
Предварительная выборка смежных строк кэша что это
Обновлено: 02.07.2024
От автора: когда вы заказываете гамбургер с картофелем фри в любом ресторане в Америке, официант часто подносит бутылку кетчупа к столу еще до того, как гамбургер будет готов. Хотя вы, возможно, и не просили явно кетчуп, официант предполагает, что вы попросите об этом, так как большинство американцев едят гамбургеры с кетчупом. Но что, если оптимизация официанта была неправильной, и вы хотели вместо этого майонез? В контексте ресторана ошибка официанта добавляет небольшую задержку до момента наслаждения вашей любимой едой и может считаться легким неудобством. Но что, если в худшем случае соус, который вы так хотели, несли так долго, что бургер успел остыть? Это раздражает, не так ли?
Подобно тому, как официант предварительно оптимизировал ваш выбор соуса, современные браузеры имеют различные методы, такие как подсказки ресурсов, для повышения производительности, угадывая, куда пользователь перейдет дальше. Такие подсказки ресурсов, как prefetch позволяют заблаговременно получать критические ресурсы и экономить ценное время при (следующем) рендеринге. Тем не менее, решение о том, что предварительно извлекать, по своей природе является спекулятивным. Мы, как разработчики, делаем предположения о пути пользователя и маршрутах, по которым он пойдет. Как мы наблюдали в случае инцидента с приправой ранее, спекулятивная предварительная выборка может быть расточительной, поскольку извлеченные ресурсы никогда не будут использоваться. Здесь может пригодиться прогностическая предварительная выборка. Объединяя достижения в области машинного обучения с данными аналитики, мы можем значительно повысить эффективность наших выборок.
Параметры предварительной выборки
Прежде чем мы углубимся в то, как мы можем реализовать прогностические предварительные выборки в приложениях, давайте уделим немного времени, чтобы изучить наши варианты, когда дело доходит до предварительной выборки. Существует три основных типа предварительной выборки, доступных в большинстве современных браузеров: предварительная выборка ссылок, предварительная выборка DNS и предварительный рендеринг. Из этих трех, предварительная выборка ссылок является самой популярной.
Предварительная выборка DNS
Предварительная выборка ссылок
Предварительная выборка ссылок аналогична предварительной выборке DNS, за исключением того, что она идет еще дальше. Она не только позволяет браузеру выполнять DNS-разрешение, но также извлекать ресурсы и сохранять их в кеше при подготовке пользователя к переходу на эту конкретную страницу.

JavaScript. Быстрый старт
Изучите основы JavaScript на практическом примере по созданию веб-приложения
Предварительный рендеринг
Предварительный рендеринг является наиболее дорогостоящим из доступных вариантов предварительной выборки и представляет собой комбинацию двух рассмотренных выше вариантов. В дополнение к выполнению разрешения DNS и предварительной выборки ссылок, предварительный рендеринг выполняет тяжелую работу по отрисовке всей страницы в фоновом режиме, шрифтов, ресурсов и всего остального. Из-за высокого потребления пропускной способности при предварительном рендеринге это наименее рекомендуемый подход к предварительной выборке.
Переход от умозрительного к прогностическому
Обычный подход к реализации предварительной выборки в приложениях заключается в жестком кодировании ссылок на страницы. Хотя эти решения часто основываются на существующих аналитических данных, они по своей природе подвержены ошибкам. Ссылки для предварительной выборки могут быстро устареть из-за нечастых обновлений, а предварительные выборки не отвечают на отзывы пользователей. Лучшее решение состоит в том, чтобы предсказать, куда пользователь пойдет, и соответственно предварительно извлечь ресурсы, другими словами, использовать прогностическую предварительную выборку.
Прогнозирование будущих кликов
В случае упреждающей предварительной выборки мы определяем наилучший возможный результат на основе данных, которые собрали для отслеживания навигации пользователя. Допустим, у нас есть информация о просмотре страницы пользователя до того, как он перейдет на текущую страницу. Основываясь на этих данных, мы можем получить общее представление о потоках пользователей и рассчитать вероятность того, что они перейдут на страницу с учетом их текущей страницы. Из приведенных ниже примеров данных мы знаем, что 2 из 4 пользователей перешли по маршруту /menu с маршрута /about, поэтому вероятность того, что любой пользователь перейдет к маршруту /menu с маршрута /about, составляет около 50%. Точно так же мы можем рассчитать, что 25% пользователей будут переходить с /menu на /contact, потому что 1 из 4 пользователей сделал именно это.

Прогностический irl
Теория этого типа работает, но давайте посмотрим, работает ли это на практике. Данные по отслеживанию навигации пользователя могут быть легко получены из Google Analytics (GA). Вы можете просмотреть эти данные в панели мониторинга GA, перейдя «Поведение» > «Содержание сайта» > «Все страницы» и кликнув вкладку «Обзор переходов». Для ясности рассмотрим необработанные данные, полученные из Google Analytics API. Мы сосредоточимся в первую очередь на части строк данных (см. ниже). Атрибут dimensions является массивом, который показывает путь к предыдущей странице, и к следующей странице соответственно. Атрибут values метрики представляет собой массив с просмотрами страниц и выходами соответственно.
Предварительная выборка из кэша - это метод, используемый компьютерными процессорами для повышения производительности выполнения путем выборки инструкций или данных из их исходного хранилища в более медленной памяти в более быструю локальную память до того, как это действительно понадобится (отсюда и термин «предварительная выборка»). Большинство современных компьютерных процессоров имеют быструю и локальную кэш-память, в которой предварительно загруженные данные хранятся до тех пор, пока они не потребуются. Источником для операции предварительной выборки обычно является основная память . Из-за их конструкции доступ к кэш-памяти обычно намного быстрее, чем доступ к основной памяти , поэтому предварительная выборка данных и последующий доступ к ним из кешей обычно на много порядков быстрее, чем доступ к ним непосредственно из основной памяти . Предварительная выборка может выполняться с помощью инструкций управления неблокирующим кешем .
СОДЕРЖАНИЕ
Данные и предварительная выборка из кеша инструкций
Предварительная выборка из кеша может извлекать данные или инструкции в кеш.
- Предварительная выборка данных извлекает данные до того, как они понадобятся. Поскольку шаблоны доступа к данным демонстрируют меньшую регулярность, чем шаблоны инструкций, точная предварительная выборка данных обычно является более сложной задачей, чем предварительная выборка инструкций.
- Предварительная выборка инструкций выбирает инструкции до того, как их нужно будет выполнить. Первыми массовыми микропроцессорами, которые использовали ту или иную форму предварительной выборки команд, были Intel8086 (шесть байтов) и Motorola68000 (четыре байта). В последние годы все высокопроизводительные процессоры используют методы предварительной выборки.
Аппаратная и программная предварительная выборка кеша
Предварительная выборка из кэша может выполняться аппаратно или программно.
- Аппаратная предварительная выборка обычно выполняется с помощью специального аппаратного механизма в процессоре, который наблюдает за потоком инструкций или данных, запрашиваемых выполняющейся программой, распознает следующие несколько элементов, которые могут понадобиться программе, на основе этого потока и выполняет предварительную выборку в кэш процессора. .
- Программная предварительная выборка обычно выполняется компилятором, анализируя код и вставляя дополнительные инструкции предварительной выборки в программу во время самой компиляции.
Методы аппаратной предварительной выборки
Буферы потока
- Потоковые буферы были разработаны на основе концепции «схемы упреждающего просмотра одного блока (OBL)», предложенной Аланом Джеем Смитом .
- Буферы потока - один из наиболее распространенных методов предварительной выборки на основе оборудования. Этот метод был первоначально предложен Норманом Джуппи в 1990 году, и с тех пор было разработано множество вариантов этого метода. Основная идея состоит в том, что адрес промаха кэша (и последующие адреса) выбираются в отдельный буфер глубины . Этот буфер называется буфером потока и отделен от кеша. Затем процессор потребляет данные / инструкции из буфера потока, если адрес, связанный с предварительно выбранными блоками, совпадает с запрошенным адресом, сгенерированным программой, выполняющейся на процессоре. Рисунок ниже иллюстрирует эту настройку: k k

- Каждый раз, когда механизм предварительной выборки обнаруживает промах в блоке памяти, скажем, A, он выделяет поток, чтобы начать предварительную выборку последовательных блоков, начиная с пропущенного блока. Если буфер потока может содержать 4 блока, тогда мы будем предварительно выбирать A + 1, A + 2, A + 3, A + 4 и удерживать их в выделенном буфере потока. Если затем процессор потребляет A + 1, то он должен быть перемещен «вверх» из буфера потока в кэш процессора. Первая запись буфера потока теперь будет A + 2 и так далее. Этот шаблон предварительной выборки последовательных блоков называется последовательной предварительной выборкой . Он в основном используется, когда необходимо выполнить предварительную выборку смежных местоположений. Например, он используется при предварительной загрузке инструкций.
- Этот механизм можно расширить, добавив несколько таких «потоковых буферов», каждый из которых будет поддерживать отдельный поток предварительной выборки. Для каждого нового промаха будет выделен новый буфер потока, и он будет работать аналогично описанному выше.
- Идеальная глубина буфера потока - это то, что является предметом экспериментов с различными тестами и зависит от остальной части задействованной микроархитектуры .
Другой шаблон инструкций предварительной выборки - это предварительная выборка адресов, которые находятся впереди в последовательности. Он в основном используется, когда последовательные блоки, которые должны быть предварительно загружены, имеют разные адреса. Это называется последовательной предварительной выборкой. s s
Методы предварительной загрузки программного обеспечения
Предварительная выборка, управляемая компилятором
Предварительная выборка, управляемая компилятором, широко используется в циклах с большим количеством итераций. В этом методе компилятор предсказывает будущие промахи в кэше и вставляет инструкцию предварительной выборки на основе штрафа за промах и времени выполнения инструкций.
Эти предварительные выборки представляют собой неблокирующие операции с памятью, т. Е. Эти обращения к памяти не мешают действительному доступу к памяти. Они не изменяют состояние процессора и не вызывают сбои страниц.
Одним из основных преимуществ программной предварительной выборки является то, что она снижает количество принудительных промахов в кэше.
В следующем примере показано, как инструкция предварительной выборки будет добавлена в код для повышения производительности кеша .
Рассмотрим цикл for, как показано ниже:
На каждой итерации осуществляется доступ к i- му элементу массива array1. Следовательно, мы можем выполнить предварительную выборку элементов, к которым будет осуществляться доступ в будущих итерациях, вставив инструкцию «предварительной выборки», как показано ниже:
Здесь шаг предварительной выборки зависит от двух факторов: штрафа за промах в кэше и времени, необходимого для выполнения одной итерации цикла for . Например, если на выполнение одной итерации цикла требуется 7 циклов, а штраф за промах в кэше составляет 49 циклов, то у нас должно быть - это означает, что мы предварительно выбираем 7 элементов вперед. На первой итерации i будет 0, поэтому мы предварительно выбираем 7-й элемент. Теперь, при таком расположении, первые 7 обращений (i = 0-> 6) по-прежнему будут пропущены (в упрощающем предположении, что каждый элемент array1 находится в отдельной строке кэша). k k знак равно 49 / 7 знак равно 7
Сравнение аппаратной и программной предварительной выборки
- В то время как программная предварительная выборка требует вмешательства программиста или компилятора , аппаратная предварительная выборка требует специальных аппаратных механизмов.
- Программная предварительная выборка хорошо работает только с циклами, в которых есть регулярный доступ к массиву, поскольку программист должен вручную кодировать инструкции предварительной выборки. Принимая во внимание, что аппаратные средства предварительной выборки работают динамически в зависимости от поведения программы во время выполнения .
- Аппаратная предварительная выборка также снижает нагрузку на ЦП по сравнению с программной предварительной выборкой.
Метрики предварительной выборки кеша
Есть три основных показателя, позволяющих судить о предварительной выборке из кеша.
Покрытие
Покрытие - это доля от общего числа промахов, которые исключаются из-за предварительной выборки, т. Е.
куда, Всего промахов кеша знак равно ( Промахи в кэше устранены с помощью предварительной выборки ) + ( Промахи в кэше не устраняются предварительной выборкой ) > = (>) + (>)>
Точность
Точность - это доля от общего числа предварительных выборок, которые были полезны, т. Е. Отношение количества предварительно выбранных адресов памяти, на которые фактически ссылалась программа, к общему количеству выполненных предварительных выборок.
Хотя кажется, что идеальная точность может означать отсутствие промахов, это не так. Сами предварительные выборки могут привести к новым пропускам, если предварительно выбранные блоки помещаются непосредственно в кэш. Хотя это может быть небольшая часть от общего количества промахов, которые мы можем увидеть без предварительной выборки, это ненулевое количество промахов.
Своевременность
Качественное определение своевременности - это то, насколько раньше блок предварительно выбирается по сравнению с тем, когда на него фактически ссылаются. Пример для дальнейшего объяснения своевременности выглядит следующим образом:
Рассмотрим цикл for, в котором каждая итерация выполняется за 3 цикла, а операция предварительной выборки - за 12 циклов. Это означает, что для того, чтобы предварительно выбранные данные были полезными, мы должны запустить итерации предварительной выборки до их использования, чтобы обеспечить своевременность. 12 / 3 знак равно 4
В этой статье мы разъясним значение компонентов Prefetcher (предварительная выборка) и Superfetch (супервыборка) в Windows 7, а также влияние Prefetcher и Superfetch на ускорение запуска Windows 7 и установленных программ.
Принципы работы предварительной выборки
Чтобы улучшить производительность, менеджер кэша Windows 7 отслеживает процесс обмена данными между жестким диском и оперативной памятью, а также между оперативной памятью и виртуальной памятью во время загрузки операционной системы и во время запуска программ. Отслеживая эти операции, менеджер кэша создает карты ссылок на все папки и файлы, которые используются во время запуска каждого приложения или процесса. Эти карты ссылок сохраняются в файлы с расширением .pf в папке C:\Windows\Prefetch.
Во время последующих запусков Windows 7, карты ссылок считываются и в оперативную память загружаются указанные в них данные. В результате, запуск соответствующих приложений и процессов происходит быстрее за счет минимального количества обращений к жесткому диску.
Сколько места на жестком диске требуется для работы Prefetcher
Нет никакой необходимости в периодической очистке папки Prefetch. Во-первых, количество часто используемых программ ограничено. Во-вторых, если какие-то программы перестают использоваться часто, их запуск перестает оптимизироваться.
Таким образом, функция предварительной выборки в целом повышает быстродействие системы. Отключение предварительной выборки или периодическая ручная очистка папки Prefetch снизят, а не повысят скорость работы Windows 7.
Настройка и отключение предварительной выборки
Вы можете самостоятельно протестировать скорость запуска Windows 7 и установленных программ при включенной и выключенной предварительной выборке. Настройка, отключение и включение предварительной выборки производится с помощью редактора реестра Windows 7.
Откройте Пуск, введите в поисковую строку regedit и нажмите Ввод .

В открывшемся окне редактора реестра раскройте HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management\PrefetchParameters
Дважды щелкните параметр EnablePrefetcher.
1. Чтобы отключить предварительную выборку, установите значение 0.
Начиная со следующего запуска Windows 7, оптимизация запуска операционной системы и часто используемых программ производиться не будет.
2. Чтобы включить предварительную выборку для часто используемых программ, установите значение 1.
Начиная со следующего запуска Windows 7, будет оптимизироваться запуск часто используемых программ, но не будет оптимизироваться запуск операционной системы.
3. Чтобы включить предварительную выборку для Windows 7, установите значение 2.
Начиная со следующего запуска Windows 7, будет оптимизироваться запуск операционной системы, но не будет оптимизироваться запуск часто используемых программ.
4. Чтобы включить предварительную выборку, установите значение 3 (рекомендуемое значение, установлено по умолчанию).
Начиная со следующего запуска Windows 7, будет оптимизироваться и запуск операционной системы, и запуск часто используемых программ.
Супервыборка выполняет все функции предварительной выборки, плюс несколько дополнительных функций. Преимущество супервыборки в том, что она лишена одного из самых главных недостатков технологии Предварительной выборки. Предварительная выборка загружает в память большинство файлов и данных, необходимых для запуска приложения или процесса, чтобы повысить скорость его запуска. Но когда другие приложения обращаются к памяти, предвыбранные данные выгружаются на жесткий диск, в файл подкачки. И когда эти данные потребуются снова, система будет загружать их обратно из файла подкачки в память, что непременно скажется на скорости запуска соответствующего приложения или процесса.
Супервыборка обеспечивает более устойчивый прирост производительности. В дополнение к созданию файлов с картами ссылок, супервыборка создает конфигурации используемых приложений. Эти конфигурации содержат информацию о том, как часто и когда используются те или иные приложения. Супервыборка отслеживает активность приложений в созданной конфигурации и отмечает, когда и какие предвыбранные данные были выгружены в файл подкачки. После выгрузки предвыбранных данных в файл подкачки, супервыборка контролирует исполнение приложения, из-за которого предвыбранные данные были выгружены, и сразу после завершения работы этого приложения, ранее выгруженные предвыбранные данные снова загружаются в память. Таким образом, когда вы снова обратитесь к часто используемому приложению, предвыбранные данные снова будут в памяти, и это приложение быстро запустится.
Таким образом, компонент SuperFetch (супервыборка) существенно увеличивает быстродействие системы и установленных программ, поэтому отключать этот компонент настоятельно не рекомендуется.
Настройка, отключение и включение супервыборки
Хотя отключение и изменение параметров супервыборки не рекомендуется, вы можете самостоятельно протестировать быстродействие Windows 7 и установленных программ при включенной и выключенной супервыборке. Настройка, отключение и включение супервыборки производится с помощью редактора реестра Windows 7.
Откройте Пуск, введите в поисковую строку regedit и нажмите Ввод .
В открывшемся окне редактора реестра раскройте HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management\PrefetchParameters
Дважды щелкните параметр EnableSuperfetch.
1. Чтобы отключить супервыборку, установите значение 0.
2. Чтобы включить супервыборку для часто используемых программ, установите значение 1.
3. Чтобы включить супервыборку для Windows 7, установите значение 2.
4. Чтобы включить супервыборку, установите значение 3 (рекомендуемое значение, установлено по умолчанию).
Также можно полностью отключить супервыборку, отключив её службу и запретив её запуск. Чтобы сделать это, откройте Панель управления -> Администрирование -> Службы (можно открыть меню Пуск, ввести в поисковую строку services.msc и нажать Ввод ).
В списке служб найдите службу Superfetch и откройте её свойства двойным щелчком мыши.
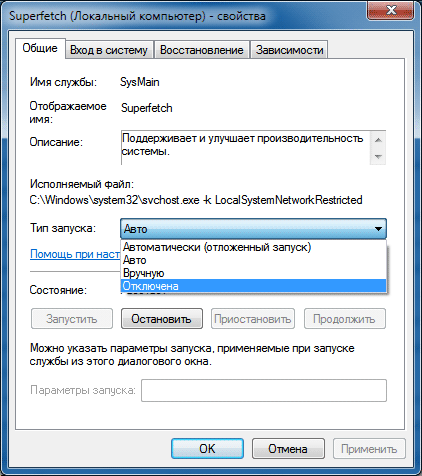
На вкладке Общие нажмите кнопку Остановить и в раскрывающемся списке Тип запуска выберите Отключена.
Итак, главная трудность измерения латентности памяти на рассматриваемой платформе обусловлена двумя отмеченными выше обстоятельствами: наличием у процессора механизма Hardware Prefetch и предвыборкой сразу двух соседних 64-байтных строк из памяти в кэш процессора.
Учитывая изложенную выше теоретическую базу, в нашей первой «официальной» методике было решено использовать следующие параметры для теста латентности оперативной памяти.
Название пресета: Minimal RAM Latency, 16MB Block, L2 Cache Line
Размер блока: 16 МБ
Размер шага: эффективная длина строки L2-кэша (128 байт для Pentium 4)
Режим обхода: псевдослучайный
Использование данного режима позволяет получить примерно следующий результат.
Кривые псевдослучайного и случайного обхода сохраняются на почти постоянном уровне, т.е. эффективность алгоритма Hardware Prefetch не изменяется при увеличении разгрузки Bus Interface Unit (BIU) процессора. В отличие от кривых прямого и обратного линейного обхода памяти, где разгрузка шины явно увеличивает эффективность Hardware Prefetch. На основании анализа этих данных в свое время был сделан вывод о том, что измерение латентности памяти данным образом (используя данные псевдослучайного обхода) можно считать вполне адекватным.

Сразу отметим: данные настройки рассчитаны исключительно для тестовых целей, о чем говорится в самой программе. Для нормального режима работы процессора в частности, и всей системы в целом трогать их не рекомендуется. Опишем вкратце каждую из них.
Итак, отметим главное: отныне у нас есть способ отключить обе особенности механизма аппаратной предвыборки данных: как сам алгоритм, так и предвыборку смежной строки (которая, заметим, может осуществляться независимо от использования Hardware Prefetch).
Последовательность действий для измерения латентности памяти вторым методом будет выглядеть следующим образом.
1. Отключить аппаратную предвыборку в Platform Info -> Tweaks, выставив Hardware Prefetch Queue в положение Disabled.
2. Выбрать тест Microarchitecture -> D-Cache Arrival, пресет Minimal RAM Latency, 16MB Block, L2 Cache Line, или выставить следующие настройки вручную:
Размер блока: 16 МБ
Размер шага: эффективная длина строки L2-кэша (128 байт для Pentium 4)
Режим обхода: псевдослучайный3. Включить аппаратную предвыборку в Platform Info -> Tweaks, выставив Hardware Prefetch Queue в положение Enabled.
Необходимо проверить, как данные предварительной выборки влияют на эффективность. Как заставить предварительную выборку некоторых значений из памяти в кэш, прежде чем они будут подсчитаны?
Решение
Во-первых, я полагаю, что tab большой двумерный массив, такой как статический массив (например, int tab[1024*1024][1024*1024] ) или динамически распределяемый массив (например, int** tab и после malloc с). Здесь вы хотите предварительно получить некоторые данные из tab в кэш, чтобы сократить время выполнения.
Просто я не думаю, что вам нужно вручную вставлять какую-либо предварительную выборку в ваш код, где выполняется простое сокращение для двумерного массива. Современные процессоры будут делать автоматическую предварительную выборку, если это необходимо и выгодно.
Два факта, которые вы должны знать для этой проблемы:
(1) Вы уже используете пространственную местность tab внутри самой внутренней петли. однажды tab[i][0] считывается (после пропуска кэша или сбоя страницы) данные из tab[i][0] в tab[i][15] будет в вашем кэше процессора, при условии, что размер строки кэша составляет 64 байта.
(2) Однако, когда код пересекается в строке, т.е. tab[i][M-1] в tab[i+1][0] , очень вероятно, что произойдет промах холодного кэша, особенно когда tab является динамически распределенным массивом, где каждая строка может быть распределена фрагментарно. Однако, если массив размещен статически, каждая строка будет находиться в памяти непрерывно.
Таким образом, предварительная выборка имеет смысл только тогда, когда вы читаете (1) первый элемент следующей строки и (2) j + CACHE_LINE_SIZE/sizeof(tab[0][0]) досрочно.
Вы можете сделать это, вставив операцию предварительной выборки (например, __builtin_prefetch ) в верхней петле. Однако современные компиляторы не всегда могут выдавать такие инструкции предварительной выборки. Если вы действительно хотите это сделать, вы должны проверить сгенерированный двоичный код.
Однако, как я уже сказал, я делаю не Рекомендую вам сделать это, потому что современные процессоры в основном будут выполнять автоматическую предварительную выборку, и эта автоматическая предварительная выборка будет в основном превосходить ваш ручной код. Например, в процессорах Intel, таких как процессоры Ivy Bridge, есть несколько средств предварительной выборки данных, таких как предварительная выборка в кэш L1, L2 или L3. (Я не думаю, что мобильные процессоры имеют причудливый предварительный сборщик данных, хотя). Некоторые prefetchers будут загружать смежные строки кэша.
Если вы выполняете более дорогие вычисления на больших двумерных массивах, есть много альтернативных алгоритмов, которые более удобны для кэшей. Ярким примером будет заблокированная (озаглавленная) матрица умножается. Умножение наивной матрицы переносит много пропусков кэша, но блокированный алгоритм значительно уменьшает промахы кэша, вычисляя небольшие подмножества, подходящие для кэшей. Смотрите некоторые ссылки, такие как этот .
Другие решения
prefetch_address может быть недействительным, не будет segfault. Если есть слишком маленькая разница между prefetch_address и текущее местоположение, там не может быть никакого эффекта или даже замедления. Попробуйте установить его как минимум на 1 Кб.
Что-то вроде того. Тем не менее, это зависит от:
1. Вы не заканчиваете чтение вне выделенной памяти [слишком много].
2. Цикл J не намного больше, чем 64 байта. Если это так, вы можете добавить больше шагов temp += *tptr; tptr += 64; в начале цикла.
keep_temp_alive после цикла важно, чтобы компилятор полностью не удалял temp как ненужные загрузки.
К сожалению, я слишком медленно пишу универсальный код, чтобы предлагать встроенные инструкции, пункты за которые идут Леониду.
Читайте также: