационного отжига для задания класса ('solving' проблема рюкзака) и хотел сделать это в Rcpp (я должен использовать R, а Rcpp быстрее). Rcpp выдает мне.
Когда я компилирую приведенный ниже код в Rcpp, я получаю следующую ошибку в файле с именем stl_algobase.h: `no type named 'value_type' in 'struct std::iterator_traits<Rcpp::Vector<14.
Я пытаюсь использовать функцию, созданную с помощью пакета Rcpp в документе Rmarkdown. Но следующее приводит к ошибке: ``` Rcpp::IntegerVector doubleMe(Rcpp::IntegerVector x)
Есть ли сахар Rcpp для %in%? Например, у меня есть следующее утверждение в R y <- c('XA','XB','XC','XF','XK','XL','XM','XN','XO','XP','XS','XU','XW','XY', 'DF','DS','AS','XL','FG') x <-.
Я запускаю виртуальную машину с 8 ГБ RAM, Debian 9, R версии 3.3. У меня есть этот сценарий R. install.packages(Rcpp) Моя машина выдала мне эту ошибку. * installing *source* package ‘Rcpp’ . **.
пакеты "ape" и "Rcpp" устанавливаются на мой Mac(последняя версия) нормально, просто всякий раз, когда я загружаю их, появляется одна и та же ошибка для обоих: Error: package or.

В большинстве случаев, особенно при установке пакетов из CRAN никаких проблем не возникает, но периодически всё таки вы можете столкнуться с некоторыми ошибками.
В этой статье я со временем буду добавлять материал с описанием различных ошибок которые возникают при установке пакетов.
package ‘foo’ is not available”
Достаточно распространённая ошибка, текст которой к сожалению не сообщает о реальной проблеме, которой была эта ошибка вызвана.
В одной из статей на RBloggers, автор опубликовал подробный чек лист как с этой ошибкой бороться.
unable to create temporary directory
С чем связано её появление я так и не понял, но устранить получилось следующим образом:
Could not find tools necessary to compile a package
С этой ошибкой я столкнулся при установке пакетов из GitHub после обновления R до более новой версии.
Ответ я нашел вот тут.
Проблема возникает при попытке RStudio проверить установленные у вас инструменты сборки пакетов, для того, что бы подвить эту проверку необходимо перед установкой пакета установить следующую опцию.
После чего можно устанавливать пакет.
Эта проблема появилась при установке пакетов из GitHub с помоью devtools не так давно, и связана она с файлом DESCRIPTION.
Для исправления вам необходимо форкнуть нужный пакет на GitHub.

Создать свою ветку пакета на GitHub
(converted from warning) installation of package ‘C:/Users/Alsey/AppData/Local/Temp/2/Rtmp4g880D/file259c11b85f00/vctrs_0.1.0.9003.tar.gz’ had non-zero exit status
Вызвана данная ошибка конфликтом возникающим при установке пакетов одновременно для разных версий ядра R, 32 и 64 битных.
Полный текст ошибки из консоли:
Узнать разрядность версии R в которой вы работаете можно двумя способами:
В случае если вы используете 32 битный R вернётся значение "/i386" .
На 32 битном R вы получите "x86_32" .
После того, как мы определили разрядность ядра требуется пойти одним из описанных способов, для 64 битной версии просто используйте при установке пакета опцию "--no-multiarch".
Если у вас 32 битная версия, то необходимо изменить в переменной окружения PATH путь к утилите RTools с C:\Rtools\mingw_64\bin на C:\Rtools\mingw_32\bin . О том как это сделать можно узнать в этой статье .
Далее запускаем установку пакета только для 32 битной версии с помощью опции "--no-multiarch" , так же как и ранее было показано с примером для 64 разрядного R.
Warning Message: cannot remove prior installation of package ‘X’
Если перезапуск RStudio не помог, то откройте диспетчер задач, и на вкладке подробности посмотрите, нет ли у вас каких либо зависших R сеансов.

Если такие есть их необходимо завершить, и попробовать повторно запустить процесс установки пакета.
Если и это не помогло, то идём третьим способом.
- Найдите путь к папкам, в которых у вас установлены пакеты, делается это командой .libPaths() .
- В ручном режиме удалите папку с пакетом, который пытаетесь установить.
- Откройте RStudio и повторите попытку установить пакет.
Один из перечисленных выше способов должен сработать.
Статья будет постоянно дополняться, дата последнего редактирования 6 октября 2020 года.

В прошлый раз мы говорили о том, как загрузить данные в среду R. Следующим важным этапом является их подготовка к визуализации и статистическому анализу. Для этого нам, как правило, необходимо внести некоторые изменения в таблицу, например: удалить столбец или строку, переименовать колонку, произвести сортировку или фильтрацию данных. Многие из этих операций можно сделать в Excel. Однако, зачастую возникают ситуации, когда необходимо изменить структуру или содержание таблицы прямо в ходе анализа. И вот тут у начинающих пользователей R могут возникнуть проблемы. В этой статье мы научимся их решать.
Структура таблицы и изменение типов данных
Лучший способ для закрепления новых знаний - это практика. Поэтому мы продолжим работать с таблицей физических данных студентов одного из военных вузов "voenvuz". Итак, загрузим знакомую уже нам таблицу в Rgui (таблицу можно скачать здесь).
Функции head и str
Для того, чтобы посмотреть правильно ли загрузились данные, введем команду head(voenvuz) , которая покажет первые 6 строчек нашей таблицы. Если все загрузилось нормально, то переходим к команде str(voenvuz) , которая выведет в консоль структуру таблицы.

Итак, в поле "data.frame" мы видим, что наша таблица состоит из 20 строк и 6 столбцов. Под ним располагается список названий столбцов, тип данных и первые шесть элементов каждого столбца. Обратите внимание, что колонки "Name" и "Rhesus.factor" сейчас хранят в себе категориальный тип данных (Factor), а остальные - целочисленный. Компьютер вычислил это автоматически, но в нашем случае - вычислил неверно. Прежде чем мы исправим типы этих данных, немного теоретической информации.
О типах данных
Почему важно правильно распознать тип данных в столбцах таблицы? Потому что при проведении статистических тестов, информация о типе данных учитывается и влияет на результат.
В языке R можно выделить 5 основных типов данных, хранящихся в столбцах таблицы:
- числовой (numeric);
- целочисленный (integer);
- текстовый (character);
- категориальный (Factor);
- логический (logical).
Есть также комплексный (complex) и сырой (raw) типы данных, но они редко встречаются, и поэтому я о них здесь писать не буду. Пропущенные данные обозначаются как "NA" (от англ. not available - недоступно), и тогда R игнорирует их.
Изменим типы данных на практике
Посмотрим еще раз на таблицу. Логично предположить, что столбец "Name" с именами студентов не содержит никаких категорий, поэтому, преобразуем эту колонку в обычный текстовый тип данных:
Идем дальше, столбец "Age" был правильно идентифицирован как целочисленный. А вот столбцы "Height" и "Weight" являются скорее числовыми, т.к. могут содержать промежуточные значения, например 182.5. Переделаем их из типа Integer в тип Numeric:
Последнее, что нам нужно - это изменить тип данных в столбце "Blood.group". Каждый из студентов так или иначе имеет одну из 4 групп крови, соответственно, этот столбец содержит четыре категории: "1", "2", "3", "4". Другими словами, в нем должен находиться категориальный тип данных:
В итоге, повторив команду str(voenvuz) , мы должны получить вот такую картинку.

Редактирование элементов таблицы
Иногда возникают ситуации, когда необходимо вставить в таблицу столбец или строку, изменить значение элемента или название колонки. Наша таблица - не исключение и нуждается в доработке.
Добавление строк
Добавим в таблицу данные о двух новых студентах: Иване и Олеге. Для этого необходимо создать новую структуру - список (list) , В список мы по порядку вносим параметры, совпадающие со структурой таблицы (напомню, что в кавычках мы пишем нечисловые типы данных):
После, при помощи функции rbind (от англ. row bind, что дословно означает "связать строчки") мы объединим эти два списка с нашей таблицей:
Добавление столбцов
Теперь у нас в таблице два Ивана и два Олега. В данном случае хорошо было бы прописать для каждого студента свой идентификационный номер (ID), чтобы не запутаться, кто есть кто. Для этого создадим структуру, которая называется вектор (последовательность элементов одного типа). В него мы запишем последовательность от 1 до 22, так, чтобы у каждого из наших 22 студентов был свой уникальный ID:
Теперь объединим наш вектор с таблицей, воспользовавшись функцией cbind (от англ. column bind):
Не забудьте поменять тип данных нового столбца на символьный:
В качестве еще одного примера добавления новых столбцов с данными в таблицу, рассчитаем индекс массы тела (BMI) для каждого студента. Для этого, мы воспользуемся новым способом: напишем математическую формулу индекса на языке R и присвоим ей новое имя столбца "BMI" внутри нашей таблицы:
Проверьте, что получилось, используя уже знакомые нам функции head и str
Удаление строк и столбцов
Существует относительно "универсальная формула" для удаления элементов таблицы: new.data <- my.data[ , ]
Для того, чтобы корректно ее использовать необходимо запомнить несколько правил:
- После имени таблицы пространство внутри квадратных скобок следует разделить на две части запятой.
- Все, что находится до запятой, относится к строчкам, все что после - к столбцам.
- Поставьте минус перед номером столбца или номером строки, которую собираетесь удалить.
- Если таких элементов несколько, используйте функцию c(. ) : внутри скобок перечисление элементов через запятую.
В нашем случае, удалять из таблицы ничего не надо, но я покажу пару примеров, назвав "укороченные" таблицы именами "trash1", "trash2", "trash3", "trash4":
Изменение имен столбцов и данных в ячейках:
Переименуем колонку "Rhesus.factor" на укороченное "Rhesus". Для этого нужно вызвать функцию names , написать в параметрах функции имя таблицы и номер столбца, и присвоить ему новое имя :
Изменение данные в ячейках таблицы не представляет особой сложности. В квадратных скобках прописываем координаты нужной ячейки (до запятой - строка, после запятой - столбец) и присваиваем новое значение:

После всех наших манипуляций мы должны получить вот такую таблицу данных:
Фильтрация и сортировка данных
В качестве примера, исключим из таблицы данных студентов, чей возраст больше 23 лет. Существует множество способов решения подобного рода задач, включая циклы if-else, for или while (о них будет написана отдельная статья). Однако в нашем случае хватит простого фильтра, основанного на логическом операторе "< wp-block-preformatted"> voenvuz.final <- voenvuz[voenvuz$Age <= 23, ]
Того же результата мы добьемся, если будем использовать логические операторы ">" (больше) и "!" (исключить):
Итак, мы получили финальную версию таблицы "voenvuz.final ". Осталось лишь упорядочить столбцы:
И произвести сортировку данных по имени студентов, используя функцию order :

После завершения редактирования таблицы, обновим имена строк, т.к. сейчас они не соответствуют действительности, и выведем таблицу на экран, введя имя таблицы в консоль:
Заключение
Описанные выше способы редактирования данных в таблице не уникальны, существует множество других методов и команд, позволяющих получить желаемый результат. Я рассказал лишь о наиболее простых и часто используемых. Для более детального ознакомления с этой темой я хотел бы порекомендовать два источника на английском языке:
- сайт http://stackoverflow.com/ (уже подробно разобраны тысячи вопросов по этой теме)
- книгу-справочник "R book" by Michael J. Crawley (легко найти бесплатную PDF версию в интернете).
Если у Вас возникли вопросы или проблемы с редактированием таблиц данных, Вы всегда можете оставить комментарий под этой статьей, и он не останется без внимания. А в качестве продолжения, читайте следующую статью, посвященную сохранению данных в среде R.
kod col.x col.y delta
1 00046949 1,000 1,000 2
2 00047069 3,000 3,000 2
3 00047070 19,000 19,000 2
4 00047071 49,000 49,000 2
5 00047072 21,000 21,000 2
356 CB128164 2,000 2
252 CB164884 1,000 2
Всем привет! Только начал изучать R и столкнулся с некой проблемой: Есть такая волшебная таблица. И задача, вывести в последний столбец разницу 2 и 3 го, и с учетом того что данные в последних строках NA, соответственно вывести в последний столбец NA2 или NA3, в зависимости от того где стоит NA. Проблема в том, что стандартные функции(о которых я еще мало знаю) удаляют строки с NA, а мне важно их сохранить и обработать.
Если у кого то будут мысли по теме, буду рад помощи. Да и еще, у меня типы данных факторы в первых трех столбцах, а последний число.
((ETH1567:0.07723012967,((ETH1478:0.03477412382,ETH1481:0.03998172409)100:0.01982264043,(LAV2470:0.04453502013,LAV2519:0.04666678739) и т.д. без пробелов.
Мне нужно извлечь блоки содержащие буквы и последующие цифры до знака двоеточия, т.е.: ETH1567 ETH1478 ETH1481 LAV2470 LAV2519
Я подобрал регулярку для этого: ([A-z]4*)
treenames <- grep("([A-z]3*)", tree, value = TRUE)
treenames
named character(0)
Перерыд весь stackoverflow и иже с ним, но ответа не нашел.
Буду благодарен за подсказку.
Здравствуйте, Данила! Вот одно из возможных решений Вашей задачи:
P.S. я мало анализирую текстовые данные, поэтому это решение вероятно не самое элегантное, но должно работать.
Отлично, все работает, большое спасибо!
Добрый день!
После преобразования матрицы в таблицу, провожу моделирование.
Выходит такая вещь:
Warning messages:
1: In log(b$y) : NaNs produced
2: In log(b$x1) : NaNs produced
3: In log(b$x2) : NaNs produced
4: In log(b$x4) : NaNs produced
5: In log(b$x5) : NaNs produced
6: In log(b$x6) : NaNs produced
Подскажите, пожалуйста, где ошибка? Голова кипит, не получается(
Доброго дня, Эсмира!
Сегодня все посмотрю и надеюсь смогу помочь ;)
Здравствуйте. Как пропустить заголовок таблицы; учесть, что заголовка нет?
В скобках функции read.table вставьте аргумент header = FALSE.
Здравствуйте! Подскажите как правильно оформить цикл и получить агрегированные данные из нескольких ресурсов гугл аналитики.
Потом я хочу взять в цикле каждый ресурс и получить агрегированные данные в объекте gaData по всем ресурсам функцией:
gaData <- get_ga(profileId = "resource_id",
start.date = "2019-09-01",
end.date = "2019-10-21",
metrics = "ga:sessions",
dimensions = "ga:date",
samplingLevel = "HIGHER_PRECISION",
max.results = 1000,
token = rga_auth)
Здравствуйте! Сходу ответить не смогу. Сейчас дописываю диссертацию, к сожалению совсем нет свободного времени.
Samoedd приветствую.
Вопрос
После расчетов на экране отображается таблица в таком формате
Qtr1 Qtr2 Qtr3 Qtr4
2000 119.28993 118.89396 118.10201 116.91410
2001 115.33021 114.48457 114.37718 115.00804
2002 116.37716 117.13394 117.27839 116.81051
2003 115.73031 114.20610 112.23790 109.82569
2004 106.96949 105.67921 105.95486 107.79644
2005 111.20394 112.48537 111.64071 108.66998
Сам пробовал искать ответ, но видимо это настолько просто, что об этом ни где не пишут. :-)
Заранее спасибо.
Здравствуйте, Alex! Извините, был в отпуске, не смог ответить. Ваш вопрос еще актуален или уже решен?
Читайте также: