
Посмотреть базу данных oracle
Обновлено: 26.06.2024
Oracle Database — это объектно-реляционная СУБД (система управления базами данных), созданная компанией Oracle. В настоящее время она имеет множество разных версий и типов. Однако в этой статье мы поговорим не о видах баз данных Oracle, а о структуре и основных концепциях, которые относятся к СУБД Oracle Database. Поняв архитектуру СУБД Oracle, вы заложите фундамент, необходимый для понимания прочих средств (а они весьма обширны), предоставляемых базой данных Oracle.
Базы данных Oracle: экземпляры и сущности
СУБД Oracle Database включает в себя физические и логические компоненты. Особого упоминания заслуживает понятие экземпляра. Замечено, что некоторые используют термины «база данных» и «экземпляр» в качестве синонимов. Да, это взаимосвязанные, но всё же разные вещи. База данных в терминологии Oracle — это физическое хранилище информации, а экземпляр — это программное обеспечение, которое работает на сервере и предоставляет доступ к информации, содержащейся в базе данных Oracle. Экземпляр исполняется на конкретном сервере либо компьютере, в то самое время как база данных хранится на дисках, подключённых к этому серверу:
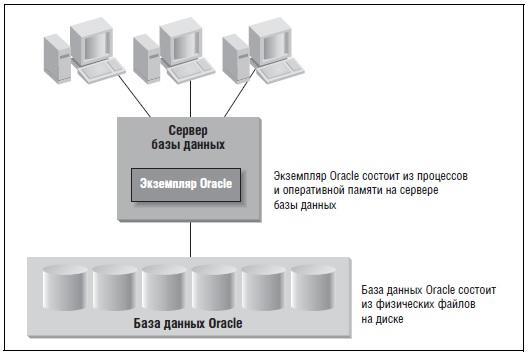
При этом база данных Oracle является физической сущностью, состоящей из файлов, которые хранятся на дисках. В то же самое время, экземпляр – это сущность логическая, состоящая из структур в оперативной памяти и процессов, которые работают на сервере. Экземпляр может являться частью только одной базы данных. При этом с одной базой данных бывает ассоциировано несколько экземпляров. Экземпляр ограничен по времени жизни, тогда как БД, условно говоря, может существовать вечно.
Также стоит заметить, что у пользователей нет прямого доступа к информации, которая хранится в базе данных Oracle — они должны запрашивать эту информацию у экземпляра Oracle.
Если упрощённо, то экземпляр — это мост к базе данных, а сама БД – это остров. Когда экземпляр запущен, мост работает, а данные способны попадать в базу данных Oracle и покидать её. Если мост перекрыт (экземпляр остановлен), пользователи не могут обращаться к базе данных, несмотря на то, что физически она никуда не исчезла.
Структура базы данных Oracle
База данных Oracle включает в себя: — табличные пространства; — управляющие файлы; — журналы; — архивные журналы; — файлы трассировки изменения блоков; — ретроспективные журналы; — файлы резервных копий (RMAN).
Табличные пространства Oracle
Любые данные, которые хранятся в базе данных Oracle, просто обязаны существовать в каком-либо табличном пространстве. Под табличным пространством (tablespace) понимают логическую структуру, то есть вы не сможете попросить ОС показать вам табличное пространство Oracle.
При этом каждое табличное пространство включает в себя физические структуры, называемые файлами данных (data files). Одно табличное пространство Oracle способно содержать один либо несколько файлов данных, в то время как каждый файл данных может принадлежать лишь одному tablespace. Создавая таблицу, мы можем указать, в какое именно табличное пространство мы её поместим — Oracle находит для неё место в каком-нибудь из файлов данных, которые составляют указанное табличное пространство.
На рисунке ниже вы можете посмотреть на соотношение между файлами данных и табличными пространствами в базе данных Oracle.
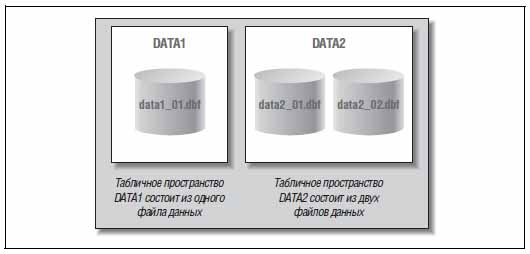
Создавая новую таблицу, мы можем поместить её в табличное пространство DATA1 либо DATA2. Таким образом, физически наша таблица окажется в одном из файлов данных, которые составляют указанное табличное пространство.
Файлы базы данных Oracle
База данных Oracle может включать в себя физические файлы 3-х основных типов: • control files — управляющие файлы; • data files — файлы данных; • redo log files — журнальные файлы либо журналы.
Посмотрим на отношения между ними:
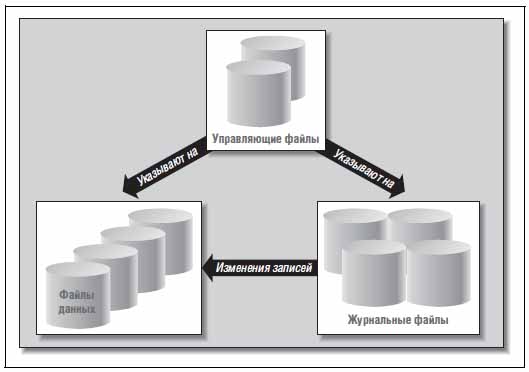
В управляющих файлах содержится информация о местонахождении других физических файлов, которые составляют базу данных Oracle, — речь идёт о файлах данных и журналов. Также там хранится важная информация о содержимом и состоянии БД Oracle. Что это за информация: • имя базы данных Oracle; • время создания БД; • имена и местонахождение журнальных файлов и файлов данных; • информация о табличных пространствах; • информация об архивных журналах; • история журналов, порядковый номер текущего журнала; • информация о файлах данных в автономном режиме; • информация о резервных копиях, контрольных точках, копиях файлов данных.
При этом функция управляющих файлов не ограничивается хранением важной информации, нужной при запуске экземпляра, — полезны они и в процессе удалении БД Oracle. К примеру, уже с версии Oracle Database 10g можно посредством команды DROP DATABASE удалить все файлы, которые перечислены в управляющем файле БД, включая сам управляющий файл.
Инициализация СУБД Oracle
Когда вы запускаете экземпляр Oracle, происходит считывание параметров инициализации. Параметры определяют, каким образом базе данных Oracle следует использовать физическую инфраструктуру и прочую конфигурационную информацию об экземпляре.
Как правило, инициализационные параметры хранятся в файле параметров инициализации экземпляра (обычно это INIT.ORA) либо, начиная с Oracle9i, в репозитории, называемом файлом параметров сервера (SPFILE). С выходом каждой новой версии Oracle число обязательных параметров инициализации уменьшается.
Кстати, в дистрибутиве Oracle можно найти пример файла инициализации, который пригоден для запуска базы данных. Также можно воспользоваться специальной программой Database Configuration Assistant (DCA) — она подскажет обязательные значения.
Более подробную информацию смотрите в официальной документации для СУБД Oracle Database.
С помощью этой команды show databases; Я вижу базы данных в в MySQL.
Как показать доступные базы данных в Oracle?
вы можете думать о "базе данных" MySQL как о схеме / пользователе в Oracle. Если у вас есть привилегии, вы можете запросить DBA_USERS просмотр для просмотра списка схем.
SELECT NAME FROM v$database; показывает имя базы данных в Oracle
Oracle не имеет простой модели базы данных, такой как MySQL или MS SQL Server. Я нахожу, что самое близкое-запросить табличные пространства и соответствующих пользователей в них.
например, у меня есть табличное пространство DEV_DB со всеми моими фактическими "базами данных"внутри них:
также можно запросить пользователей во всех табличных пространствах:
или в определенном табличном пространстве (используя my Dev_db табличное пространство в качестве примера):
может быть, вы могли бы использовать этот вид, но я не уверен.
но я думаю, что он покажет вам только информацию о текущей БД.
другой вариант, если БД работает в Linux. что бы это могло быть:
Я не ясно об этом, но обычно один сервер имеет одну базу данных (со многими пользователями), если вы создаете много баз данных, это означает, что вы создаете много экземпляров, слушателей. также. Таким образом, вы можете проверить свой LISTENER для установления его личности.
в моем тестировании я создал 2 базы данных ( dbtest и dbtest_1 ) поэтому, когда я проверяю свой статус слушателя, он выглядит так:
.
состояние слушателя
.
(описание=(адрес=(протокол = tcp) (хост=10.10.20.20) (порт=1521)))
Резюме Услуги.
сервис "dbtest" имеет 1 экземпляр(ы).
экземпляр "dbtest", состояние готово, имеет 1 обработчик(ы) для этой службы.
сервис "dbtest1XDB" имеет 1 экземпляр(ы).
экземпляр "dbtest1", состояние готово, имеет 1 обработчик(ы) для этой службы.
сервис "dbtest_1" имеет 1 экземпляр(ы).
экземпляр "dbtest1", состояние готово, имеет 1 обработчик(ы) для этой службы. Команда выполнена успешно
Как я могу запросить базу данных Oracle для отображения имен всех таблиц в ней?
ОТВЕТЫ
Ответ 1
Предполагается, что у вас есть доступ к представлению словаря данных DBA_TABLES . Если у вас нет этих привилегий, но они нуждаются в них, вы можете запросить, чтобы администратор базы данных явно предоставлял вам привилегии в этой таблице или что администратор базы данных предоставляет вам привилегию SELECT ANY DICTIONARY или SELECT_CATALOG_ROLE (любой из которых позволит вам для запроса любой таблицы словаря данных). Конечно, вы можете исключить некоторые схемы, такие как SYS и SYSTEM , которые имеют большое количество таблиц Oracle, которые вам, вероятно, не волнует.
В качестве альтернативы, если у вас нет доступа к DBA_TABLES , вы можете увидеть все таблицы, к которым ваша учетная запись имеет доступ, через представление ALL_TABLES :
Хотя это может быть подмножество таблиц, доступных в базе данных ( ALL_TABLES показывает вам информацию для всех таблиц, которым был предоставлен ваш пользователь).
Если вас интересуют только те таблицы, которые у вас есть, а не те, к которым у вас есть доступ, вы можете использовать USER_TABLES :
Так как USER_TABLES имеет только информацию о собственных таблицах, у нее нет столбца OWNER - владелец, по определению, вы.
Oracle также имеет ряд устаревших видов словарей данных - TAB , DICT , TABS и CAT например - которые могут быть использованы. В общем, я бы не предложил использовать эти устаревшие представления, если вам не нужно полностью использовать ваши сценарии для Oracle 6. Oracle не изменил эти представления за долгое время, поэтому у них часто возникают проблемы с новыми типами объектов. Например, представления TAB и CAT отображают информацию о таблицах, которые находятся в корзине пользователя, в то время как теги [DBA|ALL|USER]_TABLES все фильтруют их. CAT также показывает информацию о материализованных журналах просмотра с TABLE_TYPE в таблице "ТАБЛИЦА", которая вряд ли будет тем, что вы действительно хотите. DICT объединяет таблицы и синонимы и не говорит вам, кому принадлежит этот объект.
Ответ 2
Запрос user_tables и dba_tables не работает.
Это сделал:
Ответ 3
Идя еще на один шаг, существует другое представление, называемое cols (all_tab_columns), которое может использоваться для определения того, какие таблицы содержат заданное имя столбца.
чтобы найти все таблицы, имеющие имя, начинающееся с EST, и столбцы, содержащие CALLREF в любом месте их имен.
Это может помочь при разработке тех столбцов, к которым вы хотите присоединиться, например, в зависимости от ваших соглашений об именах таблиц и столбцов.
Ответ 4
Для лучшего просмотра с помощью sqlplus
Если вы используете sqlplus , вы можете сначала настроить несколько параметров для более удобного просмотра, если ваши столбцы становятся искалеченными (эти переменные не должны сохраняться после выхода из сеанса sqlplus ):
Показать все таблицы
Затем вы можете использовать что-то вроде этого, чтобы увидеть все имена таблиц:
Показать таблицы, которыми вы владеете
Как упоминает @Justin Cave, вы можете использовать это, чтобы отображать только те таблицы, которые у вас есть:
Не забывайте о представлениях
Имейте в виду, что некоторые "таблицы" могут быть "видами", поэтому вы также можете попробовать запустить что-то вроде:
Результаты
Это должно привести к тому, что выглядит довольно приемлемым, например:

Ответ 5
Простой запрос для выбора таблиц для текущего пользователя:
Ответ 6
Ответ 7
Попробуйте просмотреть словарные данные ниже.
Ответ 8
Существует 3 данных для этого
DBA_TABLES описывает все реляционные таблицы в базе данных.
Описание реляционных таблиц, доступных пользователю
USER_TABLES описывает реляционные таблицы, принадлежащие текущему пользователю. Это представление не отображает столбец ВЛАДЕЛЕЦ.
Ответ 9
Попробуйте выбрать user_tables, в котором перечислены таблицы, принадлежащие текущему пользователю.
Ответ 10
С помощью любого из них вы можете выбрать:
Ответ 11
База данных Oracle для отображения имен всех таблиц, используя запрос ниже
Ответ 12
предоставляет все таблицы всех пользователей только в том случае, если пользователь, с которым вы вошли в систему, имеет привилегии sysdba .
Ответ 13
Ниже приведен закомментированный фрагмент SQL-запросов, описывающий, как можно использовать параметры:
Ответ 14
Вы можете использовать Oracle Data Dictionary, чтобы получить информацию об объектах oracle.
Вы можете получить список таблиц по-разному:
Затем вы можете получить столбцы таблицы, используя имя таблицы:
Затем вы можете получить список зависимостей (триггеры, представления и т.д.):
Затем вы можете получить текстовый источник этих объектов:
И вы можете использовать USER или ALL представления вместо DBA , если хотите.
Ответ 15
Я не нашел ответа, который указывал бы на использование
Ответ 16
Ответ 17
Мы можем получить все таблицы, включая детали столбцов, из запроса ниже:
Ответ 18
Следующий запрос содержит только список необходимых данных, тогда как другие ответы дали мне дополнительные данные, которые меня только смутили.
Ответ 19
Новая функция, доступная в SQLcl (это бесплатный интерфейс командной строки для Oracle Database),
Tables псевдоним.
Вот несколько примеров, показывающих использование и дополнительные аспекты функции. Сначала подключитесь к sql.exe командной строки sql ( sql.exe в windows). Рекомендуется вводить эту конкретную команду sqlcl перед выполнением любых других команд или запросов, которые отображают данные.
SQL> tables
Чтобы узнать, на что ссылается псевдоним tables , вы можете просто использовать alias List<alias>
Вам не нужно определять этот псевдоним, так как он используется по умолчанию в SQLcl. Если вы хотите получить список таблиц из определенной схемы, используя новый пользовательский псевдоним и передавая имя схемы в качестве аргумента привязки с отображением только набора столбцов, вы можете сделать это, используя
SQL> alias tables_schema = select owner, table_name, last_analyzed from all_tables where owner = :ownr;
После этого вы можете просто передать имя схемы в качестве аргумента.
SQL> tables_schema HR
Более сложный предопределенный псевдоним известен как Tables2 , который отображает несколько других столбцов.
Чтобы узнать, какой запрос выполняется в фоновом режиме, введите
Это покажет вам немного более сложный запрос вместе с предопределенными определениями column обычно используемыми в SQL * Plus.
Джефф Смит объясняет больше об псевдонимах здесь
Ответ 20
Я искал список всех имен столбцов, принадлежащих таблице схемы, отсортированный по порядку идентификатора столбца.
Вот запрос, который я использую: -
Ответ 21
Действительно, список таблиц можно получить с помощью запросов SQL. Это можно сделать также с помощью инструментов, которые позволяют создавать словари данных, такие как ERWIN, Toad Data Modeler или ERBuilder. С этими инструментами, в дополнение к именам таблиц, у вас будут поля, их типы, объекты типа (триггеры, последовательности, домен, представления. )
Ниже приведены шаги, которые необходимо выполнить для создания определения таблиц:
- Вы должны перепроектировать вашу базу данных
- В Toad Data Modeler: Меню → Файл → Реверс инжиниринг → Мастер реинжиниринга
- В ERBuilder Data Modeler: Меню → Файл → Обратный инженер
Ваша база данных будет отображаться в программном обеспечении в виде диаграммы отношений сущностей.
Предполагается, что вы инсталлировали базу данных, согласно документа.
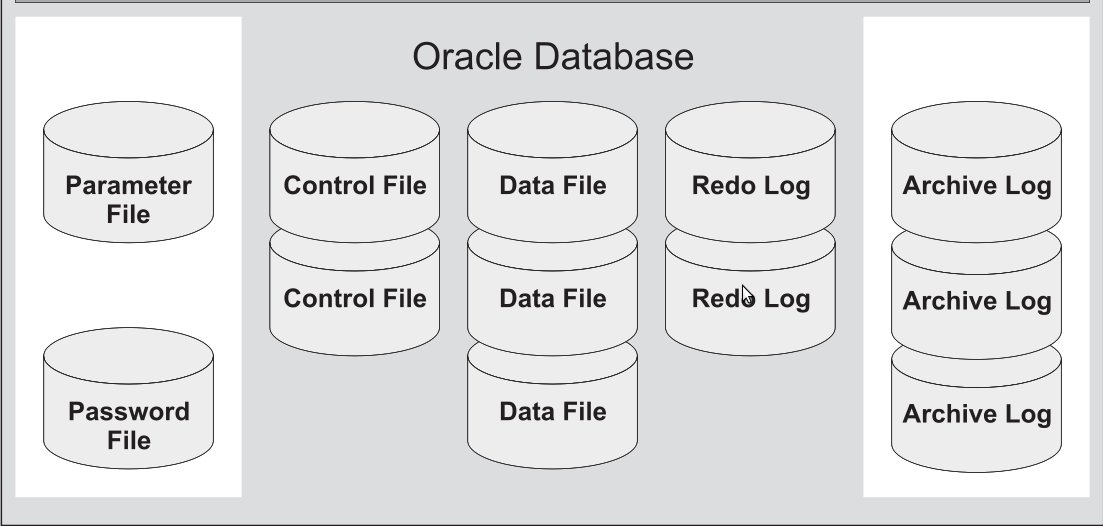
Обязательные файлы:
Необязательные файлы:
-
(необязательные в том смысле, что база может быть настроена для работы без данных файлов) (Alertlog - если нет необходимости в изучении данных по ошибкам, можно удалить. Трассировочные файлы по умолчанию не создаются. Чтобы создавались, нужно включать трассировку и потом не забыть отключить) (По умолчанию не используются. Нужно специально создавать специальными командами.)
Файлы данных (Data Files)
Все данные в базе данных Oracle сохраняются в файлах данных. Все таблицы, индексы, триггеры, последовательности, программы на PL/SQL, представления - все это находится в файлах данных. И хотя эти и другие объекты базы данных логически содержатся в табличных пространствах, в действительности они сохраняются в файлах на жестком диске компьютера.
В каждой базе данных Oracle имеется по крайней мере один файл данных (но обычно их бывает больше). Если вы создаете в Oracle таблицу и заполняете ее строками, Oracle помещает эту таблицу и строки в файл данных. Каждый файл данных может быть связан только с одной базой данных.
У каждого файла данных имеется специальный формат, внутренний для программного обеспечения Oracle. Важно отдавать себе отчет в том, что файл данных состоит из заголовка и совокупности блоков. Заголовок файла данных Oracle содержит несколько структур, в том числе и идентификатор базы данных, номер и имя файла, тип файла, SCN создания и состояния файла.
Данные в файлы вносятся исключительно средствами Oracle.
Следующий запрос, покажет, где находятся файлы данных.
Оперативные файлы журналов повтора (Online Redo Log Files)
Оперативные файлы журналов повтора - предназначены для записи всех изменений, выполненных над данными базы данных Oracle. Используется для хранения на диске информации для повторного выполнения операций.
Для компьютера выполнить задачи повторно - означает выполнить ее точно так, как она выполнялась в предыдущий раз. Поэтому назначение оперативного файла журнала повтора заключается в сохранении информации об изменениях в базе данных таким, образом, чтобы позже их можно было повторить.
Каждая база данных должна иметь не менее двух оперативных файлов журналов повтора. Текущий файл постепенно заполняется, после его заполнения (или переключения некоторыми командами), база данных приступает к записи в следующий файл. Эта операция называется переключением журналов.
Поскольку файлы повтора необходимы для выполнения восстановления базы данных и являются критичными, их объединяют в группы. Запись происходит одновременно в файлы одной группы.
Управляющие файлы (Control Files)
Поскольку база данных Oracle является физическим набором связанных файлов данных, то для их синхронизации и контроля требуется особые методы. Для этих целей используются управляющие файлы.
База данных Oracle может иметь один или несколько управляющих файлов. Если имеется несколько управляющих файлов, все они должны быть абсолютно идентичными. При каждом запуске базы данных Oracle читает информацию управляющего файла, а при каждом изменении размещения или добавления новых файлов данных и журналов базы данных обновляет управляющий файл.
Файлы параметров pfile, spfie (Parameter Files)
Файлы параметров используются для конфигурирования действий Oracle предже всего при старте. Для того, чтобы запустить экземпляр базы данных, Oracle должен прочесть файл параметров и определить, какие параметры инициализации установлены для этого экземпляра. В файле параметров содержатся многочисленные параметры и их установленные значения. Oracle считывает файл параметров при запуске базы данных. Можно создать несколько файлов параметров, каждый будет соответствовать различным конфигурациям экземпляра.
- spfile - бинарный файл, который используется сервером Oracle при старте.
- pfile - текстовый файл с параметрами, будет использоваться при старте, если не будет найден spfile.
При старте, Oracle считает файл spfileora112.ora. (файл серверных параметров). Преимущество spfile заключается в том, что при работе с базой данных, любые изменения в базе касающиеся изменения параметра системы, автоматически записываются в данный файл.
Если используется pfile, для сохранения изменений, необходимо либо “руками вносить эти изменения” в текстовый файл, либо в консоли выполнять команды для создания данных файлов Ораклом.
Как я могу узнать, что моя база данных использует PFILE или SPFILE?
Выполните следующий запрос, чтобы увидеть какой файл параметров был использован:
Архивные файлы журналов повтора (Archive Log Files)
Как только оперативный файл журнала повтора (Redolog) оказывается заполнен, программное обеспечение сервера Oracle начинает запись в следующий файл. Эта операция повторяется, как следствие информация в оперативных файлах журнала (Redolog) многократно перезаписывается.
Если необходимо сохранить историю изменений, нужно, чтобы после переключения журналов сохранялась их копия. Для этого достаточно перевести работу базы данных в режим работы ARCHIVELOG.
Архивные файлы журналов повтора жизненно важны при восстановлении. Если часть базы данных потеряна или повреждена, то для устранения повреждений обычно требуется несколько архивных журналов или туева хуча этих журналов. Файлы журналов повтора должны применяться к базе данных последовательно. Если один из архивных файлов журналов повтора пропущен, то остальные архивные файлы журналов не могут использоваться. Храните все свои архивные файлы журналов повтора с момента выполнения последней резервной копии. Файлы журналов постепенно накапливаются и разрастаются. Иногда необходимо их удалять. Все операции с данными файлами по применению их к базе выполняются исключительно средствами базы данных. А копировать и переносить их при желании можно как угодно. Бездумно удалять их руками не рекомендуется.
Alert log и трассировочные файлы (trace file)
При работе базы данных события и ошибки регистрируются в текстовых файлах на сервере базы данных. Файл журнала предупреждений (alert log) нужен администратору базы данных для отслеживания важнейших действий с базой данных - наподобие открытия и закрытия базы данных, установления параметров загрузки базы данных и переключения оперативных журналов повтора. Также в эти файлы записываются многие ошибки базы данных для последующего расследования их причин. Любые структурные изменения базы данных также регистрируются в файле журнала предупреждений.
Когда возникает ошибка базы данных, может генерироваться файл трассировки (trace file). Они содержит подробную информацию о возникновении ошибки.
Файлы паролей (Password File)
Необязательный файл, используется для защиты информации о подключениях привилегированных пользователей. Если отсутствует, то вы можете выполнять администрирование своей базы данных, только локально. Кроме того, с его помощью контролируется количество привилегированных подключений для управления в одно и то же время.
Tags: Oracle Database, Файлы базы данных Oracle,
Oracle DBA
Лучше потратить какое-то количество времени, чтобы записать успешный опыт, чем потом повторно воспроизводить его по памяти.
Все материалы обновляются по мере нахождения лучших практик и апгрейда знаний. Если будут желающие добавлять свои знания или исправлять ошибки и неточности, пишите в телеграм чате. Если будет учавствовать больше людей, качество материалов будет улучшаться и обновляться быстрее. Ссылки на ваши профили в соц. сетях будут добавлены в статьях, в которых вы учавствуете.

Привет! Меня зовут Александра, я работаю в команде тестирования производительности. В этой статье расскажу базовые сведения об OEM от Oracle. Статья будет полезна для тех, кто только знакомится с платформой, но и не только для них. Основная цель статьи — помочь провести быстрый анализ производительности БД и поиск отправных точек для более глубокого анализа.
OEM (Oracle Enterprise Manager) — платформа для управления БД. OEM предоставляет графический интерфейс для выполнения большого количества операций с базами данных: резервное копирование, просмотр аварийных журналов, графиков производительности.
Performance Home
На вкладке Performance Home можно увидеть основные графики утилизации БД.
Average Runnable Process

Этот график дает общее понимание использования CPU.
| № | Показатель | Описание |
|---|---|---|
| 1 | Instance Foreground CPU | Отображает утилизацию CPU процессами текущего инстанса, напрямую запущенными клиентом, например выполнение запросов. Список событий ожидания текущего инстанса можно посмотреть в AWR-отчете |
| 2 | Instance Background CPU | Отображает утилизацию CPU фоновыми процессами текущего инстанса, например LGWR. Список событий фонового процесса текущего инстанса можно посмотреть в AWR-отчете или в официальной документации Oracle |
| 3 | Non-database Host CPU | Отображает утилизацию CPU процессами, не относящимися к текущему инстансу |
| 4 | Load Average | Отображает среднюю длину очереди процессов, ожидающих выполнения |
| 5 | CPU Treads/CPU Cores | Отображает лимит максимально возможного использования CPU |
Average Active Sessions
- Если зафиксирован рост активных сессий, то должна расти пропускная способность (график Throughput).
- Если Active Sessions превышает CPU Cores/CPU Threads, это свидетельствует о проблемах производительности.
- Если зафиксирован рост времени отклика операций, но при этом активные сессии не превышают CPU, это значит, что узкое место не в CPU и нужно более детально смотреть, по каким классам события ожидания фиксируется рост, после чего можно на графике нажать на соответствующий класс и провалиться глубже в детализацию (откроется отчет ASH — Active Session History).
Throughput

Раздел Throughput отображает пропускную способность. Пропускная способность базы данных измеряет объем работы, которую база данных выполняет за единицу времени.
Пики на графике Throughput должны соответствовать пикам на графике Average Active Sessions. Если заметен рост времени ожидания, необходимо убедиться, что увеличивается пропускная способность. Если пропускная способность низкая, а время ожидания растет — необходимо изменить настройки БД.

Latency показывает задержку чтения блоков. Это разница между временем выполнения чтения и временем обработки чтения БД. Показатель должен стремиться к нулю.
Оптимальным считается значение до 10 мс. Этот график — основной показатель производительности в этом блоке. Если зафиксирован рост времени задержки, нужно посмотреть, не растет ли количество I/O операций и их вес, также на рост Latency может влиять утилизация CPU.
Статистику по I/O можно смотреть в разрезе функций, в разрезе типов и в разрезе групп потребителей ресурсов (группы пользователей). Для этого на графике необходимо выбрать соответствующий Breakdown. Графики показывают количество I/O-операций в секунду и их вес в разрезе выбранного значения Breakdown. Для большей детализации можно провалиться глубже в статистику, выбрав соответствующее значение на графике или в легенде, и посмотреть статистику именно по выбранному значению.
I/O Function

График дает представление об уровне утилизации диска приложениями или джобами. То есть на графике можно увидеть, какие процессы больше всего читали и писали за определенный период.
Можно выделить следующие категории:
| № | Категория | Описание |
|---|---|---|
| 1 | Фоновые процессы | Включают в себя ARCH, LGWR, DBWR (полный список фоновых процессов есть в документации) |
| 2 | Активность | XML DB, Streams AQ, Data Pump, Recovery, RMAN |
| 3 | Тип I/O | Включает прямую запись и чтение (в том числе чтение из кэша) |
| 4 | Другое | Включает операции ввода/вывода управляющих файлов |
I/O Type

Выводит статистику по тяжести операций ввода-вывода. Маленькими считаются операции, которые обрабатывают до 128 КБ. К большим операциям ввода-вывода относятся: сканирование таблиц и индексов, прямая загрузка данных, резервное копирование, восстановление и архивирование.
Consumer group
Дает представление об утилизации диска в разрезе групп пользователей: показывает, какая группа пользователей выполняет операции чтения и записи в определенный период. Включает в себя фоновые процессы.
Parallel Executions
Раздел дает представление о показателях, связанных с параллельным выполнением запросов. Параллельный запрос делится на несколько процессов для ускорения выполнения запроса. Параллельное выполнение полезно при выполнении тяжелых запросов. Подробнее можно прочесть в официальной документации Oracle.
Services

Службы на этом графике представляют собой группы приложений. Отображаются только сессии активных служб, находящиеся в ожидании в определенный момент времени. Например, служба SYS$USERS — это установка пользовательского сеанса.
ASH Report

ASH Report (Active Session History) дает более подробную информацию по потреблению ресурсов. Чтобы перейти к графику, в меню Performance нужно выбрать пункт Performance Hub/ASH Report. Также перейти к ASH Report можно при выборе класса события ожидания на графике Average Active Session.
- События ожидания и группы событий ожидания.
- Группы пользователей, пользователи, сервисы, инстансы.
- SQL-запросы.
AWR (Automatic Workload Repository) дает подробную информацию о процессах, происходящих с БД в определенный период. Для построения AWR-отчета нужно выбрать пункт меню Performance/AWR/AWR Report. Также есть возможность сравнивать два временных промежутка. Для этого нужно выбрать пункт меню Performance/AWR/Compare Period Report.
Ниже будут описаны наиболее показательные разделы AWR-отчета, описание остальных разделов можно поискать в официальной документации.
Load Profile

Здесь отображается общая информация по тому, как была загружена БД за выбранный период.
| № | Параметр | Описание |
|---|---|---|
| 1 | DB Time(s) | Сумма времени утилизации процессора и время ожидания (без простоя) |
| 2 | DB CPU(s) | Нагрузка на процессор |
| 3 | Background CPU(s) | Загрузка процессора фоновыми задачами |
| 4 | Redo size | Объем чтения |
| 5 | Logical reads | Среднее количество логических чтений блоков |
| 6 | Block changes | Среднее значение измененных блоков |
| 7 | Physical reads | Физическое чтение в блоках |
| 8 | Physical writes | Количество записей в блоках |
| 9 | Read I/O requests | Количество чтений |
| 10 | Write I/O requests | Количество записей |
| 11 | Read I/O (MB) | Объем чтения |
| 12 | Write I/O (MB) | Объем записей |
| 13 | IM scan rows | Количество строк в In-Memory Compression Units (IMCU), которые были доступны |
| 14 | Session Logical Read IM | Чтения в In-Memory |
| 15 | User calls | Пользовательские вызовы |
| 16 | Parses | Разборы |
| 17 | Logons | Количество входов |
| 18 | Excecutes | Количество вызовов |
| 19 | Rollback | Количество откатов данных |
| 20 | Transacions | Количество транзакций |
Instance Efficiency Percentages

| № | Показатель | Критерии |
|---|---|---|
| 1 | Buffer nowait | Если показатель меньше 95%, значит, буферы data block buffer используются неправильно. Возможно, нужно увеличить data block buffer size |
| 2 | Buffer Hit | Если показатель меньше 95%, значит, буферы data block buffer используются неправильно. Возможно, нужно увеличить data block buffer size |
| 3 | Library cache hit | Если показатель меньше 95% — нужно расширять shared pool (либо причина в bind-переменных) |
| 4 | Redo NOWAIT | Если показатель меньше 95%, это говорит о проблеме в redo log buffer или redo log |
| 5 | Parse CPU to Parse Elapsd | Показатель должен быть больше или равен 90%, тогда большинство процессов не ожидает ресурсов, что говорит о правильной работе базы данных |
| 6 | Non-Parse CPU | Показатель должен приближаться к 100%, это значит, что большинство ресурсов CP используется в различных операциях, кроме parsing, что говорит о правильной работе базы данных. Если Non-Parse CPU низкий, значит, база много времени тратит на разбор запроса вместо реальной работы |
| 7 | In-memory sort | Значение меньше 100 говорит о том, что сортировка идет через диск, а также есть потенциальные проблемы с PGA_AGGREGATE_TARGET,SORT_AREA_SIZE,HASH_AREA_SIZE и bitmap setting |
| 8 | Soft Parse | Чем он выше, тем меньше у нас Hard Parse |
| 9 | Latch Hit | Чем он выше, тем меньше мы ждем Latches (если он низкий — у нас проблемы с CPU-Bound и Latches) |
Top 10 Foreground Events by Total Wait Time
В разделе находится топ-10 событий, которые ожидали ресурсов дольше остальных.
При анализе необходимо обратить внимание на класс события ожидания. Если wait class System I/O, User I/O или Other, это нормально для БД. Если класс события ожидания Concurrency, это может свидетельствовать о проблемах.
Классы события ожидания можно посмотреть в разделе Wait Classes by Total Wait Time. В разделе находится статистика по классам события ожидания с сортировкой по времени ожидания.
Описание некоторых событий ожидания:
| № | Событие ожидания | Описание |
|---|---|---|
| 1 | DB CPU | Отображает процессорное время, затраченное на пользовательские операции над БД. Это событие должно находиться на первом месте списка |
| 2 | db file sequential read | Метрика сигнализирует, что пользовательский процесс не находит нужный блок в buffer cache, загружает его с диска в SGA и ждет физического ввода/вывода |
| 3 | db file scattered read | Указывает на проблему с фулл-сканами, возможно, нужны индексы |
| 4 | read by other session | Может говорить о том, что размер блока слишком большой или задержка (latency) слишком большая |
| 5 | enq TX – row lock contention | Событие возникает при ожидании блокировки строки для дальнейшей ее модификации DML-запросом. Если показатель больше 10%, необходимо разбираться в причинах. Более детальную информацию можно посмотреть в разделе Segments by Row Lock Waits, в котором есть сведения о том, какие таблицы были заблокированы и какими запросами |
| 6 | DB FILE SEQUENTIAL READ | Если среднее значение параметра больше 100 мс, это может свидетельствовать о том, что диск работает медленно |
| 7 | LOG FILE SYNC | Значение AVG WAIT более 20 мс может свидетельствовать о проблемах |
| 8 | DB FILE SCATTERED READ | Если это событие выполняется — возможно, имеет смысл создать дополнительные индексы. Для более подробной информации нужно перейти к разделу Segments By Physical Read, в котором находится информация по таблицам и индексам, в которых происходит физическое чтение |
| 9 | direct path read temp ИЛИ direct path write temp | Эти события дают информацию по использованию временных файлов |
| 10 | Buffer Busy Wait | Событие указывает на то, что несколько процессов пытаются обратиться к одному блоку памяти, то есть пока первый процесс работает с конкретным блоком памяти, остальные процессы находятся в статусе ожидания |
Host CPU и Instance CPU
Здесь стоит обратить внимание на %Idle и %Total CPU. Если показатель %Idle низкий, а %Total CPU высокий, это может свидетельствовать о том, что процессор является узким местом.
Foreground Wait Class, Foreground Wait events и Background Wait Events
Показывают классы и события, которые провели в ожидании большего всего. Foreground Wait events дополняет информацию раздела Top 10 Foreground Events By Total Wait Time. Background Wait Events показывает детализацию по событиям ожидания фоновых процессов.
SQL statistics

Раздел содержит несколько таблиц со статистикой по SQL-запросам, отсортированным по определенному критерию.
Подробнее про оптимизацию запросов и примеры типичных проблем в запросах можно почитать в статье Проактивная оптимизация производительности БД Oracle.
| № | Параметр | Описание |
|---|---|---|
| 1 | SQL ordered by Elapsed Time | Топ SQL-запросов по затраченному времени на их выполнение |
| 2 | SQL ordered by CPU Time | Топ SQL-запросов по процессорному времени |
| 3 | SQL ordered by User I/O Wait Time | Топ SQL-запросов по времени ожидания ввода/вывода для пользователя |
| 4 | SQL ordered by Gets | Запросы к БД, упорядоченные по убыванию логических операций ввода/вывода. При анализе стоит учитывать, что для PL/SQL-процедур их количество прочитанных Buffer Gets будет состоять из суммы всех запросов в рамках этой процедуры |
| 5 | SQL ordered by Reads | Этот раздел схож с предыдущим: в нем указываются все операции ввода/вывода, наиболее активно физически считывающие данные с жесткого диска. Именно на эти запросы и процессы надо обратить внимание, если система не справляется с объемом ввода/вывода |
| 6 | SQL ordered by Physical Reads (UnOptimized) | В этом разделе выводятся неоптимизированные запросы. В Oracle неоптимизированными считаются все запросы, которые не обслуживаются DSFC или Exadata Cell Smart Flash Cache (ECSFC) |
| 7 | SQL ordered by Executions | Наиболее часто выполняемые запросы |
| 8 | SQL ordered by Parse Calls | Отображает количество попыток разбора SQL-запросов до его выполнения |
| 9 | SQL ordered by Sharable Memory | Запросы, занимающие больший объем памяти общего пула SGA |
| 10 | SQL ordered by Version Count | Здесь показано количество SQL-операторов экземпляров одного и того же оператора в разделяемом пуле |
| 11 | Complete List of SQL Text | Показывает полный SQL-запрос, не только его хэш. В этой таблице можно найти неоптимальные запросы (например, запросы по всем столбцам таблицы «select * from. », запросы с большим количеством «like» и т. п.) |
Active Session History (ASH) Report
В данной таблице находятся самые тяжелые SQL запросы, на которые приходится наибольший процент активности и наибольшее время ожидания.
В таблице содержится статистика по запросам, на которые приходится наибольший процент выборочной активности и подробная информация о их плане выполнения. Вы можете использовать эту информацию, чтобы определить, какая часть выполнения SQL операторов значительно повлияла на затраченное время SQL оператора.
Читайте также: