
Почему имена файлов размещенных в одном каталоге должны быть уникальными
Обновлено: 06.07.2024
В операционной системе UNIX существуют три базовых понятия: "процесс", "файл" и "пользователь". С понятием " пользователь " мы только что уже столкнулись и будем сталкиваться в дальнейшем при изучении работы операционной системы UNIX . Понятие "процесс" характеризует динамическую сторону происходящего в вычислительной системе, оно будет подробно обсуждаться в лекции 2 и в описании последующих семинаров. Понятие " файл " характеризует статическую сторону вычислительной системы.
Из предыдущего опыта работы с вычислительной техникой вы уже имеете некоторое представление о файле, как об именованном наборе данных, хранящемся где-нибудь на магнитных дисках или лентах. Для нашего сегодняшнего обсуждения нам достаточно такого понимания, чтобы разобраться в том, как организована работа с файлами в операционной системе UNIX . Более подробное рассмотрение понятия " файл " и организации файловых систем для операционных систем в целом будет приведено в лекции 11 и лекции 12, а также на семинарах 11–12, посвященных организации файловых систем в UNIX .
Все файлы, доступные в операционной системе UNIX , как и в уже известных вам операционных системах, объединяются в древовидную логическую структуру. Файлы могут объединяться в каталоги или директории. Не существует файлов, которые не входили бы в состав какой-либо директории. Директории в свою очередь могут входить в состав других директорий. Допускается существование пустых директорий, в которые не входит ни один файл , и ни одна другая директория (см. рис. 1–2.1). Среди всех директорий существует только одна директория , которая не входит в состав других директорий – ее принято называть корневой. На настоящем уровне нашего незнания UNIX мы можем заключить, что в файловой системе UNIX присутствует, по крайней мере, два типа файлов: обычные файлы, которые могут содержать тексты программ, исполняемый код , данные и т.д. – их принято называть регулярными файлами, и директории.
Каждому файлу (регулярному или директории) должно быть присвоено имя. В различных версиях операционной системы UNIX существуют те или иные ограничения на построение имени файла. В стандарте POSIX на интерфейс системных вызовов для операционной системы UNIX содержится лишь три явных ограничения:
- Нельзя создавать имена большей длины, чем это предусмотрено операционной системой (для Linux – 255 символов).
- Нельзя использовать символ NUL (не путать с указателем NULL !) – он же символ с нулевым кодом, он же признак конца строки в языке C.
- Нельзя использовать символ '/' .
От себя добавим, что также нежелательно применять символы "звездочка" – "*" , "знак вопроса" – "?" , "кавычка" – "\"" , " апостроф " – "\`" , " пробел " – " " и " обратный слэш" – "\\" (символы записаны в нотации символьных констант языка C).
Единственным исключением является корневая директория , которая всегда имеет имя "/" . Эта же директория по вполне понятным причинам представляет собой единственный файл , который должен иметь уникальное имя во всей файловой системе. Для всех остальных файлов имена должны быть уникальными только в рамках той директории, в которую они непосредственно входят. Каким же образом отличить два файла с именами "aaa.c" , входящими в директории "b" и "d" на рисунке 1–2.1, чтобы было понятно о каком из них идет речь? Здесь на помощь приходит понятие полного имени файла .
Давайте мысленно построим путь от корневой вершины дерева файлов к интересующему нас файлу и выпишем все имена файлов (т.е. узлов дерева), встречающиеся на нашем пути, например, "/ usr b aaa.c" . В этой последовательности первым будет всегда стоять имя корневой директории, а последним – имя интересующего нас файла. Отделим имена узлов друг от друга в этой записи не пробелами, а символами "/" , за исключением имени корневой директории и следующего за ним имени ( "/usr/b/aaa.c" ). Полученная запись однозначно идентифицирует файл во всей логической конструкции файловой системы. Такая запись и получила название полного имени файла .
Понятие о текущей директории. Команда pwd. Относительные имена файлов
Полные имена файлов могут включать в себя достаточно много имен директорий и быть очень длинными, с ними не всегда удобно работать. В то же время, существуют такие понятия как текущая или рабочая директория и относительное имя файла .
Для каждой работающей программы в операционной системе, включая командный интерпретатор ( shell ), который обрабатывает вводимые команды и высвечивает приглашение к их вводу, одна из директорий в логической структуре файловой системы назначается текущей или рабочей для данной программы. Узнать, какая директория является текущей для вашего командного интерпретатора, можно с помощью команды операционной системы pwd .
Если вам кажется, что нет ничего проще, чем придумать имя для файла или папки, то скорее всего вы ошибаетесь. Существуют правила из-за которых нельзя назвать файл любым именем как обычный физический предмет. Для начала проясним, что такое имя файла, и как оно используется.
Понятия «путь» и «имя файла»
Очень часто в компьютерной литературе используются термины «путь» и «имя файла» под разными значениями. Обычно под словом «путь» понимают адрес или расположение файла, т. е. диск, папка и подпапки в которых расположен файл. Однако Microsoft и другие считают, что в путь к файлу входит не только его расположение но и само имя файла. А некоторые подразумевают под словом «путь» только имена файла и папок, в которых он расположен, без указания диска. Некоторые пользователи полагают, что «имя файла» не включает расширение. В данной статье расширение всегда является частью имени файла. На примере ниже синим цветом выделен путь к файлу, а красным имя файла.
X:\папка\подпапка\ файл.расширение
Зарезервированные символы и имена
Ограничения на длины имен файлов и путей
Существуют ограничения на длину имени файла и на длину пути. Абсолютное ограничение длины имени файла вместе включая путь к нему равно 260 символам. Этот предел называют термином MAX_PATH. На самом же деле на практике пределы для имен еще меньше из-за ряда других ограничений. Например, каждая строка на конце должна содержать так называемый нулевой символ, который обозначает конец строки. Несмотря на то, что маркер конца строки не отображается, он учитывается как отдельный символ при подсчете длины, а значит остается 259 символов доступных для имени файла и пути к нему. Первые три символа в пути используются для обозначения диска (например, C:\). Это уменьшает предел для имен папок, подпапок и файла до 256 символов.
На имя объекта (папки или файла) наложено ограничение длины 255 символов. Этот предел действителен только, если объект не расположен внутри папки. Так как при расположении объекта внутри папки, сумма длин всех папок в которых он расположен, разделителей и имени объекта ограничена 256 символами, то предел длины самого имени объекта меньше 255 символов.
Любая информация во внешних запоминающих устройствах хранится в файлах. Файл – это поименованная область диска или другого машинного носителя. В файлах могут быть размещены некоторые данные, тексты, программы. Имя файла состоит из двух частей – корневого имени и расширения, которые отделяются друг от друга точкой. Корневое имя может содержать до 8 символов, а расширение до трех. Расширение в отличие от корневого имени не является обязательным и указывает тип файла. В имени файла нельзя использовать некоторые символы (см. ниже шаблон имени).
Файлы объединяются по каким-либо признакам в каталоги (синонимы каталогов – директории, папки). В любом каталоге могут быть вложенные каталоги или подкаталоги. Имена файлов и подкаталогов в одном каталоге должны быть уникальными (т.е. разными, несовпадающими). В разных каталогах могут быть файлы и подкаталоги с одинаковыми именами.
 |
Каталоги, как и файлы, хранятся на дисках. Диски обозначаются латинскимибуквами A:, B:, C:, D: и т.д. Буквами A: и B:обозначаются гибкие диски (дисководы для работы с гибкими дисками). ДискиC:, D: и так далее. представляют собой участки жесткого диска («винчестера»). Дополнительно могут быть подключены другие дисководы, например, для лазерных дисков. Каждый дисковод имеет свое имя.
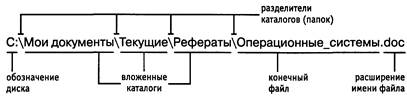
Рис. 2.1 Пример полного имени файла
Структура расположения каталогов на диске – иерархическая, древовидная. На каждом диске на вершине иерархии располагается корневой каталог, обозначаемый символом «\» (обратный слэш). В корневом каталоге располагаются файлы и каталоги 1-го уровня, в каталогах 1-го уровня – каталоги и файлы 2-го уровня и т.д. Для доступа к файлу операционной системе необходимо его полное имя, которое является комбинацией имени диска, пути к файлу (т.е. перечисления имен каталогов, в которые последовательно входит файл, разделенные обратным слэшем) и собственно имени файла (рис. 2.1). Если файл находится на текущем диске и/или в текущем каталоге, то имя диска и/или путь к файлу можно не указывать.

C самых первых проектов, поддерживающих загрузку файлов на сервер, любой программист сталкивается с необходимостью генерации уникальных случайных имён для загруженных файлов. Рассмотрим несколько вариантов решения данной проблемы.
Предположим, мы должны сохранять все файлы в одну папку. Чтобы файлы не повторялись и чтобы не возникало проблем с кириллицей нам лучше давать им уникальные имена вида
Самый лёгкий вариант – это использование встроенной в PHP функции uniqid():
Эта функция вернёт случайную 13-символьную строку. Если же нужно делать имена длиннее, то можно использовать функции вычисления хэша от случайной строки:
Функция md5() генерирует 32-символьную строку. Можно, конечно использовать любую другую функцю. При желании можно установить любую длину от 1 до 32 обрезав md5-хэш функцией substr() :
Если нужно хранить файл с расширением, то его расширение можно легко приписывать к идентификатору:
Это простые способы, но у них есть один недостаток: уникальность имени не контролируется, а следовательно имеется вероятность перезаписи старого файла при случайной генерации такого же имени для нового файла. И эта вероятность тем выше, чем больше файлов сохранено.
Чтобы избежать перезаписи нам необходимо проверять папку на отсутствие такого же файла. Напишем функцию, избавленную от этого недостатка:
Здесь в постусловии цикла осуществляется проверка на существование файла. Если файл с таким именем уже есть, то генерируется следующее имя. Вместо md5(microtime() . rand(0, 9999)) для генерации идентификатора можно использовать любой вариант из разобранных выше.
Рассмотрим пример загрузки изображения с использованием данной функции:
В Yii для получения расширения удобно пользоваться объектом $file класса CUploadedFile :
С помощью функции DFileHelper::getRandomFileName() мы генерируем уникальное имя файла для папки upload/images и используем это имя для загрузки. Теперь файлы никогда не перезапишутся, так как имена никогда не совпадут.
Не пропускайте новые статьи, бонусы и мастер-классы:
Недавно на Deworker провели большой стрим с планами по записи и перезаписи скринкастов на новый рабочий сезон этого и следующего года. Спасибо всем за ваши предложения по контенту! С вами мы сделали наши видео лучше, чем изначально планировали.
Все видеозаписи уроков обработаны, тайм-коды проставлены, вопросы отвечены. Наш самый крупный четырёхмесячный мастер-класс по Symfony завершён. Вот что у нас с вами получилось.
В комментариях к записи о HTML Purifier был задан вопрос о том, каким образом можно переделать внешние адреса на переход через промежуточную страницу на своём сайте. Сделаем функционал, обрабатывающий внешние ссылки в тексте и переадресующий их на страницу подтверждения перехода на другие сайты.
Довольно часто возникает необходимость проследить время исполнения некоторых фрагментов программного кода и отследить особо медленные участки для их последующей оптимизации. Имеющиеся отладочные расширения не проникают внутрь ваших файлов, а чаще выводят только общее время выполнения скрипта. Для локального рефакторинга и оптимизации они не подходят.
С микротаймом и мд5, коллизии никогда не будет по 1 простой причине :)
В одной папке есть лимит количества файлов, после которого просто система заглохнет читать папку, а удалять файлы в такой папке будет пыткой даже для СИшных приложений и будет очень дорогостоящей операцией для системы.
Увы, но это не причина.
Не знаю, правильно, или нет, но так в одной папке много не скопится :)
И такой вопрос: а если надо сохранить имена файлов (ещё и на русском языке)? Сервер корёжит имена при загрузке.
Да, кстати, лучше создавать папки по дате. Так многие CMS делают (тот же WordPress).
И касательно имён: можно хранить имя в ещё одной ячейке, а файлы отдавать через x-sendfile в Nginx с передачей оригинального имени.
Я делал проще с использованием TIME():
Статья вводит бедных юниоров в заблуждение. Для действительного случайного имени нужно использовать tempnam, а не указанный код.
Увы, эта функция не припишет к имени файла расширение. После конкатенации расширения её также придётся оборачивать в этот же цикл do-while.
И зачем ему расширение?
Очень прошу, поменяйте хотя бы для первых блоков (с uniqid и md5(microtime)) описание, допишите, что этот способ использовать _нельзя_. Ну открывают же и копируют, не глядя.
А Вы изображения без расширений загружаете?
В Yii2 есть методы:
Для тех кто не любит MD5.
Посмотрел на код нашего юниора, который использует эту замечательную статью, вскрылся очередной косяк:
// Генерируем уникальное имя файла с этим расширением
$filename = DFileHelper::getRandomFileName($path, $extension);
// ВОТ ТУТ ДРУГОЙ ПРОЦЕСС СОЗДАЕТ ФАЙЛ С ТАКИМ ЖЕ ИМЕНЕМ
// Собираем адрес файла назначения
$target = $path . '/' . $filename . '.' . $extension;
// Загружаем
move_uploaded_file($_FILES['image']['tmp_name'], $target);
// ОПА - А ТАКОЙ ФАЙЛ УЖЕ ЕСТЬ
Слушайте, ну уберите статью, ну пожалуйста. Она не имеет абсолютно никакого смысла и только запутывает людей. Пожалуйста, посмотрите в исходниках PHP, как работает tempnam (подсказка: через mkstemp), посмотрите, что такое mkstemp и как она отличается от mktemp. В качестве бонуса попробуйте осознать понятия "атомарность" и "параллельное выполнение".
Ваша статья в гугле висит на первых местах и несёт страдание в этот мир.
Да запросто. Если подскажете, как сгенерировать случайное имя с расширением – удалю.
Да хотя бы переработайте свой же код, чтобы он не просто пытался сгенерировать случайное имя файла, а пытался _создать_ файл со случайным именем до тех пор, пока у него это не получится, будет значительно лучше.
В простой генерации случайного несуществующего имени практического смысла мало - кроме гарантии, что _на момент_ генерации имени такого файла не существовало, больше никаких гарантий нет. А это достаточно бестолково :)
Переработал ещё позавчера.
Иначе с цикла мы выйдем когда найдем файл с таким же именем? что нам как раз не нужно
Нет. Наоборот. Это цикл while, а не until.
Да, ошибся, сорри
С интересом читаю все ваши статьи, но относительного правильности способа генерации уникального имени файла, который изложен в этом материале, возникают сомнения.
Все, что делает статический метод DFileHelper::getRandomFileName() - это генерирует уникальное (на момент генерации) имя файла в рамках заданной директории.
Однако, представим, что с приложением параллельно работают несколько клиентов (клиент1 и клиент2):
Клиент1 вызывает метод getRandomFileName() - генерируется уникальное имя;
Клиент2 вызывает этот же метод с некоторым запозданием, но еще до вызова Клиентом1 метода, который запишет файл в директорию.
В этой ситуации может произойти такое, что и для Клиента1, и для Клиента2 будет создано одно и тоже "уникальное" имя, но Клиент2 не узнает об этом, поскольку Клиент1 еще не произвел запись файла в каталог, а ведь лишь после этого метод file_exists() сможет определить, что файл с таким именем уже существует в директории.
Считаю, что после генерации уникального имени необходимо сразу же записывать файл в директорию (пустой) и после этого возвращать, действительно уникальное имя клиенту.
Сейчаc от этого спасает только rand(0, 9999) в имени, что даёт крайне малую верятность этого события:
Можно повысить верхний предел до миллиона, что снизит возможность совпадения до одной миллионной.
Но всё равно создание пустого файла не спасёт, так как это «сразу же» тоже не будет мгновенным.
А разве так не надежнее будет?
чтобы исключить возможность ошибки надо просто содать отдельную дирректорию для файлов пользователя с именем ID
Я пользуюсь алгоритмом генерации файлов как у автора, только не проверяю директорию на наличие такого файла уже, какова вероятность что два файла записанные в разное время будут иметь одинаковый хеш?, плюс ко всему у меня у каждого юзера своя папка с файлами, название которой соответствуют id юзера, который уникальный в системе.
Вопрос, какова вероятность перезаписи файла в моем случаи, я хеш не обрезаю вообще
Значит в Вашем случае способ, предложенный автором, используется просто как генератор имени файла.
Если Вы не проверяете директорию на наличие в ней файла с именем, которое было сгенерировано для записи нового файла - вероятность перезаписи существует, как если бы файлы записывались "в разное время", так и одновременно, т.к. в md5 могут быть коллизии.
Читайте также: