
Похоже файлу robots txt не назначены подходящие правила перезаписи
Обновлено: 04.07.2024
Файл robots.txt — это инструкция для поисковых роботов. В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots.txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
- Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
- Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы. Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
- Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
- Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
Советы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой. Это необходимо, чтобы не возникало путаницы и каждому роботу не нужно было сканировать весь документ в поисках подходящих инструкций. Если правила сгруппированы и разделены пустой строкой, робот находит нужную строку User-agent и следует директивам. Пример:
Учитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots.txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Это значит, что нельзя писать Disallow: /cgi-bin/ /authors/ /css/ (указаны три папки в одной строке). Для каждой нужно прописывать свою директиву Disallow:
Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots.txt. Поэтому файл необходимо проверять дважды: и в Яндекс, и в Google.
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
Чтобы проверить robots.txt с помощью валидатора Яндекс:
Выберите в левом меню раздел Инструменты → Анализ robots.txt.Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:


Чтобы сделать проверку с помощью Google:

Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.

Проверка robots.txt Google не выявила ошибок
Перечень ошибок, возникающих при анализе файла robots.txt .
Правило может начинаться только с символа / или *.
Допускается только одно правило такого типа.
Количество правил в файле превышает 2048.
Правило должно всегда следовать за директивой User-agent. Возможно, файл содержит пустую строку после User-agent.
Правило превышает допустимую длину (1024 символа).
В директиве Clean-param указывается один или несколько параметров, которые робот будет игнорировать, и префикс пути. Параметры перечисляются через символ & и отделяются от префикса пути пробелом.
Правило может начинаться только с символа / или *.
Допускается только одно правило такого типа.
Количество правил в файле превышает 2048.
Правило должно всегда следовать за директивой User-agent. Возможно, файл содержит пустую строку после User-agent.
Правило превышает допустимую длину (1024 символа).
В директиве Clean-param указывается один или несколько параметров, которые робот будет игнорировать, и префикс пути. Параметры перечисляются через символ & и отделяются от префикса пути пробелом.
Предупреждения
Перечень предупреждений, возникающих при анализе файла robots.txt .
Обнаружен спецсимвол, отличный от * и $.
Обнаружена директива, не описанная в правилах использования robots.txt. Возможно, эта директива используется роботами других поисковых систем.
Строка не может быть интерпретирована как директива robots.txt .
При анализе файла возникла неизвестная ошибка. Обратитесь в службу поддержки.
Обнаружен спецсимвол, отличный от * и $.
Обнаружена директива, не описанная в правилах использования robots.txt. Возможно, эта директива используется роботами других поисковых систем.
Строка не может быть интерпретирована как директива robots.txt .
При анализе файла возникла неизвестная ошибка. Обратитесь в службу поддержки.
Ошибки проверки URL
Перечень ошибок проверки URL в инструменте Анализ robots.txt .
Ошибка синтаксиса URL.
Заданный URL не принадлежит сайту, для которого производится анализ файла. Возможно, вы указали адрес одного из зеркал вашего сайта или допустили ошибку в написании имени домена.
Ошибка синтаксиса URL.
Заданный URL не принадлежит сайту, для которого производится анализ файла. Возможно, вы указали адрес одного из зеркал вашего сайта или допустили ошибку в написании имени домена.

Постараемся в этой статье ответить на вопрос о том, что такое правильный robots.txt и как провести настройку этого файла. В общих чертах, его назначение в том, чтобы оптимизировать процесс краулинга.
Поисковые системы регулярно считывают содержимое каждого сайта для того, чтобы индексировать актуальные страницы и материалы. Robots.txt указывает краулерам, какие разделы сайта нужно просматривать, а какие — нет. С его помощью повышается эффективность процесса — поисковая система обрабатывает сайт быстрее и запоминает релевантную информацию. Не стоит путать это с ускорением загрузки сайта. Впоследствии, когда пользователи будут делать запросы, они увидят ваш сайт в выдаче, в частности, благодаря правильной настройке Robots.txt.
Чтобы анализировать конверсии при изменениях в robots.txt, рекомендуем установить аналитику:
Наши продукты помогают вашему бизнесу оптимизировать расходы на маркетингЧто такое robots.txt
Robots.txt для сайта — это служебный файл-рекомендация. Он формирует исключения и запреты для поисковых алгоритмов, взаимодействующих с сайтом. Эти запреты не допускают индексации определенных разделов или содержимого сайта, позволяют увидеть алгоритмам только нужные элементы.
Для чего используется Robots.txt
Данный файл говорит краулерам и роботам, какие страницы сайта они должны просматривать, а к каким доступ запрещён. Это важно в связи с тем, что случайно могут быть проанализированы страницы с нерелевантным контентом. В некоторых случаях есть риск запустить бесконечный цикл считывания — например, с календарём, который генерирует новый URL для каждой даты.
Как говорится в спецификации robots.txt для Google , правильный robots.txt должен являться текстовым файлом в кодировке ASCII или UTF-8. Строки или иначе — директивы — должны отделяться типами прерывания CR, CR/LF или LF.
Обращайте внимание на размер файла, так как у каждой поисковой системы свой лимит. Google читает robots.txt не более 500 Кб, а Яндекс посчитает всё содержимое открытым, если файл весит больше 32 Кб.
Где должен располагаться Robots.txt
Когда используются правила robots.txt
На самом деле веб-сайтам не стоит полагаться на robots.txt в целях контроля краулинга. В первую очередь стоит позаботиться об архитектуре сайта и о том, чтобы сделать его более доступным для поисковых роботов, очистив от всего лишнего. Тем не менее, если на сайте работают плохо оптимизированные разделы, которые лучше скрыть от глаз пользователей, и эти проблемы не устранимы в обозримой перспективе, robots.txt будет правильным решением.
Google рекомендует использовать данный файл только в целях оптимизации работы поискового робота. Иногда чтение плохо индексируемых разделов затягивается.
Вот некоторые примеры страниц и разделов, индексация которых нежелательна:
Когда не стоит прибегать к robots.txt
При грамотном использовании данный файл несёт пользу, но есть ситуации, в которых его применение в целях блокировки краулинга только мешает.
Блокировка Javascript/CSS
Поисковым системам необходим доступ ко всем ресурсам, чтобы корректно рендерить страницы — это необходимая часть ранжирования. Если же, к примеру, Javascript, оказывающий подчас определяющее влияние на функционал страницы и пользовательский опыт отключен, это может привести к плохим результатам вплоть до понижения в выдаче.
Например, если ваша страница содержит редиректы с помощью Javascript, а тот, в свою очередь, закрыт от индексации, робот распознает в таком перенаправлении клоакинг — подмену страницы.
Блокировка по URL
Robots.txt можно использовать для блокировки URL со специфическими параметрами, но это далеко не всегда верное решение. Правильная настройка robots,txt предполагает использование Google Search Console — такой способ будет приемлем с точки зрения поисковых систем.
Блокировка URL с обратными ссылками
Если обратные ссылки запрещены robots.txt, поисковый робот не сможет перейти по ссылкам с других сайтов на ваш ресурс. Из-за этого ваш сайт не получит баллов ранжирования и опустится в выдаче.
Установка правил против краулеров соцсетей
Даже если вы не хотите, чтобы поисковые системы читали ваши страницы, возможно, доступ роботов соцсетей не помешает. Ведь они формируют сниппеты в случае репоста ваших страниц в соцсети. Например, Facebook будет пытаться зайти на каждую страницу, которую постят в нём, чтобы отображать релевантный сниппет.
Блокировка доступа к сайтам в процессе разработки
Использование robots.txt для блокировки всего сайта в процессе разработки хорошо работает. В то же время, Google рекомендует убирать из индексации страницы, но давать возможность роботу их читать. В целом же, следует делать такие сайты недоступными для посещения вообще.
Когда нечего блокировать
Некоторые сайты с весьма чистой архитектурой не испытывают потребности в блокировке каких-либо разделов. В такой ситуации вообще можно не создавать robots.txt, а возвращать страницу 404.
Эффективный маркетинг с Calltouch
- Анализируйте воронку продаж от показов рекламы до ROI от 990 рублей в месяц
- Отслеживайте звонки на сайте с точностью определения источника рекламы выше 96%
- Повышайте конверсию сайта на 30% с помощью умного обратного звонка
- Оптимизируйте свой маркетинг с помощью подробных отчетов: дашборды, графики, диаграммы
- Добавьте интеграцию с CRM и другими сервисами: более 50 готовых решений
- Контролируйте расходы на маркетинг до копейки
Как создать robots.txt
Создать файл можно тремя способами, выбор зависит от целей и навыков. Сервисы облегчают работу с robots.txt, но ручная коррекция все-таки потребуется. Поэтому для каждого варианта, хоть и в разной степени, придется самостоятельно разобраться с темой или обратиться к специалисту.
Ручное создание
Файл robots.txt можно создать в любом текстовом редакторе, например, в Блокноте и Microsoft Word. В документе прописывают специальный код-инструкцию, в нем указывают, какие элементы не подлежат индексации. После этого его сохраняют в формате.txt под названием «robots».
Готовый текстовый документ загружается в корневую папку с названием сайта, где находится файл index.html и файлы базового движка. Чтобы загрузить robots.txt на сервер, используют:
- панель управления сервером;
- консоль или пульт управления в CMS;
- любой FTP-клиент.
Система каждый раз будет обращаться к роботу, чтобы понять, что можно индексировать на сайте, а что нет.
Онлайн-генераторы
Специальные сервисы помогут автоматически сгенерировать нужный файл, например, такой инструмент есть на сайте CY-PR . Генераторы облегчают работу тем, кто владеет сразу несколькими сайтами, так как прописывать характеристики для каждого достаточно долго. Автоматизация упростит процесс, но корректировать автоматически сгенерированные файлы придется вручную. Чтобы устранять возможные ошибки, нужно изучить базовый синтаксис robots.txt.
Готовые шаблоны
В интернете представлено много шаблонов файла robots.txt, которые подходят для всех популярных движков (WordPress, Drupal). В шаблоне прописаны стандартные директивы, поэтому файл не нужно создавать полностью вручную.
Если учесть индивидуальные особенности проекта, на его основе можно сделать качественный robots.txt. Но для этого тоже необходимы хотя бы минимальные знания синтаксиса, потому что шаблон не может предоставить корректно настроенный, готовый к работе, файл.
Синтаксис robots.txt
Как настроить robots.txt? Примерно так может выглядеть блок robots.txt, ориентированный на Google.

Комментарии
Указания User-agent
Это блок, который даёт указания поисковым системам и роботам, используя директиву User-agent . Например, если вы хотите установить правила отдельно для Яндекса и Google. Тем не менее, он не применим для Facebook и рекламный сетей — на них можно повлиять только через специальный токен с применением особых правил.
Каждый робот предусматривает собственный user-agent токен.
Краулеры сперва учитывают наиболее точные директивы, разделённые дефисом, а затем переходят к объемлющим. Так, Googlebot News сначала выполнит указания для User-agent «googlebot-news», а потом уже «googlebot» и впоследствии «*».
Наиболее распространённые роботы в российском сегменте — это:
- Googlebot
- Mediapartners-Google
- Yandex
Конечно, этот список далеко не исчерпывающий. Чтобы ознакомиться с полным перечнем используемых поисковиками и другими системами роботов, лучше прочитайте их документацию.
Наименования роботов в robots.txt нечувствительны к регистру. «Googlebot» и «googlebot» вполне взаимозаменяемы.
Шаблоны адресов
Вместо того, чтобы прописывать большой перечень конечных URL для блокировки, достаточно указать только шаблоны адресов.
Для эффективного использования такой функции понадобится два знака:
- * — данный символ группировки обозначает любое количество символов. Его лучше располагать в начале или внутри адреса, но не в конце. Можно использовать сразу несколько групповых символов — например, «Disallow: */notebooks?*filter=». Правила с полными адресами не должны начинаться с данного символа.
- $ — знак доллара означает конец адреса. Так, «Disallow: */item$» будет соответствовать URL, заканчивающемуся на «/item», но не «/item?filter» или подобным.
Обратите внимание, что эти правила уже чувствительны к регистру. Если вы запрещаете адреса с параметром «search», роботы всё ещё будут просматривать адреса, содержащие «Search».
Пока вы не добавите * или / в начало директивы, она не будет ничему соответствовать. «Disallow: start» не будет иметь смысла — роботы её не поймут.
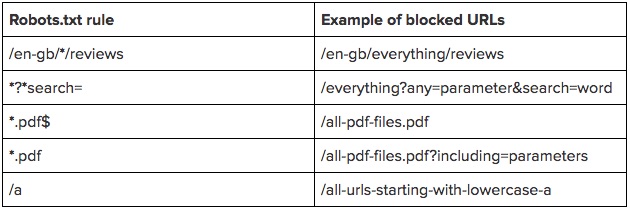
Чтобы наглядно продемонстрировать правило, приведём таблицу примеров:
Sitemap.xml
Директива Sitemap в robots.txt говорит поисковикам, где найти карту сайта в формате XML. Это поможет им лучше ориентироваться в структуре страниц.
Поисковые роботы прочитают указанные в robots.txt карты сайтов, но они не появятся в том же Google Search Console, пока вы не дадите на это разрешение.
Этот элемент раньше работал исключительно как инструкция для Яндекса, другим поисковым системам она была непонятна. Он указывал роботу Яндекса на главное зеркало сайта, и система рассматривала его в приоритетном порядке.
Директива Host уже не поддерживается Яндексом, решение об этом было принято еще в 2018 году. Теперь вместо нее схожий функционал выполняет раздел «Переезд сайта», доступный в Яндекс.Вебмастере.
Блоки в robots.txt
Директива Disallow в robots.txt может использоваться по-разному для многих агентов. Покажем, каким образом могут быть представлены разные комбинации блоков.
Важно помнить, что robots.txt — это всего-навсего набор рекомендаций. Вредоносные краулеры проигнорируют этот файл, прочитав то, что захотят, поэтому бессмысленно использовать robots.txt в качестве меры защиты.
Несколько блоков User-Agent
Вы можете назначить правило сразу нескольким роботам, указав их в начале. Например, следующая директива Disallow будет работать как для Яндекса, так и для Google.

Пустые строки между блоками
Поисковые системы игнорируют пустые строки между директивами. Даже если одна директива будет отделена таким образом от предыдущей, робот всё равно её прочитает.

В следующем примере сразу два робота будут руководствоваться одним правилом.

Комбинация отдельных блоков
Разные блоки, в которых указан один и тот же агент, будут учитываться. Таким образом, Google не станет читать оба раздела, указанных в файле.

Директива Allow
Эта директива даёт доступ к указанному разделу. Вообще она действует по умолчанию, но может применяться для отмены ранее поставленного правила Disallow для вложенного раздела. Если вы запретили доступ к «/notebooks», а затем указали директиву «Allow: /notebooks/gamers», то директория /notebooks/gamers окажется читаема для краулеров, даже с учётом того, что вышестоящая запрещена к просмотру.
Приоритеты в robots.txt
Если указано несколько правил Allow и Disallow, роботы обращают внимание на те, у которых больше длина в знаках. Рассмотрим пример пути «/home/search/shirts»:

В этом случае весь путём разрешён к чтению, так как директива Allow содержит 9 знаков, а Disallow — максимум 7. Если вам нужно обойти это правило, то для увеличения длины строки можно добавлять * .

Если длина Allow и Disallow совпадает, то приоритет отдаётся Disallow.
Директивы robots.txt
Директивы robots.txt помогают снизить затраты ресурсов на краулинг. Вы упредительно добавляете правила в robots.txt вместо того, чтобы ждать, пока поисковые системы считают все страницы, а затем предпринимать меры. Такой подход гораздо быстрее и проще.
Следующие директивы работают аналогично Allow и Disallow, используя символы * и / .
Noindex
Директива Noindex полезна для повышения точности индексирования. Disallow никак не избавляет от необходимости индексации указанную страницу, в то время как Noindex позволяет убрать страницу из индекса.
Но тот же Google официально не поддерживает директиву Noindex — ситуация может измениться со дня на день. В подобной неопределённости лучше использовать данный инструмент для решения краткосрочных задач, как дополнительную меру, но не основное решение.

Помимо Noindex Google негласно поддерживает и ряд других директив, размещаемых в robots.txt. Важно помнить, что не все краулеры поддерживают эти директивы, и однажды они могут перестать работать. Не стоит на них полагаться.
Что нужно исключать из индекса
Правильный robots.txt не должен содержать:
Кириллица в файле Robots
Советы по использованию операторов
Есть несколько операторов, наиболее распространенными из которых считаются: * и $. Они позволяют:
Файлы Robots.txt — это инструмент, ограничивающий для сканеров поисковых систем доступ к определенным страницам сайта. В этой статье мы поделимся рекомендациями, касающиеся файла robots.txt.
Что такое файл Robots.txt?
Файл robots.txt сообщает поисковым роботам, какие веб-страницы сайта они могут просматривать. Бот поисковой системы (например, Googlebot) читает файл robots.txt перед началом сканирования вашего сайта, чтобы узнать, с какими веб-страницами он должен работать.
Вот так выглядит файл robots.txt.

Когда боты и другие сканеры попадают на сайт, они могут использовать большой объем серверных мощностей. Это может замедлить ваш сайт. Robots.txt решает эту проблему.
Ниже приведен пример файла Robots.txt от Google , в котором для Googlebot заблокирован доступ к определенным каталогам, разрешен доступ к /directory2/subdirectory1/. Но для других сканеров заблокирован весь сайт.

Пользовательские агенты перечислены в «группах». Каждая группа указана в отдельных строках по типу сканера. Она содержит перечень файлов, к каким он может и не может получить доступ.
Почему файлы Robots.txt важны?
Информирование поискового сканера о том, какие страницы сайта нужно сканировать, а какие нет, позволяет лучше контролировать краулинговый бюджет сайта, направляя поисковых роботов к наиболее важным его страницам.
Файла robots.txt также позволяет избежать перегрузки сервера сайта разнообразными запросами. Например, в приведенном выше примере robots.txt есть файлы, которые хранятся в папке /cgi-bin. Их блокировка в Robots.txt дает сканерам понять, что в этой папке нет ресурсов, которые нужно индексировать.
Предупреждение: веб-страницы, заблокированные в robots.txt, могут отображаться в результатах поиска Google , но без описания.

Чтобы предотвратить отображение URL-адреса в результатах поиска Google, необходимо защитить файлы на сервере паролем, использовать метатег noindex или заголовок ответа.
Если веб-страницы заблокированы для сканирования в robots.txt, то любая информация об индексировании или служебных директивах не будет найдена и будет игнорироваться.
Поисковым роботам следует разрешить сканировать важные ресурсы, необходимые для отображения содержимого страниц сайта.
Рекомендованные практики Google для файлов Robots.txt
1. Блокировать определенные веб-страницы
Файл Robots.txt можно использовать для блокирования доступа поисковых сканеров к определенным веб-страницам сайта.
2. Медиа-файлы
Используйте файл robots.txt для предотвращения отображения в поисковой выдаче изображений, видео и аудио файлов. Но это не помешает другим веб-страницам или пользователям ссылаться на эти ресурсы. Если другие веб-страницы или сайты ссылаются на этот контент, он все равно может появиться в результатах поиска.
3. Файлы ресурсов
Используйте robots.txt, чтобы заблокировать второстепенные ресурсы. Но если их отсутствие затрудняет понимание краулером конкретных веб-страниц, то не следует их блокировать.
Как работать с атрибутами Noindex
Google не рекомендует добавлять в файл robots.txt директиву noindex, потому что она будет игнорироваться. Вместо этого используйте одно из следующих решений:
1. Метатег Robots: <meta name=«robots» content=«noindex» />
Приведенный выше пример тега указывает поисковым системам не показывать веб-страницу в результатах поиска. Значение атрибута name= «robots» указывает, что директива применяется ко всем сканерам. Чтобы обратиться к определенному сканеру, замените значение robots атрибута name на имя сканера.
Совет: данный метатег должен указываться в разделе <head>. Если нужно заблокировать определенные страницы сайта от сканирования или индексации, используйте директиву no index .
Чтобы использовать одновременно несколько директив, их нужно указать через запятую.
14 распространенных проблем с Robots.txt
1. Отсутствует файл Robots.txt
Возможная причина проблемы: Файла robots.txt повышает уровень контроля над контентом и файлами сайта, которые может сканировать и индексировать поисковый бот. Его отсутствие означает, что Google будет индексировать весь контент сайта.
2. Добавление строк Disallow для блокировки конфиденциальной информации
Добавление строки Disallow в файл robots.txt также представляет собой угрозу безопасности. Так как определяет, где хранится закрытый от пользователей контент.
В чем проблема: Используйте проверку подлинности на стороне сервера, чтобы заблокировать доступ к личному контенту.
3. Добавление Disallow для предотвращения дублирования контента
Сайты должны быть просканированы, чтобы определить их канонический индекс. Не блокируйте содержимое с помощью robots.txt вместо canonical.
В чем проблема: В некоторых CMS достаточно сложно добавлять пользовательские теги canonical. В этом случае можно попробовать другие методы.
4. Добавление Disallow для кода, размещенного на стороннем сайте
Чтобы удалить контент со стороннего сайта, вам необходимо связаться с его владельцем.
В чем проблема: Это может привести к ошибке, когда сложно определить исходный сервер для конкретного контента.
5. Использование абсолютных URL-адресов
Директивы в файле robots.txt (за исключением «Sitemap:») действительны только для относительных путей.
В чем проблема: Сайты с несколькими подкаталогами могут использовать абсолютные адреса, но действительны только относительные URL.
6. Robots.txt размещен не в корневой папке сайта
Файл Robots.txt должен быть размещен в самом верхнем каталоге сайта.
В чем проблема: Не помещайте файл robots.txt в какую-либо другую папку.
7. Обслуживание разных файлов Robots.txt
Не рекомендуется обслуживать различные файлы robots.txt в зависимости от агента пользователя или других атрибутов.
В чем проблема: сайты всегда должны использовать один и тот же файл robots.txt для международной аудитории.
8. Добавлена директива для блокировки всего содержимого сайта
Часто владельцы сайтов оставляют файл robots.txt, который может содержать строку disallow, блокирующую все содержимое сайта.
В чем проблема: Это происходит, когда на сайте используется версия robots.txt по умолчанию.
9. Добавление ALLOW вместо DISALLOW
На сайтах не обязательно указывать директиву allow. Директива allow позволяет переопределять директивы disallow в том же файле robots.txt.
В чем проблема: В случаях, когда директивы disallow похожи, использование allow может помочь в добавлении нескольких атрибутов, чтобы их различать.
10. Неверное расширение типа файла
В разделе справки Google Search Console рассказывается, как создавать файлы robots.txt . После того, как вы создали этот файл, можно будет проверить его с помощью тестера robots.txt .
В чем проблема: Файл должен иметь расширение .txt и создаваться в кодировке UTF-8.
11. Добавление Disallow для папки верхнего уровня, где размещаются веб-страницы, которые нужно индексировать
Запрет на сканирование веб-страниц может привести к их удалению из индекса Google.
В чем проблема: При добавлении перед именем папки звездочки (*) это может означать что-то промежуточное. Когда она добавлена после, это указывает на необходимость заблокировать все, что включено в URL-адрес после /.
12. Блокировка доступа ко всему сайту во время разработки
В чем может быть проблема: При перемещении сайта или массовых обновлениях robots.txt может быть пустым по умолчанию для блокировки всего сайта. В данном случае он должен оставаться на месте и не быть удален во время технического обслуживания.
13. Написание директив заглавными или прописными буквами
Директивы в файле robots.txt являются чувствительными к регистру.
В чем проблема: Некоторые CMS автоматически устанавливают URL-адреса для отображения содержимого файла robots.txt в верхнем и нижнем регистре. Директивы должны соответствовать фактической структуре URL-адресов со статусом 200.
14. Использование кодов состояния сервера (например, 403) для блокировки доступа
В чем проблема: при перемещении сайта robots.txt может оказаться пустым или удаленным. Рекомендуется, чтобы он оставался на месте и не был удален во время технического обслуживания.
Как проверить, используется ли сайте X-Robots-Tag?
Чтоб проверить заголовки сервера, используйте инструмент просмотреть как робот Google в Search Console.
Заключение
Проверьте весь сайт, чтобы определить веб-страницы, которые следует заблокировать с помощью директив disallow. Убедитесь в том, что на сайте не используется автоматическое перенаправление и не изменяется файл robots.txt. Оцените эффективность сайта до и после изменений.
Пожалуйста, оставляйте свои отзывы по текущей теме материала. За комментарии, лайки, отклики, дизлайки, подписки низкий вам поклон!
Читайте также: