
Петля в сети ethernet что это
Обновлено: 05.07.2024
Одним из самых страшных бичей сети ethernet являются, так называемые, петли. Они возникают когда (в основном из-за человеческого фактора) в топологии сети образуется кольцо. К примеру, два порта коммутатора соединили патч-кордом (часто бывает когда два свича заменяют на один и не глядя втыкают всё, что было) или запустили узел по новой линии, а старую отключить забыли (последствия могут быт печальными и трудно выявляемыми). В результате такой петли пакеты начинают множиться, сбиваются таблицы коммутации и начинается лавинообразный рост трафика. В таких условиях возможны зависания сетевого оборудования и полное нарушение работы сети.
Помимо настоящих петель не редки случаи когда при выгорания порта (коммутатора или сетевой карты) он начинает возвращать полученные пакеты назад в сеть, при этом чаще всего соединение согласовывается в 10M, а линк поднимается даже при отключенном кабеле. Когда в сегменте такой порт только один, последствия могут быть не столь плачевными, но всё же весьма чувствительны (особенно сильно страдают пользователи висты и семёрки). В любом случае с такими вещами нужно нещадно бороться и понимать тот факт, что намеренно или случайно создавая петлю, пусть и на небольшой период времени, можно отключить целый сегмент сети.
Матчасть
К счастью большинство современных управляемых коммутаторов, в том или ином виде, имеют функции выявления петель (loopdetect, stp), и даже более того, семейство протоколов stp позволяет специально строить кольцевую топологию (для повышения отказоустойчивости и надёжности). Но тут есть и обратная сторона медали, не редко случается так, что один сгоревший порт может оставить без связи целый район. Или скажем у того же stp перестроение топологии происходит далеко не мгновенно, связь в этот момент, естественно, оставляет желать лучшего. Кроме того, некоторые производители весьма халатно относятся к реализации протоколов обнаружения петель, скажем DES-3016 (глинк) вообще не может определить петлю если просто соединить два его порта.
Принципы выявления
Принцип обнаружения петель (loopdetect) довольно простой. В сеть отправляется специальный пакет с броадкаст адресом (предназначен всем) и если он вернулся назад, считаем, что сеть за этим интерфейсом закольцована. Дальнейшие действия зависят от типа оборудования и настроек. Чаще всего порт полностью или частично (в отдельном vlan) блокируется, событие записывается в логи, отправляются snmp-трапы. Тут в дело вступают системные администраторы и аварийная служба.
Если вся сеть управляемая, то выявить и устранить петлю довольно не сложно. Но не так уж мало сетей где к одному порту подключена цепочка из 5 — 6 неуправляемых коммутаторов. Устранение такой петли может занять немало времени и сил. Процесс поиска же сводится к последовательному отключению (включению) портов. Для определения наличия петли используется либо вышестоящий управляемый коммутатор, либо какой-нибудь снифер (wireshark, tcpdump). Первый способ весьма опасен в следствие наличия задержки между включением и выключением блокировки, в лучшем случае у пользователей просто будут лаги, а в худшем — сработает loopdetect выше по линии и отвалится уже куда больший сегмент. Во втором случае опасности для пользователей нет, но зато намного сложнее определять наличие петли (особенно в небольшом сегменте, где мало броадкаст трафика), всё-таки снифер вещь, по определению, пассивная.
Своими руками
Как было сказано выше, аппаратных реализаций поиска петель хватает с лихвой. Так что не долго думая, включаю wireshark настраиваю фильтр и смотрю, что и как делает коммутатор. Собственно всё просто: в порт отправляется пакет ethernet с адресом назначения cf:00:00:00:00:00, типом 0x9000 (CTP) и c неведомым номером функции 256 (в найденной мной документации описаны только две). Адрес назначение является броадкастовым, так что при наличии в сети петли назад должно вернутся несколько копий этого пакета.
Коллизия в сети
Что такое коллизия в сети (collision)? Сегодня мы разберем само понятие коллизий в локальной сети, возможные причины их возникновения и как бороться с подобным явлением? Также узнаем, что такое домен коллизий?
Наша статья, будет состоять из двух частей: в первой (теоретической) мы рассмотрим основные понятия и термины, которые нам пригодятся в дальнейшем, а во второй части я покажу Вам (на примере), какие могут быть проблемы в реальной сети и к чему нужно быть готовым?
Итак, разберем само понятие коллизия. Буквально оно означает - столкновение. Что может сталкиваться в компьютерной сети? Правильно, - передаваемые по ней данные, точнее - пакеты (кадры) данных. Помните про принцип коммутации пакетов, о котором мы говорили в одной из наших статей?
Проиллюстрируем возникновение коллизии в компьютерной сети на простенькой схеме:
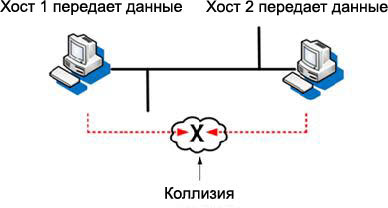
Как видите хост (компьютер) под номером «1» начинает передачу своих пакетов данных в сеть. Точно в это же время другой хост начинает передачу своих данных. В результате, данные "сталкиваются", что приводит к их полной или частичной потере. Как мы понимаем это - недопустимое явление, так как недоставленные данные нужно передавать снова, а это - временные задержки, которые не каждый пользователь будет готов терпеть. Да и Вам самим постоянное нытье "подопечных" скоро надоест:)
Итак, на основе сказанного выше, давайте дадим краткое определение коллизии в сети: коллизия это - столкновение двух или более кадров в сети, приводящее к их потере или искажению.
Сами столкновения происходят где? Правильно, - в кабеле! Отсюда следует еще одно определение: сетевой кабель это - разделяемая среда передачи данных для всех компьютеров сети. Разделяемая именно потому, что ее пропускная способность (полоса пропускания) делится между всеми компьютерами, образующими сеть.
Учитывая скорости движения данных в сети, вряд ли возникновение коллизии возможно в случае соединения только двух компьютеров? НО! Если компьютеров становится больше?
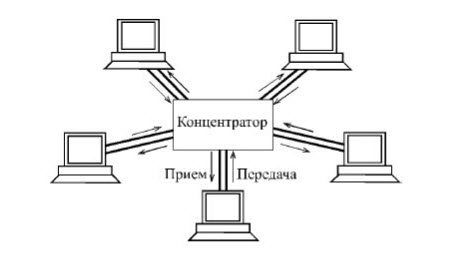
Или - очень много (несколько сотен) и всем нужно передавать (и принимать) сетевой трафик? Вот именно тогда и возрастает риск возникновения коллизий.
Здесь возникает необходимость в механизме синхронизации доступа сетевых интерфейсов отдельных компьютеров к общей разделяемой среде. Применимо к технологии Ethernet (не зависимо от скорости передачи) этот принцип доступа называется CSMA/CD (Carrier Sense Multiple Access with Collision Detection, что переводится так: множественный доступ с контролем несущей и обнаружением коллизий). Фактически, это - случайный метод доступа к среде. Иногда метод CSMA/CD называют протоколом, который работает на канальном уровне сетевой модели OSI.
Примечание: сетевая модель OSI (open systems interconnection basic reference model - базовая модель взаимодействия открытых систем). Это - модель совместной работы сетевых протоколов различных уровней (всего - семь), которая, в полной мере, позволяет реализовать эффективный обмен данными в сети.
Случайный характер алгоритма доступа к среде передачи данных, принятый в технологии Ethernet, нельзя назвать идеальным. При большом количестве запросов на доступ к среде передачи, генерируемых узлами в случайные моменты времени, вероятность возникновения коллизий также возрастает, что приводит к неэффективному использованию всего канала. Время обнаружения коллизии и время ее обработки составляют дополнительные временные затраты, а интервал в течение которого канал предоставляется в распоряжение каждому узлу, становится все меньше.
Чтобы понапрасну не впасть в состояние паники скажем, что для стандартной сетевой технологии Ethernet наличие коллизий в сети - нормальное явление! Другое дело, что иногда возникают ситуации, когда коллизионных столкновений становится настолько много, что вся полоса пропускания способность сети буквально "съедается" мусорным трафиком и передавать полезные данные становится просто невозможно!
Подобный случай мы рассматривали в статье, о возможности образования петли в локальной сети организации.
Давайте с Вами рассмотрим, какие же бывают разновидности коллизий?
- Коллизия на дальнем конце (в самом кабеле). Возникает из-за одновременной передачи по одной и той же линии данных двумя станциями.
- Коллизия на ближнем конце (в сетевой карте). Происходит, когда сбоит сетевой адаптер ПК или его драйвер и второй кадр начинается записываться в буфер карты еще до окончания передачи первого.
- Коллизии в активном оборудовании (свитчи, хабы). Возникают из-за перегрузки оборудования передаваемыми кадрами, приводя к ошибкам в адресации и наложению нескольких кадров друг на друга.
Чтобы покончить с обязательной терминологией, давайте рассмотрим еще одно нужное нам словосочетание: домен коллизий (Collision Domain).
Что это такое? Ну, грубо говоря, это - коммутатор (свитч) с подключенными к нему компьютерами. Как на схеме выше. Если чуть более академично то - "область сети одновременная передача двух и более станций которой приводит к образованию коллизии". Коммутатор изолирует большую часть трафика одного сегмента сети от трафика другого сегмента (домена коллизий). В результате, пропускная способность каждого отдельного сегмента увеличивается, а значит, - повышается и суммарная пропускная способность сети.
В идеале, коммутатор должен препятствовать распространению коллизии дальше (не пропускать ее), поэтому им, собственно, и ограничивается этот самый домен коллизий. Другое дело, что на практике это не всегда так и если возникновение коллизии происходит на ближнем конце (причиной является неисправная сетевая карта компьютера), то события могут разворачиваться совсем по другому. Но об этом - во второй (практической) части нашей статьи :)
Какие же есть методы, позволяющие предотвратить ситуацию, когда коллизия в сети может стать массовым явлением, что (со временем) приведет к полной ее неработоспособности?
Первая состоит в том, что механизм арбитража (реагирования) на возникновение коллизии уже встроен в большинство стандартных сетевых технологий! Применимо к наиболее распространенной из них технологии Ethernet, это выглядит следующим образом: один из участников коллизии (при обнаружении, что его передача приводит к столкновению кадров) автоматически генерирует на всю сеть специальную jam-последовательность (jam-signal). Получившие такой сигнал компьютеры знают, что им нужно немедленно прекратить свою передачу данных, сделать случайный временной тайм-аут (backoff time или delay) от 29-ти до 210-ти битовых интервалов, а затем - возобновить работу в штатном режиме. Метод доступа к среде CSMA/CD - в действии!
Примечание: битовый интервал это время, за которое по сети передается наименьшая единица информации - один бит.
На что похожа ситуация, которую мы описали выше? Лично мне она напоминает, когда два человека начинают говорить одновременно. Что происходит в такой ситуации при нормальных условиях? Оба говорящих замолкают, немного выжидают и кто-то первым начинает говорить снова, а второй - молчит и слушает. Потом - отвечает или задает свой вопрос.
Абсолютно идентично и с компьютерами! Их ведь люди создали, вот и "ведут" они себя так же :)
Вторая из новостей такая: с коллизией в сети можно бороться средствами, которые предоставляет нам сетевое оборудование соответствующего класса. Например: вот - один из центральных коммутаторов нашей сети на работе: D-Link DES-3550

Это - 50-ти портовый управляемый свитч стоимостью около 600 долларов. Управляемый означает, что он имеет в сети свой выделенный IP адрес и к нему можно подключиться удаленно (введя пароль доступа). Можно по сети производить конфигурацию устройства, включать или отключать отдельные порты, менять режим их работы, мониторить нагрузку на устройство, управлять скоростью каждого порта (подобным образом провайдеры выдумывают свои тарифные планы) и т.д.
Это - управляемый коммутатор второго уровня. Это значит, что он эффективно работает на втором уровне сетевой модели OSI. Сейчас все более популярными становятся устройства третьего уровня (могут работать уже на сетевом IP уровне). Упрощенно это уже - очень быстро передающие пакеты маршрутизаторы, к тому же - простые в использовании.
Давайте, о самом коммутаторе мы еще поговорим во второй части данной статьи (я покажу Вам подробные скриншоты его админ-зоны, покажу что там к чему), здесь я привел его фотографию для того, чтобы показать с помощью каких устройств можно бороться с коллизиями в сети. Коммутатор D-Link DES-3550 позволяет администратору видеть загрузку каждого из портов в режиме реального времени и если какой-либо из портов перегружен или на нем много коллизий - принять соответствующие меры.
Давайте еще немного поговорим на тему разделяемой среды передачи данных. Это, фактически, - и есть наш сетевой кабель, помните? При таком его кооперативном использовании, возникает задача утилизации среды передачи таким образом, чтобы в каждый отдельный момент времени по кабелю передавались данные только одного передатчика (компьютера).
Пропускная способность кабеля делится между всеми компьютерами сети. Например: если у нас 100 компьютеров и сеть работающая на скорости 100 мегабит в секунду, то в среднем на каждый ПК приходится 1Мбит/с пропускной способности. А если компьютеров становится больше? Время для передачи данных, выделяемое каждому из них, сокращается и, как следствие, - коллизия в сети гарантирована! Добавьте к этому все возрастающее время отклика сети, недовольство пользователей и Вы поймете, что возникновение коллизии - неприятная вещь, с которой надо бороться, а еще лучше - сводить возможность ее возникновения к минимуму еще на этапе планирования сети.
Также нужно четко понимать, что некоторую часть доступной пропускной способности сети отнимает у пользовательских данных широковещательный служебный трафик, который является неотъемлемой частью практически всех стеков протоколов, работающих в локальных сетях.
Несмотря на все эти сложности, принцип разделяемой среды используется достаточно часто. Такой подход, реализован в широко распространенных стандартных технологиях локальных сетей, например: Ethernet, Token Ring, FDDI. Почему? Наверное, из за простоты и дешевизны его конечной реализации (дешево и сердито) :)
Петля в локальной сети и ее последствия
Прежде всего: что такое петля в сети? Это - логическое кольцо для проходящего сигнала, когда запараллелены пути его прохождения. Грубо говоря можно сказать так: когда сигнал вместо того, чтобы от коммутатора разойтись по подключенным к нему компьютерам возвращается обратно в коммутатор и так продолжается бесконечно (по кругу). Возникает логическая "петля" (кольцо).
Сеть (участок сети), в такой ситуации, со временем начинает работать исключительно на передачу данных самого "кольца" (мусорных данных), "забивая" весь полезный сетевой трафик.
Само собой, что форма этого "кольца" может быть любой, главное - сигнал уходит и приходит в один и тот же коммутатор (хаб, маршрутизатор и т.д).
И вот, сижу я как-то на 11-м этаже нашего здания, компьютер настраиваю. Делаю что-то локально, не связанное с сетью. Краем уха слышу через два стола: "Интернет не грузится. " Ну, думаю, не грузится и не грузится. мало ли что? Тут - из другого конца помещения: "Ой, на сетевые диски зайти не могу!". Тут я уже насторожился и решил "пропинговать" один из наших внутренних серверов.
Каково же было мое удивление, когда я увидел временные задержки выполнения команды "ping". Они были более ста миллисекунд! Это, повторюсь, - в локальной сети, а последний пакет данных вообще не дошел до адресата. На всякий случай - перезагрузил компьютер, за которым сидел (мало ли что?) - никаких изменений, и вдобавок сетевые диски, которые автоматически монтируются при загрузке операционной системы - "отвалились".
Причем, из источников, приближенных к достоверным, известно, что этажом ниже и выше с сетью все нормально. Вывод - проблема в коммутационном шкафу этажа.
Да-а-а. думаю, а день так хорошо начинался! :) Делать нечего - беру ключи и иду к этому коммутационному центру нашей СКС (структурированной кабельной системы) сети.
Примечание: что такое СКС сеть и как ее правильно построить мы с подписчиками разбирали в одном из наших дополнительных уроков. Для того чтобы получить к ним доступ, Вам нужно подписаться на нашу бесплатную рассылку вот на этой странице.
Открываю, значится, его и заглядываю внутрь:

Давайте в двух словах что мы здесь видим? Красным обведены два сетевых коммутатора (свитча), установленных на стойках внутри. Скобками обозначены патч панели, порты которых (посредством витой пары) соединяются с сетевыми розетками на рабочих местах пользователей по всему этажу.
Сначала - локализуем проблему. Отключаем один коммутатор (нижний), идем к одному из ближайших компьютеров, который подключается через верхний свитч и проверяем работу сети - те же "длинные пинги" и прочие признаки неработоспособности локальной сети.
Теперь делаем наоборот: включаем нижний свитч и выключаем верхний. Проверяем с компьютера, подключенного к нижнему коммутатору. Работа сети восстановилась в полном объеме: «ping» проходит без задержек, после перезагрузки подмонтировались сетевые диски!
Значит - проблема в верхнем коммутаторе, либо - в подключенных к нему патч кордах (коротких сетевых кабелях). Итак, посмотрим на эти самые патч корды, которыми наш коммутатор соединяется с патч панелями в кроссовом шкафу.

Как мы уже говорили, тут есть два возможных варианта развития событий: либо проблема с самим коммутатором (тогда его придется полностью менять), либо - с кабелями подключения. Также возможен частичный выход из строя одного из портов свитча. При подобной неисправности возможна ситуация, когда сеть со временем "наполняется" широковещательными пакетами, рассылаемыми этим неисправным портом. В таком случае "симптомы" будут похожи на то, что мы и имеем сейчас и называется подобное явление - широковещательный шторм.
В любом случае, надо начинать проверку с самого незатратного по времени и силам варианта. В нашем случае это - кабели. Подключаем все в исходное положение и начинаем по порядку вытягивать из верхнего коммутатора по нескольку кабелей (при этом, естественно, мониторим ситуацию с ближайшего компьютера, гарантированно имеющего сеть).
После извлечения очередной пары кабелей (примерно на середине свитча) работа сети неожиданно (или - ожидаемо) восстанавливается! :) Та-а-ак. методом нескольких дополнительных подключений и отключений находим один порт на коммутаторе, после подключения к которому сеть "ложится"!
Похоже - битый порт? Но тут я замечаю одну очень неожиданную вещь! Обратите внимание на фото ниже:

При вытягивании кабеля из порта под номером «21» (того самого, найденного нами) гаснет светодиод на порте под номером «19». Оба кабеля обведены для наглядности красным. Верхний ряд свитча - порты с нечетными номерами.
Получается, что для коммутатора это, вроде как, - один кабель. Вставляем коннектор в порт - загораются два светодиода, отключаем - гаснут так же оба. Хотя, по идее, гаснуть должен только один (тот, который мы и отключаем)!
Такая ситуация возможна только в том случае, если мы имеем дело с "кольцом" или "петлей" в сети и эти два конца патч корда желтого цвета являются окончаниями одного кабеля, запущенного в свитч по кольцу.
Примерно вот так:

Но тогда получается, что кто-то намеренно вскрыл запертый кроссовый шкаф, создал эту "петлю", аккуратно спрятал среднюю часть кабеля за лицевую панель в шкафу, закрыл его обратно и где-то затаился? Бред какой-то! :) Да и кому это нужно?
Постояв так некоторое время в легком оцепенении перед открытым шкафом и почесав в затылке (говорят - помогает, производимый таким образом массаж головы стимулирует деятельность головного мозга), я решил полностью вытащить этот кабель из коммутационных стоек и рассмотреть его хорошенько!
Вот - результат моей деятельности:

Обратите внимание на два кабеля, обозначенные красным. Дело в том, что эти именно два разных кабеля! Фирменные патч корды, которые мы используем для коммутации в СКС шкафу достаточно короткие (сантиметров 40), поэтому четко видно, что это не один а два разных патч корда.
Научно доказав себе эту мысль, подключаю две части сетевого тестера к обеим концам висящих кабелей. Но то что я наблюдаю, продолжает категорически не укладываться в понятие нормальности:

Кабель "прозванивается", как один цельный отрезок!
Что это?! Один длиннющий нестандартный патч корд? Я такого у нас никогда не видел, но. все может быть. Подсознательно понимая, что дело не в этом, выясняю куда ведут два скрытых внутри шкафа конца этого кабеля (кабелей)?
Все правильно: к двум (разным) портам на коммутационной патч панели:

Порты под номерами «28» и «32», идущие к рабочим местам пользователей и их сетевым розеткам с такими же номерами.
Пользовательские розетки. В голове забрезжила какая-то мысль и - опа! Мозг "ухватил" ее и вытащил на поверхность! Догадались о чем это я? Кто нет - за мной! Искать на этаже розетки под номером «28» и «32» :)
Находим их через несколько комнат в другом крыле этажа. Три розетки, по два порта в каждой. Часть портов сконфигурирована, как телефонные, а часть - для подключения компьютеров пользователей.

Интересующие нас номера (28 и 32) обведены красным. С виду - все нормально, но, распутав сплетение кабелей на полу, я получил дополнительную порцию адреналина от осознания того, как запросто можно "уложить" сегмент сети!

Интересующий нас кабель обозначен с двух сторон красным, а его центральную часть я (для наглядности) скрутил на полу "бубликом". Это - непрерывный отрезок кабеля, который замыкает между собой коммутационные розетки под номерами «28» и «32», заворачивая, тем самым, передаваемый по сети сигнал в обратную сторону (к коммутатору).
"Петля" или - кольцо в действии! Вот почему, когда мы извлекали из свитча один кабель, то гасли сразу два индикатора и вот почему два разных патч корда на тестере "прозванивались", как один кабель. У нас образовалась петля в сети длиной в пол этажа, проходящая через несколько помещений, не входящая на своем пути ни в один компьютер, но возвращающаяся, в итоге, в тот же свитч, из которого она и вышла.
Большой коллайдер, гоняющий по кольцу никому не нужные данные, заполнившие со временем собой весь сегмент сети и парализовав его работу.
Начинаем разбираться, как такое могло вообще произойти? Кто-то специально закоротил две розетки одним кабелем? Оказывается - нет. Просто тут когда-то стоял компьютер, который переехал на другой стол, а сетевой кабель остался одним концом подключенный в розетку, а другой лежал где-то в куче проводов на полу. С утра один из менеджеров запнулся о телефонный кабель, подключенный к соседней розетке и идущий прямо по полу, так как телефон тоже "переехал", а его кабель нормально укладывать не стали.
Телефонный кабель порвался, клубок кабелей, лежащий на полу под розетками, - разлетелся и в результате все, что подходило по форме и диаметру - было воткнуто тем же менеджером в свободные СКС розетки. Потому что - порядок должен быть в офисе! :) Вот таким естественным образом возникло наше кольцо!
Но, как говорится: "Кто предупрежден, тот - вооружен!". Поэтому я искренне надеюсь что этот материал поможет Вам в будущем, если не избежать, то, по крайней мере, быстро выявить и устранить возникшую петлю в локальной сети. И, коллеги, не очень строго наказывайте своих пользователей, потому что не ведают они что творят и не со зла, а по незнанию совершают админо-неугодные свои действия :)
Петля (или кольцо) в локальной сети это ситуация, при которой часть информации от коммутатора не рассылается по компьютерам, а кочует по двум параллельным маршрутам, как бы замыкающимся в кольцо. Данные при этом бесконечно кружатся по этому кольцу, постепенно увеличиваясь в размерах и забивая весь канал.
Петля является крайне неприятным явлением для локальной сети или её отдельного участка и требует немедленного решения. Для большего понимания простейшая схема петли представлена ниже.

Пример петли в локальной сети
С петлей мне пришлось столкнуться в одной средней размеров конторе по долгу службы. Офис там располагался в видавшем виде здании, по-моему, даже частично или полностью деревянном. Сетевое оборудование было соответствующее, поэтому, когда в один не слишком добрый понедельник мне заявили о медленном Интернете, я, поначалу, не придал этому особого значения. Затем отвалились и Интернет, и 1С.
Поначалу я всё же думал на неисправность коммутатора (тем более, что есть у меня субъективное недоверие к D-link). Количество портов трех 24-портовых коммутаторов для небольшого офиса на 10-15 машин было излишним, и оставалось еще от старых-добрых времен, когда компов в сетке было больше. Для вычисления виновника я по очереди выключал коммутаторы, и смотрел как на это отреагирует сеть. После нахождения нужного мне свича, все пользователи были переведены на оставшиеся два коммутатора, а я стал думать как вычислить нужный мне порт, ведь неисправен мог быть не весь коммутатор. Тогда ко мне и закралась мысль о кольце.
Если бы кольцо не было таким явным, мне пришлось бы помучиться. Дело в том, что я выключил коммутатор, и повторного появления кольца нужно было бы подождать. Потом пришлось бы доставать из портов патч-корды и смотреть на реакцию сети. В целом, всё равно всё свелось бы к схеме, нарисованной выше, с её сетевыми розетками и патч-панелями.
Итак, несколько советов как вычислить петлю в локальной сети:
Причиной создания протокола STP стало возникновение петель на коммутаторах. Что такое петля? Определение петли звучит так:
Петля коммутации (Bridging loop, Switching loop) — состояние в сети, при котором происходит бесконечная пересылка фреймов между коммутаторами, подключенными в один и тот же сегмент сети.
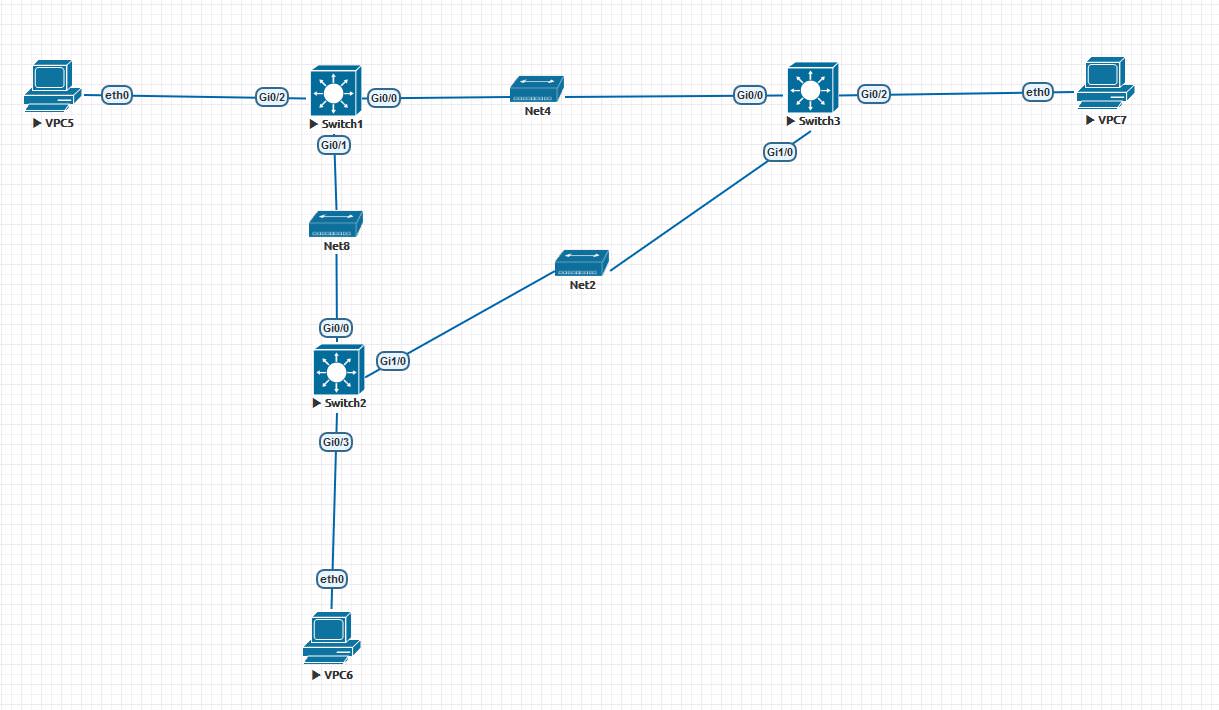
Из определения становится ясно, что возникновение петли создает большие проблемы — ведет к перегрузке свитчей и неработоспособности данного сегмента сети. Как возникает петля? На картинке ниже приведена топология, при которой будет возникать петля при отсутствии каких-либо защитных механизмов:
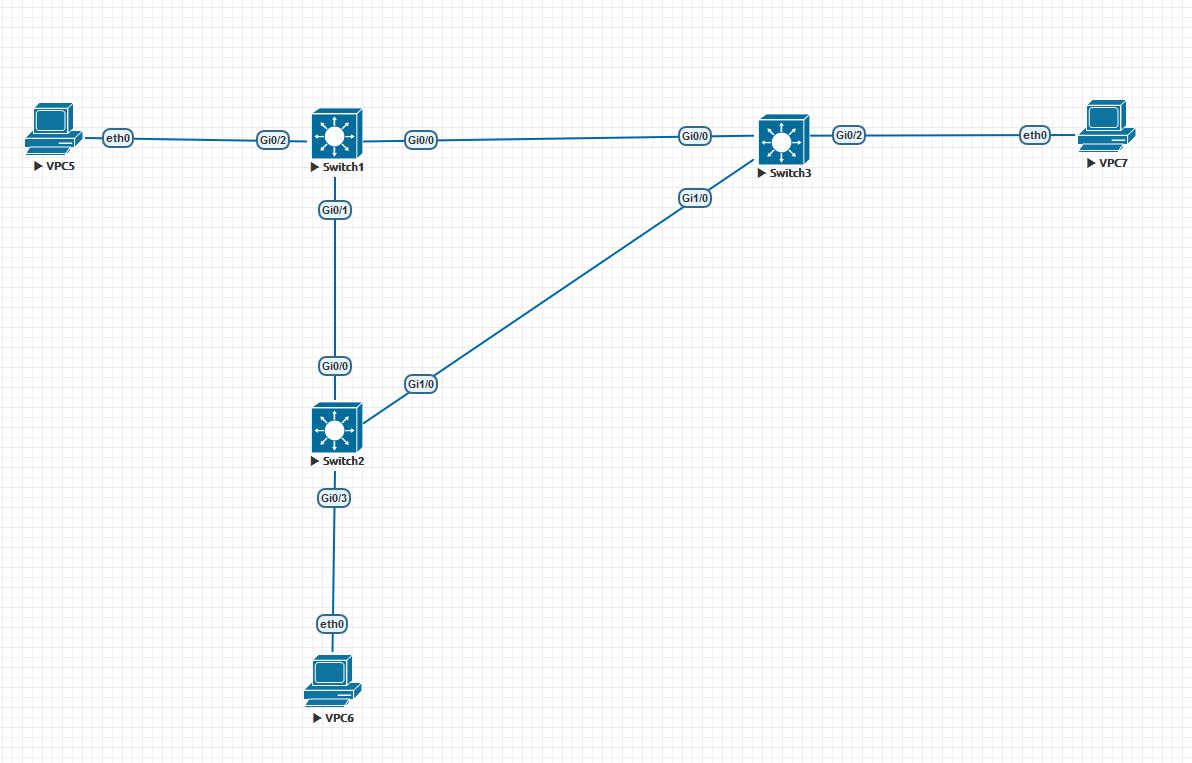
Возникновение петли при следующих условиях:
1. Какой-либо из хостов посылает бродкаст фрейм:
2. Также петля может образоваться и без отправки бродкаст фрейма.
- К примеру, VPC5 отправляет фрейм с юникастовым мак-адресом назначения.
- Возможна ситуация, что мак-адрес назначения отсутствует в таблице мак-адресов коммутаторов. В данном случае, коммутатор будет пересылать пакет через все порты, кроме порта с которого получил данный фрейм. И получаем такую же ситуацию, как и с бродкаст фреймом.
- Ниже мы будем рассматривать протокол STP на коммутаторах Cisco. На них используется STP отдельно для каждого vlan-а, протокол PVST+. У нас всего один vlan, поэтому смысл от этого не меняется.
Основы STP
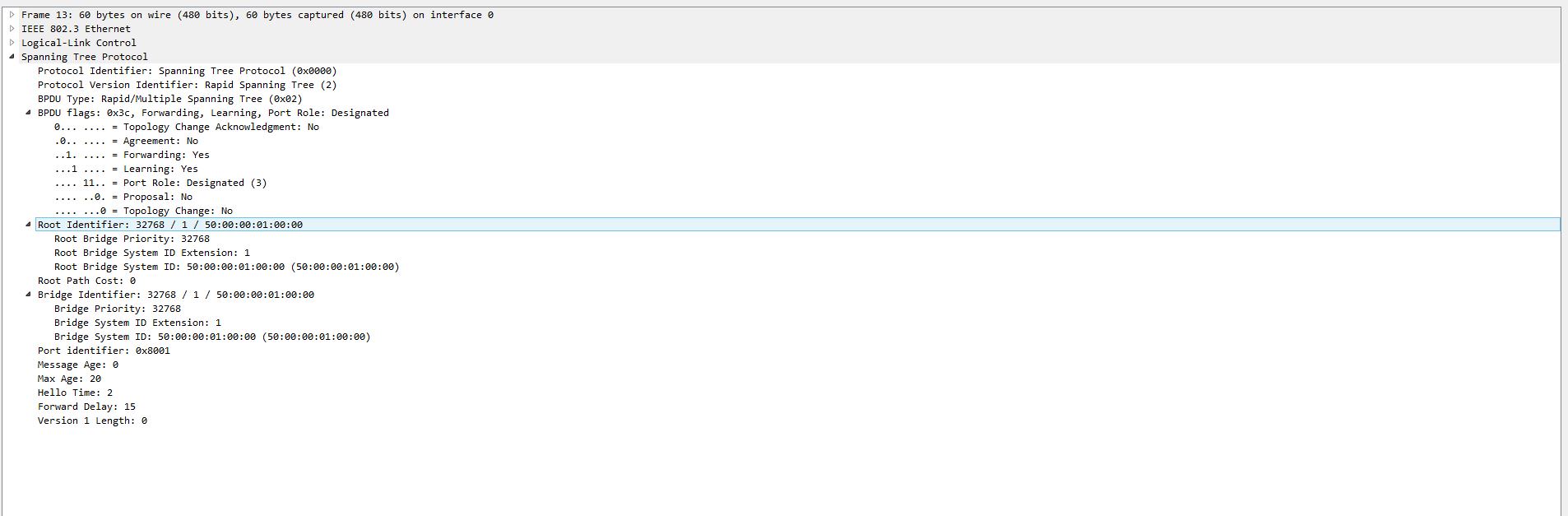
Фрейм BPDU имеет следующие поля:
- Идентификатор отправителя (Bridge ID)
- Идентификатор корневого свича (Root Bridge ID)
- Идентификатор порта, из которого отправлен данный пакет (Port ID)
- Стоимость маршрута до корневого свича (Root Path Cost)
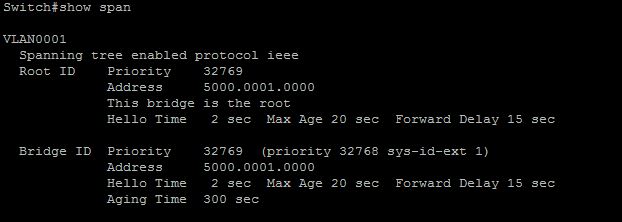
Вот вывод информации о Bridge ID с коммутатора Switch1 из первой картинки. Priority — 32769 ( по умолчанию 32768 + Vlan Id), MAC-адреса — Address 5000.0001.0000:
Представим картину, коммутаторы только включились и теперь начинают строить топологию без петель. Как только коммутаторы загрузились, они приступают к рассылке BPDU, где информируют всех, что они являются корнем дерева. В BPDU в качестве Root Bridge ID, коммутаторы указывают собственный Bridge ID. Например, Switch1 отправляет BPDU коммутатору Switch3, а Switch3 отправляет к Switch1. BPDU от Switch1 к Switch3:

BPDU от Switch3 к Switch1:
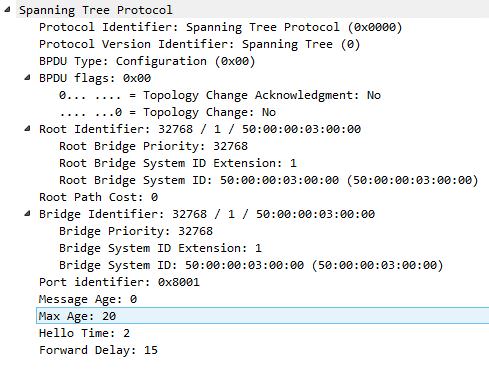
Как видим из Root Identifier, оба коммутотара друг другу сообщают, что именно он является Root коммутатором.
Выбор корневого коммутатора
Блокирование избыточных каналов
Как мы видим из топологии, канал между Switch2 и Switch3 должен быть заблокирован для предотвращения образования петель. Как STP справляется с этим?
После того, как выбран Root Bridge, Switch2 и Switch3 перестают отправлять BPDU через Root Port-ы, но BPDU, полученные от Root Bridge, они пересылают через все свои остальные активные порты, при этом изменив в данных BPDU только следующие поля:
- Идентификатор отправителя (Bridge ID) — заменяется на свой идентификатор.
- Идентификатор порта, из которого отправлен данный пакет (Port ID) — изменяется на идентификатор порта, с которого будет отправлен BPDU.
- Стоимость маршрута до корневого свича (Root Path Cost) — вычисляется стоимость маршрута относительно самого коммутатора.

А Switch3 от Switch2 получает такой BPDU:
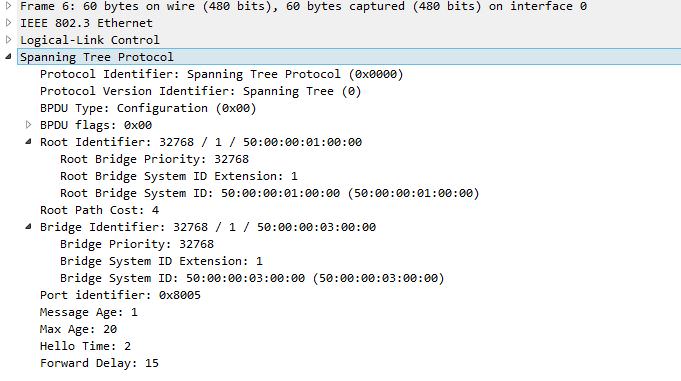
После обмена такими BPDU, Switch2 и Switch3 понимают, что топология избыточна. Почему коммутаторы понимают, что топология избыточна? И Switch2, и Switch3 в своих BPDU сообщают об одном и том же Root Bridge. Это означает, что к Root Bridge, относительно Switch3, существует два пути — через Switch1 и Switch2, а это и есть та самая избыточность против которой мы боремся. Также и для Switch2 два пути — через Switch1 и Switch3. Чтоб избавиться от этой избыточности
необходимо заблокировать канал между Switch3 и Switch2. Как это происходит?
Выбор на каком коммутатоторе заблокировать порт происходит по следующей схеме:
- Меньшего Root Path Cost.
- Меньшего Bridge ID.
- Меньшего Port ID.
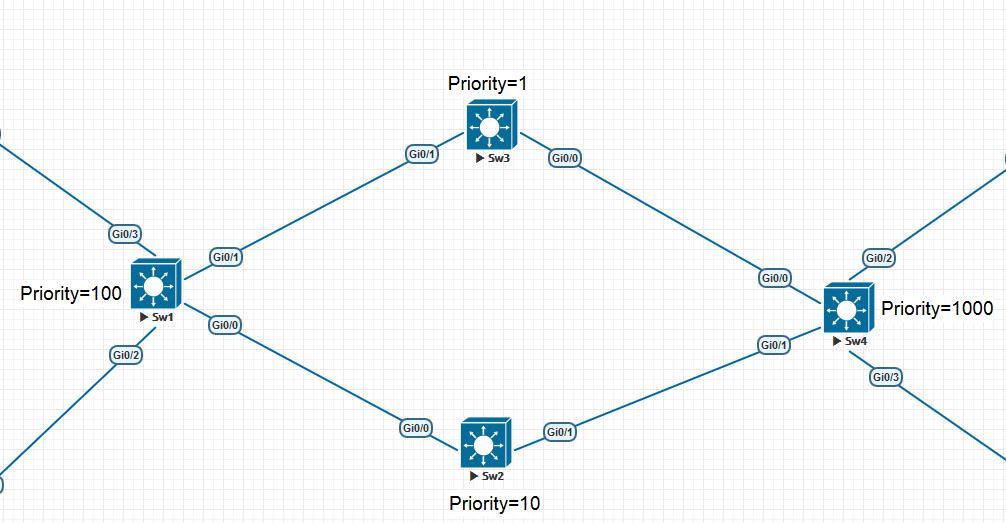
Здесь как оказалось заблокируется порт Gi 0/1 на коммутаторе Sw2. В данном голосовании определяющим становится Root Path Cost. Вернемся к нашей топологии. Так как путь до Root Bridge одинаковый, то в данном выборе побеждает Switch2, так как его priority равны, сравниваются Bridge ID. У Switch2 — 50:00:00:02:00:00, у Switch3 — 50:00:00:03:00:00. У Switch2 MAC-адрес лушче (меньше). После того, как выбор сделан, Switch3 перестает переслать какие-либо пакеты через данный порт — Gi1/0, в том числе и BPDU, а только слушает BPDU от Switch2. Данное состояние порта в STP называется Blocking(BLK). Порт Gi1/0 на Switch2 работает в штатном режиме и пересылает различные пакеты при необходимости, но Switch3 их сразу отбрасывает, слушая только BPDU. Таким образом, на данном примере мы построили топологию без избыточных каналов. Единственный избыточный канал между Switch2 и Switch3 был заблокирован при помощи перевода порта Gi1/0 на Switch3 в специальное состояние блокирования — BLK. Теперь более детально разберем механизмы STP.
Состояния портов
Мы говорили выше, что, например, порт Gi1/0 на Switch3 переходит в специальное состояние блокирования — Blocking. В STP существуют следующие состояния портов:
Blocking — блокирование. В данном состоянии через порт не передаются никакие фреймы. Используются для избежания избыточности топологии.
Listening — прослушивание. Как мы говорили выше, что до того, пока еще не выбран корневой коммутатор, порты находятся в специальном состоянии, где передаются только BPDU, фреймы с данными не передаются и не принимаются в этом случае. Состояние Listening не переходит в следующее даже, если Root Bridge определен. Данное состояние порта длится в течении Forward delay timer, который, по умолчанию, равен 15. Почему всегда надо ждать 15 секунд? Это вызвано осторожностью протокола STP, чтоб случайно не был выбран некорректный Root Bridge. По истечению данного периода, порт переходит в следующее состояние — Learning.
Learning — обучение. В данном состояние порт слушает и отправляет BPDU, но информацию с данными не отправляет. Отличие данного состояния от Listening в том, что фреймы с данными, который приходят на порт изучаются и информация о MAC-адресах заносится в таблицу MAC-адресов коммутатора. Переход в следующее состояние также занимает Forward delay timer.
Forwarding — пересылка. Это обычное состояние порта, в котором отправляются и пакеты BPDU, и фреймы с обычными данными. Таким образом, если мы пройдемся по схеме, когда коммутаторы только загрузились, то получается следующая схема:
- Коммутатор переводит все свои подключенные порты в состояние Listening и начинает отправлять BPDU, где объявляет себя корневым коммутатором. В этот период времени, либо коммутатор остается корневым, если не получил лучший BPDU, либо выбирает корневой коммутатор. Это длится 15 секунд.
- После переходит в состояние Learning и изучает MAC-адреса. 15 секунд.
- Определяет какие порты перевести в состояние Forwarding, а какие в Blocking.
Роли портов
Помимо состояний портов, также в STP нужны определить портам их роли. Это делается для того, чтоб на каком порте должен ожидаться BPDU от корневого коммутатора, а через какие порты передавать копии BPDU, полученных от корневого коммутатора. Роли портов следующие:
Root Port — корневой порт коммутатора. При выборе корневого коммутатора также и определяется корневой порт. Это порт через который подключен корневой коммутатор. Например, в нашей топологии порты Gi0/0 на Switch2 и Switch3 являются корневыми портами. Через данные порты Switch2 и Switch3 не отправляют BPDU, а только слушают их от Root Bridge. Возникает вопрос — как выбирается корневой порт? Почему не выбран порт Gi1/0? Через него ведь тоже можно иметь связь с коммутатором? Для определения корневого порта в STP используется метрика, которая указывает в поле BPDU — Root Path Cost (стоимость маршрута до корневого свича). Данная стоимость определяется по скорости канала.
Switch1 в своих BPDU в поле Root Path Cost ставит 0, так как сам является Root Bridge. А вот, когда Switch2, когда отправляет BPDU к Switch3, то изменяет данное поле. Он ставит Root Path Cost равным стоимости канала между собой и Switch1. На картинке BPDU от Switch2 и Switch3 можно увидеть, что в данном поле Root Path Cost равен 4, так как канал между Switch1 и Switch2 равен 1 Gbps. Если количество коммутаторов будет больше, то каждый следующий коммутатор будет суммировать стоимость Root Path Cost. Таблица Root Path Cost.
Designated Port — назначенный порт сегмента. Для каждого сегмента сети должен быть порт, который отвечает за подключение данного сегмента к сети. Условно говоря, под сегментом сети может подразумеваться кабель, который осуществляет подключение данного сегмента. Например, порты Gi0/2 на Switch1, Switch3 подключают отдельные сегменты сети, к которым ведет только данный кабель. Также, например, порты на Root Bridge не могут быть заблокированы и все являются назначенными портами сегмента. После данного пояснения можно дать более строгое определения для назначенных портов:
Designated Port (назначенный) — некорневой порт моста между сегментами сети, принимающий трафик из соответствующего сегмента. В каждом сегменте сети может быть только один назначенный порт. У корневого коммутатора все порты — назначенные.
Также важно заметить, что порт Gi1/0 на Switch2 также является назначенным, несмотря на то, что данный канал связи заблокированным на Switch3. Условно говоря, Switch2 не имеет информации о том, что на другом конце порт заблокирован.
Nondesignated Port — неназначенный порт сегмента. Non-designated Port (неназначенный) — порт, не являющийся корневым, или назначенным. Передача фреймов данных через такой порт запрещена. В нашем примере, порт Gi1/0 является неназначенным.
Disabled Port — порт который находится в выключенном состоянии.
Таймеры и сходимость протокола STP

TCN был включен в STP, чтоб некорневые коммутаторы могли уведовлять об изменении в сети. Обычными BPDU они этого делать не могут, так как некорневые коммутаторы не отправляют BPDU. Как можно заметить структура TCN не несет в себе никакой информации о том, что именно и где изменилось, а просто сообщает что где-то что-то изменилось. Теперь перейдем к рассмотрению вопроса о сходимости STP.
Посмотрим, что произойдет если мы отключим интерфейс Gi0/1 на Switch1 и посмотрим при помощи каких механизмов перестроится дерево STP. Switch2 перестанет получать BPDU от Switch1 и не будет получать BPDU от Switch3, так как на Switch3 данный порт заблокирован. У Switch2 уйдет 20 секунд ( Max Age Timer ), чтоб понять потерю связи с Root Bridge. До этого времени, Gi0/0 на Switch2 будет находится в состоянии Forwarding с ролью Root Port. Как только истечет Max Age Timer и Switch2 поймет потерю связи, он будет заново строить дерево STP и как это свойственно STP начнет считать себя Root Bridge. Он отправит новый BPDU, где укажет самого себя в качестве Root Bridge через все активные порты, в том числе и на Switch3. Но таймер Max Age, истекший на Switch2 также истек и на Switch3 для интерфейса Gi1/0. Данный порт уже 20 секунд не получал BPDU и данный порт перейдет в состояние LISTENING и отправит BPDU c указанием в качестве Root Bridge — Switch1. Как только Switch2 примет данный BPDU, он перестанет считать себя Root Bridge и выберет в качестве Root Port — интерфейс Gi1/0. В этот момент Switch2 также отправит TCN через Gi1/0, так как это новый Root Port. Это приведет к тому, что время хранения MAC-адресов на коммутаторах уменьшится с 300 секунд до 15. Но на этом работоспособность сети не восстановится полностью, необходимо подождать пока порт Gi1/0 на Switch3 пройдет состояние Listening, а затем Learning. Это займет время равное двум периодам Forward delay timer — 15 + 15 = 30 секунд. Что мы получаем — при потери связи Switch2 ждет пока истечет таймер Max Age = 20 секунд, заново выберает Root Bridge через другой интерфейс и ждет еще 30 секунд пока ранее заблокированный порт перейдет в состояние Forwarding. Суммарно получаем, что связь между VPC5 и VPC6 прервется на 50 секунд. Как было сказано несколькими предложениями выше при изменение Root Port с Gi0/0 на Gi1/0 на Switch2 был отправлен TCN. Если бы этого не произошло, то все MAC-адреса, изученные через порт Gi 0/0, оставались бы привязаны к Gi0/0. Например, MAC-адрес VPC5 и VPC7 несмотря на то, что STP завершит сходимость через 50 секунд, связь между VPC6 и VPC5, VPC7 не была бы восстановлена, так как все пакеты предназначенные VPC5, VPC7 отправлялись через Gi0/0. Надо было бы ждать не 50 секунд, а 300 секунд пока таблица MAC-адресов перестроится. При помощи TCN, время хранение изменилось с 300 секунд до 15 и пока интерфейс Gi1/0 на Switch3 проходил состояния Listening, а затем Learning и данные о MAC-адресах обновятся.
Также интересен вопрос, что произойдет, если мы заново включим интерфейс Gi0/1 на Switch1? При включение интерфейса Gi0/1, он, как и подобает, перейдет в состояние Listening и начнет рассылать BPDU. Как только Switch2 получит BPDU на порту Gi0/0, то сразу перевыберет свой Root Port, так как тут Cost будет наименьшем и начнет пересылать траффик через интерфейс Gi0/0, но нам необходимо подождать пока интерфейс Gi0/1 пройдет состояния Listening, Learning до Forwarding. И задержка будет уже не 50 секунд, а 30.
В протоколе STP также продуманы различные технологии для оптимизации и безопасности работы протокола STP. Более подробно в данной статье рассматривать их не буду, материалы по поводу них можно найти в избытке на различных сайтах.
Читайте также: