
Отключить кэш hibernate 2 го уровня
Обновлено: 03.07.2024
Руководство по кэшу второго уровня Hibernate и как его использовать на практике.
1. Обзор
Одним из преимуществ уровней абстракции баз данных, таких как фреймворки ORM (объектно-реляционного отображения), является их способность прозрачно кэшировать данные, полученные из базового хранилища. Это помогает снизить затраты на доступ к базе данных для часто используемых данных.
Прирост производительности может быть значительным, если соотношение чтения/записи кэшированного содержимого велико, особенно для объектов, состоящих из больших графов объектов.
В этой статье мы исследуем кэш второго уровня гибернации.
Мы объясняем некоторые основные понятия и, как всегда, иллюстрируем все простыми примерами. Мы используем JPA и возвращаемся к Hibernate native API только для тех функций, которые не стандартизированы в JPA.
2. Что такое Кэш Второго Уровня?
Как и большинство других полностью оснащенных платформ ORM, Hibernate имеет концепцию кэша первого уровня. Это кэш с областью действия сеанса, который гарантирует, что каждый экземпляр сущности загружается только один раз в постоянном контексте.
Как только сеанс закрыт, кэш первого уровня также завершается. Это на самом деле желательно, поскольку позволяет параллельным сеансам работать с экземплярами сущностей изолированно друг от друга.
С другой стороны, кэш второго уровня имеет область SessionFactory -, что означает, что он является общим для всех сеансов, созданных с помощью одной и той же фабрики сеансов. Когда экземпляр сущности просматривается по его идентификатору (либо по логике приложения, либо по внутренней спящей системе, например, , когда он загружает ассоциации с этой сущностью из других сущностей), и если для этой сущности включено кэширование второго уровня, происходит следующее:
- Если экземпляр уже присутствует в кэше первого уровня, он возвращается оттуда
- Если экземпляр не найден в кэше первого уровня, а соответствующее состояние экземпляра кэшируется в кэше второго уровня, то данные извлекаются оттуда, и экземпляр собирается и возвращается
- В противном случае необходимые данные загружаются из базы данных, а экземпляр собирается и возвращается
Как только экземпляр сохраняется в контексте сохранения (кэш первого уровня), он возвращается оттуда во всех последующих вызовах в рамках одного сеанса до тех пор, пока сеанс не будет закрыт или экземпляр не будет вручную удален из контекста сохранения. Кроме того, состояние загруженного экземпляра хранится в кэше L2, если его там еще не было.
3. Фабрика региона
Кэширование второго уровня Hibernate предназначено для того, чтобы не знать о фактическом используемом поставщике кэша. Hibernate необходимо предоставить только реализацию интерфейса org.hibernate.cache.spi.RegionFactory , который инкапсулирует все сведения, относящиеся к фактическим поставщикам кэша. По сути, он действует как мост между поставщиками гибернации и кэша.
В этой статье мы используем Ehcache в качестве поставщика кэша , который является зрелым и широко используемым кэшем. Конечно, вы можете выбрать любого другого поставщика, если для него есть реализация Region Factory .
Мы добавляем реализацию Ehcacheregionfactory в путь к классу со следующей зависимостью Maven:
Посмотрите здесь для последней версии hibernate-ehcache . Однако убедитесь, что hibernate-ehcache версия равна версии Hibernate, которую вы используете в своем проекте, например если вы используете hibernate-ehcache 5.2.2.Final , как в этом примере, то версия Hibernate также должна быть 5.2.2.Final .
Артефакт hibernate-ehcache зависит от самой реализации Ehcache, которая, таким образом, также транзитивно включена в путь к классу.
4. Включение кэширования Второго Уровня
С помощью следующих двух свойств мы сообщаем Hibernate, что кэширование L2 включено, и даем ему имя класса фабрики региона:
Например, в persistence.xml это будет выглядеть так:
5. Сделать объект кэшируемым
Чтобы сделать объект подходящим для кэширования второго уровня , мы аннотируем его с помощью специальных @org.hibernate.аннотаций.Кэш аннотацию и укажите стратегию параллелизма кэша .
Некоторые разработчики считают, что было бы неплохо добавить стандарт @javax.persistence.Также кэшируемая аннотация (хотя и не требуется для Hibernate), поэтому реализация класса сущностей может выглядеть следующим образом:
Например, экземпляры Foo хранятся в кэше с именем com.baeldung.hibernate.cache.model.Foo в Ehcache.
Чтобы убедиться, что кэширование работает, мы можем написать быстрый тест, подобный этому:
Здесь мы используем API Ehcache напрямую, чтобы проверить, что com.baeldung.hibernate.cache.model.Кэш Foo не пуст после загрузки экземпляра Foo .
Вы также можете включить ведение журнала SQL, созданного Hibernate, и вызвать FooService.findOne(foo.getId()) несколько раз в тесте, чтобы убедиться, что оператор select для загрузки Foo печатается только один раз (в первый раз), что означает, что при последующих вызовах экземпляр сущности извлекается из кэша.
6. Стратегия параллелизма кэша
В зависимости от вариантов использования мы можем выбрать одну из следующих стратегий параллелизма кэша:
7. Управление кэшем
Если политики истечения срока действия и выселения не определены, кэш может расти бесконечно и в конечном итоге потреблять всю доступную память. В большинстве случаев Hibernate оставляет подобные обязанности по управлению кэшем поставщикам кэша, поскольку они действительно специфичны для каждой реализации кэша.
Например, мы могли бы определить следующую конфигурацию Ehcache, чтобы ограничить максимальное количество кэшированных экземпляров Foo до 1000:
8. Кэш коллекции
Коллекции по умолчанию не кэшируются, и нам нужно явно пометить их как кэшируемые. Например:
9. Внутреннее представление Кэшированного состояния
Сущности хранятся не в кэше второго уровня как экземпляры Java, а в их разобранном (гидратированном) состоянии:
- Идентификатор (первичный ключ) не сохраняется (он хранится как часть ключа кэша)
- Переходные свойства не сохраняются
- Коллекции не хранятся (подробнее см. Ниже)
- Значения свойств, не связанных с ассоциацией, хранятся в их первоначальном виде
- Только идентификатор (внешний ключ) хранится для До одной ассоциации
Это показывает общий дизайн кэша второго уровня Hibernate, в котором модель кэша отражает базовую реляционную модель, которая экономична в пространстве и позволяет легко синхронизировать их.
9.1. Внутреннее представление кэшированных коллекций
Мы уже упоминали, что мы должны явно указать, что коллекция ( OneToMany или ManyToMany association) кэшируется, в противном случае она не кэшируется.
На самом деле Hibernate хранит коллекции в отдельных областях кэша, по одной для каждой коллекции. Имя региона-это полное имя класса плюс имя свойства коллекции, например: com.baeldung.hibernate.cache.model.Foo.bars . Это дает нам гибкость в определении отдельных параметров кэша для коллекций, например /политика выселения/истечения срока действия.
Кроме того, важно отметить, что для каждой записи коллекции кэшируются только идентификаторы сущностей, содержащихся в коллекции, что означает, что в большинстве случаев рекомендуется также кэшировать содержащиеся в ней сущности.
10. Аннулирование кэша для запросов в стиле HQL DML и собственных запросов
Когда речь заходит о HQL в стиле DML ( insert , update и delete HQL-операторах), Hibernate может определить, на какие сущности влияют такие операции:
В этом случае все экземпляры Foo удаляются из кэша L2, в то время как другое кэшированное содержимое остается неизменным.
Однако, когда дело доходит до собственных операторов SQL DML, Hibernate не может угадать, что обновляется, поэтому он делает недействительным весь кэш второго уровня:
Это, вероятно, не то, что вы хотите! Решение состоит в том, чтобы сообщить Hibernate, на какие сущности влияют собственные операторы DML, чтобы он мог удалить только записи, связанные с Foo сущностями:
Мы должны вернуться в спящий режим SQL-запрос API, поскольку эта функция (пока) не определена в JPA.
Обратите внимание, что вышесказанное относится только к операторам DML ( insert , update , delete и вызовам собственных функций/процедур). Собственные select запросы не делают кэш недействительным.
11. Кэш запросов
Результаты запросов HQL также могут быть кэшированы. Это полезно, если вы часто выполняете запрос к сущностям, которые редко меняются.
Затем для каждого запроса необходимо явно указать, что запрос можно кэшировать (с помощью подсказки org.hibernate.cacheable query):
11.1. Рекомендации по кэшированию запросов
Вот некоторые рекомендации и рекомендации, связанные с кэшированием запросов :
- Как и в случае с коллекциями, кэшируются только идентификаторы сущностей, возвращаемых в результате кэшируемого запроса, поэтому настоятельно рекомендуется включить кэш второго уровня для таких сущностей.
- Существует одна запись кэша на каждую комбинацию значений параметров запроса (переменные привязки) для каждого запроса, поэтому запросы, для которых вы ожидаете много различных комбинаций значений параметров, не являются хорошими кандидатами для кэширования.
- Запросы, включающие классы сущностей, для которых в базе данных часто происходят изменения, также не являются хорошими кандидатами для кэширования, поскольку они будут аннулированы всякий раз, когда произойдет изменение, связанное с любым из классов сущностей, участвующих в запросе, независимо от того, кэшируются ли измененные экземпляры как часть результата запроса или нет.
- По умолчанию все результаты кэша запросов хранятся в файле org.hibernate.cache.internal.Стандартный кэш регион. Как и в случае кэширования сущностей/коллекций, вы можете настроить параметры кэша для этой области, чтобы определить политики выселения и истечения срока действия в соответствии с вашими потребностями. Для каждого запроса вы также можете указать пользовательское имя региона, чтобы предоставить различные настройки для разных запросов.
- Для всех таблиц, которые запрашиваются как часть кэшируемых запросов, Hibernate сохраняет метки времени последнего обновления в отдельном регионе с именем org.hibernate.cache.spi.UpdateTimestampsCache . Знание этой области очень важно при использовании кэширования запросов, поскольку Hibernate использует ее для проверки того, что кэшированные результаты запросов не устарели. Записи в этом кэше не должны быть удалены/истекли до тех пор, пока существуют кэшированные результаты запросов для соответствующих таблиц в областях результатов запросов. Лучше всего отключить автоматическое удаление и истечение срока действия для этой области кэша, так как она в любом случае не потребляет много памяти.
12. Заключение
В этой статье мы рассмотрели, как настроить кэш второго уровня гибернации. Мы увидели, что его довольно легко настроить и использовать, поскольку Hibernate выполняет всю тяжелую работу за кулисами, делая использование кэша второго уровня прозрачным для бизнес-логики приложения.
Реализация этого учебника по кэшированию второго уровня Hibernate доступна на Github . Это проект на основе Maven, поэтому его должно быть легко импортировать и запускать как есть.
Довольно часто в java приложениях с целью снижения нагрузки на БД используют кеш. Не много людей реально понимают как работает кеш под капотом, добавить просто аннотацию не всегда достаточно, нужно понимать как работает система. Поэтому этой статье я попытаюсь раскрыть тему про то, как работает кеш популярного ORM фреймворка. Итак, для начала немного теории.
- Кеш первого уровня (First-level cache);
- Кеш второго уровня (Second-level cache);
- Кеш запросов (Query cache);
Кеш первого уровня
Кеш первого уровня всегда привязан к объекту сессии. Hibernate всегда по умолчанию использует этот кеш и его нельзя отключить. Давайте сразу рассмотрим следующий код:
Возможно, Вы ожидаете, что будет выполнено 2 запроса в БД? Это не так. В этом примере будет выполнен 1 запрос в базу, несмотря на то, что делается 2 вызова load(), так как эти вызовы происходят в контексте одной сессии. Во время второй попытки загрузить план с тем же идентификатором будет использован кеш сессии.
Один важный момент — при использовании метода load() Hibernate не выгружает из БД данные до тех пор пока они не потребуются. Иными словами — в момент, когда осуществляется первый вызов load, мы получаем прокси объект или сами данные в случае, если данные уже были в кеше сессии. Поэтому в коде присутствует getName() чтобы 100% вытянуть данные из БД. Тут также открывается прекрасная возможность для потенциальной оптимизации. В случае прокси объекта мы можем связать два объекта не делая запрос в базу, в отличии от метода get(). При использовании методов save(), update(), saveOrUpdate(), load(), get(), list(), iterate(), scroll() всегда будет задействован кеш первого уровня. Собственно, тут нечего больше добавить.
Кеш второго уровня
Если кеш первого уровня привязан к объекту сессии, то кеш второго уровня привязан к объекту-фабрике сессий (Session Factory object). Что как бы подразумевает, что видимость этого кеша гораздо шире кеша первого уровня. Пример:
В данном примере будет выполнено 2 запроса в базу, это связано с тем, что по умолчанию кеш второго уровня отключен. Для включения необходимо добавить следующие строки в Вашем конфигурационном файле JPA (persistence.xml):
- EHCache
- OSCache
- SwarmCache
- JBoss TreeCache
Только после всех этих манипуляций кеш второго уровня будет включен и в примере выше будет выполнен только 1 запрос в базу.
Еще одна важная деталь про кеш второго уровня про которую стоило бы упомянуть — хибернейт не хранит сами объекты Ваших классов. Он хранит информацию в виде массивов строк, чисел и т. д. И идентификатор объекта выступает указателем на эту информацию. Концептуально это нечто вроде Map, в которой id объекта — ключ, а массивы данных — значение. Приблизительно можно представить себе это так:
Что есть очень разумно, учитывая сколько лишней памяти занимает каждый объект.
Помимо вышесказанного, следует помнить — зависимости Вашего класса по умолчанию также не кешируются. Например, если рассмотреть класс выше — SharedDoc, то при выборке коллекция users будет доставаться из БД, а не из кеша второго уровня. Если Вы хотите также кешировать и зависимости, то класс должен выглядеть так:
И последняя деталь — чтение из кеша второго уровня происходит только в том случае, если нужный объект не был найден в кеше первого уровня.
Кеш запросов
Перепишем первый пример так:
Результаты такого рода запросов не сохраняются ни кешом первого, ни второго уровня. Это как раз то место, где можно использовать кеш запросов. Он тоже по умолчанию отключен. Для включения нужно добавить следующую строку в конфигурационный файл:
а также переписать пример выше добавив после создания объекта Query (то же справедливо и для Criteria):
Кеш запросов похож на кеш второго уровня. Но в отличии от него — ключом к данным кеша выступает не идентификатор объекта, а совокупность параметров запроса. А сами данные — это идентификаторы объектов соответствующих критериям запроса. Таким образом, этот кеш рационально использовать с кешем второго уровня.
Стратегии кеширования
- Read-only
- Read-write
- Nonstrict-read-write
- Transactional
Cache region
Регион или область — это логический разделитель памяти вашего кеша. Для каждого региона можна настроить свою политику кеширования (для EhCache в том же ehcache.xml). Если регион не указан, то используется регион по умолчанию, который имеет полное имя вашего класса для которого применяется кеширование. В коде выглядит так:
А для кеша запросов так:
Что еще нужно знать?
Во время разработки приложения, особенно сначала, очень удобно видеть действительно ли кешируются те или иные запросы, для этого нужно указать фабрике сессий следующие свойства:
В дополнение фабрика сессий также может генерировать и сохранять статистику использования всех объектов, регионов, зависимостей в кеше:
Для этого есть объекты Statistics для фабрики и SessionStatistics для сессии.
Методы сессии:
flush() — синхронизирует объекты сессии с БД и в то же время обновляет сам кеш сессии.
evict() — нужен для удаления объекта из кеша cессии.
contains() — определяет находится ли объект в кеше сессии или нет.
clear() — очищает весь кеш.


В статье о поддержке пользовательских типов в Hibernate упоминается о поддержке кэширования. В этой статье я постараюсь рассказать о кэшровании подробнее.
Идея кэширования (не только в Hibernate) основывается на мнении, что из всех данных, доступных для обработки, работа ведётся только над некоторым небольшим набором и если ускорить доступ к этому набору, то в среднем программа будет работать быстрее. Говоря конкретно о Hibernate, доступ к базе занимает на порядке больше времени, чем доступ к объекту в памяти JVM. И поэтому, если какое-то время хранить в памяти загруженные из БД объекты, то при их повторном запросе Hibernate сможет вернуть их гораздо быстрее.
С объектом Session , а точнее с persistence context, в Hibernate всегда связан кэш первого уровня. При помещении объекта в persistence context, то есть при его загрузке из БД или сохранении, объект так же автоматически будет помещён в кэш первого уровня и это невозможно отключить. Соответственно, при запросах того же самого объекта несколько раз в рамках одного persistence context, запрос в БД будет выполнен один раз, а всё остальные загрузки будут выполнены из кэша.
System . out . println ( session . get ( Person . class , 123456L ) ) ; System . out . println ( session . get ( Person . class , 123456L ) ) ;В примере выше только первый вызов get ( ) инициирует запрос к базе, второй вызов будет обслужен уже из кэша и обращения к базе не произойдёт.
Интересно поведение кэша первого уровня при использовании ленивой загрузки. При загрузке объекта методом load ( ) или объекта с лениво загружаемыми полями, лениво загружаемые данные в кэш не попадут. При обращении к данным будет выполнен запрос в базу и данные будут загружены и в объект и в кэш. А вот следующая попытка лениво загрузить объект приведёт к тому, что объект сразу вернут из кэша и уже полностью загруженным.
// Database is not queried, only reference is returnedКонфигурирование кэша
Hibernate не реализует сам никакого in-memory сache, а использует существующие реализации кэшей. Раньше Hibernate самостоятельно поддерживал интерфейс с этими кэшами, но сейчас существует JCache и корректнее будет использовать этот интерфейс. Реализаций у JCache множество, но я выберу ehcache, как одну из самых распространённых.
В первую очередь надо добавить поддержку JCache и ehcache в зависимости:
Затем настроить hibernate на использование ehcache для кэширования:
<property name = "hibernate.cache.region.factory_class" > org.hibernate.cache.jcache.JCacheRegionFactory </property> <property name = "hibernate.javax.cache.provider" > org.ehcache.jsr107.EhcacheCachingProvider </property>В первой строке мы говорим Hibernate, что хотим использовать JCache интерфейс, а во второй строке выбираем конкретную реализацию JCache: ehcache.
Наконец, включим кэш второго уровня:
<property name = "hibernate.cache.use_second_level_cache" > true </property>@Cacheable и @Cache
@Cacheable это аннотация JPA и позволяет объекту быть закэшированным. Hibernate поддерживает эту аннотацию в том же ключе. public class Person extends AbstractIdentifiableObject <@Cache это аннотация Hibernate, настраивающая тонкости кэширования объекта в кэше второго уровня Hibernate. Аннотации @Cacheable достаточно, чтобы объект начал кэшироваться с настройками по умолчанию. При этом @Cache использованная без @Cacheable не разрешит кэширование объекта.
@Cache принимает три параметра:
- include , имеющий по умолчанию значение all и означающий кэширование всего объекта. Второе возможное значение, non-lazy, запрещает кэширование лениво загружаемых объектов. Кэш первого уровня не обращает внимания на эту директиву и всегда кэширует лениво загружаемые объекты.
- region позволяет задать имя региона кэша для хранения сущности. Регион можно представить как разные кэши или разные части кэша, имеющие разные настройки на уровне реализации кэша. Например, я мог бы создать в конфигурации ehcache два региона, один с краткосрочным хранением объектов, другой с долгосрочным и отправлять часто изменяющиеся объекты в первый регион, а все остальные во второй.
- usage задаёт стратегию одновременного доступа к объектам.
Последний пункт достаточно объёмен, чтобы рассматривать его внутри списка. Проблема заключается в том, что кэш второго уровня доступен из нескольких сессий сразу и несколько потоков программы могут одновременно в разных транзакциях работать с одним и тем же объектом. Следовательно надо как-то обеспечивать их одинаковым представлением этого объекта.
Стратегий одновременного доступа к объектам в кэше в hibernate существует четыре:
Список выше отсортирован по нарастанию производительности, transactional стратегия самая медленная, read-only самая быстрая. Недостатком read-only стратегии является её бесполезность, в случае если объекты постоянно изменяются, так как в этом случае они не будут задерживаться в кэше.
Использование кэша второго уровня требует изменений в конфигурации Hibernate и в коде сущностей, но не требует изменения кода запросов и управления сущностями:
Пример
Извлекать из базы сущности мы будем в тесте Spring Boot приложения. На старте приложения (и теста) а базу добавляются некоторые данные. А в настройках включено отображение SQL-команд в консоли.
Тест помечен аннотацией @Transactional, что означает, что он выполняется в рамках транзакции. То есть в начале и в конце теста неявно выполняется begin() и commit() транзакции. Мы эти методы не видим, их вызывает Spring с помощью AOP.
Итак, давайте вызовем в тесте em.find() дважды:
В результате такого теста выполнится только один SQL-select:
Обратите внимание что EntityManager так и аннотирован говорящей аннотацией @PersistenceContext.Включение кэша второго уровня
Рассмотрим пример. Только сначала включим кэш второго уровня. Для этого надо добавить в POM-файл какой-либо кэш, например Ehcache:
Теперь можно извлекать сущность в двух разных сессиях, для этого сделаем два @Transactional-теста, для каждого из будет открываться своя сессия и выполняться em.find() сущности City с >
Только сначала пометим сущность City как кэшируемую, поскольку кэш второго уровня включается не для всех сущностей сразу, а только для помеченных аннотацией @org.hibernate.annotations.Cache:
READ_ONLY CacheConcurrencyStrategy
Обратите внимание, что мы пометили сущность кэшируемой, выбрав стратегию CacheConcurrencyStrategy.READ_ONLY, что и подразумевает, что сущность не редактируется, а доступна только для чтения.
После первого select City помещается в кэш второго уровня. Поэтому для второго теста SQL- команда select не выполняется, что и видно выше.
Если же в application.yml отключить кэш второго уровня (поставить false), то в к консоли мы увидим две SQL-команды select:
Что означает, что City не кэшируется.
Итоги
Мы рассмотрели на примерах, что такое кэш первого и второго уровня в Hibernate, и как включить кэш второго уровня.
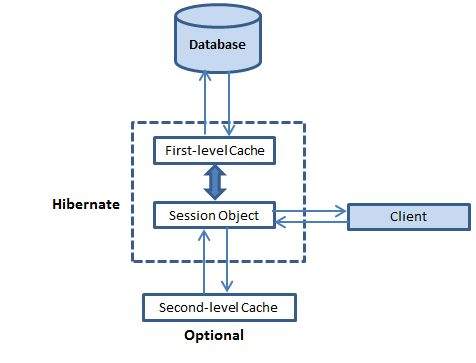
Кэш первого уровня
Если вы выпускаете несколько обновлений для объекта, Hibernate пытается отложить выполнение обновления как можно дольше, чтобы уменьшить количество выпущенных операторов SQL обновления. Если вы закроете сеанс, все кэшируемые объекты будут потеряны и сохранены или обновлены в базе данных.
Кэш второго уровня
Любой сторонний кеш может быть использован с Hibernate. Предоставляется интерфейс org.hibernate.cache.CacheProvider , который должен быть реализован, чтобы обеспечить Hibernate дескриптором реализации кэша.
Кэш на уровне запросов
Hibernate также реализует кеш для наборов результатов запросов, который тесно интегрируется с кешем второго уровня.
Это необязательная функция, для которой требуются две дополнительные области физического кэша, в которых хранятся результаты кэшированного запроса и отметки времени последнего обновления таблицы. Это полезно только для запросов, которые часто выполняются с одинаковыми параметрами.
Кэш второго уровня
Hibernate по умолчанию использует кэш первого уровня, и вам нечего делать, чтобы использовать кэш первого уровня. Давайте перейдем прямо к дополнительному кешу второго уровня. Не все классы получают выгоду от кэширования, поэтому важно иметь возможность отключить кэш второго уровня.
Кэш второго уровня Hibernate настраивается в два этапа. Сначала вы должны решить, какую стратегию параллелизма использовать. После этого вы настраиваете срок действия и физические атрибуты кеша с помощью провайдера кеша.
Стратегии параллелизма
Транзакционный. Используйте эту стратегию для данных, предназначенных главным образом для чтения, где важно предотвратить устаревшие данные в параллельных транзакциях в редких случаях обновления.
Транзакционный. Используйте эту стратегию для данных, предназначенных главным образом для чтения, где важно предотвратить устаревшие данные в параллельных транзакциях в редких случаях обновления.
Если мы собираемся использовать кэширование второго уровня для нашего класса Employee , добавим элемент отображения, необходимый для того, чтобы Hibernate кэшировал экземпляры Employee, используя стратегию чтения-записи.
Он может кэшироваться в памяти или на диске, а также в кластерном кэшировании и поддерживает дополнительный кэш результатов запроса Hibernate.
Поддерживает кэширование в память и на диск в одной JVM с богатым набором политик истечения срока действия и поддержкой кэша запросов.
Кластерный кеш на основе JGroups. Он использует кластеризованную аннулирование, но не поддерживает кэш запросов Hibernate.
JBoss Cache
Полностью транзакционный реплицируемый кластерный кеш, также основанный на многоадресной библиотеке JGroups. Он поддерживает репликацию или аннулирование, синхронную или асинхронную связь, а также оптимистическую и пессимистическую блокировки. Кеш запросов Hibernate поддерживается.
Он может кэшироваться в памяти или на диске, а также в кластерном кэшировании и поддерживает дополнительный кэш результатов запроса Hibernate.
Поддерживает кэширование в память и на диск в одной JVM с богатым набором политик истечения срока действия и поддержкой кэша запросов.
Кластерный кеш на основе JGroups. Он использует кластеризованную аннулирование, но не поддерживает кэш запросов Hibernate.
JBoss Cache
Полностью транзакционный реплицируемый кластерный кеш, также основанный на многоадресной библиотеке JGroups. Он поддерживает репликацию или аннулирование, синхронную или асинхронную связь, а также оптимистическую и пессимистическую блокировки. Кеш запросов Hibernate поддерживается.
Каждый поставщик кэша не совместим с любой стратегией параллелизма. Следующая матрица совместимости поможет вам выбрать подходящую комбинацию.
| Стратегия / Provider | Только для чтения | Nonstrictread-записи | Читай пиши | транзакционный |
|---|---|---|---|---|
| EHCache | Икс | Икс | Икс | |
| OSCache | Икс | Икс | Икс | |
| SwarmCache | Икс | Икс | ||
| JBoss Cache | Икс | Икс |
Теперь вам нужно указать свойства областей кэша. EHCache имеет свой собственный файл конфигурации, ehcache.xml , который должен находиться в CLASSPATH приложения. Конфигурация кэша в ehcache.xml для класса Employee может выглядеть так:
Вот и все, теперь у нас включено кэширование второго уровня для класса Employee, а Hibernate теперь обращается к кэшу второго уровня, когда вы переходите к Employee или когда вы загружаете Employee по идентификатору.
Вы должны проанализировать все свои классы и выбрать подходящую стратегию кэширования для каждого из классов. Иногда кэширование второго уровня может снизить производительность приложения. Поэтому рекомендуется сначала провести сравнительный анализ вашего приложения, не включая кэширование, а затем включите хорошо подходящее кэширование и проверьте производительность. Если кэширование не улучшает производительность системы, то нет смысла включать любой тип кэширования.
Кэш на уровне запросов
Hibernate также поддерживает очень тонкую поддержку кэша благодаря концепции области кэша. Регион кеша является частью кеша, которому дано имя.
Этот код использует метод, чтобы сообщить Hibernate хранить и искать запрос в области кэша сотрудников.
Читайте также: